文章列表
Kafka的灵魂伴侣Logi-KafkaManger一之集群的接入及相关概念讲解
Kafka的灵魂伴侣Logi-KafkaManger二之kafka针对Topic粒度的配额管理(限流)
文章目录
- 运维管控
- 接入集群
- 物理集群列表
- 集群概览
- 实时流量
- 历史流量
- Broker 信息
- Leader Rebalance
- Broker详情
- 基本信息
- 监控信息
- Topic信息 (TODO 页面跳转)
- 磁盘信息 (TODO 页面跳转)
- partition信息
- Topic分析
- 消费者信息
- Region信息
- Region列表
- 逻辑集群信息
- 逻辑集群列表
- Controller信息
- 限流信息
- Finally 官方群
前面的文章简单介绍了如何接入集群,以及Topic的申请和配额申请,这个时候我们还不是很了解Logi-KafkaManager究竟有哪些优点,如何去管理众多的kafka集群;
运维管控
运维管控这个菜单栏目下面主要是供
运维人员来管理所有集群的;
接入集群
Kafka的灵魂伴侣Logi-KafkaManger一之集群的接入及相关概念讲解
物理集群列表

列出了所有物理集群,点击一个物理集群进去看详细信息;
如果没有信息请检查一下是否正确开启了JMX; ==> JMX-连接失败问题解决
集群概览
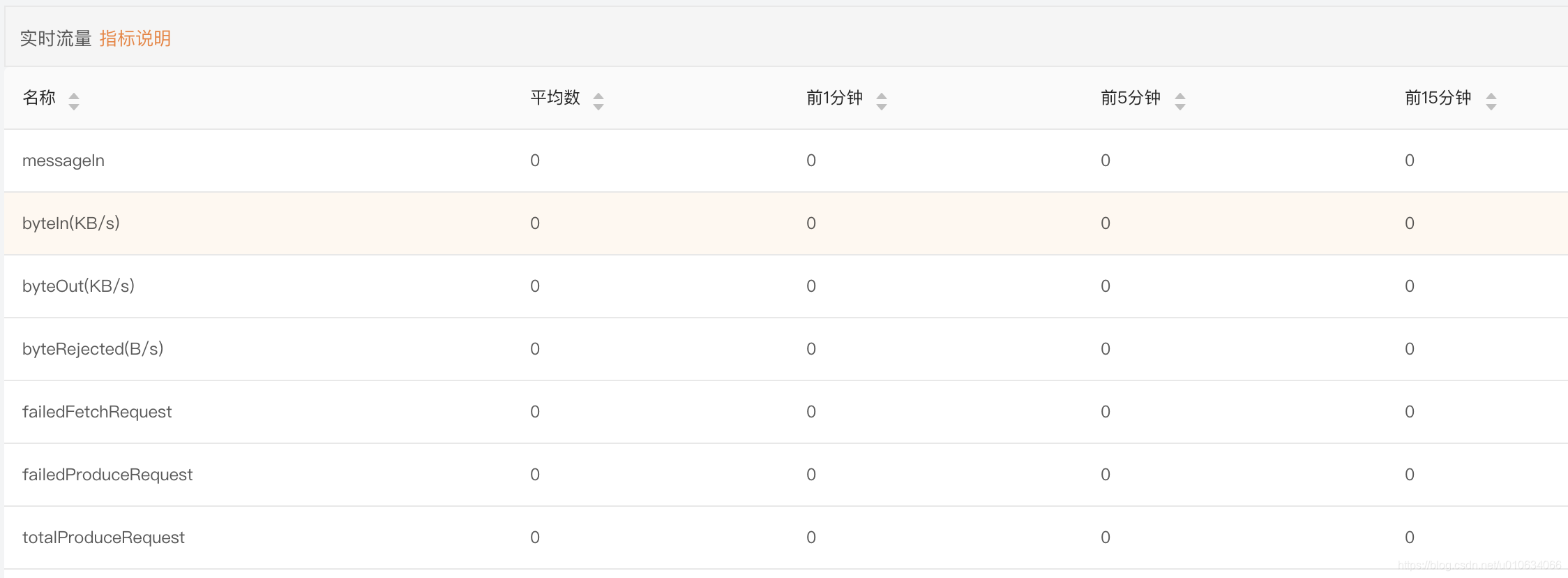
实时流量
指标说明

因为我发送和消费过消息, 为了不让之前的数据干扰; 我们重新把Broker重启一下,Jmx的数据就会清0了; 历史数据清楚就去数据库中把_metrics结尾的表数据全部清空;
执行下面的代码,验证一下实时流量的指标准不准确;
下面的代码表示的是: 60S秒发送60条消息; 每条消息大小1个字节; 但是在这60S内只发送一次消息; 因为将linger.ms=60000, 设置为60秒后发送;
那么期望中的实时指标是;
@Test
void contextLoads() {
Properties props = new Properties();
props.put("bootstrap.servers", "xxxxxxx");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384000);
props.put("linger.ms", 60000);
props.put("buffer.memory", 335544320);
props.put("client.id", "appId_000001_cn.Test2");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for(int i = 0; i < 60; i++){
//将一个消息设置大一点
byte[] log = new byte[1024];
String slog = new String(log);
producer.send(new ProducerRecord<String, String>("Test2",0, Integer.toString(i), slog));
}
try {
Thread.sleep(62000);
} catch (InterruptedException e) {
e.printStackTrace();
}
producer.close();
}
messagesIn:每秒发送到kafka的消息条数 = 1条
byteIn:每秒发送到kafka的字节数 = 1字节
totalProduceReques:每秒总共发送的请求数 = 1/60=0.017 这里是请求数量,因为60s内实际上只发送了一次请求;
执行代码然后看结果
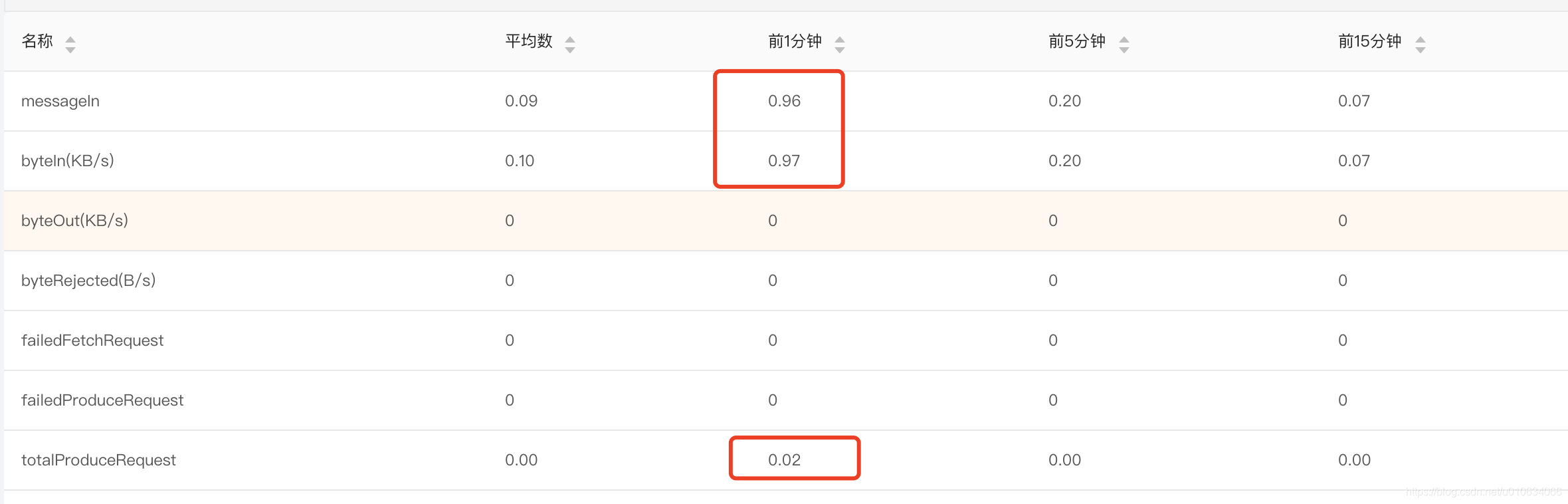
基本上是符合我们预期的,实时流量数据还是准确的;
除了上面几个指标,我们应该还要关注下面几个异常指标,正常情况下他们都是0; 如果不为0的情况说明可能就有异常了,运维同学就应该去查查异常日志了;
byteRejected(B/s) 每秒被拒绝的字节数
failedFetchRequest 每秒拉取失败的请求数
failedProduceRequest 每秒发送失败的请求数
messageIn/totalProduceRequest 消息条数/总请求数 也可以关注一下; 假如他们的结果=1; 说明没有批量发送,一条消息就发送了一个请求了
历史流量
指标说明
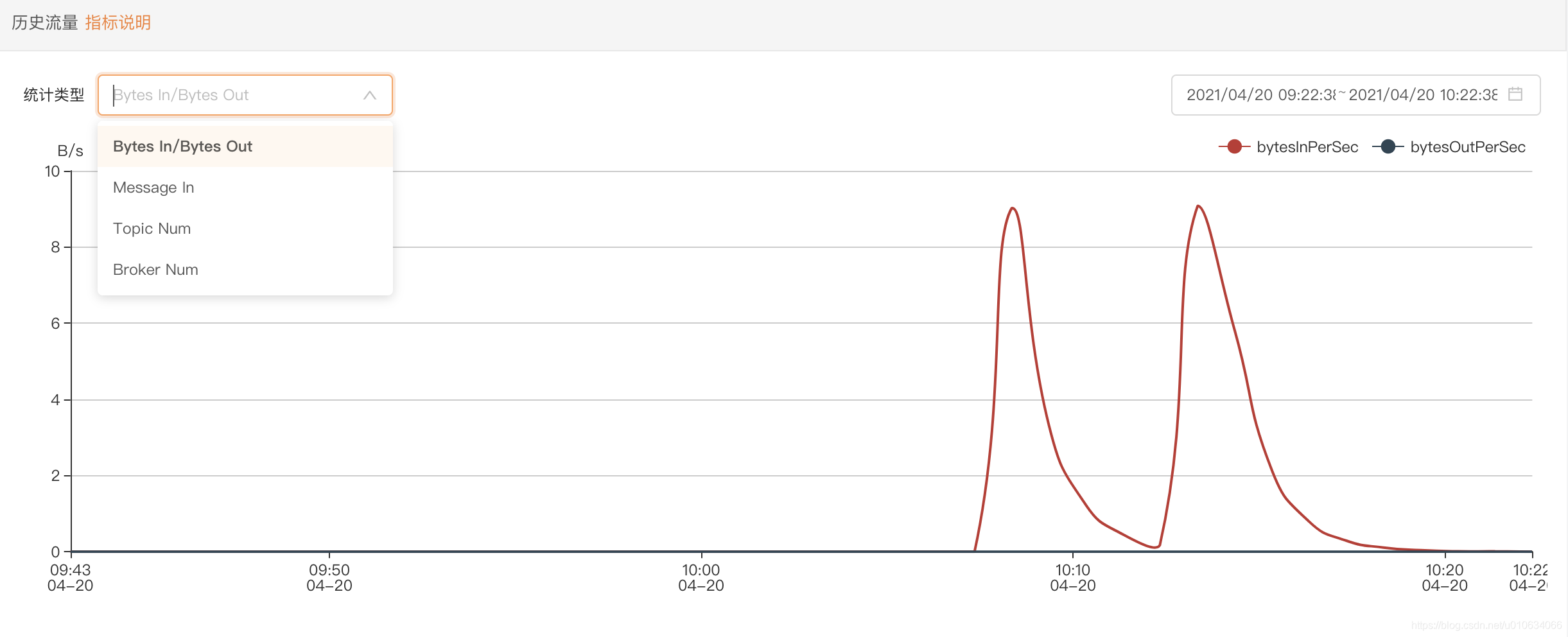
历史数据都存放在_metrics结尾的表中;
Broker 信息
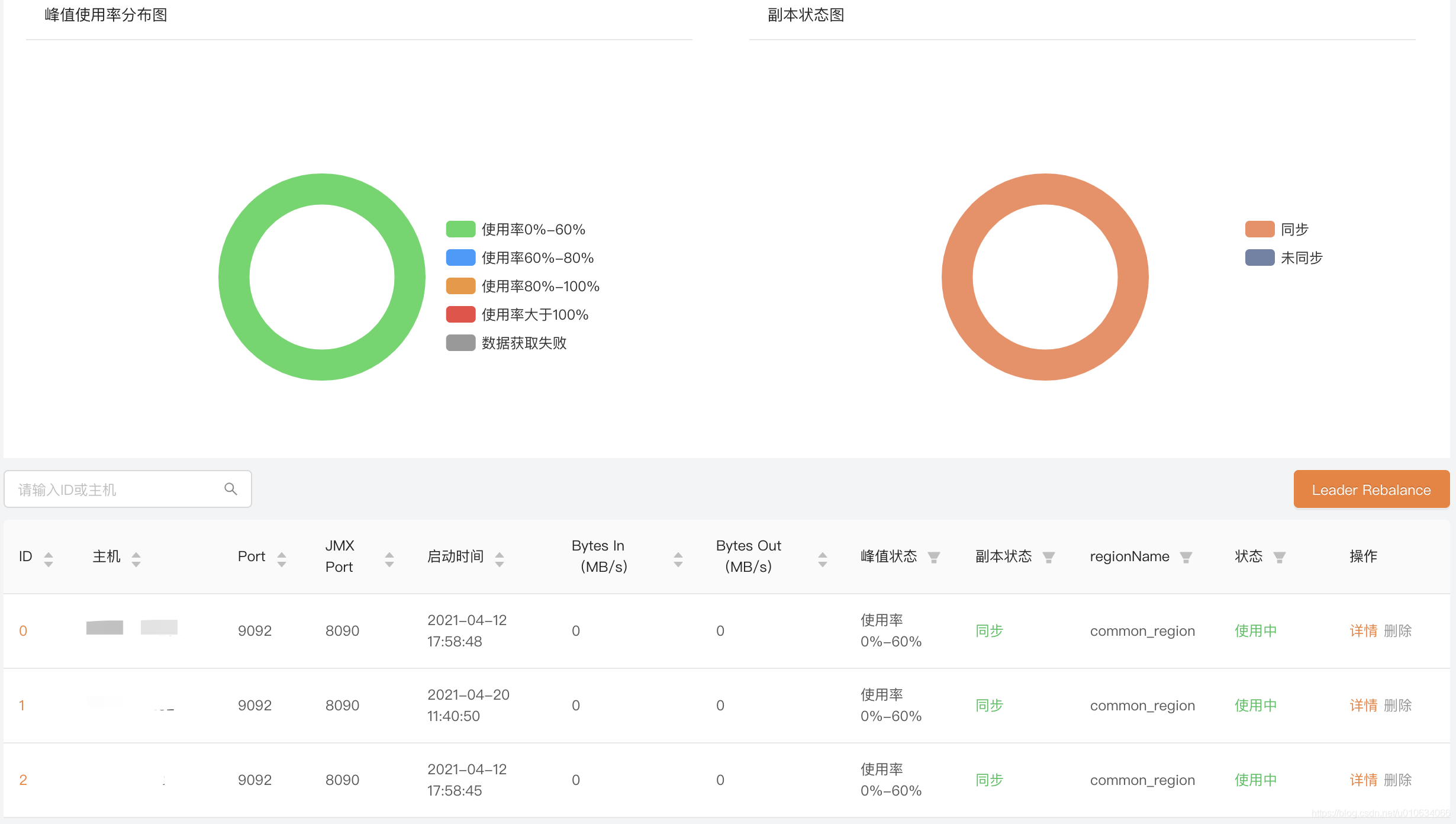
上面左边部分是对所有Broker峰值使用率的看板, 可以通过这个图简单了解一下Broker的峰值情况, 那么这个使用率是怎么计算的,计算的到底准不准确,得需要去源码里面看看, 这个图我们可以作为一个参考值来了解;
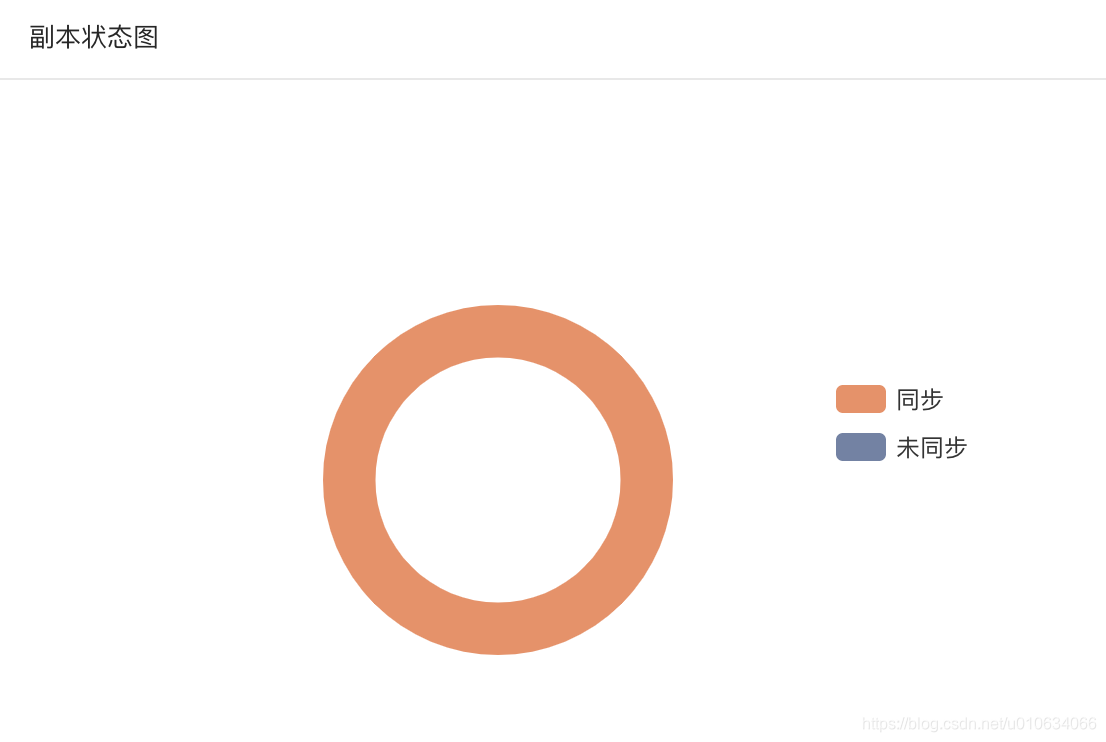
副本状态图, 可以理解为在 ISR中的是同步;不在ISR中的是未同步;
我们现在把其中一台Broker 1 关机 模拟Broker宕机等异常情况; 可以看到变成了下面这样子;
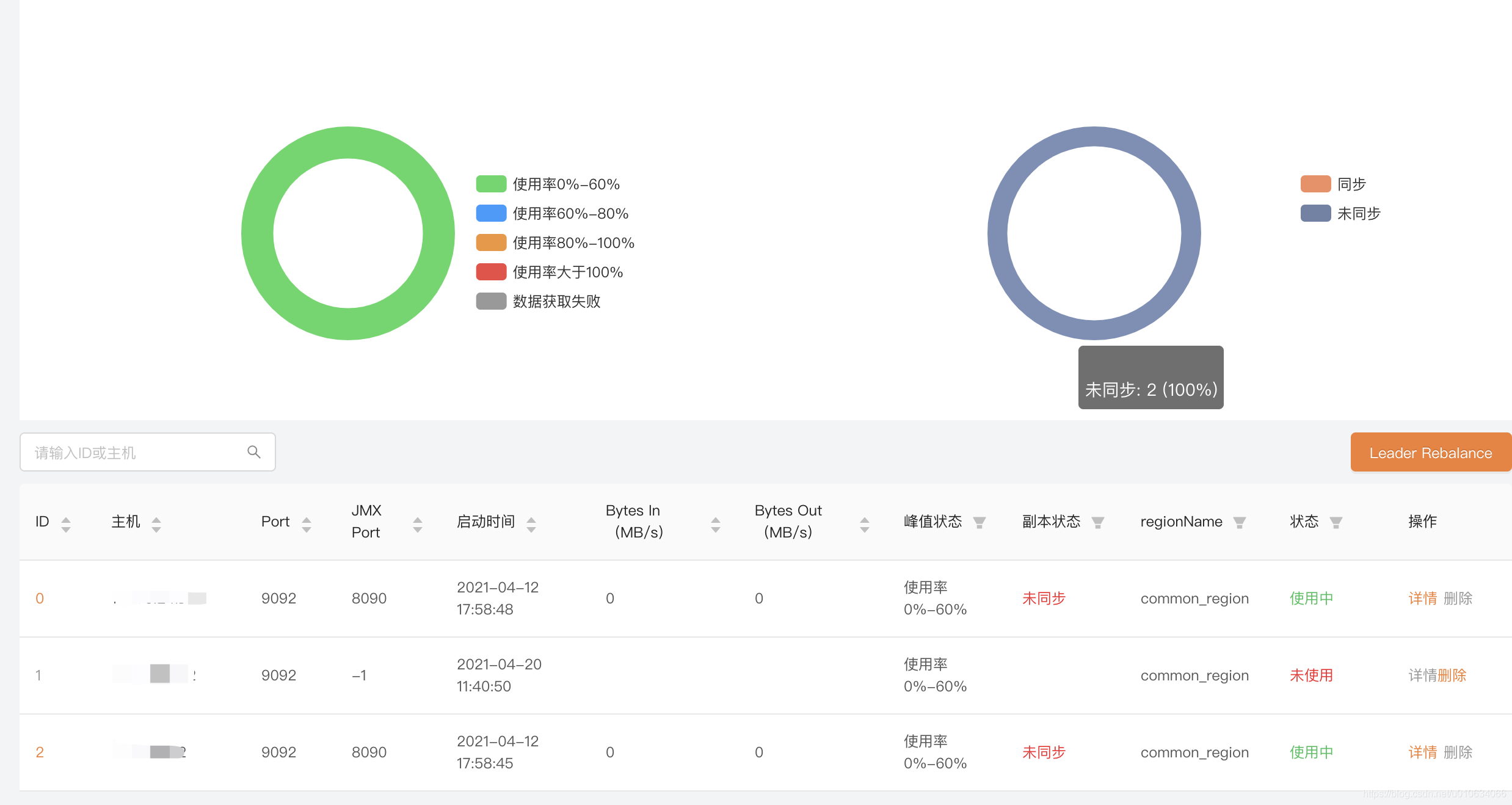
图中可以看到, 1的状态为未使用, 0,2 两台broker的副本状态都变成了未同步 ;
副本状态:
失效副本分区的个数 大于0 则这个副本状态就展示 未同步 ; 失效副本分区的个数UnderReplicatedPartitions 是通过JMX访问kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions获取到的值;如果获取的UnderReplicatedPartitions值大于0,有可能是某个Broker的问题,也有可能引申到整个集群的问题,也许还要引入其他一些信息、指标等配合找出问题之所在。
注意:如果Kafka集群正在做分区迁移(kafka-reassign-partitions.sh)的时候,这个值也会大于0。
更多关于失效副本分区数异常问题排查请看 失效副本的诊断及预警
理解了副本状态的意思,那上图我们就可以理解了; 之所以Broker[0,2] 都显示未同步,是因为 Broker 2中含有[0,2]的副本; Broker2宕机了,失效副本分区的个数就大于0了
删除操作:
当Broker下线的时候,可以执行删除操作, 一般是当你把这个Broker移除集群的时候你就可以去删除掉他, 不过删除之后,如果重新加入到集群还是会被添加回来的; 如果仅仅只是Broker宕机就不要删除了;
Leader Rebalance
想要知道这个功能用来干什么, 那么我们得先了解一个概念 leader 均衡机制;
Leader 均衡机制(auto.leader.rebalance.enable=true)
当一个broker停止或者crashes时,所有本来将它作为leader的分区将会把leader转移到其他broker上去,极端情况下,会导致同一个leader管理多个分区,导致负载不均衡,同时当这个broker重启时,如果这个broker不再是任何分区的leader,kafka的client也不会从这个broker来读取消息,从而导致资源的浪费。
kafka中有一个被称为
优先副本(preferred replicas)的概念。如果一个分区有3个副本,且这3个副本的优先级别分别为0,1,2,根据优先副本的概念,0会作为leader 。当0节点的broker挂掉时,会启动1这个节点broker当做leader。当0节点的broker再次启动后,会自动恢复为此partition的leader。不会导致负载不均衡和资源浪费,这就是leader的均衡机制
在配置文件conf/ server.properties中配置开启(默认就是开启)auto.leader.rebalance.enable = true
与其相关的配置还有
leader.imbalance.check.interval.seconds partition 检查重新 rebalance 的周期时间 ; 默认300秒;
leader.imbalance.per.broker.percentage 标识每个 Broker 失去平衡的比率,如果超过改比率,则执行重新选举 Broker 的 leader;默认比例是10%;
上面几个配置都是 && 的关系; 同时满足才能触发再平衡;
调优建议:考虑到leader重选举的代价比较大,可能会带来性能影响,也可能会引发客户端的阻塞,生产环境建议设置为false。或者周期设置长一点,比如一天一次;
那么如果我们关闭了 均衡机制 , 或者周期时间比较长, 也就有可能造成上面说的问题, 那么Kafka-manager就提供了一个手动再平衡的操作;
假如有一台Broker宕机了, 等它重启之后, 并且等它副本同步完成之后(为了副本同步与再平衡错开一下), 运维管理人员 就可以操作一下这个 Leader Rebalance ;手动触发一下再平衡;
举个栗子🌰
- 首先将broker的自动均衡关闭
auto.leader.rebalance.enable = false; 并且逐个重启 - 查看一下某个Topic在各个broker的 Leader分布情况 ;
我们这里看看TEST3这个TOPIC的情况;
Broker-0
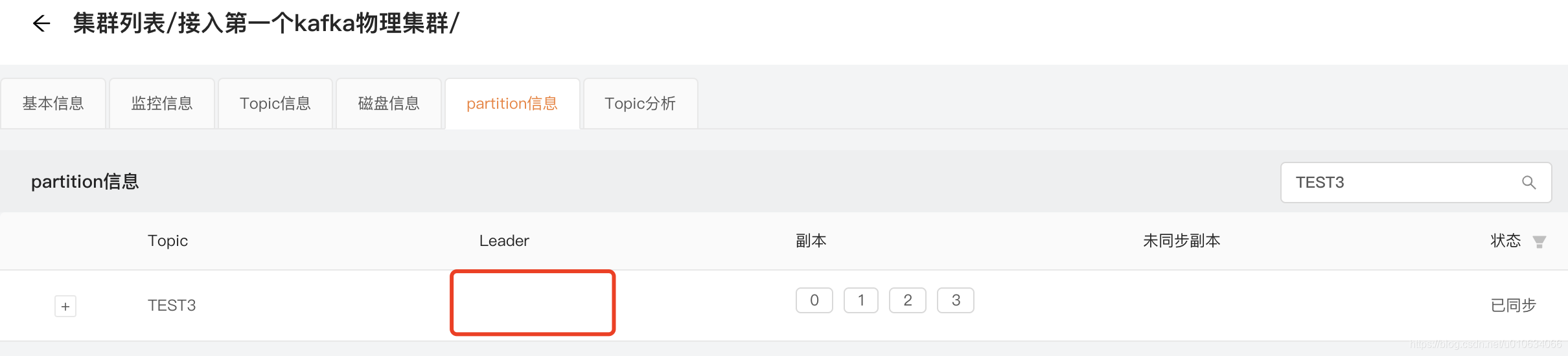
Broker-1
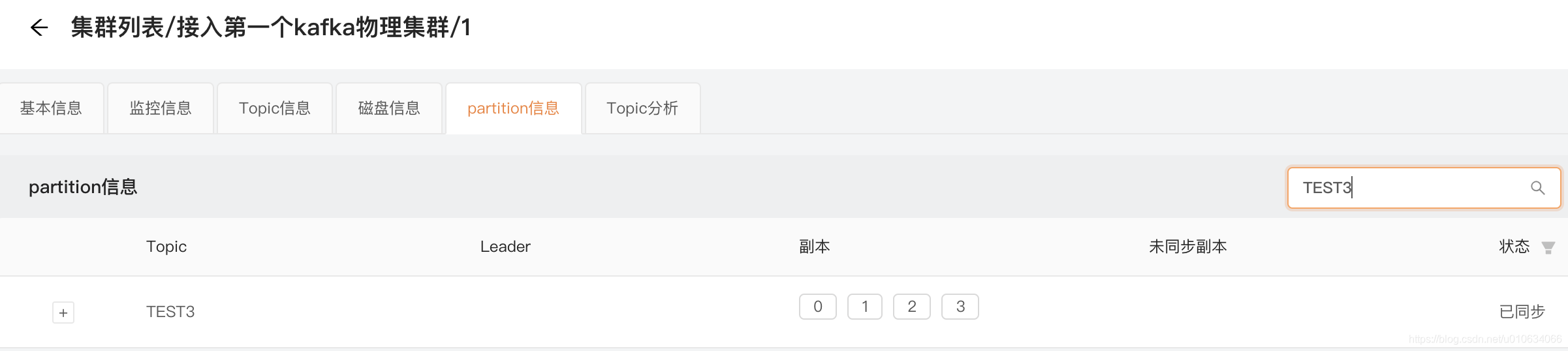
Broker-2
在逐个启动完成的时候 他们的Leader分布情况如下;
| Broker | Leader |
|---|---|
| 0 | |
| 1 | |
| 2 | 0,1,2,3 |
因为Broker-2是我启的第一台; 所以所有分区的Leader都集中在这一台机器上; 而后面启动的Broker都没有分配到Leader;
这样的情况明显不合理; 所以我们需要执行一次 再均衡;
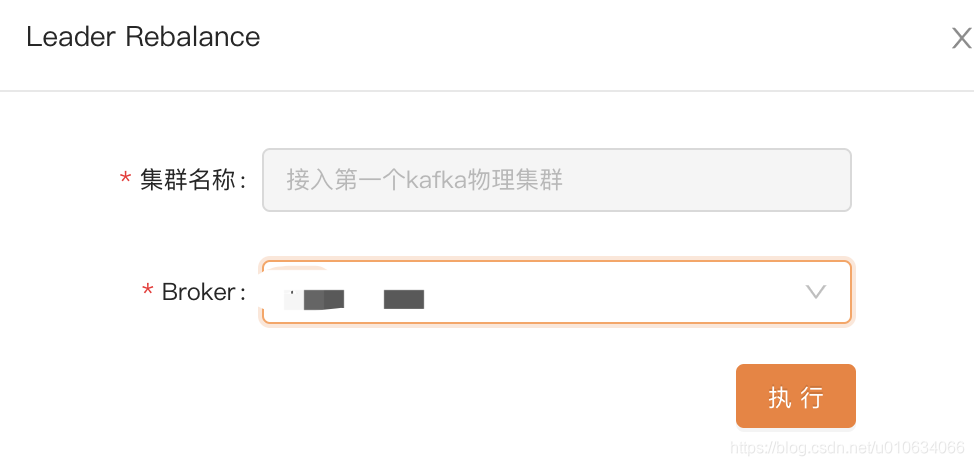
- 手动执行 再均衡策略;下拉选中的Broker; 这里选择Broker的作用是选择这台Broker上的所有Topic来进行再均衡
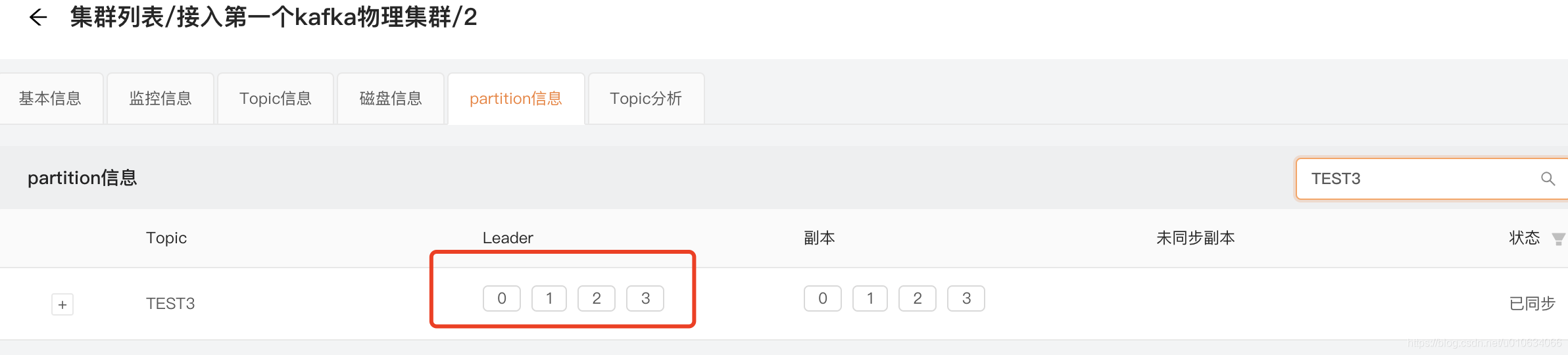
再均衡之后再看看Leader情况
| Broker | Leader |
|---|---|
| 0 | 2,3 |
| 1 | 0 |
| 2 | 1 |
可以看到均衡之后的结果,Broker-0 分配了2个Leader ; 自动恢复到了之前的分配情况;
PS: Leader Rebalance 时候选择的Broker的作用是针对该Broker下面的所有Topic来进行再均衡; 假如你3台Broker上的Topic都一样,那选哪个Broker都一样
Broker详情
基本信息
展示了当前Broker的基本信息和 实时流量 历史流量 ; 注意 这里的流量信息展示的是当前这一台Broker的流量; 集群概览那里展示的是整个物理集群的所有流量信息(Brokers之和);
监控信息
按照时间轴展示多个指标信息,当然指标也是当前选中的Broker的指标信息;
Topic信息 (TODO 页面跳转)
展示当前Broker下有哪些Topic; 更为详细的介绍情况 TODO…
磁盘信息 (TODO 页面跳转)
展示当前Broker的一些磁盘信息; 但是此功能 需要 接入 滴滴的 kafka-gatway 组件才可以生效; 目前该组件为企业服务,暂未有开源计划; 更为详细的介绍请看 TODO…
partition信息
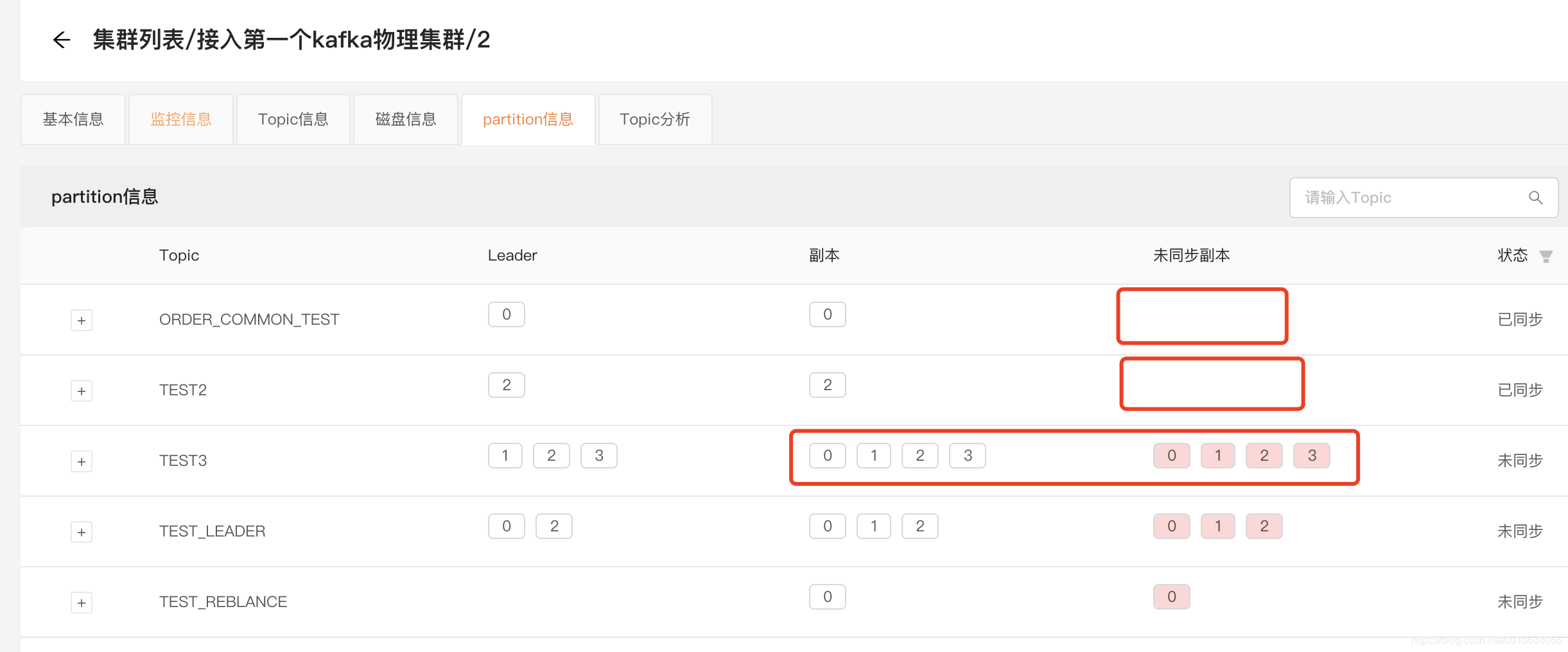
展示当前Broker的partition信息, 列出当前Broker所有Topic的 Leader 和副本 以及未同步副本 情况;
在上面的 Leader Rebalance 模块中,其实已经说明讲解了一部分这里的信息情况;
例如Broker-0宕机了,可以看到那些在Broker-0中存在对应副本的Topic, 清晰的展示了哪些副本是没有同步的; 像下面的TEST2在Broker-0中不含有副本,所有它的状态是 已同步;
Topic分析
当前Broker的Topic基本信息,其实这里的信息在 最左边的基本信息里面有了
不过这里展示的是最近一分钟的数据,而且把所有Topic的数据列出来展示对比;
我们模拟一下批量发送消息,给TEST2 TEST3的TOPIC发个1万条消息
bin/kafka-producer-perf-test.sh --topic TEST3 --num-records 10000 --record-size 100 --throughput 100 --producer-props bootstrap.servers=xxx:9092,xxx:9092,xxx:9092
bin/kafka-producer-perf-test.sh --topic TEST2 --num-records 10000 --record-size 100 --throughput 100 --producer-props bootstrap.servers=xxx:9092,xxx:9092,xxx:9092
看看展示的数据
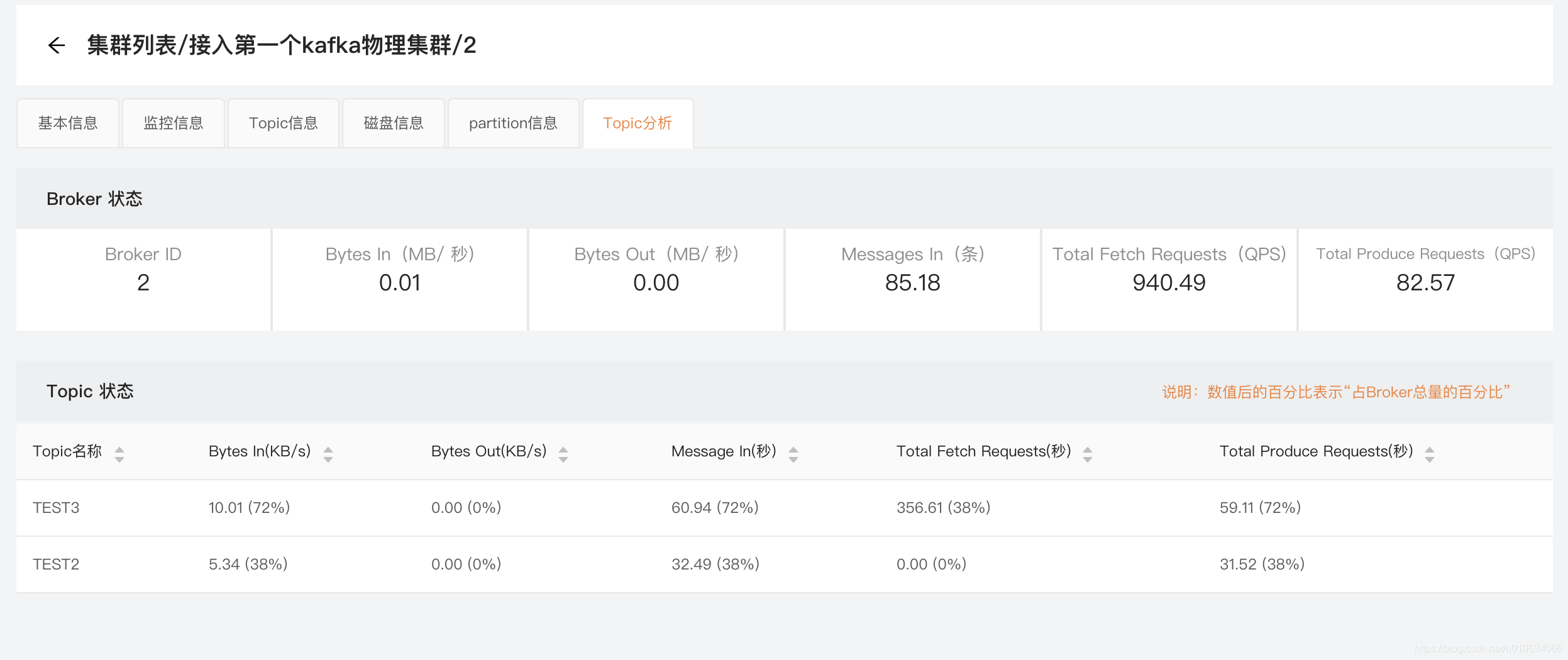
通过这个数据可以看到当前Broker下最近一分钟的Topic活动状态; 可以看到哪个Topic比较活跃; 图中的百分比应该算的有问题,去提一个BUG;
消费者信息
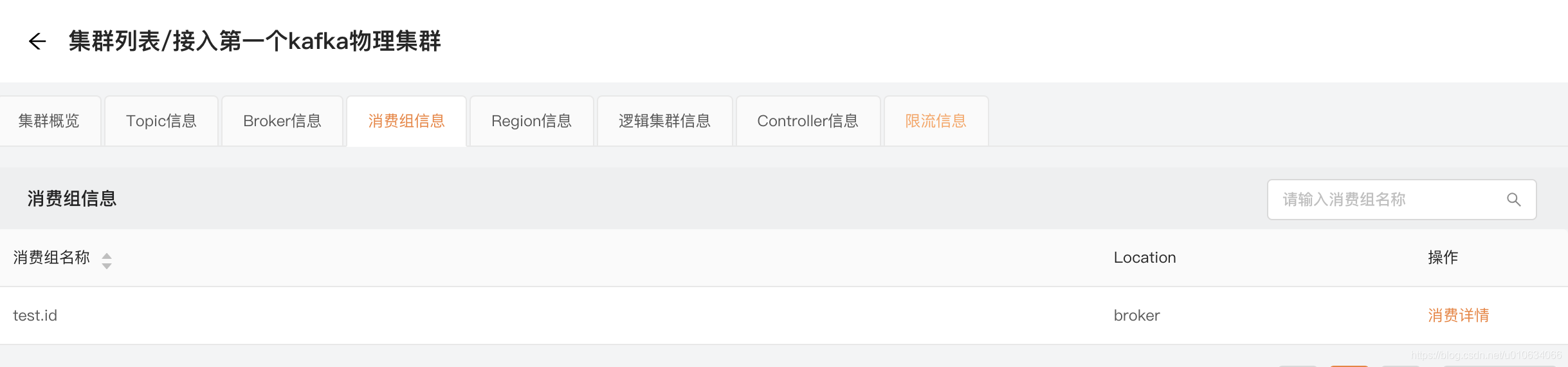
展示当前Broker下的所有消费组信息, Location 表示数据是从Broker上获取的(老版本存放在ZK中); 注意刚启动的时候这里可能为空,一分钟之后执行获取Consumer的任务才会获取到
Region信息
Region列表
展示的是当前物理集群下划分的所有Region;
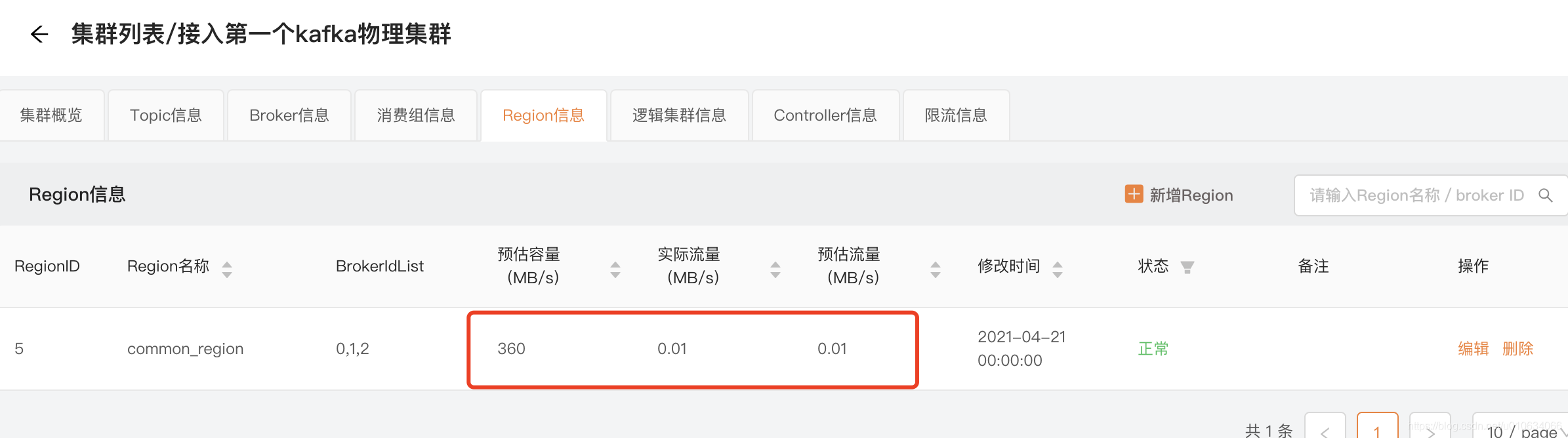
我们主要看上面的几个参数
预估容量: 很多人对这个数值比较疑惑, 也不知道怎来的; 我们找找源码就知道它是怎么来的了;
此数值计算的是 当前Region下面能够承受的最大流量值 ;比如上面的表示最大支持 360M/s; 但是这个值其实是一个非常模糊的预估值,是需要运维管理人员 去设置的,如果没有设置默认的就是每台Broker 最大流量值是 120M/s;
运维管理人员 需要对自己的Broker能够承受的峰值流量有个数; 然后设置完成可以直观的了解到此Region是否能够承受住峰值流量;
实际流量: 从历史数据中计算一下实际的峰值流量;
预估流量: 实际流量+ 新申请的Topic的预估流量;
解释一下; 我们新申请的Topic,这个时候还没有流量进来, 但是我们要给这个新申请的Topic预留一个Buffer; 我们在申请Topic的时候不是有让填写一个预估峰值流量么;
但是当前代码里面实际流量=预估流量; 待优化
那么如何修改Broker能够承受的峰值流量呢?
点击 运维管控 ->平台管理->平台配置 填写如下信息
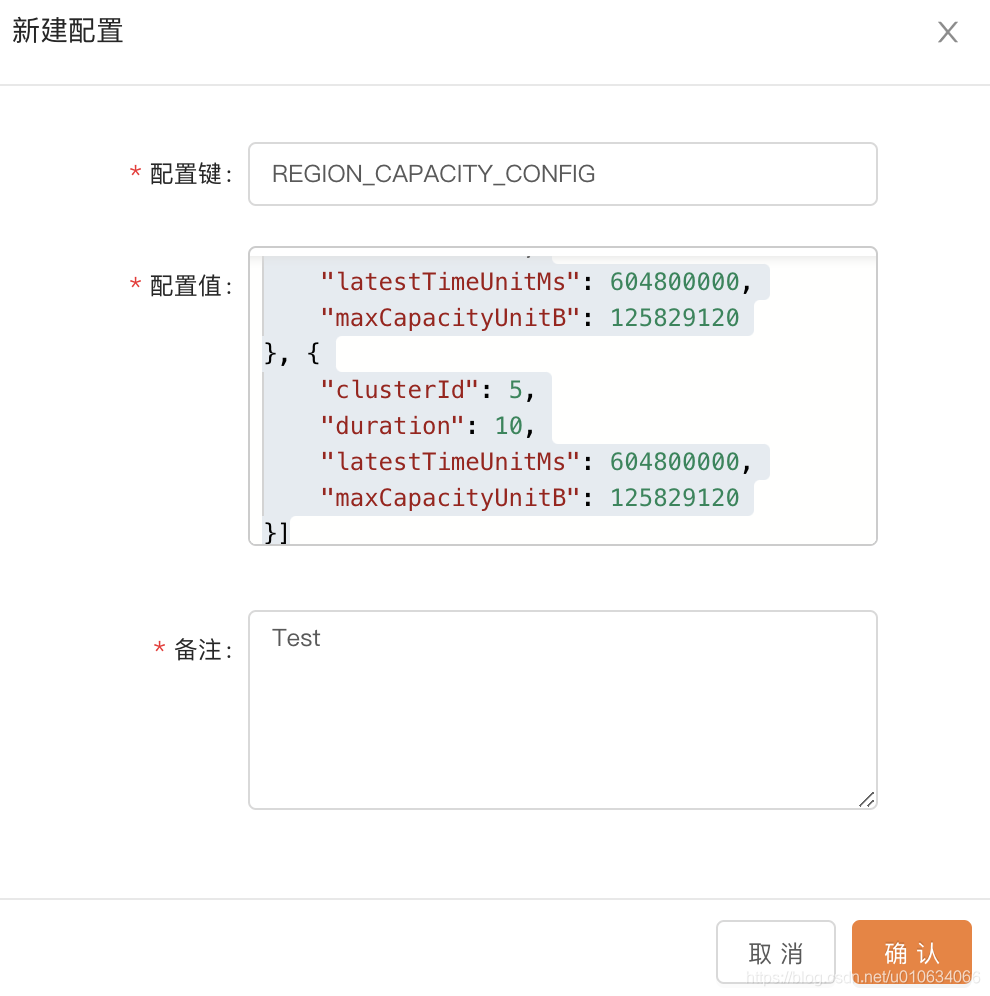
配制键: REGION_CAPACITY_CONFIG
配置值Json串; 它是一个array
[{
"clusterId": 4, //物理集群的ID
"duration": 10, //持续时间,为了最大值最小值对实际流量产生的紊乱,才有这么一个值,具体含义就不分析了,默认值就是10
"latestTimeUnitMs": 604800000,// 表示计算的是最近多少天内的数据;比如这个默认值是7天;7 * 24 * 60 * 60 * 1000L
"maxCapacityUnitB": 125829120 //预估容量;默认值是120 * 1024 * 1024 ;也就是120M; 针对的是单台Broker
}, {
"clusterId": 5,
"duration": 10,
"latestTimeUnitMs": 604800000,
"maxCapacityUnitB": 125829120
}]
PS: 上面的配置每个都是针对物理集群下面的所有Broker; 比如我设置的clusterId=4的物理集群的maxCapacityUnitB=125829120;(120M),那么这个物理集群下面的所有Region下面的Broker;给的预估容量都是120M
上面的计算是每隔12小时才会计算一次;
针对这一块,后续社区应该会做优化改造,或者让预估容量可以自动计算 平台配置那里也不方便; 或者社区也会做修改
逻辑集群信息
逻辑集群列表
展示当前物理集群的所有逻辑集群信息;
创建逻辑集群讲解请看 【KafkaManager 二 】集群的接入及相关概念讲解
Controller信息
展示Controller的变更历史 和 设置候选Controller
关于Controller
控制器组件(Controller),是 Apache Kafka 的核心组件。它的主要作用是在 Apache ZooKeeper 的帮助下管理和协调整个 Kafka 集群。集群中任意一台 Broker 都能充当控制器的角色,但是,在运行过程中,只能有一个 Broker 成为控制器,行使其管理和协调的职责
更为详细内容请参考Kafka的Controller Broker是什么
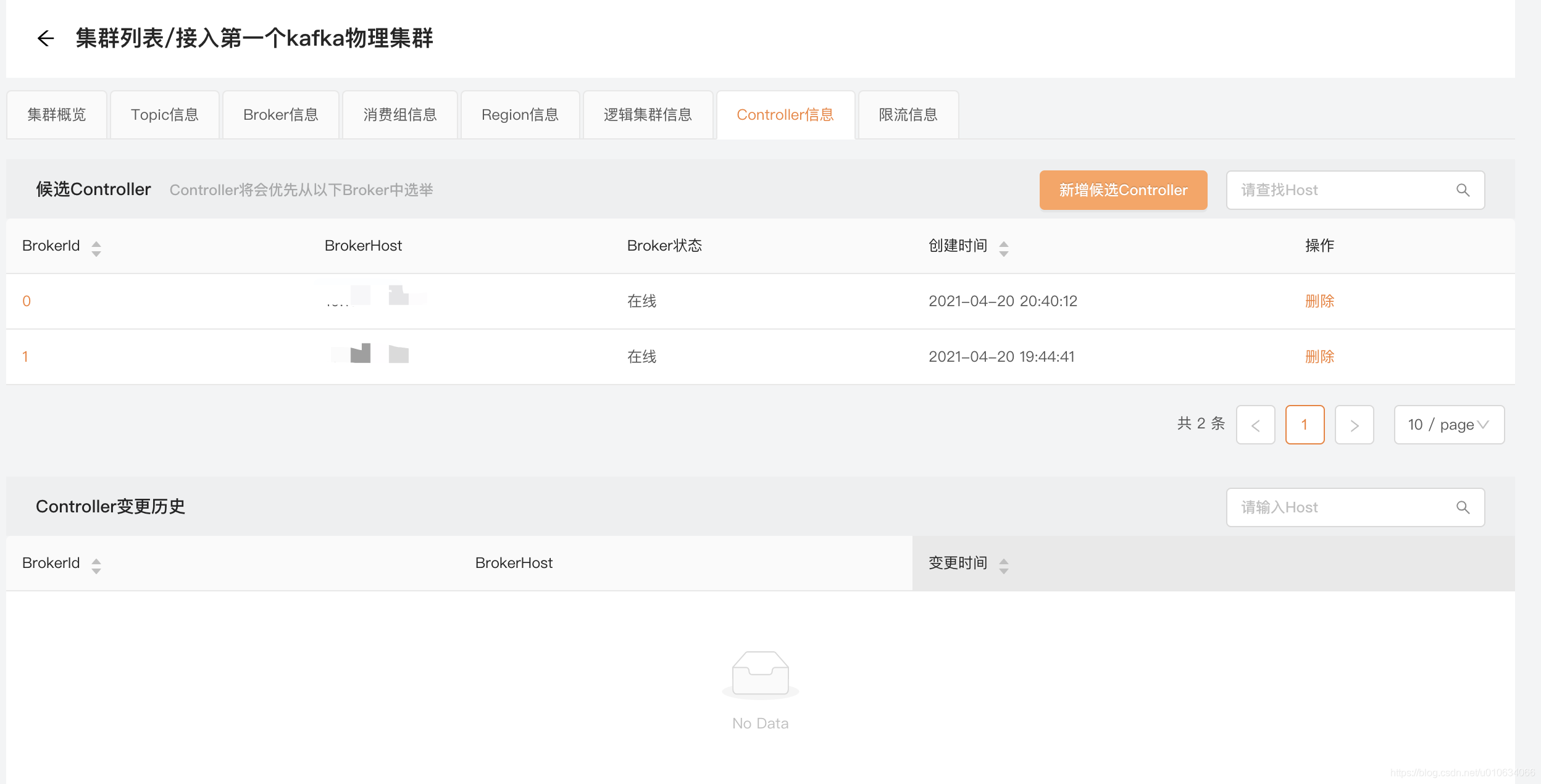
设置了候选Controller之后 : Controller将会优先从选中的Broker中选举 ; 这个功能使用的场景可能是
你知道哪几台Broker比较空闲 , 想让他们承担Controller的责任;
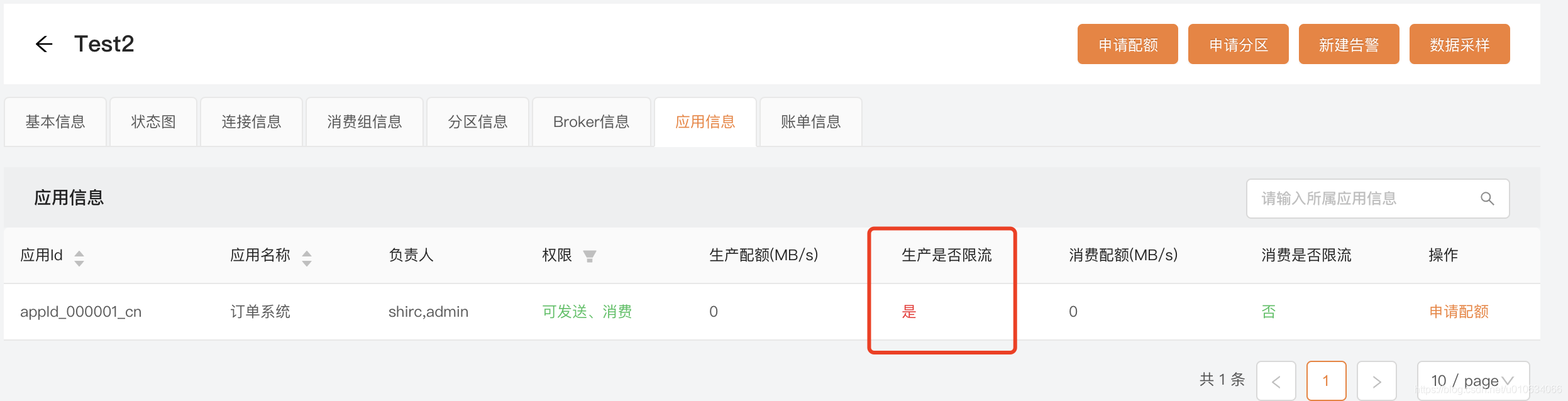
限流信息
这里展示的是当前物理集群中此时此刻正在被限流的所有Topic信息;
还记得我们上一篇文章有也有讲过限流的相关么 【KafkaManager 三】kafka针对Topic粒度的配额管理(限流)
那里是查看当前的Topic是否被限流了
关于kafka的配额限流 kafka中的配额管理(限速)机制
那么我们这里的限流信息怎么看呢?什么时候出来呢?
那我们来制造一个Producer发生限流的场景;
1.设置一个限流配置
// 添加限流信息
sh bin/kafka-configs.sh --bootstrap-server broker1:9092 --alter --add-config 'producer_byte_rate=100,consumer_byte_rate=100' --entity-type clients --entity-name appId_000001_cn.Test2
上面的命令的意思是 在broker1:9092上 添加一个针对客户端clientName = appId_000001_cn.Test2 加上一个限流配置;
生产者producer 的速率是100b/s ; 消费组consumer的速率是100b/s ;
不放心我们也可以去zk上看看是不是配置成功了

2.生产消息
@Test
void contextLoads() throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "broker1:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 110);
props.put("linger.ms", 0);
props.put("client.id", "appId_000001_cn.Test2");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for(int i = 0; i < 1000; i++){
//将一个消息设置大一点
byte[] log = new byte[100];
String slog = new String(log);
producer.send(new ProducerRecord<String, String>("Test2",0, Integer.toString(i), slog));
System.out.println("i="+i);
}
try {
Thread.sleep(62000);
} catch (InterruptedException e) {
e.printStackTrace();
}
producer.close();
}
上面的代码表示 每次发送100b的消息出去,并且是立即发送; 因为我们设置的限流速度 是100b/s; 那么妥妥的就被限流了嘛;
注意:客户端id设置的为 appId_000001_cn.Test2 ;跟我们上面针对的客户端限流名称一样才会生效;
执行代码之后我们再看看效果;
限流的Topic就展示出来了,当然这个展示的是当前限流的;等它不限流了 就会消息;
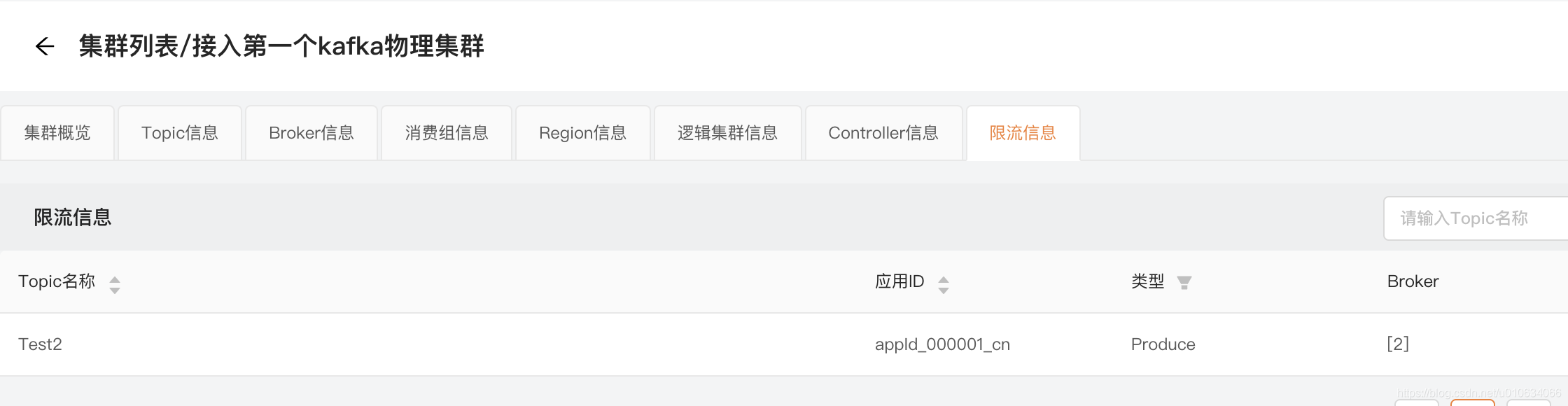
PS:这里有个要注意的地方就是,这里展示的是针对单个Topic的限流信息; 我们知道kafka当前是不支持针对Topic这一维度来进行限流配置的; 当然想要自己实现针对Topic限流也很简单,只需要让每个Topic的client.id不一样;然后针对每个topic的client.id做限流配置就行; 看上面我设置的客户端是 appId_000001_cn.Test2 这样的格式; 但是自己这样去做非常麻烦;不建议自己去做; 上篇文章有讲过 【KafkaManager 三】kafka针对Topic粒度的配额管理(限流)
如果只是开源版本的话 这一块功能还是用不上了(自己做麻烦主要是)
不过滴滴的kafka-gateway 是支持这个功能的; 但是kafka-gateway 是滴滴的商业服务,暂未开源; kafka-gateway 在原生的kafka上做了很多的增强; 想要使用kafka-gateway的开源联系滴滴官方
Finally 官方群
有疑问可以加官方开源群

