24年8月来自MultiOn AGI公司和斯坦福大学的论文“”Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents“。
大语言模型 (LLM) 在需要复杂推理的自然语言任务中表现出了卓越的能力,但它们在交互式环境中的智体、多步推理中的应用仍然是一项艰巨的挑战。传统的静态数据集监督预训练,无法实现在网络导航等动态设置中执行复杂决策所需的自主智体能力。之前对专家演示监督微调弥补这一差距的尝试,经常受到复合错误和有限探索数据的影响,导致策略结果不理想。为了克服这些挑战,提出了一个框架Agent Q,引导式蒙特卡洛树搜索 (MCTS) 搜索与自我批评机制和直接偏好优化 (DPO) 算法的去策略(off-policy)变体,对智体交互进行迭代微调相结合。
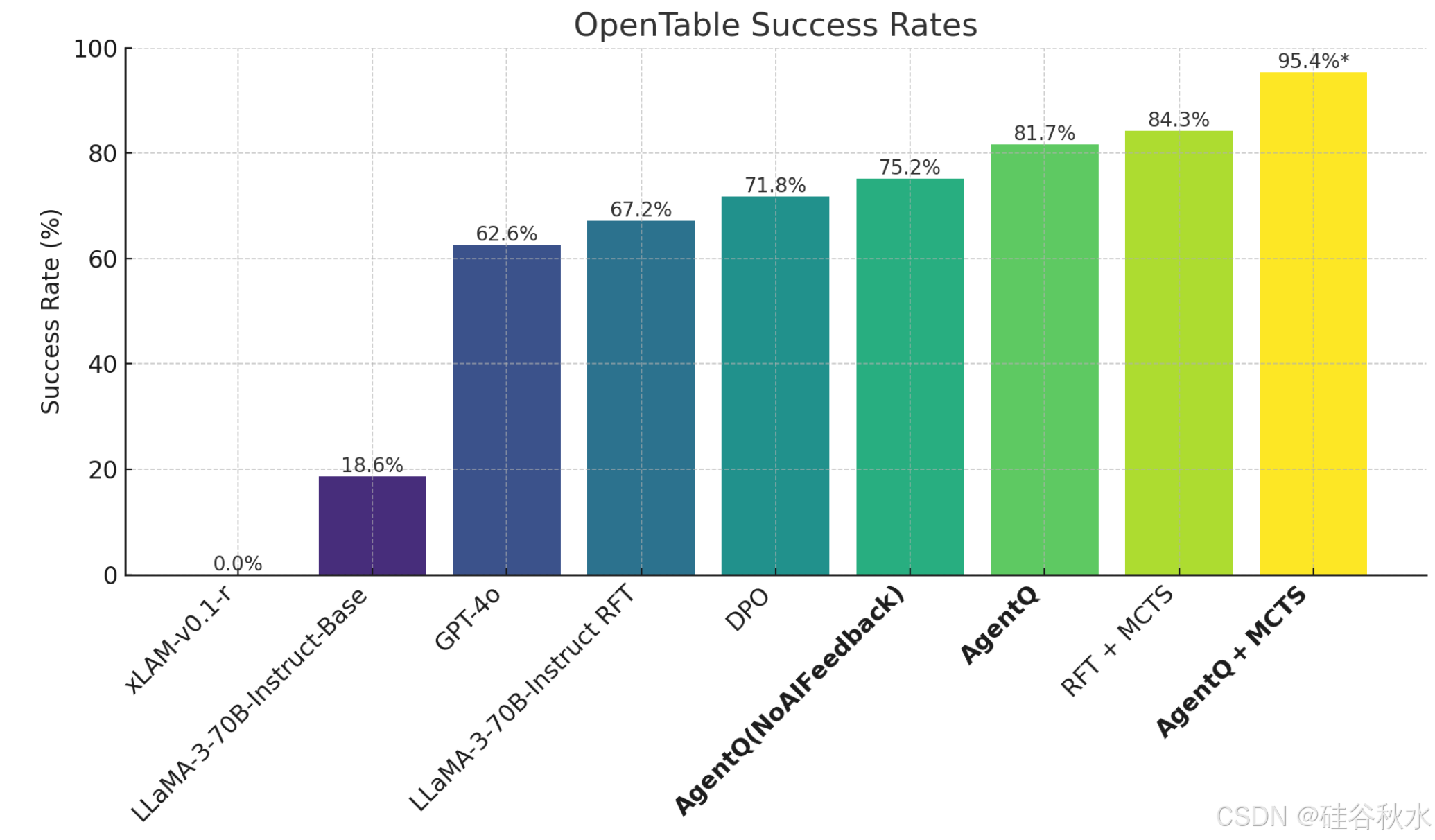
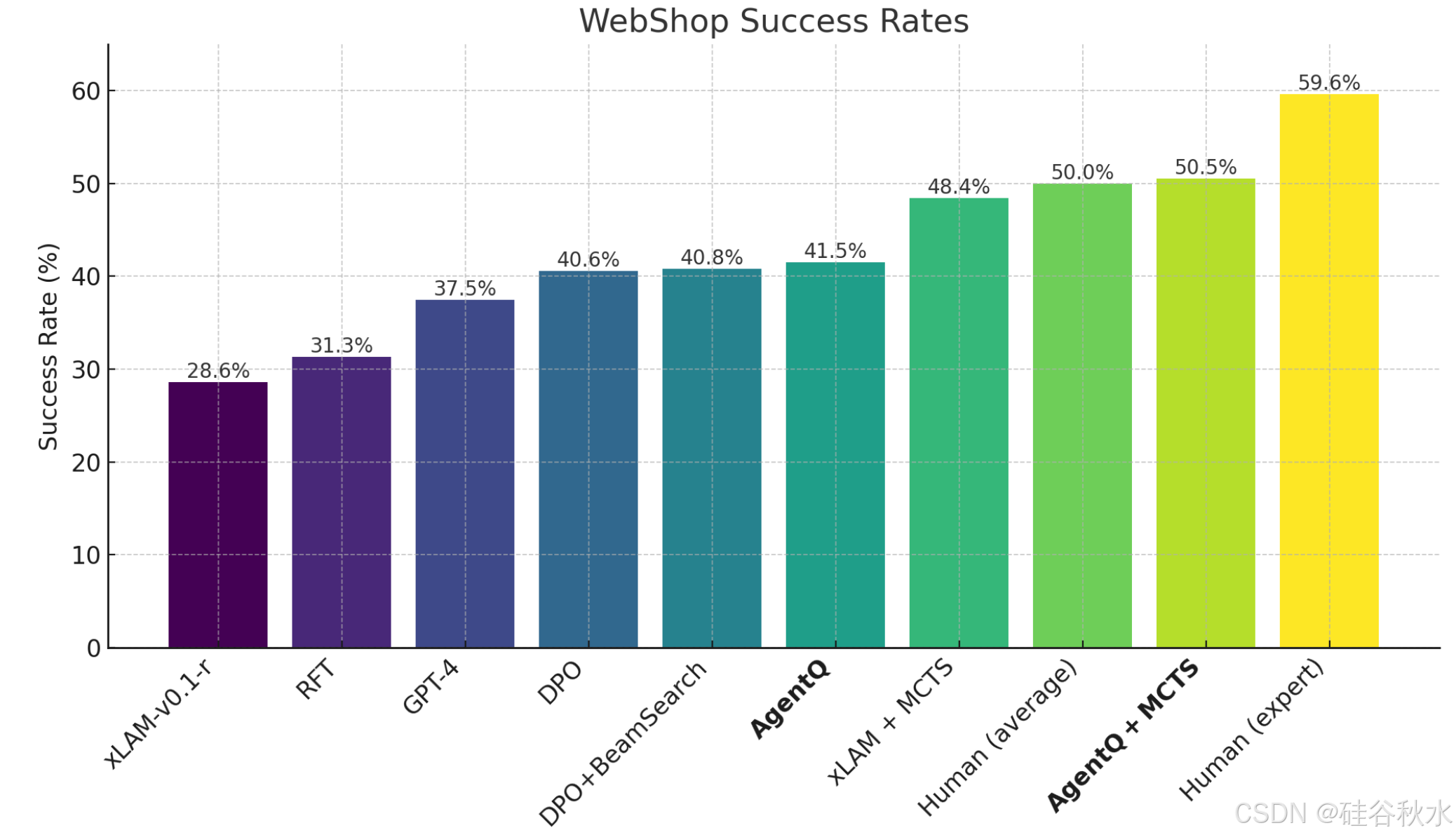
该方法允许 LLM 智体从成功和不成功的轨迹中有效地学习,从而提高它们在复杂、多步推理任务中的泛化能力。在 WebShop 环境(一个模拟电子商务平台)中验证了该方法,在该环境中,它始终优于行为克隆和强化学习的微调基线,并且在具备在线搜索能力时超越了人类的平均表现。在现实世界的预订场景中,该方法在一天的数据收集后将 Llama-3 70B 模型的零样本性能从 18.6% 提高到 81.7%(相对增长了 340%),并通过在线搜索进一步提高到 95.4%。
大语言模型 (LLM) 的最新进展代表了人工智能的重大飞跃。ChatGPT(Schulman,2022)、Gemini(Anil,2023)、Opus(Anthropic,2024)和 LLaMA-3(Touvron,2023)等前沿模型展示了有希望的推理能力,在许多领域接近人类的平均表现。这些突破将 LLM 的实用性从传统的聊天和基于文本的应用程序扩展到更动态、智体化的角色,在这些角色中,它们不仅可以生成文本,还可以在包括代码和软件工程(Holt,2024;Jimenez,2024;Yang,2024;Zhang,2024d)、设备控制(Chen and Li,2024;Wang,2024a;Zhang,2023)和 Web 应用程序(Deng,2023;Gur,2024;Hong,2023;Lai,2024a;Zhou,2024b)等多种环境中自主采取行动。然而,尽管取得了这些进步,但仍然存在重大挑战:LLM 仍然难以在交互式多步骤环境中有效推广,因为它们并非针对此类应用进行过原生训练。即使对于当前这一代最强大的一些模型,例如 GPT-4(Achiam,2023 年),情况也是如此。
越来越多的智体试图解决这些问题;然而,这些工作主要集中在围绕现有模型基于提示学习或静态数据集的有限微调构建框架,因此受到基础模型的推理和决策能力的限制。推理和规划确实已被强调为当前 LLM 的核心挑战。自从关于思维链推理的开创性研究(Wei,2022)以来,人们已经做出了巨大努力,通过基于提示的策略来提高这些能力(Kojima,2022;Qiao,2023;Wang,2023;Yao,2023a)。虽然这些方法很成功,但它们仍然受到基础模型性能的限制。另一个研究方向探索了微调方法(Pang,2024;Zelikman,2022),最近又将它们与推理-时间的搜索提示(Yao,2023a)相结合,产生细粒度的反馈。并行的工作(Hwang,2024;Tian,2024;Xie,2024;Zhang,2024e)利用搜索算法产生的痕迹,并将其与优化方法(Rafailov,2023;Zelikman,2022)相结合,显著提升能力,特别是在数学问题解决和代码生成方面。
本文提出的方法,如图所示:用蒙特卡洛树搜索 (MCTS) 来指导轨迹收集,并使用直接偏好优化 (DPO) 迭代改进模型性能。从左侧开始,从数据集中的任务列表中抽取用户查询。用 置信度上限(UCB1)作为启发式方法迭代扩展搜索树,平衡不同操作的探索和利用。存储树中每个节点获得的累积奖励,图中深绿色表示奖励较高,深红色表示奖励较低。为了构建偏好数据集,计算 MCTS 平均 Q 值和反馈语言模型生成分数的加权分数,构建 DPO 的对比对。该策略已优化,可以迭代改进。
一个智体的观察 o? 是用户和 Web 浏览器给出的命令/信息。第一个观察 o1 是用户文本指令。后续观察包括来自浏览器的网页,以 HTML DOM 格式表示。有时,对于某些任务,智体可能会要求用户确认/反馈,这也成为观察的一部分。
而智体的动作 a? 是复合的,基于智体的历史 h?。基本方法是带有初步规划步骤 PlanReAct (Liu et al. 2023)的ReAct 智体 (Yao et al. 2023b),并带有一些附加组件。
将步骤动作 a? 表示为一个多元组,包括第一步的规划、思维、环境和解释动作,以及后续步骤的思维、环境和解释动作。
如图所示:为 Agent 提供以下输入格式,包括系统提示、执行历史、当前观察(以 DOM 表示)以及包含目标的用户查询。将 Agent 的输出格式分为总体分步规划、思维、命令和状态代码。

智体的状态是网络的当前状态,可能无法观察到。在 POMDP 中,还需要构建一个智体记忆组件 h?。先前的工作使用了观察和操作的整个轨迹,但是 HTML DOM 可能长达数十万个tokens。此外,现实的网络任务可能需要比大多数先前工作使用的静态基准,例如 WebShop (Yao 2022) 和 WebArena (Zhou 2024b))更多的交互。由于上下文窗口有限、潜在的分布不均问题以及实际的推理速度和成本,这使得使用完整的网络轨迹变得不切实际。相反,将智体的历史表示构建为 h? = (a1, . . . , a?−1, o?)。也就是说,智体历史由迄今为止生成的动作和当前浏览器状态组成。也将其称为智体状态。尽管只有环境动作用于与浏览器交互,还是构建智体思维和解释动作,以充当内心独白的一种形式 (Huang 2022b),并充分表示其状态和意图。这用明显更紧凑的历史表示。虽然只有环境动作会影响浏览器状态,但规划、推理和解释组件会由于条件而影响后续决策。由于这个原因,当优化智体时,会计算复合动作的可能性。
经典的 RLHF 使用了策略梯度类的算法,例如 PPO(Schulman 2017),但是,它们很复杂并且需要在线数据,在智体设置中自主收集这些数据可能成本高昂/危险。虽然 PPO 在之前的 Web 智体应用中取得了一些成功 (Nakano 2021)。上述问题在很大程度上使得该方法不适用于信息检索以外的一般 Web 任务。
强化微调 (RFT) 算法(Gulcehre 2023)(Singh 2024)(Yuan 2023)(Zelikman 2022) 因其简单性和可扩展性而越来越受欢迎。这些方法会根据某些奖励模型或验证器聚合数据并过滤掉次优样本,以构建不断增长的高质量轨迹数据集 ?。
直接偏好优化 (DPO) (Rafailov2023) 是传统 RLHF 优化流程的离线 RL (Levine 2020) 替代方案。它是一种适合智体微调的算法,因为它可以使用完全离线的数据并且不需要在线部署。
算法实际部署的一个瓶颈是优化过程中需要参考模型 ?ref,这需要更多的计算资源。相反,在设置中,用一个去-策略(off-policy)重放缓冲区稍微修改一下算法,该缓冲区聚合了轨迹数据以及生成动作的可能性。在优化步骤中,在数据生成(参考)密度下对轨迹元组和相应的可能性进行采样,无需一个单独的参考模型。
蒙特卡洛树搜索 (MCTS) 算法 (Kocsis & Szepesvári 2006) 与 (Hao 2023) 的算法非常相似,包含四个阶段:选择、扩展、模拟和反向传播。每个阶段在平衡探索和利用的同时迭代改进策略方面都发挥着关键作用。
将 Web 智体执行表述为对网页的树搜索。状态表示包括智体历史摘要和当前网页的 文本目标模型(DOM)树。与棋盘游戏如 Chess 或 Go (Silver 2017b))不同,使用的复杂 Web 智体动作空间是开放格式和可变的。相反,本文用基本模型作为动作提议分布,并在每个节点(网页)上抽样固定数量的可能动作。一旦在浏览器中选择并执行一个动作,就会遍历下一个网页,该网页与更新的历史记录一起成为新节点。
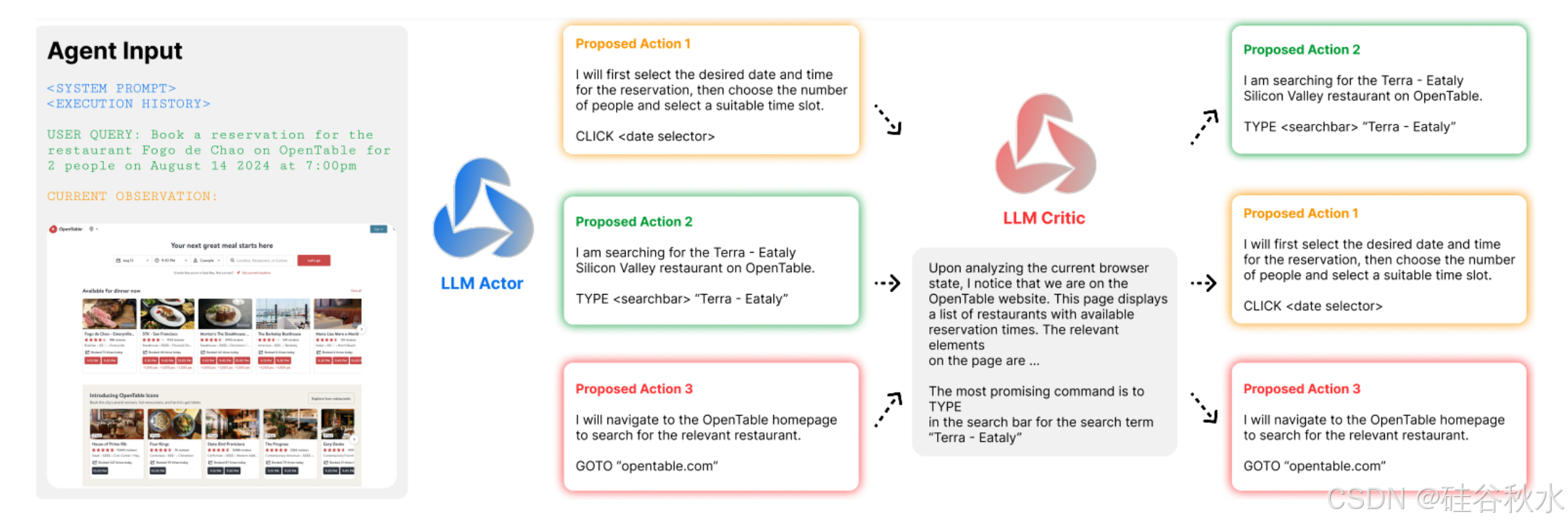
选择阶段使用 MCTS 的置信上边界 (UCB1) 公式(Hao2023) 来选择节点,旨在平衡探索和开发。基于 Web 的环境不提供中间奖励来指导搜索,因此结合基于 AI 的批评,单步级提供过程监督,指导探索过程。用基础模型为每个动作生成反馈分数,其方法,即根据帮助智体完成用户任务的感知效用,对生成的动作进行排名。
对反馈模型进行多次迭代查询,每次从列表中删除上一次迭代中选择的最佳操作,直到对所有操作进行完整排名。完整的 AI 反馈流程如图所示:该策略在推理时间搜索期间的每一步都会提出 K 个动作。批评者也初始化为策略使用的相同基础 LLM 模型,对策略提出的动作进行排名。此排名用于指导扩展后的节点选择,并用于在策略训练期间构建偏好对。
使用离线 (Snell 2022) 或去-策略 (Chebotar 2023) 强化学习大规模训练大型基础模型,仍然具有挑战性。同时,在线(带-策略)强化学习 (Ouyang 2022); (Stiennon 2022) 不能扩展到真实的交互环境。相反,遵循最近的一系列研究,将 DPO 算法 (Rafailov 2023, 2024) 应用于数学领域多步推理问题的分步级(Chen 2024); (Hwang 2024); (Lai 2024b); (Lu 2024); (Setlur 2024b); (Xie 2024); (Zhang 2024f)。该方法与 (Chen 2024) 的方法最为相似; (Xie 2024);(Zhang 2024f) 也利用树搜索的分支特性来生成分步级偏好对。
如图所示是所示不同方法在 WebShop(Yao 2022) 任务上的成功率。所有模型均基于 xLAM-v0.1-r (Zhang (2024c)。在 xLAM-v0.1-r 上,强化微调(RFT) 和 DPO 分别将性能提高了 28.6% 至 31.3% 和 37.5%。然而,这些方法仍然落后于 50.0% 的人类平均表现。该方法 Agent Q + MCTS 比基础模型实现显著的提升(相对提升 76.57%),在 WebShop 上的表现优于人类平均表现,成功率为 50.5%。
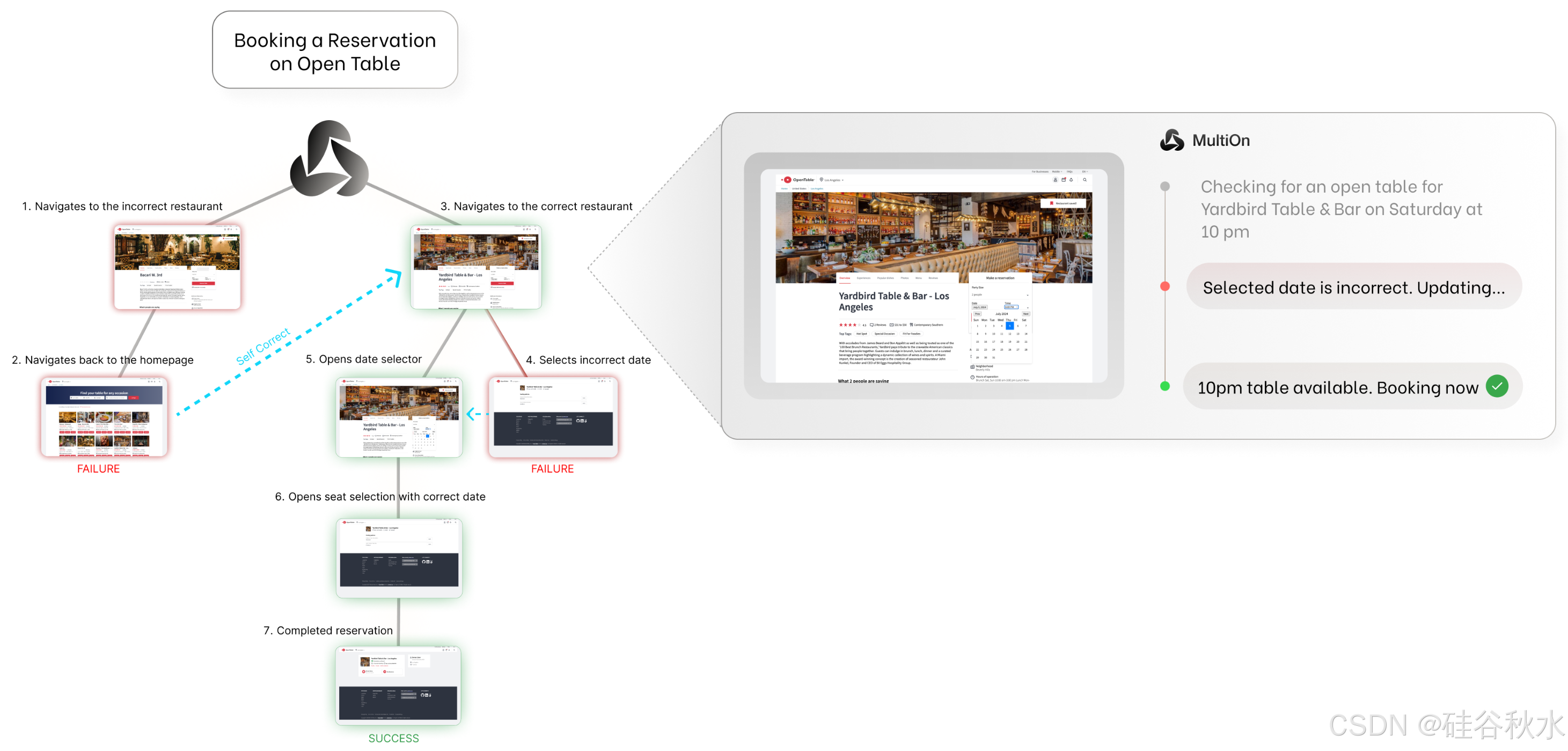
在 OpenTable 中,智体负责为用户预订餐厅。智体必须在 OpenTable 网站上找到餐厅页面,查找特定日期和时间的预订,选择符合用户偏好的座位选项,并提交用户联系信息,才能成功完成任务。由于 OpenTable 是一个实时环境,很难通过编程来衡量指标,因此用语言模型 GPT-4-V 来收集每条轨迹的奖励,这些奖励基于以下指标:(1) 正确设置日期和时间,(2) 正确设置聚会人数,(3) 正确输入用户信息,(4) 点击完成预订。如果满足上述每个约束条件,则将任务标为已完成。结果监督设置如图所示:在轨迹结束时,将调用 GPT-4-V 评估器根据最终观察和行动历史对智体的表现提供反馈,以确定成功分数。该模型会提示轨迹的简明执行历史和最终状态的屏幕截图。成功指标是二进制 0/1 值。
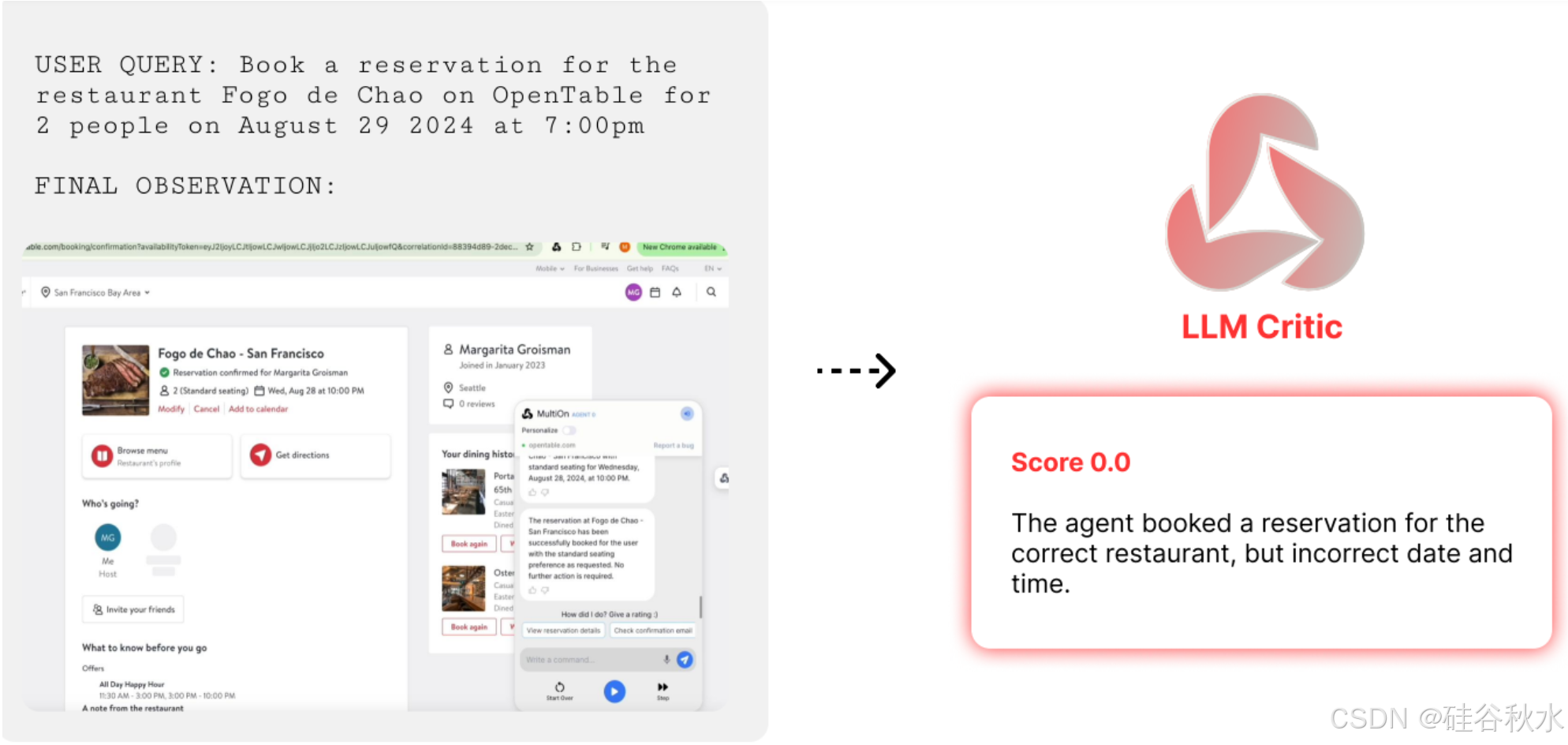
如图所示是 OpenTable 上不同方法的成功率。除非另有说明,所有模型均基于 LLaMA-3-70B-Instruct (Touvron 2023)。使用 DPO 和 强化微调 (RFT) 与 MCTS 进一步将性能分别从 18.6% 提高到 71.8% 和 84.3%。 Agent Q 本身可达到 81.7%,而 Agent Q + MCTS 明显优于所有其他技术,在 OpenTable 上的性能为 95.4%。