摘要
这篇博客为C++初学者提供了一份全面而详尽的入门指南,涵盖了C++的方方面面。首先,从语言的起源与发展入手,讲述了C++的历史脉络及其对现代编程的深远影响。接着,详细剖析了C++的核心关键字,包括const、static和auto,并通过实际示例展示其应用。文章还深入探讨了命名空间的概念、C++基础语法、变量与数据类型、输入输出、控制流等基础知识,帮助读者构建扎实的编程基础。此外,还详细解读了C++的函数机制,涵盖函数参数、递归、函数重载、内联函数及模板等高级内容。文章同样没有忽视数组与指针的复杂性及错误与异常处理的重要性。通过理论与代码实例相结合的方式,本博客旨在让初学者快速上手,同时为进一步深入学习打下坚实基础。如果你想全面掌握C++,这篇博客将是不可错过的起点。
1、引言
C++ 语言作为现代编程语言的基石之一,在软件开发的多个领域发挥着至关重要的作用。自从 20 世纪 80 年代由 Bjarne Stroustrup 发明以来,C++ 通过其强大的性能、灵活的编程模型和丰富的特性,一直深受开发者的喜爱和推崇。它既可以用来编写系统底层代码,又适用于复杂的高性能应用,成为从操作系统、嵌入式系统到大型分布式系统的首选语言之一。
1.1、C++ 简介
C++ 的起源可以追溯到 C 语言,后者是一种高效的系统编程语言。然而,随着软件系统的复杂度不断提高,程序员逐渐需要更高层次的抽象工具,以便简化开发并提高代码的可维护性。因此,Bjarne Stroustrup 在 C 语言的基础上引入了面向对象编程(OOP)的理念,结合 C 的高性能特点,创造了 C++。
C++ 的发展从未停止,随着 C++98 的标准化开启,后续版本(C++11、C++14、C++17、C++20)不断加入了诸多新特性,例如自动类型推导(auto)、智能指针、Lambda 表达式、并发支持等,使得语言的表达能力和易用性得到了极大提升。
1.2、为什么学习 C++?
尽管现代编程语言层出不穷,如 Python、Java 和 Rust,但 C++ 依然在许多领域不可替代。这主要得益于以下几个特点:
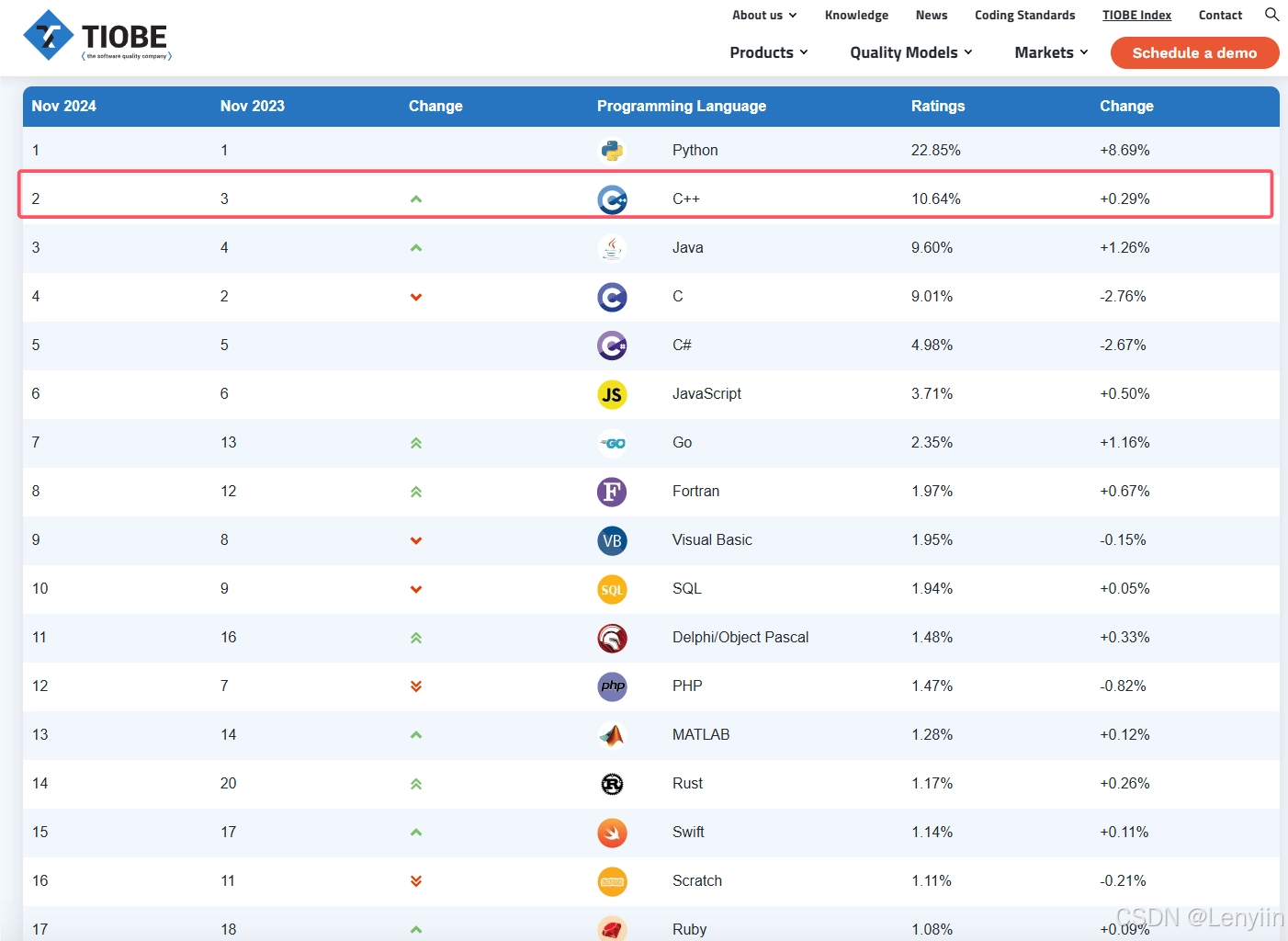
高性能与资源控制:C++ 提供了对硬件资源的细粒度控制,使其在性能至关重要的领域(如游戏开发、图形渲染、高频交易)中占据重要地位。跨平台性:C++ 支持跨平台开发,几乎所有操作系统和硬件架构都能运行 C++ 程序。强大的工具链与生态:C++ 拥有丰富的标准模板库(STL)和第三方库支持,从 Boost 到 OpenCV,应有尽有。深厚的行业基础:大量遗留系统是用 C++ 编写的,学习和掌握 C++ 是理解这些系统的基础。截至我写这篇文章的时候,C++ 占据第二名的位置。
1.3、学习 C++ 的价值
对于初学者来说,C++ 的强大功能可能显得复杂难懂。然而,掌握这门语言能够打开编程世界的更多可能性。通过本文,我们将从基础语法入手,逐步深入到高级特性和实际应用,以帮助读者全面理解 C++ 的核心概念和实践方法。
C++ 不仅是一门编程语言,更是一种思维方式。在掌握 C++ 的过程中,读者将学会高效解决复杂问题的能力,并对底层计算机系统有更加深入的理解。无论是对职业发展,还是对技术深度的追求,C++ 都是值得长期投入的语言。
通过本文的学习,读者将对 C++ 有全面的认识,并具备用 C++ 开发高效、可靠程序的能力。这是一段充满挑战与收获的旅程,期待与您共同开启。
2、C++ 的起源与发展
C++ 是一门在编程语言发展史上具有里程碑意义的语言,其诞生与发展反映了编程技术从底层硬件控制到抽象化编程的巨大进步。本节将从 C++ 的起源讲起,逐步梳理其发展的主要脉络、重要里程碑事件以及对编程语言和软件开发领域的深远影响。
2.1、起源:从 C 到 C++ 的初步探索
C++ 的故事始于 20 世纪 70 年代,当时 Dennis Ritchie 在贝尔实验室发明了 C 语言。C 语言以其简洁、高效和硬件友好的特性迅速成为操作系统开发(尤其是 UNIX)以及嵌入式系统的首选语言。然而,随着计算机科学的发展,程序的复杂度和规模不断增加,传统的过程式编程逐渐显露出局限性,例如代码的可维护性差和模块化能力不足。
在这种背景下,Bjarne Stroustrup 于 1979 年在贝尔实验室开始了对面向对象编程(OOP)的探索。他结合 C 语言的性能优势与 Simula 语言的对象模型特性,创建了一种新的编程工具—— “C with Classes”,即 “带类的 C”。这是 C++ 的雏形,它最早实现了类(class)和继承(inheritance)等面向对象的基本特性。
2.2、标准化与正式命名:C++ 的初次亮相
1983 年,Bjarne Stroustrup 将 “C with Classes” 正式命名为 C++,其中 “++” 象征着对 C 的“ 增量” 改进。早期版本的 C++ 引入了以下核心特性:
类与对象:实现了数据封装和抽象。继承与多态:支持代码复用和扩展性。运算符重载:使得类行为更加直观。1985 年,Bjarne Stroustrup 发布了《The C++ Programming Language》一书,这是 C++ 的第一本权威教程。同年,第一个正式的 C++ 编译器 Cfront 发布,该编译器基于 C 编译器,能够将 C++ 代码翻译为 C 代码。
2.3、蓬勃发展:C++ 的标准化过程
随着 C++ 的广泛应用,社区对语言标准化的需求逐渐增长。标准化过程始于 1990 年代,由 ANSI(美国国家标准学会) 和 ISO(国际标准化组织) 牵头。1998 年,第一版 C++ 标准(即 C++98)正式发布,这标志着 C++ 成为一门标准化的编程语言。
C++98 的主要特性包括:
标准模板库(STL):提供通用容器(如vector 和 map)和算法(如 sort 和 search)。异常处理:提高程序的鲁棒性。命名空间:避免命名冲突,支持模块化开发。 2003 年,C++98 的修订版 C++03 发布,主要修复了一些标准中的细节问题,但未引入重大新特性。
2.4、现代化的浪潮:C++11 及其后续版本
进入 21 世纪,编程语言的需求发生了显著变化:程序复杂度不断提升,硬件并行性加剧,开发效率和性能之间的平衡变得至关重要。在这种背景下,C++ 迎来了现代化的变革。
C++11(2011 年)被称为 C++ 的 “现代化元年” ,C++11 引入了许多重要特性,使语言更加高效和易用: 自动类型推导:
auto 和 decltype 减少了代码冗余。智能指针:std::shared_ptr 和 std::unique_ptr 简化内存管理。Lambda 表达式:提高代码的简洁性和可读性。并发支持:引入线程库(std::thread)和原子操作。右值引用与移动语义:显著提升性能,尤其是在容器操作中。 C++14(2014 年)C++14 是对 C++11 的小幅改进,提供了更直观的语法和标准库增强。例如: 通用 Lambda 捕获:增强了 Lambda 表达式的灵活性。二进制文字:如
0b1010。 C++17(2017 年)C++17 引入了更多的标准库支持,并增强了语言的表达能力: 结构化绑定:
auto [x, y] = pair; 提升代码可读性。文件系统支持:std::filesystem 提供跨平台文件操作。if constexpr:支持编译期分支判断。 C++20(2020 年)C++20 被认为是继 C++11 后又一次重大更新,带来了许多革命性特性: 协程(Coroutine):支持异步编程。概念(Concepts):提升模板编程的可读性和安全性。模块化编程:减少头文件依赖。范围(Ranges)库:增强对容器的操作能力。
2.5、对编程世界的影响
C++ 的发展对计算机科学和软件工程领域产生了深远影响:
现代编程语言的设计C++ 的多范式特性(过程式、面向对象、泛型编程)启发了后续语言的设计,如 Java 和 C#。尤其是模板和 STL 的设计理念被广泛借鉴。系统开发的主力
由于其高性能和硬件亲和性,C++ 成为操作系统(如 Windows 和 Linux 内核模块)、数据库(如 MySQL)和嵌入式系统的首选语言。提升了编程教育水平
作为学习面向对象和泛型编程的重要语言,C++ 被许多大学选为编程课程的核心语言。
2.6、未来展望
C++ 的未来充满潜力,尤其是在高性能计算、人工智能、图形渲染和嵌入式系统领域。随着协程、模块化等特性的进一步普及,C++ 将更好地适应并行化和模块化开发的需求。
尽管面临其他现代语言的竞争,C++ 依然以其高效、灵活和强大的特性,在编程语言的历史长河中占据重要位置。它不仅记录了编程语言的发展,也引领了技术的进步,成为软件开发者心目中的经典。
如果你对 C++ 的起源与发展足够感兴趣的话,可以移步我的这篇关于 C++起源与发展 的专题博客:《 C++ 点滴漫谈: 一 》C++ 传奇:起源、演化与发展
3、C++ 关键字
关键字(Keywords)是 C++ 语言的核心组成部分,它们为语言提供了基础功能和语法结构。理解关键字是学习 C++ 的重要环节,因为关键字定义了语言的基本操作和特性。本节将从多个维度系统地讲解 C++ 的关键字,并通过实例展示其应用。
本节将详细介绍 C++ 的所有关键字,包括其分类、功能及使用场景,并通过示例代码帮助读者深入理解关键字的作用。
3.1、关键字的定义与特点
3.1.1、什么是关键字?
关键字是由 C++ 语言预定义的保留字。这些单词具有特定的含义,不能用作用户定义的标识符(例如变量名、函数名或类名)。
3.1.2、关键字的特点
固定性:关键字在语言规范中定义,其含义不可改变。不可重用性:关键字不能用于其他目的,如变量名或函数名。大小写敏感:C++ 是大小写敏感的,因此int 是关键字,但 INT 是合法标识符。 3.2、关键字总览
C++ 是一门功能强大且灵活的编程语言,其中关键字(Keywords)是语言语法的核心组成部分。关键字是 C++ 预定义的保留词,它们用于实现特定功能,不可用作变量名、函数名或其他标识符。C++ 总计63个关键字 (C++ 98),C语言32个关键字

C++ 中的关键字随着语言版本的更新而增加。以下是一些关键字的分类和用途:
类型定义相关关键字:int、float、double、char、bool、void 等。 存储类关键字: auto、static、extern、register、mutable 等。 控制流关键字: if、else、switch、case、for、while、do、break、continue、return 等。 类型修饰符关键字: long、short、signed、unsigned、const、volatile 等。 面向对象相关关键字: class、public、private、protected、virtual、friend 等。 异常处理关键字: try、catch、throw 等。 模板相关关键字: template、typename、constexpr、decltype 等。 操作符重载相关关键字: operator。 动态内存分配关键字: new、delete。 命名空间相关关键字: namespace、using。 其他关键字: sizeof、this、nullptr、alignof 等。 3.2.1、类型定义关键字
C++ 提供了一系列用于定义变量数据类型的关键字。
1、基本数据类型关键字
int:用于声明整数类型。float:用于声明浮点数类型。double:用于声明双精度浮点数。char:用于声明字符类型。bool:用于声明布尔类型,仅有两个值 true 和 false。 示例:基本数据类型
#include <iostream>using namespace std;int main() { int num = 42; float price = 19.99; char grade = 'A'; bool isAvailable = true; cout << "Number: " << num << endl; cout << "Price: " << price << endl; cout << "Grade: " << grade << endl; cout << "Available: " << (isAvailable ? "Yes" : "No") << endl; return 0;}2、复合类型
void:表示无返回值的函数类型。enum:定义枚举类型。struct、union:表示用户定义的复合数据类型。 3.2.2、存储类关键字
存储类关键字用于定义变量的存储位置、生命周期、可见性和作用域。
1、自动存储(自动推导类型)
auto:推断变量的类型(C++11 引入)。 示例:自动类型推导
#include <iostream>using namespace std;int main() { auto num = 10; // 自动推导为 int auto price = 3.14; // 自动推导为 double cout << num << " " << price << endl; return 0;}2、静态存储
static:声明静态变量或函数,其生命周期为整个程序运行期间。 示例:静态变量
#include <iostream>using namespace std;void counter() { static int count = 0; count++; cout << "Count: " << count << endl;}int main() { counter(); counter(); counter(); return 0;}3、其他存储类
register:建议将变量存储在寄存器中。extern:用于声明全局变量或函数,延长作用域至整个程序。 3.2.3、控制流关键字
控制语句关键字用于控制程序的执行流程。
1、条件控制
if、else:执行条件判断。switch、case:执行多分支选择。 2、循环控制
for:固定次数循环。while:条件满足时循环。do:至少执行一次的循环。 3、跳转控制
break:跳出循环或 switch 语句。continue:跳过本次循环,进入下一次循环。goto:直接跳转到标记位置(不建议使用)。return:从函数中返回。 示例:循环与条件控制
#include <iostream>using namespace std;int main() { for (int i = 0; i < 5; i++) { if (i == 3) { continue; } cout << i << " "; } return 0;}3.2.4、类型修饰符关键字
修饰符用于增强数据类型的灵活性或控制数据存储。
long:表示长整型。short:表示短整型。signed:表示带符号类型。unsigned:表示无符号类型。const:定义常量。volatile:防止编译器优化的变量。 示例:常量修饰符
#include <iostream>using namespace std;int main() { const int a = 10; // a = 20; // 编译错误 cout << a << endl; return 0;}3.2.5、面向对象相关关键字
C++ 通过一组关键字支持面向对象编程。
1、类与访问控制
class、public、private、protected:定义类及其成员的访问权限。public:公有成员,任何地方都可以访问。protected:保护成员,仅类及其派生类可访问。private:私有成员,仅类内部可访问。 2、继承与多态
virtual:实现虚函数,用于多态。friend:定义友元类或函数,允许其访问私有成员。 示例:面向对象
#include <iostream>using namespace std;class MyClass {private: int privateVar;public: int publicVar;protected: int protectedVar;};int main() { MyClass obj; obj.publicVar = 10; // 可访问 // obj.privateVar = 20; // 错误 return 0;}3.2.6、异常处理关键字
用于处理运行时异常。
try:定义异常监控代码块。throw:抛出异常。catch:捕获并处理异常。 示例:
#include <iostream>using namespace std;int main() { try { throw "Error occurred!"; } catch (const char* msg) { cout << msg << endl; } return 0;}3.2.7、模板相关关键字
C++ 提供了模板机制,用于编写通用代码。
template:定义模板。typename:表示类型。class:在模板中可替代 typename。 示例:模板
#include <iostream>using namespace std;template <typename T>T add(T a, T b) { return a + b;}int main() { cout << add(5, 10) << endl; // 输出 15 cout << add(2.5, 3.5) << endl; // 输出 6.0 return 0;}3.2.8、其他特殊功能关键字
new、delete:动态内存管理。namespace:定义命名空间,避免名称冲突。using:引入命名空间或类型别名。operator:定义运算符重载。friend:定义友元类或友元函数。 示例:命名空间
#include <iostream>using namespace std;namespace Lenyiin { void display() { cout << "Inside MyNamespace" << endl; }}int main() { Lenyiin::display(); return 0;}3.2.9、关键字的使用限制与注意事项
避免重名冲突:不要将关键字作为标识符使用。大小写敏感:注意关键字的拼写和大小写。版本兼容性:不同版本的 C++ 标准可能引入新关键字(如nullptr 在 C++11 中引入)。 3.3、const 关键字
const 是 C++ 中非常重要的关键字,代表 “不可变性” 。通过使用 const,可以明确表达某些变量、对象或函数的不可变属性,从而提高代码的可读性和安全性,同时帮助编译器优化代码。本节将详细讲解 const 的使用场景、应用细节及潜在的陷阱。
3.3.1、什么是 const?
const 是 “constant” 的缩写,表示 “常量” 或 “不可变性” 。
在 C++ 中,const 可以用于:
其主要目的是确保被声明为 const 的对象在定义后不能被修改。
3.3.2、const 的基本用法
1、常量变量
通过将变量声明为 const,可以防止对该变量进行修改:
const int maxValue = 100;maxValue = 200; // 错误, 无法修改 const 变量除了这种方式可以创建常量外,还可以使用宏定义的方式创建常量
#define NUMBER 1024常考题:const 常量与宏定义的区别是什么?
const 常量是在编译时。类型和安全检查不同。宏定义没有类型,不做任何类型检査;const 常量有具体的类型,在编译期会执行类型检查。
在使用中,应尽量以
const 替换宏定义,可以减小犯错误的概率, 2、常量指针和指针常量
const 和指针结合时有以下几种情况:
指向常量的指针:指针指向的内容不可修改。
const int value = 10;const int* ptr = &value;// 常量指针, Pointer to const*ptr = 20; // 错误, 无法修改指向的内容常量指针:指针本身的地址不可修改,但指向的内容可以修改。
int value = 10;int value2 = 20;int* const ptr = &value;// 指针常量, const pointerptr = &value2; // 错误, 无法修改指针地址*ptr = 30; // 正确, 修改指向的内容指向常量的常量指针:指针地址和指向的内容都不可修改。
const int value = 10;const int* const ptr = &value;*ptr = 20; // 错误, 无法修改指向的内容ptr = &value2; // 错误, 无法修改指针地址3.3.3、const 与函数
1、函数参数的 const
值传递参数:对于传值参数,const 没有实际作用,因为传值本质是拷贝。
void func(const int x) { // 虽然 x 不可修改, 但不会影响实参}引用参数:对于引用传参,const 可以避免修改原始对象。
void printValue(const int& value) { // value 是只读的 std::cout << value << std::endl;}指针参数:可以通过 const 限制指针或指针指向内容的修改。
void printArray(const int* arr, int size) { for (int i = 0; i < size; ++i) { std::cout << arr[i] << std::endl; }}2、返回值的 const
返回常量值:返回值为 const 时,无法修改返回值。
const int getConstantValue() { return 42;}返回指针或引用:返回的内容无法被修改。
const int& getConstantReference(const int& value) { return value;}3.3.4、const 与类
1、成员变量的 const
类中可以定义 const 成员变量,但必须在构造函数初始化列表中进行初始化:
class MyClass {private: const int value;public: MyClass(int v) : value(v) {} int getValue() const { return value; }};2、成员函数的 const
将成员函数声明为 const 表示该函数不会修改类的成员变量:
class MyClass {private: int value;public: MyClass(int v) : value(v) {} int getValue() const { // const 成员函数 return value; } void setValue(int v) { value = v; }};const 成员函数只能调用其他 const 成员函数,不能修改成员变量。
3、mutable 修饰符
即使在 const 对象中,mutable 修饰的成员变量依然可以被修改:
class MyClass {private: mutable int counter;public: MyClass() : counter(0) {} void increment() const { ++counter; // 合法, 因为 counter 是 mutable }};3.3.5、const_cast
在某些情况下,可以通过 const_cast 来移除 const 限制,但这通常是危险且不可取的:
void modifyValue(const int* value) { int* nonConstValue = const_cast<int*>(value); *nonConstValue = 20; // 强行修改}使用 const_cast 应该非常慎重,仅在确有必要时使用。
3.3.6、常见错误与陷阱
误用 const:
const int* ptr; // 指针指向的内容不可修改int* const ptr; // 指针本身不可修改忽略 const 的传递:当返回 const 引用或指针时,调用者可能会尝试修改其内容,这会引发未定义行为。
滥用 const_cast:强行移除 const 可能会导致程序不稳定。
3.3.7、小结
const 是 C++ 中一个功能强大且灵活的关键字,通过合理使用,可以大幅提高代码的健壮性和可读性。在现代 C++ 开发中,遵循 “能用 const 就用 const” 的原则是一种良好的编程习惯。通过深入理解 const 的语法和应用,可以在代码中构建出更安全、高效的逻辑结构。
3.4、static 关键字
static 是 C++ 中功能强大的关键字之一,其应用范围广泛且功能多样。**在不同的上下文中,static 的行为和作用各不相同。它主要用于管理变量的存储持续性、作用域及类成员的共享性。**本节将深入探讨 static 的各种用法,并通过示例代码展示其具体应用。
3.4.1、什么是 static 关键字?
在 C++ 中,static 关键字的含义根据上下文的不同而变化。主要有以下几种应用:
3.4.2、static 在函数中的使用
局部静态变量
局部静态变量的生命周期扩展到程序结束,而不是函数调用结束。它们在函数调用时不会被重新初始化,且值可以在函数多次调用之间保持不变。
#include <iostream>void counter() { static int count = 0; // 局部静态变量 count++; std::cout << "Count: " << count << std::endl;}int main() { counter(); // 输出: Count: 1 counter(); // 输出: Count: 2 counter(); // 输出: Count: 3 return 0;}特点:
初始值仅在第一次调用时被初始化。生命周期贯穿程序的整个执行过程。适合需要在函数多次调用间保存状态的场景。3.4.3、static 在全局变量和函数中的使用
static 修饰全局变量或函数时,作用是将其可见性限制在声明的文件中(内部链接性)。这是实现信息隐藏的一种方法。
1、静态全局变量
静态全局变量只能在声明它的源文件中访问。
// file1.cppstatic int globalVar = 10; // 静态全局变量void printVar() { std::cout << "globalVar: " << globalVar << std::endl;}// file2.cppextern void printVar();int main() { // 无法访问 globalVar printVar(); // 通过函数间接访问 return 0;}2、静态函数
静态函数的作用域仅限于声明的文件,其他文件无法调用。
// file1.cppstatic void staticFunction() { std::cout << "This is a static function." << std::endl;}// file2.cppextern void staticFunction(); // 错误:无法访问静态函数应用场景:
模块化编程:隐藏模块内部实现细节,防止命名冲突。安全性:确保某些变量或函数仅在特定范围内可用。3.4.4、static 在类中的使用
在类中,static 可以用来修饰成员变量和成员函数,使其属于类而非对象。
1、静态成员变量
静态成员变量在类中共享,每个对象访问的都是同一份数据。静态成员变量的生命周期贯穿程序始终。
#include <iostream>class MyClass {public: static int count; // 静态成员变量声明 MyClass() { count++; }};// 静态成员变量定义并初始化int MyClass::count = 0;int main() { MyClass obj1, obj2; std::cout << "Count: " << MyClass::count << std::endl; // 输出: Count: 2 return 0;}特点:
静态成员变量必须在类外定义并初始化。不依赖于任何对象,也可通过类名直接访问。2、静态成员函数
静态成员函数只能访问静态成员变量,因为它们不依赖于对象实例。
class MyClass {public: static int count; static void incrementCount() { // 静态成员函数 count++; }};int MyClass::count = 0;int main() { MyClass::incrementCount(); // 通过类名调用 std::cout << "Count: " << MyClass::count << std::endl; // 输出: Count: 1 return 0;}3.4.5、静态类变量和静态局部变量的区别
| 特性 | 静态类变量 | 静态局部变量 |
|---|---|---|
| 生命周期 | 程序运行期间 | 程序运行期间 |
| 作用域 | 类的范围(所有对象共享) | 函数内部(不可被外部访问) |
| 初始化 | 类外初始化 | 函数内定义时初始化 |
3.4.6、static 的使用注意事项
滥用static: 在函数中滥用静态变量可能导致多线程环境中的数据竞争。滥用静态全局变量或函数可能降低模块的灵活性。 线程安全性: 静态局部变量在 C++11 及以后的标准中是线程安全的,但仍需注意多线程访问时可能的逻辑错误。与内存管理的结合: 静态变量不会自动释放,需要谨慎管理其生命周期和资源。 3.4.7、小结
static 是一个功能丰富的关键字,可以在不同上下文中表现出截然不同的行为。在函数中,它扩展了局部变量的生命周期;在全局范围内,它限制了变量和函数的可见性;在类中,它支持成员的共享性。通过合理使用 static,可以提升程序的性能、安全性以及代码的可维护性。然而,滥用 static 也可能导致难以发现的错误或模块间的耦合问题,因此需要谨慎对待。
3.5、auto 关键字
在早期 C/C++ 中 auto 的含义是:使用 auto 修饰的变量,是具有自动存储器的局部变量,但遗憾的是一直没有人去使用它,为什么?
C++11 中,标准委员会赋予了 auto 全新的含义即:auto 不在是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto 声明的变量必须由编译器在编译时期推导而得。
3.5.1、类型别名思考
随着程序越来越复杂,程序中用到的类型也越来越复杂,经常体现在
类型难于拼写含义不明确导致容易出错#include <string>#include <map>int main{std::map<std::string, std::string> m{{"apple", "苹果"}, {"orange", "橙子"}, {"pear", "梨子"}};std::map<std::string, std::string>::iterator it = m.begin();while (it != m.end()){// ...}return 0;}std::map<std::string, std::string>::iterator 是一个类型,但是该类型太长了,特别容易写错。聪明的你肯定已经想到了:可以通过 typedef 给类型取别名,比如:
#include <string>#include <map>typedef std::map<std::string, std::string> Map;int main{Map m{{"apple", "苹果"}, {"orange", "橙子"}, {"pear", "梨子"}};Map it = m.begin();while (it != m.end()){// ...}return 0;}使用 typedef 给类型取别名确实可以简化代码,但是 typedef 有会遇到新的难题:
typedef char* pstring;int main(){const pstring p1;// 编译成功还是失败?const pstring* p2;// 编译成功还是失败?return 0;}在编程时,常常需要把表达式的值赋值给变量,这就要求在声明变量的时候清楚地知道表达式的类型。然而有时候要做到这点并非那么容易,因此 C++11 给 auto 赋予了新的含义。
3.5.2、auto 的基本概念
auto 关键字的作用是根据初始化表达式自动推导变量的类型。其基本语法如下:
auto variable_name = expression;expression 的类型自动推导 variable_name 的类型。auto 必须在声明时初始化,否则编译器无法推导类型。 示例:
#include <iostream>int main(){int a = 10;auto b = a;// auto 自动识别类型, b 是 int 类型auto c = &a;// auto 自动识别类型, c 是 int* 类型int& d = a;// d 是 int 类型auto& e = a;// e 是 int 类型auto* f = &e;auto g = &e;// auto 后面加*意义不大, 都是 int* 类型//auto h = 10, i = 20.0;// 该行代码会编译失败, 因为 h, i 的初始化表达式类型不同cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;cout << typeid(d).name() << endl;cout << typeid(e).name() << endl;cout << typeid(f).name() << endl;cout << typeid(g).name() << endl;//auto e;// 无法通过编译, 使用 auto 定义变量时必须对其进行初始化return 0;}注意:使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto的实际类型。因此auto并非是一种"类型"的声明,而是一个类型声明时的"占位符”,编译器在编译期会将auto替换为变量实际的类型
3.5.3、auto 的使用场景
1、简化变量声明
在 C++ 中,某些类型的声明可能非常复杂,比如带有模板或迭代器的变量。使用 auto 可以避免冗长的代码。
示例:传统迭代器声明:
#include <vector>#include <iostream>int main() { std::vector<int> vec = {1, 2, 3, 4, 5}; // 传统声明方式 std::vector<int>::iterator it = vec.begin(); // 使用 auto auto auto_it = vec.begin(); std::cout << *auto_it << std::endl; // 输出 1 return 0;}2、减少模板代码的复杂性
在模板编程中,类型推导可以使代码更加清晰。
示例:模板函数返回值:
#include <iostream>#include <type_traits>template <typename T, typename U>auto add(T a, U b) -> decltype(a + b) { return a + b;}int main() { auto result = add(5, 3.14); // result 的类型为 double std::cout << result << std::endl; return 0;}3、减少类型依赖
当变量的类型可能因为某些原因改变时,使用 auto 可以避免因类型修改而需要更改大量代码的问题。
示例:类型变更:
#include <vector>int main() { std::vector<int> numbers = {1, 2, 3, 4, 5}; for (auto num : numbers) { // 自动推导 num 的类型 std::cout << num << " "; } return 0;}3.5.4、auto 的细节与注意事项
1、auto 必须初始化
auto 关键字的类型推导依赖于初始化表达式,因此不能使用未初始化的 auto 变量。
auto x; // 错误: 没有初始值, 编译器无法推导类型2、auto 的推导规则
如果表达式的类型是引用,则auto 会忽略引用,直接推导为其基本类型。如果需要保留引用,可以使用 auto&。 示例:引用的推导:
int a = 10;int& ref = a;// auto 忽略引用auto x = ref; // x 的类型为 intx = 20; // 修改 x 不影响 ref// 使用 auto&auto& y = ref; // y 的类型为 int&y = 30; // 修改 y 会影响 ref3、数组与指针
对于数组,auto 会将其推导为指针。如果需要保留数组类型,可以使用 auto(&)。 示例:数组推导:
#include <iostream>int main() { int arr[] = {1, 2, 3, 4, 5}; // auto b[] = {6, 7, 8, 9};// error, auto 不能直接用来声明数组 auto p = arr; // p 的类型为 int* auto(&ref)[5] = arr; // ref 的类型为 int(&)[5] std::cout << p[0] << " " << ref[0] << std::endl; return 0;}4、const 与 auto
如果初始化表达式是const,auto 会忽略 const 限定。使用 const auto 可以保留常量属性。 示例:const 的推导:
const int a = 10;auto x = a; // x 的类型为 intconst auto y = a; // y 的类型为 const int3.5.5、auto 的局限性
虽然 auto 简化了代码,但在某些情况下,可能会带来问题:
auto 是 C++11 引入的,较早的编译器版本可能不支持。 3.5.6、auto 的扩展应用
1、与范围 for 循环结合
auto 常用于范围 for 循环,进一步简化代码。
#include <vector>#include <iostream>int main() { std::vector<int> nums = {1, 2, 3, 4, 5}; for (auto& num : nums) { // 使用 auto& 修改元素 num *= 2; } for (auto num : nums) { // 使用 auto 遍历 std::cout << num << " "; } return 0;}2、与 decltype 配合
auto 可以与 decltype 配合,进一步增强类型推导能力。
#include <iostream>template <typename T1, typename T2>auto multiply(T1 a, T2 b) -> decltype(a * b) { return a * b;}int main() { auto result = multiply(5, 3.5); std::cout << result << std::endl; // 输出: 17.5 return 0;}3.5.7、小结
auto 是 C++ 的重要特性之一,通过自动类型推导,简化了代码,提升了开发效率。它的广泛应用涵盖了变量声明、模板编程、范围 for 循环等多种场景。在使用 auto 时,需注意其推导规则、可能的局限性,以及在复杂代码中的可读性问题。通过合理使用 auto,可以大大提升 C++ 代码的简洁性和灵活性。
3.6、小结
C++ 提供了丰富的关键字,用于支持面向对象编程、异常处理、模板、动态内存管理等特性。在开发中,理解并正确使用这些关键字是写出高效且优雅代码的基础。通过深入理解和合理使用这些关键字,开发者可以高效构建复杂系统。结合实际代码示例和扩展阅读,可以更好地理解并掌握每个关键字的用途及其最佳实践。
如果你对 C++ 关键字还想进行更加深入的了解的话,可以移步我的这篇关于 C++关键字 的专题博客:《 C++ 点滴漫谈: 二 》穿越代码的迷雾:C++ 关键字的应用与未来
4、namespace
命名空间(Namespace)是 C++ 引入的一项重要特性,用于解决命名冲突和管理代码的逻辑结构。在大型项目中,命名空间的合理使用可以显著提高代码的可读性、可维护性和扩展性。本节将从命名空间的基本概念到高级应用逐步展开,全面剖析 C++ 命名空间的方方面面。
4.1、什么是命名空间?
命名空间是一种逻辑分组机制,用于将标识符(如变量、函数、类等)组织到一个独立的范围内。通过使用命名空间,可以避免全局作用域中的命名冲突问题。
4.1.1、命名空间的特点
分组功能:将相关的标识符归类到同一个命名空间中。避免冲突:不同命名空间中的标识符互不干扰。支持嵌套:命名空间可以嵌套定义。可扩展性:命名空间可以在不同文件中扩展。4.1.2、命名空间的语法
namespace Lenyiin// Lenyiin 为命名空间的名字 { // 标识符定义 // 命名空间中的内容, 既可以定义变量, 也可以定义函数、类 // 同一个工程中允许存在相同名称的命名空间,编译器最后会合成同一个命名空间中 int variable; void function(); class MyClass {};}定义在名称空间中的变量或者函数都称为实体,名称空间中的实体作用域是全局的,并不意味着其可见域是全局的。
如果不使用作用域限定符和 using 机制,抛开名称空间嵌套和内部屏蔽的情况,实体的可见域是从实体创建到该名称空间结束。
在名称空间外,该实体是不可见的。
4.2、为什么需要命名空间?
一个大型的工程往往是由若干个人独立完成的,不同的人分别完成不同的部分,最后再组合成一个完整
的程序。由于各个头文件是由不同的人设计的,有可能在不同的头文件中用了相同的名字来命名所定义
的类或函数,这样在程序中就会出现名字冲突。不仅如此,有可能我们自己定义的名字会与 C++ 库中的
名字发生冲突。名字冲突就是在同一个作用域中有两个或多个同名的实体。
在 C 语言中,所有全局标识符都共享同一个命名空间,这在大型项目中可能导致命名冲突。例如:
int count = 10; // 定义一个全局变量void count() { // 错误:函数名冲突 // ...}为了解决命名冲突,C++中引入了命名空间,所谓命名空间就是一个可以由用户自己定义的作用域,在不同的作用域中可以定义相同名字的变量,互不干扰,系统能够区分它们,通过将标识符分组,避免全局冲突。
4.3、命名空间的基本用法
4.3.1、定义命名空间
可以通过 namespace 关键字定义命名空间:
namespace MyNamespace { int value = 42; void printValue() { std::cout << "Value: " << value << std::endl; }}4.3.2、访问命名空间中的成员
有两种方式访问命名空间中的成员:
使用作用域解析运算符 :: :
MyNamespace::printValue();使用 using 声明或 using 指令:
using 声明:
using MyNamespace::value;std::cout << value; // 直接使用using 指令:
using namespace MyNamespace;printValue(); // 不需要加命名空间前缀4.3.3、匿名命名空间
匿名命名空间(Unnamed Namespace)没有名字,定义的标识符仅在当前文件内有效。常用于限制标识符的作用范围:
namespace { int localVar = 100; // 仅在当前文件中可见}4.3.4、嵌套命名空间
命名空间可以嵌套定义,从而形成层次化的逻辑结构:
namespace Outer { namespace Inner { void func() { std::cout << "Nested namespace" << std::endl; } }}// 调用嵌套命名空间的函数Outer::Inner::func();4.4、命名空间的高级应用
4.4.1、扩展命名空间
可以在不同的文件或代码块中对同一个命名空间进行扩展:
namespace MyNamespace { void newFunction() { std::cout << "Extended namespace function" << std::endl; }}4.4.2、命名空间别名
为了简化嵌套命名空间的使用,可以使用别名:
namespace MN = MyNamespace;MN::printValue();4.4.3、内联命名空间
C++11 引入了内联命名空间,支持在命名空间嵌套中直接访问其成员,而无需指定完整路径:
namespace Outer { inline namespace Inner { void func() { std::cout << "Inline namespace" << std::endl; } }}Outer::func(); // 可直接访问4.5、命名空间的实际案例
4.5.1、标准命名空间 std
C++ 标准库所有内容都定义在命名空间 std 中。例如:
#include <iostream>#include <string>int cout = 0;// cout和库函数重名, 建议不要取库函数名类似的名字using std::cout;// using声明机制, 声明后就可以直接使用cout, 不用加std::coutusing std::endl;// 可以选择不全展开, 只展开需要的部分int main(){// 自动识别类型cout << "Hello World!" << endl;// std::cout << "Hello World!" << endl;// 非要取重名的名字, 可以用std::coutint a = 10;cin >> a;// cin是输入流, >> 是提取运算符, endl是换行符cout << a << endl;// cout是输出流, << 是插入运算符, endl是换行符system("pause");// 暂停, 等待用户输入任意键继续return 0;}4.5.2、多团队协作中的命名空间
在大型项目中,不同团队可以为其模块定义独立的命名空间。例如:
namespace TeamA { void processData() { std::cout << "Processing data in Team A" << std::endl; }}namespace TeamB { void processData() { std::cout << "Processing data in Team B" << std::endl; }}4.5.3、匿名命名空间的应用
命名空间还可以不定义名字,不定义名字的命名空间称为匿名命名空间。由于没有名字,该空间中的实体,其它文件无法引用,它只能在本文件的作用域内有效,它的作用域是从匿名命名空间声明开始到本文件结束。在本文件使用无名命名空间成员时不必用命名空间限定。其实匿名命名空间和static是同样的道理,都是只在本文件内有效,无法被其它文件引用。
在文件内定义静态函数或变量,避免污染全局命名空间:
namespace {int val = 10; void helperFunction() { std::cout << "Helper function in anonymous namespace" << std::endl; }}int main() { helperFunction(); return 0;}在匿名空间中创建的全局变量,具有全局生存期,却只能被本空间内的函数等访问,是 static 变量的有效替代手段。
4.6、命名空间的注意事项
避免过度嵌套:嵌套过多的命名空间会增加代码复杂度。合理使用using 指令:过多的 using namespace 可能引入意外的命名冲突。命名规范:为命名空间选择清晰、易懂的名字,避免过于笼统的命名。 4.7、小结
命名空间是 C++ 语言中用于组织代码的强大工具。通过合理使用命名空间,可以有效解决命名冲突问题,增强代码的可读性和模块化程度。从简单的逻辑分组到高级特性(如内联命名空间和别名),命名空间的应用范围广泛,是 C++ 开发者必须掌握的技能。
5、C++基础语法 — 变量和数据类型
C++ 是一门兼具高性能和灵活性的编程语言,其基础语法体系提供了丰富的功能,使开发者可以高效编写从简单到复杂的程序。本节将详细介绍 C++ 的基础语法,涵盖变量和数据类型、输入输出、控制流、函数、数组与指针、类与对象等核心内容,并辅以代码示例。
在 C++ 中,变量 是数据的存储单元,而 数据类型 则决定了变量可以存储的值的类型及其范围。理解变量与数据类型是掌握 C++ 编程的第一步。本节将全面介绍变量与数据类型的概念、分类、声明方式及其应用。
5.1、什么是变量?
变量是程序运行时用来存储数据的命名存储单元。变量允许程序动态地操作数据,并通过其名称访问存储的值。
变量的特点:
每个变量都有一个类型,决定了它的取值范围和内存占用大小。变量名称是访问存储数据的标识符。变量的值可以被修改,但其类型不能改变。变量声明语法:
<数据类型> <变量名> [= 初始值];示例:
int age = 25; // 整型变量float height = 5.9; // 浮点型变量5.2、C++ 中的数据类型
C++ 提供了多种基本数据类型,分为内置类型和用户定义类型。
常见数据类型:
整型(int): 存储整数,如 int a = 10;浮点型(float, double): 存储小数,如 float pi = 3.14;字符型(char): 存储单个字符,如 char c = 'A';布尔型(bool): 存储布尔值,如 bool flag = true;空类型(void): 用于函数无返回值时声明。 5.2.1、基本数据类型
整型(Integer)
用于存储整数,分为以下几种:
int:标准整型。short:短整型,占用内存较小。long:长整型,适合存储更大的整数。long long:超长整型。 示例:
int x = 10;long y = 1000000;浮点型(Floating-point)
用于存储小数或实数:
float:单精度浮点数。double:双精度浮点数,精度更高。long double:扩展精度浮点数。 示例:
float pi = 3.14f;double e = 2.71828;字符型(Character)
用于存储单个字符:
char:占用 1 字节。 示例:
char grade = 'A';布尔型(Boolean)
用于存储布尔值:
bool:值为 true 或 false。 示例:
bool isPassed = true;5.2.2、构造数据类型
数组(Array):存储相同数据类型的多个值。结构体(Struct):用户定义的一组不同数据类型的集合。类(Class):面向对象编程中的核心,用户定义的数据类型。枚举(Enum):用于定义有限集合的命名常量。示例:结构体
struct Point { int x; int y;};Point p1 = {1, 2};5.2.3、指针类型
指针是存储内存地址的变量。指针允许程序动态地操作内存。
示例:
int a = 10;int* p = &a; // 指针 p 存储 a 的地址5.2.4、空类型(Void)
空类型表示函数无返回值,或者作为泛型指针使用。
示例:
void display() { cout << "Hello, World!" << endl;}5.3、变量的作用域与生命周期
C++ 中变量的作用域和生命周期分为以下几种:
局部变量:定义在函数或代码块内部,仅在该范围内有效。全局变量:定义在所有函数外部,整个程序都可以访问。静态变量:使用static 修饰,生命周期贯穿整个程序。动态变量:通过 new 和 delete 操作符动态分配和释放内存。 示例:静态变量
void counter() { static int count = 0; count++; cout << "Count: " << count << endl;}5.4、类型修饰符
C++ 提供了一些修饰符,用于扩展数据类型的功能:
signed / unsigned:控制数值是否带符号。short / long:调整整数的存储大小。 示例:
unsigned int positiveNum = 10;signed int negativeNum = -10;5.5、常量与枚举
C++ 中的常量表示不可修改的变量。
常量声明: 使用const 或 constexpr 修饰。枚举: 定义一组相关常量。 代码示例:
const double PI = 3.14159;enum Color { RED, GREEN, BLUE };Color favoriteColor = GREEN;5.6、示例代码:变量与数据类型综合应用
#include <iostream>using namespace std;int main() { // 基本数据类型 int age = 30; double salary = 85000.50; char grade = 'A'; bool isEmployed = true; // 数组 int scores[5] = {90, 85, 88, 92, 95}; // 枚举 enum Day { MON, TUE, WED, THU, FRI, SAT, SUN }; Day today = WED; // 指针 int* pAge = &age; // 输出 cout << "Age: " << age << ", Salary: $" << salary << ", Grade: " << grade << endl; cout << "Employed: " << (isEmployed ? "Yes" : "No") << endl; cout << "Today is day: " << today << endl; cout << "Pointer to age: " << *pAge << endl; return 0;}5.7、小结
C++ 的变量和数据类型构成了编程的基础,通过多样化的数据类型、灵活的变量修饰以及类型转换,程序员能够高效地操作数据并优化内存使用。理解变量的作用域与生命周期是深入学习复杂功能的关键,而类型转换与常量的应用则增强了程序的灵活性和安全性。在实际开发中,灵活选择合适的数据类型与变量修饰符将大大提升代码的性能与可读性。
6、输入输出
C++ 的输入与输出操作是程序与用户或文件进行交互的基础功能。C++ 提供了丰富的输入输出机制,通过标准输入输出流和文件流实现多样化的功能。本节将详细探讨 C++ 中的输入输出操作,涵盖基础概念、操作方法、进阶技巧及代码示例。
6.1、输入输出的基础概念
C++ 的输入输出机制基于 流(Stream) 模型:
输入流(Input Stream):用于读取数据,如cin。输出流(Output Stream):用于输出数据,如 cout。 输入输出流的核心类:
std::istream:输入流类。std::ostream:输出流类。std::iostream:输入输出流基类。 标准输入输出流:
std::cin:标准输入流,通常是键盘。std::cout:标准输出流,通常是屏幕。std::cerr:标准错误流,用于输出错误信息。std::clog:标准日志流,用于记录日志。 6.2、基本输入输出操作
6.2.1、标准输出 std::cout
使用 << 操作符将数据输出到控制台。
示例:
#include <iostream>// std 是 C++ 标准库的命名空间名, C++ 将标准库的定义实现都放到了这个命名空间using namespace std;int main() { int a = 10; cout << "The value of a is: " << a << endl; // 输出整数 cout << "Hello, World!" << endl; // 输出字符串 return 0;}std::endl 与 \n 的区别:
std::endl 插入换行符并刷新输出缓冲区。\n 仅插入换行符,不刷新缓冲区。 6.2.2、标准输入 std::cin
使用 >> 操作符从标准输入读取数据。
示例:
#include <iostream>using namespace std;int main() { int x; cout << "Enter a number: "; cin >> x; // 从用户输入中读取整数 cout << "You entered: " << x << endl; return 0;}注意:
>> 操作符会跳过空格、换行和制表符。如果输入与期望类型不匹配,输入流将进入错误状态。 6.2.3、标准错误流 std::cerr 和 std::clog
std::cerr:直接输出错误信息,输出时不缓存。std::clog:用于输出日志信息,输出时缓冲。 示例:
#include <iostream>using namespace std;int main() { cerr << "Error: Invalid input!" << endl; clog << "Log: Program started successfully." << endl; return 0;}6.2.4、注意事项
使用cout 标准输出对象(控制台)和 cin 标准输入对象(键盘)时,必须包含 <iostream> 头文件,以及按命名空间使用方法使用 std。cout 和 cin 是全局的流对象,endl 是特殊的 C++ 符号,表示换行输出,他们都包含在包含 <iostream> 头文件中。<< 是流插入运算符,>> 是流提取运算符。使用 C++ 输入输出更方便,不需要像 printf/scanf 输入输出时那样,需要手动控制格式。C++ 的输入输出可以自动识别变量类型。实际上 cout 和 cin 分别是 ostream 和 istream 类型的对象,>> 和 << 也涉及运算符重载等知识,后面的博客再更深入讲解。 注意:早期标准库将所有功能在全局域中实现,声明在 .h 后缀的头文件中,使用时只需包含对应头文件即可,后来将其实现在 std 命名空间下,为了和 C 头文件区分,也为了正确使用命名空间,规定 C++ 头文件不带 .h 。旧编译器 (vc 6.0) 中还支持 <iostream.h> 格式,后续编译器已不支持,因此推荐使用 <iostream> + std 的方式。
6.3、进阶输入输出操作
6.3.1、格式化输出
C++ 提供了 iomanip 头文件,可以设置输出格式。
常用格式化操作:
std::setw(n):设置宽度。std::setprecision(n):设置小数精度。std::fixed 和 std::scientific:设置浮点数格式。 示例:
#include <iostream>#include <iomanip>using namespace std;int main() { double pi = 3.141592653589793; cout << fixed << setprecision(3) << "Pi: " << pi << endl; cout << scientific << "Pi in scientific notation: " << pi << endl; return 0;}6.3.2、字符与字符串输入输出
字符输入输出: 使用 std::cin.get() 和 std::cout.put() 处理字符。
示例:
char c;cin.get(c);cout.put(c);字符串输入输出: 使用 std::getline() 处理整行输入。
示例:
string name;cout << "Enter your name: ";getline(cin, name);cout << "Hello, " << name << "!" << endl;6.3.3、输入输出错误处理
C++ 提供了输入输出状态检查机制:
std::cin.fail():检测输入流是否出错。std::cin.eof():检测是否到达输入流末尾。std::cin.clear():清除错误状态。 示例:
#include <iostream>using namespace std;int main() { int num; cout << "Enter a number: "; cin >> num; if (cin.fail()) { cerr << "Error: Invalid input!" << endl; cin.clear(); // 清除错误状态 cin.ignore(1000, '\n'); // 忽略无效输入 } else { cout << "You entered: " << num << endl; } return 0;}6.4、文件输入输出
C++ 使用 fstream 头文件进行文件操作:
std::ifstream:文件输入流。std::ofstream:文件输出流。std::fstream:文件输入输出流。 6.4.1、文件写入
示例:
#include <fstream>using namespace std;int main() { ofstream outFile("example.txt"); if (outFile.is_open()) { outFile << "Hello, file!" << endl; outFile.close(); } return 0;}6.4.2、文件读取
示例:
#include <fstream>#include <iostream>using namespace std;int main() { ifstream inFile("example.txt"); if (inFile.is_open()) { string line; while (getline(inFile, line)) { cout << line << endl; } inFile.close(); } return 0;}6.4.3、文件读写
示例:
#include <fstream>#include <iostream>using namespace std;int main() { fstream file("data.txt", ios::in | ios::out | ios::app); if (file.is_open()) { file << "Appending data to the file." << endl; file.seekg(0); // 将文件指针移到开头 string line; while (getline(file, line)) { cout << line << endl; } file.close(); } return 0;}6.5、输入输出的最佳实践
检查输入输出流状态:确保操作正确完成。使用格式化工具:提升数据输出的可读性。资源管理:及时关闭文件流,避免资源泄漏。合理使用缓冲:优化性能。6.6、小结
C++ 的输入输出功能以流为核心,支持多种操作场景,从简单的标准输入输出到复杂的文件操作。本节不仅介绍了基本用法,还涵盖了格式化输入输出、错误处理和文件流操作,帮助开发者掌握更灵活高效的数据交互方法。熟练应用这些功能是编写高效、健壮 C++ 程序的关键。
7、控制流
控制流是决定程序执行路径的关键,它通过条件判断、循环以及跳转语句控制程序的逻辑执行顺序。C++ 提供了丰富的控制流语句,帮助开发者编写灵活高效的程序。本节将全面介绍 C++ 中的控制流,包括条件分支、循环结构及跳转语句,辅以详细的解释和示例。
7.1、控制流的基本概念
程序执行的三种基本控制流:
顺序结构:代码按照书写顺序从上到下依次执行。分支结构:根据条件的真或假,选择不同的执行路径。循环结构:重复执行某些代码块,直到满足特定条件。C++ 控制流分为三大类:
条件分支语句:if、if-else、switch。循环语句:for、while、do-while。跳转语句:break、continue、goto。 7.2、条件分支语句
7.2.1、if 语句
if 语句根据条件的真假决定是否执行某段代码。
语法:
if (条件) { // 条件为真时执行的代码}示例:
#include <iostream>using namespace std;int main() { int x = 10; if (x > 5) { cout << "x is greater than 5" << endl; } return 0;}7.2.2、if-else 语句
if-else 语句在条件为假时执行另一段代码。
语法:
if (条件) { // 条件为真时执行} else { // 条件为假时执行}示例:
#include <iostream>using namespace std;int main() { int x = 3; if (x > 5) { cout << "x is greater than 5" << endl; } else { cout << "x is less than or equal to 5" << endl; } return 0;}7.2.3、if-else if-else 语句
用于处理多个条件分支。
语法:
if (条件1) { // 条件1为真时执行} else if (条件2) { // 条件2为真时执行} else { // 条件1和条件2都为假时执行}示例:
#include <iostream>using namespace std;int main() { int score = 85; if (score >= 90) { cout << "Grade: A" << endl; } else if (score >= 80) { cout << "Grade: B" << endl; } else { cout << "Grade: C" << endl; } return 0;}7.2.4、switch 语句
switch 语句用于处理多个可能的值。
语法:
switch (表达式) { case 常量1: // 代码块1 break; case 常量2: // 代码块2 break; default: // 默认代码块}示例:
#include <iostream>using namespace std;int main() { int day = 3; switch (day) { case 1: cout << "Monday" << endl; break; case 2: cout << "Tuesday" << endl; break; case 3: cout << "Wednesday" << endl; break; default: cout << "Invalid day" << endl; } return 0;}注意:
break 防止继续执行后续的 case。default 是可选的,但建议提供以处理未知值。 7.3、循环语句
7.3.1、for 循环
for 循环在已知循环次数时使用。
语法:
for (初始化; 条件; 更新) { // 循环体}示例:
#include <iostream>using namespace std;int main() { for (int i = 0; i < 5; i++) { cout << "Iteration: " << i << endl; } return 0;}7.3.2、while 循环
while 循环在满足条件时重复执行。
语法:
while (条件) { // 循环体}示例:
#include <iostream>using namespace std;int main() { int x = 0; while (x < 5) { cout << "x: " << x << endl; x++; } return 0;}7.3.3、do-while 循环
do-while 循环至少执行一次。
语法:
do { // 循环体} while (条件);示例:
#include <iostream>using namespace std;int main() { int x = 0; do { cout << "x: " << x << endl; x++; } while (x < 5); return 0;}7.4、跳转语句
7.4.1、break
break 语句用于退出当前循环或 switch 语句。
示例:
#include <iostream>using namespace std;int main() { for (int i = 0; i < 10; i++) { if (i == 5) { break; // 提前退出循环 } cout << i << " "; } return 0;}7.4.2、continue
continue 语句跳过当前循环剩余部分,进入下一次迭代。
示例:
#include <iostream>using namespace std;int main() { for (int i = 0; i < 10; i++) { if (i % 2 == 0) { continue; // 跳过偶数 } cout << i << " "; } return 0;}7.4.3、goto
goto 是一种无条件跳转,但不建议使用。
语法:
goto 标号;标号: // 代码块示例:
#include <iostream>using namespace std;int main() { int x = 0; start: if (x < 5) { cout << x << " "; x++; goto start; // 跳转到标号 } return 0;}7.5、嵌套与组合
控制流语句可以嵌套或组合以实现复杂逻辑。
示例:
#include <iostream>using namespace std;int main() { for (int i = 1; i <= 3; i++) { for (int j = 1; j <= 3; j++) { cout << "i: " << i << ", j: " << j << endl; } } return 0;}7.6、控制流的最佳实践
清晰的逻辑结构:避免过深的嵌套。尽量避免使用goto:难以维护代码。合适的注释:帮助理解复杂的控制流。简化条件表达式:使用函数或变量名提高可读性。 7.7、小结
控制流是 C++ 程序开发的核心。通过灵活运用条件分支、循环和跳转语句,开发者可以实现复杂的程序逻辑。本节不仅讲解了基础语法,还提供了大量的示例与实践建议,帮助开发者全面掌握控制流的使用技巧。这是构建高效、可维护代码的基础。
8、函数
函数是程序设计的基本模块化单元,用于将代码逻辑封装到一个独立的功能块中。在 C++ 中,函数通过名称调用,并可接受参数和返回值。函数的使用不仅提高了代码的可重用性和可读性,还帮助开发者实现复杂逻辑的分解和管理。
8.1、什么是函数?
函数是一段完成特定任务的代码块,可以根据需要多次调用。C++ 支持各种类型的函数,包括普通函数、内联函数、递归函数和模板函数等。
8.1.1、函数的基本组成:
返回类型:函数的输出类型,使用void 表示没有返回值。函数名:标识函数的名称,遵循变量命名规则。参数列表:函数所接受的输入参数,位于小括号内。函数体:包含函数的实现逻辑,用花括号 {} 包裹。 8.1.2、函数的基本语法:
返回类型 函数名(参数列表) { // 函数体 return 返回值; // 如果返回类型为 void,则可以省略 return。}8.2、函数的声明与定义
8.2.1、函数声明(Function Declaration)
函数声明用于告诉编译器函数的名称、参数和返回类型。
语法:
返回类型 函数名(参数列表);示例:
int add(int a, int b); // 声明一个加法函数8.2.2、函数定义(Function Definition)
函数定义包含函数的实现逻辑。
示例:
int add(int a, int b) { // 定义加法函数 return a + b;}8.2.3、函数调用(Function Call)
通过函数名加括号调用函数,并传递必要的参数。
示例:
#include <iostream>using namespace std;int add(int a, int b); // 声明int main() { cout << "Sum: " << add(3, 4) << endl; // 调用 return 0;}int add(int a, int b) { // 定义 return a + b;}8.3、函数的参数
8.3.1、参数按值传递
函数的参数是按值传递的,实参的值被复制给形参,函数内的修改不会影响实参。
示例:
void modify(int x) { x = 100; // 修改仅在函数内部有效}int main() { int num = 10; modify(num); cout << "num: " << num << endl; // 输出 10 return 0;}8.3.2、参数按引用传递
通过引用传递参数,函数内对参数的修改会直接影响实参。
示例:
void modify(int &x) { // 使用引用 x = 100;}int main() { int num = 10; modify(num); cout << "num: " << num << endl; // 输出 100 return 0;}8.3.3、参数默认值 (缺省参数)
函数参数可以指定默认值,在调用时可以省略该参数。
缺省参数是声明或定义函数时为函数的参数指定一个默认值。在调用该函数时,如果没有指定实参则采用该默认值,否则使用指定的实参。
示例:
// 半缺省(缺省部分)必须从右往左依次缺省int Add(int left, int right = 0)// right缺省参数,可以不传,不传就用默认值{return left + right;}// 全缺省void Test(int a = 10, int b = 20, int c = 30)// 全缺省参数, 可以不传, 不传就用默认值{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl;}int main(){int a = 10;int b = 20;int c = Add(a, b);// 传两个参数int d = Add(a);// 只传一个参数, 另一个参数用默认值cout << c << endl;cout << d << endl;Test();// 不传参数, 三个参数都用默认值Test(1);// 传一个参数, 其他参数用默认值Test(1, 2);// 传两个参数, 另一个参数用默认值Test(1, 2, 3);// 传三个参数, 不用默认值system("pause");return 0;}注意:
半缺省参数必须从右往左依次来给出,不能间隔着给
缺省参数不能在函数声明和定义中同时出现
// a.hvoid TestFunc(int a = 10);// a.cvoid TestFunc(int a = 20){}// 注意:如果声明和定义位置同时出现,恰巧两个位置提供的值不同,那编译器就无法确定到底该用哪个缺省值缺省值必须是常量或者全局遍历
C 语言不支持(编译器不支持)
8.3.4、可变参数函数
C++ 提供了 ... 语法实现可变参数函数,常见于库函数,如 printf。
示例:
#include <cstdarg>#include <iostream>using namespace std;int sum(int count, ...) { va_list args; va_start(args, count); int total = 0; for (int i = 0; i < count; i++) { total += va_arg(args, int); } va_end(args); return total;}int main() { cout << "Sum: " << sum(3, 1, 2, 3) << endl; // 输出 6 return 0;}8.4、引用
C++ 中的引用(reference)是一种高级特性,通过别名的方式为变量提供了一种更灵活的访问方式。引用常用于函数参数传递、返回值优化和内存管理以及复杂数据结构的操作中,是理解 C++ 高效编程的关键。
8.4.1、什么是引用
引用是一个变量的别名,通过引用可以直接操作该变量,而无需显式地访问变量本身。
引用的定义使用 & 符号,语法如下:
数据类型 &引用名 = 原变量名;type &reference_name = original_variable;引用的特点
必须初始化:引用在定义时必须被初始化,且不能更改引用的绑定对象。操作引用等同于操作原变量:引用和原变量共享同一块内存地址。不占用额外内存:引用仅作为原变量的别名存在。8.4.2、引用的基本使用
1、引用定义与使用
#include <iostream>using namespace std;int main() { int x = 10; int &ref = x; // 引用定义 cout << "x: " << x << ", ref: " << ref << endl; ref = 20; // 修改引用即修改原变量 cout << "x: " << x << ", ref: " << ref << endl; return 0;}输出:
x: 10, ref: 10x: 20, ref: 202、引用的本质
引用本质上是变量的一个别名,它与变量共享同一块内存空间:
#include <iostream>using namespace std;int main() { int x = 10; int &ref = x; cout << "Address of x: " << &x << endl; cout << "Address of ref: " << &ref << endl; return 0;}输出:
Address of x: 0x7ffee54c88acAddress of ref: 0x7ffee54c88ac8.4.3、引用的特性
1、必须初始化
引用在定义时必须被初始化,因为它需要立即绑定到某个变量。
int &ref; // 错误,引用必须初始化2、一旦绑定,无法更改绑定对象
引用的绑定是不可变的,一旦绑定到一个变量,就无法再绑定到其他变量。
cint a = 10, b = 20;int &ref = a;ref = b; // 修改的是 a 的值, 而不是更改引用的绑定3、与变量共享内存
引用与其绑定的变量共享内存,因此引用只是访问原变量的一种方式。
8.4.4、引用的类型
1、左值引用
左值引用绑定到左值变量,可以对变量进行修改:
int a = 10;int &ref = a; // 左值引用ref = 20; // 修改引用即修改 a2、右值引用
右值引用绑定到右值变量,用于资源的移动和临时对象的优化:
int &&rref = 10; // 右值引用3、常量引用
常量引用(const 引用)可以绑定到常量或右值,且不能通过引用修改原值:
const int &ref = 10; // 常量引用// ref = 20; // 错误:不能修改常量引用绑定的值4、通用引用
通用引用(T&&)是一种模板参数,可以同时绑定到左值和右值:
template <typename T>void func(T&& val) { // 通用引用}8.4.5、引用在函数中的使用
1、引用作为函数参数
使用引用参数可以避免值拷贝,直接操作原变量:
#include <iostream>using namespace std;void increment(int &x) { x += 1;}int main() { int a = 10; increment(a); // 传递引用 cout << "a: " << a << endl; // a: 11 return 0;}2、常量引用参数
使用 const 引用可以防止函数修改参数,且允许绑定到临时对象:
void print(const string &msg) { cout << msg << endl;}int main() { print("Hello, World!"); // 临时字符串绑定到常量引用 return 0;}3、引用作为函数返回值
函数可以通过返回引用直接返回变量本身:
int& max(int &x, int &y) { return (x > y) ? x : y;}int main() { int a = 10, b = 20; int &result = max(a, b); result = 30; // 修改 result 即修改原变量 cout << "a: " << a << ", b: " << b << endl; return 0;}输出:
a: 10, b: 30注意:返回引用时确保返回的变量是有效的,避免返回局部变量引用。
8.4.6、左值引用与右值引用的区别
| 特性 | 左值引用(T&) | 右值引用(T&&) |
|---|---|---|
| 绑定对象 | 左值 | 右值或临时对象 |
| 修改原值 | 可以修改 | 可以修改 |
| 用途 | 共享数据 | 临时对象的优化和资源移动 |
| 典型场景 | 普通变量的引用 | 实现移动语义和完美转发 |
8.4.7、引用与指针的对比
| 特性 | 引用 | 指针 |
|---|---|---|
| 定义 | 必须初始化 | 可以不初始化 |
| 绑定后是否可变 | 不可更改绑定 | 可以更改指向的对象 |
| 是否支持空值 | 不支持空引用 | 可以指向 nullptr |
| 内存访问 | 更直接,语法简单 | 需要解引用 |
| 用途 | 参数传递、返回值 | 动态内存管理、灵活操作 |
示例:指针和引用的区别
#include <iostream>using namespace std;int main() { int a = 10, b = 20; int &ref = a; // 引用 int *ptr = &a; // 指针 ref = b; // 修改 a 的值 ptr = &b; // 指针指向 b cout << "a = " << a << ", b = " << b << endl; // 输出 a = 20, b = 20 return 0;}8.4.8、引用的实际应用
1、避免拷贝
使用引用避免对大型对象的拷贝,提高效率:
void process(const vector<int>& data) { // 避免对 data 的拷贝}2、实现函数链式调用
引用可以实现函数的链式调用:
#include <iostream>using namespace std;class Number {public: Number(int val) : value(val) {} Number& add(int x) { value += x; return *this; } void print() { cout << value << endl; }private: int value;};int main() { Number num(10); num.add(5).add(10).print(); // 链式调用 return 0;}3、实现移动语义
右值引用是 C++11 引入的特性,用于实现移动语义和避免不必要的拷贝:
#include <iostream>#include <vector>using namespace std;class Moveable {public: vector<int> data; Moveable(vector<int>&& d) : data(move(d)) {}};int main() { vector<int> vec = {1, 2, 3}; Moveable m(move(vec)); // 使用右值引用实现移动语义 return 0;}8.4.9、常见问题与注意事项
引用必须初始化:未初始化引用会导致编译错误。不要返回局部变量的引用:返回局部变量引用会导致未定义行为。常量引用的灵活性:常量引用可以绑定到临时对象,提升代码安全性。右值引用的误用:避免滥用右值引用,确保语义清晰。8.4.10、小结
引用是 C++ 中一种高效的变量访问方式,可以减少内存开销和提升程序性能。通过左值引用、右值引用和常量引用的组合使用,开发者可以实现更灵活的程序设计。同时,C++11 引入的右值引用和移动语义进一步提升了 C++ 在性能上的优势。在实际开发中,合理选择引用类型能够让程序更加高效和安全。
8.5、内联函数
在 C++ 编程中,内联函数(Inline Function)是用于提高性能的一种特殊函数形式。通过将函数代码直接嵌入调用处,内联函数能够避免函数调用的开销。尽管这一机制提升了效率,但其使用也需要遵循一定的规则和注意事项。本节将从概念、实现原理、使用场景、优缺点以及实际案例等方面全面解析 C++ 内联函数。
8.5.1、内联函数的概念
内联函数是由关键字 inline 修饰的函数。编译器在编译阶段将函数的代码嵌入到每个调用点,从而省略了函数调用的栈帧分配与跳转操作。这使得内联函数在性能敏感的代码中非常有用。
定义方式
内联函数的定义需要使用 inline 关键字,并且函数体通常放在头文件中。
语法:
inline 返回类型 函数名(参数列表) { // 函数体}示例:
#include <iostream>using namespace std;inline int Add(int left, int right) { return left + right;}int main() {int ret = 0; ret = Add(1, 2); return 0;}在上述代码中,编译器会将 add(1, 2) 替换为 1 + 2。
汇编下的指令:
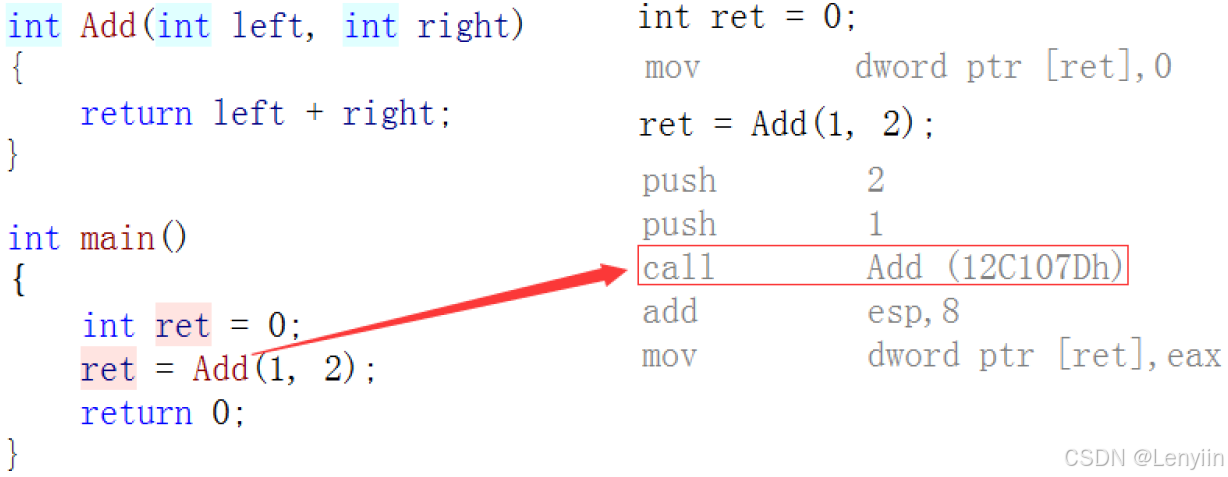
如果在上述函数前增加 inline 关键字,将其改变成内联函数,在编译期间编译器会用函数体替换函数的调用。
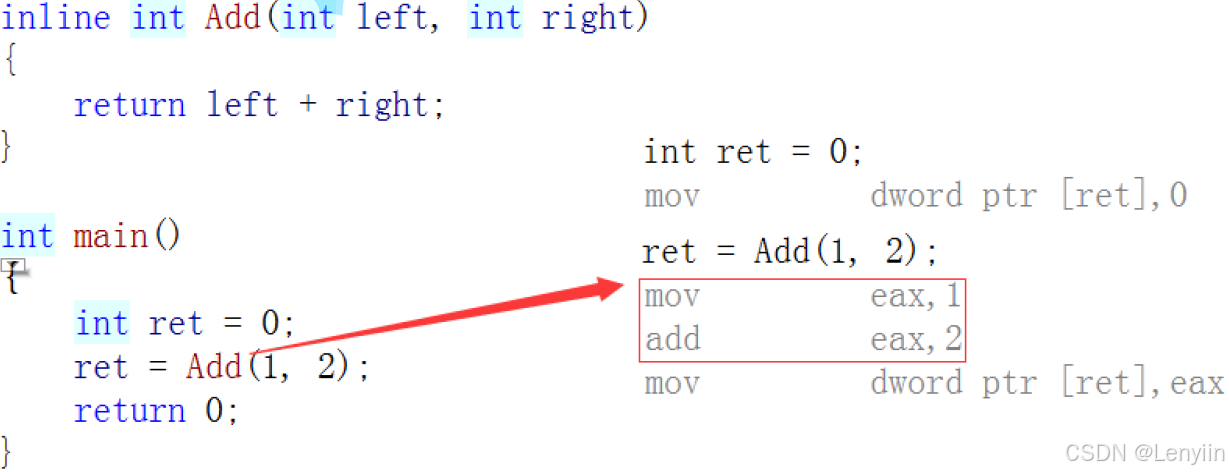
8.5.2、内联函数的实现原理
内联函数的实现是编译器优化的一部分。当函数被声明为内联时,编译器尝试在函数调用处直接插入函数的代码,从而避免常规函数调用的开销。
1、编译器的内联决策
尽管程序员可以用 inline 声明函数,但编译器并不一定会内联该函数。这取决于以下因素:
-O2 或 -O3 会启用更多的内联优化。 注意:内联函数不是强制性的,而是编译器的建议。
2、代码展开与性能
内联函数的展开过程如下:
将函数调用点替换为函数体代码。在调用处直接进行参数替换。如果有多个调用点,函数体会被多次复制。3、特性
inline 是一种以空间换时间的做法,省去调用函数的开销。所以代码很长或者有循环/递归的函数不适宜使用作为内联函数。inline 对于编译器而言只是一个建议,编译器会自动优化,如果定义为 inline 的函数体内有循环/递归等,编译器优化时会忽略掉内联。inline 不建议声明和定义分离,分离会导致链接错误。因为 inline 被展开,就没有函数地址了,链接就会找不到。 void Swap(int& left, int& right){int tmp = left;left = right;right = tmp;}// 频繁调用Swap函数需要建立栈帧,是有消耗的// 如何解决:1.C语言使用宏函数2.C++使用内联函数inline void Swap(int& left, int& right);inline int Add(int left, int right){return left + right;}int main(){int a = 10;int b = 20;int c = Add(a, b);// Add函数调用时,编译器会将Add函数的代码拷贝到这里,然后再编译// 这样做的好处是,不用调用函数,直接执行代码,提高效率// 这样做的坏处是,代码会变大,占用更多的内存空间// 所以内联函数适合代码量比较小的函数system("pause");return 0;}8.5.3、内联函数的使用场景
1、提高性能
内联函数适用于短小、频繁调用的函数。例如:
简单的算术计算。Getter 和 Setter 函数。示例:
class Rectangle {private: int width, height;public: // 内联函数 inline int getWidth() const { return width; } inline int getHeight() const { return height; } inline void setWidth(int w) { width = w; } inline void setHeight(int h) { height = h; }};2、替代宏定义
内联函数是宏定义(#define)的更安全替代方案,避免了宏的常见问题如缺乏类型检查和难以调试。
示例:
#include <iostream>// 宏定义#define SQUARE(x) ((x) * (x))// 内联函数inline int square(int x) { return x * x;}int main() { std::cout << "Macro: " << SQUARE(3 + 2) << std::endl; // 结果错误 std::cout << "Inline: " << square(3 + 2) << std::endl; // 结果正确 return 0;}8.5.4、内联函数的优缺点
1、优点
消除函数调用开销:直接插入代码,避免了栈帧的创建与销毁。提高性能:对频繁调用的短小函数效果显著。类型安全:相比宏定义,内联函数具有更好的类型检查。易于调试:支持调试符号,而宏定义在预处理阶段就被替换。2、缺点
代码膨胀:函数体多次展开会增加可执行文件的大小,影响指令缓存性能。滥用风险:对复杂函数使用内联会导致编译器拒绝内联或引发性能下降。维护复杂性:过度内联可能使代码难以阅读和维护。8.5.5、内联函数的限制与注意事项
1、限制条件
递归函数:递归函数不能完全内联,因为函数调用点无法静态展开。虚函数:虚函数通常不支持内联,因为虚函数需要通过虚表查找地址。复杂函数:如果函数体太大或包含循环,编译器可能会拒绝内联。2、头文件中的内联函数
内联函数通常定义在头文件中,因为编译器需要在调用点看到函数的完整定义。
示例:
// Rectangle.h#ifndef RECTANGLE_H#define RECTANGLE_Hclass Rectangle {public: inline int area(int width, int height) { return width * height; }};#endif // RECTANGLE_H3、容易被滥用
尽量避免将复杂的函数声明为内联函数,因为可能导致反效果。
8.5.6、面试题
宏的优缺点?
优点:
增强代码的复用性提高性能缺点:
不方便调试宏。(因为在预编译阶段进行了替换)导致代码可读性差,可维护性差,容易误用没有类型安全的检查C++ 有哪些技术替代宏?
常量定义 换用const短小函数定义,换用内联函数#define N 10 -> const int N = 10;
宏函数 -> inline内联函数替代
8.5.7、小结
内联函数是 C++ 提供的一种强大机制,用于消除函数调用开销并优化代码性能。在实际使用中,应根据函数的复杂性、调用频率和代码可维护性决定是否使用内联函数。过度使用内联可能导致代码膨胀和性能下降,因此需要权衡利弊并合理设计。通过正确的使用,内联函数能够显著提升程序的效率和安全性,成为开发者的得力工具。
8.6、递归函数
递归是编程中一种强大的工具,它允许函数调用自身以解决问题。C++ 支持递归函数的实现,并且在解决许多分治算法和数学问题时非常实用。本节将全面解析 C++ 中递归函数的基础概念、工作原理、实现方式,以及递归函数的优缺点、常见问题和优化策略。
8.6.1、什么是递归函数
递归函数是指在函数定义中调用自身的函数。它通过不断简化问题,最终达到可以直接解决的基础情况(Base Case)。每次函数调用都会生成一个新的调用栈帧,直至满足终止条件,递归逐层返回结果。
递归的组成部分
基础情况(Base Case):递归的终止条件,用于避免无限循环。递归步骤(Recursive Step):将问题分解为更小的子问题,并递归调用自身。示例:计算阶乘的递归实现:
#include <iostream>using namespace std;int factorial(int n) { if (n == 0) return 1; // 基础情况 return n * factorial(n - 1); // 递归步骤}int main() { int num = 5; cout << "Factorial of " << num << " is " << factorial(num) << endl; return 0;}上述代码中,factorial(5) 会调用 factorial(4),依次递减直至 factorial(0),然后逐层返回结果。
8.6.2、递归函数的工作原理
1、栈帧的调用
每次递归调用时,函数的参数、局部变量和返回地址都会被压入栈中,形成一个栈帧(Stack Frame)。当前函数调用完成后,栈帧被弹出,控制权返回上层调用。
2、递归过程
向下递归(递归展开):问题逐步被分解为更小的子问题,直到满足基础情况。向上返回(递归收敛):从基础情况逐层返回结果,最终得到完整的解。3、调用栈示例
以 factorial(3) 为例:
调用过程:
factorial(3) → factorial(2) → factorial(1) → factorial(0)返回过程:
factorial(0) → factorial(1) → factorial(2) → factorial(3)8.6.3、递归函数的实现与示例
1、数学问题
示例 1:斐波那契数列
#include <iostream>using namespace std;int fibonacci(int n) { if (n <= 1) return n; // 基础情况 return fibonacci(n - 1) + fibonacci(n - 2); // 递归步骤}int main() { int num = 10; for (int i = 0; i < num; ++i) { cout << fibonacci(i) << " "; } cout << endl; return 0;}2、分治算法
示例 2:归并排序
#include <iostream>#include <vector>using namespace std;void merge(vector<int>& arr, int left, int mid, int right) { vector<int> temp(right - left + 1); int i = left, j = mid + 1, k = 0; while (i <= mid && j <= right) { temp[k++] = (arr[i] <= arr[j]) ? arr[i++] : arr[j++]; } while (i <= mid) temp[k++] = arr[i++]; while (j <= right) temp[k++] = arr[j++]; for (k = 0; k < temp.size(); ++k) { arr[left + k] = temp[k]; }}void mergeSort(vector<int>& arr, int left, int right) { if (left >= right) return; // 基础情况 int mid = left + (right - left) mergeSort(arr, left, mid); // 左半部分排序 mergeSort(arr, mid + 1, right); // 右半部分排序 merge(arr, left, mid, right); // 合并两个有序部分}int main() { vector<int> arr = {38, 27, 43, 3, 9, 82, 10}; mergeSort(arr, 0, arr.size() - 1); for (int num : arr) { cout << num << " "; } cout << endl; return 0;}8.6.4、递归函数的优缺点
1、优点
代码简洁:递归可以用较少的代码解决复杂问题。易于实现:许多问题可以自然地通过递归表达。适合分治算法:递归在处理分治问题(如归并排序、快速排序)时极为高效。2、缺点
性能问题:递归调用会产生大量的函数栈帧,可能导致栈溢出。内存开销大:每次递归调用都需要分配新的栈帧。不适合大规模问题:深度递归可能导致效率低下或栈溢出。8.6.5、常见问题与优化
1、栈溢出
当递归深度过大时,会导致栈溢出。例如:
int factorial(int n) { return n * factorial(n - 1); // 缺乏终止条件}解决方法:确保函数有明确的基础情况。
2、重复计算
以斐波那契数列为例,递归会重复计算相同的子问题,导致性能低下。
优化策略:记忆化递归
#include <iostream>#include <vector>using namespace std;vector<int> memo;int fibonacci(int n) { if (n <= 1) return n; if (memo[n] != -1) return memo[n]; return memo[n] = fibonacci(n - 1) + fibonacci(n - 2);}int main() { int num = 10; memo.assign(num + 1, -1); for (int i = 0; i < num; ++i) { cout << fibonacci(i) << " "; } cout << endl; return 0;}3、尾递归优化
尾递归是指递归调用发生在函数末尾,且不需要保存当前栈帧信息。编译器可以将其优化为迭代形式,从而减少栈空间使用。
示例:
#include <iostream>using namespace std;int factorialTail(int n, int acc = 1) { if (n == 0) return acc; // 基础情况 return factorialTail(n - 1, n * acc); // 尾递归}int main() { cout << "Factorial of 5 is " << factorialTail(5) << endl; return 0;}8.6.6、小结
递归函数是 C++ 中一种重要的编程工具,能够以简洁的方式解决复杂问题。通过基础情况与递归步骤的设计,递归函数适用于数学问题、分治算法和树的操作等场景。然而,递归的效率问题需要通过记忆化、尾递归优化等技术手段加以解决。在实际开发中,递归和迭代往往需要结合使用,以平衡代码简洁性和运行效率。
8.7、函数重载
C++ 提供了强大的面向对象编程能力,其中函数重载(Function Overloading)是核心特性之一。函数重载允许在同一个作用域中定义多个同名函数,但参数列表必须不同。这一特性提升了程序的可读性和灵活性,使代码更加简洁。本节将深入解析函数重载的原理、规则、实现方式以及注意事项,并通过丰富的代码示例加深理解。
8.7.1、函数重载的基本概念
函数重载是指在同一作用域中允许定义多个名字相同但参数列表不同的函数。编译器会根据函数调用时传递的参数来选择对应的函数。
函数重载的规则:
必须具有相同的函数名。参数的个数、类型、或顺序至少有一个不同。返回类型不能作为重载的依据。示例:
#include <iostream>void print(int i) { std::cout << "Integer: " << i << std::endl;}void print(double d) { std::cout << "Double: " << d << std::endl;}void print(const std::string& s) { std::cout << "String: " << s << std::endl;}int main() { print(10); // 调用第一个 print print(3.14); // 调用第二个 print print("Hello"); // 调用第三个 print return 0;}8.7.2、函数重载的实现原理
函数重载的实现依赖于函数签名(Function Signature),也称为修饰名。它由函数名和参数列表的组合决定,编译器通过签名来区分不同的重载函数。
函数签名的影响因素:
函数名。参数的个数。参数的类型及顺序。编译器会在编译阶段对重载函数进行名字修饰(Name Mangling),将其转换为唯一的内部表示,以区分不同的重载函数。
8.7.3、函数重载的使用场景
1、提升代码的可读性与灵活性
函数重载允许用统一的名称表示不同的操作,避免了函数名的膨胀,提高了代码的可读性。
示例:重载计算面积的函数:
#include <iostream>// 计算矩形的面积double area(double length, double width) { return length * width;}// 计算正方形的面积double area(double side) { return side * side;}// 计算圆的面积double area(double radius, bool isCircle) { const double PI = 3.14159; return isCircle ? PI * radius * radius : 0;}int main() { std::cout << "Rectangle: " << area(5.0, 3.0) << std::endl; std::cout << "Square: " << area(4.0) << std::endl; std::cout << "Circle: " << area(2.5, true) << std::endl; return 0;}2、简化函数接口的设计
可以通过重载设计一个多用途函数,减少使用者的学习成本。
示例:多种类型数据输出:
#include <iostream>void display(int value) { std::cout << "Integer: " << value << std::endl;}void display(double value) { std::cout << "Double: " << value << std::endl;}void display(const std::string& value) { std::cout << "String: " << value << std::endl;}int main() { display(42); display(3.14); display("C++"); return 0;}8.7.4、函数重载的注意事项
1、返回值不能作为重载依据
函数返回值类型不同,但参数列表完全相同的情况下,不能作为重载。
int func(int x);double func(int x); // 错误:仅返回值不同,不能重载2、默认参数的干扰
函数重载与默认参数一起使用时,可能会导致调用不明确的问题。
示例:
void print(int x, int y = 0) { std::cout << "Two integers: " << x << ", " << y << std::endl;}void print(int x) { std::cout << "One integer: " << x << std::endl;}int main() { print(10); // 错误:编译器无法决定调用哪个重载 return 0;}3、类型转换的优先级
在存在隐式类型转换的情况下,函数重载可能产生歧义。
示例:
void func(int x) { std::cout << "Integer: " << x << std::endl;}void func(double x) { std::cout << "Double: " << x << std::endl;}int main() { func(3.14f); // float 可转为 int 或 double,可能导致歧义 return 0;}4、与模板函数的冲突
模板函数可以与普通函数重载,但需要注意优先级问题。
示例:
#include <iostream>void print(int x) { std::cout << "Non-template function: " << x << std::endl;}template <typename T>void print(T x) { std::cout << "Template function: " << x << std::endl;}int main() { print(10); // 优先调用非模板函数 print(3.14); // 调用模板函数 return 0;}8.7.5、函数重载与其他特性的结合
1、与构造函数结合
构造函数可以被重载,用于初始化类的不同情况。
示例:
#include <iostream>class Point {public: Point() : x(0), y(0) {} // 默认构造函数 Point(int a) : x(a), y(a) {} // 初始化为同一个值 Point(int a, int b) : x(a), y(b) {} // 初始化为不同值 void display() { std::cout << "(" << x << ", " << y << ")" << std::endl; }private: int x, y;};int main() { Point p1; Point p2(5); Point p3(3, 7); p1.display(); p2.display(); p3.display(); return 0;}2、与运算符重载结合
运算符重载是函数重载的特例,允许为类定义特定的运算符行为。
8.7.6、小结
C++ 函数重载是一个强大且灵活的特性,提供了代码复用、可读性和灵活性。通过函数重载,开发者可以设计直观的接口,适配多种场景。然而,使用时需注意可能的歧义问题,并结合其他特性(如模板、运算符重载)以充分发挥其作用。在实践中,合理设计函数重载规则,将极大提升代码质量和维护性。
8.8、函数模板
模板函数允许编写通用代码,适用于多种数据类型。
示例:
#include <iostream>using namespace std;template <typename T>T add(T a, T b) { return a + b;}int main() { cout << add(3, 4) << endl; // 整数相加 cout << add(2.5, 3.5) << endl; // 浮点数相加 return 0;}8.9、Lambda 表达式
C++11 引入了 Lambda 表达式,用于简洁定义匿名函数。
语法:
[捕获列表](参数列表) -> 返回类型 { // 函数体};示例:
#include <iostream>using namespace std;int main() { auto add = [](int a, int b) -> int { return a + b; }; cout << add(3, 4) << endl; // 输出 7 return 0;}8.10、函数的最佳实践
保持函数短小精悍:每个函数实现一个明确的功能。适当使用默认参数:简化调用。避免滥用递归:可能导致栈溢出。注重代码重用性:多使用模板函数。内联函数慎用:不要滥用内联关键字。8.11、小结
C++ 函数是程序设计的基础,通过灵活使用普通函数、内联函数、递归函数和模板函数等特性,可以大幅提升代码的可维护性和效率。本节内容详细讲解了函数的基本概念、各种实现方式及最佳实践,帮助开发者全面掌握 C++ 函数的使用技巧。
9、数组与指针详解
数组和指针是 C++ 中处理数据的基础工具,它们不仅紧密相关,还构成了复杂数据结构的基础。本节将深入探讨数组与指针的基本概念、使用方法、两者的联系与区别,以及相关的高级用法。
9.1、数组的基本概念
9.1.1、什么是数组
数组是存储相同类型数据的集合,具有固定大小。数组的每个元素在内存中占据连续的存储空间,通过索引访问。
9.1.2、数组的声明与初始化
语法:
数据类型 数组名[大小];示例:
#include <iostream>using namespace std;int main() { int arr[5]; // 声明一个大小为5的整型数组 int numbers[3] = {1, 2, 3}; // 初始化数组 return 0;}注意:
如果未显式初始化,数组中的元素值未定义。使用{} 可以显式初始化为零:int arr[5] = {};。 9.1.3、数组元素的访问
数组元素通过索引访问,索引从 0 开始。
示例:
int arr[3] = {10, 20, 30};cout << arr[0] << endl; // 输出 10arr[1] = 40; // 修改第二个元素cout << arr[1] << endl; // 输出 409.1.4、多维数组
多维数组是数组的数组,最常见的是二维数组。
语法:
数据类型 数组名[行][列];示例:
int matrix[2][3] = {{1, 2, 3}, {4, 5, 6}};cout << matrix[1][2] << endl; // 输出 69.2、指针的基本概念
9.2.1、什么是指针
指针是存储内存地址的变量。它用于动态内存分配、数组操作和函数参数传递等。
9.2.2、指针的声明与初始化
语法:
数据类型* 指针名;示例:
int x = 10;int* ptr = &x; // 指针 ptr 存储变量 x 的地址cout << *ptr << endl; // 通过指针访问 x 的值,输出 109.2.3、指针的使用
&(取地址符):获取变量的地址。*(解引用符):通过指针访问地址中的值。 9.3、数组与指针的关系
数组与指针密切相关。在大多数情况下,数组名即为指向第一个元素的指针。
9.3.1、数组名与指针
int arr[3] = {1, 2, 3};int* ptr = arr; // 数组名等价于指向首元素的指针cout << *ptr << endl; // 输出 1cout << *(ptr + 1) << endl; // 输出 29.3.2、指针遍历数组
int arr[5] = {10, 20, 30, 40, 50};int* ptr = arr;for (int i = 0; i < 5; ++i) { cout << *(ptr + i) << " "; // 输出数组元素}9.3.3、多维数组与指针
int matrix[2][3] = {{1, 2, 3}, {4, 5, 6}};int (*ptr)[3] = matrix; // 指针指向二维数组的行cout << *(*(ptr + 1) + 2) << endl; // 输出 69.4、动态内存分配
使用指针动态分配数组,可以在运行时确定数组的大小。
9.4.1、动态分配一维数组
#include <iostream>using namespace std;int main() { int size; cin >> size; int* arr = new int[size]; // 动态分配数组 for (int i = 0; i < size; ++i) { arr[i] = i + 1; } delete[] arr; // 释放内存 return 0;}9.4.2、动态分配二维数组
int** matrix = new int*[rows];for (int i = 0; i < rows; ++i) { matrix[i] = new int[cols];}// 使用完毕后释放内存for (int i = 0; i < rows; ++i) { delete[] matrix[i];}delete[] matrix;9.5、数组与指针的局限性
9.5.1、固定大小
数组大小在定义时固定,无法动态调整,使用动态内存分配可解决此问题。
9.5.2、指针的风险
野指针:未初始化或已释放的指针。内存泄漏:动态分配内存未释放。越界访问:对数组或指针操作时索引越界,可能导致未定义行为。9.5.3、不同步的指针与数组
在多维数组中,指针偏移需要严格遵循数据存储规则。
9.6、常见应用场景
字符串处理:C 风格字符串使用字符数组与指针操作。函数参数传递:指针传递数组或结构体,避免数据复制。动态数据结构:如链表、队列、栈等,广泛使用指针。矩阵操作:动态分配多维数组,处理大规模数据。9.7、实际案例分析
9.7.1、使用指针实现数组的倒序
#include <iostream>using namespace std;void reverse(int* arr, int size) { int* start = arr; int* end = arr + size - 1; while (start < end) { swap(*start, *end); ++start; --end; }}int main() { int arr[5] = {1, 2, 3, 4, 5}; reverse(arr, 5); for (int i = 0; i < 5; ++i) { cout << arr[i] << " "; } return 0;}9.7.2、使用指针实现二维数组转置
#include <iostream>using namespace std;void transpose(int matrix[2][3], int result[3][2]) { for (int i = 0; i < 2; ++i) { for (int j = 0; j < 3; ++j) { result[j][i] = matrix[i][j]; } }}int main() { int matrix[2][3] = {{1, 2, 3}, {4, 5, 6}}; int result[3][2]; transpose(matrix, result); for (int i = 0; i < 3; ++i) { for (int j = 0; j < 2; ++j) { cout << result[i][j] << " "; } cout << endl; } return 0;}9.8、小结
C++ 中数组和指针提供了高效的数据处理能力,掌握它们的使用有助于开发复杂程序。通过灵活使用数组与指针,可以高效实现动态分配、字符串处理以及复杂的数据结构。同时,需要注意指针的安全性和数组越界的问题,养成良好的编程习惯以避免常见错误。
10、错误与异常处理
C++ 提供了丰富的机制来处理程序执行中的错误和异常。通过错误与异常处理,程序可以更安全、更稳定地运行,同时减少错误引发的系统崩溃风险。本节将深入探讨 C++ 中错误和异常的基本概念、处理机制及其在实际开发中的应用。
10.1、错误与异常的基本概念
10.1.1、错误的分类
在程序运行中,错误通常分为以下几类:
语法错误:编译时检测到的代码结构错误,例如缺少分号。逻辑错误:程序运行结果与预期不符的错误。运行时错误:程序运行时发生的错误,例如除以零、数组越界或文件无法打开。10.1.2、什么是异常
异常是程序运行时发生的意外或错误情况。C++ 提供了一种基于 try-catch 的异常处理机制,用于捕获和处理异常,而不是直接终止程序。
10.2、异常处理机制
10.2.1、异常的基本结构
C++ 的异常处理由以下关键字构成:
try:定义一段可能引发异常的代码块。throw:抛出异常。catch:捕获并处理异常。 示例:
#include <iostream>using namespace std;int main() { try { int a = 10, b = 0; if (b == 0) throw "Division by zero error!"; cout << a / b << endl; } catch (const char* msg) { cout << "Exception caught: " << msg << endl; } return 0;}10.2.2、异常处理的流程
程序进入try 块,执行可能引发异常的代码。如果发生异常,执行 throw 语句,抛出异常。程序跳转到匹配的 catch 块处理异常。如果未找到匹配的 catch,程序终止。 10.2.3、抛出异常
C++ 支持抛出以下类型的异常:
基本数据类型(如int、char)标准异常类(如 std::exception)用户自定义类型(如类或结构体) 示例:抛出和捕获基本类型异常
try { throw 404;} catch (int errorCode) { cout << "Error code: " << errorCode << endl;}10.2.4、多重 catch 块
一个 try 块可以拥有多个 catch 块,用于捕获不同类型的异常。
示例:
try { throw 3.14;} catch (int e) { cout << "Integer exception: " << e << endl;} catch (double e) { cout << "Double exception: " << e << endl;}10.2.5、泛型捕获(捕获所有异常)
使用 catch(...) 可以捕获所有未明确处理的异常。
try { throw "Unknown error";} catch (...) { cout << "Caught an exception" << endl;}10.3、标准异常类
C++ 提供了一组标准异常类,定义在 <stdexcept> 头文件中。这些类继承自基类 std::exception。
10.3.1、常见标准异常类
| 异常类 | 描述 |
|---|---|
std::exception | 所有标准异常的基类 |
std::logic_error | 逻辑错误(编程错误) |
std::runtime_error | 运行时错误 |
std::out_of_range | 越界错误 |
std::bad_alloc | 动态内存分配失败 |
10.3.2、使用标准异常类
示例:
#include <iostream>#include <stdexcept>using namespace std;int main() { try { throw std::runtime_error("Runtime error occurred"); } catch (const std::exception& e) { cout << "Exception: " << e.what() << endl; } return 0;}10.3.3、自定义异常类
用户可以继承 std::exception 创建自定义异常类。
示例:
#include <iostream>#include <exception>using namespace std;class MyException : public exception {public: const char* what() const noexcept override { return "Custom exception occurred"; }};int main() { try { throw MyException(); } catch (const MyException& e) { cout << e.what() << endl; } return 0;}10.4、异常处理的最佳实践
10.4.1、避免滥用异常
异常应仅用于处理真正的错误情况。不应将异常用于普通的程序逻辑控制。10.4.2、异常安全性
确保在异常发生时,资源正确释放,避免资源泄漏。
示例:使用 std::unique_ptr 确保资源自动释放
#include <iostream>#include <memory>using namespace std;void process() { unique_ptr<int[]> data(new int[100]); throw runtime_error("Error during processing");}int main() { try { process(); } catch (const std::exception& e) { cout << e.what() << endl; } return 0;}10.4.3、使用 RAII
RAII(资源获取即初始化)是确保资源安全释放的常用设计模式,结合异常处理效果更佳。
10.5、实际案例分析
10.5.1、文件操作中的异常处理
#include <iostream>#include <fstream>#include <stdexcept>using namespace std;void readFile(const string& filename) { ifstream file(filename); if (!file.is_open()) { throw runtime_error("Unable to open file: " + filename); } string line; while (getline(file, line)) { cout << line << endl; }}int main() { try { readFile("nonexistent.txt"); } catch (const exception& e) { cout << "Error: " << e.what() << endl; } return 0;}10.5.2、动态内存分配异常
#include <iostream>#include <new>using namespace std;int main() { try { int* largeArray = new int[10000000000]; delete[] largeArray; } catch (const bad_alloc& e) { cout << "Memory allocation failed: " << e.what() << endl; } return 0;}10.6、小结
C++ 提供了灵活而强大的异常处理机制,可以有效捕获和管理程序中的错误。通过合理使用异常处理工具,程序员可以提高代码的鲁棒性和可维护性。结合 RAII 和智能指针等现代技术,异常处理不仅是防止程序崩溃的工具,更是实现高质量软件开发的必备技能。
11、其他知识点
12、总结与展望
本篇博客旨在为读者提供一份详尽且系统的 C++ 入门指南,从语言的起源到核心概念的深入探讨,为初学者铺设了扎实的基础,也为更深入的学习奠定了基石。以下是对各章节内容的简要总结:
引言
引言部分点明了 C++ 在现代编程中的重要性,以及它从底层高效性到高层抽象能力的独特优势。通过探讨学习 C++ 的意义和应用场景,为本博客的内容提供了清晰的框架。
C++ 的起源与发展
通过梳理 C++ 从 20 世纪 80 年代诞生到现代发展的历程,我们深刻理解了它作为面向对象编程和底层系统开发语言的价值,并探讨了它对后续编程语言的重要影响。
关键字及其深入解析
本章系统介绍了 C++ 关键字的特性和分类,并详细探讨了 const、static 和 auto 关键字的应用及原理。
const:定义不可修改的数据,提升代码的安全性和可读性。static:优化变量存储周期与作用域,控制函数访问权限。auto:简化类型推导,增强编程效率与代码灵活性。 命名空间 (namespace)
通过命名空间的讲解,我们解决了标识符冲突问题,阐明了如何通过 std 等标准命名空间组织代码,使得大规模项目管理更加清晰。
基础语法:变量与数据类型
本章详细讨论了变量的定义规则、数据类型的分类及使用,并通过示例演示了 C++ 强类型体系的严谨性,为编写可靠代码提供了保障。
输入输出
以 cin 和 cout 为核心,探讨了 C++ 标准库 I/O 流的使用,并结合文件操作展示了灵活的数据输入输出能力。
控制流
本章系统分析了条件语句、循环语句等控制流结构,帮助读者学会控制程序的执行逻辑,从而编写更高效的代码。
函数
函数部分是本博客的重点,涵盖了多种概念:
函数参数与引用:提高传参效率并避免数据拷贝。
内联函数:降低函数调用开销,优化性能。
递归函数:实现复杂问题的分治与求解。
函数重载与模板:展示 C++ 高级函数特性的灵活性与扩展性。
数组与指针
通过对数组和指针的讲解,我们认识到如何管理连续存储空间,以及如何通过指针操作内存地址,从而深刻理解了 C++ 在底层内存操作中的强大能力。
错误与异常处理
本章重点介绍了 C++ 的异常机制,探讨了 try-catch 结构的使用以及自定义异常的实现,为构建健壮的程序提供了指导。
本篇博客系统地梳理了 C++ 的核心概念和基础应用,从语言起源到函数与内存管理的深入探讨,为初学者提供了全面的学习路径。通过对 C++ 语言特性的详细讲解,读者不仅可以掌握其基本语法,还能理解其设计思想和底层逻辑,为解决实际问题打下扎实基础。
展望未来,随着现代 C++ 的不断演进(如 C++11、C++17 和 C++20 的引入),本博客的内容还需结合新标准进行扩展。C++ 不仅是系统开发的基石,也是现代复杂软件架构中不可或缺的工具。希望这篇博客能为读者打开 C++ 的大门,并激发进一步学习和探索的兴趣。
希望这篇博客对您有所帮助,也欢迎您在此基础上进行更多的探索和改进。如果您有任何问题或建议,欢迎在评论区留言,我们可以共同探讨和学习。更多知识分享可以访问我的 个人博客网站