找往期文章包括但不限于本期文章中不懂的知识点:
个人主页:我要学编程(ಥ_ಥ)-CSDN博客
所属专栏: Python
目录
集合
相关概念
集合的创建与删除
集合的操作符
集合的相关操作方法
集合的遍历
集合生成式
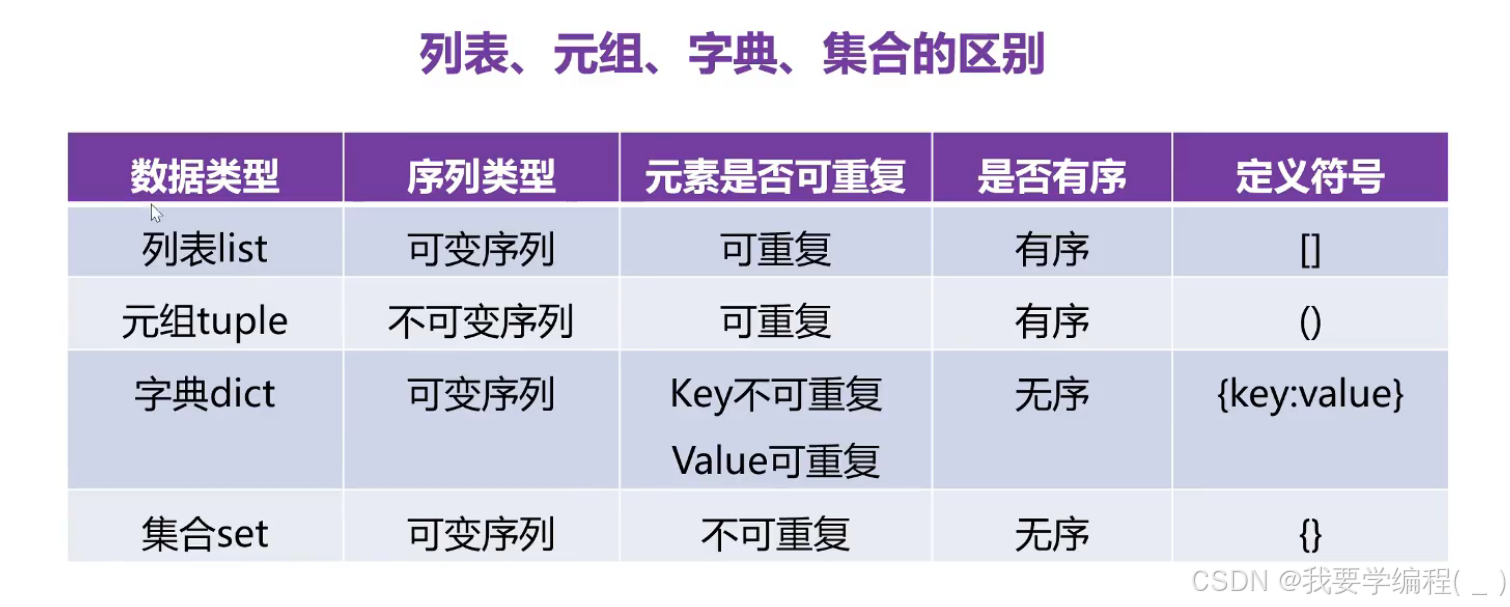
列表、元组、字典、集合的区别
Python3.11新特性
结构模型匹配
字典合并运算符
同步迭代
集合
相关概念
Python中的集合是一个无序的不重复元素序列。也就是说这个集合是天然的去重容器,学过数据结构的小伙伴应该可以联想到 Set的用法。
集合中只能存储不可变数据类型。例如,整型、字符串、元组等,但像列表、字典等类型是不能够存放的。集合与列表、字典一样,都是Python中的可变数据类型。
集合是序列的一种,因此操作序列的相关方法也可以用来操作集合。
集合的创建与删除
语法:
# 使用{}创建集合s = {elem1,elem2,...,elemN}# 使用内置函数set()创建集合s = set(e) # e必须是可迭代的对象代码演示:
# 1、使用{}创建集合s = {1,'Hello',('Python',5)}print(s) # {1, ('Python', 5), 'Hello'}# 2、使用内置函数set创建集合s = set([1,2,3,4]) # 列表是属于序列,即可迭代的对象print(s) # {1, 2, 3, 4}s = set('Hello Python')print(s) # {' ', 'P', 't', 'e', 'n', 'H', 'l', 'h', 'y', 'o'}# 创建空集合print({}, type({})) # {} <class 'dict'>print(set(), type(set())) # set() <class 'set'>从上面的输出结果,我们也可以知道,集合是无序的。
注意:创建空集合,只能使用 内置函数set ,而不能使用 {} 去创建。
可迭代对象与序列的关系:序列是可迭代对象的一种。
集合的删除也是使用 del 关键字:
del 集合名集合的操作符
由于Python中的集合与数学中的集合是一个概念,因此集合与集合也有一些操作。例如,交集等。
语法:
A = {e1,e2,...,eN}B = {elem1,elem2,...,elemN}# 交集A & B# 并集A | B# 差集A - B# 补集A ^ B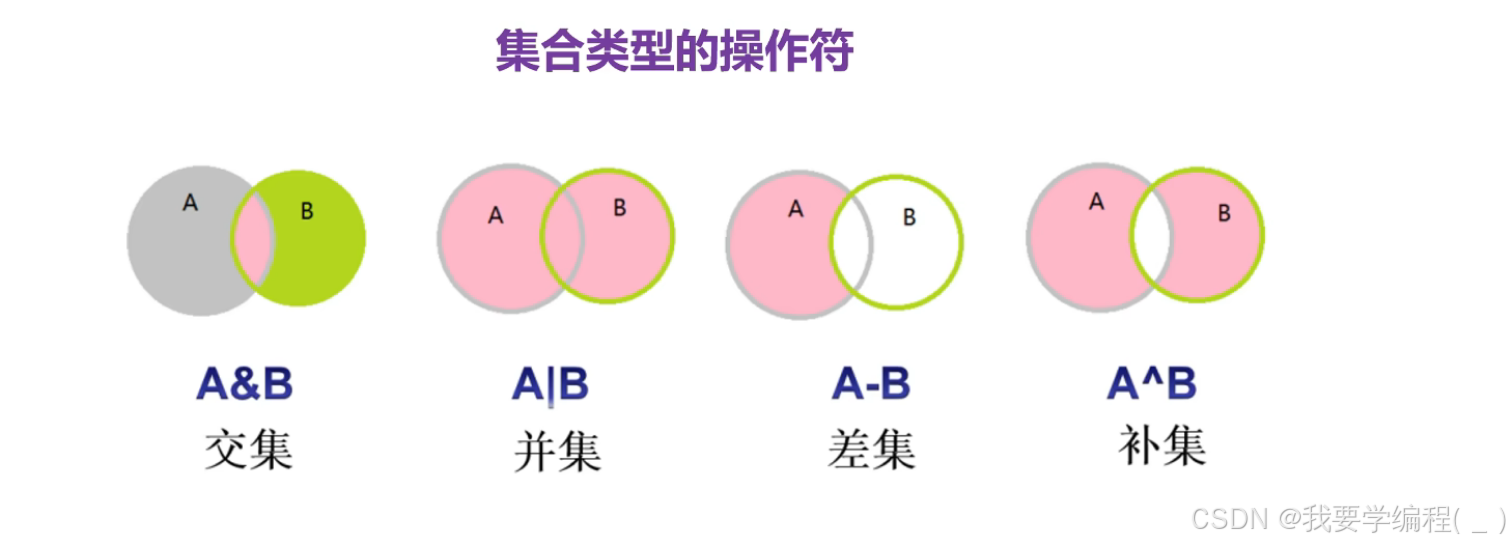
差集的结果是和前面的一个集合的结果有关,即前面一个集合中不在后面一个集合中出现的元素所组成的集合,便是差集。
代码演示:
A = {1,2,3,4,5}B = {1,3,5,7,9}# 交集print(A&B) # {1, 3, 5}# 并集print(A|B) # {1, 2, 3, 4, 5, 7, 9}# 差集print(A-B) # {2, 4}# 补集print(A^B) # {2, 4, 7, 9}集合的相关操作方法
| 方法 | 描述 |
| s.add(x) | 如果x不在集合s中,则将x添加到集合s |
| s.remove(x) | 如果x在集合中,将其删除,如果不在集合中,程序报错 |
| s.clear() | 清除集合中所有元素 |
代码演示:
s = {1,2,3,4,5}s.add(8)print(s) # {1, 2, 3, 4, 5, 8}s.remove(3)print(s) # {1, 2, 4, 5, 8}s.clear()print(s) # set()集合的遍历
语法:
# 1、使用for循环遍历for item in s: print(item)# 2、使用enumerate函数遍历for index,item in enumerate(s): print(index,item)# index 是序号,可以手动修改的代码演示:
# 1、通过for循环遍历s = {1,2,3,4,5}for item in s: print(item,end=' ')print()# 2、使用enumerate函数遍历for index,item in enumerate(s): print(index,'-->',item)# 0 --> 1# 1 --> 2# 2 --> 3# 3 --> 4# 4 --> 5集合生成式
语法:
s = {i for i in range(1,5)}代码演示:
# 集合生成式s = {random.randint(1,100) for i in range(1,5)}print(s) # {34, 2, 82, 7} --> 随机输出的到现在为止,Python中的数据类型基本上已经学完了。我们现在回过头来看,发现这些数据类型也是有很多的相似之处的。例如,生成式、遍历、可变数据类型的相关操作方法等这些基本上框架都是一样的。这也有利于我们学习记忆。
列表、元组、字典、集合的区别
Python3.11新特性
结构模型匹配
虽然Python中没有与C语言、Java那样的switch-case 语句,但在Python3.11之后加入了结构模式匹配,虽不如switch-case那样灵活,但是也是可以避免多重 if-else 造成的可读性差。
data = eval(input('请输入你的成绩:'))if data < 60: print('你的成绩等级是:E')elif 60 <= data < 70: print('你的成绩等级是:D')elif 70 <= data < 80: print('你的成绩等级是:C')elif 80 <= data < 90: print('你的成绩等级是:B')elif 90 <= data <= 100: print('你的成绩等级是:A')else: print('输入错误')上面是多重 if-else 的语句,下面我们来使用match-case语句:
data = eval(input('请输入你的成绩:'))match data: # data表示要匹配的数据 case _ if data < 60: # _表示匹配任何值,也就是通配符 print('你的成绩等级是:E') case _ if 60 <= data < 70: print('你的成绩等级是:D') case _ if 70 <= data < 80: print('你的成绩等级是:C') case _ if 80 <= data < 90: print('你的成绩等级是:B') case _ if 90 <= data <= 100: print('你的成绩等级是:A') case _: print('输入错误')case 后面的 "_" 是一个通配符,必须写上。
上面是match-case的标准写法, 还有一些简略写法:
对于可以直接匹配的情况:
data = 30match data: case _ if data == 10: print(data) case _ if data == 20: print(data) case _ if data == 30: print(data) # 上面三种都是标准写法,下面就是更简单的写法 case 40: # 这是 data == 40 的简略写法 print(40) case 50: print(50) case _: # 上面的都匹配不成功时,会执行这里的 print('匹配失败')如果想要进行范围匹配,例如,上面我们在匹配成绩等级时,这种情况就只能是在 通配符后面加上 if语句 进行判断了。
除了,可以匹配数据之外,还能匹配数据类型。
type = type(eval(input('请输入要匹配的类型:')))match type: case _ if type == str: print('This is a string') case _ if type == int: print('This is an integer') case _ if type == float: print('This is a float') case _ if type == list: print('This is a list') case _ if type == dict: print('This is a dictionary') case _ if type == tuple: print('This is a tuple') case _ if type == set: print('This is a set') case _: print('This is None')其实只要我们理解最标准的写法, 剩下的也就是使用 if语句去进行判断了。
字典合并运算符
字典合并运算符使用的是 "|"
代码演示:
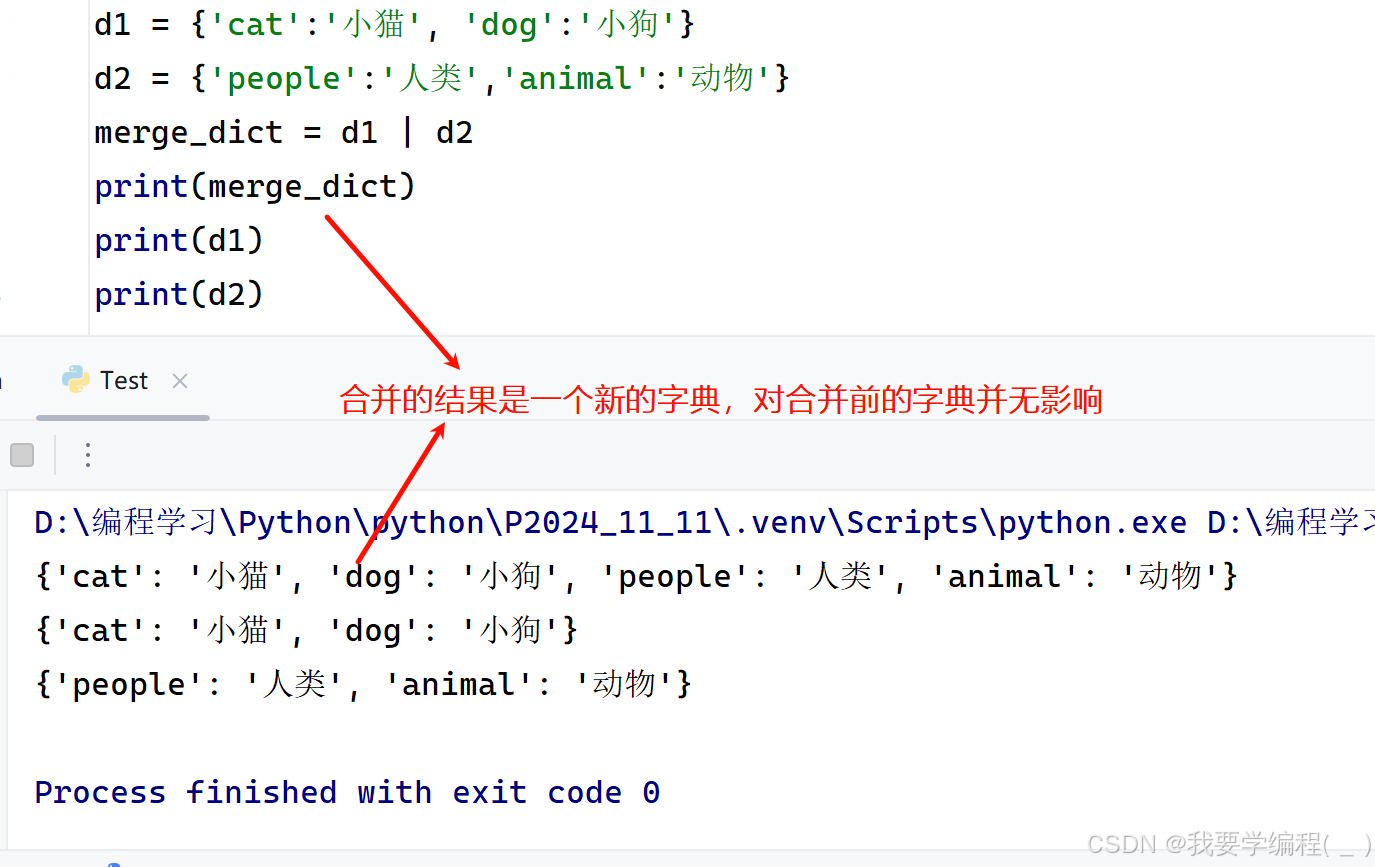
d1 = {'cat':'小猫', 'dog':'小狗'}d2 = {'people':'人类','animal':'动物'}merge_dict = d1 | d2print(merge_dict)print(d1)print(d2)运行效果:
同步迭代
当需要同时遍历多个对象时,就可以使用同步迭代的方式。
代码演示:
list1 = ['dog', 'cat', 'bird', 'fish']list2 = [1,2,3,4]# 通过zip函数将两个对象压缩成一份,然后再去遍历这个一份,达到同时遍历两个的效果for l1,l2 in zip(list1, list2): match l1,l2: case _ if l1 == 'dog' and l2 == 1: print('一只单身狗') case _ if l1 == 'cat' and l2 == 2: print('两个恋爱的小猫') case _ if l1 == 'bird' and l2 == 3: print('一家幸福的三口子') case _ if l1 == 'fish' and l2 == 4: print('四个幸福加倍的一家人') case _: print('匹配失败')运行效果:

因为这里使用了for循环去遍历,因此最终的效果就是 全部都匹配成功了。
注意:
1、在压缩的过程中,将两个对象中的元素的对应位置进行相互匹配,这里我们使用的是列表,因此最终的匹配都会成功,如果我们使用的是集合这种无序的数据结构去存储的话,就可能会匹配失败。
2、当压缩的对象的元素个数不相等时,是以元素个数少的对象作为基准来进行压缩的,后面的就会自动舍弃。例如,当一个对象有5个元素,另一个对象有10个元素,那么最终压缩的结果就是以5个元素为基准。
好啦!本期 初始Python篇(5)—— 集合 的学习之旅就到此结束啦!我们下一期再一起学习吧!