基于Q-learning的无人机三维路径规划(含完整C++代码)
目录
1.实验目标
2.相关原理
3.实验过程
3.1基于Q-learning的三维模型创建
3.2无人机类、环境类和障碍物类的建立
3.3继承和多态的实现
3.4训练
3.5测试
4.完整代码
main.cpp
Q-learning.cpp
train.cpp
test.cpp
environment.cpp
map.cpp
obstacles.cpp
view.cpp
uav.h
obstacle.h
envionment.h
5.实验结果
5.1图形界面
5.2训练结果
5.3飞行路径
5.4决策优化奖励
5.5路径规划
6.参考文献
1.实验目标
通过C++编写一段程序,采用Q-learning算法实现一架无人机的智能三维航线规划。定义无人机类,包含飞行半径、最大平飞速度、最小平飞速度、垂直飞行速度、最大飞行高度、最小飞行高度、最大飞行过载等属性。。算法的仿真环境中定义两种环境类,自然环境与静态障碍物,其中自然环境类包括地形、风速、风向、温度、光照等属性,障碍物包括位置、大小、轮廓顶点、移动速度、移动路线等属性。定义多种相关的环境类时,使用继承与多态的方法。通过算法和代码实现无人机自动分辨最佳路线,要求避开障碍物,并根据具体环境分析出适合的路线,最后找出一条最佳路线完成目标,即到达终点。2.相关原理
无人机的三维航迹规划就是要在综合考虑无人机的飞行时间、燃料消耗、外界威胁等因素的前提下,为无人机规划出一条最优或者是最满意的三维飞行航迹,以保证飞行任务的圆满完成。
随着无人机系统的功能越来越强大,其操纵越来越复杂,而现代飞行任务的难度及强度也在不断增加,良好的三维航迹规划成为提高无人机系统任务完成质量和生存概率的重要途径之一。
基于强化学习的航迹规划方法不仅具有与随机线路图法相似的在规划时间和航迹质量之间进行折中的能力,而且其本身具有一定的鲁棒性和对动态环境的适应能力。目前,强化学习方法已经在智能机器人导航、路径规划和运动控制领域取得了许多成功的应用。
无人机通过 Agent 与环境交互,获得航迹过程的本质是马尔可夫决策过程(Markov decision process,MDP),无人机的下一个空间状态只与当前的状态信息有关,与之前的信 息状态无关,即无人机航迹规划的过程具有马尔可夫性。 MDP 由< S,A,P,R,γ >五个元素构成:
S 表示空间状态的集合,s ∈ S,st 表示 t 时刻的 空间状态;A 表示动作策略的集合,a ∈ A,at 表示 t 时刻的 动作策略;P 表示状态转移概率, 表示当前状态 s 下,经 过动作策略 a 后,状态变为 s' 的概率;R 表示环境根据智能体的状态与动作,给予智能 体的奖励,是奖励取值的集合;γ 为“折扣”,表示后续策略对当前状态的影响, γ 为 0 表示只关心当前奖励,γ 越大表示对未来奖励越看重。Q-Learning 算法是异策略时序差分价值迭代的无模型算法。算法基于状态 s,采用 ε- 贪心策略选择动作 a,在状态 s 下执行当前动作 a,得到新状态 s' 和奖励 R,价值函数 Q(s, a)更新公式为:
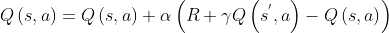
基于Q-Learning 学习的无人机航迹规划方法是基于强化学习的航迹规划领域最重要的方法之一。然而,现有的基于Q-Learning 学习的无人机航迹规划方法的思想与传统航迹规划算法一样,仍然是基于预先定义的代价函数生成一条具有最小代价的航迹。虽然该类算法已经取得了大量重要的理论和应用成果,但由于其规划过程中没有考虑诸如无人机的最大爬升/下降率和最小转弯半径等航迹约束条件,使其存在2个重要的缺点:
算法获得的最小代价航迹不一定满足实际要求,甚至对无人机来说根本无法飞行实施;算法的规划空间离散化过程缺少依据,往往采用较小的离散化步长以保证离散化过程的合理性,这使得最终离散规划问题具有很大的搜索空间,因此其只适用于二维平面内的航迹规划问题。当这类算法在无人机航迹规划问题中应用时,由于其无法充分利用无人机的三维飞行能力,故其规划获得的航迹从根本上说就是次优航迹。在现有的基于Q-Learning 学习的航迹规划算法的基础上,设计出一种能够有效完成无人机三维航迹规划任务的航迹规划方法。该方法利用无人机的航迹约束条件指导规划空间离散化,不仅减小了最终离散规划问题的规模,也在一定程度上提高规划获得的优化航迹的可用性。最后,通过测试在不同地图环境中的实验结果验证了该方法的有效性。
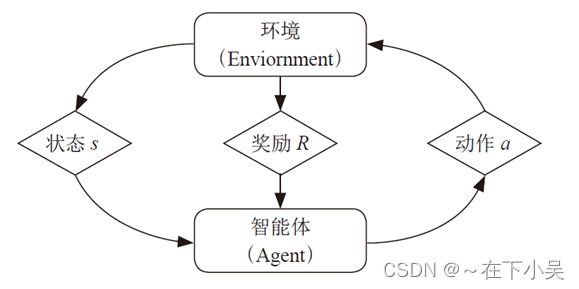
强化学习模型由智能体和环境组成,其主要内容是智能体通过与环境交互,对当前状态下不同动作策略的价值函数进行估计,执行高回报动作,避免执行低回报或惩罚的动作,从而达到不断改进策略,逼近最优决策的效果。
强化学习模型的机理图如图所示:
3.实验过程
3.1基于Q-learning的三维模型创建
要实现基于Q-learing的无人机智能航线规划,需建立回报奖励地图,经过慎重讨论后决定,对空间进行栅格化,将模拟的现实空间栅格化为M*M*M的三维数组模型,对数组中每一栅格进行赋值处理,赋上用环境回报函数所求得的回报奖励,完成对现实空间的模拟。
3.2无人机类、环境类和障碍物类的建立
在无人机类中,包含了飞行半径、最大平飞速度、最小平飞速度、垂直飞行速度、最大飞行高度、最小飞行高度、最大飞行过载这些属性。其中飞行半径用无人机最大可以走的格子数来实现;最大平飞速度和最小平飞速度用于在顺风和逆风环境中与风速相结合在设置的奖励方程中求环境的奖励;垂直飞行速度用于在高山环境这类在现实中需要做出垂直高度调整的环境中与风速结合代入设置的奖励方程中求环境的奖励;最大风行高度和最小飞行高度用于与每个环境的高度,障碍物的大小作比较,考虑到现实情况,当最大飞行高度低于环境高度或最小飞行高度高于环境高度时,在该环境处的会为很小的负值,表示无法通过。
在自然环境类中,包含了地形、风速、风向、温度、光照、环境奖励这些属性,并且我们对每一种环境设置了环境奖励方程,该方程由各中队无人机有影响的环境类属性组成,用于求该环境的回报奖励。其中,地形我们设为高度,考虑到实际地形作为判断无人机能否通过该环境的首要因素;风向和风向结合,风速分为顺风和逆风两种,我们用1来表示顺风,-1来表示逆风,作为风速的系数,风速大小用绝对值的大小来体现;温度和光照也作为了环境奖励方程中的一部分。
在障碍物类中我们设置了位置、大小、轮廓顶点等属性。其中位置用x,y,z来表示,用于确定障碍物在设置的地图中的坐标;大小类似于环境类中的地形,我们将它设置为高度;轮廓顶点则用于表示该障碍物会占用他自身坐标周围多少个格子数。
3.3继承和多态的实现
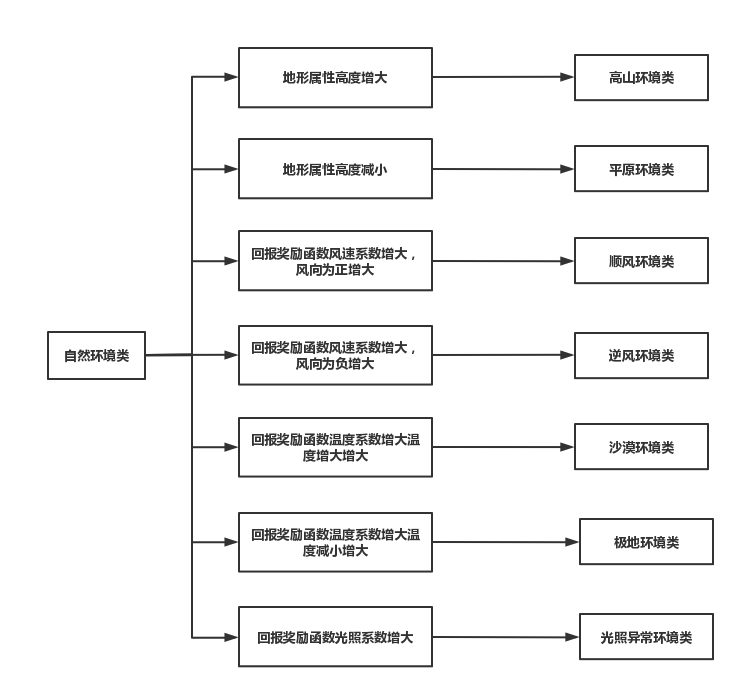
继承和多态的实现,主要体现在定义多种相关的环境类时。在定义自然环境类时,我们首先定义了一个基类,包含要求的各种基本属性和计算环境回报奖励的虚函数,在这之后定义了环境类基类的七个派生类,分别是高山环境类,用以模拟地形过高的环境;平原环境类,用以模拟地形过低的环境;顺风环境类,用以模拟风向为正方向,风速系数为正值的环境;逆风环境类,用以模拟风向为反方向,风速系数为负值的环境;沙漠环境类,用以模拟温度过高,光照过强的环境;极地环境类,用以模拟温度过低,光照过弱的环境;光照异常环境类,用以模拟各处栅格的光照差异过大的环境。在每个派生类中,我们都依据基类中定义的虚函数进行了函数的重载,以实现在每种派生类中由于模拟的环境的不同导致的对环境奖励回报方程的不同写法,从而实现继承和多态。
3.4训练
| 参数 | 数值 | 单位 |
| 移动方向i | 1-26 | - |
| 贪心系数G | 0.2 | - |
| 回报系数R | 0.8 | - |
| 训练次数 | 3000 | 次 |
| 最大移动次数 | 80 | 步 |
| 地图边长M | 5(8) | 格 |
| 地图数量 | 4(10) | 个 |
3.4.1数据结构Q-table
Qtable 是一张表,存储着无人机的每一个状态下,执行不同行为时的预期奖励。在航线规划训练中,对于固定的一张地图,无人机的状态可以由向量(x,y,z)表示其位置,现实世界是不变的,所以不算作状态;在本项目程序中,数组Qtablexyzi 代表智能体在(x,y)位置下执行动作i时的预期奖励,由于是三维空间,i有26个值。
3.4.2算法
优化决策的过程由马尔科夫决策过程对Qtable 进行优化。该过程的核心方程为:
Q[x][y][z] [i] = Q[x][y][z] [i] + rate * ( r[x₁][y₁][z₁] + max( Q[x₁][y₁][z₁] [i] ))
即:执行一个策略之后无人机从x,y,z 移动到x1,y1,z1 点,那么在状态x,y,z 下执行动作 i 的奖励就是:下一个行为本身的收益 + 走到下一个方格之后,最好的预期收益。上式中,rate为一个比例系数,决定了预期收益的权重。本算法中取0.8。
3.4.3技巧
贪心系数Greedy = 0.2 。Q-learning本质上是贪心算法。但是如果每次都取预期奖励最高的行为去做,那么在训练过程中可能无法探索其他可能的行为,甚至会进入“局部最优”,无法完成游戏。所以,由贪心系数,使得无人机有Greedy的概率采取最优行为,也有一定概率探索新的路径。
3.4.4回报函数构造
航迹规划本质上是搜索满足约束条件的最优航迹。在基于强化学习的无人机三维避障航迹规划问题中,学习目标即航迹评价指标用回报函数进行形式化表达。回报函数的构造需要综合考虑影响航迹性能的各种指标、指标的量化方法及各项指标权重的选择等。
在本程序中,我们考虑了风力,山体,温度,光照等环境因素的影响,分别设计了其连续回报函数,其整体形式是
Reward=w1×f1+w2×f2+w3×f3
其中w1 ~w3 为和为0.5的非负加权系数,f1 ~f3 为环境参量,其大小受环境因素影响,在程序中我们使用1和-1(1表示环境良好,-1代表环境较差)来使其量化。
3.4.5打分表
表示无人机走到某个位置获得的分数。在巡线训练中,无人机经过的每一栅格都有由环境所得的奖励作为该位置的分数。
按照如上的训练策略,我们在最终测试前进行3000次训练,以得到尽可能准确的Qtable 表,使得无人机在最终测试时能够走最优航线。
3.5测试
通过之前的训练,团队已经得到尽可能准确的Qtable 表,现在可以进行最终测试验证训练结果,将最终走出的最优路径输出。
问题1:最终测试时遭遇到了程序会陷入循环,无法走出的难题,团队经过输出位置的方式进行分析,发现问题在于无人机陷入了局部最优的困境,导致在两个位置之间不断来回,就建立了用于跳出循环的函数。
解决方案:如果走最大的Qtable 值无法走出,就原路返回,寻找第二大的Qtable 值,如此直到走出循环,从而解决了局部最优的问题。
问题2:原本Qtable 数组开的太小,导致空间不足,当训练次数过多时,会出现程序自动终止,无法完成训练的情况。这是一个很隐蔽性的错误,我们一开始没意识到是Qtable 数组太小的原因,一直在反复观察和测试训练程序和最终测试程序,经过很长时间的琢磨才发现是Qtable 数组开的太小的缘故
4.完整代码
main.cpp
/*主函数*/#include<iostream>#include<graphics.h>#include"map.h"using namespace std;void initmap(double sc[M][M][M], double sc1[M][M][M]);void show();void train();//int main()//{//int flag = 0;//cout << "地图模式(1-6):" << endl;//cout << "1 - 普通地图" << endl;//cout << "2 - 高低不平的地图" << "\n" << "3 - 风速较高的地图" << "\n" << "4 - 温度较高的地图" << "\n" << "5 - 温度较低的地图" << "\n" << "6 - 复杂环境的地图" << endl;//cout << "\n" << endl;//cout << "请选择地图模式(1 - 6):" << endl;//cin >> flag;//switch (flag)//{//case 1://initmap(score0, score1);//train();//break;//case 2://initmap(score0, score2);//train();//break;//case 3://initmap(score0, score3);//train();//break;//case 4://initmap(score0, score4);//train();//break;//case 5://initmap(score0, score5);//train();//break;//case 6://initmap(score0, score6);//train();//break;//}//}int main(){show();ExMessage m;//鼠标while (1){m = getmessage(EM_MOUSE | EM_KEY);switch (m.message){case WM_LBUTTONDOWN:if (m.x >= 200 && m.x <= 500 && m.y >= 130 && m.y <= 430){cout << "平原" << endl;initmap(score0, score9);train();cout << "平原地形" << endl;cout << "********" << endl;break;}else if (m.x >= 700 && m.x <= 1000 && m.y >= 450 && m.y <= 750){initmap(score0, score10);train();cout << "沙漠地形" << endl;cout << "********" << endl;break;}else if (m.x >= 700 && m.x <= 1000 && m.y >= 130 && m.y <= 430){initmap(score0, score9);train();cout << "雪地地形" << endl;cout << "********" << endl;break;}else if (m.x >= 200 && m.x <= 500 && m.y >= 450 && m.y <= 750){initmap(score0, score8);train();cout << "山地地形" << endl;cout << "********" << endl;break;}case WM_KEYDOWN:if (m.vkcode == VK_ESCAPE){closegraph();break;return 0;}}}}Q-learning.cpp
/*Q-learning*/#include"map.h"#include<iostream>#include<cstdlib>#include<algorithm>using namespace std;double rate = 0.8;double greedy = 20;int vis[M+5][M+5][M+5] = { 0 };double Qtable[M + 5][M + 5][M + 5][30] = { 0.0 };void set(){for (int i = 0; i < M; i++){for (int j = 0; j < M; j++){//在第一层就不能再向下走Qtable[0][i][j][down] = S;Qtable[0][i][j][mid_down_forward] = S;Qtable[0][i][j][mid_down_backward] = S;Qtable[0][i][j][mid_down_left] = S;Qtable[0][i][j][mid_down_right] = S;Qtable[0][i][j][edge5] = S;Qtable[0][i][j][edge6] = S;Qtable[0][i][j][edge7] = S;Qtable[0][i][j][edge8] = S;//在第M-1层就不能再向上走Qtable[M - 1][i][j][up] = S;Qtable[M - 1][i][j][mid_up_forward] = S;Qtable[M - 1][i][j][mid_up_backward] = S;Qtable[M - 1][i][j][mid_up_left] = S;Qtable[M - 1][i][j][mid_up_right] = S;Qtable[M - 1][i][j][edge1] = S;Qtable[M - 1][i][j][edge2] = S;Qtable[M - 1][i][j][edge3] = S;Qtable[M - 1][i][j][edge4] = S;//在最左面就不能再向左飞Qtable[i][0][j][left0] = S;Qtable[i][0][j][mid_up_left] = S;Qtable[i][0][j][mid_down_left] = S;Qtable[i][0][j][mid1] = S;Qtable[i][0][j][mid3] = S;Qtable[i][0][j][edge1] = S;Qtable[i][0][j][edge3] = S;Qtable[i][0][j][edge5] = S;Qtable[i][0][j][edge7] = S;//在最后面的就不能再向右飞Qtable[i][M - 1][j][right0] = S;Qtable[i][M - 1][j][mid_up_right] = S;Qtable[i][M - 1][j][mid_down_right] = S;Qtable[i][M - 1][j][mid2] = S;Qtable[i][M - 1][j][mid4] = S;Qtable[i][M - 1][j][edge2] = S;Qtable[i][M - 1][j][edge4] = S;Qtable[i][M - 1][j][edge6] = S;Qtable[i][M - 1][j][edge8] = S;//在最后面的就不能再向后飞Qtable[i][j][0][backword] = S;Qtable[i][j][0][mid_down_backward] = S;Qtable[i][j][0][mid_up_backward] = S;Qtable[i][j][0][mid3] = S;Qtable[i][j][0][mid4] = S;Qtable[i][j][0][edge3] = S;Qtable[i][j][0][edge4] = S;Qtable[i][j][0][edge7] = S;Qtable[i][j][0][edge8] = S;//在最前面的就不能再向前飞Qtable[i][j][M - 1][forward0] = S;Qtable[i][j][M - 1][mid_down_forward] = S;Qtable[i][j][M - 1][mid_up_forward] = S;Qtable[i][j][M - 1][mid1] = S;Qtable[i][j][M - 1][mid2] = S;Qtable[i][j][M - 1][edge1] = S;Qtable[i][j][M - 1][edge2] = S;Qtable[i][j][M - 1][edge5] = S;Qtable[i][j][M - 1][edge6] = S;}}srand(time(0));}void init(int& x, int& y, int& z, int& dend)//初始化位置{x = 0;y = 0;z = 0;dend = 0;}//Qtable[z][x][y][i]=Qtable[z][x][y][i]+rate*(r[z1][x1][y1]+max(Qtable[z1][x1][y1]double get_expected_max_score(int x, int y, int z){double s = -10000;for (int i = 1; i <= 26; i++){s = max(s, Qtable[z][x][y][i]);}return s;}double go(int dir, int& x, int& y, int& z, int& dend){//如果走出了边界,奖励为0,xyz值不变if ((z == 0 && dir == down) || (z == 0 && dir == mid_down_backward) || (z == 0 && dir == mid_down_forward) || (z == 0 && dir == edge5) || (z == 0 && dir == edge6) || (z == 0 && dir == edge7) || (z == 0 && dir == edge8) || (z == 0 && dir == mid_down_left) || (z == 0 && dir == mid_down_right))return S;if ((z == M - 1 && dir == up) || (z == M - 1 && dir == mid_up_backward) || (z == M - 1 && dir == mid_up_forward) || (z == M - 1 && dir == mid_up_left) || (z == M - 1 && dir == mid_up_right) || (z == M - 1 && dir == edge1) || (z == M - 1 && dir == edge2) || (z == M - 1 && dir == edge3) || (z == M - 1 && dir == edge4))return S;if ((x == 0 && dir == left0) || (x == 0 && dir == mid_down_left) || (x == 0 && dir == mid_up_left) || (x == 0 && dir == mid1) || (x == 0 && dir == mid3) || (x == 0 && dir == edge1) || (x == 0 && dir == edge3) || (x == 0 && dir == edge5) || (x == 0 && dir == edge7))return S;if ((x == M - 1 && dir == right0) || (x == M - 1 && dir == mid_down_right) || (x == M - 1 && dir == mid_up_right) || (x == M - 1 && dir == mid2) || (x == M - 1 && dir == mid4) || (x == M - 1 && dir == edge2) || (x == M - 1 && dir == edge4) || (x == M - 1 && dir == edge6) || (x == M - 1 && dir == edge8))return S;if ((y == 0 && dir == backword) || (y == 0 && dir == mid_down_backward) || (y == 0 && dir == mid_up_backward) || (y == 0 && dir == mid3) || (y == 0 && dir == mid4) || (y == 0 && dir == edge3) || (y == 0 && dir == edge4) || (y == 0 && dir == edge7) || (y == 0 && dir == edge8))return S;if ((y == M - 1 && dir == forward0) || (y == M - 1 && dir == mid_down_forward) || (y == M - 1 && dir == mid_up_forward) || (y == M - 1 && dir == mid1) || (y == M - 1 && dir == mid2) || (y == M - 1 && dir == edge1) || (y == M - 1 && dir == edge2) || (y == M - 1 && dir == edge3) || (y == M - 1 && dir == edge4))return S;//走到下一步,变更无人机位置if (dir == forward0)y++;if (dir == mid_up_forward) { z++, y++; }if (dir == mid_down_forward) { z--, y++; }if (dir == mid1) { x--, y++; }if (dir == mid2) { x++, y++; }if (dir == edge1) { z++, x--, y++; }if (dir == edge2) { z++, x++, y++; }if (dir == edge5) { z--, x--, y++; }if (dir == edge6) { z--, x++, y++; }if (dir == up) { z++; }if (dir == mid_up_left) { z++, x--; }if (dir == mid_up_right) { z++, x++; }if (dir == left0) { x--; }if (dir == right0) { x++; }if (dir == mid_down_left) { z--, x--; }if (dir == mid_down_right) { z--, x++; }if (dir == down) { z--; }if (dir == mid_up_backward) { z++, y--; }if (dir == mid_down_backward) { z--, y--; }if (dir == mid3) { x--, y--; }if (dir == mid4) { x++, y--; }if (dir == edge3) { x--, z++, y--; }if (dir == edge4) { x++, z++, y--; }if (dir == edge7) { x--, z--, y--; }if (dir == edge8) { x++, z--, y--; }if (dir == backword) { y--; }//如果走到了终点,返回到达终点的奖励//地图终点在[M-1,M-1,M-1]if (x == M - 1 && y == M - 1 && z == M - 1){dend = 1;return score0[z][x][y];}else if (x >= 0 && x < M && y >= 0 && y < M && z >= 0 && z < M){//执行后,得到相应奖励double temp = get_expected_max_score(x, y, z);return score0[z][x][y] + rate * temp;}elsereturn 0;}train.cpp
/*训练*/#include<iostream>#include<cstdlib>#include <cstring>#include <cstdio>#include <ctime>#include <conio.h>#include<vector>#include<algorithm>#include<graphics.h>#include"map.h"using namespace std;void game_final_test();void set();void init(int& x, int& y, int& z, int& dend);double get_expected_max_score(int x, int y, int z);double go(int dir, int& x, int& y, int& z, int& dend);void initmap(double sc[M][M][M], double sc1[M][M][M]);void train(){set();cout << "*****************" << endl;cout << "训练中" << endl << endl;for (int i = 1; i <= 3000; i++){init(x, y, z, dend);int op;if (i % 100 == 0){cout << "*****************" << endl;cout << "第" << i << "次训练" << endl;}for (int j = 0; j < 80; j++){if (i % 100 == 0)cout << "第" << j + 1 << "步" << endl;int xx = x, yy = y, zz = z;if (rand() % 101 > greedy)op = rand() % 26 + 1;else{double maxx = -1000000;for (int m = 1; m < 27; m++)maxx = max(maxx + 0.0, Qtable[z][x][y][m]);for (int m = 1; m < 27; m++)if (maxx == Qtable[z][x][y][m])op = m;}double reward = go(op, x, y, z, dend);Qtable[zz][xx][yy][op] += reward / 1000;if (i % 100 == 0){cout << "方向\tX\tY\tZ\t奖励" << endl;cout << op << "\t";cout << x << "\t" << y << "\t" << z << "\t";cout << reward << endl << endl;}if (dend == 1)break;}//cout << endl;}cout << endl;cout << "*****************" << endl;cout << "无人机在X、Y、Z处执行不同方向的最终奖励" << endl << endl;for (int i = 0; i < M; i++){for (int j = 0; j < M; j++){for (int k = 0; k < M; k++){//cout << "最终奖励" << endl;cout << "X\tY\tZ" << endl;cout << i << "\t" << j << "\t" << k << "\t" << endl;for (int m = 1; m < 27; m++){cout << Qtable[i][j][k][m] << "\t";}cout << endl << endl;}}}game_final_test();}test.cpp
/*训练结果测试 */#include"map.h"#include<iostream>#include<vector>using namespace std;vector<int> v;void init(int& x, int& y, int& z, int& dend);double go(int dir, int& x, int& y, int& z, int& dend);int x, y, z, dend;void game_final_test(){init(x, y, z, dend);int q = 0;/*当没有走到终点时*/while (!(x == (M - 1) && y == (M - 1) && z == (M - 1))){int dir;while (1){int xx = x, yy = y, zz = z;vector<int>::iterator it;double maxx = -1000000;for (int m = 1; m < 27 && v.end() == find(v.begin(), v.end(), m); m++)maxx = max(maxx + 0.0, Qtable[z][x][y][m]);for (int m = 1; m < 27; m++)if (maxx == Qtable[z][x][y][m])dir = m;if (dir == forward0){yy++;if (yy == M){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == mid_up_forward){zz++, yy++;if (zz == M || yy == M){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == mid_down_forward){zz--, yy++;if (zz == -1 || yy == M){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == mid1){xx--, yy++;if (xx == -1 || yy == M){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == mid2){xx++, yy++;if (xx == M || yy == M){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == edge1){zz++, xx--, yy++;if (zz == M || yy == M || xx == -1){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == edge2){zz++, xx++, yy++;if (zz == M || yy == M || xx == M){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == edge5){zz--, xx--, yy++;if (zz == -1 || yy == M || xx == -1){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == edge6){zz--, xx++, yy++;if (zz == -1 || yy == M || xx == M){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == up){zz++;if (zz == M){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == mid_up_left){zz++, xx--;if (zz == M || xx == -1){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == mid_up_right){zz++, xx++;if (zz == M || xx == M){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == left0){xx--;if (xx == -1){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == right0){xx++;if (xx == M){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == mid_down_left){zz--, xx--;if (zz == -1 || xx == -1){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == mid_down_right){zz--, xx++;if (zz == -1 || xx == M){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == down){zz--;if (zz == -1){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == mid_up_backward){zz++, yy--;if (zz == M || yy == -1){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == mid_down_backward){zz--, yy--;if (zz == -1 || yy == -1){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == mid3){xx--, yy--;if (yy == -1 || xx == -1){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == mid4){xx++, yy--;if (yy == -1 || xx == M){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == edge3){xx--, zz++, yy--;if (zz == M || yy == -1 || xx == -1){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == edge4){xx++, zz++, yy--;if (zz == M || yy == -1 || xx == M){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == edge7){xx--, zz--, yy--;if (zz == -1 || yy == -1 || xx == -1){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == edge8){xx++, zz--, yy--;if (zz == -1 || yy == -1 || xx == M){v.push_back(dir);continue;}else{v.clear();break;}}if (dir == backword){yy--;if (yy == -1){v.push_back(dir);continue;}else{v.clear();break;}}}q++;cout << "**********" << endl;cout << "第" << q << "次飞行" << endl;cout << "飞行方向:" << dir << endl;go(dir, x, y, z, dend);cout << "X\tY\tZ" << endl;cout << x << "\t" << y << "\t" << z << endl << endl;//如果走到了一个点,记录这个点的vis = 1, 方便输出观察 vis[x][y][z] = 1;if (q >= 200){cout << "很遗憾,运气不佳,路径规划失败,但这种情况概率极低,关闭界面,重试即可" << endl;break;}}int m = 1;if (q < 200){/*输出,带有 @ 符号的代表智能体选择的路径*/cout << "将三维地图展开,";cout << "带有 @ 符号的代表无人机选择的路径" << endl;for (int i = 0; i < M; i++){for (int j = 0; j < M; j++){for (int k = 0; k < M; k++){cout << "[" << i << "," << j << "," << k << "]";if (vis[i][j][k] == 1){cout << '@' << m;m++;}cout << "\t";}}cout << endl << endl;}cout << "一共进行了" << m - 1 << "次飞行方向的选择,就到达终点,此路线为考虑环境与避开障碍物的最佳路径,路径规划成功!" << endl;}}environment.cpp
/*环境类.cpp*/#include"environment.h"double Environment::get_reward(int h_h, int l_h){{if (terrain<h_h && terrain>l_h)//高度起决定性作用{reward = -(0.1 * wind_direction * wind_speed + 0.2 * temperature + 0.1 * light);//环境获得奖励的计算方程}elsereward = -100;return reward;}}Mountain::Mountain()//构造函数,给高山环境的属性赋值{terrain = 100;wind_speed = 1;wind_direction = 1;light = 1;}double Mountain::get_reward(int h_h, int l_h, int v_v)//计算环境获得奖励的虚函数,传入飞机的最高和最低飞行高度,和飞机垂直方向的速度{if (terrain<h_h && terrain>l_h)//高度起决定性作用{reward = -(0.1 * wind_direction * (wind_speed + v_v) + 0.2 * temperature + 0.1 * light);//环境获得奖励的计算方程,和基类一样,该怎么化简呢?}elsereward = -100;return reward;}Plain::Plain()//构造函数,给平原环境的属性赋值{terrain = 1;wind_speed = 1;wind_direction = 1;light = 1;}double Plain::get_reward(int h_h, int l_h, int v_v)//计算环境获得奖励的虚函数,传入飞机的最高和最低飞行高度{if (terrain<h_h && terrain>l_h)//高度起决定性作用{reward = -(0.1 * wind_direction * (wind_speed + v_v) + 0.2 * temperature + 0.1 * light);//环境获得奖励的计算方程,和基类一样,该怎么化简呢?}elsereward = -100;return reward;}Against_wind::Against_wind()//构造函数,给环境的属性赋值{terrain = 1;wind_speed = 1;wind_direction = -1;light = 1;}double Against_wind::get_reward(int h_h, int l_h, int h_s)//计算环境获得奖励的虚函数,第三个参数传入飞机水平最大速度{if (terrain<h_h && terrain>l_h)//高度起决定性作用{reward = -(0.2 * wind_direction * (h_s - wind_speed) + 0.2 * temperature + 0.1 * light);//环境获得奖励的计算方程,风速乘以风向的系数变大}elsereward = -100;return reward;}With_wind::With_wind()//构造函数,给环境的属性赋值{terrain = 1;wind_speed = 1;wind_direction = 1;light = 1;}double With_wind::get_reward(int h_h, int l_h)//计算环境获得奖励的虚函数,第三个参数传入飞机水平最小速度{if (terrain<h_h && terrain>l_h)//高度起决定性作用{reward = -(0.2 * (wind_direction + l_h) * wind_speed + 0.2 * temperature + 0.1 * light);//环境获得奖励的计算方程,风速乘以风向的系数变大}elsereward = -100;return reward;}Desert::Desert()//构造函数,给环境的属性赋值{terrain = 1;wind_speed = 1;wind_direction = 1;light = 1;}double Desert::get_reward(int h_h, int l_h)//计算环境获得奖励的虚函数{if (terrain<h_h && terrain>l_h)//高度起决定性作用{reward = -(0.1 * wind_direction * wind_speed + 0.3 * temperature + 0.1 * light);//环境获得奖励的计算方程,温度的系数变大}elsereward = -100;return reward;}Polar::Polar()//构造函数,给环境的属性赋值{terrain = 1;wind_speed = 1;wind_direction = 1;light = 1;}double Polar::get_reward(int h_h, int l_h)//计算环境获得奖励的虚函数{if (terrain<h_h && terrain>l_h)//高度起决定性作用{reward = -(0.1 * wind_direction * wind_speed + 0.3 * temperature + 0.1 * light);//环境获得奖励的计算方程,温度的系数变大}elsereward = -100;return reward;}Light::Light()//构造函数,给环境的属性赋值{terrain = 1;wind_speed = 1;wind_direction = 1;light = 1;}double Light::get_reward(int h_h, int l_h)//计算环境获得奖励的虚函数{if (terrain<h_h && terrain>l_h)//高度起决定性作用{reward = -(0.1 * wind_direction * wind_speed + 0.2 * temperature + 0.2 * light);//环境获得奖励的计算方程,光照的系数变大}elsereward = -100;return reward;}map.cpp
/*地图*/#include"map.h"double r1, r2, r3, r4, r5, r6, r7;void give_reward(){Uav uav1(10, 1, 1, 1, 1, 1, 1);Mountain mountain;Plain plain;Against_wind wind1;With_wind wind2;Desert desert;Polar polar;Light light;//配置环境变量的相应值r1 = mountain.get_reward(uav1.h_height, uav1.l_height, uav1.v_speed);//高度过高r2 = plain.get_reward(uav1.h_height, uav1.l_height, uav1.v_speed);//高度过低r3 = wind1.get_reward(uav1.h_height, uav1.l_height, uav1.v_speed);//逆风r4 = wind2.get_reward(uav1.h_height, uav1.l_height);//顺风r5 = desert.get_reward(uav1.h_height, uav1.l_height);//过热r6 = polar.get_reward(uav1.h_height, uav1.l_height);//过寒r7 = light.get_reward(uav1.h_height, uav1.l_height);//光照异常}//地图初始化选择模式void initmap(double sc[M][M][M], double sc1[M][M][M]) {for (int i = 0; i < M; i++) {for (int j = 0; j < M; j++) {for (int k = 0; k < M; k++) {sc[i][j][k] = sc1[i][j][k];}}}}double score0[M][M][M] = { 0 };//double score1[M][M][M] =//{////0,0,-1,//0,r1,0,//0,0,-1,////-1,0,r2,//-2,-1,0,//0,0,-1,////0,-5,0,//-1,0,-1,//-1,0,30//};//普通地图////double score2[M][M][M] =//{//0,r2,r2,//0,r1,r2,//r3,r2,-1,////r2,0,-2,//0,r2,r1,//r2,0,r2,////-1,r2,-3,//r2,r1,0,//r2,-1,30//};//高低不平的地图////double score3[M][M][M] =//{//0,r3,-1,//-2,r4,r3,//0,0,r3,////-2,r3,r4,//0,r3,0,//r4,0,r3,////0,-1,r3,//-1,r3,r4,//0,0,30//};//风速较高的地图////double score4[M][M][M] =//{//0,-2,r5,//-1,0,0,//r7,0,-1,////r5,r7,0,//r5,0,0,//-1,r7,r5,////0,0,r7,//r7,r7,r5,//-2,0,30//};//温度较高的地图////double score5[M][M][M] =//{//0,-1,r1,//r6,0,-1,//r2,0,r6,////r6,0,r7,//r2,r6,0,//r2,0,0,////r7,r6,-3,//-2,0,r2,//r2,r6,30//};//温度较低的地图////double score6[M][M][M] =//{//0,r1,-1,//r3,0,-2,//r6,-1,r3,////0,r7,r4,//r4,-1,r6,//-2,0,r4,////-2,r2,r6,//r7,0,r2,//0,-2,30//};//复杂环境的地图double score7[5][5][5] ={0,r5,r2,-1,-2,0,r5,-1,0,-2,r2,-1,r5,r5,0,-1,r2,r5,-2,-3,r7,r2,r5,r5,r2,0,0,r5,r5,-2,-2,r5,r3,0,0,r5,0,r5,0,r5,0,r5,0,r5,r5,r5,-1,0,0,-2,0,0,r5,0,0,r5,r5,0,0,-4,r2,0,0,r2,0,0,r2,r5,-3,0,r5,r2,r2,0,-2,r2,0,0,-3,r2,r2,-2,0,0,0,r5,r5,0,-3,0,r2,0,r5,0,r2,0,0,r5,r2,0,-3,0,0,-1,0,r2,r2,r5,r5,0,r2,r5,0,0 - 2,0,0,r2,r5,30};//沙漠地图double score8[5][5][5] ={0,r3,r4,r3,r4,r4,-1,-2,-1,r4,r3,-1,-2,r3,r3,r4,r4,0,0,r3,r3,r4,r4,r3,0,r4,r4,0,0,r3,r4,-1,-2,-1,r4,0,0,-2,-2,0,r4,r4,0,0,-2,r4,r4,r4,r4,0,r4,r6,0,-2,0,r4,r6,0,-1,0,0,0,0,0,-2,-2,r4,r7,0,-1,r4,0,0,r7,-3,r4,r6,0,-1,0,r4,-1,-2,-1,r4,-2,r4,r7,0,-1,r4,r4,0,0,r3,r4,r4,0,0,-2,r4,r4,0,0,-2,r4,r4,0,0,r3,r3,r4,r4,r3,0,-2,r4,r7,0,-1,r3,r4,r4,r3,30};//山地地图double score9[5][5][5] ={0,r3,r4,r3,r4,r4,-1,-2,-1,r4,r3,-1,-2,r3,r3,r4,r4,0,0,r3,r3,r4,r4,r3,0,r4,r4,0,0,r3,r4,-1,-2,-1,r4,0,0,-2,-2,0,r4,r4,0,0,-2,r4,r4,r4,r4,0,r4,r6,0,-2,0,r4,r6,0,-1,0,0,0,0,0,-2,-2,r4,r7,0,-1,r4,0,0,r7,-3,r4,r6,0,-1,0,r4,-1,-2,-1,r4,-2,r4,r7,0,-1,r4,r4,0,0,r3,r4,r4,0,0,-2,r4,r4,0,0,-2,r4,r4,0,0,r3,r3,r4,r4,r3,0,-2,r4,r7,0,-1,r3,r4,r4,r3,30};//平原地图double score10[5][5][5] ={0,0,0,-2,r7,0,r7,r6,r7,r6,-1,-2,0,r6,r7,0,-1,r6,r6,0,r6,r3,r6,-1,0,0,-2,-4,r7,r6,r6,r6,r6,r6,r6,0,r6,0,0,-2,0,r6,0,r7,0,-2,r7,0,0,-4,r2,r6,r6,r7,0,r3,r6,0,-2,r4,r4,r6,r7,0,-2,r6,-2,0,0,-2,r3,0,0,r6,-3,0,r6,0,0,-2,0,r7,r6,r7,r6,r4,r6,r7,0,-2,0,r6,0,r7,0,r6,r3,r6,-1,0,-2,r7,0,0,-4,0,-1,r6,r6,0,0,0,r6,r3,r7,0,-2,-1,r6,r6,0,0,r7,r6,30};//雪地地图obstacles.cpp
/*障碍物类.cpp*/#include"Obstacles.h"double Obstacles::get_reward(int h_h, int l_h)//计算获得奖励的虚函数,传入飞机的最高和最低飞行高度{if (size<h_h && size>l_h)//高度起决定性作用{reward = -0.1 * size;//获得奖励的计算方程}elsereward = -100;return reward;}Obstacles1::Obstacles1(){i = 1;j = 1;k = 1;size = 1;}double Obstacles1::get_reward(int h_h, int l_h)//计算获得奖励的虚函数,传入飞机的最高和最低飞行高度{if (size<h_h && size>l_h)//高度起决定性作用{reward = -0.1 * size;//获得奖励的计算方程}elsereward = -100;return reward;}Obstacles2::Obstacles2(){i = 2;j = 2;k = 2;size = 0;}double Obstacles2::get_reward(int h_h, int l_h)//计算获得奖励的虚函数,传入飞机的最高和最低飞行高度{if (size<h_h && size>l_h)//高度起决定性作用{reward = -0.1 * size;//获得奖励的计算方程}elsereward = -100;return reward;}view.cpp
/*界面*/#include<conio.h>#include<iostream>#include<stdlib.h>#include<graphics.h>using namespace std;void show(){IMAGE img1, img2, img3, img4, img5;//背景图initgraph(1200, 768,EW_SHOWCONSOLE);//initgraph(1200, 768);setbkcolor(WHITE);cleardevice();loadimage(&img1, L"6.jpg", 1200, 768, true);putimage(0, 0, &img1);loadimage(&img2, L"2.jpg", 300, 300);putimage(200, 130, &img2);loadimage(&img3, L"3.jpg", 300, 300);putimage(700, 450, &img3);loadimage(&img4, L"4.jpg", 300, 300);putimage(700, 130, &img4);loadimage(&img5, L"5.jpg", 300, 300);putimage(200, 450, &img5);settextcolor(WHITE);setbkmode(TRANSPARENT);settextstyle(30, 0, _T("宋体"));outtextxy(325, 60, _T("基于Q-learning的无人机三维路径规划"));settextcolor(WHITE);settextstyle(30, 0, _T("宋体"));outtextxy(320, 400, _T("平原"));settextcolor(WHITE);settextstyle(30, 0, _T("宋体"));outtextxy(320, 720, _T("山地"));settextcolor(WHITE);settextstyle(30, 0, _T("宋体"));outtextxy(820, 400, _T("雪地"));settextcolor(WHITE);settextstyle(30, 0, _T("宋体"));outtextxy(820, 720, _T("沙漠"));settextcolor(WHITE);settextstyle(20, 0, _T("宋体"));outtextxy(20, 20, _T("ESC:退出界面"));outtextxy(20, 50, _T("点击图片选择地形"));HWND hnd = GetHWnd();SetWindowText(hnd, L"C++大作业");/*while (1){m = getmessage(EM_MOUSE | EM_KEY);switch (m.message){case WM_LBUTTONDOWN:if (m.x >= 200 && m.x <= 500 && m.y >= 130 && m.y <= 430)closegraph();else if (m.x >= 700 && m.x <= 1000 && m.y >= 450 && m.y <= 750)closegraph();else if (m.x >= 700 && m.x <= 1000 && m.y >= 130 && m.y <= 430)closegraph();else if (m.x >= 200 && m.x <= 500 && m.y >= 450 && m.y <= 750)closegraph();break;case WM_KEYDOWN:if (m.vkcode == VK_ESCAPE)break;system("pause");closegraph();*/}uav.h
/*无人机类.h*/#pragma once#include<iostream>using namespace std;//空间大小M*M*Mconst int M=5;//全局变量extern int x, y, z, dend;//走出边界的负奖励const int S = -1;/*下一步飞行方向*///前后左右上下const int forward0 = 1;const int backword = 2;const int left0 = 3;const int right0 = 4;const int up = 5;const int down = 6;//上下两层的中间8个const int mid_up_forward = 7;const int mid_down_forward = 8;const int mid_up_backward = 9;const int mid_down_backward = 10;const int mid_up_left = 11;const int mid_down_left = 12;const int mid_up_right = 13;const int mid_down_right = 14;//中间一层的4个const int mid1 = 15;const int mid2 = 16;const int mid3 = 17;const int mid4 = 18;//边缘8个,1-4上面四个const int edge1 = 19;const int edge2 = 20;const int edge3 = 21;const int edge4 = 22;const int edge5 = 23;const int edge6 = 24;const int edge7 = 25;const int edge8 = 26;//设置无人机类class Uav{public:int radius;//飞行半径int h_speed, l_speed, v_speed;//最大平飞速度、最小平飞速速、最大垂直速度int h_height, l_height;//最大、最小飞行高度int guozai;//最大负载Uav(int r, int h_s, int l_s, int v_s, int h_h, int l_h, int gz)//有参构造函数,留给交互用{radius = r;h_speed = h_s;l_speed = l_h;v_speed = v_s;h_height = h_h;l_height = l_h;guozai = gz;}};obstacle.h
/*障碍物类.h*/#pragma once#include<string>//设置障碍物类,轮廓顶点,移动速度,移动路线没写class Obstacles{public:int i, j, k;//障碍物的位置int size;//大小,算作高度double reward;virtual double get_reward(int h_h, int l_h);//计算获得奖励的虚函数,传入飞机的最高和最低飞行高度};class Obstacles1 :public Obstacles//继承障碍物类实现多态{public:Obstacles1();virtual double get_reward(int h_h, int l_h);//计算获得奖励的虚函数,传入飞机的最高和最低飞行高度};class Obstacles2 :public Obstacles{public:Obstacles2();virtual double get_reward(int h_h, int l_h);//计算获得奖励的虚函数,传入飞机的最高和最低飞行高度};envionment.h
/*环境类.h*/#pragma once#include<string>class Environment{public:int terrain;//地形,实际上设为高度int wind_speed, wind_direction;//风向1为顺风,-1为逆风int temperature;int light;double reward;virtual double get_reward(int h_h, int l_h);//计算环境获得奖励的虚函数,传入飞机的最高和最低飞行高度};class Mountain :public Environment//作为高度过高的环境{public:Mountain();//构造函数,给高山环境的属性赋值double get_reward(int h_h, int l_h, int v_v);//计算环境获得奖励的虚函数,传入飞机的最高和最低飞行高度,和飞机垂直方向的速度};class Plain :public Environment//作为高度过低的环境{public:Plain();//构造函数,给平原环境的属性赋值double get_reward(int h_h, int l_h, int v_v);//计算环境获得奖励的虚函数,传入飞机的最高和最低飞行高度};class Against_wind :public Environment//作为逆风的环境{public:Against_wind();//构造函数,给环境的属性赋值double get_reward(int h_h, int l_h, int h_s);//计算环境获得奖励的虚函数,第三个参数传入飞机水平最大速度};class With_wind :public Environment//作为顺风的环境{public:With_wind();//构造函数,给环境的属性赋值double get_reward(int h_h, int l_h);//计算环境获得奖励的虚函数,第三个参数传入飞机水平最小速度};class Desert :public Environment//作为过热的环境{public:Desert();//构造函数,给环境的属性赋值double get_reward(int h_h, int l_h);//计算环境获得奖励的虚函数};class Polar :public Environment//作为过寒的环境{public:Polar();//构造函数,给环境的属性赋值double get_reward(int h_h, int l_h);//计算环境获得奖励的虚函数};class Light :public Environment//作为光照异常的环境{public:Light();//构造函数,给环境的属性赋值double get_reward(int h_h, int l_h);//计算环境获得奖励的虚函数};5.实验结果
5.1图形界面
哈哈哈哈,这个界面我做个,特别丑,就别嘲笑了。

5.2训练结果
由于算法得出的结果与训练次数有关,训练次数越多,其规划最优路线的效果越好,所以程序中设定训练次数为3000次。每一次训练中还包括执行步数,即算法做出的决策及其相应的奖励,在这里执行步骤设置了上限80,每次训练走到终点或者走够80步时结束.

5.3飞行路径
记录该次飞行中的飞行方向以及经过地方对应的位置坐标。

5.4决策优化奖励
计算无人机在该点x,y,z 处执行不同飞行方向所获得的奖励,以此来优化决策,找出相应的最优路线。

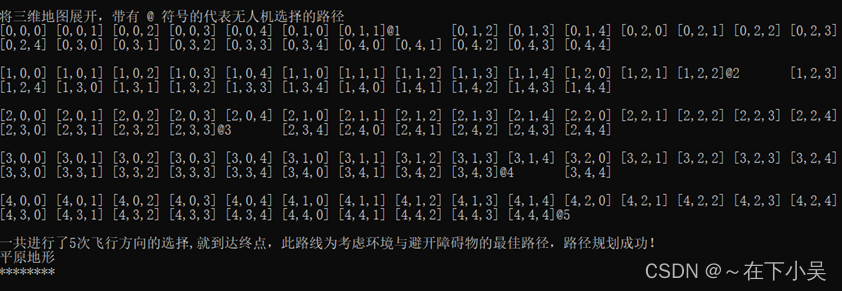
5.5路径规划
最终无人机在该地图下做出的最优规划路线,将三维地图展开,以符号‘@’来表示无人机选择的执行路径.在此我们可以看出无人机执行五次飞行步骤即可获得最大收益来到达终点,执行效果还是不错的。
6.参考文献
[1]田茂祥. 无人机三维路径规划方法[D].贵州民族大学,2021.DOI:10.27807/d.cnki.cgzmz.2021.000047.
[2]杨思明,单征,曹江,郭佳郁,高原,郭洋,王平,王景,王晓楠.基于模型的强化学习算法在无人机升空平台路径规划中的应用[J/OL].计算机工程:1-9[2022-04-05].DOI:10.19678/j.issn.1000-3428.0063156.
[3]程传斌,倪艾辰,房翔宇,张亮.改进的动态A~*-Q-Learning算法及其在无人机航迹规划中的应用[J].现代信息科技,2021,5(09):1-5+9.DOI:10.19850/j.cnki.2096-4706.2021.09.001.
[4]郝钏钏,方舟,李平.基于Q学习的无人机三维航迹规划算法[J].上海交通大学学报,2012,46(12):1931-1935.DOI:10.16183/j.cnki.jsjtu.2012.12.010.
[5]姚玉坤,张本俊,周杨.无人机自组网中基于Q-learning算法的及时稳定路由策略[J].计算机应用研究,2022,39(02):531-536.DOI:10.19734/j.issn.1001-3695.2021.07.0
由于这是一次学校布置的大作业,时间也很紧凑,所以难免有疏漏,还请多多指教。另外,基于Q-learning的二维路径规划效果不错,但三维路径规划效果其实不是很好,现在实际用的较多的为D*、RRT*算法,他们可能更适合用于三维路径规划。最后,要特别感谢我的另外两位队友吕同学和李同学,没有紧密的团队合作,也不会有本次内容的呈现。
登录后可发表评论
点击登录