引言
在编写代码并调试的过程中,跨域报错是每个新手小白甚至部分老玩家们都头疼不已的问题。
这时一定会去到处查,查百度,查csdn,查博客园或其他类似overflow的国外论坛
然而大多数情况是即使查了,涉及里面协议层面的术语以及公式化AI式的刻板回答
大多答非所问找不到解决问题的关键点
于是乎便硬着头皮去各种尝试
哪怕最终碰巧解决了,仍不知其云,亦不知其所以云
下次一旦再遇到跨域相关的问题
不过是新一轮的痛苦循环
所以我写这篇文章的初衷其实很简单
就是想用大白话的形式尽量讲明白跨域这茬事
让大家不要怕遇到跨域问题
当然,在阅读本文章之前,你需要至少对http协议有个简单了解
比如至少需要知道get和post请求的区别以及cookie机制和token存储方式,不知道的请先简单了解后再看
前言
当发现浏览器报跨域错误时,
你是否疑惑过究竟该在哪里,对谁配置跨域?
不知你是否发现,
为什么有很多第三方接口都标注过只允许服务端调用,
而一旦在浏览器上用js去请求时就一定报跨域,
而在服务器端用curl等去调用又能正常,这又是为何呢?
如果你抱着以上的疑惑,
可以继续往下看下去,
我会试着用简单易懂的大白话去尝试解释他
当然,这样势必是要牺牲严谨性的,
但我想对于像曾经的我一样对此感到困惑的人一定会有所帮助
废话不多说,下面是正文:

说到跨域(CORS),很多人其实误解了一件事,就是认为它是属于http协议的一部分的。其实这么理解有误
CORS验证其实是对HTTP协议的一种扩展和规范。非原来就有的。而是后来加上的。
对于CORS(跨域资源共享)协议验证,通常只有浏览器端实现了这一机制,而大多数服务器端并不会主动进行CORS验证。
是的,通常只有浏览器端实现了这一机制。
这怎么理解呢,先说浏览器吧
现在你要用这个浏览器上网
首先,浏览器的所有资源都是按照域名(或IP)来进行分配和隔离的
且浏览器打开的每个页面都是有明确归属的!
但是,现在开始假设这个浏览器并未实现对于CORS(跨域资源共享)协议验证,也就是页面只有归属但没有隔离的情况。
想想你现在浏览器打开的每个页面,是不是头部都有它所属的网址(url)
而网址上一定有当前页面归属的域名,这就是浏览器每个页面的归属方
比如上图,这个页面就是来自mp.csdn.net这个三级域名的。
那么 mp.csdn.net 就是这个页面的归属人
确定了每个页面都存在唯一的归属后,会产生一个安全问题(跨域检测不存在的年代)
比如你打开了一个页面,假设这个页面归属是你当前访问的这个站点的域名www.xxx.com
而此时这个页面逻辑中包含js,而js中存在异步调用(xhr的ajax等接口调用逻辑)
如果js的异步调用的恰好是其他域名的接口(假设域名是www.weixinhaoyou.com),就比如是某网页微信的好友消息接口(假设存在并且是只有登录鉴权的webapi接口)

这个接口(域名www.weixinhaoyou.com)是获取你登录的网页微信中的所有好友信息(只是假设),只要能从cookie中获取你的登录token,就能成功请求通这个接口获取好友信息。
(ps:如果不懂cookie的运作原理,我先挖个坑,下次专门写个cookie运作机制的文章)
那会怎么样?

咱们分类来讨论:

两种可能性:
1,你未在这个浏览器上登录过网页微信,此时你打开这个网页时,这个网页(域名www.xxx.com)的js去ajax(xhr)请求网页微信的好友消息接口(域名www.weixinhaoyou.com)报错,被拦截提示未登录。一切正常
2,你在这个浏览器上登录过网页微信,此时浏览器的cookie库中存在网页微信成功登录的token凭证(域名www.weixinhaoyou.com),那么此时该网页(域名www.xxx.com)发起的向请求网页微信的好友消息接口(域名www.weixinhaoyou.com)将带上这个域名下的所有cookie(cookie的运作原理),其中也包括了那个登录凭证。那此时接口将调用成功,查询出的你的好友信息将出现在ajax的成功回调中并且如果此时网页的回调中还写了将查询的信息再ajax发送给归属者(域名www.xxx.com)的服务器,那是不是意味着你的好友信息被盗取了?同时你的token的泄露了,那能做的事就很多了。
对于可能性2,你可能会疑惑,我明明是在网页微信上登录的,为什么我访问其他网站,其他网站也能拿到我的登录凭证?
为什么网页微信没有拦截他?

因为在这个网页微信看来,就是真的用户在访问它,毕竟钥匙都有(cookie里的token)为什么不放行呢?
什么原因造成的这一切?
因为没有隔离!
在这个例子中,你可以清晰的看到,
归属于域名www.xxx.com的网页,竟然可以向归属于域名www.weixinhaoyou.com的服务器发请求?
虽然这个需求挺常见的,比如任何一个官网都可能挂友情链接或者在js层面上访问其他第三方接口(比如天气)并展示在网页中。
但仔细想想,在一个域名归属下的页面,可以访问其他域名归属的东西,本身是存在安全隐患的,上面就是典型的例子,被称为跨站请求伪造(CSRF)攻击
就是利用域名互相不隔离的漏洞,恶意网站通过跨站请求伪造(CSRF)攻击手段,利用用户的身份(那个cookie里的token)对受害网站进行未授权的操作。

假设有这么一段对话:

我问你!
CORS(跨域资源共享)协议验证究竟做了什么,它又怎么预防请求伪造(CSRF)攻击呢?
很简单
一刀切呗!
既然造成它的最根本原因是在一个域名归属下的页面,可以访问其他域名归属的东西,
那么直接禁止了呗!
就不让页面请求除了它自身归属域名(假设www.xxx.com)以外的其他任何域名就行了呗!
等等,不行啊,我页面引入了好多其他域名站点的js啊,而且外部js没记错的话,好些还是GET请求方式吧,你这一刀切,网站不带蹦啊
那行,那就GET请求方式的引入其他服务器js这种的,允许跨域,这下行了吧!
(这就是jsonp的工作原理:在网页上用ajax发get请求时,将get请求和响应伪装成js引入和加载!)
那你这也不行啊?一刀切的什么玩意儿。
可能有些网站人家就是要请求其他站点的,比如我的网站要挂地图业务,用的还是人家高德的地图api呢,这玩意也不可能写在服务器上吧,要渲染的!
我想想
那这样吧
咱把浏览器发出的请求分成两大类(记住啊,只说了浏览器没说其他),一个是简单请求,一个是复杂请求,规定一下
简单请求的只要对方在响应头中有允许跨域的标识就管放行。
(
简单请求定义:
请求方式:GET、POST、HEAD之一。HTTP头部信息:只包含Accept、Accept-Language、Content-Language、DPR、Downlink、Save-Data、Viewport-Width、Width、Content-Type(且Content-Type只有三个值:application/x-www-form-urlencoded、multipart/form-data、text/plain)等标准字段。 在这种情况下,如果服务器允许跨域访问,需要在返回的响应头中携带以下信息:Access-Control-Allow-Origin:指定允许访问的源地址,可以是一个具体域名或者“*”,代表任意域名。Access-Control-Allow-Credentials:指定是否允许携带cookie,默认情况下CORS不会携带cookie,除非这个值是true。如果跨域请求要操作cookie,需要满足以下三个条件:服务的响应头中需要携带Access-Control-Allow-Credentials并且为true;浏览器发起ajax需要指定withCredentials为true;响应头中的Access-Control-Allow-Origin一定不能为“*”,必须是指定的域名。 )
复杂请求则要先发一个与实际要发的请求无关的问候请求询问对方自己指定的跨域规则,
浏览器校对完无误后再把实际请求发出去。
(
复杂请求定义:
请求方式:不是GET、POST、HEAD的请求,如PUT、DELETE等。请求头中包含自定义头部字段。(目前流行将登录凭证塞进自定义header中,那就意味着你服务器的所有接口都将是复杂请求!)向服务器发送了application/json格式的数据。(前端ajax接收的通常都是json,这也意味着大多返回json的post接口都是复杂请求,这点要记住!!)在这种情况下,浏览器会在正式通信之前,先发送一个OPTIONS请求进行预检,以获知服务器是否允许该实际请求。服务器需要在响应这个OPTIONS请求的头部中包含以下信息: Access-Control-Allow-Origin:指定允许访问的源地址。Access-Control-Allow-Methods:指定允许的HTTP请求方法,如GET、POST、PUT、DELETE等。Access-Control-Max-Age:指定预检请求的有效期时间(秒)。Access-Control-Allow-Headers:指定允许的请求头信息字段。
特殊应答报文的作用
通过配置这些特殊的应答报文,服务器可以明确告知浏览器哪些跨域请求是被允许的,哪些是不被允许的。这有助于保护服务器的资源不被恶意访问,同时也确保了合法的跨域请求能够顺利进行。
)
这期间只要任何验证环节出问题,那就报CORS错误,拒绝访问!
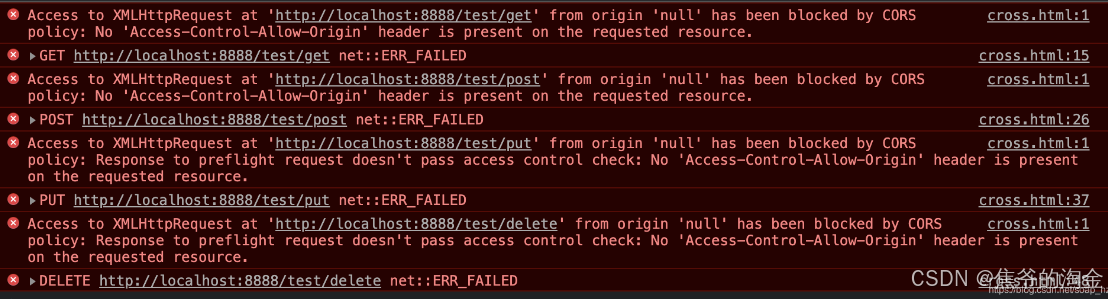
这样子就不会一刀切了,完全由对方意愿来决定是否让你请求!
这里千万不要懵逼!
处理跨域一定要区分好谁是资源索取方!谁是资源拥有者!处理跨域是资源拥有者这里放行!
处理跨域一定要区分好谁是资源索取方!谁是资源拥有者!处理跨域是资源拥有者这里放行!
处理跨域一定要区分好谁是资源索取方!谁是资源拥有者!处理跨域是资源拥有者这里放行!
重要的事情说三遍!
比如网站图片跨域,此时网页归属域名是资源索取方,而图片所存放的静态资源服务器就是资源拥有者,如果图片在服务器上就去服务器配置放行头,如果图片在阿里云等oss上,就去那里配,搞清楚了谁是资源拥有者,也就找对跨域的配置地方了!
怎么样,这样够完善吧!
好像很完善了。。。等等!!有点问题!
你老说浏览器,浏览器,浏览器啥的
考虑过服务器的感受吗!
照你这么整,服务器上是不是还要写跨域的拦截逻辑啊,那些沉淀了几十年的屎山老网站程序员怕是都退休了,谁去给那些屎山网站写跨域拦截的代码去!
这技术债务直接原地升天!
那这样吧,跨域的拦截代码由浏览器写,在浏览器里实现,一旦在浏览器中一个域名下的网页用了js调用了其他域名的接口,只要对方服务器没有验证过,我浏览器来拦截,这样成本是不是就小了,服务器只要写几行放行条件的代码就好(上文的请求定义)
但是你这样做是不是也有问题啊!
什么?
那脱离浏览器,不用浏览器的js去请求接口,用服务器直接请求接口(curl)不就绕开跨域拦截了么,(如果请求方不要求验证身份对暗号,那就没有跨域这回事)
这我就管不着了,脱离了浏览器js调用接口,随他们的,自己随便怎么验证都行(证书,密钥等手段。对于CORS(跨域资源共享)协议验证,通常只有浏览器端实现了这一机制,而大多数服务器端并不会主动进行CORS验证。这是因为CORS主要是针对浏览器端的安全策略设计的,用于解决浏览器在访问跨域资源时可能遇到的同源策略限制。)