???欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。

推荐:Linux运维老纪的首页,持续学习,不断总结,共同进步,活到老学到老
导航剑指大厂系列:全面总结 运维核心技术:系统基础、数据库、网路技术、系统安全、自动化运维、容器技术、监控工具、脚本编程、云服务等。
常用运维工具系列:常用的运维开发工具, zabbix、nagios、docker、k8s、puppet、ansible等
数据库系列:详细总结了常用数据库 mysql、Redis、MongoDB、oracle 技术点,以及工作中遇到的 mysql 问题等
懒人运维系列:总结好用的命令,解放双手不香吗?能用一个命令完成绝不用两个操作
数据结构与算法系列:总结数据结构和算法,不同类型针对性训练,提升编程思维,剑指大厂
非常期待和您一起在这个小小的网络世界里共同探索、学习和成长。??? ✨✨ 欢迎订阅本专栏 ✨✨
使用kube-prometheus部署k8s监控(超详细)
kubernetes的最新版本已经到了1.20.x,利用假期时间搭建了最新的k8s v1.20.2版本,截止我整理此文为止,发现官方最新的release已经更新到了v1.20.4。
1、概述
1.1 在k8s中部署Prometheus监控的方法
通常在k8s中部署prometheus监控可以采取的方法有以下三种
1.2 什么是Prometheus Operator
Prometheus Operator的本职就是一组用户自定义的CRD资源以及Controller的实现,Prometheus Operator负责监听这些自定义资源的变化,并且根据这些资源的定义自动化的完成如Prometheus Server自身以及配置的自动化管理工作。以下是Prometheus Operator的架构图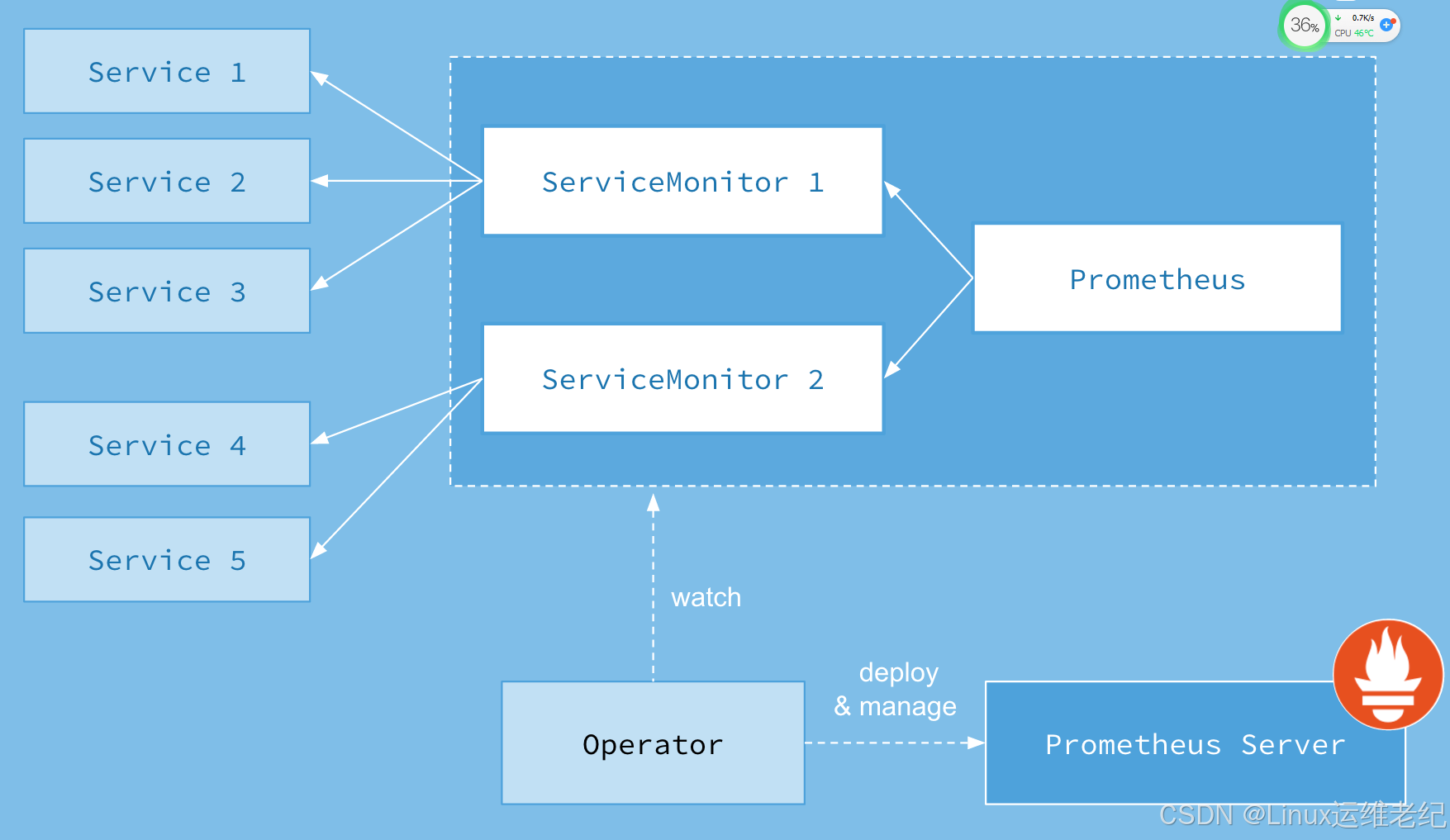
1.3 为什么用Prometheus Operator
由于Prometheus本身没有提供管理配置的AP接口(尤其是管理监控目标和管理警报规则),也没有提供好用的多实例管理手段,因此这一块往往要自己写一些代码或脚本。为了简化这类应用程序的管理复杂度,CoreOS率先引入了Operator的概念,并且首先推出了针对在Kubernetes下运行和管理Etcd的Etcd Operator。并随后推出了Prometheus Operator
1.4 kube-prometheus项目介绍
prometheus-operator官方地址:GitHub - prometheus-operator/prometheus-operator: Prometheus Operator creates/configures/manages Prometheus clusters atop Kubernetes
kube-prometheus官方地址:GitHub - prometheus-operator/kube-prometheus: Use Prometheus to monitor Kubernetes and applications running on Kubernetes
两个项目的关系:前者只包含了Prometheus Operator,后者既包含了Operator,又包含了Prometheus相关组件的部署及常用的Prometheus自定义监控,具体包含下面的组件
2、环境介绍
本文的k8s环境是通过kubeadm搭建的v 1.20.2版本,由1master+2node组合
持久化存储为storageclass动态存储,底层由ceph-rbd提供
➜ kubectl version -o yamlclientVersion: buildDate: "2020-12-08T17:59:43Z" compiler: gc gitCommit: af46c47ce925f4c4ad5cc8d1fca46c7b77d13b38 gitTreeState: clean gitVersion: v1.20.0 goVersion: go1.15.5 major: "1" minor: "20" platform: darwin/amd64serverVersion: buildDate: "2021-01-13T13:20:00Z" compiler: gc gitCommit: faecb196815e248d3ecfb03c680a4507229c2a56 gitTreeState: clean gitVersion: v1.20.2 goVersion: go1.15.5 major: "1" minor: "20" platform: linux/amd64➜ kubectl get nodes NAME STATUS ROLES AGE VERSIONk8s-m-01 Ready control-plane,master 11d v1.20.2k8s-n-01 Ready <none> 11d v1.20.2k8s-n-02 Ready <none> 11d v1.20.2➜ manifests kubectl get sc NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGEdynamic-ceph-rbd (default) ceph.com/rbd Delete Immediate false 7d23hkube-prometheus的兼容性说明(https://github.com/prometheus-operator/kube-prometheus#kubernetes-compatibility-matrix),按照兼容性说明,部署的是最新的release-0.7版本
| kube-prometheus stack | Kubernetes 1.16 | Kubernetes 1.17 | Kubernetes 1.18 | Kubernetes 1.19 | Kubernetes 1.20 |
|---|---|---|---|---|---|
release-0.4 | ✔ (v1.16.5+) | ✔ | ✗ | ✗ | ✗ |
release-0.5 | ✗ | ✗ | ✔ | ✗ | ✗ |
release-0.6 | ✗ | ✗ | ✔ | ✔ | ✗ |
release-0.7 | ✗ | ✗ | ✗ | ✔ | ✔ |
HEAD | ✗ | ✗ | ✗ | ✔ | ✔ |
3、清单准备
从官方的地址获取最新的release-0.7分支,或者直接打包下载release-0.7
➜ git clone https://github.com/prometheus-operator/kube-prometheus.git➜ git checkout release-0.7或者➜ wget -c https://github.com/prometheus-operator/kube-prometheus/archive/v0.7.0.zip默认下载下来的文件较多,建议把文件进行归类处理,将相关yaml文件移动到对应目录下
➜ cd kube-prometheus/manifests➜ mkdir -p serviceMonitor prometheus adapter node-exporter kube-state-metrics grafana alertmanager operator other最终结构如下
➜ manifests tree ..├── adapter│ ├── prometheus-adapter-apiService.yaml│ ├── prometheus-adapter-clusterRole.yaml│ ├── prometheus-adapter-clusterRoleAggregatedMetricsReader.yaml│ ├── prometheus-adapter-clusterRoleBinding.yaml│ ├── prometheus-adapter-clusterRoleBindingDelegator.yaml│ ├── prometheus-adapter-clusterRoleServerResources.yaml│ ├── prometheus-adapter-configMap.yaml│ ├── prometheus-adapter-deployment.yaml│ ├── prometheus-adapter-roleBindingAuthReader.yaml│ ├── prometheus-adapter-service.yaml│ └── prometheus-adapter-serviceAccount.yaml├── alertmanager│ ├── alertmanager-alertmanager.yaml│ ├── alertmanager-secret.yaml│ ├── alertmanager-service.yaml│ └── alertmanager-serviceAccount.yaml├── grafana│ ├── grafana-dashboardDatasources.yaml│ ├── grafana-dashboardDefinitions.yaml│ ├── grafana-dashboardSources.yaml│ ├── grafana-deployment.yaml│ ├── grafana-service.yaml│ └── grafana-serviceAccount.yaml├── kube-state-metrics│ ├── kube-state-metrics-clusterRole.yaml│ ├── kube-state-metrics-clusterRoleBinding.yaml│ ├── kube-state-metrics-deployment.yaml│ ├── kube-state-metrics-service.yaml│ └── kube-state-metrics-serviceAccount.yaml├── node-exporter│ ├── node-exporter-clusterRole.yaml│ ├── node-exporter-clusterRoleBinding.yaml│ ├── node-exporter-daemonset.yaml│ ├── node-exporter-service.yaml│ └── node-exporter-serviceAccount.yaml├── operator│ ├── 0namespace-namespace.yaml│ ├── prometheus-operator-0alertmanagerConfigCustomResourceDefinition.yaml│ ├── prometheus-operator-0alertmanagerCustomResourceDefinition.yaml│ ├── prometheus-operator-0podmonitorCustomResourceDefinition.yaml│ ├── prometheus-operator-0probeCustomResourceDefinition.yaml│ ├── prometheus-operator-0prometheusCustomResourceDefinition.yaml│ ├── prometheus-operator-0prometheusruleCustomResourceDefinition.yaml│ ├── prometheus-operator-0servicemonitorCustomResourceDefinition.yaml│ ├── prometheus-operator-0thanosrulerCustomResourceDefinition.yaml│ ├── prometheus-operator-clusterRole.yaml│ ├── prometheus-operator-clusterRoleBinding.yaml│ ├── prometheus-operator-deployment.yaml│ ├── prometheus-operator-service.yaml│ └── prometheus-operator-serviceAccount.yaml├── other├── prometheus│ ├── prometheus-clusterRole.yaml│ ├── prometheus-clusterRoleBinding.yaml│ ├── prometheus-prometheus.yaml│ ├── prometheus-roleBindingConfig.yaml│ ├── prometheus-roleBindingSpecificNamespaces.yaml│ ├── prometheus-roleConfig.yaml│ ├── prometheus-roleSpecificNamespaces.yaml│ ├── prometheus-rules.yaml│ ├── prometheus-service.yaml│ └── prometheus-serviceAccount.yaml└── serviceMonitor ├── alertmanager-serviceMonitor.yaml ├── grafana-serviceMonitor.yaml ├── kube-state-metrics-serviceMonitor.yaml ├── node-exporter-serviceMonitor.yaml ├── prometheus-adapter-serviceMonitor.yaml ├── prometheus-operator-serviceMonitor.yaml ├── prometheus-serviceMonitor.yaml ├── prometheus-serviceMonitorApiserver.yaml ├── prometheus-serviceMonitorCoreDNS.yaml ├── prometheus-serviceMonitorKubeControllerManager.yaml ├── prometheus-serviceMonitorKubeScheduler.yaml └── prometheus-serviceMonitorKubelet.yaml9 directories, 67 files修改yaml,增加prometheus和grafana的持久化存储
manifests/prometheus/prometheus-prometheus.yaml
... serviceMonitorSelector: {} version: v2.22.1 retention: 3d storage: volumeClaimTemplate: spec: storageClassName: dynamic-ceph-rbd resources: requests: storage: 5Gimanifests/grafana/grafana-deployment.yaml
... serviceAccountName: grafana volumes:# - emptyDir: {}# name: grafana-storage - name: grafana-storage persistentVolumeClaim: claimName: grafana-data新增grafana的pvc,manifests/other/grafana-pvc.yaml
kind: PersistentVolumeClaimapiVersion: v1metadata: name: grafana-data namespace: monitoring annotations: volume.beta.kubernetes.io/storage-class: "dynamic-ceph-rbd"spec: accessModes: - ReadWriteMany resources: requests: storage: 5Gi4、开始部署
部署清单
➜ kubectl create -f other/grafana-pvc.yaml ➜ kubectl create -f operator/➜ kubectl create -f adapter/ -f alertmanager/ -f grafana/ -f kube-state-metrics/ -f node-exporter/ -f prometheus/ -f serviceMonitor/ 查看状态
➜ kubectl get po,svc -n monitoring NAME READY STATUS RESTARTS AGEpod/alertmanager-main-0 2/2 Running 0 15mpod/alertmanager-main-1 2/2 Running 0 10mpod/alertmanager-main-2 2/2 Running 0 15mpod/grafana-d69dcf947-wnspk 1/1 Running 0 22mpod/kube-state-metrics-587bfd4f97-bffqv 3/3 Running 0 22mpod/node-exporter-2vvhv 2/2 Running 0 22mpod/node-exporter-7nsz5 2/2 Running 0 22mpod/node-exporter-wggpp 2/2 Running 0 22mpod/prometheus-adapter-69b8496df6-cjw6w 1/1 Running 0 23mpod/prometheus-k8s-0 2/2 Running 1 75spod/prometheus-k8s-1 2/2 Running 0 9m33spod/prometheus-operator-7649c7454f-nhl72 2/2 Running 0 28mNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEservice/alertmanager-main ClusterIP 10.1.189.238 <none> 9093/TCP 23mservice/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 23mservice/grafana ClusterIP 10.1.29.30 <none> 3000/TCP 23mservice/kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 23mservice/node-exporter ClusterIP None <none> 9100/TCP 23mservice/prometheus-adapter ClusterIP 10.1.75.64 <none> 443/TCP 23mservice/prometheus-k8s ClusterIP 10.1.111.121 <none> 9090/TCP 23mservice/prometheus-operated ClusterIP None <none> 9090/TCP 14mservice/prometheus-operator ClusterIP None <none> 8443/TCP 28m为prometheus、grafana、alertmanager创建ingress
manifests/other/ingress.yaml
apiVersion: networking.k8s.io/v1kind: Ingressmetadata: name: prom-ingress namespace: monitoring annotations: kubernetes.io/ingress.class: "nginx" prometheus.io/http_probe: "true"spec: rules: - host: alert.k8s-1.20.2.com http: paths: - path: / pathType: Prefix backend: service: name: alertmanager-main port: number: 9093 - host: grafana.k8s-1.20.2.com http: paths: - path: / pathType: Prefix backend: service: name: grafana port: number: 3000 - host: prom.k8s-1.20.2.com http: paths: - path: / pathType: Prefix backend: service: name: prometheus-k8s port: number: 90905、解决ControllerManager、Scheduler监控问题
默认安装后访问prometheus,会发现有以下有三个报警:
Watchdog、KubeControllerManagerDown、KubeSchedulerDown
Watchdog是一个正常的报警,这个告警的作用是:如果alermanger或者prometheus本身挂掉了就发不出告警了,因此一般会采用另一个监控来监控prometheus,或者自定义一个持续不断的告警通知,哪一天这个告警通知不发了,说明监控出现问题了。prometheus operator已经考虑了这一点,本身携带一个watchdog,作为对自身的监控。
如果需要关闭,删除或注释掉Watchdog部分
prometheus-rules.yaml
... - name: general.rules rules: - alert: TargetDown annotations: message: 'xxx' expr: 100 * (count(up == 0) BY (job, namespace, service) / count(up) BY (job, namespace, service)) > 10 for: 10m labels: severity: warning# - alert: Watchdog# annotations:# message: |# This is an alert meant to ensure that the entire alerting pipeline is functional.# This alert is always firing, therefore it should always be firing in Alertmanager# and always fire against a receiver. There are integrations with various notification# mechanisms that send a notification when this alert is not firing. For example the# "DeadMansSnitch" integration in PagerDuty.# expr: vector(1)# labels:# severity: noneKubeControllerManagerDown、KubeSchedulerDown的解决
原因是因为在prometheus-serviceMonitorKubeControllerManager.yaml中有如下内容,但默认安装的集群并没有给系统kube-controller-manager组件创建svc
selector: matchLabels: k8s-app: kube-controller-manager修改kube-controller-manager的监听地址
# vim /etc/kubernetes/manifests/kube-controller-manager.yaml...spec: containers: - command: - kube-controller-manager - --allocate-node-cidrs=true - --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf - --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf - --bind-address=0.0.0.0# netstat -lntup|grep kube-contro tcp6 0 0 :::10257 :::* LISTEN 38818/kube-controll创建一个service和endpoint,以便serviceMonitor监听
other/kube-controller-namager-svc-ep.yaml
apiVersion: v1kind: Servicemetadata: name: kube-controller-manager namespace: kube-system labels: k8s-app: kube-controller-managerspec: type: ClusterIP clusterIP: None ports: - name: https-metrics port: 10257 targetPort: 10257 protocol: TCP---apiVersion: v1kind: Endpointsmetadata: name: kube-controller-manager namespace: kube-system labels: k8s-app: kube-controller-managersubsets:- addresses: - ip: 172.16.1.71 ports: - name: https-metrics port: 10257 protocol: TCPkube-scheduler同理,修改kube-scheduler的监听地址
# vim /etc/kubernetes/manifests/kube-scheduler.yaml...spec: containers: - command: - kube-scheduler - --authentication-kubeconfig=/etc/kubernetes/scheduler.conf - --authorization-kubeconfig=/etc/kubernetes/scheduler.conf - --bind-address=0.0.0.0# netstat -lntup|grep kube-schedtcp6 0 0 :::10259 :::* LISTEN 100095/kube-schedul创建一个service和endpoint,以便serviceMonitor监听
kube-scheduler-svc-ep.yaml
apiVersion: v1kind: Servicemetadata: name: kube-scheduler namespace: kube-system labels: k8s-app: kube-schedulerspec: type: ClusterIP clusterIP: None ports: - name: https-metrics port: 10259 targetPort: 10259 protocol: TCP---apiVersion: v1kind: Endpointsmetadata: name: kube-scheduler namespace: kube-system labels: k8s-app: kube-schedulersubsets:- addresses: - ip: 172.16.1.71 ports: - name: https-metrics port: 10259 protocol: TCP再次查看prometheus的alert界面,全部恢复正常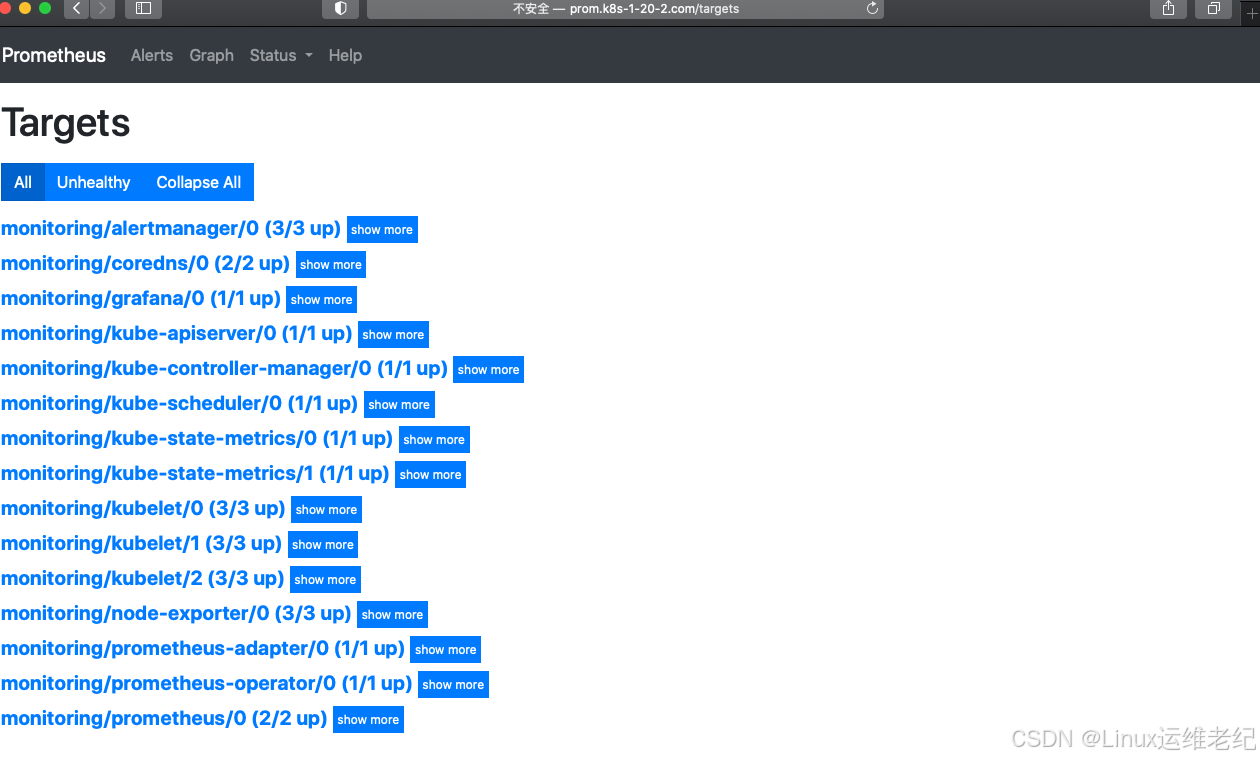
登录到grafana,查看相关图像展示
 至此,通过
至此,通过kube-prometheus部署k8s监控已经基本完成了,后面再分享自定义监控和告警、告警通知、高可用、规模化部署等相关内容