【更新说明】项目代码已在2024年11月13日进行更新,如有问题可评论或私信与我联系!
目录
项目介绍
代码部分
引用第三方库
全局定义
主函数
爬虫主函数代码
翻页函数代码
编辑
获取商品列表信息代码
完整代码
项目介绍
项目使用ChromeDriver插件,基于Python的第三方库Selenium模拟浏览器运行、PyQuery解析和操作HTML文档,获取淘宝平台中某类商品的详细信息(商品标题、价格、销量、商铺名称、地区、商品详情页链接、商铺链接等),并基于第三方库openpyxl建立、存储于Excel表格中。
【说明】若允许代码出现翻译错误、代码能正常运行但是Excel没有数据等问题,可能是淘宝网页更新了父元素类选择器的缘故,大家可以参照教程检查一下元素是否更新;若网页元素更新,则可参照教程自行修改;【爬虫】教你如何获取淘宝网页父元素类选择器标签(超详细)-CSDN博客
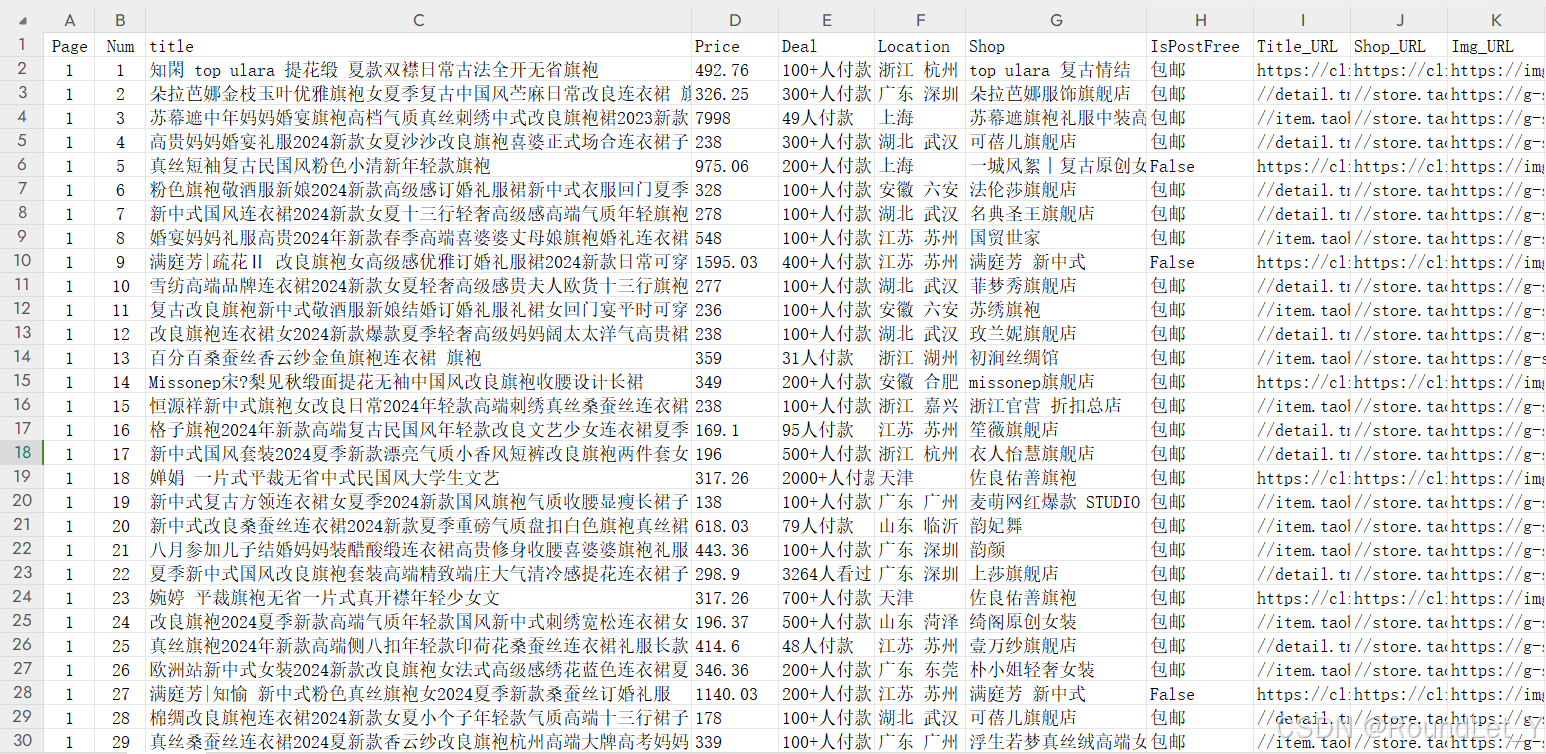
效果预览:
代码部分
引用第三方库
# 声明第三方库/头文件from selenium import webdriverfrom selenium.common.exceptions import TimeoutExceptionfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom pyquery import PyQuery as pqimport timeimport openpyxl as op #导入Excel读写库【第三方库】主要运用到PyQuery、selenium、openpyxl等Python的第三方库;如若缺失,使用pip指令安装即可。
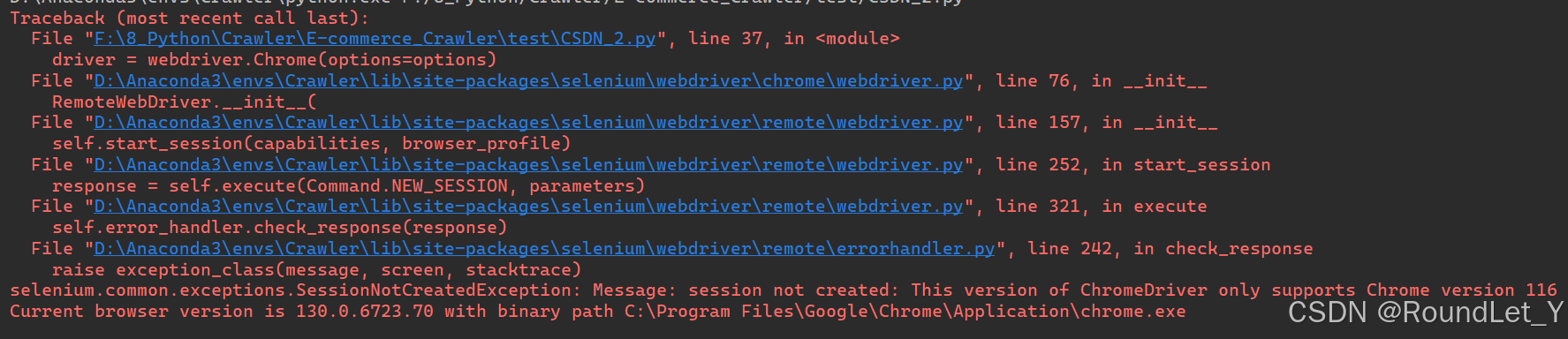
pip install pyquerypip install seleniumpip install openpyxl【ChromeDriver下载与安装】若运行过程中出现如下问题,可能是ChromeDriver版本与Chrome版本不一致导致,需要对ChromeDriver进行更新。ChromeDriver下载与安装:手把手教你,ChromeDriver下载与安装
全局定义
# 全局变量count = 1 # 写入Excel商品计数# 启动ChromeDriver服务options = webdriver.ChromeOptions()# 关闭自动测试状态显示 // 会导致浏览器报:请停用开发者模式options.add_experimental_option("excludeSwitches", ['enable-automation'])# 把chrome设为selenium驱动的浏览器代理;driver = webdriver.Chrome(options=options)# 反爬机制driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""})driver.get('https://www.taobao.com')# 窗口最大化driver.maximize_window()# wait是Selenium中的一个等待类,用于在特定条件满足之前等待一定的时间(这里是15秒)。# 如果一直到等待时间都没满足则会捕获TimeoutException异常wait = WebDriverWait(driver,10)# 打开页面后会强制停止10秒,请在此时手动扫码登陆主函数
1、输入初始参数:
爬取商品的关键词Keyword爬取网页的起始页PageStart爬取网页的终止页PageEnd2、建立Excel表格,并设置第一行(表头);
3、调用爬虫主函数Crawer_main,启动爬虫程序;
4、输入存储文件名称filename,输出.xlsx格式文件
if __name__ == '__main__': KEYWORD = input('输入搜索的商品关键词Keyword:') # 要搜索的商品的关键词 pageStart = int(input('输入爬取的起始页PageStart:')) # 爬取起始页 pageEnd = int(input('输入爬取的终止页PageEnd:')) # 爬取终止页 # 建立Excel表格 try: ws = op.Workbook() # 创建Workbook wb = ws.create_sheet(index=0) # 创建worsheet # Excel第一行:表头 title_list = ['Page', 'Num', 'title', 'Price', 'Deal', 'Location', 'Shop', 'IsPostFree', 'Title_URL', 'Shop_URL', 'Img_URL'] for i in range(0, len(title_list)): wb.cell(row=count, column=i + 1, value=title_list[i]) count += 1 # 从第二行开始写爬取数据 except Exception as exc: print("Excel建立失败!") # 开始爬取数据 Crawer_main(KEYWORD,pageStart,pageEnd) # 保存Excel表格 Filename = input("输入存储文件名称:") Filename = Filename + '_From_Taobao.xlsx' ws.save(filename = Filename) print(Filename + "存储成功~")(输入)效果预览:
爬虫主函数代码
1、ChromeDriver服务请求淘宝(https://www.taobao.com)服务,模拟浏览器运行,找到“输入框”输入关键词KEYWORD,并点击“搜索”按键;
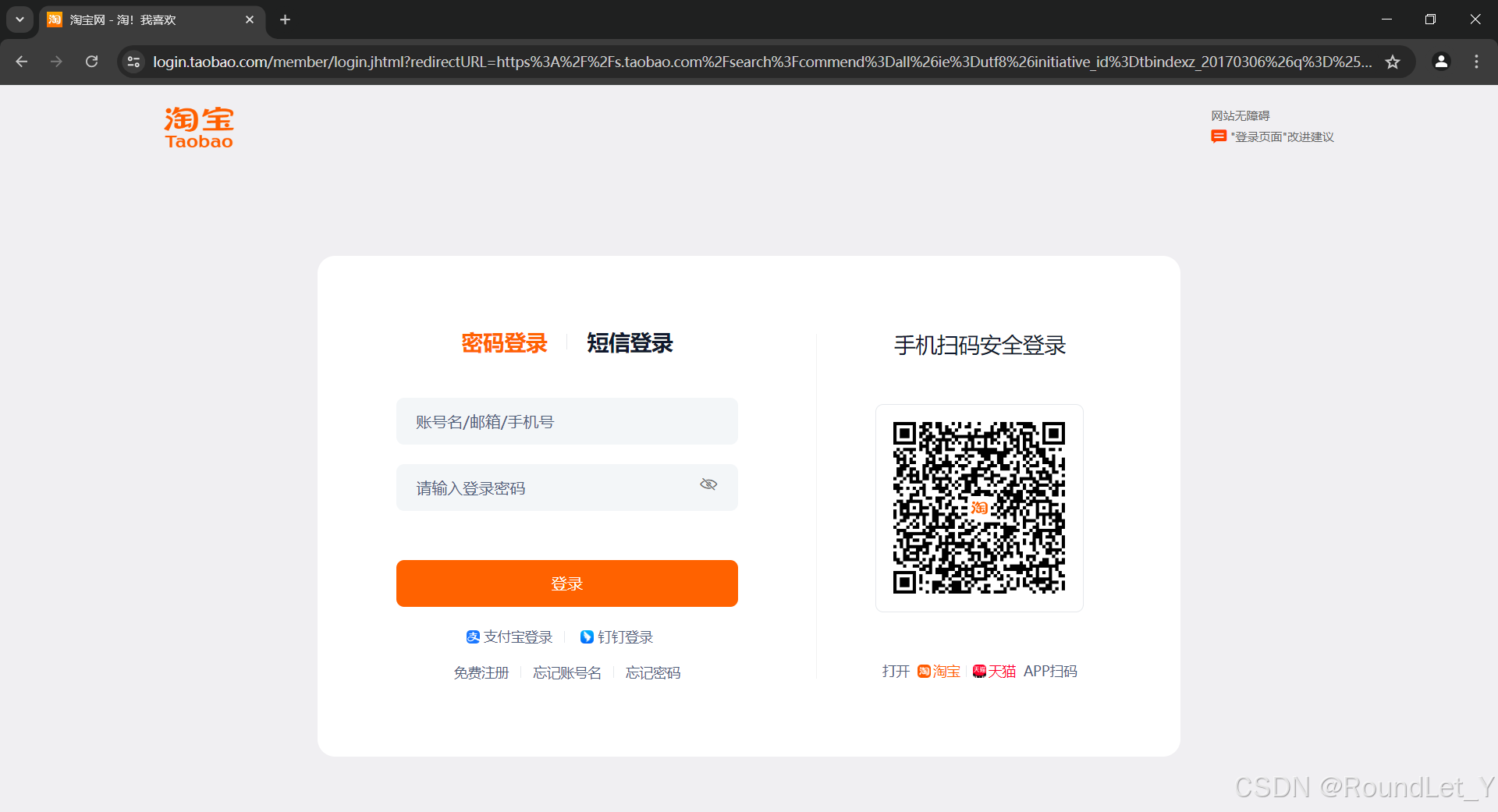
2、若弹出登录窗口,使用手机“淘宝”APP,扫码登录(如图所示);
3、判断PageStart是否为1;若PageStart不为1,跳转至PageStart所在页;
4、调用get_goods获取起始页PageStart的商品列表信息;
5、调用page_turning进行翻页,并获取所在页商品列表信息;
# 爬虫main函数def Crawer_main(KEYWORD,pageStart,pageEnd): try: # 爬取从pageStart到pageAll页的数据 search_goods(KEYWORD,pageStart,pageEnd) except Exception as exc: print('Crawer_main函数报错:', exc)# 输入“关键词”,搜索,并进行首次爬取def search_goods(KEYWORD,start_page,total_pages): try: print('正在搜索: ') # 找到搜索“输入框” input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q"))) # 找到“搜索”按钮 submit = wait.until( EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_TSearchForm > div.search-button > button'))) # 输入框写入“关键词KeyWord” input.send_keys(KEYWORD) # 点击“搜索”按键 submit.click() # 搜索商品后会再强制停止5秒,如有滑块请手动操作 # time.sleep(5) # 如果不是从第一页开始爬取,就滑动到底部输入页面然后跳转 if start_page != 1: # 滑动到页面底端 # driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 滑动到底部后停留3s time.sleep(3) # 找到输入“页面”的表单,输入“起始页” pageInput = wait.until(EC.presence_of_element_located( (By.XPATH, '//*[@id="pageContent"]/div[1]/div[3]/div[4]/div/div/span[3]/input'))) pageInput.send_keys(start_page) # 找到页面跳转的“确定”按钮,并且点击 admit = wait.until(EC.element_to_be_clickable( (By.XPATH, '//*[@id="pageContent"]/div[1]/div[3]/div[4]/div/div/button[3]'))) admit.click() # 获取商品信息 get_goods(start_page) # 翻页操作 for i in range(start_page + 1, total_pages+1): page_turning(i) except TimeoutException: print("search_goods: error") return search_goods(KEYWORD,start_page,total_pages)淘宝登录界面示意图:
翻页函数代码
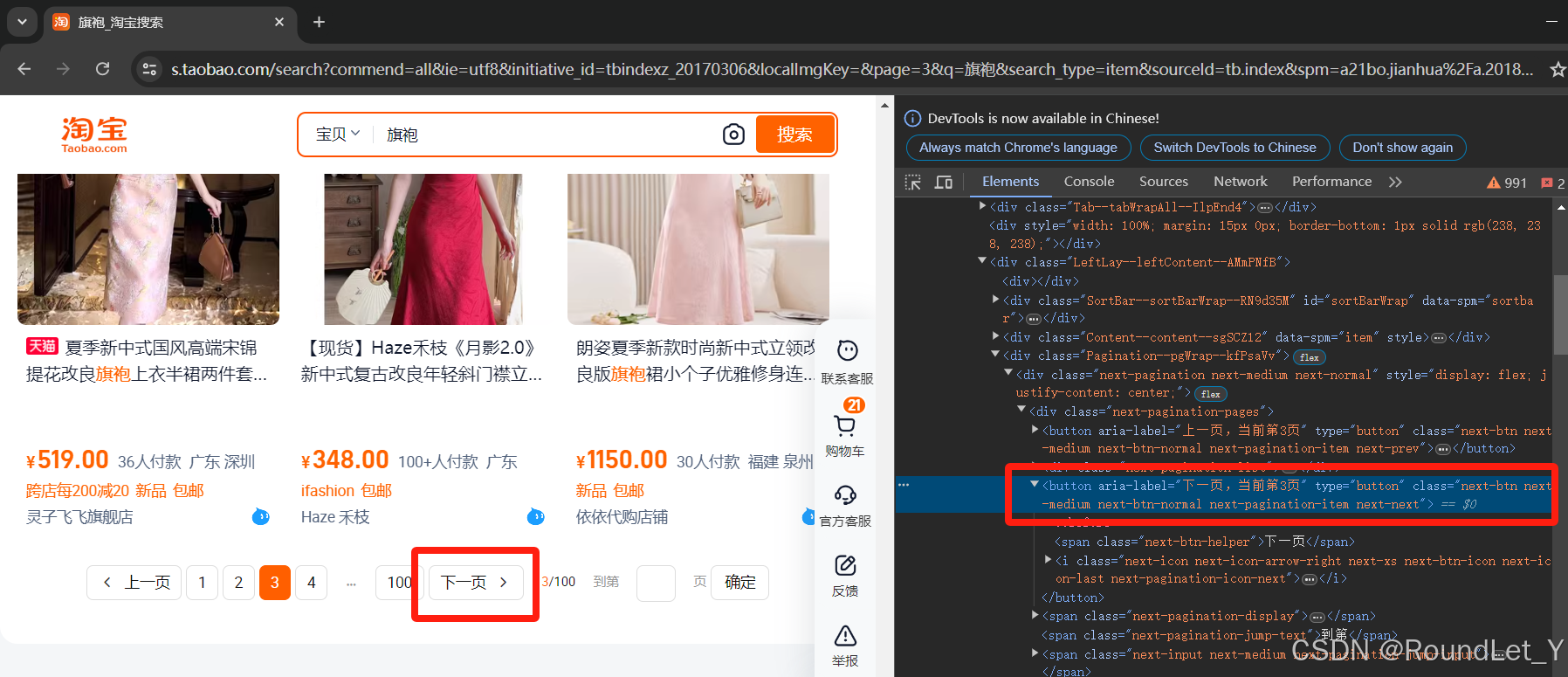
翻页函数page_turning搜索并点击“下一页”按键,判断页码是否相等;若页码相等获取该页商品列表信息。
# 翻页函数def page_turning(page_number): print('正在翻页: ', page_number) try: # 强制等待2秒后翻页 time.sleep(2) # 找到“下一页”的按钮 submit = wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="search-content-leftWrap"]/div[2]/div[4]/div/div/button[2]'))) submit.click() # 判断页数是否相等 wait.until(EC.text_to_be_present_in_element((By.XPATH, '//*[@id="search-content-leftWrap"]/div[2]/div[4]/div/div/span[1]/em'), str(page_number))) get_goods(page_number) except TimeoutException: print("page_number: error") page_turning(page_number)“下一页”按键示意图:
获取商品列表信息代码
1、强制等待10秒,用于刷新或滑动页面,使页面所有信息加载完成;
2、pyquery请求HTML页面信息,并进行解析;
3、商品详细信息(商品标题、价格、销量、商铺名称、地区、详情页链接、商铺链接等)
4、将获取的信息写入字典和Excel表格中;
# 获取每一页的商品信息;def get_goods(page): # 声明全局变量count global count # 获取商品前固定等待10秒,刷新/滑动界面,使所有信息都加载完成 # time.sleep(10) if input('确认界面加载完毕,输入数字“1”开始爬取-->') == 1: pass html = driver.page_source doc = pq(html) # 提取所有商品的共同父元素的类选择器 items = doc('div.contentInner--xICYBlag > a').items() for item in items: # 定位商品标题 title = item.find('.title--qJ7Xg_90 span').text() # 定位价格 price_int = item.find('.priceInt--yqqZMJ5a').text() price_float = item.find('.priceFloat--XpixvyQ1').text() if price_int and price_float: price = float(f"{price_int}{price_float}") else: price = 0.0 # 定位交易量 deal = item.find('.realSales--XZJiepmt').text() # 定位所在地信息 location = item.find('.procity--wlcT2xH9 span').text() # 定位店名 shop = item.find('.shopNameText--DmtlsDKm').text() # 定位包邮的位置 postText = item.find('.subIconWrapper--Vl8zAdQn ').text() postText = "包邮" if "包邮" in postText else "/" # 定位商品url # t_url = item.find('.Card--doubleCardWrapper--L2XFE73') # t_url = t_url.attr('href') t_url = item.attr('href') # print(t_url) # 定位店名url shop_url = item.find('.TextAndPic--grkZAtsC a') shop_url = shop_url.attr('href') # print(shop_url) # 定位商品图片url img = item.find('.mainPicWrapper--qRLTAeii img') img_url = img.attr('src') # print(img_url) # 构建商品信息字典 product = { 'Page': page, 'Num': count-1, 'title': title, 'price': price, 'deal': deal, 'location': location, 'shop': shop, 'isPostFree': postText, 'url': t_url, 'shop_url': shop_url, 'img_url': img_url } print(product) # 商品信息写入Excel表格中 wb.cell(row=count, column=1, value=page) # 页码 wb.cell(row=count, column=2, value=count-1) # 序号 wb.cell(row=count, column=3, value=title) # 标题 wb.cell(row=count, column=4, value=price) # 价格 wb.cell(row=count, column=5, value=deal) # 付款人数 wb.cell(row=count, column=6, value=location) # 地理位置 wb.cell(row=count, column=7, value=shop) # 店铺名称 wb.cell(row=count, column=8, value=postText) # 是否包邮 wb.cell(row=count, column=9, value=t_url) # 商品链接 wb.cell(row=count, column=10, value=shop_url) # 商铺链接 wb.cell(row=count, column=11, value=img_url) # 图片链接 count += 1 # 下一行获取商品列表信息示意图:

完整代码
【说明】考虑到浏览器请求数据时间长短不定,代码由“定时延时方式”改为“手动输入方式”以便留足时间等待数据请求完成;请求数据期间,可手动滑动淘宝界面,加载商品详情【注意:滑动到页面选择位置即可】加载完成后,输入数字“1”开始爬取当前页商品详情(如下图所示)。

# 代码说明:'''代码功能: 基于ChromeDriver爬取taobao(淘宝)平台商品列表数据输入参数: KEYWORLD --> 搜索商品“关键词”; pageStart --> 爬取起始页; pageEnd --> 爬取终止页;输出文件:爬取商品列表数据 'Page' :页码 'Num' :序号 'title' :商品标题 'Price' :商品价格 'Deal' :商品销量 'Location' :地理位置 'Shop' :商品 'IsPostFree' :是否包邮 'Title_URL' :商品详细页链接 'Shop_URL' :商铺链接 'Img_URL' :图片链接'''# 声明第三方库/头文件from selenium import webdriverfrom selenium.common.exceptions import TimeoutExceptionfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom pyquery import PyQuery as pqimport timeimport openpyxl as op #导入Excel读写库# 全局变量count = 1 # 写入Excel商品计数# 启动ChromeDriver服务options = webdriver.ChromeOptions()# 关闭自动测试状态显示 // 会导致浏览器报:请停用开发者模式options.add_experimental_option("excludeSwitches", ['enable-automation'])# 把chrome设为selenium驱动的浏览器代理;driver = webdriver.Chrome(options=options)# 反爬机制driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"""})driver.get('https://www.taobao.com')# 窗口最大化driver.maximize_window()# wait是Selenium中的一个等待类,用于在特定条件满足之前等待一定的时间(这里是15秒)。# 如果一直到等待时间都没满足则会捕获TimeoutException异常wait = WebDriverWait(driver,10)# 打开页面后会强制停止10秒,请在此时手动扫码登陆# 输入“关键词”,搜索,并进行首次爬取def search_goods(KEYWORD,start_page,total_pages): try: print('正在搜索: ') # 找到搜索“输入框” input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q"))) # 找到“搜索”按钮 submit = wait.until( EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_TSearchForm > div.search-button > button'))) # 输入框写入“关键词KeyWord” input.send_keys(KEYWORD) # 点击“搜索”按键 submit.click() # 搜索商品后会再强制停止5秒,如有滑块请手动操作 # time.sleep(5) # 如果不是从第一页开始爬取,就滑动到底部输入页面然后跳转 if start_page != 1: # 滑动到页面底端 # driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 滑动到底部后停留3s time.sleep(3) # 找到输入“页面”的表单,输入“起始页” pageInput = wait.until(EC.presence_of_element_located( (By.XPATH, '//*[@id="pageContent"]/div[1]/div[3]/div[4]/div/div/span[3]/input'))) pageInput.send_keys(start_page) # 找到页面跳转的“确定”按钮,并且点击 admit = wait.until(EC.element_to_be_clickable( (By.XPATH, '//*[@id="pageContent"]/div[1]/div[3]/div[4]/div/div/button[3]'))) admit.click() # 获取商品信息 get_goods(start_page) # 翻页操作 for i in range(start_page + 1, total_pages+1): page_turning(i) except TimeoutException: print("search_goods: error") return search_goods(KEYWORD,start_page,total_pages)# 翻页函数def page_turning(page_number): print('正在翻页: ', page_number) try: # 强制等待2秒后翻页 time.sleep(2) # 找到“下一页”的按钮 submit = wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="search-content-leftWrap"]/div[2]/div[4]/div/div/button[2]'))) submit.click() # 判断页数是否相等 wait.until(EC.text_to_be_present_in_element((By.XPATH, '//*[@id="search-content-leftWrap"]/div[2]/div[4]/div/div/span[1]/em'), str(page_number))) get_goods(page_number) except TimeoutException: print("page_number: error") page_turning(page_number)# 获取每一页的商品信息;def get_goods(page): # 声明全局变量count global count # 获取商品前固定等待10秒,刷新/滑动界面,使所有信息都加载完成 # time.sleep(10) if input('确认界面加载完毕,输入数字“1”开始爬取-->') == 1: pass html = driver.page_source doc = pq(html) # 提取所有商品的共同父元素的类选择器 items = doc('div.contentInner--xICYBlag > a').items() for item in items: # 定位商品标题 title = item.find('.title--qJ7Xg_90 span').text() # 定位价格 price_int = item.find('.priceInt--yqqZMJ5a').text() price_float = item.find('.priceFloat--XpixvyQ1').text() if price_int and price_float: price = float(f"{price_int}{price_float}") else: price = 0.0 # 定位交易量 deal = item.find('.realSales--XZJiepmt').text() # 定位所在地信息 location = item.find('.procity--wlcT2xH9 span').text() # 定位店名 shop = item.find('.shopNameText--DmtlsDKm').text() # 定位包邮的位置 postText = item.find('.subIconWrapper--Vl8zAdQn ').text() postText = "包邮" if "包邮" in postText else "/" # 定位商品url # t_url = item.find('.Card--doubleCardWrapper--L2XFE73') # t_url = t_url.attr('href') t_url = item.attr('href') # print(t_url) # 定位店名url shop_url = item.find('.TextAndPic--grkZAtsC a') shop_url = shop_url.attr('href') # print(shop_url) # 定位商品图片url img = item.find('.mainPicWrapper--qRLTAeii img') img_url = img.attr('src') # print(img_url) # 构建商品信息字典 product = { 'Page': page, 'Num': count-1, 'title': title, 'price': price, 'deal': deal, 'location': location, 'shop': shop, 'isPostFree': postText, 'url': t_url, 'shop_url': shop_url, 'img_url': img_url } print(product) # 商品信息写入Excel表格中 wb.cell(row=count, column=1, value=page) # 页码 wb.cell(row=count, column=2, value=count-1) # 序号 wb.cell(row=count, column=3, value=title) # 标题 wb.cell(row=count, column=4, value=price) # 价格 wb.cell(row=count, column=5, value=deal) # 付款人数 wb.cell(row=count, column=6, value=location) # 地理位置 wb.cell(row=count, column=7, value=shop) # 店铺名称 wb.cell(row=count, column=8, value=postText) # 是否包邮 wb.cell(row=count, column=9, value=t_url) # 商品链接 wb.cell(row=count, column=10, value=shop_url) # 商铺链接 wb.cell(row=count, column=11, value=img_url) # 图片链接 count += 1 # 下一行# 爬虫main函数def Crawer_main(KEYWORD,pageStart,pageEnd): try: # 爬取从pageStart到pageAll页的数据 search_goods(KEYWORD,pageStart,pageEnd) except Exception as exc: print('Crawer_main函数报错:', exc)if __name__ == '__main__': KEYWORD = input('输入搜索的商品关键词Keyword:') # 要搜索的商品的关键词 pageStart = int(input('输入爬取的起始页PageStart:')) # 爬取起始页 pageEnd = int(input('输入爬取的终止页PageEnd:')) # 爬取终止页 # 建立Excel表格 try: ws = op.Workbook() # 创建Workbook wb = ws.create_sheet(index=0) # 创建worsheet # Excel第一行:表头 title_list = ['Page', 'Num', 'title', 'Price', 'Deal', 'Location', 'Shop', 'IsPostFree', 'Title_URL', 'Shop_URL', 'Img_URL'] for i in range(0, len(title_list)): wb.cell(row=count, column=i + 1, value=title_list[i]) count += 1 # 从第二行开始写爬取数据 except Exception as exc: print("Excel建立失败!") # 开始爬取数据 Crawer_main(KEYWORD,pageStart,pageEnd) # 保存Excel表格 Filename = input("输入存储文件名称:") Filename = Filename + '_From_Taobao.xlsx' ws.save(filename = Filename) print(Filename + "存储成功~")【不足】不足之处,恳请批评指正,我们共同进步!
【鸣谢】特别感谢“芝士胡椒粉”的文章指导!