前排提醒:仅供参考,答案不一定正确,还请读者自行判断
A题 劲舞团

简单题,log.txt共2000行 ,暴力即可。
参考答案:9
n=2000res=[]for _ in range(2000): c,in_,t=input().split() res.append([c,in_,int(t)])print(res) ans=0n=len(res)for i in range(n): if res[i][0]!=res[i][1]: continue st=i while i+1<n and res[i+1][0]==res[i+1][1] and res[i+1][2]-res[i][2]<=1000: i+=1 ans=max(ans,i-st+1)print(ans)P.S 本人喜提WA。当时脑子迷糊先把字符打错的data去掉,再判断时间的。
B题 召唤数学精灵

思路:
1.范围过大,无法暴力;
2.注意到B(i)为阶乘,其数值在10之后将全是100的倍数。因为n>10时,n!=1*2*...*5*...*10*......已经有2*5*10存在。
3.由2,只需考虑A(i)是否为100的倍数。
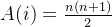
因此只需![[n(n+1)]mod(200)=0](http://m.zhangshiyu.com/zb_users/upload/2024/11/20241126100129173258648935596.png)
考虑如下事实:
若对于某个x有:
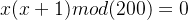
即A(x)能被100整除,则:
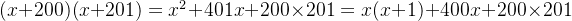
显然也是200的倍数,因此只需要找出200以内满足要求的数字个数即可。
4.符合3中条件的200以内的x为:
24,175,199,200
共4个。
因此,满足条件的数字个数为:
2024041331404202//200*4+2=40480826628086
最后的2是10以内满足要求的数,即1,3
参考答案:40480826628086
C题 封闭图形个数



本题对于python来说直接秒杀,不多说。
from functools import cmp_to_keycnt=[1,0,0,0,1,0,1,0,2,1]def get(num): res=0 for w in str(num): res+=cnt[int(w)] return resdef f(a,b): if a==b: return 0 x,y=get(a),get(b) if x==y: return -1 if a<b else 1 elif x<y: return -1 else: return 1def solve(): n=int(input()) a=list(map(int,input().split())) a.sort(key=cmp_to_key(f)) print(*a) solve()D题 商品库存管理



方法1:暴力,不多说。显然不能拿到所有分数
方法2:对于区间修改与查询,应该想到:差分数组,树状数组,线段树...etc
由于本题只是对区间整体加上同一个数(1),考虑使用差分数组。
若没有最后撤销执行操作,则只需要O(n)遍历数组,对0计数即可。
然而存在m个撤销操作,由于m范围较大,我们需要O(1)的找到撤销操作对答案的影响。
显然,这只要找到该撤销区间内1的个数即可。
O(1)获得某个区间内1的个数,用简单的前缀和即可解决。
最终时间复杂度为O(n+m)
n,m=map(int,input().split())t=[]for i in range(m): L,R=map(int,input().split()) t.append((L-1,R-1)) dif=[0]*(n+1)for L,R in t: dif[L]+=1 dif[R+1]-=1f=[0]for d in dif: f.append(f[-1]+d)f=f[1:-1]cnt1=[0]# print('final:',f)for x in f: cnt1.append(cnt1[-1]+int(x==1))cnt1=cnt1[1:]# print('cnt1=',cnt1)cnt0=sum([x==0 for x in f])# print(cnt0)for L,R in t: new=cnt1[R]-cnt1[L-1] if L>0 else cnt1[R] print(cnt0+new)E题 砍柴

 比赛喜提WA。
比赛喜提WA。
不太会。没找到规律。dfs不能获得所有结果,打表未遂。
DFS:定义dfs(x)为棍长为x时,当前砍柴方赢为True,否则为False。
对某个n,在1-n-1里面遍历所有的质数x(砍掉),如果存在dfs(n-x)为False(对方输),则return True,否则return False。
以下不是赛时使用的编译器。注意cache在赛时编译器用不了,不过这不是为了打表吗。
from functools import cacheimport syssys.setrecursionlimit(10**6)mx=10**3f=[True for i in range(mx+1)]for i in range(2,mx+1): if f[i]: for x in range(2*i,mx+1,i): f[x]=Falsea=[i for i in range(2,mx+1) if f[i]]d=set(sorted(a))print(a)@cachedef dfs(x): if x==0 or x==1: return False res=False if x in d: return True for i in range(1,x+1): if i in d: res|=not(dfs(x-i)) return res# print([dfs(i) for i in range(mx+1)])print([i for i in range(mx+1) if not dfs(i)])Update:
与其遍历各个质数,不如遍历各个能够让对方输掉的值,判断需要砍掉的值是否为质数,存在一种情况即可。这样做是因为暴力发现让当前方输掉的值要远少于小于该值的质数的个数。
打表代码:
from functools import cacheimport syssys.setrecursionlimit(10**6)mx=10**5f=[True for i in range(mx+1)]for i in range(2,mx+1): if f[i]: for x in range(2*i,mx+1,i): f[x]=Falsef[0]=f[1]=False# a=[i for i in range(2,mx+1) if f[i]]# d=set(sorted(a))lose=set()lose.add(0)lose.add(1)@cachedef dfs(x): if x==0 or x==1: return False if f[x]: return True for y in lose: if f[x-y]: return True lose.add(x) return False# print([dfs(i) for i in range(mx+1)])print([i for i in range(mx+1) if not dfs(i)])通过代码:
from functools import cachefrom bisect import bisect_rightdef dfs(x): # print(x) if memo[x]!=-1: return memo[x] if f[x]: memo[x]=True return True for j in range(bisect_right(a,x)-1,-1,-1): y=a[j] if not dfs(x-y): memo[x]=True return True memo[x]=False return Falsenums=[]for _ in range(int(input())): nums.append(int(input()))mx=max(nums)f = [True for i in range(mx + 1)]for i in range(2, mx + 1): if f[i]: for x in range(2 * i, mx + 1, i): f[x] = Falsea = [i for i in range(2, mx + 1) if f[i]]memo = [-1] * (mx + 1)memo[0] = memo[1] = Falsefor x in nums: if dfs(x): print(1) else: print(0)某dotcpp网上TLE可能因为:
1.预处理中固定mx=10**5而非max(nums);
2.dfs枚举时从小的质数开始而非大的质数。
F题 智力测试

智力不够,不会。奠。
G题 最大异或节点

树并没有什么卵用。只是添加了一个限制条件而已。
前置题:
421. 数组中两个数的最大异或值
本题只要在更新答案判断x和y是否为树中相邻节点即可。
def solve(): n=int(input()) g=[set() for i in range(n)] nums=list(map(int,input().split())) root=list(map(int,input().split())) for pa,son in enumerate(root): if pa==-1: continue g[pa].add(son) g[son].add(pa) res=0 mask=0 for i in range(31,-1,-1): mask|=(1<<i) tmp=res|(1<<i) s=dict() ok=False for i,x in enumerate(nums): if ok: break t=mask&x if t^tmp in s: for node in s[t^tmp]: if node not in g[i]: res=tmp ok=True break if t in s: s[t].append(i) else: s[t]=[i] print(res) solve()H题 植物生命力


dfs枚举所有节点,同时判断其子树中符合条件的节点数量,时间复杂度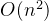
比赛WA了倒是。
def solve(): n,root=map(int,input().split()) val=list(map(int,input().split())) root-=1 g=[[] for _ in range(n)] for _ in range(n-1): x,y=map(int,input().split()) x-=1 y-=1 g[x].append(y) g[y].append(x)# print(g) res=0 def dfs(x,pa): s=[] for y in g[x]: if y!=pa: s+=dfs(y,x) nonlocal res for v in s: if v<val[x] and val[x]%v!=0: res+=1 s.append(val[x]) return s dfs(root,-1) print(res)solve()优化:
按照暴力的正常思路:
考虑每个结点及其子树。统计每个结点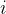 的子树中符合条件的结点 j 数量。
的子树中符合条件的结点 j 数量。
以结点i的子树节点的权值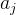 有如下情况:
有如下情况:
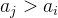 :
: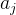 一定不能被
一定不能被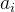 整除;
整除;
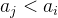 :可以被整除,不可以被整除均有。
:可以被整除,不可以被整除均有。
需要求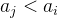 ,且不能被
,且不能被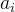 整除的结点个数。考虑:
整除的结点个数。考虑:
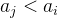 的结点个数减去能被
的结点个数减去能被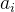 整除的结点个数
整除的结点个数
考虑能被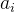 整除的结点个数,只需统计
整除的结点个数,只需统计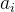 的因子数即可,这个数量并不大,具体内容见数论有关内容,这里不展开。
的因子数即可,这个数量并不大,具体内容见数论有关内容,这里不展开。
考虑 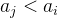 的结点个数:如果能够得到结点i的子树权值的计数数组
的结点个数:如果能够得到结点i的子树权值的计数数组![cnt=[cnt[1],cnt[2],...,cnt[n]]](http://m.zhangshiyu.com/zb_users/upload/2024/11/20241126100133173258649358633.png) (本题中各结点的值不同,因而数组中元素值只能为0或1),利用树状数组即可求得。
(本题中各结点的值不同,因而数组中元素值只能为0或1),利用树状数组即可求得。
但是最麻烦的是更新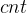 数组需要
数组需要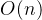 的时间(该节点的
的时间(该节点的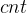 等于所有子节点的
等于所有子节点的 数组相加),因此这个方法有点寄了。
数组相加),因此这个方法有点寄了。
上述方法是由底向上的dfs,不太好做。如果换成自上向下的dfs,那么就能够O(1)更新频率数组 ,这就启发我们换一个思考方式,不以结点i以及其子树思考,而以一种能自顶向下的方式解题。
,这就启发我们换一个思考方式,不以结点i以及其子树思考,而以一种能自顶向下的方式解题。
思路改为,统计子节点 的所有祖先节点
的所有祖先节点 (即根结点到该结点路径上的所有结点)中,
(即根结点到该结点路径上的所有结点)中,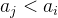 且
且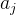 能被
能被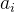 整除的结点 i 数量。这样就能够O(1)进行频率统计,进而快速求得
整除的结点 i 数量。这样就能够O(1)进行频率统计,进而快速求得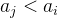 或
或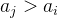 的结点数量。
的结点数量。
依然转化成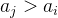 的祖先节点
的祖先节点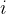 的数量减去能够整除
的数量减去能够整除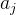 的祖先节点
的祖先节点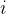 的数量。
的数量。
显然,对于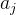 ,只需要遍历
,只需要遍历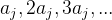 ,这有
,这有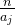 个数。
个数。
所以,对于1-n的所有结点,总遍历数为(不清楚的去看调和级数):
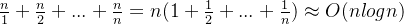
树状数组更新和查询均为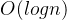 ,因此整体时间复杂度
,因此整体时间复杂度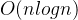
python选手注意,py的栈太浅,如果直接写递归的dfs会有问题(Codeforces上有类似问题),因此需要换成迭代写法。
以下代码可以通过:
1.植物生命力 - 蓝桥云课
class FenwickTree: def __init__(self,n): #下标从1开始 self.n=n self.tree=[0]*(n+1) def add(self,x,val): while x<=self.n: self.tree[x]+=val x+=x&-x def query(self,x): res=0 while x>0: res+=self.tree[x] x-=x&-x return res# 克服py栈太浅的问题from types import GeneratorType# 装饰器 手写栈# 函数头加上@bootstrap, 函数内部 return 改成 yielddef bootstrap(f, stack=[]): def wrappedfunc(*args, **kwargs): if stack: # 递归一层返回 return f(*args, **kwargs) else: # 遍历生成器函数 to = f(*args, **kwargs) while True: if type(to) is GeneratorType: # 新的生成器函数 stack.append(to) # 入栈 to = next(to) # 递归 else: # 没有新的生成器函数 stack.pop() # 弹出递归入口 if not stack: # 全部遍历完了 break to = stack[-1].send(to) return to # 返回答案 return wrappedfuncdef solve(): n,root=map(int,input().split()) val=list(map(int,input().split())) root-=1 g=[[] for _ in range(n)] for _ in range(n-1): x,y=map(lambda x:int(x)-1,input().split()) g[x].append(y) g[y].append(x) res=0 t=FenwickTree(n) cnt=[0]*(n+1) @bootstrap def dfs(x,pa): bigger=t.query(n)-t.query(val[x]) ok=0 for y in range(val[x],n+1,val[x]): ok+=cnt[y] nonlocal res res+=bigger-ok cnt[val[x]]+=1 t.add(val[x],1) for y in g[x]: if y!=pa: yield dfs(y,x) cnt[val[x]]-=1 t.add(val[x],-1) yield dfs(root,-1) print(res)solve()