亲爱的读者朋友们?,此文开启知识盛宴与思想碰撞?。
快来参与讨论?,点赞?、收藏⭐、分享?,共创活力社区。

目录
一、前言
二、优先队列(Priority Queue):排队也有 “特权”?
(一)优先队列是啥?
(二)C++ 里怎么用优先队列?
(三)优先队列内部到底咋回事?
1. 秘密武器:二叉堆(Binary Heap)
2. 元素进出的 “魔法”
插入(push)元素
删除(pop)元素
(四)优先队列都在哪里大显身手?
1. 任务调度:谁先谁后安排好
2. 图算法中的 “指路明灯”
3. 数据压缩:让数据 “瘦身” 有妙招
一、前言
在 C++ 编程的奇妙世界里,数据结构就像是一个个功能各异的工具,帮助我们高效地处理和组织数据。而在众多的数据结构中,优先队列(Priority Queue)有着独特且重要的地位。它们各自有着独特的工作方式和应用场景,就如同特殊的钥匙,能为我们开启解决不同编程难题的大门。
? priority_queue文档介绍
二、优先队列(Priority Queue):排队也有 “特权”?
(一)优先队列是啥?
想象一下,你在一个超级特别的队伍里。这个队伍里的人可不是按照先来后到排队的哦?,而是每个人都有一个 “重要程度” 的标签?。比如说,在医院的急诊室,重伤的病人就比轻伤的病人更 “重要”,会优先得到救治。这就是优先队列的基本概念啦!它是一种数据结构,元素们按照自己的优先级排队,优先级最高的元素总是站在队伍的最前面,等着被处理。
(二)C++ 里怎么用优先队列?
标准模板库(STL)来帮忙
C++ 的 STL 给我们提供了一个超方便的priority_queue类。要用它的话,先把<queue>头文件包含进来哦?。就像这样:
#include <iostream>#include <queue>int main() { std::priority_queue<int> pq; pq.push(5); pq.push(10); pq.push(3); std::cout << "队首元素(最大值): " << pq.top() << std::endl; pq.pop(); std::cout << "队首元素(最大值): " << pq.top() << std::endl; return 0;}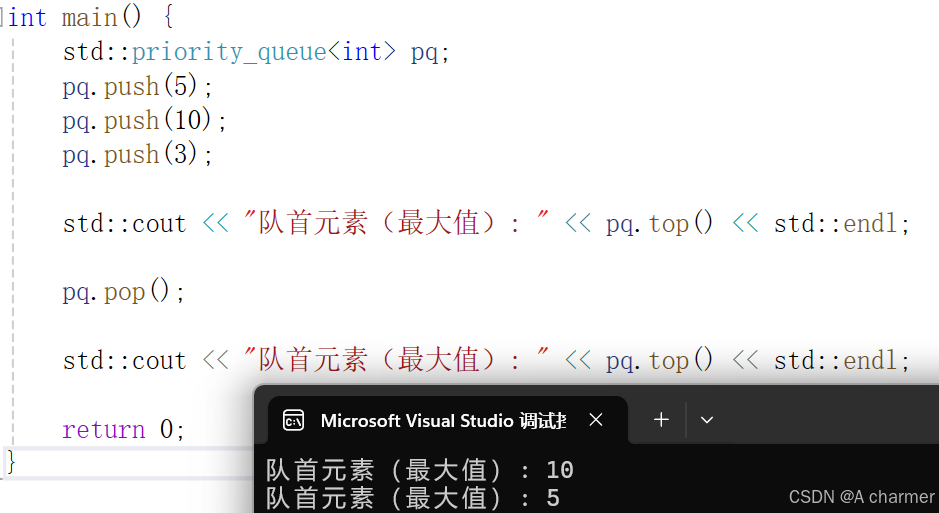 这里我们创建了一个存整数的优先队列,默认情况下,它就像一个 “选大比赛”,最大的数在队首哦?。每次
这里我们创建了一个存整数的优先队列,默认情况下,它就像一个 “选大比赛”,最大的数在队首哦?。每次push进去一个数,它就会自动按照大小排好队,top就能看到队首的最大值,pop就把最大值请出去啦。
想自定义规则?没问题!
要是你觉得默认的 “选大” 或者 “选小” 规则不合心意,也可以自己定规则哦?。这时候就要用到比较函数或者函数对象啦。看下面这个例子,我们来创建一个小顶堆,让最小的数在队首:
#include <iostream>#include <queue>struct Compare { bool operator()(int a, int b) { return a > b; }};int main() { std::priority_queue<int, std::vector<int>, Compare> pq; pq.push(5); pq.push(10); pq.push(3); std::cout << "队首元素(最小值): " << pq.top() << std::endl; pq.pop(); std::cout << "队首元素(最小值): " << pq.top() << std::endl; return 0;}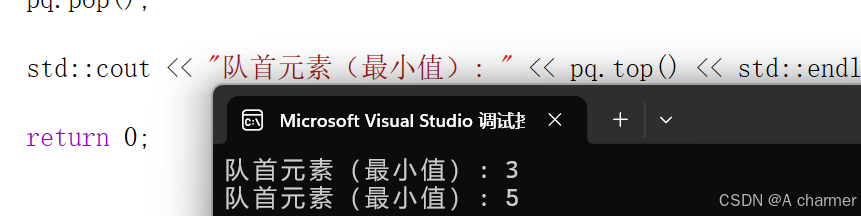 我们定义了一个
我们定义了一个Compare结构体,里面的operator()函数就是我们的比较规则。这样,优先队列就会按照我们定的规则来排队啦。
(三)优先队列内部到底咋回事?
1. 秘密武器:二叉堆(Binary Heap)
其实呀,priority_queue背后是靠二叉堆这个小助手来干活的呢?。二叉堆就像一棵特别的树,每个节点都有自己的任务哦。对于大顶堆来说,父节点就像个小队长,它的值得比子节点的值大,这样才能保证队里最大的值在最上面呀。小顶堆呢,就刚好相反,父节点的值要小于等于子节点的值。
下面是个简单示意二叉堆节点结构体的代码,实际 STL 里的实现更复杂哦:
template<typename T>struct BinaryHeapNode { T value; BinaryHeapNode<T>* left; BinaryHeapNode<T>* right; BinaryHeapNode(T val) : value(val), left(nullptr), right(nullptr) {}};2. 元素进出的 “魔法”
插入(push)元素
当有新元素要加进这个特别的队伍时,它会先站到队伍最后面哦。然后呢,它就开始和前面的人比,如果它比前面的人更 “重要”(按堆的规则),就和前面的人换位置,一直这么比下去,直到找到自己合适的位置,这就叫 “上溯(sift up)” 啦,就好像新队员要在队伍里找到自己的等级一样呢?。
下面是个简单示例代码片段,展示插入元素并维护二叉堆性质(假设已有上面那个二叉堆节点结构体定义哦):
template<typename T>void siftUp(BinaryHeapNode<T>* node) { while (node!= nullptr && node->parent!= nullptr && node->value > node->parent->value) { // 交换节点和其父节点的值 swap(node->value, node->parent->value); node = node->parent; }}template<typename T>void pushToHeap(BinaryHeapNode<T>* root, T value) { // 创建新节点并插入到堆的末尾 BinaryHeapNode<T>* newNode = new BinaryHeapNode<T>(value); if (root == nullptr) { root = newNode; } else { // 找到合适的位置插入新节点(这里简单假设插入到最后一个叶子节点位置) BinaryHeapNode<T>* current = root; while (current->left!= nullptr && current->right!= nullptr) { current = current->left; } if (current->left == nullptr) { current->left = newNode; } else { current->right = newNode; } // 对新插入的节点进行上溯操作 siftUp(newNode); }}删除(pop)元素
当要处理队首元素(也就是pop操作)时,队伍最后面的那个人会跑到队首来。但他可能不符合队首的要求呀,所以他就得和下面的人比,如果下面的人比他更 “适合” 队首,就和下面的人换位置,一直比到他找到自己合适的位置为止,这就是 “下溯(sift down)” 的过程啦?。
下面是个简单示例代码片段,展示删除堆顶元素并维护二叉堆性质(同样假设已有上面那个二叉堆节点结构体定义哦):
template<typename T>void siftDown(BinaryHeapNode<T>* node) { while (node!= nullptr) { BinaryHeapNode<T>* largest = node; if (node->left!= nullptr && node->left->value > largest->value) { largest = node->left; } if (node->right!= nullptr && node->right->value > largest->value) { largest = node->right; } if (largest!= node) { // 交换节点和最大子节点的值 swap(node->value, largest->value); node = largest; } else { break; } }}template<typename T>T popFromHeap(BinaryHeapNode<T>* root) { if (root == nullptr) { throw runtime_error("堆为空"); } T rootValue = root->value; // 将堆的最后一个节点的值赋给堆顶 BinaryHeapNode<T>* lastNode = findLastNode(root); root->value = lastNode->value; // 删除最后一个节点(这里简单假设能正确删除,实际可能更复杂) delete lastNode; // 对新的堆顶节点进行下溯操作 siftDown(root); return rootValue;}在这代码里,popFromHeap函数就是用来删二叉堆的堆顶元素的,删完后用siftDown函数来保证二叉堆还是符合大顶堆的条件呢。
(四)优先队列都在哪里大显身手?
1. 任务调度:谁先谁后安排好
在操作系统或者任务管理系统里呀,任务就像一群等着被处理的小士兵?✈️。每个任务都有自己的优先级,比如紧急任务优先级高,普通任务优先级低。优先队列就像个聪明的指挥官,把任务按优先级排好队,处理器就可以按顺序先处理重要的任务啦,这样系统就能高效地运行咯,就跟快递分拣中心会优先处理加急件一样呢?。
下面是个简单的任务调度模拟代码示例,用优先队列来实现任务按优先级排序处理哦:
#include <iostream>#include <queue>#include <string>using namespace std;// 任务结构体struct Task { string name; int priority; Task(const string& n, int p) : name(n), priority(p) {}};// 自定义比较函数,按照任务优先级从高到低排序struct TaskCompare { bool operator()(const Task& t1, const Task& t2) { return t1.priority < t2.priority; }};int main() { // 创建任务优先队列 priority_queue<Task, vector<Task>, TaskCompare> taskQueue; // 添加一些任务到队列 taskQueue.push(Task("任务1", 5)); taskQueue.push(Task("任务2", 3)); taskQueue.push(Task("任务3", 8)); // 模拟处理器处理任务 while (!taskQueue.empty()) { Task currentTask = taskQueue.top(); cout << "正在处理任务: " << currentTask.name << ",优先级: " << currentTask.priority << endl; taskQueue.pop(); } return 0;} 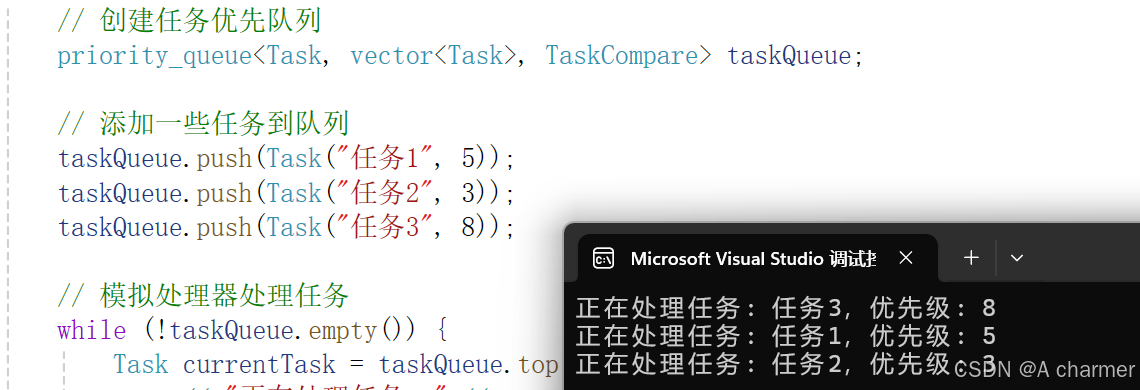
在这个例子里,我们先定义了Task结构体来表示任务,有任务名字和优先级两个属性哦。然后通过自定义的TaskCompare比较函数,让优先队列按任务优先级从高到低给任务排队。最后模拟处理器依次处理队列里的任务呢。
2. 图算法中的 “指路明灯”
在一些图算法里呀,比如 Dijkstra 算法求单源最短路径,优先队列可真是个大功臣呢?。想象一下你在一个迷宫里找出口,每个路口都有不同的距离标记。算法得不断选离起点最近的未访问路口继续探索呀,优先队列就能很快告诉算法哪个路口离起点最近,就像个导航仪一样,让算法能高效地找到最短路径呢?。
下面是个简单的 Dijkstra 算法示例,用优先队列来辅助找到从一个源点到其他节点的最短路径哦(这只是个简化示例,实际应用可能更复杂啦):
#include <iostream>#include <queue>#include <vector>#include <unordered_map>using namespace std;// 节点结构体struct Node { int id; vector<Node*> neighbors; int distance; Node(int i) : id(i), distance(INT_MAX) {}};// 自定义比较函数,按照节点距离从小到大排序struct NodeCompare { bool operator()(const Node* n1, const Node* n2) { return n1->distance > n2->distance; }};// Dijkstra算法实现void dijkstra(Node* source) { // 创建优先队列,按照节点距离排序 priority_queue<Node*, vector<Node*>, NodeCompare> pq; // 将源点加入队列,并设置其距离为0 source->distance = 0; pq.push(source); // 用于记录已访问过的节点 unordered_map<int, bool> visited; while (!pq.empty()) { Node* currentNode = pq.top(); pq.pop(); // 如果节点已经访问过,跳过 if (visited[currentNode->id]) { continue; } // 标记当前节点为已访问 visited[currentNode->id] = true; // 更新当前节点邻居的距离 for (Node* neighbor : currentNode->neighbors) { int newDistance = currentNode->日前距离 + 1; if (newDistance < neighbor->distance) { neighbor->distance = newDistance; pq.push(neighbor); } } }}int main() { // 创建一些节点 Node* node1 = new Node(1); Node* node2 = new Node(2); Node* node3 = new Node(3); // 构建节点之间的连接关系 node1->日前邻居.push_back(node2); node1->日前邻居.push_back(node3); node2->日前邻居.push_back(node3); // 运行Dijkstra算法 dijkstra(node1); // 输出节点到源点的距离 cout << "节点2到源点的距离: " << node2->distance << endl; cout << "节点3到源点的距离: " << node3->distance << endl; return 0;} 在这个例子里,我们先定义了Node结构体来表示图中的节点,有节点 ID、邻居节点列表和到源点的距离这些属性哦。然后通过自定义的NodeCompare比较函数,让优先队列按节点距离从小到大给节点排队。接着在 Dijkstra 算法里,利用优先队列高效地选离源点最近的未访问节点进行处理,这样就能找到从源点到其他节点的最短路径啦。
3. 数据压缩:让数据 “瘦身” 有妙招
在哈夫曼编码这个数据压缩方法里呀,优先队列也发挥着重要作用呢?。它就像个聪明的小助手,帮我们构建哈夫曼树。在构建过程中,它会选出现频率最低的两个字符,把它们合并成一个新的 “组合字符”,然后继续选频率最低的进行合并,直到构建出完整的哈夫曼树。最后根据这棵树给每个字符分配不同长度的编码,这样就能让数据占用更少的空间啦?。
下面是个简单的哈夫曼编码构建示例,用优先队列来辅助构建哈夫曼树哦(这也是个简化示例,实际应用可能更复杂啦):
#include <iostream>#include <queue>#include <vector>#include <unordered_map>using namespace std;// 哈夫曼树节点结构体struct HuffmanNode { char data; int frequency; HuffmanNode* left; HuffmanNode* left右; HuffmanNode(char d, int f) : data(d), frequency(f), left(nullptr), left右(nullptr) {}}// 自定义比较函数,按照节点频率从小到大排序struct HuffmanNodeCompare { bool operator()(const HuffmanNode* n1, const HuffmanNode* n2) { return n1->frequency > n2->frequency; }};// 构建哈夫曼树HuffmanNode* buildHuffmanTree(const unordered_map<char, int>& frequencyMap) { // 创建优先队列,按照节点频率排序 priority_queue<HuffmanNode*, vector<H夫曼Node*>, HuffmanNodeCompare> pq; // 将每个字符及其频率对应的节点加入队列 for (const auto& pair : frequencyMap) { pq.push(new HuffmanNode(pair.first, pair.second)); } while (pq.size() > 1) { // 取出频率最低的两个节点 HuffmanNode* leftNode = pq.top(); pq.pop(); HuffmanNode* rightNode = pq.top(); pq.pop(); // 创建新的父节点,频率为两个子节点频率之和 HuffmanNode* parentNode = new HuffmanNode('\0', leftNode->frequency + rightNode->frequency); parentNode->left = leftNode; parentNode->right = rightNode; // 将父节点加入队列 pq.push(parentNode); } return pq.top();}int main() { // 假设这里有个字符频率映射表 unordered_map<char, int> frequencyMap = { {'a', 5}, {'b', 3}, {'c', 8} }; // 构建哈夫曼树 HuffmanNode* huffmanTree = buildHuffmanTree(frequencyMap); // 这里可以根据哈夫曼树进一步处理,比如生成编码等,但为了简化先不展示啦 return 0;} 在这个例子里,我们先定义了HuffmanNode结构体来表示哈夫曼树的节点,有字符数据、频率、左右子节点这些属性哦。然后通过自定义的HuffmanNodeCompare比较函数,让优先队列按节点频率从小到大给节点排队。接着在构建哈夫曼树的过程中,利用优先队列选出频率最低的两个节点合并成新节点,一直重复这个过程直到构建出完整的哈夫曼树呢。
如果本文对你有帮助欢迎关注我?【A Charmer】
