B题——汽油辛烷值优化
作者序言
B题当时比赛时选的人非常多,可以说占据了近一般的参赛队伍,但是这题蕴含很多小问题,诸多选手也是叫苦连天。
我们队伍利用3天的时间完成这道赛题,最终获得全国一等奖(1.3%),也是全校唯一 一等奖,在此将整体思路整理,供大家参考,也欢迎一起交流、批评、指正。
在本科时期参加的美国大学生数学建模比赛也获得M奖,后续会出一片数学建模经验的blog,有问题或备赛疑惑的同学可以私信我。
背景
- 汽油是小型车辆的主要燃料,汽油燃烧产生的尾气排放对大气环境有重要影响。为此,
世界各国都制定了日益严格的汽油质量标准。汽油清洁化重点是降低汽油中的硫、烯烃含
量,同时尽量保持其辛烷值。 - 辛烷值(以 RON 表示)是反映汽油燃烧性能的最重要指标,并作为汽油的商品牌号。
现有技术在对催化裂化汽油进行脱硫和降烯烃过程中,普遍降低了汽油辛烷值。 - 化工过程的建模一般是通过数据关联或机理建模的方法来实现的,取得了一定的成果,
但是由于炼油工艺的复杂性以及操作变量的高度非线性及相互强耦联,传统数据关联模型
难以对过程优化作出及时响应,效果不佳。 - 现有某石化企业运行 4 年的催化裂化汽油精制脱硫装置并积累了大量历史数据,其汽
油产品辛烷值损失平均为 1.37 个单位相较于同类装置的最小损失值 0.6 个单位有较大的优
化空间。现通过数据挖掘技术来解决该场景化工过程建模问题。
数据
具体数据源参见数学建模B题资料
问题提出
- 根据从催化裂化汽油精制装置采集的 325 个数据样本(每个数据样本都有 354 个操作
变量),通过数据挖掘技术来建立汽油辛烷值(RON)损失的预测模型,并给出每个样本
的优化操作条件,在保证汽油产品脱硫效果(欧六和国六标准均为不大于 10µg/g,但为了
给企业装置操作留有空间,本次建模要求产品硫含量不大于 5µg/g)的前提下,最终完成
降低汽油辛烷含量损失降幅在 30% 以上。
现根据以上背景以及所提供数据完成以下任务:
- 参考近四年的工业数据的数据样本,对 285 号和 313 号样本原始数据根据给定的
样本处理方法对数据样本进行预处理,填入样本数据集中对应的数据样本编号中,以便进
一步分析。 - 数据样本提供了 325 个样本数据,以及建立辛烷损失值模型所需要的 367 个操作
变量。通过降维的方法筛选出建模的主要变量,并给出详尽的分析。 - 采用(1)(2)中完成的数据样本以及建模变量,使用数据挖掘技术建立辛烷值
(RON)损失预测模型,并验证。 - 在保证产品硫含量不大于 5µg/g 的前提下,利用(3)中的模型对应的 325 个数据
样本可操作变量进行优化,并给出辛烷值(RON)损失降幅大于 30% 的主要变量优化后的
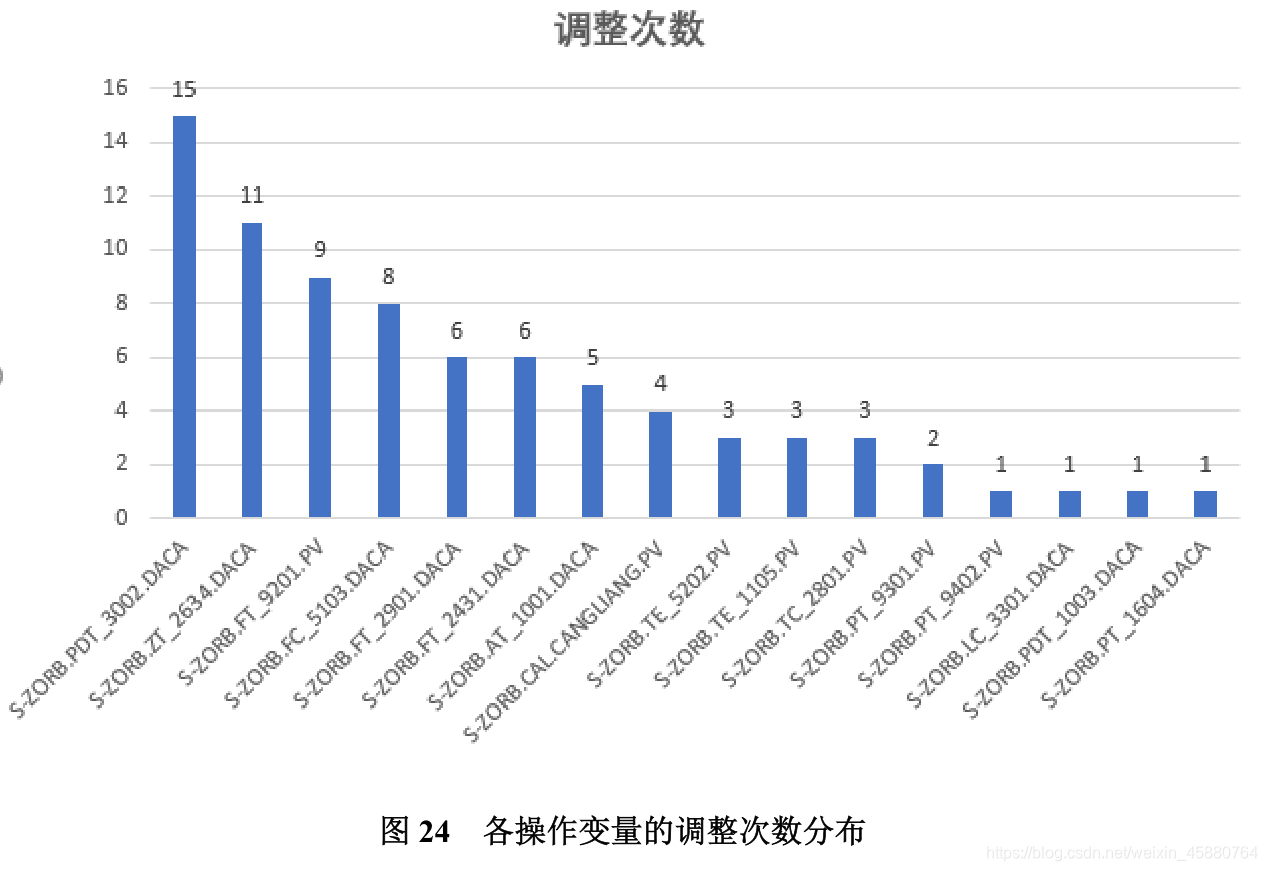
操作条件。 - 对 133 号样本,图形展示(2)中选定的主要操作变量在优化调整过程中对应辛烷
值和硫含量的变化轨迹。
问题一分析
本题要求对 285 号和 313 号原始数据根据指定的数据处理规范进行预处理并填入相应
的样本编号。样本的原始数据每编号各 40 组,我们将每组的数据用给定的数据处理规范
进行验证,得到最终的数据,最后对每一列求期望补充相应的样本编号。
问题二分析
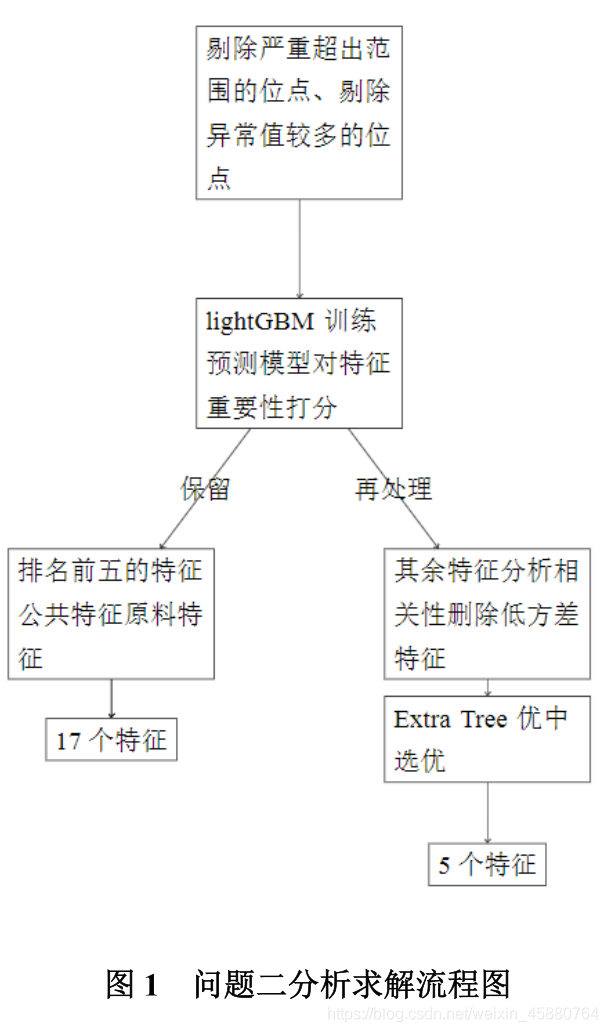
本题首先对数据样本按照最大最小限幅以及拉依达法则进行列变量清洗。
- 第一轮筛选,将处理后的数据针对产品中硫含量、RON 损失值用 lightGBM 做特征权
重打分并以一定规则筛选出权重排名较前以及原料性质附带待生吸附剂、再生吸附剂等 17
个变量。 - 第二轮筛选,针对排名较低且独立出现的 57 个变量进行相关性分析,针对相关性 >0.8
的两两变量避免同时出现。之后基于决策树模型再做特征,选择选出最终 5 个变量并整合
第一轮 17 个变量,得到建模所需要的 22 个主要变量,具体流程如图1所示。
问题三分析
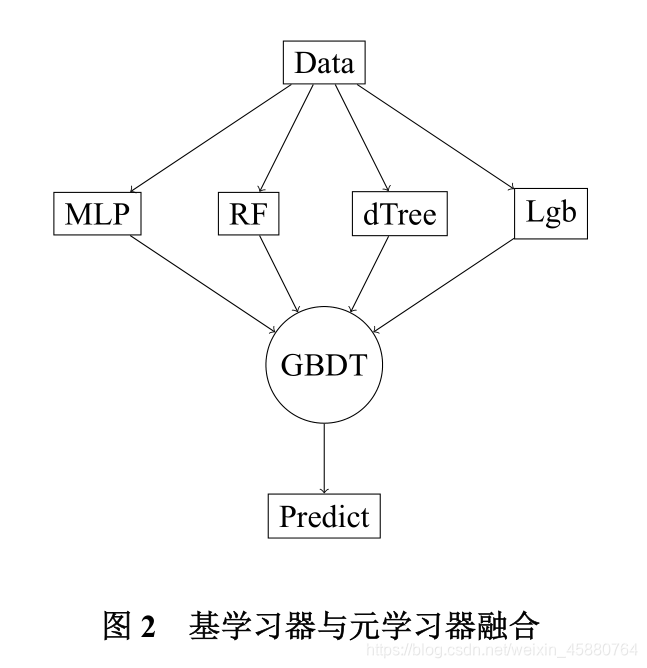
本题利用模型融合的方法,构建集成学习模型,分别建立产品硫含量、RON 损失值预
测的集成学习模型。
- 首先分别训练 4 个基学习器:多层感知机、随机森林、决策树、梯度提升决策树,构
建 4 个相关性较低的弱学习器。 - 再将 4 个基学习器进行模型融合,集成到梯度下降树(GBDT)中,实现 2 层的集成
学习模型,如图2所示。 - 根据评价指标均方误差(MSE)、平均绝对误差(MAE), 集成的模型对硫含量、RON
损失值的预测准确度远高于单一基学习器,且误差都较小。模型有较好的预测效果。
问题四分析
问题要求给出操作变量的优化方案,使得依据优化操作变量生成的 RON loss 和 CP S
满足给定要求。
将此问题建模为多目标优化问题,目标函数即为第三问建立的两个模型。
由遗传算法计算得到 325 个样本的操作变量的帕累托最优取值,再在其中进行筛选,删去
不满足题设要求的帕累托最优解,即可找到完全满足题设要求的优化操作变量取值。
问题五分析
根据问题四中构建的优化策略,在保证优化目标的前提下,寻找 133 号样本点的帕累
托最优解对应的最优操作变量。结合操作变量范围,将初始操作变量逐步调整至最优数值。
每一步调整都会产生 133 号新的样本,利用预测模型对其预测,得到操作变量优化调整过
程中对应的汽油辛烷值和硫含量的变化
论文架构
论文主要由以下几个部分组成

论文重要图片