0、提纲:
运行环境部署Dify部署OllamaDify串联Ollama运行效果1、运行环境
CPU:12th Gen Intel(R) Core(TM) i9-12900K【16核24线程】GPU:NVIDIA GeForce RTX 3080 Ti【12G显存】内存:32G系统:Ubuntu 20.04.4 LTS2、部署Dify
参照Dify官方资料,选择本地源码启动(https://docs.dify.ai/v/zh-hans/getting-started/install-self-hosted/local-source-code),主体步骤如下:
2.1 克隆代码:
git clone https://github.com/langgenius/dify.git2.2 部署依赖组件
Docker部署 PostgresSQL / Redis / Weaviate:
cd dockercp middleware.env.example middleware.envdocker compose -f docker-compose.middleware.yaml up -ddocker ps查看是否都正常启动。如果遇到redis端口占用,可考虑先关闭系统的redis,启动docker的redis:
sudo service redis stop如果遇到部分未安装(比如weaviate、2024年4月11日福布斯全球网站发布的2023 AI 50 榜单中唯一开源向量数据库),可直接指定:
docker compose -f docker-compose.middleware.yaml up -d weaviate2.3 服务端部署运行
先安装Python 3.10、poetry。API 接口服务:python -Vcd apipoetry shellflask run --host 0.0.0.0 --port=5001 --debugcd apipoetry shellcelery -A app.celery worker -P gevent -c 1 -Q dataset,generation,mail,ops_trace --loglevel INFO2.4 前端页面部署运行
先安装Node.js v18.x stable版本。node -vcd webnpm run start如果遇到安装慢,可以安装pnpm,使用pnpm安装依赖包【亲测更快】:
npm install -g pnpmpnpm install2.5 访问方式
浏览器访问 http://127.0.0.1:3000 即可使用 Dify注册登录,在主页右上角折叠菜单中点击“设置”后可修改“语言”。
3、部署Ollama
Ollama是一个开源工具(Go语言开发),可以在本地运行大型语言模型,比如LLaMA3.1(可能是当前开源最好的)。用起来的感受是:使用快捷方便、运行稳定高效。
3.1 安装
curl -fsSL https://ollama.com/install.sh | sh安装成功,浏览器打开“http://localhost:11434/” 能看到“Ollama is running”。
3.2 运行安装时自带的模型llava
ollama run llava
3.3 查看下载其它模型
参看Ollama模型库(https://ollama.com/library/),搜索下载支持的模型(比如llama3.1、qwen2、nomic-embed-text)
ollama pull llama3.1ollama pull qwen2ollama pull nomic-embed-textollama list3.4 运行qwen2
可查看运行情况和显存消耗
ollama run qwen2ollama psnvidia-smi4、Dify串联Ollama
参考接入Ollama 部署的本地模型(https://docs.dify.ai/v/zh-hans/guides/model-configuration/ollama)执行以下操作:4.1 界面操作1
在浏览器Dify主页右上角折叠菜单中点击“设置”,弹框中左侧“模型供应商”里选择“Ollama”

4.2 界面操作2
点击“添加模型”,弹框中填写LLM和Text Embedding【用于知识检索】信息,其中“基础 URL”填写“http://[本地IP]:11434”。


5、运行效果
5.1 创建知识库
在浏览器Dify顶部选择“知识库”,点击“创建知识库”,按顺序操作:
1.选择数据源【导入已有文本、同步自Notion内容、同步自Web站点】2.文本分段与清洗【“Embedding 模型”选择前面用Ollama安装的nomic-embed-text,再选择“混合检索”】3.处理并完成【知识库命名】创建完毕,需进入该知识库“设置”页面,“Embedding 模型”选择“nomic-embed-text”,然后保存。
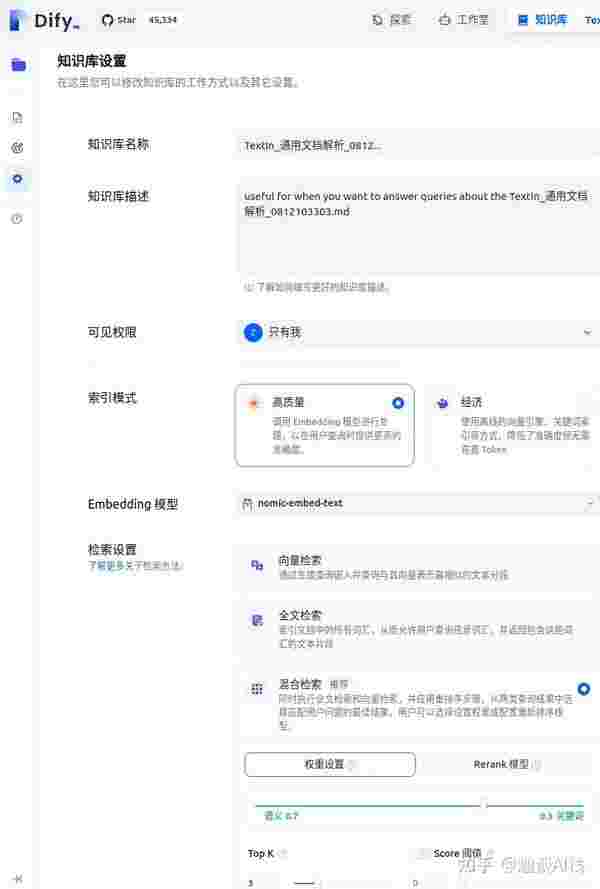
另外,在该知识库页面下进行“召回测试”,以观察对输入文本的检索结果,还可以返回“设置”界面,调整权重和返回结果数(TOP k),以改善召回结果。

5.2 创建应用
1.在浏览器Dify顶部选择“工作室”,点击左侧“创建空白应用”,选择“聊天助手”->“工作流编排”。2.创建成功后,系统会自动生成1个工作流。可点击右上方“功能”按钮,编辑“对话开场白”、“下一步问题建议”等功能。3.在“开始”-“LLM”节点之间,手动增加“知识检索”节点。4.选中“知识检索”节点,在右侧添加上述知识库,并完成“召回设置”,选择“多路召回”。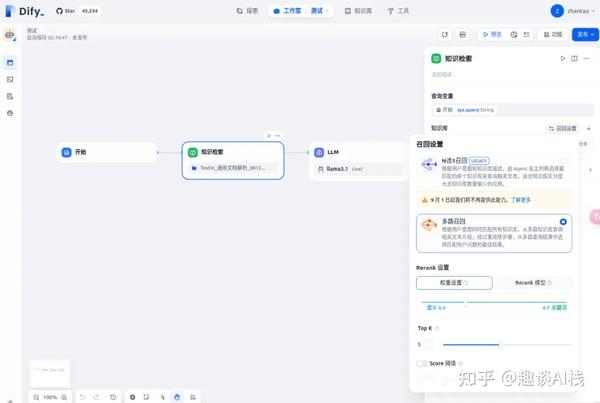

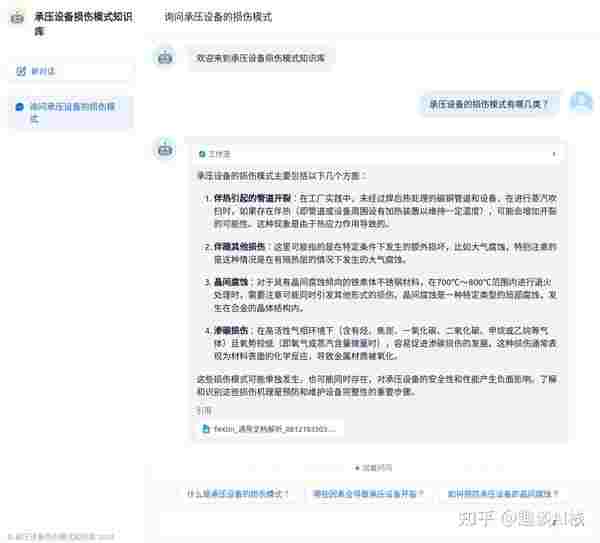
5.3 运行应用
点击右上角“预览”,输入文本后,观察工作流各节点的运行情况
以上Enjoy~