文章目录
- 前言
- 1. 造轮子式生成数据样本
- 1.1 月牙形
- 1.2 方形
- 1.3 螺旋形
- 2. 自定义生成数据样本
- 2.1 点簇形
- 2.2 线簇形
- 2.3 环形
- 2.4 圆形
- 2.5 月牙形
- 结束语
前言
毕业季又到了,论文里涉及到一些机器学习算法,就想用一些数据样本来对算法的性能做一些可视化,苦于自制数据集的困难,所以本篇就介绍一下scikit-learn自带的一些函数库来生成数据。
1. 造轮子式生成数据样本
很久之前,也就是对scikit-learn不是特别熟悉的时候,那时候找不到合适的数据集,于是就用numpy自己造轮子,过程之艰难就不一一细说了,先看一个自己做的。
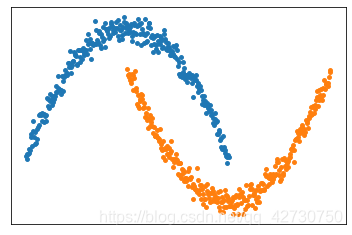
1.1 月牙形
import numpy as np
np.random.seed(256)
x1 = np.linspace(-3, 3, 300, dtype=np.float32)[:, np.newaxis]
noise = np.random.normal(0, 0.15, x1.shape).astype(np.float32)
y1 = -np.square(x1) / 3 + 4.5 + noise
x2 = np.linspace(0, 6, 300, dtype=np.float32)[:, np.newaxis]
y2 = np.square(x2 - 3) / 3 + 0.5 + noise
plt.figure()
plt.xticks([])
plt.yticks([])
plt.scatter(x1, y1, s=15)
plt.scatter(x2, y2, s=15)
plt.show()
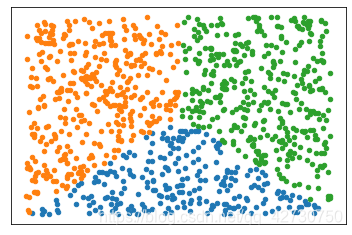
1.2 方形
import numpy as np
np.random.seed(256)
x = np.random.rand(1000, 2)
condition1 = x[:, 1] <= x[:, 0]
condition2 = x[:, 1] <= (1-x[:, 0])
index1 = np.where(condition1 & condition2)
x1 = x[index1]
x = np.delete(x, index1, axis=0)
index2 = x[:, 0] <= 0.5
x2 = x[index2]
x3 = np.delete(x, index2, axis=0)
plt.figure()
plt.xticks([])
plt.yticks([])
plt.scatter(x1[:, 0], x1[:, 1], s=20)
plt.scatter(x2[:, 0], x2[:, 1], s=20)
plt.scatter(x3[:, 0], x3[:, 1], s=20)
plt.show()
1.3 螺旋形
n_samples = 1500
np.random.seed(0)
t = 1.5 * np.pi * (1 + 3 * np.random.rand(1, n_samples))
x = t * np.cos(t)
y = t * np.sin(t)
X = np.concatenate((x, y))
X += 0.7 * np.random.randn(2, n_samples)
X = X.T
norm = plt.Normalize(y.min(), y.max())
plt.figure()
plt.xticks([])
plt.yticks([])
# cmap=plt.cm.nipy_spectral
plt.scatter(X[:, 0], X[:, 1], s=20, c=norm(X[:, 0]), cmap='viridis')
plt.show()

还可以,是吧,想要什么形状的数据都可以自己造,无非就是拟合一个函数再加上噪声,但就是稍微有一些繁琐,不如现成的库函数来的实在。当然啦,如果没事干,自己去探索不同的方程然后用代码的形式去实现,还是蛮好的。
2. 自定义生成数据样本
使用
sklearn.datasets自带的样本生成器来做数据集,具体参数可以参考官方文档。
2.1 点簇形
from sklearn.datasets import make_blobs
# x1表示生成的样本数据 y1表示样本的标签
x1, y1 = make_blobs(n_samples=300, n_features=2, centers=3, random_state=170)
plt.figure()
plt.xticks([])
plt.yticks([])
plt.scatter(x1[:, 0], x1[:, 1], c=y1, s=20)
plt.show()
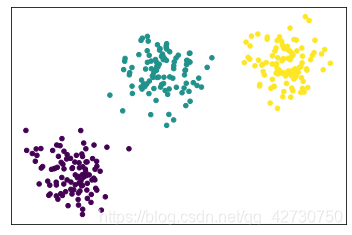
一条命令就可以生成数据,通过修改参数即可制作不同的数据集。如果颜色不喜欢,还可以修改一下:
x1, y1 = make_blobs(n_samples=300, n_features=2, centers=3, random_state=170)
plt.figure()
plt.xticks([])
plt.yticks([])
# plt.scatter(x, y, c=None, s=None)
# c 表示点的颜色 s表示点的大小
plt.scatter(x1[y1==0][:, 0], x1[y1==0][:, 1], s=20)
plt.scatter(x1[y1==1][:, 0], x1[y1==1][:, 1], s=20)
plt.scatter(x1[y1==2][:, 0], x1[y1==2][:, 1], s=20)
plt.show()
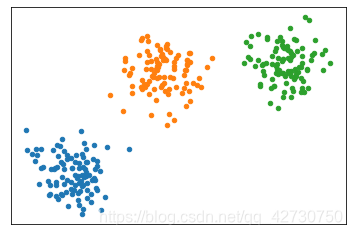
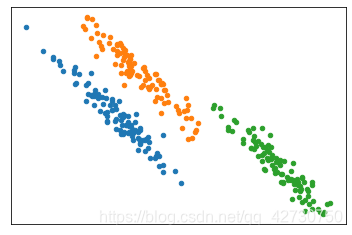
2.2 线簇形
圆簇形状的不喜欢的话还可以把它拉直一下,做一个变换:
x1, y1 = make_blobs(n_samples=300, n_features=2, centers=3, random_state=170)
transformation = [[0.60834549, -0.63667341], [-0.40887718, 0.85253229]]
x1 = np.dot(x1, transformation)
plt.figure()
plt.xticks([])
plt.yticks([])
plt.scatter(x1[y1==0][:, 0], x1[y1==0][:, 1], s=20)
plt.scatter(x1[y1==1][:, 0], x1[y1==1][:, 1], s=20)
plt.scatter(x1[y1==2][:, 0], x1[y1==2][:, 1], s=20)
plt.show()
2.3 环形
from sklearn.datasets import make_circles
x1, y1 = make_circles(n_samples=500, noise=0.07, random_state=16, factor=0.6)
plt.figure()
plt.xticks([])
plt.yticks([])
plt.scatter(x1[y1==0][:, 0], x1[y1==0][:, 1], s=20)
plt.scatter(x1[y1==1][:, 0], x1[y1==1][:, 1], s=20)
plt.show()

2.4 圆形
调整一下画板的尺寸,还可以变成圆形的形状:
x1, y1 = make_circles(n_samples=500, noise=0.07, random_state=16, factor=0.6)
plt.figure(figsize=(6, 6))
plt.xticks([])
plt.yticks([])
plt.scatter(x1[y1==0][:, 0], x1[y1==0][:, 1], s=20)
plt.scatter(x1[y1==1][:, 0], x1[y1==1][:, 1], s=20)
plt.show()

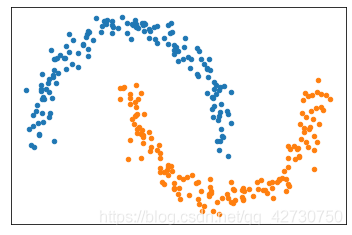
2.5 月牙形
from sklearn.datasets import make_moons
x1, y1 = make_moons(n_samples=300, noise=0.07, random_state=120)
plt.figure()
plt.xticks([])
plt.yticks([])
plt.scatter(x1[y1==0][:, 0], x1[y1==0][:, 1], s=20)
plt.scatter(x1[y1==1][:, 0], x1[y1==1][:, 1], s=20)
plt.show()
结束语
sklearn里面还有好多函数来自定制数据,除此之外还可以使用numpy生成,然后通过高级索引进行划分,最好结合着matplotlib中的cmap来做颜色映射,这样可以做出好玩又好看的数据集。