
文 / Emily Fertig、Joshua V. Dillon、Wynn Vonnegut、Dave Moore 和 TensorFlow Probability 团队
本文将介绍 TensorFlow Probability 中新的联合分布变分推断工具,展示如何在回归模型中使用这些工具估计权重的贝叶斯可信区间。
-
TensorFlow Probability
https://tensorflow.google.cn/probability/
概述
变分推断 (Variational Inference, VI) 将近似贝叶斯推断转换为优化问题,并寻求一个“代理 (Surrogate)”后验分布,使 KL 与真后验散度最小化。基于梯度的 VI 通常比 MCMC 方法更快,与模型参数的优化自然组合,并提供模型证据的下限,可直接用于模型比较、收敛诊断和可组合推断。
TensorFlow Probability (TFP) 提供了快速、灵活和可扩展的 VI 工具,自然融入 TFP 堆栈。这些工具可以通过线性变换或归一化流引起的协方差结构构建代理后验。
VI 可用于估计回归模型参数的贝叶斯可信区间 (Credible Intervals),以估计各种处理或观察到的特征对目标结果的影响。可信区间根据参数以观察数据为条件的后验分布,给定参数的先验分布的假设,以一定的概率约束未观察到的参数的值。
本文演示了如何使用 VI 获得贝叶斯线性回归模型参数的可信区间,该模型用于测量家庭中的氡水平(使用 Gelman et al.'s (2007) Radon dataset;参见 Stan 中的类似示例)。我们演示了 TFP JointDistributions 如何与双射器结合以建立和拟合两种类型的表达性代理后验:
-
由块矩阵变换的标准正态分布。矩阵可以反映后验的某些分量之间的独立性和其他分量之间的依赖性,放宽均值场或全方差后验的假设。
-
一个更复杂、容量更大的逆自回归流 (Inverse Autoregressive Flow) 。
-
Gelman et al.'s (2007) Radon dataset
http://www.stat.columbia.edu/~gelman/arm/ -
类似示例
https://mc-stan.org/users/documentation/case-studies/radon.html#Correlations-among-levels -
逆自回归流
https://arxiv.org/abs/1606.04934
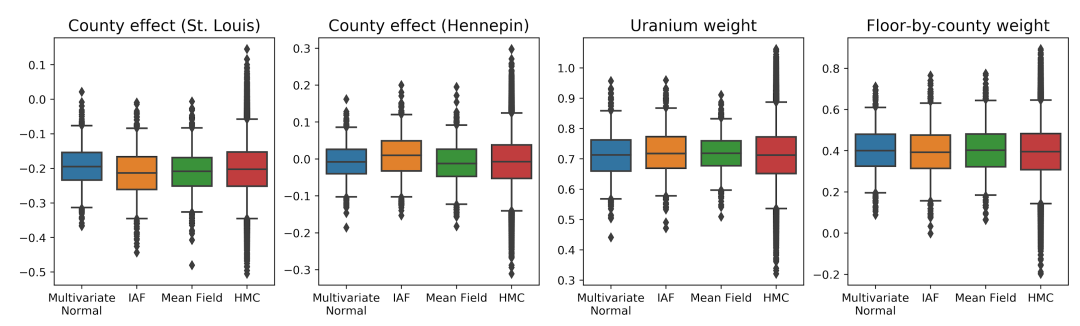
训练代理后验,并与均值场代理后验基线结果进行比较。下图显示了三个 VI 代理后验得到的四个模型参数的可信区间,以及用于比较的汉密尔顿蒙特卡洛 (Hamiltonian Monte Carlo) 算法。
您可以在此 Google Colab 中跟进和了解所有详细信息。
-
Google Colab
https://colab.research.google.com/github/tensorflow/probability/blob/master/tensorflow_probability/examples/jupyter_notebooks/Variational_Inference_and_Joint_Distributions.ipynb
示例:氡测量的贝叶斯分层线性回归
氡是一种放射性气体,通过地面的接触点进入房屋。这种致癌物质是非吸烟者患肺癌的主要原因。不同家庭的氡水平差异很大。
EPA 对 8 万间房屋的氡水平进行了研究。两个重要的预测因素是:
-
测量的楼层(地下室的氡含量较高)
-
县级铀水平(与氡水平正相关)
预测按县分组的房屋的氡水平是贝叶斯分层建模中的一个经典问题,由Gelman 和 Hill (2006) 提出。我们感兴趣的是位置(县,Countyi)对明尼苏达州房屋氡水平影响的可信区间。为了隔离这种影响,模型中还包括楼层和铀水平的影响。此外,我们还将按县纳入一个与测量的平均楼层相对应的背景效应,这样如果测量的楼层在各县之间存在差异,就不会归因于县效应。
-
Gelman 和 Hill (2006)
http://www.stat.columbia.edu/~gelman/arm/
回归模型具体如下:

其中 i 为观测值,countyi 即县的第 i 个观测值。
我们使用 county-level 随机效应捕捉地理差异。参数 uranium_weight 和 county_floor_weight 经过概率建模,floor_weight 和常数 bias 是确定性的。这些建模选择在很大程度上是任意的,目的是为了在一个合理复杂的概率模型上证明 VI。关于使用氡数据集在 TFP 中通过固定和随机效应进行多层建模的更深入讨论,请参阅多级建模 Primer 和使用变分推断拟合泛化的线性混合效应模型。
-
多级建模 Primer
https://github.com/tensorflow/probability/blob/master/tensorflow_probability/examples/jupyter_notebooks/Multilevel_Modeling_Primer.ipynb -
使用变分推断拟合泛化的线性混合效应模型
https://github.com/tensorflow/probability/blob/master/tensorflow_probability/examples/jupyter_notebooks/Linear_Mixed_Effects_Model_Variational_Inference.ipynb
Github 上提供了此示例的完整代码。
-
Github
https://colab.research.google.com/github/tensorflow/probability/blob/master/tensorflow_probability/examples/jupyter_notebooks/Variational_Inference_and_Joint_Distributions.ipynb
变量为确定性参数和正态分布尺度参数定义,后者被约束为正数。
import tensorflow as tf
import tensorflow_probability as tfp
tfd = tfp.distributions
tfb = tfp.bijectors
floor_weight = tf.Variable(0.)
bias = tf.Variable(0.)
log_radon_scale = tfp.util.TransformedVariable(1., tfb.Exp())
county_effect_scale = tfp.util.TransformedVariable(1., tfb.Exp())
我们将回归的概率图模型指定为 TFP JointDistribution
@tfd.JointDistributionCoroutineAutoBatched
def model():
uranium_weight = yield tfd.Normal(0., scale=1., name='uranium_weight')
county_floor_weight = yield tfd.Normal(
0., scale=1., name='county_floor_weight')
county_effect = yield tfd.Sample(
tfd.Normal(0., scale=county_effect_scale),
sample_shape=[num_counties], name='county_effect')
yield tfd.Normal(
loc=(log_uranium * uranium_weight
+ floor_of_house * floor_weight
+ floor_by_county * county_floor_weight
+ tf.gather(county_effect, county, axis=-1)
+ bias),
scale=log_radon_scale[..., tf.newaxis],
name='log_radon')
我们将 log_radon 固定在观测到的氡数据上,以对未归一化的后验进行建模。
target_model = model.experimental_pin(log_radon=log_radon)
贝叶斯变分推断快速摘要
假设我们有以下生成过程,其中 𝜃 代表随机参数(回归模型中的 uranium_weight、county_floor_weight, 和 county_effect),ω 代表确定性参数(floor_weight、log_radon_scale、county_effect_scale 和 bias)。x𝑖 为特征(log_uranium、floor_of_house 和 floor_by_county);𝑦𝑖 为目标值 (log_radon),𝑖 = 1...n 个观测数据点:
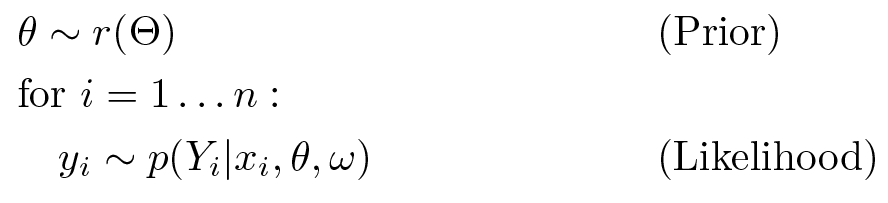
VI 的特征为:
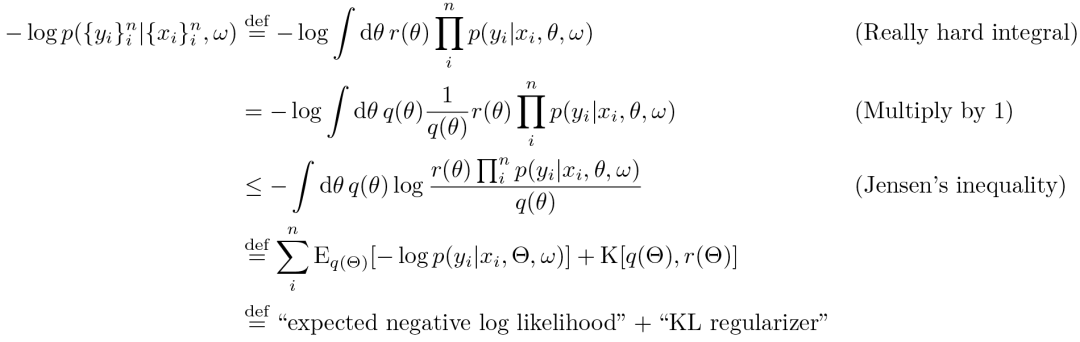
(从技术上看,我们假设 q 相对于 r 是绝对连续的。另请参阅琴生不等式)
由于该约束对所有 q 都成立,显然最严格的是:
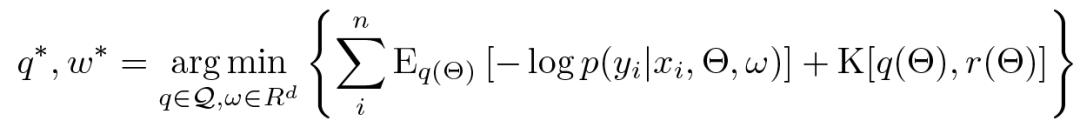
关于术语,我们称
-
q* 为“代理后验”,
-
Q 为“代理族”。
ω* 表示 VI 损失上确定性参数的最大似然值。有关变分推断的更多信息,请参见此调研。
-
调研
https://arxiv.org/abs/1601.00670
表达性代理后验
接下来我们用 VI 估计参数的后验分布,有两种不同类型的代理后验:
-
受约束的多元正态分布,其协方差结构由分块矩阵变换诱导。
-
由逆自回归流变换的多元标准正态分布,随后进行拆分和重构以匹配后验的支持。
多元正态代理后验
为了构建该代理后验,使用可训练的线性算子诱导后验分量之间的相关性。
首先构建一个具有向量值的标准正态分量的基础分布,其大小等于相应的先验分量的大小。这些分量具有向量值,因此可以被线性算子变换。
flat_event_size = tf.nest.map_structure(
tf.reduce_prod,
tf.nest.flatten(target_model.event_shape_tensor()))
base_standard_dist = tfd.JointDistributionSequential(
[tfd.Sample(tfd.Normal(loc=0., scale=1.), s)
for s in flat_event_size])
对此分布应用可训练的分块下三角线性算子诱导后验的相关性。在线性算子中,可训练的全矩阵块代表后验两个分量之间的全协方差,而零(或 None)的块表示独立性。对角线上的块是下三角矩阵或对角线矩阵,因此整个块结构代表下三角矩阵。
将此双射器应用于基础分布会导致均值为 0、(Cholesky 分解的)协方差等于下三角块矩阵的多元正态分布。
operators = (
(tf.linalg.LinearOperatorDiag,), # Variance of uranium weight (scalar).
(tf.linalg.LinearOperatorFullMatrix, # Covariance between uranium and floor-by-county weights.
tf.linalg.LinearOperatorDiag), # Variance of floor-by-county weight (scalar).
(None, # Independence between uranium weight and county effects.
None, # Independence between floor-by-county and county effects.
tf.linalg.LinearOperatorDiag) # Independence among the 85 county effects.
)
block_tril_linop = (
tfp.experimental.vi.util.build_trainable_linear_operator_block(
operators, flat_event_size))
scale_bijector = tfb.ScaleMatvecLinearOperatorBlock(block_tril_linop)
最后,应用可训练的 Shift 双射器允许平均值取非零值。
loc_bijector = tfb.JointMap(
tf.nest.map_structure(
lambda s: tfb.Shift(
tf.Variable(tf.random.uniform(
(s,), minval=-2., maxval=2., dtype=tf.float32))),
flat_event_size))
以比例尺和位置双射器对标准正态分布进行变换所得的多元正态分布必须进行重塑和重构才能匹配先验,并最终制约于先验的支持。
reshape_bijector = tfb.JointMap(
tf.nest.map_structure(tfb.Reshape, flat_event_shape))
unflatten_bijector = tfb.Restructure(
tf.nest.pack_sequence_as(
event_shape, range(len(flat_event_shape))))
event_space_bijector = target_model.experimental_default_event_space_bijector()
接下来将其整合 - 将可训练的双射器链接在一起,并应用于基础标准正态分布以构建代理后验。
surrogate_posterior = tfd.TransformedDistribution(
base_standard_dist,
bijector = tfb.Chain([ # Chained bijectors are applied in reverse order.
event_space_bijector, # Constrain to the support of the prior.
unflatten_bijector, # Pack components into the event_shape structure.
reshape_bijector, # Reshape the vector-valued components.
loc_bijector, # Allow for nonzero mean.
scale_bijector # Apply the block matrix transformation.
]))
训练多元正态代理后验。
optimizer = tf.optimizers.Adam(learning_rate=1e-2)
@tf.function(jit_compile=True)
def run_vi():
return tfp.vi.fit_surrogate_posterior(
target_model.unnormalized_log_prob,
surrogate_posterior,
optimizer=optimizer,
num_steps=10**4,
sample_size=16)
mvn_loss = run_vi()
mvn_samples = surrogate_posterior.sample(1000)
由于训练后的代理后验是 TFP 分布,因此我们可以从中获取样本并进行处理,得出参数的后验可信区间。
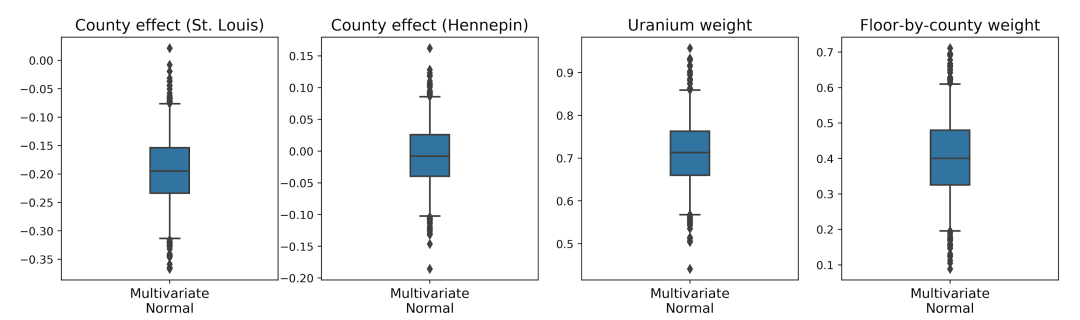
以下箱须图显示了两个最大县的县效应的 50% 和 95% 可信区间,以及各个县对土壤铀测量值和平均楼层的回归权重。县效应的后验可信区间表明,在考虑其他变量之后,圣路易斯县的地理位置与较低的氡水平相关,亨内平县的地理位置效应接近中性。
回归权重的后验可信区间表明,较高的土壤铀水平与较高的氡水平相关,在较高楼层进行测量的县(很可能是因为房屋没有地下室)往往有较高的氡水平,这可能与土壤特性及其对建筑结构类型的影响有关。
楼层的(确定性)系数为 -0.7,表明较低楼层的氡水平较高,符合预期。
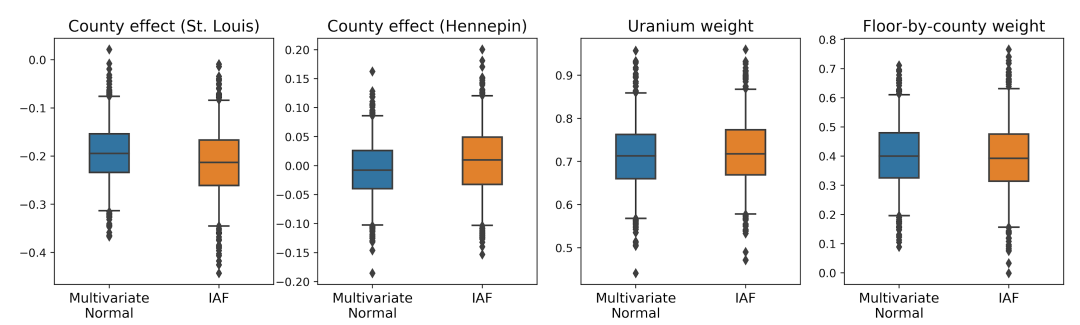
逆自回归流代理后验
逆自回归流 (IAF) 是一种正态化流,使用神经网络捕获分布中各分量之间复杂的非线性依赖关系。接下来,我们构建 IAF 代理后验,探明此容量更大、更灵活的模型是否优于受约束的多元正态。
首先建立具有矢量事件形状的标准正态分布,其长度等于后验自由度的总数。
base_distribution = tfd.Sample(
tfd.Normal(loc=0., scale=1.),
sample_shape=[tf.reduce_sum(flat_event_size)])
可训练的 IAF 变换正态分布。
num_iafs = 2
iaf_bijectors = [
tfb.Invert(tfb.MaskedAutoregressiveFlow(
shift_and_log_scale_fn=tfb.AutoregressiveNetwork(
params=2,
hidden_units=[256, 256],
activation='relu')))
for _ in range(num_iafs)
]
IAF 双射器与其他双射器链接,建立具有与先验相同的事件形状和支持的代理后验。
iaf_surrogate_posterior = tfd.TransformedDistribution(
base_distribution,
bijector=tfb.Chain([
event_space_bijector, # Constrain to the support of the prior.
unflatten_bijector, # Pack components into the event_shape structure.
reshape_bijector, # Reshape the vector-valued components.
tfb.Split(flat_event_size), # Split into parts, same size as prior.
] + iaf_bijectors)) # Apply a flow model.
与多元正态代理后验相同,IAF 代理后验也使用 tfp.vi.fit_surrogate_posterior 训练。IAF 代理后验的可信区间与受约束的多元正态的可信区间相似。
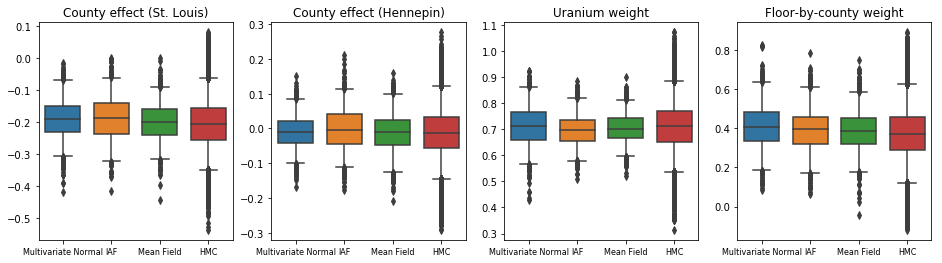
均值场代理后验
VI 代理后验通常被假定为均值场(独立)正态分布,具有可训练的均值和方差,通过双射变换约束到先验支持。除了两个更具表达性的代理后验之外,我们还使用一个与多元正态代理后验相同的通用公式来定义均值场代理后验。我们不使用分块下三角线性算子,而是使用分块对角线性算子,其中每个块都是对角线的:
operators = (
tf.linalg.LinearOperatorDiag,
tf.linalg.LinearOperatorDiag,
tf.linalg.LinearOperatorDiag,
)
block_diag_linop = (
tfp.experimental.vi.util.build_trainable_linear_operator_block(
operators, flat_event_size))
在这种情况下,均值场代理后验给出了与更具表达性的代理后验相似的结果,表明这种更简单的模型可能足以完成推断任务。作为“基本事实”,我们还使用汉密尔顿蒙特卡洛算法采样(有关完整示例,请参见 Colab)。这三个代理后验产生的可信区间在视觉上均与 HMC 样本相似,尽管有时由于 ELBO 损失的影响而分散不足,这常见于 VI。
-
Colab
https://colab.research.google.com/github/tensorflow/probability/blob/master/tensorflow_probability/examples/jupyter_notebooks/Variational_Inference_and_Joint_Distributions.ipynb
结论
在这篇文章中,我们使用联合分布和多部分双射器构建了 VI 代理后验,并将其拟合以估计氡数据集回归模型中权重的可信区间。对于此简单模型,更具表达性的代理后验的表现似乎与均值场代理后验相似。不过我们展示的工具可构建各种灵活的代理后验,适用于更复杂的模型。
前往 TFP 首页查看我们的代码、文档和更多示例。
-
TFP 首页
https://tensorflow.google.cn/probability/
想了解 TensorFlow 更多实用工具,请点击下方链接,前往 TensorFlow 官网。在机器学习的道路上,我们共同进步。
https://tensorflow.google.cn