什么是Apache Tika?
Apache Tika是一个用于从各种文件格式中检索文档类型和内容的库。在内部,Tika使用现有的各种文档解析器和文档类型检测技术来检测和提取数据。使用Tika,可以开发通用类型检测器和内容提取器,以在一定程度上提取结构化文本以及来自不同类型文档的元数据,例如电子表格,文本文档,图像,PDF甚至多媒体输入格式。Tika提供了一个通用的API来解析不同的文件格式。 它为每种文档类型使用现有的专用解析器库。支持得格式
| 文件格式 | 包库 | 蒂卡班 |
| XML | org.apache.tika.parser.xml | XMLParser |
| HTML | org.apache.tika.parser.html它使用了Tagsoup Library | HtmlParser |
| MS-Office复合文档Ole2到2007年ooxml 2007年起 | org.apache.tika.parser.microsoft org.apache.tika.parser.microsoft.ooxml,它使用Apache Poi库 | OfficeParser(OLE2) OOXMLParser(ooxml) |
| OpenDocument格式openoffice | org.apache.tika.parser.odf | OpenOfficeParser |
| 便携式文件格式(PDF) | org.apache.tika.parser.pdf和这个包使用Apache PdfBox库 | PDFParser |
| 电子出版物格式(数字图书) | org.apache.tika.parser.epub | EpubParser |
| 富文本格式 | org.apache.tika.parser.rtf | RTFParser |
| 压缩和包装格式 | org.apache.tika.parser.pkg和这个包使用Common压缩库 | PackageParser和CompressorParser及其子类 |
| 文字格式 | org.apache.tika.parser.txt | TXTParser |
| Feed和联合格式 | org.apache.tika.parser.feed | FeedParser |
| 音频格式 | org.apache.tika.parser.audio和org.apache.tika.parser.mp3 | AudioParser MidiParser Mp3-适用于mp3parser |
| Imageparsers | org.apache.tika.parser.jpeg | JpegParser-用于jpeg图像 |
| Videoformats | org.apache.tika.parser.mp4和org.apache.tika.parser.video这个解析器在内部使用简单算法来解析flash视频格式 | Mp4parser FlvParser |
| java类文件和jar文件 | org.apache.tika.parser.asm | ClassParser CompressorParser |
| Mobxformat(电子邮件) | org.apache.tika.parser.mbox | MobXParser |
| Cad格式 | org.apache.tika.parser.dwg | DWGParser |
| FontFormats | org.apache.tika.parser.font | TrueTypeParser |
| 可执行程序和库 | org.apache.tika.parser.executable | ExecutableParser |
解析器
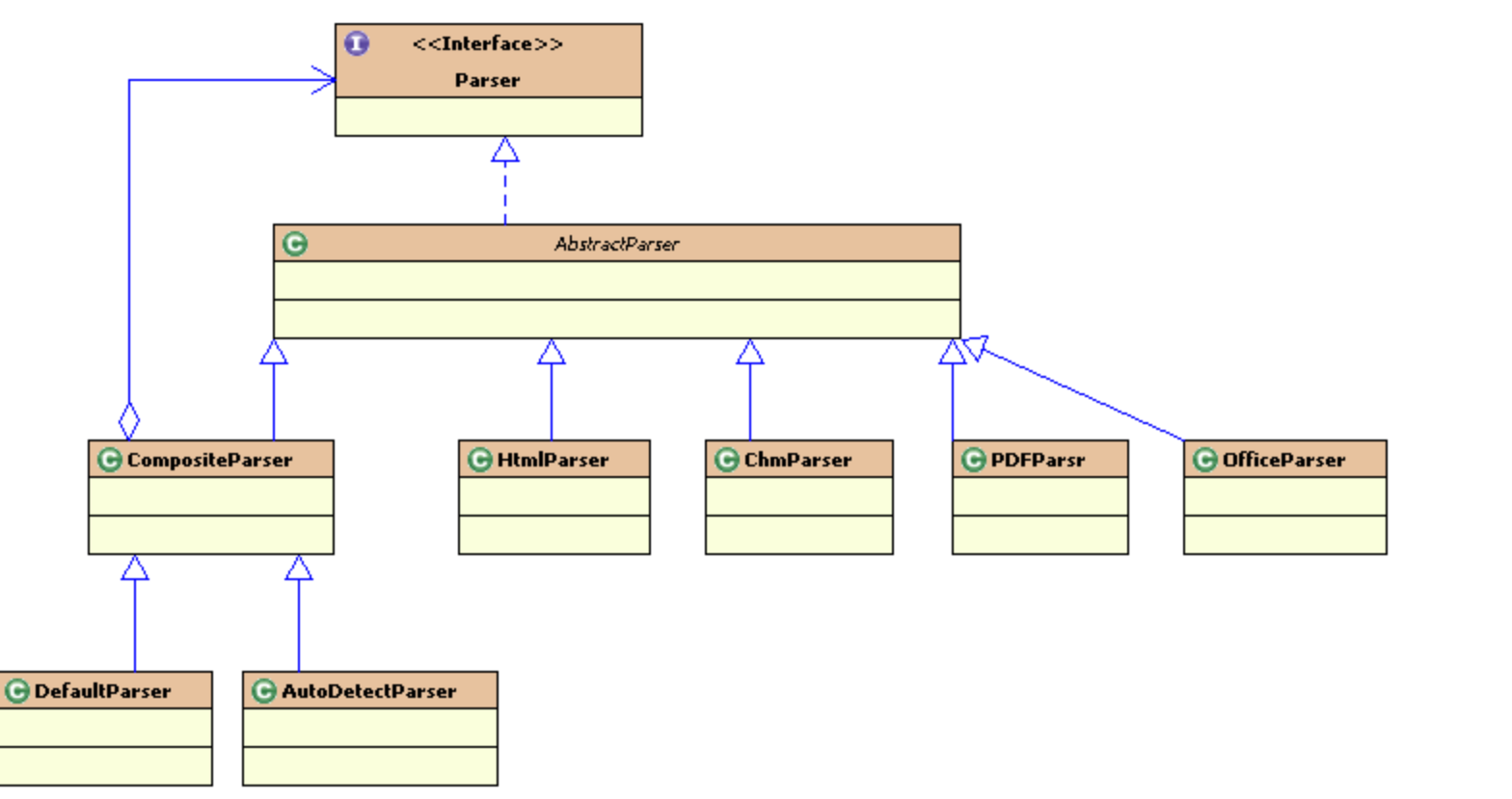
public interface Parser extends Serializable { Set<MediaType> getSupportedTypes(ParseContext var1); void parse(InputStream var1, ContentHandler var2, Metadata var3, ParseContext var4) throws IOException, SAXException, TikaException;}接口说明
| 参数 | 说明 |
| InputStream | 待解析的文档,以字节流形式传入,可以避免tika占用太多内存 |
| ContentHandler | 内容处理器,用来收集结果,Tika会将解析结果包装成XHTML SAX event进行分发,通过ContentHandler处理这些event就可以得到文本内容和其他有用的信息 |
| Metadata | 元数据,既是输入也是输出,可以将文件名或者可能的文件类型传入,tika解析时可以根据这些信息判断文件类型,再调用相应的解析器进行处理;另外,tika也会将一些额外的信息保存到Metadata中,如文件修改日期,作者,编辑工具等 |
| ParseContext | 解析上下文,用来控制解析过程,比如是否提取Office文档里面的宏等 |
tika的解析类的相关接口和类的UML模型
SpringBoot集成简单使用
添加依赖
<dependency> <groupId>org.apache.tika</groupId> <artifactId>tika-core</artifactId> <version>2.8.0</version> </dependency> <dependency> <groupId>org.apache.tika</groupId> <artifactId>tika-parsers-standard-package</artifactId> <version>2.8.0</version> </dependency> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.11.0</version> <!-- 请根据需要选择合适的版本 --> </dependency>简单使用
public class TikiService { public static void main(String[] args) throws Exception { //创建解析器--在不确定文档类型时候可以选择使用AutoDetectParser可以自动检测一个最合适的解析器 //如果确定可以使用确定的一个 //PDFParser pdfParser = new PDFParser(); //XMLParser xmlParser = new XMLParser(); //OfficeParser officeParser = new OfficeParser(); //........................ Parser parser = new AutoDetectParser(); //用于捕获文档提取的文本内容。-1 参数表示使用无限缓冲区,解析到的内容通过此hander获取 BodyContentHandler bodyContentHandler = new BodyContentHandler(-1); //元数据对象,它在解析器中传递元数据属性---可以获取文档属性 Metadata metadata = new Metadata(); //带有上下文相关信息的ParseContext实例,用于自定义解析过程。 ParseContext parseContext = new ParseContext(); File file = new File("C:\\Users\\cc\\study\\12.docx"); FileInputStream fileInputStream = new FileInputStream(file); parser.parse(fileInputStream,bodyContentHandler,metadata,parseContext); //获取文本 System.out.println(bodyContentHandler.toString()); //元数据信息 String[] names = metadata.names(); for (String name : names) { System.out.println(name); } }}支持解析模块