Qwen2.5-Coder-7B-Instruct模型本地部署,并实现简单的web对话
在自己电脑上部署一个聊天机器人,实现简单的chat界面,适用于千问2或者千问2.5的模型。windows环境也通用,修改好对应的路径就可以。
该Qwen-Coder-7B模型加载进显存后大约占用14G,支持流式传输,界面示例如图:
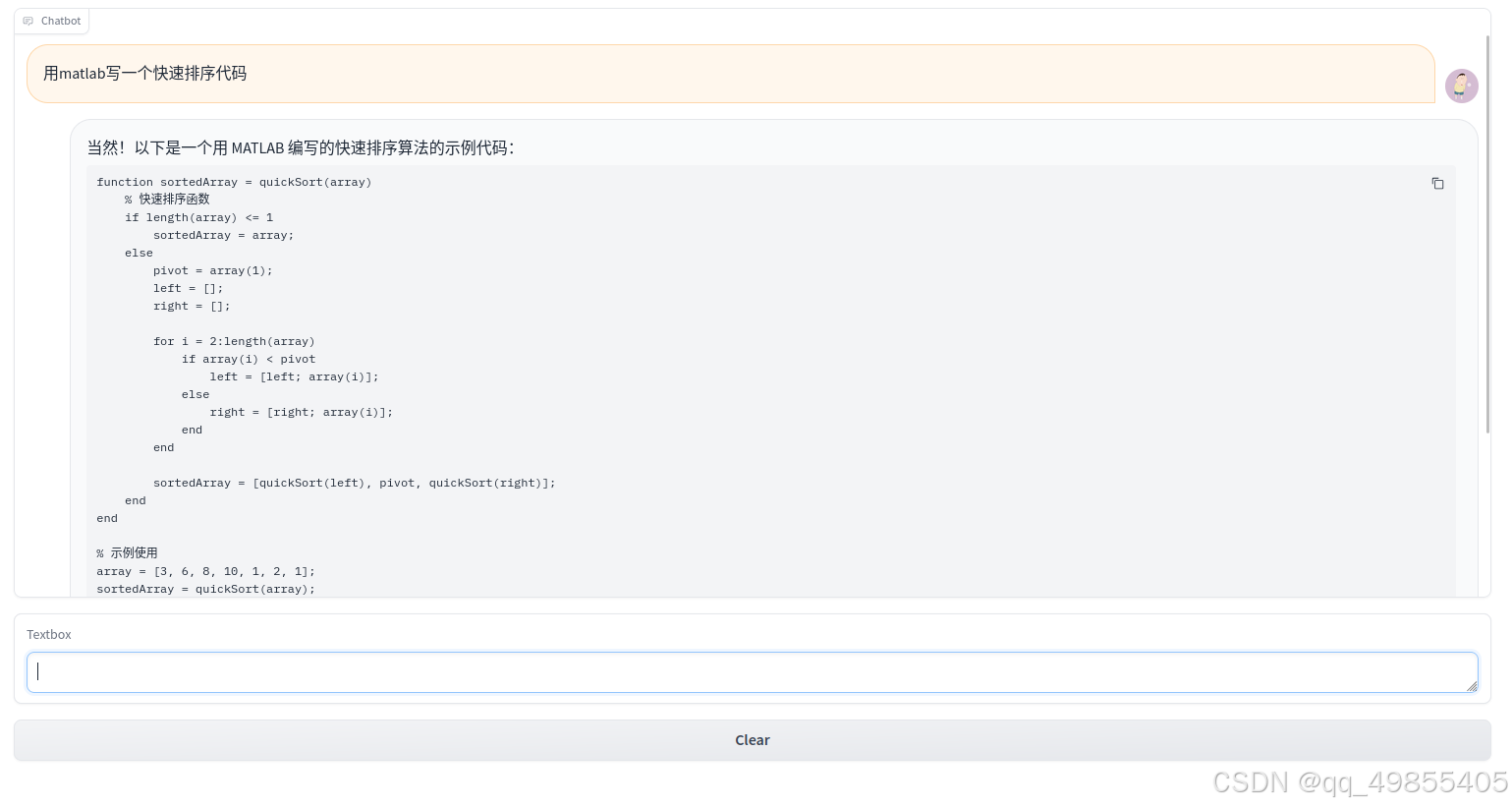
部署流程:
1、配置环境
在已经有torch+cuda的条件下,还需要以下几个库:
pip install transformers pip install accelerate pip install gradio其中transformers库需满足版本大于等于4.37.0,用来加载模型,accelerate用于加速模型,gradio用于生成前端界面。
2、下载模型文件
下载模型的地方:(魔搭社区)
点击此处下载模型:
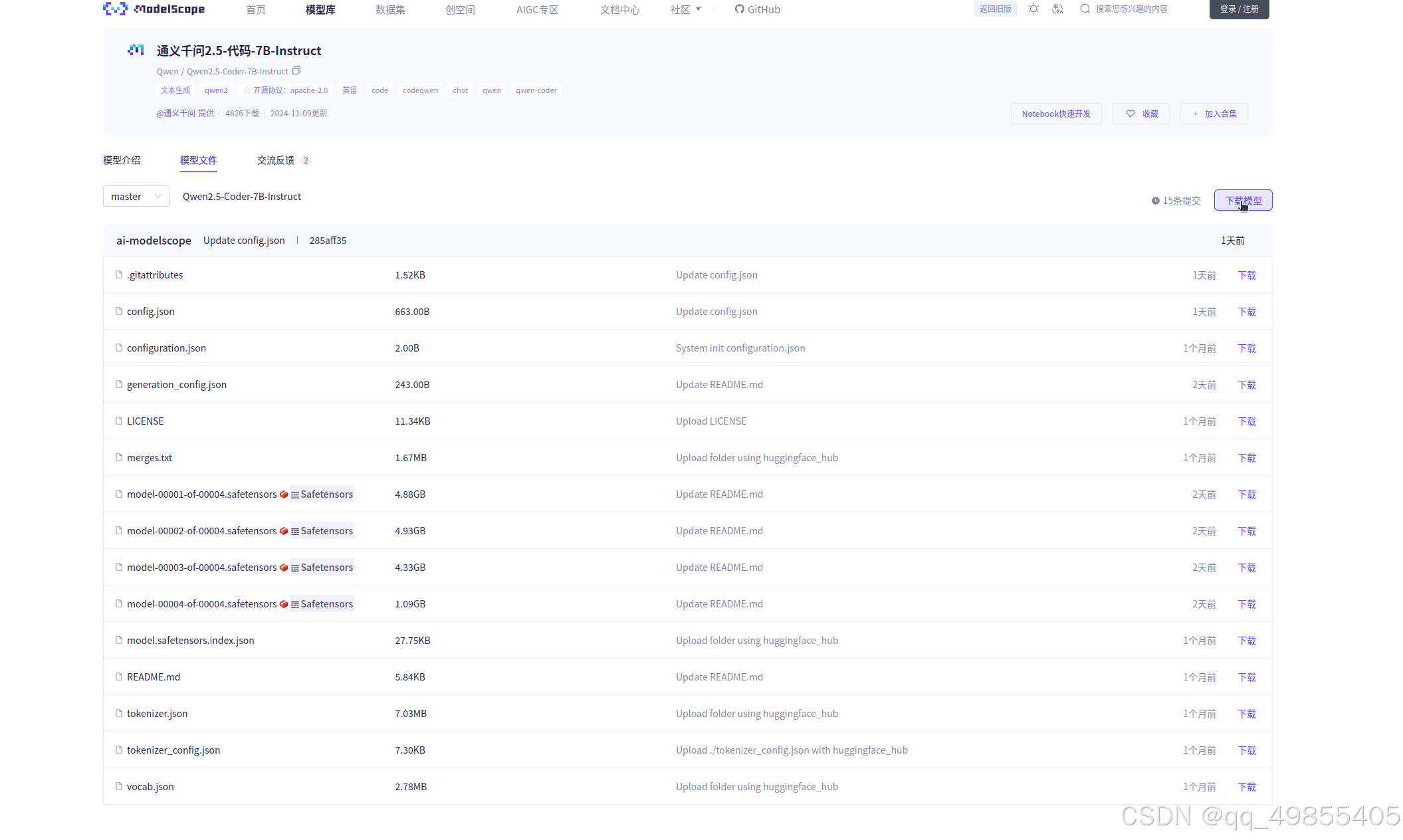
提供了很多种下载方式,选择一种方式下载即可:
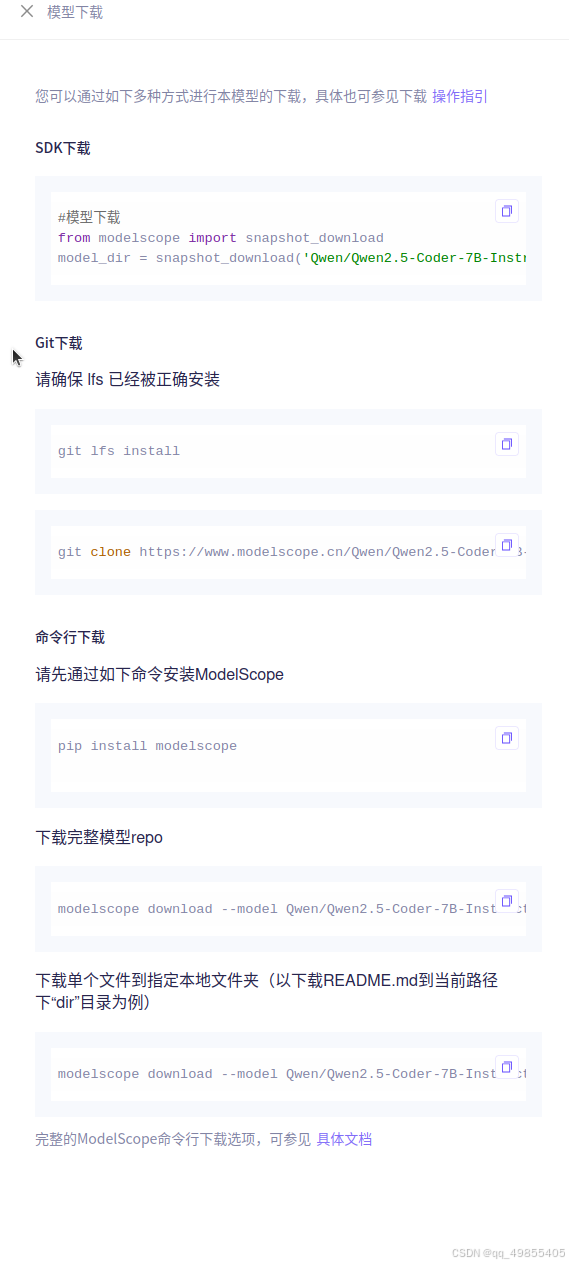
3、加载模型
下面代码是官方的示例
from transformers import AutoModelForCausalLM, AutoTokenizermodel_name = "path/to/your/model"# 把这里修改成你下载的模型位置,比如我是/home/LLM/Qwen/Qwen2_5-Coder-7B-Instructmodel = AutoModelForCausalLM.from_pretrained( # 加载模型 model_name, torch_dtype="auto", device_map="auto")tokenizer = AutoTokenizer.from_pretrained(model_name) # 加载分词器prompt = "Give me a short introduction to large language model.Answer it in Chinese"messages = [ {"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."}, {"role": "user", "content": prompt}]text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)generated_ids = model.generate( **model_inputs, max_new_tokens=512)response = tokenizer.decode(generated_ids[0], skip_special_tokens=True)print(response)4、实现简单的chat功能,进行web访问
首先导入需要用到的库和几个全局变量
from threading import Threadimport gradio as grfrom transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer# 分别是用户头像和聊天机器人的头像(需要在gradio工作的项目下,这里我的项目名为LLM)user_icon = '/home/LLM/Qwen-main/gradio_avatar_images/user_icon.jpeg'bot_icon = '/home/LLM/Qwen-main/gradio_avatar_images/bot_icon.jpg'model_name = '/home/LLM/Qwen/Qwen2_5-Coder-7B-Instruct' # 模型存放位置qwen_chat_history = [ {"role": "system", "content": "You are a helpful assistant."}]# 储存历史对话定义一个加载模型的函数:
def _load_model(): tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto", device_map="auto", ) streamer = TextIteratorStreamer(tokenizer=tokenizer, skip_prompt=True, skip_special_tokens=True) return model, tokenizer, streamerTextIteratorStreamer用于生成流式输出。
然后是整个聊天界面的一个实现,使用gradio库实现
with gr.Blocks() as demo: model, tokenizer, streamer = _load_model() # 载入模型 chatbot = gr.Chatbot( height=600, # 界面高度,可以自己调 avatar_images=(user_icon, bot_icon) )# Chatbot还涉及很多参数,如需了解清查阅官方技术文档 msg = gr.Textbox() clear = gr.ClearButton([msg, chatbot]) # 清除历史记录 def _clean_history(): global qwen_chat_history qwen_chat_history = [] #生成回复 def _response(message, chat_history): qwen_chat_history.append({"role": "user", "content": message}) # 拼接历史对话 history_str = tokenizer.apply_chat_template( qwen_chat_history, tokenize=False, add_generation_prompt=True ) inputs = tokenizer(history_str, return_tensors='pt').to(model.device) chat_history.append([message, ""]) # 推理参数 generation_kwargs = dict( **inputs, streamer=streamer, max_new_tokens=2048, num_beams=1, do_sample=True, top_p=0.8, temperature=0.3, ) # 监控流失输出结果 thread = Thread(target=model.generate, kwargs=generation_kwargs) thread.start() for new_text in streamer: chat_history[-1][1] += new_text yield "", chat_history qwen_chat_history.append( {"role": "assistant", "content": chat_history[-1][1]} ) clear.click(_clean_history()) msg.submit(_response, [msg, chatbot], [msg, chatbot])demo.queue().launch( share=False, server_port=8000, server_name="127.0.0.1",) # 绑定8000端口,进行web访问运行代码,会生成一个链接:

直接点开或者复制到浏览器打开就可以进入聊天界面:
完整代码:
from threading import Threadimport gradio as grfrom transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreameruser_icon = '/home/lhp/Desktop/LLM/Qwen-main/gradio_avatar_images/user_icon.jpeg'bot_icon = '/home/lhp/Desktop/LLM/Qwen-main/gradio_avatar_images/bot_icon.jpg'model_name = '/home/lhp/Desktop/LLM/Qwen/Qwen2_5-Coder-7B-Instruct'qwen_chat_history = [ {"role": "system", "content": "You are a helpful assistant."}]def _load_model(): tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype="auto", device_map="auto", ) streamer = TextIteratorStreamer(tokenizer=tokenizer, skip_prompt=True, skip_special_tokens=True) return model, tokenizer, streamerwith gr.Blocks() as demo: model, tokenizer, streamer = _load_model() chatbot = gr.Chatbot( height=600, avatar_images=(user_icon, bot_icon) ) msg = gr.Textbox() clear = gr.ClearButton([msg, chatbot]) def _clean_history(): global qwen_chat_history qwen_chat_history = [] def _response(message, chat_history): qwen_chat_history.append({"role": "user", "content": message}) # 拼接历史对话 history_str = tokenizer.apply_chat_template( qwen_chat_history, tokenize=False, add_generation_prompt=True ) inputs = tokenizer(history_str, return_tensors='pt').to(model.device) chat_history.append([message, ""]) # 拼接推理参数 generation_kwargs = dict( **inputs, streamer=streamer, max_new_tokens=2048, num_beams=1, do_sample=True, top_p=0.8, temperature=0.3, ) # 启动线程,用以监控流失输出结果 thread = Thread(target=model.generate, kwargs=generation_kwargs) thread.start() for new_text in streamer: chat_history[-1][1] += new_text yield "", chat_history qwen_chat_history.append( {"role": "assistant", "content": chat_history[-1][1]} ) clear.click(_clean_history()) msg.submit(_response, [msg, chatbot], [msg, chatbot])demo.queue().launch( share=False, server_port=8000, server_name="127.0.0.1",)
登录后可发表评论
点击登录