
论文地址:官方论文地址
代码地址:官方代码地址

一、本文介绍
本篇文章给大家带来的实战讲解是Crossformer模型,其是一个针对多变量时间序列预测的新型深度学习模型,发表ICLR 2023上并且排名前5%,所以这个模型的质量还是能够有一定保证的(但是我用官方的代码真的是Bug一堆改的让人头大)。Bug多是很多但是其效果还是可圈可点的,Crossformer的主要思想是:通过维度-段式嵌入技术将时间序列数据转换为二维向量数组,同时使用两阶段注意力层来高效地捕获这两种依赖关系。Crossformer采用分层编码器-解码器结构,在不同层次上利用信息进行预测。
专栏目录:时间序列预测目录:深度学习、机器学习、融合模型、创新模型实战案例
专栏订阅: 时间序列预测专栏:基础知识+数据分析+机器学习+深度学习+Transformer+创新模型
目录
一、本文介绍
二、网络结构讲解
2.1 Crossformer的主要思想
2.2、维度-段式(DSW)嵌入
2.3、两阶段注意力(TSA)层
2.4、分层编码器-解码器(HED)结构
2.5、模型代码
三、数据集
四、参数讲解
五、模型训练
六、配置代码
七、模型预测
八、训练个人数据集
8.1、修改一
8.2、修改二
九、全文总结
二、网络结构讲解
2.1 Crossformer的主要思想
这个模型是一种新的基于Transformer的模型,名为Crossformer,这个模型在今年的ICLR上提出,是一种专门为多变量时间序列(MTS)预测设计。 Crossformer的主要特点包括:
1. 维度-段式(DSW)嵌入:这种新颖的嵌入技术将多变量时间序列数据沿每个维度划分为段,将这些段嵌入到特征向量中。这种方法保持了时间和维度信息,有助于模型更好地捕捉MTS数据的固有结构。
2. 两阶段注意力(TSA)层:Crossformer使用TSA层来有效捕捉时间和不同维度之间的依赖性。对于MTS预测来说,这两个方面的依赖性都是重要的。
3. 分层编码器-解码器(HED)结构:模型使用HED来利用不同规模的信息进行预测。这种分层方法有助于更有效地理解和预测MTS数据。 论文表明,通过其独特的方法,Crossformer有效地捕捉了跨维度依赖性,这是现有基于Transformer的MTS预测模型中常常忽视的一个关键方面。通过在六个真实世界数据集上的广泛实验结果显示,Crossformer在性能上超越了以前的最先进模型,表明了其有效性和实际应用的潜力。 这项研究通过解决现有模型的局限性并引入创新技术以提高性能,对时间序列预测领域做出了重要贡献。
下面我分别来解释这个模型中的三种结构->
2.2、维度-段式(DSW)嵌入
DSW嵌入是Crossformer模型的一个关键特性,它的目的是更好地捕捉MTS(多变量时间序列)数据中的跨维度依赖关系。传统的基于Transformer的模型主要关注于捕捉时间跨度上的依赖(即跨时间依赖),而往往没有显式地捕捉不同变量间的依赖性(即跨维度依赖),这限制了它们的预测能力。
在DSW嵌入中,每个维度的时间序列数据点被分成一定长度的段。然后,每个段被嵌入到一个向量中,方法是使用线性投影加上位置嵌入。线性投影矩阵E和位置嵌入Epos都是可学习的。这样,每个嵌入后的向量hid表示一个时间序列的单变量段,最终得到一个二维向量数组H。在这个数组中,每个向量hid代表一段时间序列的一维切片。与其他针对MTS预测的Transformer模型不同,DSW嵌入显式地捕捉了跨维度依赖性。
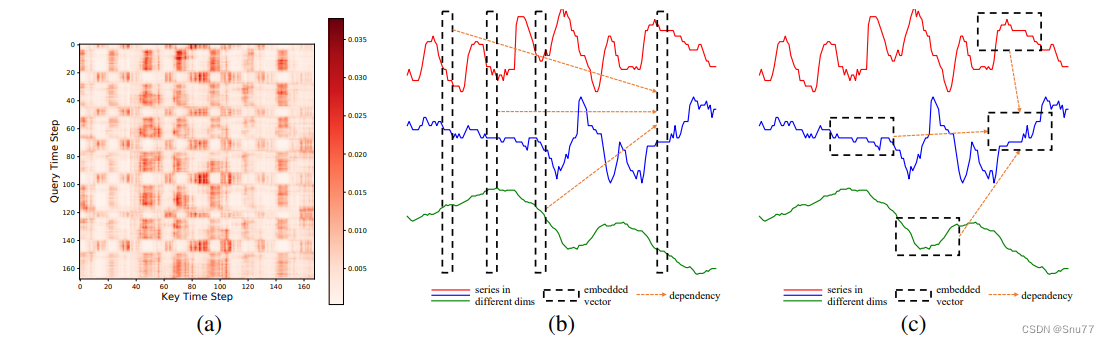
上图展示了Crossformer模型中维度-段式(DSW)嵌入的概念:
a) 由在ETH1数据集上训练的双层Transformer模型得出的自注意力分数热图,展示了多变量时间序列(MTS)数据倾向于被分段。
b) 描述了之前Transformer基础模型的嵌入方法,这些模型将同一时间步的不同维度的数据点嵌入到一个向量中。
c) 展示了Crossformer的DSW嵌入:在每个维度中,相邻的时间点形成一个段进行嵌入。
总结:这个图解清晰地说明了Crossformer如何通过其DSW嵌入机制来处理MTS数据,这是该模型与以前的方法不同的地方,它保留了时间序列数据在不同时间步的维度信息,以便更好地捕捉跨维度的依赖性。
2.3、两阶段注意力(TSA)层
两阶段注意力(TSA)层是Crossformer模型的一个核心组成部分,用于捕捉嵌入数组中的跨时间和跨维度依赖性。具体来说,通过DSW嵌入,输入数据被嵌入到一个二维向量数组中,以保留时间和维度的信息。然后,TSA层被设计出来,用于捕捉这些嵌入数组的依赖性。
以下是TSA层的工作流程说明:
1. 跨时间阶段:
TSA层接收一个二维数组 Z 作为输入,这个数组可能是维度-段式(DSW)嵌入的输出或下层TSA层的输出。对于每个维度,直接应用多头自注意力(MSA)机制来捕捉同一维度内不同时间段之间的依赖关系。这一阶段的计算涉及到层归一化(LayerNorm)和多层感知机(MLP),这有助于处理自注意力机制的输出。此阶段的计算复杂度为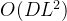 ,其中 L 是段的数量,D 是维度的数量。
,其中 L 是段的数量,D 是维度的数量。 2. 跨维度阶段:
为了避免直接在维度之间应用MSA所带来的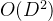 的计算复杂度,提出了一种路由机制。为每个时间步设置了一小组可学习的向量,称为“路由器”,用于从所有维度聚集信息。这些路由器随后将聚合的信息分发到各个维度,有效地建立了维度之间的全连接,而没有高复杂度。路由机制显著降低了复杂度,从
的计算复杂度,提出了一种路由机制。为每个时间步设置了一小组可学习的向量,称为“路由器”,用于从所有维度聚集信息。这些路由器随后将聚合的信息分发到各个维度,有效地建立了维度之间的全连接,而没有高复杂度。路由机制显著降低了复杂度,从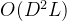 减少到
减少到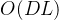 ,通过限制需要考虑的连接数量。与跨时间阶段类似,跨维度阶段也使用层归一化和MLP来处理路由机制的输出
,通过限制需要考虑的连接数量。与跨时间阶段类似,跨维度阶段也使用层归一化和MLP来处理路由机制的输出 这种两阶段的方法使Crossformer能够高效地处理多变量时间序列数据中的复杂依赖关系,通过区别对待时间轴和维度轴,尊重它们在数据结构中的独特作用。
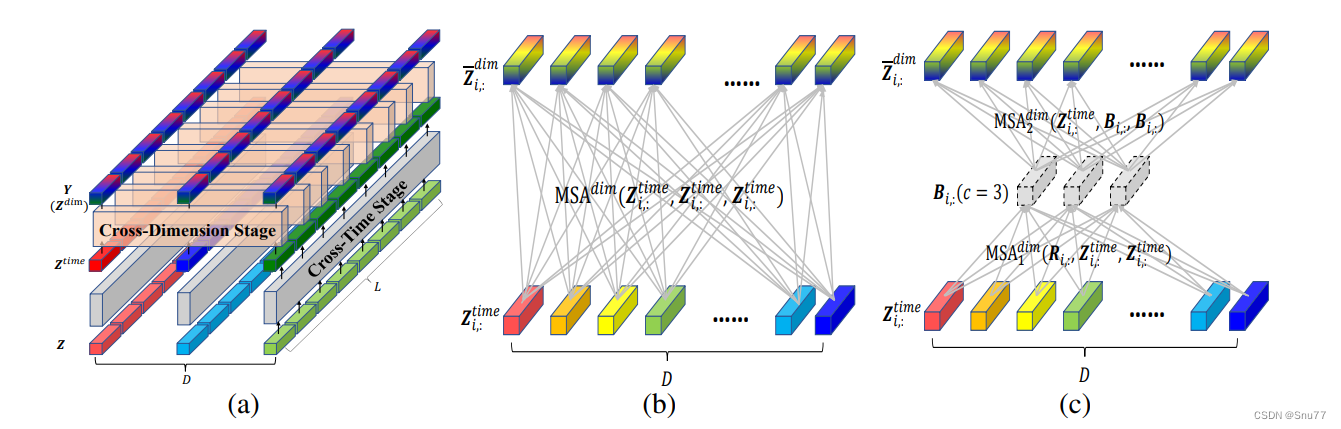 上图显示了两阶段注意力(TSA)层的构造和功能:
上图显示了两阶段注意力(TSA)层的构造和功能:
a)TSA层的整体结构,包含了跨时间阶段(Cross-Time Stage)和跨维度阶段(Cross-Dimension Stage),用于处理 O(2cD)=O(D)。
2.4、分层编码器-解码器(HED)结构
分层编码器-解码器(HED)结构在Crossformer模型中用于多变量时间序列(MTS)预测,并能捕获不同尺度上的信息。HED结构包括编码器和解码器两个部分,它们按照以下步骤工作:
1. 编码器:
除了第一层之外,编码器的每一层都会将时间域内两个相邻的向量合并,以获得更粗糙级别的表示。然后应用TSA层来捕获这个尺度上的依赖性。如果层数不是2的倍数,将进行填充以确保适当的长度。这个过程的输出表示为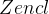 ,它是编码器第 l 层的输出。编码器的每一层的复杂度是
,它是编码器第 l 层的输出。编码器的每一层的复杂度是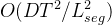 。
。 2. 解码器:
解码器接收编码器输出的N+1个特征数组,并使用N+1层(索引为0到N)进行预测。第 l 层取第 l 层编码的数组作为输入,然后输出解码的二维数组。解码过程中也使用了TSA层和多头自注意力机制(MSA),构建编码器和解码器之间的连接。解码器的每一层的复杂度是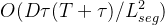 。
。 3. 最终预测:
应用线性投影到解码器的每一层输出,以产生该层的预测。然后将所有层的预测相加,以得到最终的预测结果。HED结构能够利用不同层次的信息进行预测,通过合并相邻的向量,并在不同的尺度上捕获依赖关系,最终通过解码器产生预测结果(其实看着好像考虑挺多但是结果我认为也就那样,对于时间序列领域我觉得往往简单才是真谛纯属个人见解哈哈)。
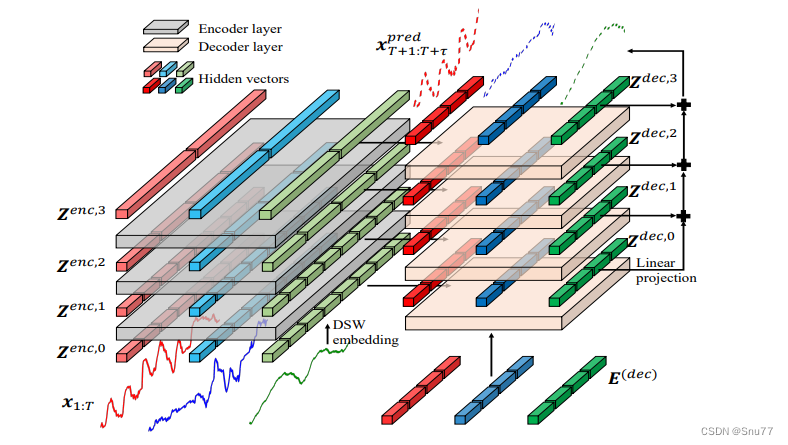
上图展示了Crossformer模型中分层编码器-解码器(HED)结构的架构,其中包含3层编码器层次。每个向量的长度表示它所覆盖的时间范围。编码器(左侧)利用TSA层和段合并来捕捉不同尺度上的依赖关系:上层的一个向量覆盖了更长的时间范围,从而在更粗糙的尺度上产生依赖性。解码器(右侧)通过在每个尺度上进行预测并将它们相加来制作最终的预测。
2.5、模型代码
大家可以根据上面流程来缕一缕下面的代码应该会有一定的收获。
class Crossformer(nn.Module): def __init__(self, data_dim, in_len, out_len, seg_len, win_size = 4, factor=10, d_model=512, d_ff = 1024, n_heads=8, e_layers=3, dropout=0.0, baseline = False, device=torch.device('cuda:0')): super(Crossformer, self).__init__() self.data_dim = data_dim self.in_len = in_len self.out_len = out_len self.seg_len = seg_len self.merge_win = win_size self.baseline = baseline self.device = device # The padding operation to handle invisible sgemnet length self.pad_in_len = ceil(1.0 * in_len / seg_len) * seg_len self.pad_out_len = ceil(1.0 * out_len / seg_len) * seg_len self.in_len_add = self.pad_in_len - self.in_len # Embedding self.enc_value_embedding = DSW_embedding(seg_len, d_model) self.enc_pos_embedding = nn.Parameter(torch.randn(1, data_dim, (self.pad_in_len // seg_len), d_model)) self.pre_norm = nn.LayerNorm(d_model) # Encoder self.encoder = Encoder(e_layers, win_size, d_model, n_heads, d_ff, block_depth = 1, \ dropout = dropout,in_seg_num = (self.pad_in_len // seg_len), factor = factor) # Decoder self.dec_pos_embedding = nn.Parameter(torch.randn(1, data_dim, (self.pad_out_len // seg_len), d_model)) self.decoder = Decoder(seg_len, e_layers + 1, d_model, n_heads, d_ff, dropout, \ out_seg_num = (self.pad_out_len // seg_len), factor = factor) def forward(self, x_seq): if (self.baseline): base = x_seq.mean(dim = 1, keepdim = True) else: base = 0 batch_size = x_seq.shape[0] if (self.in_len_add != 0): x_seq = torch.cat((x_seq[:, :1, :].expand(-1, self.in_len_add, -1), x_seq), dim = 1) x_seq = self.enc_value_embedding(x_seq) x_seq += self.enc_pos_embedding x_seq = self.pre_norm(x_seq) enc_out = self.encoder(x_seq) dec_in = repeat(self.dec_pos_embedding, 'b ts_d l d -> (repeat b) ts_d l d', repeat = batch_size) predict_y = self.decoder(dec_in, enc_out) return base + predict_y[:, :self.out_len, :]
三、数据集
本文是实战讲解文章,上面主要是简单讲解了一下网络结构比较具体的流程还是很复杂的涉及到很多的数学计算,下面我们来讲一讲模型的实战内容,第一部分是我利用的数据集。
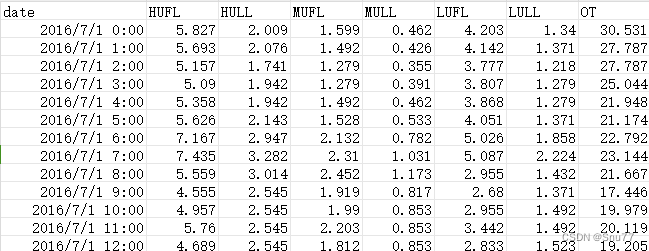
我们本文用到的数据集是官方的ETTh1.csv(这个模型官方实验的数据集就是这个) ,该数据集是一个用于时间序列预测的电力负荷数据集,它是 ETTh 数据集系列中的一个。ETTh 数据集系列通常用于测试和评估时间序列预测模型。以下是 ETTh1.csv 数据集的一些内容:
数据内容:该数据集通常包含有关电力系统的多种变量,如电力负荷、价格、天气情况等。这些变量可以用于预测未来的电力需求或价格。
时间范围和分辨率:数据通常按小时或天记录,涵盖了数月或数年的时间跨度。具体的时间范围和分辨率可能会根据数据集的版本而异。
以下是该数据集的部分截图->
四、参数讲解
parser = argparse.ArgumentParser(description='CrossFormer')parser.add_argument('--data', type=str, default='ETTh1', help='data')parser.add_argument('--root_path', type=str, default='./datasets/', help='root path of the data file')parser.add_argument('--data_path', type=str, default='ETTh1.csv', help='data file') parser.add_argument('--data_split', type=str, default='0.7,0.1,0.2',help='train/val/test split, can be ratio or number')parser.add_argument('--checkpoints', type=str, default='./checkpoints/', help='location to store model checkpoints')parser.add_argument('--in_len', type=int, default=96, help='input MTS length (T)')parser.add_argument('--out_len', type=int, default=24, help='output MTS length (\tau)')parser.add_argument('--seg_len', type=int, default=6, help='segment length (L_seg)')parser.add_argument('--win_size', type=int, default=2, help='window size for segment merge')parser.add_argument('--factor', type=int, default=10, help='num of routers in Cross-Dimension Stage of TSA (c)')parser.add_argument('--data_dim', type=int, default=7, help='Number of dimensions of the MTS data (D)')parser.add_argument('--d_model', type=int, default=256, help='dimension of hidden states (d_model)')parser.add_argument('--d_ff', type=int, default=512, help='dimension of MLP in transformer')parser.add_argument('--n_heads', type=int, default=4, help='num of heads')parser.add_argument('--e_layers', type=int, default=3, help='num of encoder layers (N)')parser.add_argument('--dropout', type=float, default=0.2, help='dropout')parser.add_argument('--baseline', action='store_true', help='whether to use mean of past series as baseline for prediction', default=False)parser.add_argument('--num_workers', type=int, default=0, help='data loader num workers')parser.add_argument('--batch_size', type=int, default=32, help='batch size of train input data')parser.add_argument('--train_epochs', type=int, default=20, help='train epochs')parser.add_argument('--patience', type=int, default=3, help='early stopping patience')parser.add_argument('--learning_rate', type=float, default=1e-4, help='optimizer initial learning rate')parser.add_argument('--lradj', type=str, default='type1',help='adjust learning rate')parser.add_argument('--itr', type=int, default=1, help='experiments times')parser.add_argument('--save_pred', action='store_true', help='whether to save the predicted future MTS', default=False)parser.add_argument('--use_gpu', type=bool, default=True, help='use gpu')parser.add_argument('--gpu', type=int, default=0, help='gpu')parser.add_argument('--use_multi_gpu', action='store_true', help='use multiple gpus', default=False)parser.add_argument('--devices', type=str, default='0,1,2,3',help='device ids of multile gpus')args = parser.parse_args()上面就是模型注册的所有代码,当然了模型还有一部分评估模型用的代码我就不讲解了,有兴趣不会的可以私聊问我或者评论区提问我也会回答。
| 参数名称 | 参数类型 | 参数讲解 | |
|---|---|---|---|
| 0 | data | str | 模型的类型,可以理解为定制化的的东西量身特作的感觉,如果你想用个人数据集就需要自己量身定做一个,下面会介绍 |
| 1 | root_path | str | 你输入文件的目录,填写到文件的目录即可。 |
| 2 | data_path | str | 文件的名字这个和上面的进行组合。 |
| 3 | data_split | str | 训练集测试集验证集划分的比例 |
| 4 | checkpoints | str | 模型训练结果保存的目录 |
| 5 | in_len | int | 观测器窗口,利用多少条数据预测未来的多少条数据 |
| 6 | out_len | int | 更大注意力的数据 |
| 7 | seg_len | int | 预测多少条未来的数据 |
| 8 | win_size | int | 此参数用于指定分层编码器-解码器结构中段合并的窗口大小(前面有提到过) |
| 9 | factor | int | 此参数设置TSA层跨维度阶段的路由器数量(在TSA层文档中表示为c) |
| 10 | data_dim | int | 数据的特征数不算时间列!!! |
| 11 | d_model | int | 模型的隐藏层单元数(根据数据来设置) |
| 12 | d_ff | int | 这个参数用来指定Transformer模型中多层感知机(MLP)的维度大小 |
| 13 | n_heads | int | 注意力机制头数 |
| 14 | e_layers | int | 解码层 |
| 15 | dropout | float | 丢弃的概率大家都会了估计 |
| 16 | baseline | store_true | 此参数用于决定是否使用过去序列的平均值作为预测的基线 |
| 17 | num_workers | int | 线程windows设置为0 |
| 18 | train_epochs | int | 训练的轮次 |
| 19 | patience | int | 早停机制的耐心度 |
| 20 | learning_rate | float | 学习率 |
| 21 | lradj | str | 学习率更正的方案不用理会 |
| 22 | itr | int | 实验次数填写1不发论文不用做对比。 |
| 23 | save_pred | store_true | 是否保存预测值(测试集的) |
| 24 | use_gpu | bool | 是否使用gpu |
| 25 | gpu | int | gou编号 |
| 26 | use_multi_gpu | store_true | 多GPU训练 |
| 27 | device | str | 多个gpu型号 |
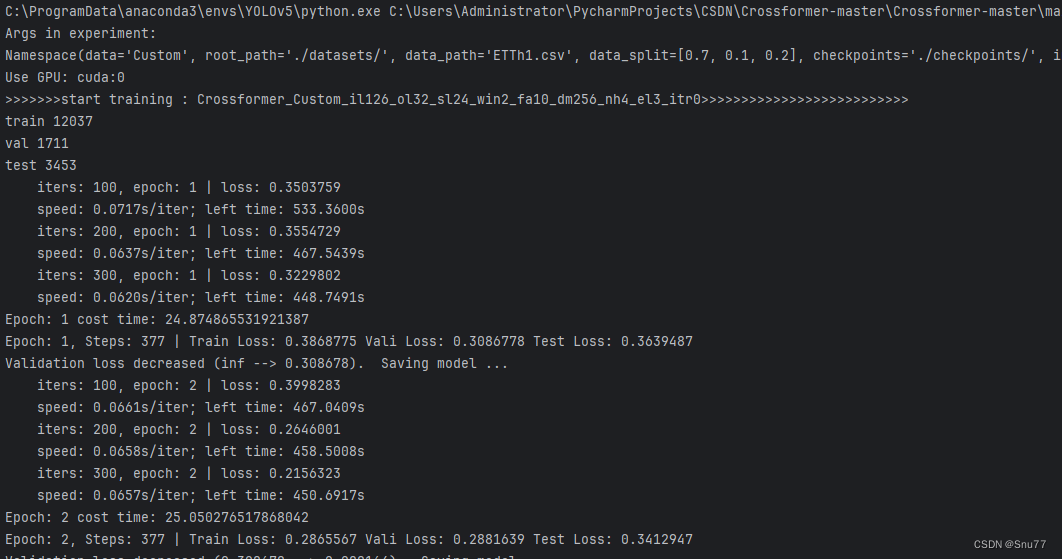
五、模型训练
当我们设置完所有的参数之后(根据你自己的数据集)就可以开始训练模型啦~
我们找到如下文件“main_crossformer.py”运行即可。
六、配置代码
下面是我的该文件main_crossformer.py的完整内容,发给大家参考。
import argparseimport osimport torchfrom cross_exp.exp_crossformer import Exp_crossformerfrom utils.tools import string_splitparser = argparse.ArgumentParser(description='CrossFormer')parser.add_argument('--data', type=str, default='Custom', help='data')parser.add_argument('--root_path', type=str, default='./datasets/', help='root path of the data file')parser.add_argument('--data_path', type=str, default='ETTh1.csv', help='data file') parser.add_argument('--data_split', type=str, default='0.7,0.1,0.2',help='train/val/test split, can be ratio or number')parser.add_argument('--checkpoints', type=str, default='./checkpoints/', help='location to store model checkpoints')parser.add_argument('--in_len', type=int, default=126, help='input MTS length (T)')parser.add_argument('--out_len', type=int, default=32, help='output MTS length (\tau)')parser.add_argument('--seg_len', type=int, default=24, help='segment length (L_seg)')parser.add_argument('--win_size', type=int, default=2, help='window size for segment merge')parser.add_argument('--factor', type=int, default=10, help='num of routers in Cross-Dimension Stage of TSA (c)')parser.add_argument('--data_dim', type=int, default=7, help='Number of dimensions of the MTS data (D)')parser.add_argument('--d_model', type=int, default=256, help='dimension of hidden states (d_model)')parser.add_argument('--d_ff', type=int, default=512, help='dimension of MLP in transformer')parser.add_argument('--n_heads', type=int, default=4, help='num of heads')parser.add_argument('--e_layers', type=int, default=3, help='num of encoder layers (N)')parser.add_argument('--dropout', type=float, default=0.2, help='dropout')parser.add_argument('--baseline', action='store_true', help='whether to use mean of past series as baseline for prediction', default=False)parser.add_argument('--num_workers', type=int, default=0, help='data loader num workers')parser.add_argument('--batch_size', type=int, default=32, help='batch size of train input data')parser.add_argument('--train_epochs', type=int, default=20, help='train epochs')parser.add_argument('--patience', type=int, default=3, help='early stopping patience')parser.add_argument('--learning_rate', type=float, default=1e-4, help='optimizer initial learning rate')parser.add_argument('--lradj', type=str, default='type1',help='adjust learning rate')parser.add_argument('--itr', type=int, default=1, help='experiments times')parser.add_argument('--save_pred', action='store_true', help='whether to save the predicted future MTS', default=False)parser.add_argument('--use_gpu', type=bool, default=True, help='use gpu')parser.add_argument('--gpu', type=int, default=0, help='gpu')parser.add_argument('--use_multi_gpu', action='store_true', help='use multiple gpus', default=False)parser.add_argument('--devices', type=str, default='0,1,2,3',help='device ids of multile gpus')args = parser.parse_args()args.use_gpu = True if torch.cuda.is_available() and args.use_gpu else Falseif args.use_gpu and args.use_multi_gpu: args.devices = args.devices.replace(' ','') device_ids = args.devices.split(',') args.device_ids = [int(id_) for id_ in device_ids] args.gpu = args.device_ids[0] print(args.gpu)data_parser = { 'ETTh1':{'data':'ETTh1.csv', 'data_dim':7, 'split':[12*30*24, 4*30*24, 4*30*24]}, 'ETTm1':{'data':'ETTm1.csv', 'data_dim':7, 'split':[4*12*30*24, 4*4*30*24, 4*4*30*24]}, 'WTH':{'data':'WTH.csv', 'data_dim':12, 'split':[28*30*24, 10*30*24, 10*30*24]}, 'ECL':{'data':'ECL.csv', 'data_dim':321, 'split':[15*30*24, 3*30*24, 4*30*24]}, 'ILI':{'data':'national_illness.csv', 'data_dim':7, 'split':[0.7, 0.1, 0.2]}, 'Traffic':{'data':'traffic.csv', 'data_dim':862, 'split':[0.7, 0.1, 0.2]}, 'Custom': {'data': 'ETTh1.csv', 'data_dim': 7, 'split': [0.7, 0.1, 0.2]},}if args.data in data_parser.keys(): data_info = data_parser[args.data] args.data_path = data_info['data'] args.data_dim = data_info['data_dim'] args.data_split = data_info['split']else: args.data_split = string_split(args.data_split)print('Args in experiment:')print(args)Exp = Exp_crossformerfor ii in range(args.itr): # setting record of experiments setting = 'Crossformer_{}_il{}_ol{}_sl{}_win{}_fa{}_dm{}_nh{}_el{}_itr{}'.format(args.data, args.in_len, args.out_len, args.seg_len, args.win_size, args.factor, args.d_model, args.n_heads, args.e_layers, ii) exp = Exp(args) # set experiments print('>>>>>>>start training : {}>>>>>>>>>>>>>>>>>>>>>>>>>>'.format(setting)) exp.train(setting) print('>>>>>>>testing : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting)) exp.test(setting, args.save_pred)
七、模型预测
值得一提是,该代码来自于官方,官方并没有出预测的功能,本来我想给其加上的,但是我确实没有这个需求也不知道这个文章看的人多不多,所以如果大家有需要我是可以给官方代码补全的,所以大家有需要可以评论区催更。
八、训练个人数据集
8.1、修改一
训练个人数据集需要修改的地方主要有三处(只能保证大家跑起来),
parser.add_argument('--data', type=str, default='Custom', help='data')parser.add_argument('--root_path', type=str, default='./datasets/', help='root path of the data file')parser.add_argument('--data_path', type=str, default='ETTh1.csv', help='data file') parser.add_argument('--data_dim', type=int, default=7, help='Number of dimensions of the MTS data (D)')这四个需要根据你自己的填写,其中data就随便设置一个名字,然后root_path,data_path前面参数讲解的地方以及将结果了,最后一个data_dim就是你的特征数注意不算时间列!!!!
8.2、修改二
上面讲解了参数部分需要修改的,下面还有一部分需要修改。
data_parser = { 'ETTh1':{'data':'ETTh1.csv', 'data_dim':7, 'split':[12*30*24, 4*30*24, 4*30*24]}, 'ETTm1':{'data':'ETTm1.csv', 'data_dim':7, 'split':[4*12*30*24, 4*4*30*24, 4*4*30*24]}, 'WTH':{'data':'WTH.csv', 'data_dim':12, 'split':[28*30*24, 10*30*24, 10*30*24]}, 'ECL':{'data':'ECL.csv', 'data_dim':321, 'split':[15*30*24, 3*30*24, 4*30*24]}, 'ILI':{'data':'national_illness.csv', 'data_dim':7, 'split':[0.7, 0.1, 0.2]}, 'Traffic':{'data':'traffic.csv', 'data_dim':862, 'split':[0.7, 0.1, 0.2]}, 'Custom': {'data': 'ETTh1.csv', 'data_dim': 7, 'split': [0.7, 0.1, 0.2]},}上面看我建立了一个custom这个就是我自己的数据集的,你可以根据你自己的数据集在下面建立一个,就可以了。
九、全文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的时间序列专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的模型进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
(同时最近在研究各种顶会内容,专栏也会持续更新一段时间顶会的内容,大家如果想一起学习,发表论文的可以私信我)
专栏回顾: 时间序列预测专栏——持续复习各种顶会内容——科研必备
如果大家有不懂的也可以评论区留言一些报错什么的大家可以讨论讨论看到我也会给大家解答如何解决!最后希望大家工作顺利学业有成!
