目录
**理解数据与数据可视化的基本流程****了解Python与其他可视化工具****掌握Anaconda、Jupyter Notebook的常用操作方法****原理** 环境配置1. **安装Anaconda软件,创建实验环境**2. **安装Jupyter Notebook**3. **创建第一个Jupyter Notebook文本**(1)**更改保存路径、重命名文件**(2)**创建代码单元和Markdown单元** 实验1-1:鸢尾花数据集可视化练习1. **安装scikit-learn库**2. **导入鸢尾花数据集并绘制表格**代码步骤: 绘制特征之间的散点图绘制饼图绘制散点图条形图:展示每种鸢尾花品种的平均特征值,例如平均花萼长度。 通过鸢尾花的目标(种类)创建类别列计算每个品种的平均特征值绘制条形图 - 展示不同品种的平均花萼长度代码解析:散点图:条形图: 结论:
理解数据与数据可视化的基本流程
数据可视化的核心不仅是将数据映射为图形,而是一个贯穿整个数据流向的完整过程。这个过程可以分为以下几个关键步骤:
数据采集:首先需要收集原始数据,可能来自数据库、API、手动输入或其它形式的文件(如CSV、Excel等)。数据处理和变换:对数据进行清洗、转换、聚合等处理,以便获得可用的数据结构和格式。可视化映射:将数据映射为图形符号,如点、线、颜色等,展示数据的结构和关系。人机交互:通过交互式图形实现动态数据探索,用户可以通过缩放、选择、过滤等操作更深入理解数据。用户感知:最终目标是通过图形呈现帮助用户理解数据的模式、趋势和重要信息。了解Python与其他可视化工具
在数据可视化领域,Python拥有多个强大的库,可以生成各种类型的图形。常用的库包括:
Matplotlib:最基础的可视化库,支持创建各种静态、动态、交互式图形。Seaborn:基于Matplotlib,提供了更高级和美观的统计图形工具,简化了数据的可视化操作。Pandas:主要是用于数据操作和分析的库,但其内置的可视化功能也非常强大,适合快速生成常见图表。Pyecharts:一个基于Python的库,支持创建交互式图形,适合需要精美和复杂展示的场景。掌握Anaconda、Jupyter Notebook的常用操作方法
Anaconda:是一个集成数据科学工具的平台,常用于安装和管理Python及其相关库。 创建虚拟环境:使用conda create -n myenv python=3.x来创建环境。安装库:在环境中运行conda install <package>或pip install <package>。 Jupyter Notebook:是一个交互式编程环境,支持实时代码执行、数据可视化和文档撰写。 在终端输入jupyter notebook启动应用,打开浏览器进行操作。通过Markdown格式添加文本注释、公式,方便记录实验过程。 原理
数据可视化的流程可以分为四个主要部分:
数据采集:收集、导入数据源,通常以CSV、数据库等形式存在。数据处理和变换:利用Pandas等工具对数据进行整理。可视化映射:借助Matplotlib、Seaborn等库创建图形展示。交互和感知:通过交互功能(如Pyecharts)与用户进行数据分析交互,增强对数据的理解。这种整体的流程不仅提升了可视化的质量,也为用户提供了高效的分析工具。
环境配置
1. 安装Anaconda软件,创建实验环境
下载并安装 Anaconda。
打开Anaconda Prompt,创建新的实验环境并指定Python版本:
conda create -n myenv python=3.x(例如,python=3.8可以选择合适版本)
激活环境:
conda activate myenv2. 安装Jupyter Notebook
安装Jupyter Notebook:
conda install jupyter启动Jupyter Notebook:
jupyter notebook3. 创建第一个Jupyter Notebook文本
在Jupyter Notebook界面中,点击New -> Python 3,创建一个新的Notebook文件。 (1)更改保存路径、重命名文件
创建文件后,可以点击顶部文件名(默认是Untitled),然后重命名为Iris Visualization或其他合适的名字。 (2)创建代码单元和Markdown单元
点击+按钮可以添加新的单元。在Cell类型的下拉框中,可以选择Code(代码单元)或Markdown(文本单元)。代码单元用来输入Python代码,Markdown单元则可以用来写实验步骤、注释、公式等。 实验1-1:鸢尾花数据集可视化练习
打开软件,可能需要等一会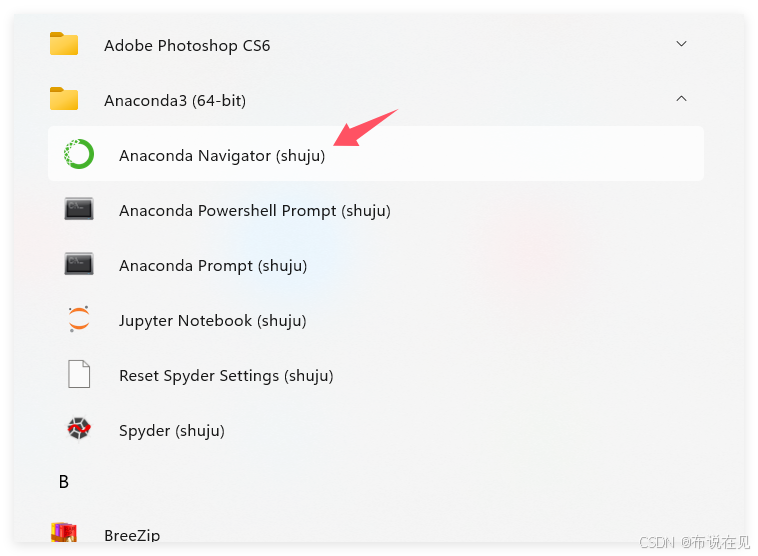
点击file——》Python 3
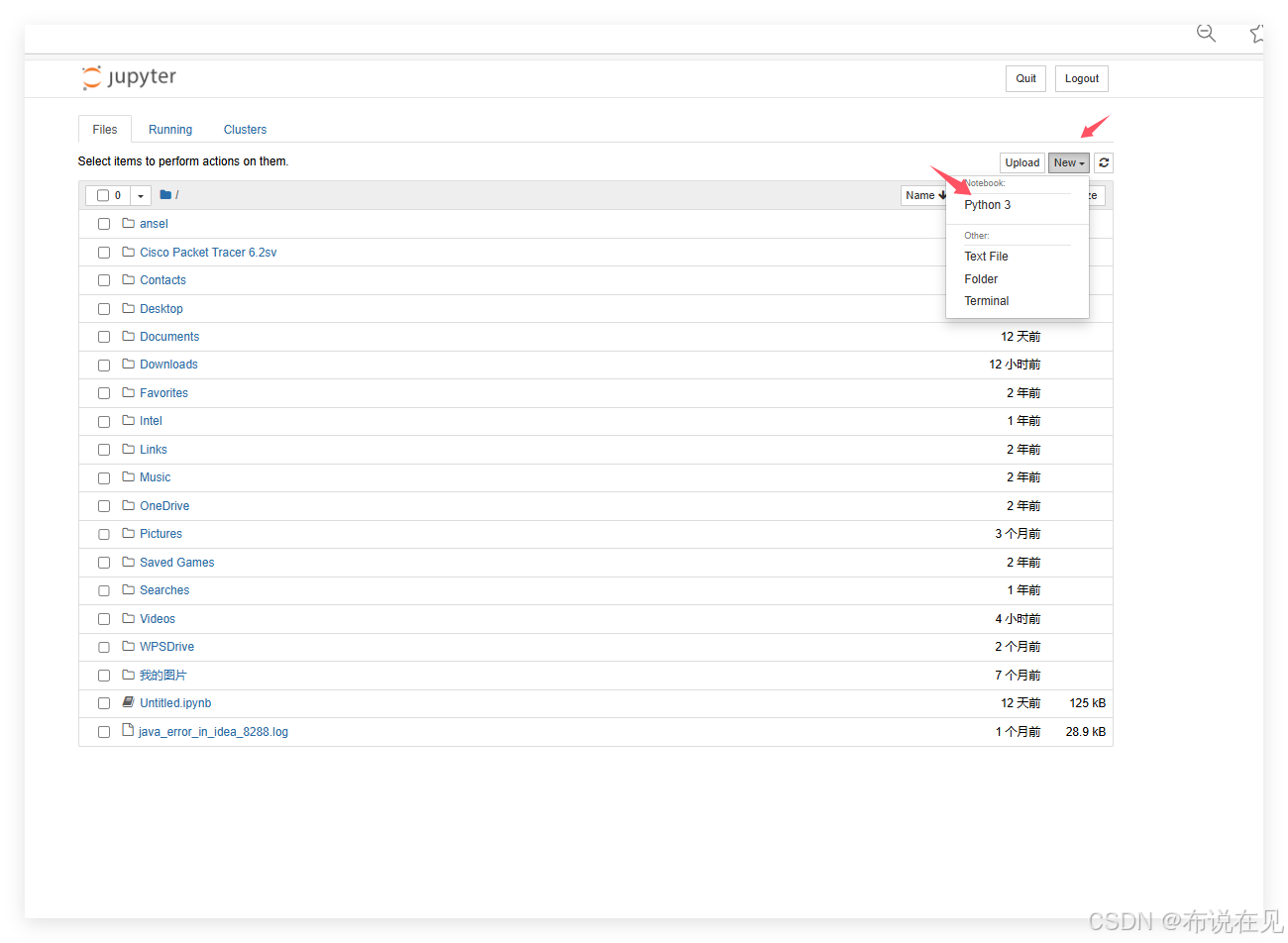
点击红框,重命名bushuo1-1.
1. 安装scikit-learn库
scikit-learn库:conda install scikit-learn
2. 导入鸢尾花数据集并绘制表格
代码步骤:
# 导入必要的库from sklearn import datasetsimport pandas as pdimport matplotlib.pyplot as plt# 设置字体以支持中文显示plt.rcParams['font.family'] = 'Arial Unicode MS'# 加载鸢尾花数据集iris = datasets.load_iris()# 创建DataFrame并设置列名df = pd.DataFrame(iris.data, columns=['SL', 'SW', 'PL', 'PW'])# 修改列名为中文df.columns = ['长度', '宽度', '长度2', '宽度2']# 显示前几行数据print(df.head())
绘制特征之间的散点图
plt.figure(figsize=(10, 6))plt.scatter(df['长度'], df['宽度'], c=iris.target, cmap='viridis')plt.xlabel('花萼长度 (cm)')plt.ylabel('花萼宽度 (cm)')plt.title('鸢尾花花萼长度与宽度的散点图')plt.colorbar(label='种类')plt.show()绘制饼图
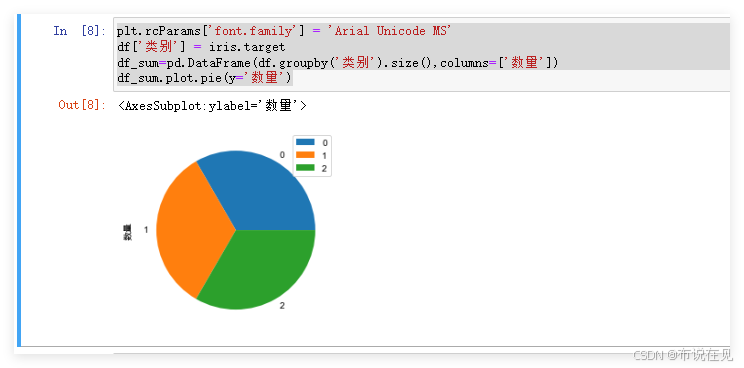
plt.rcParams['font.family'] = 'Arial Unicode MS'df['类别'] = iris.targetdf_sum=pd.DataFrame(df.groupby('类别').size(),columns=['数量'])df_sum.plot.pie(y='数量')绘制散点图
# 导入必要的库from sklearn import datasetsimport pandas as pdimport matplotlib.pyplot as plt# 设置字体以支持中文显示plt.rcParams['font.family'] = 'Arial Unicode MS'# 加载鸢尾花数据集iris = datasets.load_iris()# 创建DataFrame并设置列名df = pd.DataFrame(iris.data, columns=['SL', 'SW', 'PL', 'PW'])df.columns = ['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度']# 绘制散点图 - 展示花萼长度与宽度的关系plt.figure(figsize=(10, 6))plt.scatter(df['花萼长度'], df['花萼宽度'], c=iris.target, cmap='viridis')plt.xlabel('花萼长度 (cm)')plt.ylabel('花萼宽度 (cm)')plt.title('鸢尾花花萼长度与宽度的散点图')plt.colorbar(label='种类')plt.show()条形图:展示每种鸢尾花品种的平均特征值,例如平均花萼长度。
通过鸢尾花的目标(种类)创建类别列
df[‘种类’] = pd.Categorical.from_codes(iris.target, iris.target_names)
计算每个品种的平均特征值
mean_values = df.groupby(‘种类’).mean()
绘制条形图 - 展示不同品种的平均花萼长度
plt.figure(figsize=(10, 6))mean_values['花萼长度'].plot(kind='bar', color=['#4CAF50', '#FF9800', '#2196F3'])plt.title('不同鸢尾花品种的平均花萼长度')plt.xlabel('鸢尾花品种')plt.ylabel('平均花萼长度 (cm)')plt.xticks(rotation=0)plt.show()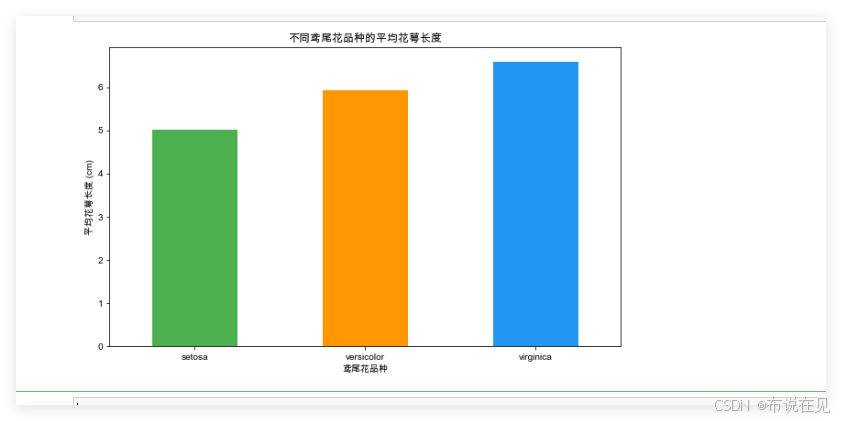
代码解析:
散点图:
使用 plt.scatter() 绘制花萼长度与花萼宽度的关系,并根据鸢尾花品种(iris.target)进行颜色映射。
cmap=‘viridis’ 用来指定颜色图,plt.colorbar() 添加颜色图例,显示各个颜色对应的品种。
条形图:
使用 groupby(‘种类’) 将鸢尾花数据按种类分类,并计算每种花的平均特征值。
mean_values[‘花萼长度’].plot(kind=‘bar’) 用于绘制条形图,显示不同品种鸢尾花的平均花萼长度。
color 参数指定了不同品种的颜色,xticks(rotation=0) 保持x轴标签不旋转。
结论:
散点图提供了特征之间的相关性和品种的分布信息,有助于发现不同品种的分布模式。
条形图则突出展示了不同品种鸢尾花的平均特征值,直观对比它们在某个维度(如花萼长度)上的差异。
这两个可视化方法相结合,有助于从多个角度深入理解鸢尾花数据集中的特征关系和品种差异。