贝叶斯最优化(Bayesian Optimization)是一种用于函数全局最优化的策略,特别适用于那些计算代价昂贵的黑箱函数(如机器学习模型的超参数调优)。其核心思想是通过构建一个代理模型(通常是高斯过程或随机森林),逐步选择最优的参数,从而有效地找到全局最优解。贝叶斯最优化能够在不需要大量计算资源的情况下,有效探索参数空间,具有更高效、更严密的特点。
贝叶斯最优化的原理
初始采样:
随机选择一些参数点,并计算对应的目标函数值。这些点和目标函数值将用于初始化代理模型。构建代理模型:
使用高斯过程(Gaussian Process, GP)或随机森林(Random Forest)等方法,构建目标函数的代理模型。高斯过程常用,因为它不仅能预测函数值,还能提供预测不确定性。代理模型优化:
使用代理模型预测新的参数点的目标函数值和不确定性。基于这些预测,计算一个采集函数(Acquisition Function),如期望改进(Expected Improvement, EI),上置信界(Upper Confidence Bound, UCB)等。采集函数用来平衡探索(exploration)和开发(exploitation)之间的权衡。 探索:选择那些不确定性较大的点,希望发现新的好点。开发:选择那些预计目标函数值较好的点,利用已有信息改进最优解。更新代理模型:
在采集函数的指导下选择下一个参数点,计算其目标函数值。将新的数据点加入已有的数据集中,更新代理模型。重复迭代:
重复步骤3和4,逐步缩小参数空间,找到最优参数。迭代过程在达到预设的迭代次数或收敛条件时结束。贝叶斯最优化的优势
高效性:
贝叶斯最优化通过代理模型有效地探索参数空间,减少了直接计算目标函数的次数,适合计算昂贵的优化问题。平衡探索与开发:
通过采集函数,贝叶斯最优化能很好地平衡探索未知区域和利用已知好区域,避免陷入局部最优。不确定性量化:
高斯过程能提供预测不确定性,这有助于更好地指导采样过程。应用领域
贝叶斯最优化广泛应用于机器学习中的超参数调优,如:
深度学习模型中的超参数调优(学习率、批量大小、网络结构等)。机器学习算法(如支持向量机、随机森林等)的参数设置。强化学习中的策略优化。总之,贝叶斯最优化在处理高维、非凸、计算代价昂贵的优化问题时,提供了一种高效且严密的方法。
示例
# -*- coding: utf-8 -*-import numpy as npimport matplotlib.pyplot as pltfrom sklearn.gaussian_process import GaussianProcessRegressorfrom sklearn.gaussian_process.kernels import Maternfrom scipy.optimize import minimizefrom scipy.stats import norm# 目标函数:f(x, y) = \sin(x) + \cos(y)def objective_function(x): return np.sin(x[0]) + np.cos(x[1])# 采集函数:期望改进def acquisition_function(x, gp, y_max): mean, std = gp.predict(np.array([x]), return_std=True) z = (mean - y_max - 0.01) / std return (mean - y_max - 0.01) * norm.cdf(z) + std * norm.pdf(z)# 绘制目标函数热力图x = np.linspace(-5, 5, 100)y = np.linspace(-5, 5, 100)X, Y = np.meshgrid(x, y)Z = np.sin(X) + np.cos(Y)plt.figure(figsize=(10, 7))plt.contourf(X, Y, Z, levels=50, cmap='viridis')plt.colorbar(label='Objective Function Value')plt.title('Objective Function Heatmap')plt.xlabel('x')plt.ylabel('y')# 初始化随机采样点initial_points = np.random.uniform(-5, 5, (5, 2))initial_values = np.array([objective_function(x) for x in initial_points])# 高斯过程模型kernel = Matern(nu=2.5)gp = GaussianProcessRegressor(kernel=kernel, n_restarts_optimizer=10)gp.fit(initial_points, initial_values)# 贝叶斯优化过程n_iter = 15for i in range(n_iter): y_max = max(initial_values) res = minimize(lambda x: -acquisition_function(x, gp, y_max), x0=np.random.uniform(-5, 5, 2), bounds=[(-5, 5), (-5, 5)]) next_sample = res.x next_value = objective_function(next_sample) initial_points = np.vstack((initial_points, next_sample)) initial_values = np.append(initial_values, next_value) gp.fit(initial_points, initial_values) plt.scatter(next_sample[0], next_sample[1], c='red') plt.scatter(initial_points[:, 0], initial_points[:, 1], c='black', label='Samples')plt.legend()plt.show()这段代码实现了贝叶斯优化算法,用于优化一个二维目标函数 f ( x , y ) = sin ( x ) + cos ( y ) f(x, y) = \sin(x) + \cos(y) f(x,y)=sin(x)+cos(y)。下面是代码的具体实现步骤及其功能:
代码实现步骤及功能
导入必要的库:
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.gaussian_process import GaussianProcessRegressorfrom sklearn.gaussian_process.kernels import Maternfrom scipy.optimize import minimizefrom scipy.stats import norm定义目标函数:
def objective_function(x): return np.sin(x[0]) + np.cos(x[1])定义采集函数:
def acquisition_function(x, gp, y_max): mean, std = gp.predict(np.array([x]), return_std=True) z = (mean - y_max - 0.01) / std return (mean - y_max - 0.01) * norm.cdf(z) + std * norm.pdf(z)绘制目标函数热力图:
x = np.linspace(-5, 5, 100)y = np.linspace(-5, 5, 100)X, Y = np.meshgrid(x, y)Z = np.sin(X) + np.cos(Y)plt.figure(figsize=(10, 7))plt.contourf(X, Y, Z, levels=50, cmap='viridis')plt.colorbar(label='Objective Function Value')plt.title('Objective Function Heatmap')plt.xlabel('x')plt.ylabel('y')初始化随机采样点:
initial_points = np.random.uniform(-5, 5, (5, 2))initial_values = np.array([objective_function(x) for x in initial_points])构建高斯过程模型:
kernel = Matern(nu=2.5)gp = GaussianProcessRegressor(kernel=kernel, n_restarts_optimizer=10)gp.fit(initial_points, initial_values)贝叶斯优化过程:
n_iter = 15for i in range(n_iter): y_max = max(initial_values) res = minimize(lambda x: -acquisition_function(x, gp, y_max), x0=np.random.uniform(-5, 5, 2), bounds=[(-5, 5), (-5, 5)]) next_sample = res.x next_value = objective_function(next_sample) initial_points = np.vstack((initial_points, next_sample)) initial_values = np.append(initial_values, next_value) gp.fit(initial_points, initial_values) plt.scatter(next_sample[0], next_sample[1], c='red') plt.scatter(initial_points[:, 0], initial_points[:, 1], c='black', label='Samples')plt.legend()plt.show()结果
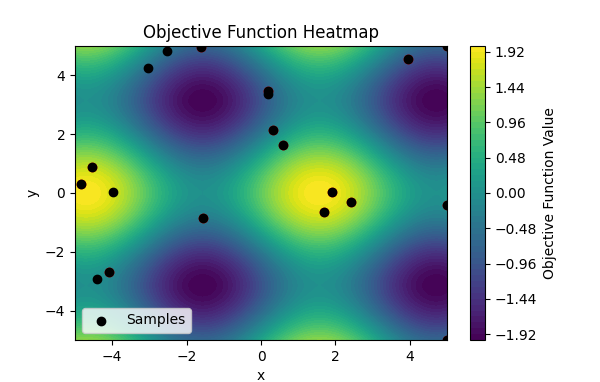
这个热力图展示了目标函数 ( f(x, y) = \sin(x) + \cos(y) ) 在二维空间中的值分布。以下是图中的一些要点及其与代码的关系:
热力图的解释
颜色表示目标函数值:
颜色从紫色到黄色,表示目标函数值从低到高。紫色区域表示目标函数值较低的区域,而黄色区域表示目标函数值较高的区域。图右侧的颜色条显示了目标函数值的范围,从大约 -1.92 到 1.92。坐标轴:
x 轴和 y 轴分别表示参数 ( x ) 和 ( y ) 的取值范围,从 -5 到 5。这个范围内的每个点都有一个对应的目标函数值 ( f(x, y) ),其大小由图中的颜色表示。采样点:
图中的黑色点表示采样点,即在优化过程中实际计算了目标函数值的点。初始的几个采样点是随机选择的,而后续的采样点是通过贝叶斯优化过程选择的。代码的解释与图结合
代码通过以下步骤生成了这个热力图并选择采样点:
目标函数的热力图:
代码生成了一组 ( x ) 和 ( y ) 值的网格(通过np.meshgrid),并计算了每个网格点的目标函数值 ( \sin(x) + \cos(y) )。使用 plt.contourf 绘制目标函数值的等高线图,颜色表示目标函数值的大小。 初始化随机采样点:
初始采样点通过np.random.uniform 在范围 [-5, 5] 内随机生成,代码中的 initial_points 和 initial_values 保存了这些点及其对应的目标函数值。图中的一些黑色点表示这些初始采样点。 高斯过程模型拟合和更新:
使用高斯过程回归模型拟合初始采样点及其目标函数值。在每次迭代中,通过最小化采集函数(期望改进函数)选择下一个采样点,这个采样点是优化过程中认为可能改进最大的点。采样点的可视化:
在每次新的采样点被选择并计算其目标函数值后,代码通过plt.scatter 将新的采样点绘制在图上(红色点)。最后使用黑色点(plt.scatter(initial_points[:, 0], initial_points[:, 1], c='black', label='Samples'))表示所有采样点。 总结
热力图展示了目标函数在二维空间中的值分布。
黑色点表示在贝叶斯优化过程中计算目标函数值的采样点。
贝叶斯优化过程通过代理模型(高斯过程)逐步选择新的采样点,以高效找到目标函数的全局最优解。
通过可视化,可以直观地看到采样点如何逐步分布在目标函数的高值区域。
代码通过贝叶斯优化算法在目标函数的二维参数空间中逐步逼近最优值。
初始随机采样点经过高斯过程模型的拟合和采集函数的引导,逐步找到目标函数的最优解。
可视化部分展示了采样点如何逐步逼近最优区域。
通过这个过程,贝叶斯优化有效地减少了目标函数评估次数,同时能够在计算代价昂贵的情况下找到全局最优解。