自己的很多文章都发在公众号上,想要查看所有历史文章,可不是那么方便。
有没有办法能一键抓取所有文章,自动呈现在我眼前?
这时,爬虫了解下?
今日分享,就带着大家实操一番,爬取公众号所有历史文章。
目录
什么是爬虫如何爬取公众号文章Step 1:注册一个公众号Step 2:获取三个值Step 3:编写代码 写在最后
什么是爬虫
爬虫这个名词,由来已久了,对于非技术同学来说,可能稍微有点陌生。
爬虫,是一种自动浏览网页的技术,它按照一定的规则,自动访问互联网上的网页,获取网页内容。爬虫可以用于多种目的,比如搜索引擎的数据收集、市场研究、数据挖掘等。
爬虫的类型可以分为:
通用爬虫:爬取整个互联网上的信息,如 Google 和 百度 的爬虫。特定爬虫:专注于特定主题或领域的信息,只爬取与特定主题相关的网页。!友情提醒:使用爬虫需遵守相关法律法规,和网站的 robots.txt 文件规定,避免对网站服务器造成过大负担。
所以,爬取网络资源,最重要的就是可以找到目标网站的 url 地址。
如何爬取公众号文章
Step 1:注册一个公众号
首先,你需要有一个自己的公众号,已经有公众号的小伙伴可以略过,接着往下看。
如果没有的话,大家可以自行操作,注册公众号的步骤非常简单。
Step 2:获取三个值
登录自己的公众号,在控制台首页找到新的创作,点击 图文信息:
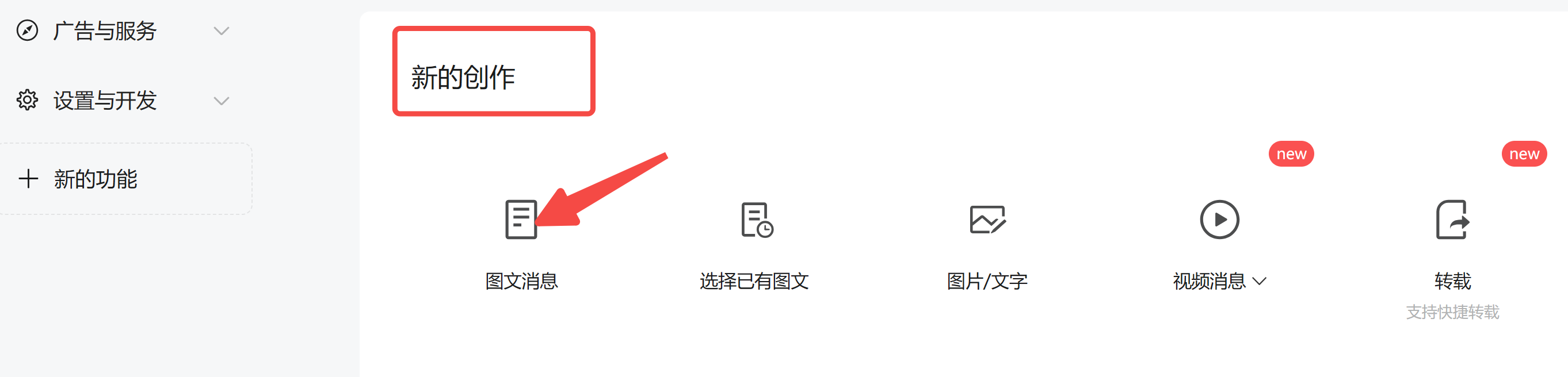
然后,找到正上面的超链接并打开:
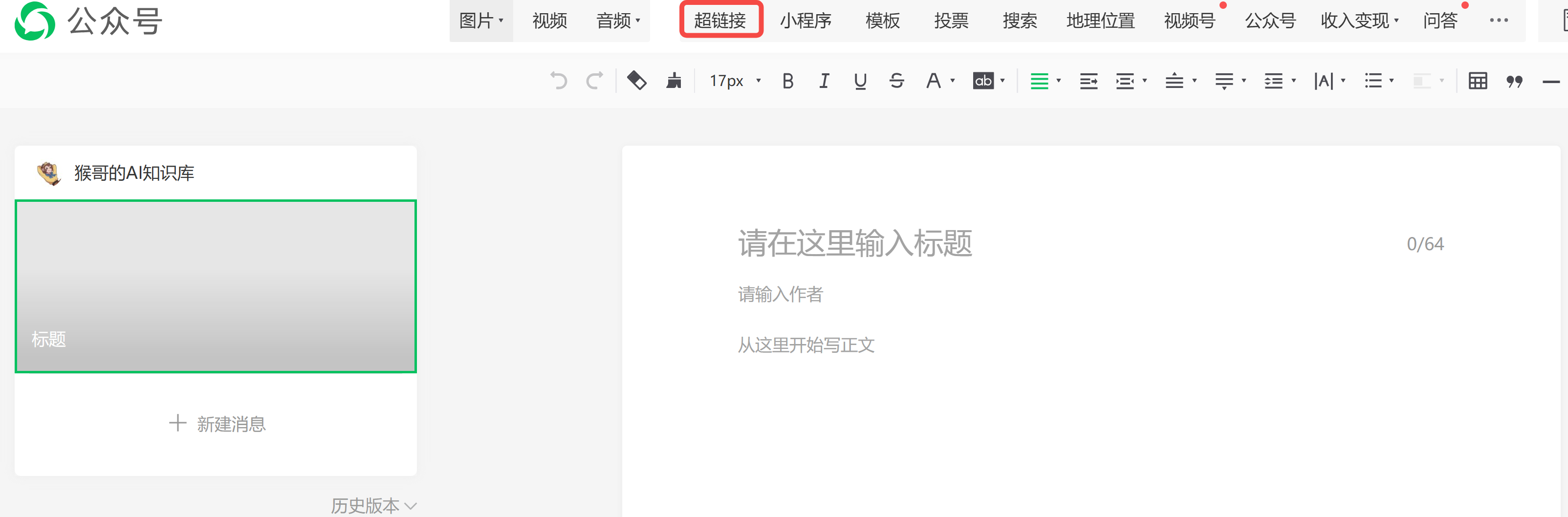
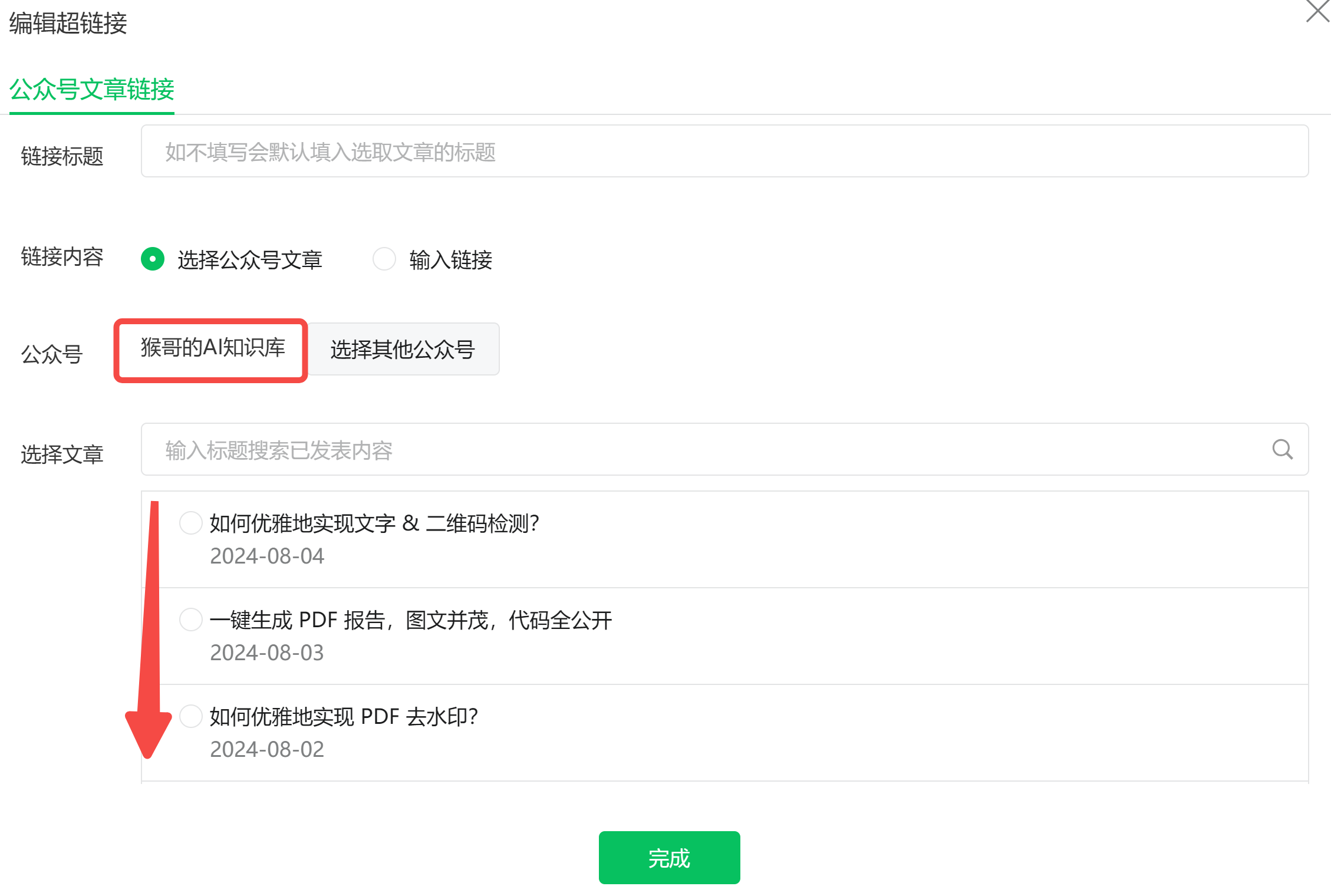
这时你就可以看到自己的所有文章列表了:(如果你想查看其他公众号,在右侧?)
停留在当前网页,按 F12 打开浏览器的开发者工具,找到网络,点击Fetch/XHR,过滤掉其他信息。
注:我这里用的 edge 浏览器,其他浏览器也是类似的。
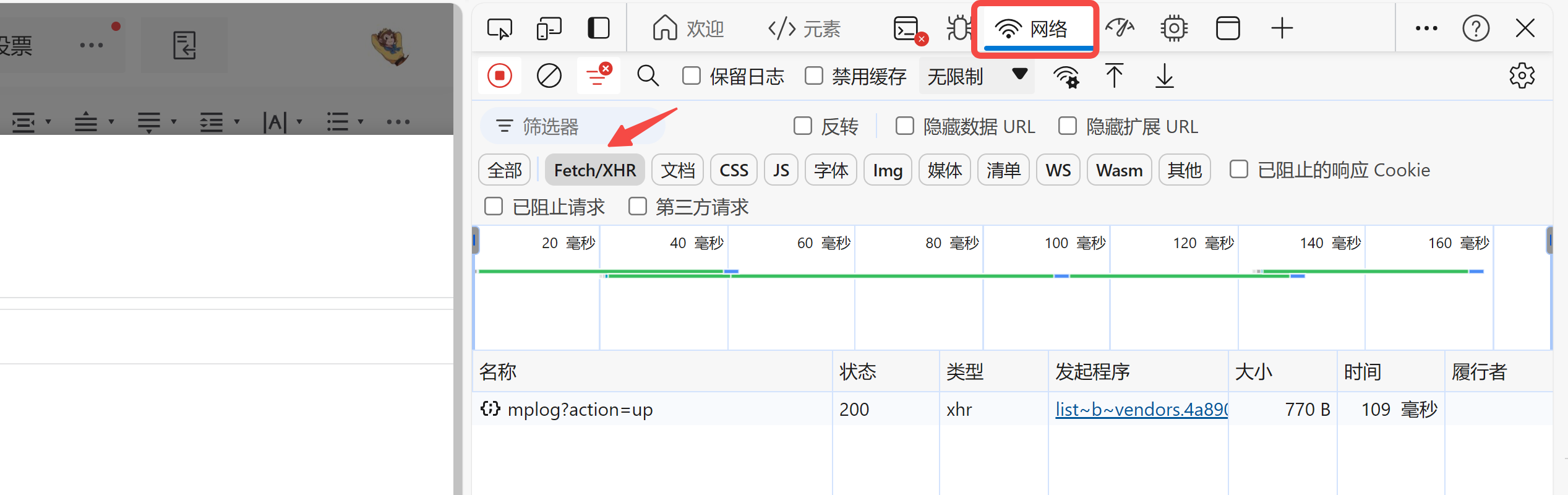
拉到文章列表的最下方,找到并点击翻页按钮。此时,你会发现右侧的开发者工具界面内容多出来一条,就点它?:
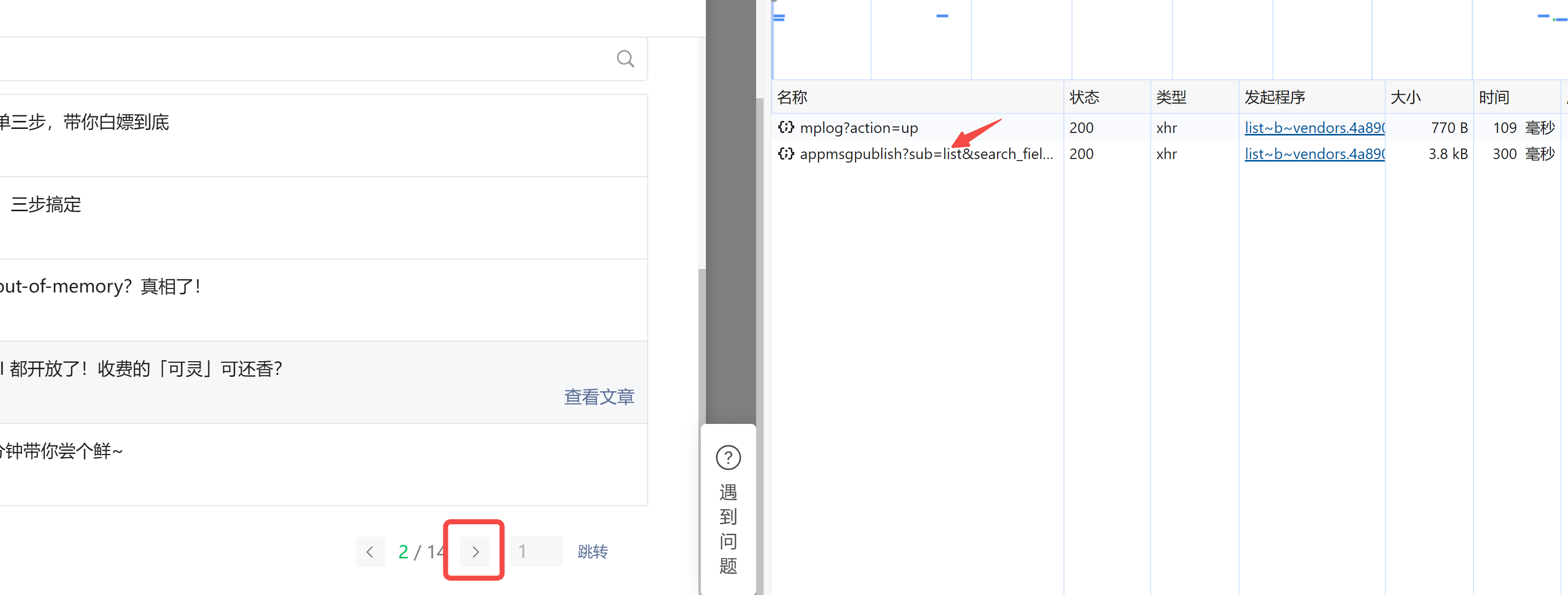
在 标头 这里,找到 cookie 并复制右侧对应的值:

再到 负载 这里,找到 fakeid 和 token 并复制保存下来。

把 cookies、token 以及 fakeid,保存下来,这三者缺一不可。
Step 3:编写代码
有了上述这三个值,我们就可以编写 Python 代码了。
首先,定义 url,header ,然后把三个值填到下面参数的对应位置。
# 目标urlurl = "https://mp.weixin.qq.com/cgi-bin/appmsg"cookie = "填写上方获取到的 cookie"headers = { "Cookie": cookie, "User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.75 Mobile Safari/537.36",}data = { "token": "填写上方获取到的 token", "lang": "zh_CN", "f": "json", "ajax": "1", "action": "list_ex", "begin": "0", "count": "5", "query": "", "fakeid": "填写上方获取到的 fakeid", # 自己的号,设置为空 "type": "9",}想要看看公众号共有多少篇内容? 来~
def get_total_count(): content_json = requests.get(url, headers=headers, params=data).json() count = int(content_json["app_msg_cnt"]) return count想要获取所有文章内容? 来~
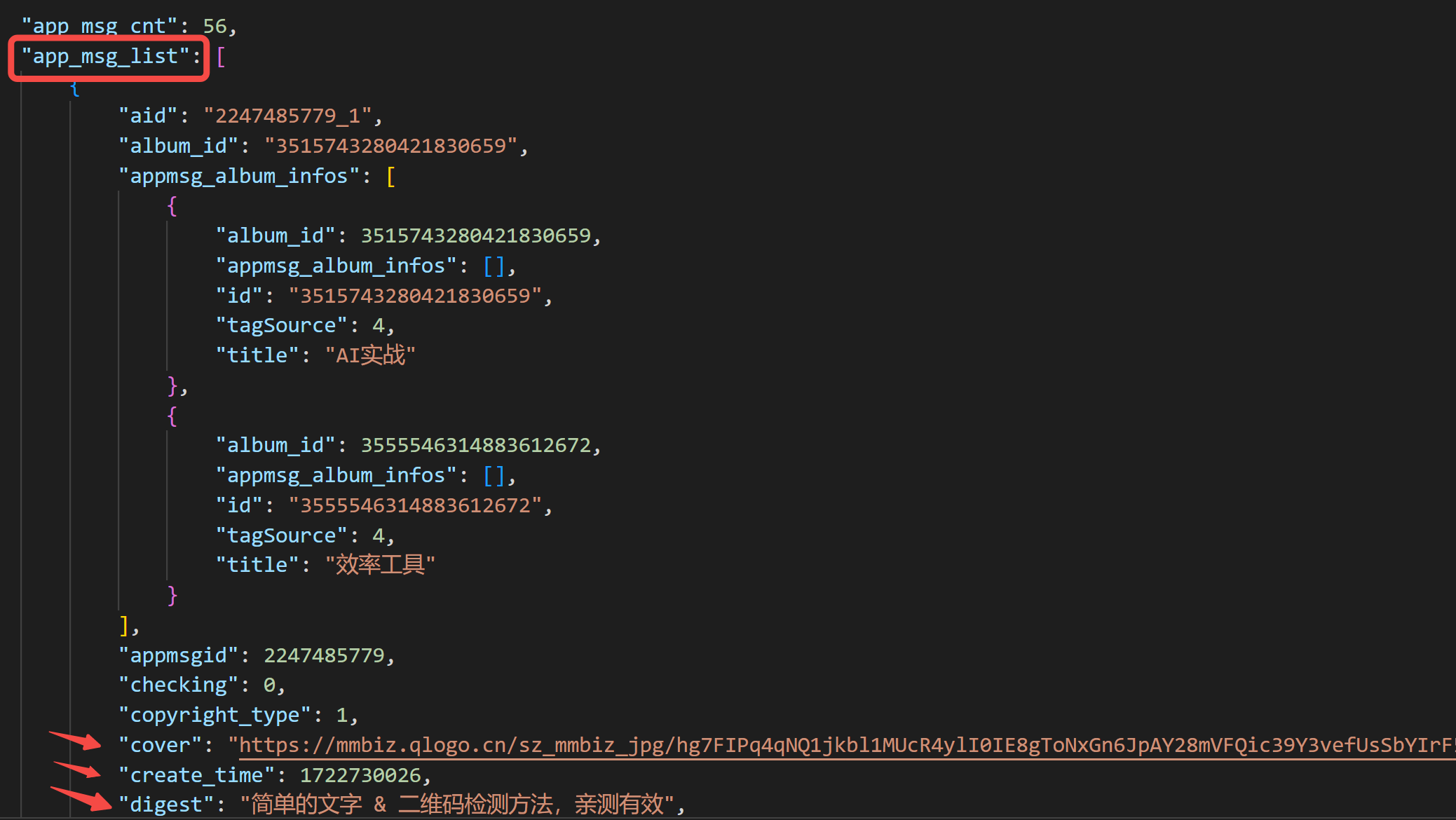
def get_content_list(count, per_page=5): page = int(math.ceil(count / per_page)) content_list = [] for i in tqdm(range(page), desc="获取文章列表"): data["begin"] = i * per_page content_json = requests.get(url, headers=headers, params=data).json() content_list.extend(content_json["app_msg_list"]) time.sleep(random.randint(5, 10)) # 保存成json with open("content_list.json", "w", encoding="utf-8") as f: json.dump(content_list, f, ensure_ascii=False, indent=4)我们在"app_msg_list"中可以看到,拿到了所有文章的列表:
当然,你也可以把文章处理成表格,方便查看:
import pandas as pddef precess_content_list(): content_list = json.load(open("content_list.json", "r", encoding="utf-8")) results_list = [] for item in content_list: title = item["title"] link = item["link"] create_time = time.strftime("%Y-%m-%d %H:%M", time.localtime(item["create_time"])) results_list.append([title, link, create_time]) name = ['title', 'link', 'create_time'] data = pd.DataFrame(columns=name, data=results_list) data.to_csv("data.csv", mode='w', encoding='utf-8')用 Excel 打开看看吧:

写在最后
本文通过一个简单的实操,带大家走进爬虫的世界,手把手教你如何使用 Python,一键抓取