论文学习——Tune-A-Video
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
Abstract
本文提出了一种方法,站在巨人的肩膀上——在大规模图像数据集上pretrain并表现良好的 text to image 生成模型——加入新结构并进行微调,训练出一套 one shot 的 text to video 生成器。这样做的优点在于利用已经非常成功、风格多样的图像扩散生成模型,在其基础上进行扩展,同时其训练时间很短,大大降低了训练开销。作为one shot 方法,tune a video还需要额外信息,一个文本-视频对儿作为demo。
作者对于T2I(text to image)模型得到了两个观察:
(1)T2I模型可以生成·展示动词项效果的·静止图像
(2)扩展T2I模型同时生成的多张图像展现出了良好的内容一致性。
有了这两个观察作为基础,其实生成视频的关键就在于如何保证一致的物体的连续运动。
为了更进一步,学习到连贯的动作,作者设计出one shot 的 Tune-A-Video模型。这个模型涉及到一个定制的时空注意力机制,以及一个高效的one shot 调整策略(tuning strategy)。在推理阶段,使用DDIM的inversion过程(常规DDIM在逆扩散过程中的采样部分是确定的:将预测的高斯噪声~N(μ, σ)中的标准差设置为0,以此消除逆扩散过程中的随机性;而DDIM inversion相反,其正向扩散过程是确定的。)来为采样过程提供结构性的引导。
1. Introduction
为在T2V领域赋值T2I生成模型的成果经验,有许多模型[30,35,6,42,40]也尝试将空间领域的T2I生成模型拓展到时空领域。它们通常在大规模的text-video数据集上采取标准的训练范式,效果很好,但计算开销太大太耗时。
本模型的思路:在大规模text-image数据集上完成预训练的T2I模型以及有了开放域概念的许多知识,那简单给它一个视频样例,它是否能够自行推理出其他的视频呢?
One-Shot Video Tuning,仅使用一个text-video对儿来训练T2V生成器,这个生成器从输入视频中捕获基础的动作信息,然后根据修改提示(edited prompts)生成新颖的视频。

上面abstract提到,生成视频的关键就在于如何保证一致的物体的连续运动。下面,作者从sota的T2I扩散模型中进行如下观察,并依此激励我们的模型。
(1)关于动作:T2I模型能够很好地根据包括动词项在内的文本生成的图片。这表明T2I模型在静态动作生成上,可以通过跨模态的注意力来考虑到文本中的动词项。
(2)关于一致的物体:简单的将T2I模型中的空间自注意力进行扩展,使之从生成一张图片变为生成多张图片,足可以生成内容一致的不同帧,如图2第1行是内容和背景不同的多张图像,而图2第2行是相同的人和沙滩。不过动作仍不是连续的,这表明T2I中的自注意力层只关注空间相似性而不关注像素点的位置。
Tune A Video方法是在sota 的T2I模型在时空维度上的简单膨胀。为避免计算量的平方级增长,对于帧数不断增多的任务来说,这种方案显然是不可行的。另外,使用原始的微调方法,更新所有的参数可能会破坏T2I模型已有的知识,并阻碍新概念视频的生成。为解决这个问题,作者使用稀疏的时空注意力机制而非full attention,仅使用视频的第一帧和前一帧,至于微调策略,只更新attention 块儿中的投影矩阵。以上操作只保证视频帧中的内容的一致性,但并不保证动作的连续性。
因此,在推理阶段,作者通过DDIM的inversion过程,从输入视频中寻求structure guidance。将该过程得到的逆转潜向量作为初始的噪音,这样来产生时间上连贯、动作平滑的视频帧。
作者贡献:
(1)为T2V生成任务提出了一类新的模型One-Shot Video Tuning,这消除了模型在大尺度视频数据集上训练的负担
(2)这是第一个使用T2I实现T2V生成任务的框架
(3)使用高效的attention tuning和structural inversion来显著提升时序上的联系性
3.2 网络膨胀
先说T2I模型,以LDM模型为例,使用U-Net,先使用孔家下采样再使用上采样,并保持跳联。U-Net由堆叠的2d残差卷积和transformer块儿们组成。每个transformer块儿都有一个空间自注意力层,一个交叉注意力层,一个前馈网络组成。空间自注意力层利用feature map中的像素位置寻找相似关系;交叉注意力则考虑像素和条件输入之间的关系。
zvi表示video的第vi帧,空间自注意力可以表示为如下形式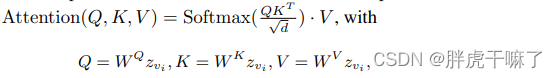
下面讲怎么改:
(1)将其中的2d卷积层膨胀为伪3d卷积层,3x3变为1x3x3这样;
(2)对于每个transformer块儿加入时序的自注意力层(,以完成时间建模);
(3)(为增强时序连贯性,)将空间自注意力机制转为时空自注意力机制。转换的方法并不是使用full attention 或者causal attention,它们也能捕获时空一致性。但由于在introduction中提到的开销问题,显然并不适用。本文采用的是系数的causal attention,将计算量从O((mN)2)转为了O(2mN2),其中m为帧数,N为每帧中的squence数目。需要注意的是,这种自注意力机制里,计算query的向量是zvi,计算key和value使用的向量则是v1和vi-1的拼接。
4.4 微调和推理
模型微调
为获得时序建模能力,使用输入视频微调网络。
由于时空注意力机制通过查询之前帧上的相关位置来建模其时序一致性。因此固定ST-Attn layers中的WK和WV,仅更新投影矩阵WQ。
而对于新加入的时序自注意力层,则更新所有参数,因为新加入层的参数不包含先验。
对于交叉注意力Cross-Attn,则通过更新Query的投影矩阵(query projection)来完善text-video的对应关系。
这样的微调,相对于完全调整来说更节约计算开销,并且也有助于保持原有T2I预训练所得到的的原有性质。下图中标亮了所有需要更新参数的模块。
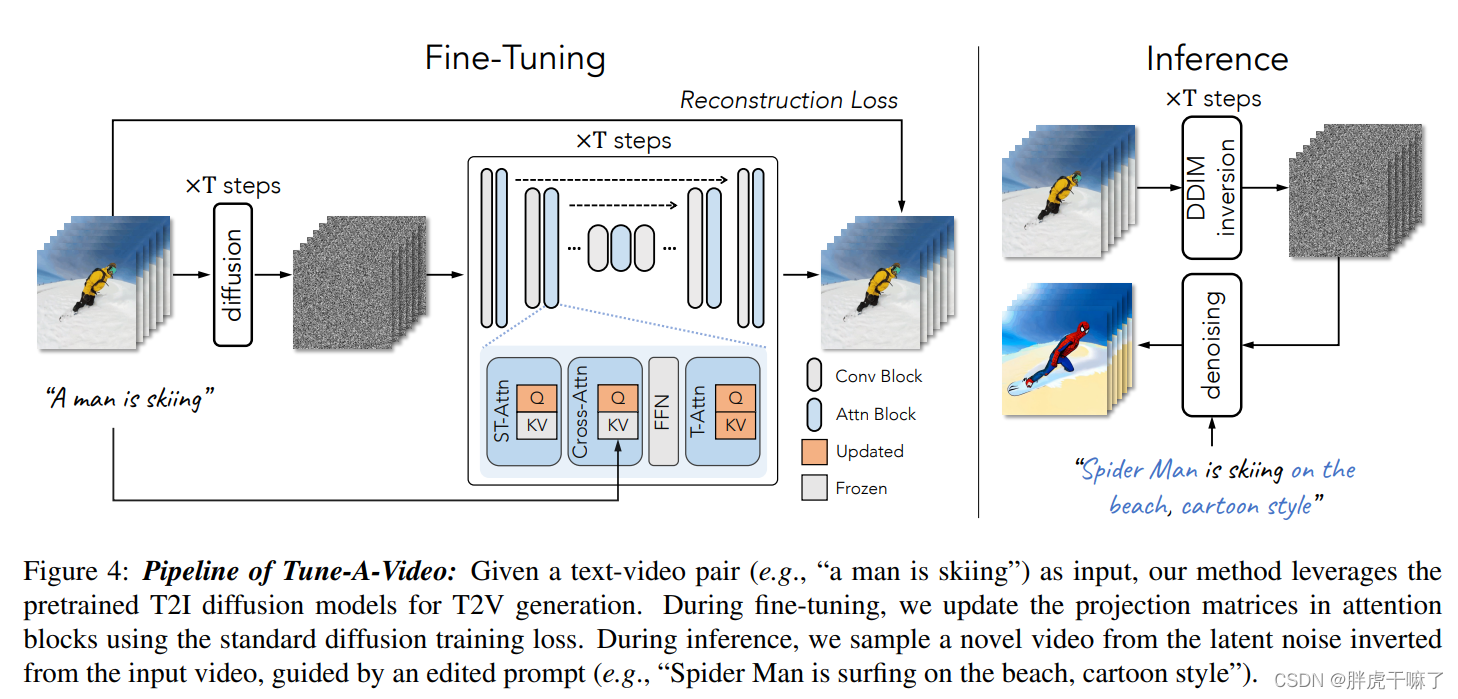
通过DDIM的inversion获得结构上的指导
为了更好地确保不同帧之间的像素移动,在推理阶段,本模型从原视频中引入结构的指导。具体来说,通过DDIM的inversion过程,从没有文本条件的原视频中能够提取出潜向量噪音。这种噪音作为DDIM采样过程的起点,同时受到编辑提示edited prompt T*的引导,进入DDIM的采样过程,输出视频可以表示如下
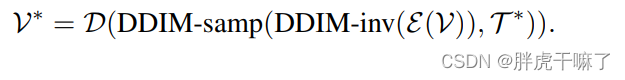
登录后可发表评论
点击登录