1. vision mamba 背景
Mamba 成功的关键在于采用了 Selective Scan Space State Sequential Model(S6 模型)。是用于解决自然语言处理(NLP)任务。与 transformer中注意力机制不同,Mamba的S6 将 1D 向量中的每个元素(例如文本序列)与在此之前扫描过的信息进行交互,从而有效地将二次复杂度降低到线性。
然而,由于视觉信号(如图像)不像文本序列那样具有天然的有序性,因此无法在视觉信号上简单地对 S6 中的数据扫描方法进行直接应用。为此研究者设计了 Cross-Scan 扫描机制。Cross-Scan 模块(CSM)采用四向扫描策略,即从特征图的四个角同时扫描(见上图)。该策略确保特征中的每个元素都以不同方向从所有其他位置整合信息,从而形成全局感受野,又不增加线性计算复杂度。
2. SS2D的演变
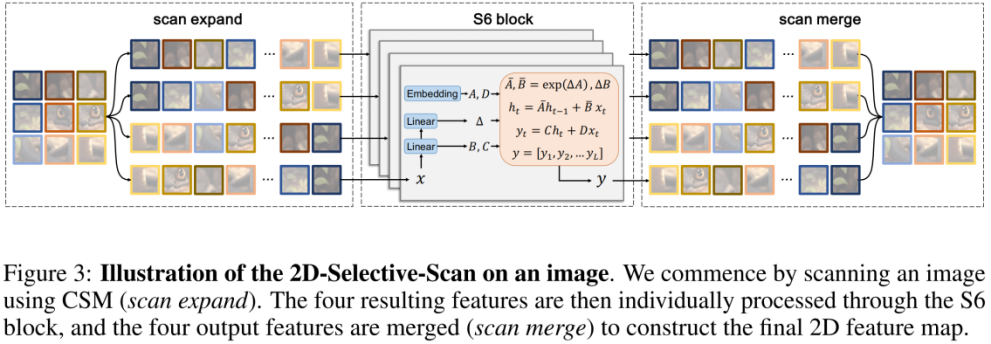
在 CSM 的基础上,设计了 2D-selective-scan(SS2D)模块。如上图所示,SS2D 包含了三个步骤:
scan expand 将一个 2D 特征沿 4 个不同方向(左上、右下、左下、右上)展平为 1D 向量。
S6 block 独立地将上步得到的 4 个 1D 向量送入 S6 操作。
scan merge 将得到的 4 个 1D 向量融合为一个 2D 特征输出。
3. VMamba 结构图
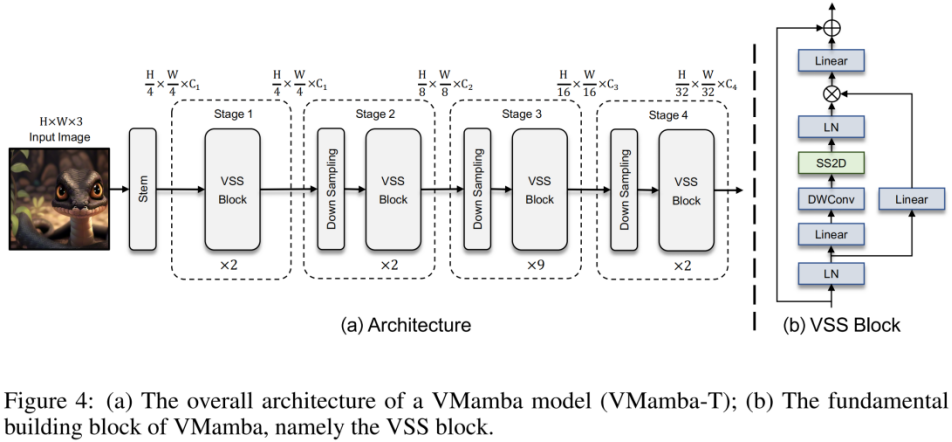
上图为本文提出的 VMamba 结构图。VMamba 的整体框架与主流的视觉模型类似,如上图 (b)所示。经过Layer Normalization后,输入被分成两个分支。在第一个分支中,输入经过一个线性层,然后是一个激活函数。在第二个分支中,输入通过线性层、深度可分离卷积和激活函数进行处理,然后输入到2D选择性扫描(SS2D)模块中进行进一步的特征提取。随后,使用Layer Normalization对特征进行归一化,然后使用第一个分支的输出执行逐元素的生成,以合并两条路径。最后,使用线性层混合特征,并将此结果与残差连接相结合,形成VSS块的输出。本文默认采用SiLU作为激活函数。
其主要区别在于基本模块(VSS block)中采用的算子不同。VSS block 采用了上述介绍的 2D-selective-scan 操作,即 SS2D。SS2D 保证了 VMamba 在线性复杂度的代价下实现全局感受野。
SS2D由三个部分组成:扫描expanding操作、S6块操作和扫描merging操作。如图2(a)所示,扫描expanding操作沿着四个不同的方向(左上到右下、左下到右上、右下到左上、右上到左下)将输入图像展开成序列。然后通过S6块对这些序列进行特征提取,确保各个方向的信息被彻底扫描,从而捕获不同的特征。随后,如图2(b)所示,扫描merging操作将来自四个方向的序列相加并合并,将输出图像恢复为与输入相同的大小。源自Mamba[16]的S6块在S4[17]之上引入了一种选择机制,通过根据输入调整SSM的参数。这使模型能够区分并保留相关信息,同时过滤掉不相关的信息。