迭代器(Iterator)和生成器(Generator)在python中都是处理序列数据时非常重要的概念,它们都属于python的迭代协议的一部分,用于遍历数据集合。
目录
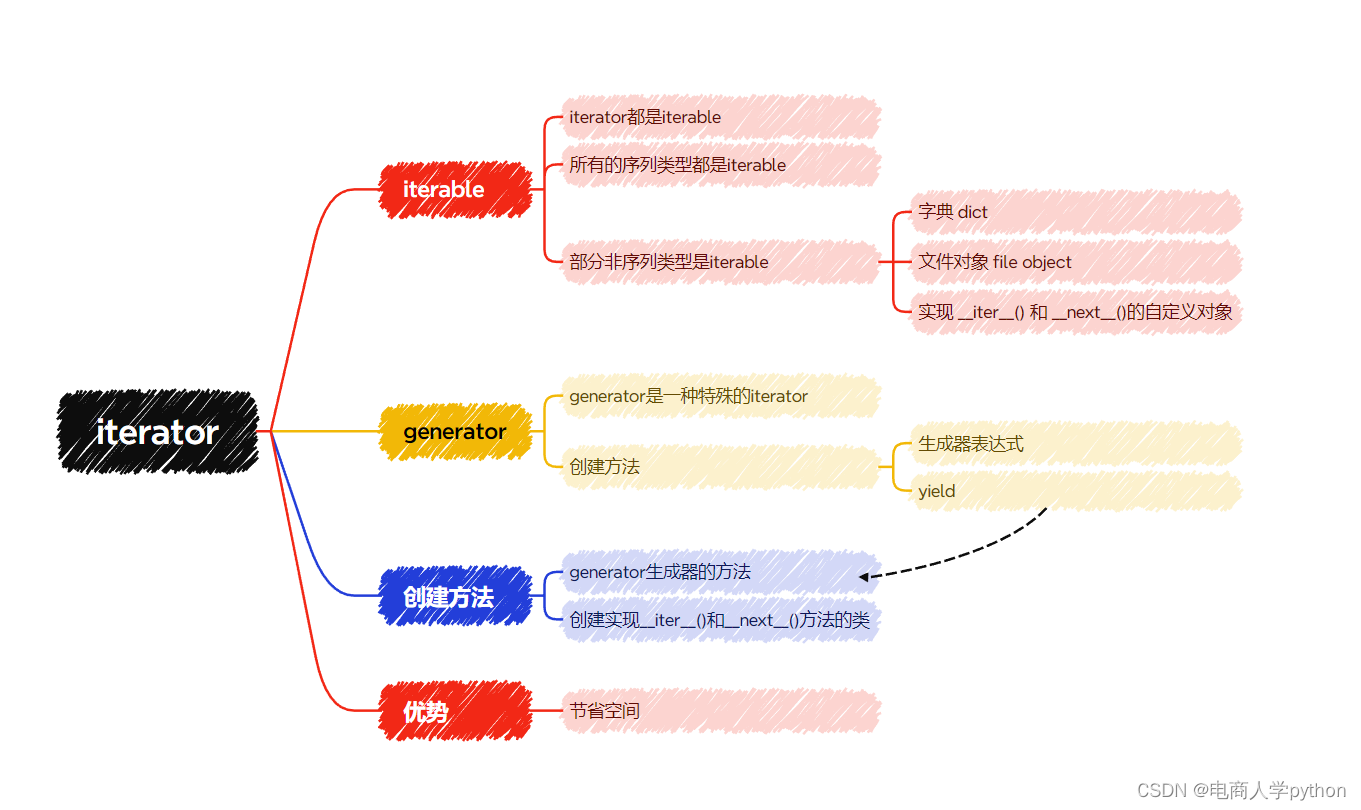
一、迭代器
1、什么是迭代器
2、创建迭代器
1)、内置类型迭代:
2)、自定义迭代器类:
二、生成器
1、什么是生成器
2、创建生成器
方式1:
方式2:
3、访问生成器
方式1:
方式2:
方式3:
方式4:
4、生成器的应用实例:
三、总结
生成器(Generator)
一、迭代器
1、什么是迭代器
迭代器(Iterator)是一种设计模式和编程接口,它在计算机科学中扮演着至关重要的角色,特别是在处理集合数据结构时。迭代器提供了一种标准的方法来访问一个容器对象中的元素序列,而无需暴露容器的底层实现细节。
迭代器是一个实现了迭代协议的对象,它可以让我们遍历一个容器中的所有元素,而不需要知道容器的内部结构,迭代器可以被用于遍历列表、元组、字典、集合等容器类型。迭代器的工作原理是通过实现两个方法:__iter__()和__next__()方法,__iter__()方法返回迭代器对象本身,__next__()方法每次调用都会返回容器中的下一个元素,直到容器中的所有元素都被遍历完毕后,再调用__next__()方法就会抛出StopIteration异常,表示迭代已结束。Python内置的数据类型如列表、元组、字符串等,以及自定义的类,只要实现了这两个方法,都可以作为迭代器使用。在Python中,几乎只要涉及有序访问一组元素而无需同时将所有元素保留在内存中时,都可能用到迭代器。python的for循环就是通过迭代器来实现的,当我们使用for循环遍历一个容器时,python会自动创建一个迭代对象,并调用__next__()方法来获取容器中的下一个元素,知道容器中的所有元素都被遍历完毕。除了使用for循环,还可以使用iter()函数来手动创建一个迭代器对象,并使用next()函数来获取容器中的下一个元素,这种方式可以让我们更灵活地控制迭代的过程。迭代器可以让我们更加方便的遍历容器中的元素,提高代码可读性和可维护性。
可以直接作用于for循环的数据类型有:1、集合数据类型,如list、tuple、dict、set、str等;2、generator,包括生成器和带yeild的generator function。这些可以直接作用于for循环的对象统称为可迭代对象:iterable;而可以被next()函数调用并不断返回下一个值的对象称为迭代器:iterator。
list,dict,str虽然是iterable,却不是iterator
from collections.abc import Iterator,Iterabledic={}lis=[]str1="123"print(isinstance(dic,Iterable),isinstance(lis,Iterable),isinstance(str1,Iterable)) #True True Trueprint(isinstance(dic,Iterator),isinstance(lis,Iterator),isinstance(str1,Iterator)) #False False False注:为什么list、dict、str等数据类型不是Iterator?---因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。Iterator甚至可以表示一个无限大的数据流,例如全体自然数,而使用list是永远不可能存储全体自然数的。
小结:
1、凡是可作用于for循环的对象都是Iterable类型;
2、凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
3、集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
再举个生活例子来解释一下迭代器:
迭代器这个概念,其实可以把它比喻成一个在图书馆里帮你找书的图书管理员。想象一下:
在图书馆中,图书按照一定的规则排列在不同的书架上。我们想要读遍整个图书馆的所有书籍,但不需要一次性把所有书都搬出来堆在一起。
这时,图书管理员(迭代器)就出场了。你只需要告诉管理员:“我想一本接一本地看所有的书。”管理员就会从第一个书架的第一个位置开始,每次给你取出一本书,并告诉你书的名字和内容(即访问集合中的每个元素)。当你看完一本后,只需说一声“下一本”,管理员就会找到下一个书的位置并递给你(调用next()方法获取下一个元素)。
如果图书馆很大,图书很多,而你的书包很小(内存有限),那么这个图书管理员服务就显得非常实用且高效,因为它只在你需要的时候才取出下一本书,而不是一次性拿出所有书占用大量空间。
当图书馆里的书都被你看完了(容器中所有元素都被访问过),管理员会告诉你没有更多的书可看了(抛出StopIteration异常),这意味着遍历过程结束。
这样,通过迭代器,你可以方便地按照一定顺序逐个访问一组数据,无需关心这些数据是如何存储或组织的,就像你不用了解图书馆的内部布局一样,只需要和图书管理员打交道即可。
2、创建迭代器
1)、内置类型迭代:
对于Python内置的可迭代对象(如列表、元组、字符串、字典、集合等),可以直接通过调用内建函数iter()来获取对应的迭代器。
list1=[1,2,3]list_it=iter(list1)print(isinstance(list_it,Iterator)) #Trueprint(next(list_it)) #输出1print(next(list_it)) #输出2print(next(list_it)) #输出3# print(next(list_it))'''遍历完容器,没有数据后继续next()调用会报错: print(next(list_it))StopIteration'''dict1={1:1,2:2,3:3}dict_it=iter(dict1)print(isinstance(dict_it,Iterator))print(next(dict_it)) #输出1print(next(dict_it)) #输出2print(next(dict_it)) #输出3str2='123'str_it=iter(str2)print(isinstance(str_it,Iterator))print(next(str_it))#输出1print(next(str_it))#输出2print(next(str_it))#输出3Python的for循环本质上就是通过不断调用next()函数实现的:
list2=[1,2,3,4,5]for i in list2: print(i,end=',')#输出1,2,3,4,5,print('')#等价于list2_it=iter(list2)while True: try: print(next(list2_it),end=',') except StopIteration: #遇到StopIteration就退出循环 break#输出1,2,3,4,5,2)、自定义迭代器类:
也可以通过定义一个类,实现__iter__()方法和__next__()方法来自定义迭代器。类都有一个构造函数,Python 的构造函数为 __init__(), 它会在对象初始化的时候执行。__iter__() 方法返回一个特殊的迭代器对象, 这个迭代器对象实现了 __next__() 方法并通过 StopIteration 异常标识迭代的完成。
class CustomIterator: def __init__(self, data): self.data = data self.index = 0 def __iter__(self): return self def __next__(self): if self.index >= len(self.data): raise StopIteration value = self.data[self.index] self.index += 1 return valuelist3=[1,2,3,4]list3_it=CustomIterator(list3)print(list3_it)print(list3_it.__next__())print(list3_it.__next__())print(list3_it.__next__())print(list3_it.__next__())print(list3_it.__next__())'''<__main__.CustomIterator object at 0x000001DD3AB5BE50>1234 raise StopIterationStopIteration'''二、生成器
1、什么是生成器
是Python中一种特殊的迭代器,它是一个能按需生成值的轻量级对象。与一次性创建所有元素的数据结构(如列表或元组)不同,生成器在每次迭代时只生成下一个值,从而节省内存并支持无限序列或其他大量数据流的操作。
使用了 yield 的函数被称为生成器(generator)。
yield 是一个关键字,用于定义生成器函数,生成器函数是一种特殊的函数,可以在迭代过程中逐步产生值,而不是一次性返回所有结果。跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。当在生成器函数中使用 yield 语句时,函数的执行将会暂停,并将 yield 后面的表达式作为当前迭代的值返回。然后,每次调用生成器的 next() 方法或使用 for 循环进行迭代时,函数会从上次暂停的地方继续执行,直到再次遇到 yield 语句。这样,生成器函数可以逐步产生值,而不需要一次性计算并返回所有结果。调用一个生成器函数,返回的是一个迭代器对象。列表推导式更加耗时,消耗系统内存;生成器存储数据是实际上算法的存储,更节约时间,节省内存。代码演示一下:
import timeit # 时间模块import sys # 系统模块 可以通过getsizeof() 计算变量在内存中所使用的内存消耗list_1 = [x for x in range(2, 1000000, 2)]t=timeit.timeit(stmt='list_1 = [x for x in range(2, 1000000, 2)]',number=10)print(f"创建列表耗时{t:f}")print(f"创建列表内存消耗{sys.getsizeof(list_1):d}")gen_1=(x for x in range(2,1000000,2))t1=timeit.timeit(stmt='gen_1=(x for x in range(2,1000000,2))',number=10)print(f"创建生成器耗时{t1:f}")print(f"创建生成器内存消耗{sys.getsizeof(gen_1):d}")'''创建列表耗时0.266365创建列表内存消耗4167352创建生成器耗时0.000007创建生成器内存消耗104'''#可以明显看到创建生成器耗时以及内存消耗都比创建列表小很多2、创建生成器
方式1:
生成器表达式: 元组推导式
gen_2 = (i * 2 for i in range(5)) # 创建一个生成器表达式print(gen_2) # <generator object <genexpr> at 0x0000027D27CCD850>方式2:
生成器函数: 通过在函数内部使用 yield 关键字定义一个生成器函数。当调用这个函数时,它并不会立即执行函数体,而是返回一个生成器对象。每当对生成器对象进行迭代时,函数会在每个 yield 语句处暂停,并返回一个值,然后在下一次迭代时从上次离开的地方继续执行。
def gen_func(): for x in range(5): yield xf=gen_func()print(f) #<generator object gen_func at 0x0000019A1355D7E0>print(next(f))# 0print(next(f))# 13、访问生成器
方式1:
for循环遍历
gen_list = (x for x in range(2, 10, 2))for i in gen_list: print(i)'''2468'''方式2:
使用next(object)方法访问
gen_list = (x for x in range(2, 10, 2))print(next(gen_list))print(next(gen_list))print(next(gen_list))print(next(gen_list))print(next(gen_list)) #需要注意:超出生成器生成数据的范围,会报错StopIteration'''2468 print(next(gen_list))StopIteration'''方式3:
使用__next__()方法访问
gen_list = (x for x in range(2, 10, 2))print(gen_list.__next__())print(gen_list.__next__())print(gen_list.__next__())print(gen_list.__next__())print(gen_list.__next__())#需要注意:超出生成器生成数据的范围,会报错StopIteration'''2468 print(gen_list.__next__())StopIteration'''方式4:
send() 方法是 Python 中生成器(generator)的一个方法,用于在生成器内部发送一个值并继续执行到下一个 yield 语句。当调用 send(value) 时,这个 value 将会作为上一个 yield 表达式的返回值。
def simple_generator(): value = None while True: received_value = (yield value) # 如果 send() 第一次被调用或者传入了 None,则 received_value 为 None if received_value is not None: value = received_value * 2 # 对接收到的值进行处理# 创建一个生成器对象gen = simple_generator()# 启动生成器,获取第一个 yield 的返回值(默认为 None)first_value = next(gen) # first_value 是 Noneprint(first_value) # 输出:None,因为上一个 yield 表达式返回了 None# 使用 send() 方法发送一个值response = gen.send(5) # 这里,5 将会被赋值给上一个 yield 表达式,并将 5 * 2 赋值给 valueprint(response) # 输出:10,因为这次 send(5) 后,生成器内部将 5 * 2 赋值给 value# 继续发送另一个值response = gen.send(10)print(response) # 输出:20,因为这次 send(10) 后,生成器内部将 10 * 2 返回给了 response# 可以继续这样交互,直到生成器停止或抛出异常'''在这个例子中,send() 方法用于与生成器之间传递信息和控制流,实现了类似协程的功能。注意首次调用 send() 前需要先通过 next() 函数启动生成器,之后才能正常发送值。如果在没有调用过 next() 或者 send(None) 之前直接调用 send(),将会导致 TypeError: can't send non-None value to a just-started generator 错误。'''再来一个例子展示send()方法如何工作:
# 定义一个生成器函数,模拟银行账户存款和取款的过程def bank_account(): balance = 0 # 初始余额为0 while True: print(f"当前余额: {balance},") amount = (yield balance) # yield语句暂停并返回当前余额 # 使用send()方法时,amount将接收外部传入的值 if amount is not None: if amount > 0: #如果发送的金额大于0,则为存款操作,余额增加相应金额 balance += amount print(f"存入了{amount}元") elif amount < 0: #如果发送的金额小于0,则为取款操作, if balance + amount >= 0: #若余额充足则余额减少相应金额 balance += amount print(f"取出{abs(amount)}元") else: #否则打印"余额不足,无法取出!" print("余额不足,无法取出!") else: print("没有操作金额")# 创建生成器实例account = bank_account()next(account) # 初始化生成器,执行到第一个yield语句# 使用send()方法进行存款和取款操作account.send(1000) # 存入1000元时,余额更新为1000元,并打印相应信息;'''当前余额: 0,存入了1000元当前余额: 1000,'''account.send(-500) # 取出500元时,余额减至500元,并打印相应信息;'''取出500元当前余额: 500,'''account.send(-1000) # 尝试取出1000元时,由于余额不足,只打印“余额不足,无法取出!”的信息,但下一轮循环依然会打印当前真实的余额:500元。'''余额不足,无法取出!当前余额: 500,'''4、生成器的应用实例:
斐波那契数列
#1-用函数打印斐波那契数列:def fib(n): sequence = [] a, b = 0, 1 for _ in range(n): sequence.append(a) a, b = b, a + b return sequenceprint(fib(5)) # [0, 1, 1, 2, 3]#2-使用生成器生成斐波那契数列(无限序列)def fibonacci(): a, b = 0, 1 while True: yield a a, b = b, a + bgen = fibonacci()for _ in range(10): print(next(gen),end=',') #0,1,1,2,3,5,8,13,21,34,生成器(generator)与普通函数在执行流程上的差异是其核心特性之一
普通函数:当调用一个普通函数时,它会从函数的第一行代码开始顺序执行,直到遇到return语句或者执行到函数的最后一行。返回值是在函数执行过程中遇到return时确定的,并且一旦函数执行完毕,它的内部状态就会被销毁。生成器函数:而定义为生成器的函数会在每次调用next()方法或使用for循环迭代时才执行。首次调用时,函数会运行到第一个yield表达式并暂停,同时返回yield后面的值。此后每次调用next()时,函数都会从上次暂停的地方继续执行,再次遇到yield表达式时再次暂停并返回新的值。这种“分段执行”和“状态保留”的机制使得生成器特别适合处理大量数据流或需要保持中间状态的任务,比如斐波那契数列生成、文件读取等场景。总结来说,生成器是一种特殊的迭代器,可以控制程序的执行流程,按需产生结果,并能够在多次调用之间保持内部状态。
三、总结
总结一下迭代器和生成器的应用场景
迭代器(Iterator)
遍历大型数据集:当处理无法一次性加载到内存中的大文件、数据库记录或大规模数据结构时,迭代器可以逐条读取数据,无需全部加载,从而节省内存。循环遍历任何可迭代对象:包括列表、元组、字典、集合、字符串以及自定义的可迭代类型。for 循环等语句会自动调用迭代器来访问容器内的元素。无限序列:用于生成斐波那契数列、阶乘序列或其他无限序列,每次仅计算下一个值。
生成器(Generator)
延迟计算/惰性求值:生成器允许按需生成结果,适合处理大量计算密集型或IO密集型任务,比如大数据流处理,只在需要时才执行计算并产出结果。资源管理:在需要有限资源的情况下,例如打开文件并逐行读取内容,生成器可以在读取完一行后释放相关资源,然后在下一次请求时重新获取资源。节省内存空间:类似于迭代器,但更加灵活。在函数中使用yield 关键字暂停函数的执行,并在下次调用时从上次停止的地方恢复,这样在生成复杂数据结构时避免了同时存储所有中间结果的开销。 综上所述,迭代器和生成器是Python中用来简化代码、优化性能和管理资源的重要工具,在处理大规模数据、编写高效算法及构建复杂程序逻辑时发挥着重要作用。
希望以上内容能有效帮助大家理解运用迭代器与生成器!