点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis (已更完)Kafka(已更完)Spark(正在更新!)章节内容
上节完成了如下的内容:
Spark Streaming Kafka自定义管理Offset Scala代码实现
Offset 管理
Spark Streaming 集成Kafka,允许从Kafka中读取一个或者多个Topic的数据,一个Kafka Topic包含一个或者多个分区,每个分区中的消息顺序存储,并使用offset来标记消息位置,开发者可以在Spark Streaming应用中通过offset来控制数据的读取位置。
Offsets 管理对于保证流式应用在整个生命周期中数据的连贯性是非常重要的,如果在应用停止或者报错退出之前将Offset持久化保存,该消息就会丢失,那么Spark Streaming就没有办法从上次停止或保存的位置继续消费Kafka中的消息。
Spark Streaming 与 Kafka 的集成
Spark Streaming 可以通过 KafkaUtils.createDirectStream 直接与 Kafka 集成。这种方式不会依赖于 ZooKeeper,而是直接从 Kafka 分区中读取数据。
在这种直接方式下,Spark Streaming 依赖 Kafka 的 API 来管理和存储消费者偏移量(Offsets),默认情况下偏移量保存在 Kafka 自身的 __consumer_offsets 主题中。
使用 Redis 管理 Offsets
Redis 作为一个高效的内存数据库,常用于存储 Spark Streaming 中的 Kafka 偏移量。
通过手动管理偏移量,你可以在每批次数据处理后,将当前批次的 Kafka 偏移量存储到 Redis 中。这样,在应用程序重新启动时,可以从 Redis 中读取最后处理的偏移量,从而从正确的位置继续消费 Kafka 数据。
实现步骤
从 Redis 获取偏移量
应用启动时,从 Redis 中读取上次处理的偏移量,并从这些偏移量开始消费 Kafka 数据。
处理数据
通过 Spark Streaming 处理从 Kafka 消费到的数据。
保存偏移量到 Redis
每处理完一批数据后,将最新的偏移量存储到 Redis 中。这样,如果应用程序崩溃或重启,可以从这个位置继续消费。
自定义Offsets:根据Key从Redis获取Offsets 处理完更新Redis
添加依赖
<!-- jedis --><dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version></dependency>服务器上我们需要有:
Redis服务启动

Kafka服务启动
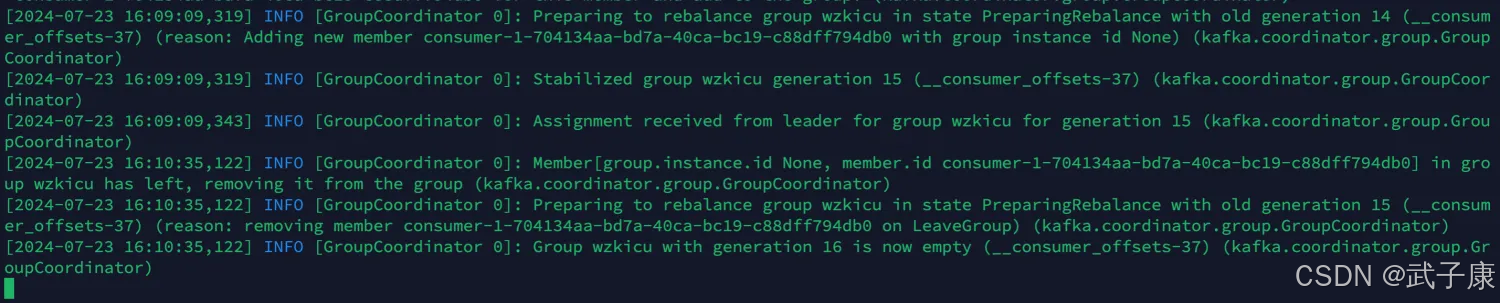
编写代码,实现的主要逻辑如下所示:
package icu.wzkimport org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}import org.apache.kafka.common.TopicPartitionimport org.apache.kafka.common.serialization.StringDeserializerimport org.apache.log4j.{Level, Logger}import org.apache.spark.SparkConfimport org.apache.spark.streaming.dstream.InputDStreamimport org.apache.spark.streaming.kafka010.{ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies, OffsetRange}import org.apache.spark.streaming.{Seconds, StreamingContext}object KafkaDStream3 { def main(args: Array[String]): Unit = { Logger.getLogger("args").setLevel(Level.ERROR) val conf = new SparkConf() .setAppName("KafkaDStream3") .setMaster("local[*]") val ssc = new StreamingContext(conf, Seconds(5)) val groupId: String = "wzkicu" val topics: Array[String] = Array("spark_streaming_test01") val kafkaParams: Map[String, Object] = getKafkaConsumerParameters(groupId) // 从 Kafka 获取 Offsets val offsets: Map[TopicPartition, Long] = OffsetsRedisUtils.getOffsetsFromRedis(topics, groupId) // 创建 DStream val dstream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream( ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](topics, kafkaParams, offsets) ) // DStream 转换&输出 dstream.foreachRDD { (rdd, time) => if (!rdd.isEmpty()) { // 处理消息 println(s"====== rdd.count = ${rdd.count()}, time = $time =======") // 将 Offsets 保存到 Redis val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges OffsetsRedisUtils.saveOffsetsToRedis(offsetRanges, groupId) } } ssc.start() ssc.awaitTermination() } private def getKafkaConsumerParameters(groupId: String): Map[String, Object] = { Map[String, Object]( ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "h121.wzk.icu:9092", ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer], ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer], ConsumerConfig.GROUP_ID_CONFIG -> groupId, ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "earliest", ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG -> (false: java.lang.Boolean) ) }}代码中我们封装了一个工具类:
package icu.wzkimport org.apache.kafka.common.TopicPartitionimport org.apache.spark.streaming.kafka010.OffsetRangeimport redis.clients.jedis.{Jedis, JedisPool, JedisPoolConfig}import scala.collection.mutableobject OffsetsRedisUtils { private val config = new JedisPoolConfig private val redisHost = "h121.wzk.icu" private val redisPort = 6379 config.setMaxTotal(30) config.setMaxIdle(10) private val pool= new JedisPool(config, redisHost, redisPort, 10000) private val topicPrefix = "kafka:topic" private def getKey(topic: String, groupId: String, prefix: String = topicPrefix): String = s"$prefix:$topic:$groupId" private def getRedisConnection: Jedis = pool.getResource // 从Redis中获取Offsets def getOffsetsFromRedis(topics: Array[String], groupId: String): Map[TopicPartition, Long] = { val jedis: Jedis = getRedisConnection val offsets: Array[mutable.Map[TopicPartition, Long]] = topics.map { topic => import scala.collection.JavaConverters._ jedis.hgetAll(getKey(topic, groupId)) .asScala .map { case (partition, offset) => new TopicPartition(topic, partition.toInt) -> offset.toLong } } jedis.close() offsets.flatten.toMap } // 将 Offsets 保存到 Redis def saveOffsetsToRedis(ranges: Array[OffsetRange], groupId: String): Unit = { val jedis: Jedis = getRedisConnection ranges .map(range => (range.topic, range.partition -> range.untilOffset)) .groupBy(_._1) .map { case (topic, buffer) => (topic, buffer.map(_._2)) } .foreach { case (topic, partitionAndOffset) => val offsets: Array[(String, String)] = partitionAndOffset.map(elem => (elem._1.toString, elem._2.toString)) import scala.collection.JavaConverters._ jedis.hmset(getKey(topic, groupId), offsets.toMap.asJava) } jedis.close() }}我们启动后,如图所示:
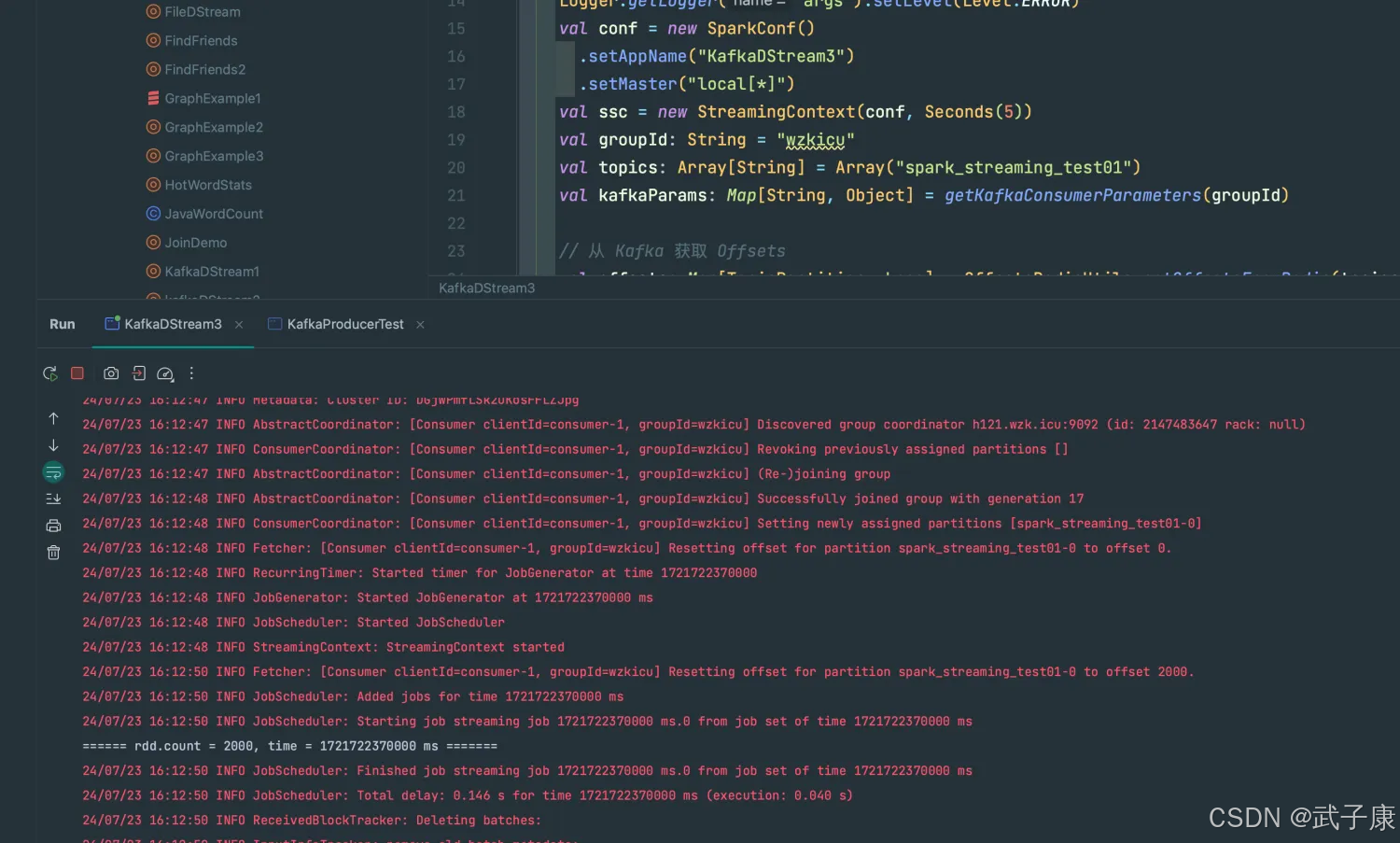
这里我使用Redis查看当前的存储情况:

可以看到当前已经写入了,我们继续启动 KafkaProducer工具,继续写入数据。
可以看到,已经统计到数据了。
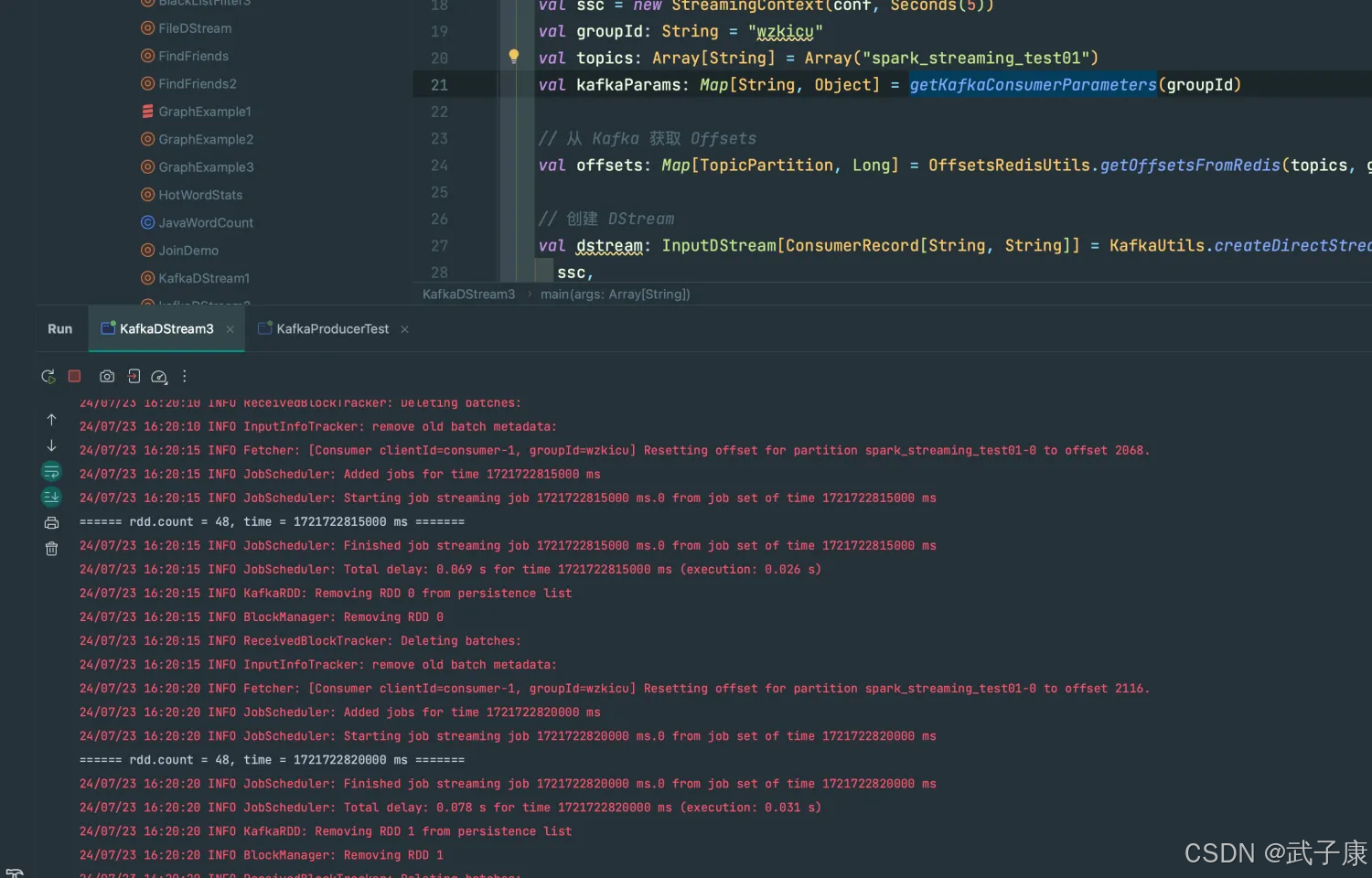
我们继续查看当前的Redis中的数据:
