目录
一、哈希表概述
1. 什么是哈希表编辑
2. 哈希表的优点
3. 哈希表的缺点
二、哈希函数
常见哈希函数
三. 哈希冲突的原因和解决方法
一.哈希冲突的原因
二、哈希冲突的解决方法
1. 链表法(Separate Chaining)
2. 开放寻址法(Open Addressing)
四 哈希表的实际应用:C++实现
1. 使用 unordered_set
2. 使用 unordered_map
五.哈希表与红黑树的性能对比
总结
?引言
在计算机科学中,数据结构与算法是解决问题的核心工具。各种数据结构和算法的设计决定了程序的效率和性能。在众多数据结构中,哈希表(Hash Table) 是一个极其重要且高效的结构。它广泛应用于数据库索引、缓存技术、加密算法等领域,并且是很多高级编程语言中内置的基础容器之一。
本文将深入探讨哈希表的原理、哈希函数的设计、哈希冲突的解决策略,并结合C++实现 unordered_set 和 unordered_map 来展示哈希表的实际应用。
一、哈希表概述
1. 什么是哈希表
哈希表是一种基于数组的数据结构,用于快速地存储和查找数据。它通过一个哈希函数将元素的键值映射到哈希表中的一个位置,从而实现常数时间复杂度 O(1) 的查找和插入操作。
哈希表的基本工作原理如下:
键值对存储:每个元素都有一个“键”与其对应的“值”。哈希函数:根据“键”计算出该元素的存储位置(哈希值)。数组存储:将哈希值作为索引,快速存取对应的值。
2. 哈希表的优点
高效查找:对于随机访问、插入和删除操作,哈希表能提供接近 O(1)O(1)O(1) 的时间复杂度,这是因为它能直接通过哈希函数定位到元素的存储位置。空间利用:哈希表通常比其他结构(如树)更节省空间,尤其是在大规模数据的存储上表现优秀。3. 哈希表的缺点
内存浪费:为了避免冲突,哈希表通常需要较大的内存空间。哈希冲突:当不同的键经过哈希函数计算后,映射到同一位置时,会发生哈希冲突,需要通过一定方法来解决。二、哈希函数
哈希函数是哈希表的核心,它负责将输入的键值映射到一个固定范围内的哈希值。一个好的哈希函数应当具备以下几个特点:
均匀性:哈希值应均匀分布,避免集中在哈希表的某些区域。效率:哈希函数应当简单、计算速度快。低碰撞率:哈希函数应尽量减少哈希冲突的发生。常见哈希函数
哈希函数 的发展已经有很多年历史了,在前辈的实践之下,留下了这些常见的 哈希函数
1、直接定址法(常用)
函数原型:HashI = A * key + B
优点:简单、均匀
缺点:需要提前知道键值的分布情况
适用场景:范围比较集中,每个数据分配一个唯一位置
2、除留余数法(常用)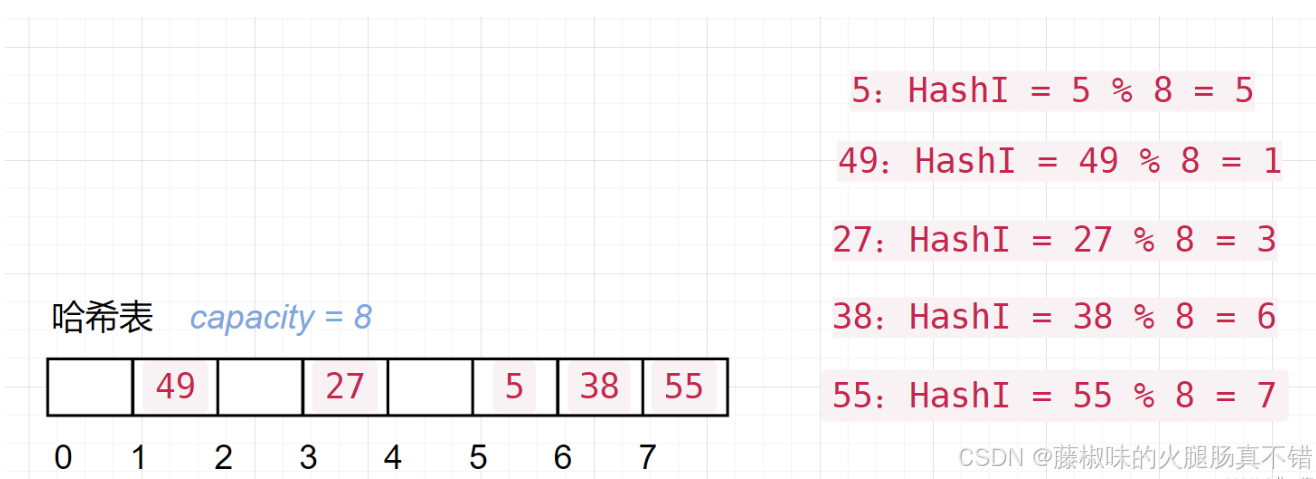
假设 哈希表 的大小为 m
函数原型:HashI = key % p (p < m)
优点:简单易用,性能均衡
缺点:容易出现哈希冲突,需要借助特定方法解决
适用场景:范围不集中,分布分散的数据
3、平方取中法(了解)
函数原型:HashI = mid(key * key)
适用场景:不知道键值的分布,而位数又不是很大的情况
假设键值为 1234,对其进行平方后得到 1522756,取其中间的三位数 227 作为 哈希值
4、折叠法(了解)
折叠法是将键值从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这几部分叠加求和,并按 哈希表 表长,取后几位作为散列地址
适用场景:事先不需要知道键值的分布,且键值位数比较多
假设键值为 85673113,分为三部分 856、731、13,求和:1600,根据表长(假设为 100),哈希值 就是 600
5、随机数法(了解)
选择一个随机函数,取键值的随机函数值为它的 哈希值
函数原型:HashI = rand(key)
其中 rand 为随机数函数
适用场景:键值长度不等时
哈希函数 还有很多很多种,最终目的都是为了计算出重复度低的 哈希值
最常用的是 直接定址法 和 除留余数法
三. 哈希冲突的原因和解决方法
哈希表是一种高效的数据结构,广泛应用于各种算法中,如查找、插入和删除操作等。然而,哈希表并非没有缺点,最常见的问题之一就是哈希冲突。哈希冲突发生在多个元素被映射到哈希表中的同一个位置时。理解哈希冲突的原因以及解决方法对于优化哈希表的性能至关重要。
一.哈希冲突的原因
哈希冲突的产生主要由以下几个原因导致:
看下方的简图??:
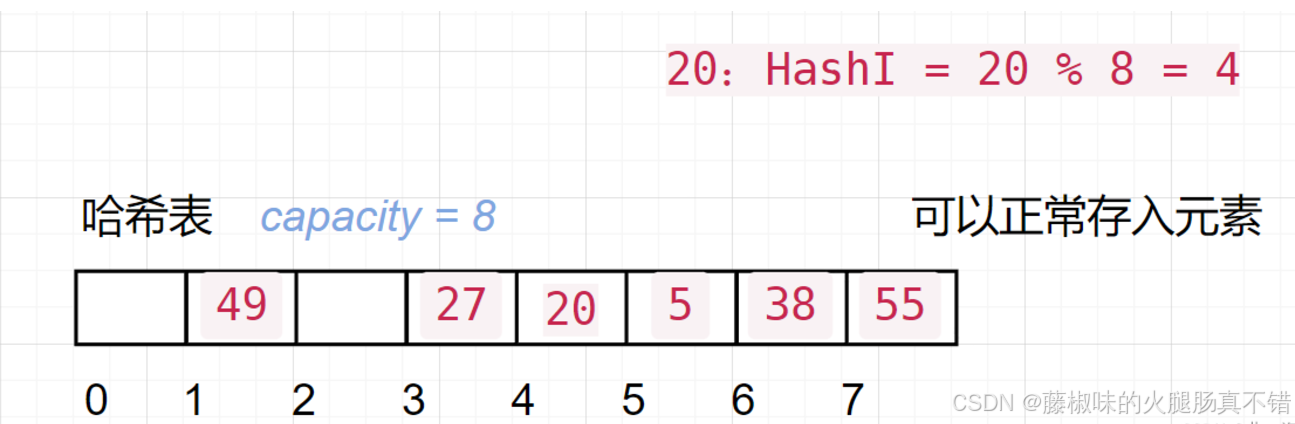
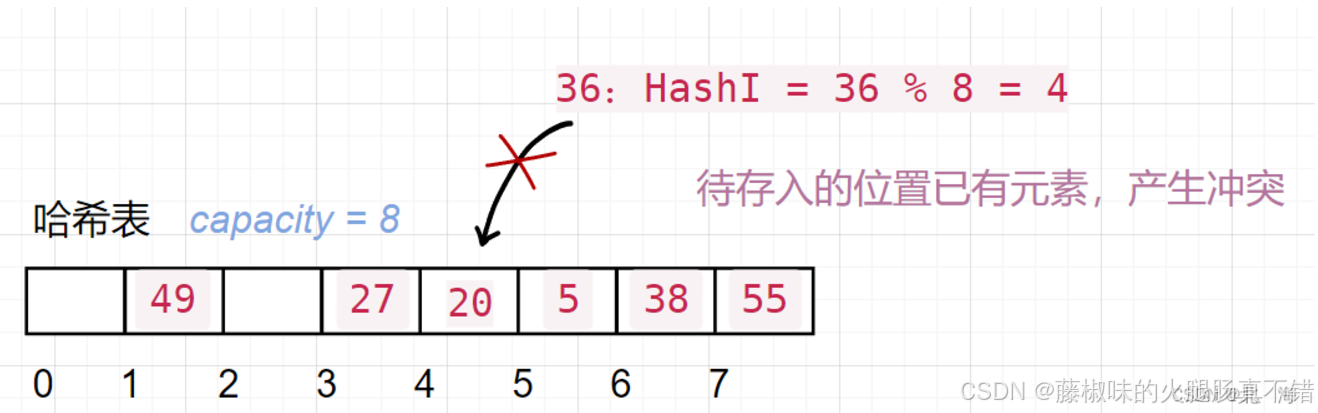
1. 哈希函数的设计问题
哈希函数的主要任务是将输入数据(如字符串或整数)映射到哈希表的索引上。理想的哈希函数应该能够均匀地分布所有可能的输入值。然而,在实际应用中,哈希函数可能会出现设计不当的情况,例如:
哈希函数映射范围过小,导致许多不同的输入值映射到同一个索引。哈希函数的输出分布不均匀,导致哈希表中某些区域频繁发生冲突。2. 输入数据的特点
哈希冲突的发生也可能与输入数据本身的特性有关。例如,如果多个数据项本身非常相似(如有相同的前缀或后缀),即使哈希函数设计得当,它们也可能被映射到相同的哈希桶。
3. 哈希表的大小和负载因子
哈希表的大小决定了它能容纳多少元素。当哈希表的负载因子(即哈希表中元素的数量与表的容量之比)过高时,哈希冲突的概率也会增加。即使哈希函数设计得很好,如果哈希表容量不足以存储所有元素,哈希冲突不可避免。
二、哈希冲突的解决方法
为了解决哈希冲突,通常有两种主要的方法:开放寻址法和链表法。每种方法都有其优缺点,适用于不同的场景。
1. 链表法(Separate Chaining)
链表法是最常见的哈希冲突解决方案。其基本思路是,在哈希表的每个位置上,存储一个链表或其他数据结构,用来存储发生冲突的多个元素。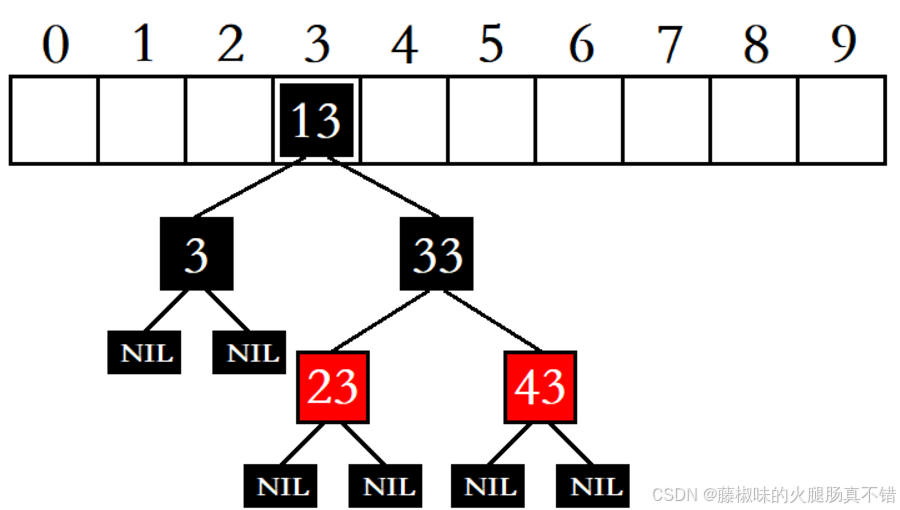
具体步骤:
每当发生冲突时,将新的元素插入到该位置的链表中。查找时,首先通过哈希函数找到对应的桶,再遍历桶中的链表进行查找。优点:
解决哈希冲突的简单性:链表法能够很自然地处理哈希冲突。动态扩展性:如果负载因子过高,链表的长度会增加,但不至于导致性能大幅下降。缺点:
空间浪费:每个桶都需要存储一个额外的数据结构(如链表),这可能导致额外的内存开销。查找效率下降:如果链表过长,查找操作的效率就会受到影响,最坏情况下变成 O(n)。2. 开放寻址法(Open Addressing)
开放寻址法的基本思想是,当发生冲突时,哈希表会尝试找到一个空桶来存储冲突的元素,而不是使用链表存储所有冲突的元素。常见的开放寻址法有以下几种:
线性探测(Linear Probing)
线性探测是一种常见的开放寻址方法,当发生冲突时,哈希表会按顺序探测下一个位置,直到找到一个空桶为止。具体步骤如下:
计算哈希值,如果位置已经被占用,则尝试当前位置后的桶(即加1、加2、加3…)。优点:
实现简单,直接。空间效率较高,因为不需要额外的数据结构。缺点:
聚集问题:线性探测会导致“聚集”现象,即多个元素集中在一小段区域内,导致查找效率降低。删除操作复杂:删除一个元素时,可能会导致查找操作失败,需要特别处理。二次探测(Quadratic Probing)
二次探测是一种改进版的线性探测方法。当发生冲突时,探测过程遵循一个二次方程(如加 1^2、2^2、3^2…)。
优点:
避免了线性探测的聚集问题。缺点:
仍然有聚集现象(虽然比线性探测要轻微)。可能导致表的大小不合适,影响性能。
四 哈希表的实际应用:C++实现
C++标准库提供了基于哈希表实现的容器,如 unordered_set 和 unordered_map,它们是无序的集合和映射容器。与 set 和 map 的区别在于,unordered_set 和 unordered_map 使用哈希表作为底层实现,因此查找、插入和删除操作具有常数时间复杂度。
1. 使用 unordered_set
unordered_set 是一个哈希表实现的集合,存储的元素是唯一的,不允许重复。
#include <iostream>#include <unordered_set>int main() { std::unordered_set<int> mySet = {1, 2, 3, 4, 5}; // 插入元素 mySet.insert(6); // 查找元素 if (mySet.find(3) != mySet.end()) { std::cout << "Found 3!" << std::endl; } // 删除元素 mySet.erase(4); // 打印元素 for (int element : mySet) { std::cout << element << " "; } std::cout << std::endl; return 0;}2. 使用 unordered_map
unordered_map 是一个哈希表实现的映射容器,存储键值对。
#include <iostream>#include <unordered_map>int main() { std::unordered_map<std::string, int> myMap; // 插入元素 myMap["Alice"] = 25; myMap["Bob"] = 30; // 查找元素 if (myMap.find("Alice") != myMap.end()) { std::cout << "Alice's age: " << myMap["Alice"] << std::endl; } // 删除元素 myMap.erase("Bob"); // 打印键值对 for (const auto& pair : myMap) { std::cout << pair.first << ": " << pair.second << std::endl; } return 0;}五.哈希表与红黑树的性能对比
下面是性能测试代码,包含 大量重复、部分重复、完全有序 三组测试用例,分别从 插入、查找、删除 三个维度进行对比
注:测试性能用的是 Release 版,这里的基础数据量为 100 w
#include <iostream>#include <vector>#include <set>#include <unordered_set>using namespace std;int main(){const size_t N = 1000000;unordered_set<int> us;set<int> s;vector<int> v;v.reserve(N);srand(time(0));for (size_t i = 0; i < N; ++i){//v.push_back(rand());//大量重复//v.push_back(rand()+i);//部分重复//v.push_back(i);//完全有序}size_t begin1 = clock();for (auto e : v){s.insert(e);}size_t end1 = clock();cout << "set insert:" << end1 - begin1 << endl;size_t begin2 = clock();for (auto e : v){us.insert(e);}size_t end2 = clock();cout << "unordered_set insert:" << end2 - begin2 << endl;size_t begin3 = clock();for (auto e : v){s.find(e);}size_t end3 = clock();cout << "set find:" << end3 - begin3 << endl;size_t begin4 = clock();for (auto e : v){us.find(e);}size_t end4 = clock();cout << "unordered_set find:" << end4 - begin4 << endl << endl;cout << s.size() << endl;cout << us.size() << endl << endl;;size_t begin5 = clock();for (auto e : v){s.erase(e);}size_t end5 = clock();cout << "set erase:" << end5 - begin5 << endl;size_t begin6 = clock();for (auto e : v){us.erase(e);}size_t end6 = clock();cout << "unordered_set erase:" << end6 - begin6 << endl << endl;return 0;}插入大量重复数据
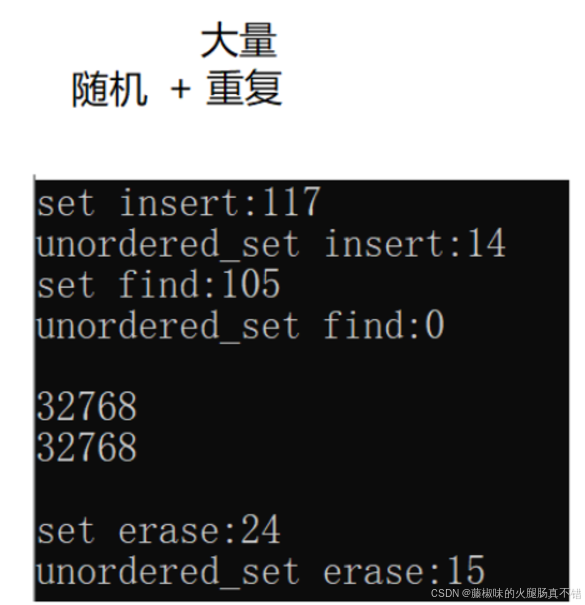
插入数据 大量重复 ---- 结果:
插入:哈希 比 红黑 快88%查找:哈希 比 红黑 快 100%删除:哈希 比 红黑 快 37% 插入部分重复数据

插入数据 部分重复 ---- 结果:
插入:哈希 与 红黑 差不多查找:哈希 比 红黑 快100%删除:哈希 比 红黑 快 41% 插入大量重复数据
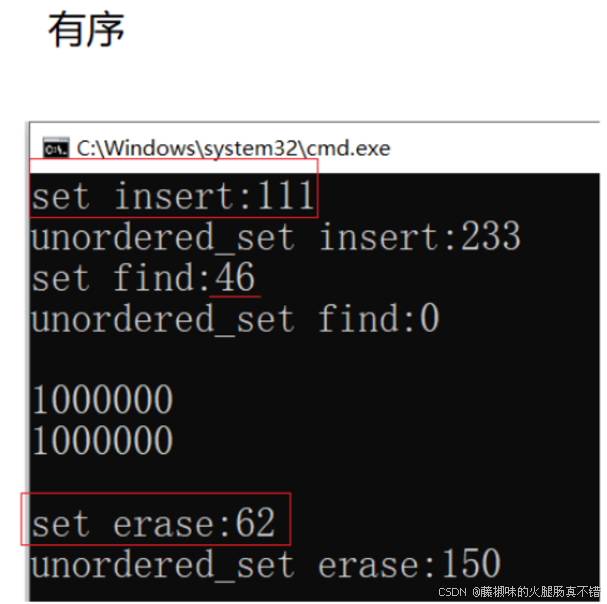
插入数据 完全有序 ---- 结果:
插入:哈希 比 红黑 慢52%查找:哈希 比 红黑 快 100%删除:哈希 比 红黑 慢 58% 总的来说,在数据 随机 的情况下,哈希各方面都比红黑强,在数据 有序 的情况下,红黑更胜一筹.
综上所述??:
1. 操作性能差异
| 操作 | 哈希表平均时间复杂度 | 红黑树平均时间复杂度 |
|---|---|---|
| 查找 | O(1)O(1)O(1) | O(logn)O(\log n)O(logn) |
| 插入 | O(1)O(1)O(1) | O(logn)O(\log n)O(logn) |
| 删除 | O(1)O(1)O(1) | O(logn)O(\log n)O(logn) |
从表中可以看出,哈希表的平均性能优于红黑树,尤其在查找和插入操作中,其常数时间复杂度具有明显优势。然而,红黑树的性能更为稳定,即使在最坏情况下,其时间复杂度依然为 O(logn)O(\log n)O(logn)。
2. 空间效率对比
哈希表:通常需要较大的内存来避免哈希冲突,因此在存储稀疏数据时可能造成一定的空间浪费。红黑树:作为平衡二叉树,其内存利用率较高,适合存储密集数据。3. 数据顺序支持
哈希表中的数据存储是无序的,无法直接支持范围查询或按顺序遍历。而红黑树则天然支持有序性操作,如查找区间范围、按序遍历等。
总结
哈希表是现代计算机科学中不可或缺的数据结构,它通过哈希函数实现快速的数据存取,并广泛应用于各个领域。本文通过对哈希表的介绍,深入探讨了哈希函数的设计、哈希冲突的解决方法以及 C++ 中的实现,旨在帮助读者更好地理解和使用这一高效的数据结构。
在实际应用中,我们不仅要选择合适的哈希函数,还要灵活运用冲突解决策略,以确保哈希表能够高效地工作。在性能