【MySQL】增删改查进阶
一.新增
这里的新增相当于复制!!!
简单说就是把一张表的记录复制到另外一张表,可以复制全部记录到另外一张表,也可以单独选择想要复制的记录到另外一张表
注意:查询的表的列要和插入(复制)的表的列要相匹配,列的名字无所谓,但是列的个数和类型是要相匹配的
下面举一个例子,创建两张student和student2表,为了简单明了,把两个表的元素个数和类型搞成相同的
(1)现在把student里面的所有记录插入到student2中

图1中表是两张表,student里面有两条记录,student2中没有记录
现在把student 全列查询的结果插入到student2中,要想全部记录复制,那必然要全列查询查到所有的记录
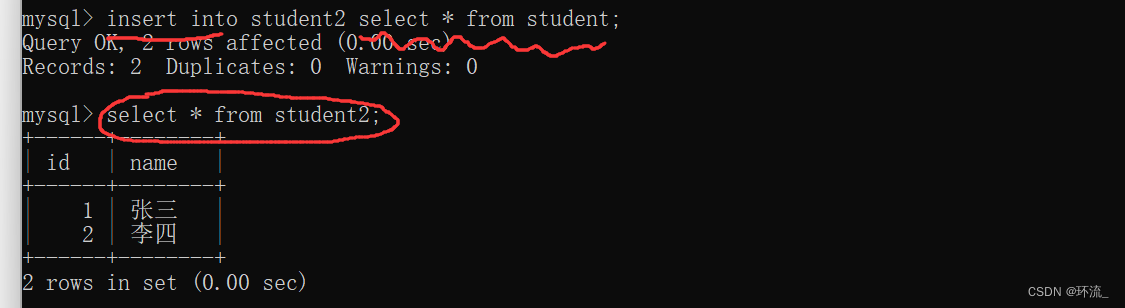
图2所示的就是把student的全列查询结果插入到student2中(插入到student2的时候就不用加上values了,直接插入即可)
(2)把student中张三的记录单独插入到student2中
既然要单独选择,那势必要用到where来选择要插入的记录
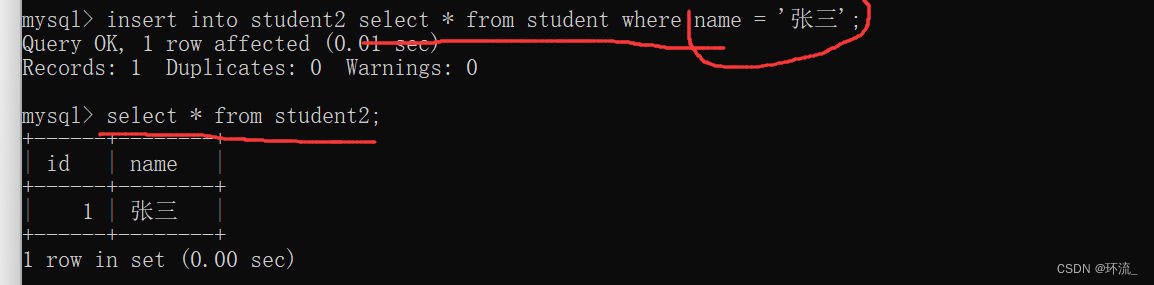
如图3所示,我们查询好student的张三记录,然后单独插入到student2中
看起来很简单把~
二.查询
1.聚合查询
聚合查询:是针对行和行之间的运算查询
要想实现聚合查询,就要用到聚合函数
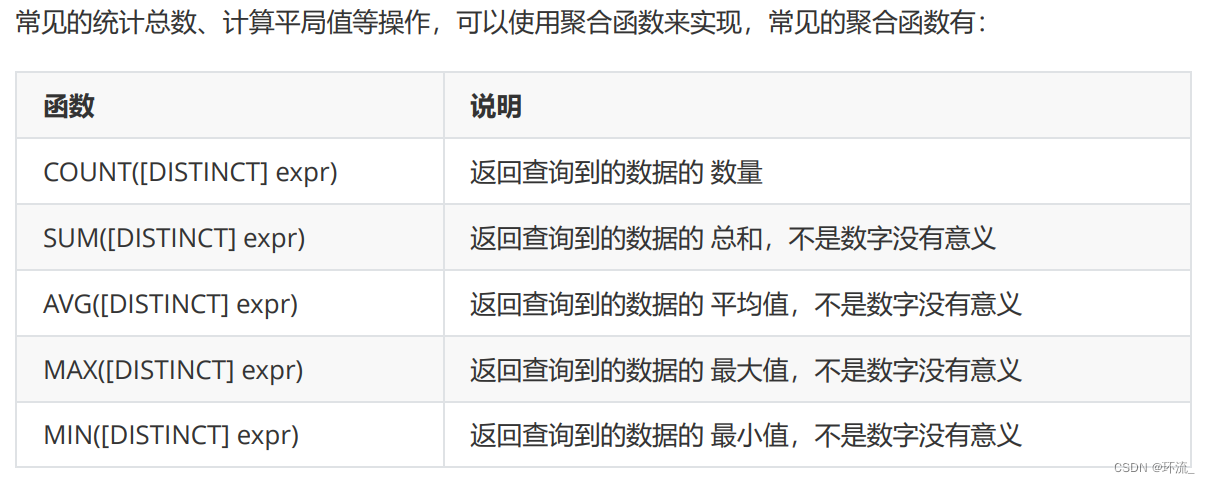
上图的五个聚合函数,分别是求 行数,和,平均值,最大值,最小值
注意:这些聚合函数只能针对数字进行运算,你总不能求一下同学名字的和吧?
下面给出一张考试成绩表
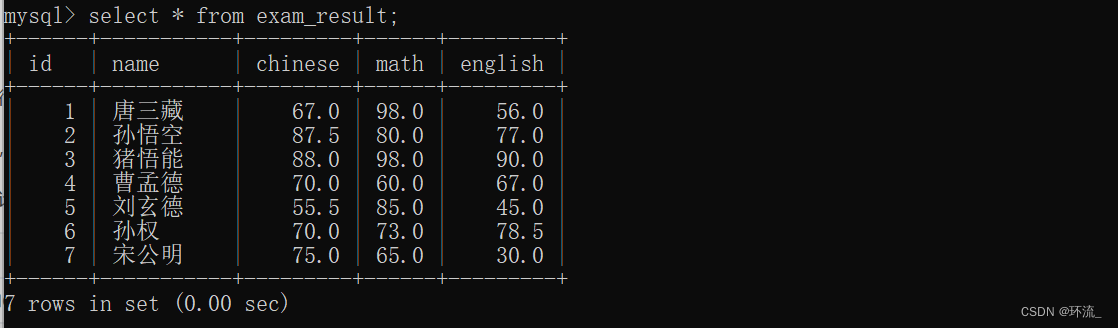
(1)用count查询一下这张表里面一共有多少条记录(行数)
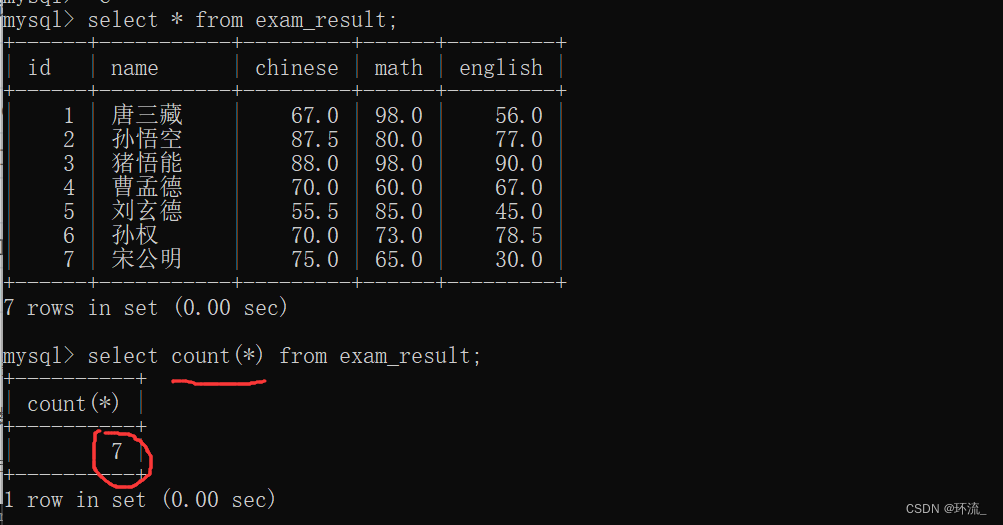
查询出这张表里面一共有7行
(2)用sum查询一下所有同学语文成绩的和
注意:为什么说是行和行计算?你看啊,语文成绩这列一共有7个同学,那就是有7行语文记录,分别把这7行相加,所以就叫做行和行之间的运算

(3) 查询一下语文成绩的平均值

(4)查询语文成绩最大最小值

2.分组查询
group by 列名
把查询结果进行分组
把相同的记录,分成一组,然后就可以针对每组来进行聚合查询了~
意思就是说,把相同属性的记录搞成一组,然后在组里面来找什么最大值啊,平均值什么的
现在先给一张员工表
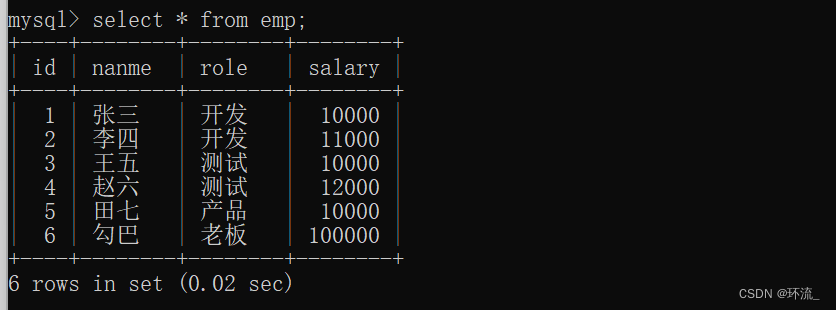
有6个人,对应的岗位有相同的,也有不同的,现在我们把岗位相同的人分成各自一组
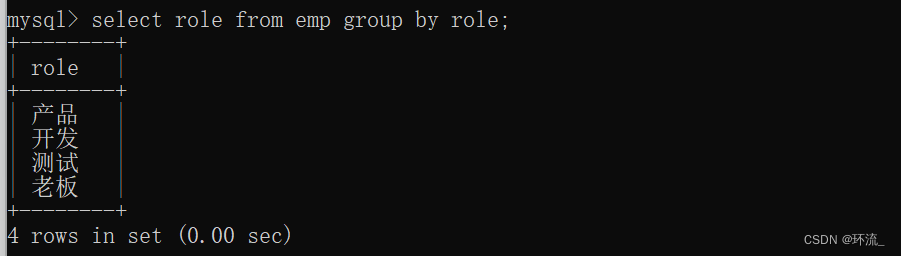
上图,我们把岗位都各自分好了组
比如说开发这个岗位,里面有张三和李四这两条记录,分组就是说,把表里错综复杂的记录按组分好,把记录存在组里面
分好组后,我们可以搭配聚合函数来进行查询,现在我们查询一下各个组里面都有有多少人(多少条记录)
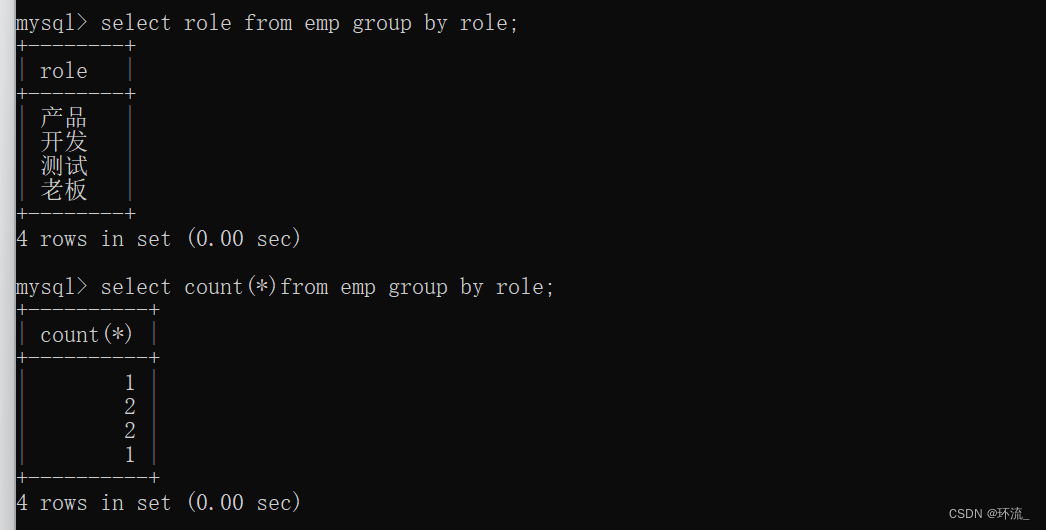
这样就能查询到每个岗位里面分别有多少人
现在我们再来查询一下每个岗位的平均薪资
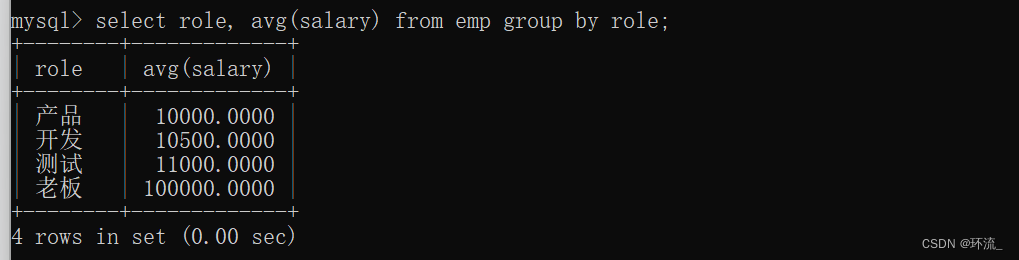
上述两个例子就能明白如何分组&如何分组查询搭配聚合函数来使用~
注意:假如分组后 用 * 号来查询会有什么效果(不好)
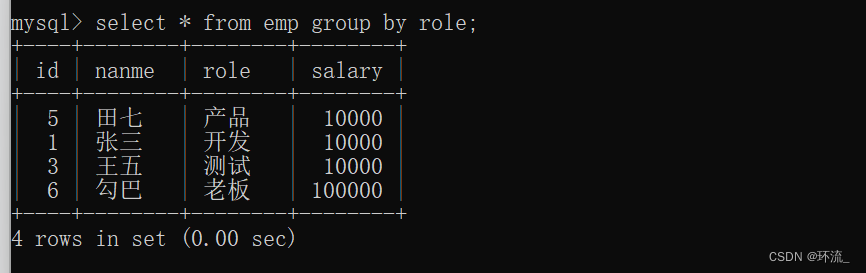
我们按照组分好后,每组显示的记录即在表中每组第一个成员的记录
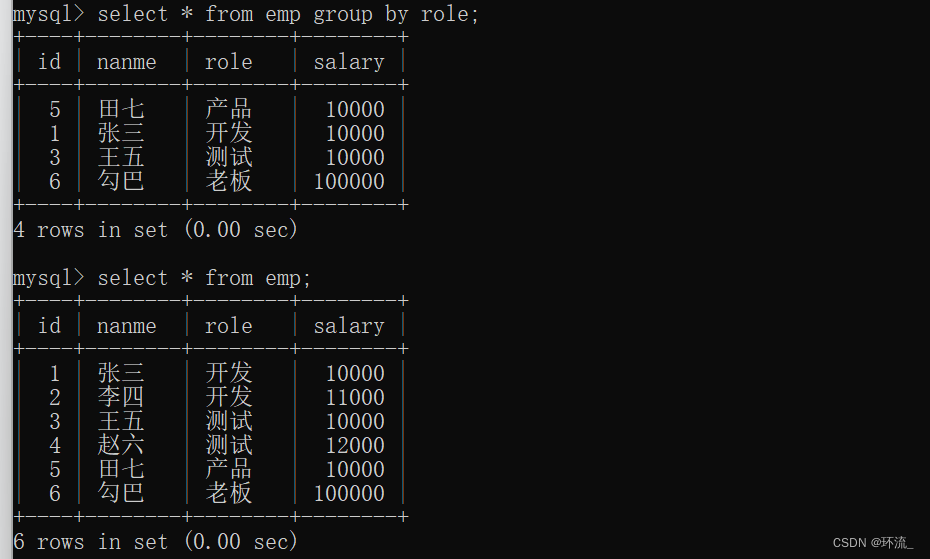
张三在开发组中是表里面第一个出现的开发成员
王五是在测试组中第一个出现在表中的测试成员……
这样的查询是不合理的,容易脑瓜子嗡嗡的
对于分组查询来说,我们最好使用聚合函数搭配来使用,这也是分组查询的难点
对于分组查询,我们可以指定条件来查询
我们要明确的是
1. 我们是 分组之前,使用条件筛选 (使用之前学过的where)
2.还是 分组之后,使用条件筛选(使用 having)
根据不同的筛选情况分别使用不同的筛选关键字(明确是使用 where 还是使用 having )
下面我们进行3个查询语句练习
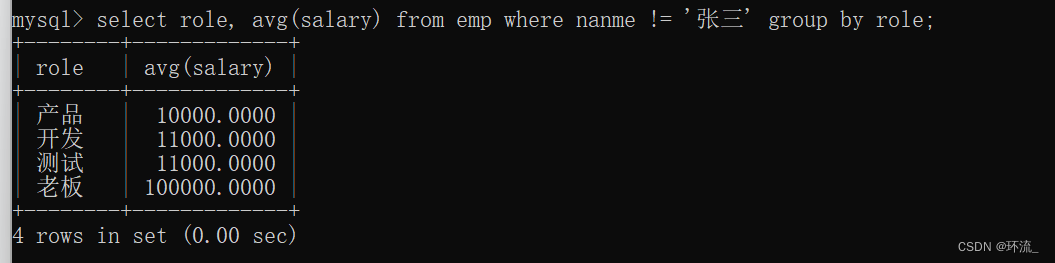
(1)查询每个岗位的平均薪资(除去张三这个记录)
根据条件,先把张三除去,再进行分组
(2)查询平均薪资 > 10000的岗位
这个则是先分好组,算好平均薪资,然后再找到平均薪资大于10000的岗位

(3)求除了张三以外,每个岗位的平均薪资,并且保留平均薪资 > 10000的岗位

上面这个就看出了 where , group by, 和 having 在同一个语句中相对应的位置
以上就是分组查询&聚合函数的介绍~~~
3.联合查询(多表查询)
实际开发中往往数据来自不同的表,所以需要多表联合查询。
多表查询是对多张表的数据取笛卡尔积
下面来理解一下什么叫做笛卡尔积~
笛卡尔积,就是简单的排列组合(即高中数学排列章节所讲的 分步计数原理)
把两张表的记录分别进行分布计数即可,举个例子
比如现在有一张学生表和一张班级表,学生表和班级表是有关联关系的,学生对应一个班级
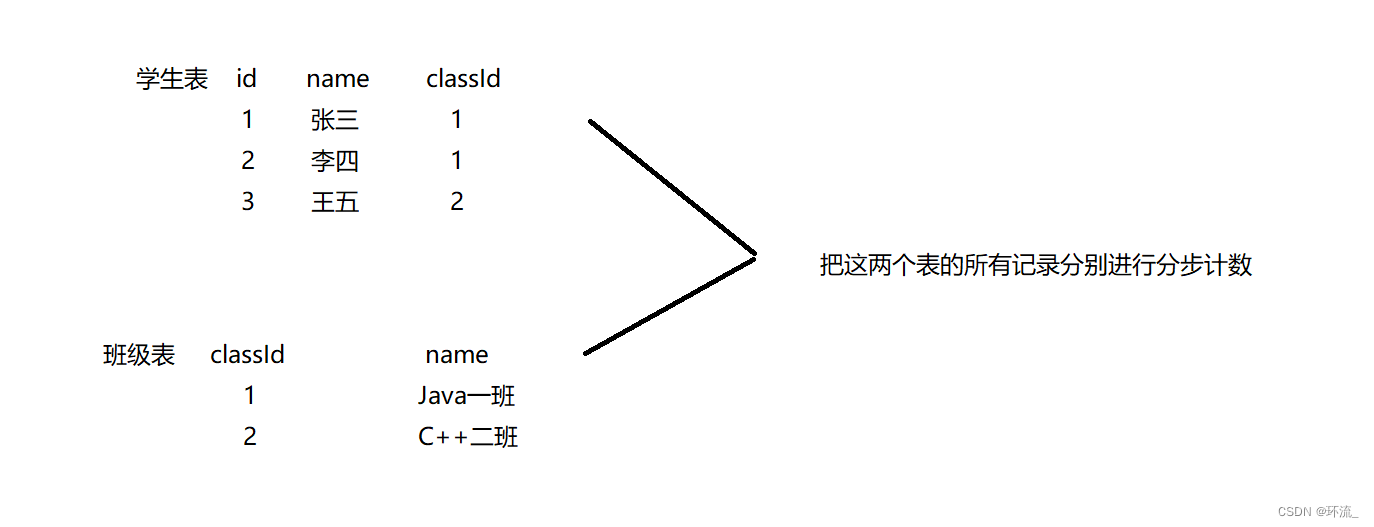
学生表里面有三个同学,班级表里面有两个班级
笛卡尔积就是把两张表的记录无脑的进行分步计数
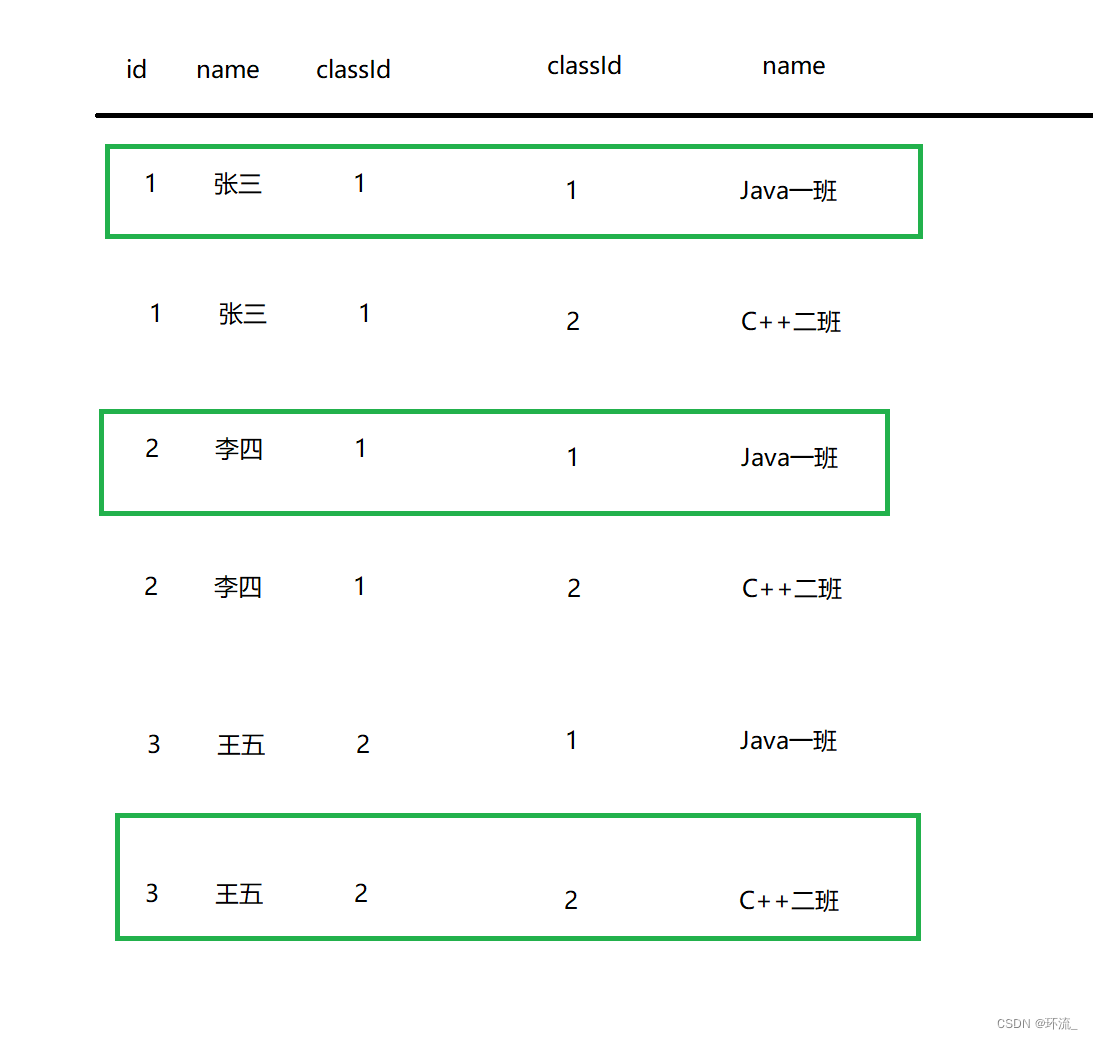
笛卡尔积 两张表的记录,,得到的行数就是 3 * 2 = 6 条记录
发现笛卡尔积表里面有很多鱼龙混杂的无效记录,有效记录就是绿色框框的记录~
因此笛卡尔积后的表,我们 要把合理的挑出来,筛掉不合理的数据
因此要想筛掉不合理的记录,就要用两张表的连接条件
学生表里面有 classId
班级表里面有 classId
所以这就是两张表的连接条件,根据这个条件把不合理的条件给筛除掉
student.classId = classes.classId
这种用来“筛选笛卡尔积有效数据的条件” 就叫做连接条件~
(1)笛卡尔积 两种写法 逗号写法,和join写法

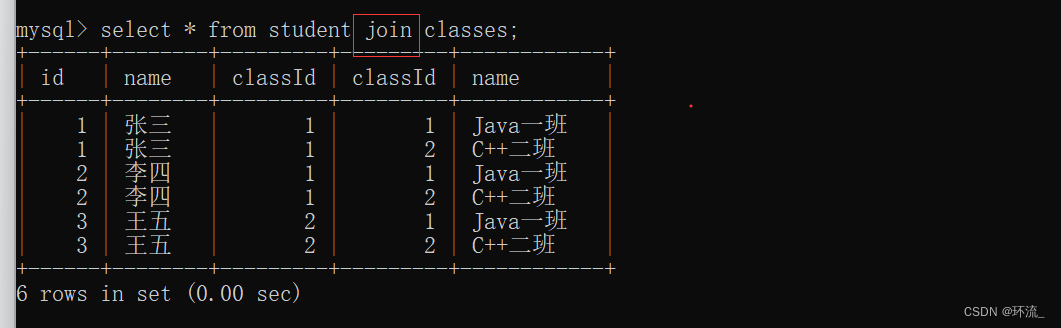
上图有无效数据,用连接条件筛掉
逗号写法的筛选(用where来筛选有效数据)

join 写法 配合 on来筛选有效数据
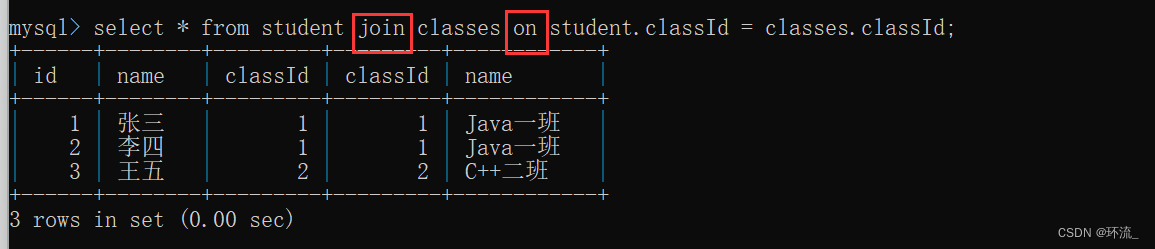
上述表述了笛卡尔积的用法
笛卡尔积:是一种危险操作
众所周知,笛卡尔积要进行分步计数
假如笛卡尔积的两张表的数据有分别有上万条或者上亿条,那么两张表的记录分别相乘,结果的数据会有超级多条~~~这是很恐怖的!!!
会导致服务器卡爆了
内连接
外连接
自连接
子查询

合并查询

登录后可发表评论
点击登录