前言

博主介绍:
– 本人是了凡,意思为希望本人任何时候以善良为先,以人品为重,喜欢了凡四训中的立命之学、改过之法、积善之方、谦德之效四训,更喜欢每日在简书上投稿每日的读书感悟笔名:三月_刘超。专注于 Go Web 后端,辅学Python、Java、算法、前端等领域。
文章目录
- 前言
- 引言
- 官方解释语言来历
- 主要特征
- 优点
- 最大优点
- 准备学习前讲解
- 语言IDE编辑器安装包及开发环境(全套)
- 安装教程讲解
- 语言结构
- 语言基础语法
- 语法简讲
- 分割
- 注释
- 标识符
- 关键字
- 语法之变量
- 变量初始化
- 变量声明
- 常量声明
- 匿名变量
- 语法之数据类型
- 整型
- 浮点型
- 复数
- 布尔值
- 字符串
- byte和rune类型
- 类型转换
- 实战
- 语法之运算符
- 算数运算符
- 关系运算符
- 位运算符
- 赋值运算符
- 实战
- 语法之流程控制
- if else(分支结构)
- for(循环结构)
- for range(热键循环)
- switch case(分支结构)
- goto(跳转到指定标签)
- break(结束循环)
- continue(继续下一个循环)
- 实战
- 语法之数组
- 基础语法
- 数据定义
- 数组的初始化
- 数组的遍历
- 多维数组
- 数组是值类型
- 实战
- 语法之切片
- 切片是什么?
- 为什么要有切片?
- 切片的定义
- 切片不能直接比较
- 切片的赋值拷贝
- 切片遍历
- append()方法为切片添加元素
- 切片的扩容策略
- 使用copy()函数赋值切片
- 从切片中删除元素
- 实战
- 语法之map
- map定义
- map基本使用
- m判断某个值是否存在
- map的遍历
- 使用delete()函数删除值
- 按照指定顺序遍历map
- 元素为map类型的切片
- 值为切片类型的map
- 实战
- 语法之Go语言指针
- 指针地址和指针类型
- 指针取值
- new和make
- 语法之go语言函数
- 函数定义
- 函数的调用
- 参数
- 返回值
- 变量作用域
- 函数类型与变量
- 高级函数
- 匿名函数和闭包
- defer语句
- 内置函数介绍
- 实战
引言
官方解释语言来历
很久以前,有一个IT公司,这公司有个传统,允许员工拥有20%自由时间来开发实验性项目。在2007的某一天,公司的几个大牛,正在用c++开发一些比较繁琐但是核心的工作,主要包括庞大的分布式集群,大牛觉得很闹心,后来c++委员会来他们公司演讲,说c++将要添加大概35种新特性。这几个大牛的其中一个人,名为:Rob Pike,听后心中一万个xxx飘过,“c++特性还不够多吗?简化c++应该更有成就感吧”。于是乎,Rob Pike和其他几个大牛讨论了一下,怎么解决这个问题,过了一会,Rob Pike说要不我们自己搞个语言吧,名字叫“go”,非常简短,容易拼写。其他几位大牛就说好啊,然后他们找了块白板,在上面写下希望能有哪些功能(详见文尾)。接下来的时间里,大牛们开心的讨论设计这门语言的特性,经过漫长的岁月,他们决定,以c语言为原型,以及借鉴其他语言的一些特性,来解放程序员,解放自己,然后在2009年,go语言诞生。
主要特征
1.自动立即回收
2.更丰富的内置类型
3.函数多返回值
4.错误处理
5.匿名函数和闭包
6.类型和接口
7.并发编程
8.反射
9.语言交互性
10.既面向过程也面向对象
优点
自带gc。
静态编译,编译好后,扔服务器直接运行。
简单的思想,没有继承,多态,类等。
丰富的库和详细的开发文档。
语法层支持并发,和拥有同步并发的channel类型,使并发开发变得非常方便。
简洁的语法,提高开发效率,同时提高代码的阅读性和可维护性。
超级简单的交叉编译,仅需更改环境变量。
Go 语言是谷歌 2009 年首次推出并在 2012 年正式发布的一种全新的编程语言,可以在不损失应用程序性能的情况下降低代码的复杂性。谷歌首席软件工程师罗布派克(Rob Pike)说:我们之所以开发 Go,是因为过去10多年间软件开发的难度令人沮丧。Google 对 Go 寄予厚望,其设计是让软件充分发挥多核心处理器同步多工的优点,并可解决面向对象程序设计的麻烦。它具有现代的程序语言特色,如垃圾回收,帮助开发者处理琐碎但重要的内存管理问题。Go 的速度也非常快,几乎和 C 或 C++ 程序一样快,且能够快速开发应用程序。
最大优点
Go语言为并发而生:
Go语言的并发是基于 goroutine 的,goroutine 类似于线程,但并非线程。可以将 goroutine 理解为一种虚拟线程。Go 语言运行时会参与调度 goroutine,并将 goroutine 合理地分配到每个 CPU 中,最大限度地使用CPU性能。开启一个goroutine的消耗非常小(大约2KB的内存),你可以轻松创建数百万个goroutine。
goroutine的特点:
具有可增长的分段堆栈。意味着它们只在需要时才会使用更多内存。
goroutine的启动时间比线程快。
goroutine原生支持利用channel安全地进行通信。
goroutine共享数据结构时无需使用互斥锁。
准备学习前讲解
语言IDE编辑器安装包及开发环境(全套)
链接:https://pan.baidu.com/s/18di4xhP-rvCt0xHeJkV15A
提取码:AAAA
安装教程讲解
参考:https://www.jb51.net/article/200627.htm
语言结构
基础组成有以下几个部分:
包声明
package main // 以 package 关键字作为包声明 后面加上当前包名
引入包
import "fmt" // 以 import 关键字作为引入包 后面加上要引入的包名 这里暂时举例fmt 数据格式化包为举例,后序讲解具体用法
函数
func main() {} // 以 func 关键字作为声明函数或者方法 后面跟你要声明的函数名或者方法名
变量
var a string = "hello" // 这里先声明一个字符串格式的 hello 后面细节讲解
语句 & 表达式
if 布尔表达式 {
/* 在布尔表达式为 true 时执行 */
} // 这里暂时举例一种表达式为 if 语句 后面分别讲解 if、for、goto、switch...
注释
/*...*/ // 多行注释
// // 单行注释
语言基础语法
语法简讲
fmt.Println("Hello, World!")
上述代码分别是由关键字,标识符,常量,字符串,符号组成
1. fmt // 关键字
2. . // 标识符
3. Println // 关键字
4. ( // 符号
5. "Hello, World!" // 字符串
6. ) // 符号
分割
go的多行数书写不需要用 ; 分号做间隔像C语言一样书写 和 Python 写法有一点相似
注释
注释不会被编译
单行注释用// 进行注释
// 单行注释
多行注释用/* */进行注释
/*
多行注释
*/
标识符
标识符用来命名变量、类型等程序实体
不能以数字开头、不能是Go 语言的关键字、不能用运算符
举例:
1ab 以数字开头
func 是Go 语言的关键字
a+b 用运算符
关键字
25 个关键字或保留字:

还有 36 个预定义标识符:

语法之变量
变量初始化
单个初始化
var 变量名 类型 = 表达式
多个初始化
var 变量名1, 变量名2 = 表示式1, 表达式2
变量声明
单个声明
var 变量名 变量类型
// 例如:
var a string = "hello" // 声明一个名叫做 a 字符串类型的变量
多个声明
var (
one string // 声明一个名叫做 one 字符串类型的变量
two int // 声明一个名叫做 two 整型类型的变量
three bool // 声明一个名叫做 three 布尔类型的变量
)
全局声明
在程序的任意一行代码都可以引用的变量
局部声明
函数内部,可以使用更简略的 := 方式声明并初始化变量
举例:
package main
import (
"fmt"
)
// 全局变量
var All = 10
func main() {
n := 30
toPo := 20 // 局部变量
fmt.Println(toPo, n)
}
打印结果:
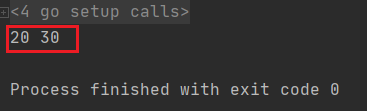
常量声明
单个常量声明
count a string = "hello" // 声明一个名叫做 a 字符串类型的常量
多个常量声明
count (
one string // 声明一个名叫做 one 字符串类型的常量
two int // 声明一个名叫做 two 整型类型的常量
three bool // 声明一个名叫做 three 布尔类型的常量
)
匿名变量
如果想要忽略某一个返回值的时候可以使用以_下划线符号来做匿名变量返回值
例如:
package main
import "fmt"
func fun1()(int, int) {
return 1, 2
}
func main() {
_, b := fun1() // 这里使用匿名返回值,对1返回值进行忽略掉
fmt.Println(b)
}
打印结果:
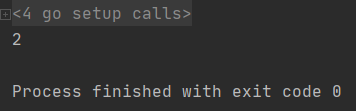
iota
iota 是一个常量计数器
目前没有发现什么大的用处

具体可以看:https://segmentfault.com/a/1190000023532777
语法之数据类型
整型
普通整型
普通整型:uint8 无符号 8位整型 (0 到 255) int8 有符号 8位整型 (-128 到 127)
特殊整型
特殊整型:uint 32位操作系统上就是uint32,64位操作系统上就是uint64 int 32位操作系统上就是int32,64位操作系统上就是int64 uintptr 无符号整型,用于存放一个指针
注意: 在使用int和 uint类型时,不能假定它是32位或64位的整型,而是考虑int和uint可能在不同平台上的差异。
进制表示
二进制: v := 0b00101101, 代表二进制的 101101,相当于十进制的 45
八进制:v := 0o377,代表八进制的 377,相当于十进制的 255
十进制: 不做改变
十六进制:v := 0x1p-2,代表十六进制的 1 除以 2²,也就是 0.25
而用 _ 来分隔数字,比如说: v := 123_456 表示 v 的值等于 123456
浮点型
float32
float32 的浮点数的最大范围约为 3.4e38,可以使用常量定义:math.MaxFloat32
float64
float64 的浮点数的最大范围约为 1.8e308,可以使用一个常量定义:math.MaxFloat64
复数
复数有实部和虚部,complex64的实部和虚部为32位,complex128的实部和虚部为64位。
布尔值
两种状态:
以bool类型进行声明布尔型数据,布尔型数据只有true(真)和false(假)两个值
注意
1.布尔类型变量默认值为false。
2.不允许将整型强制转换为布尔型。
3.布尔型无法参与数值运算,也无法与其他类型进行转换。
字符串
单行声明
s1 := "hello"
多行声明
使用反引号字符 列如:
s1 := `第一行
第二行
第三行
`
注意:反引号间换行将被作为字符串中的换行,但是所有的转义字符均无效,文本将会原样输出
字符串必会:
字符串的内部实现使用UTF-8编码
— — — — — —
求长度:
len(str)
— — — — — —
拼接字符串
+或fmt.Sprintf
— — — — — —
分割
strings.Split
— — — — — —
判断是否包含
strings.contains
— — — — — —
前缀/后缀判断
strings.HasPrefix,strings.HasSuffix
— — — — — —
子串出现的位置
strings.Index(),strings.LastIndex()
— — — — — —
join操作
strings.Join(a[]string, sep string)
byte和rune类型
byte 类型
uint8类型,或者叫 byte 型,代表了ASCII码的一个字符
Go 使用了特殊的 rune 类型来处理 Unicode,让基于 Unicode 的文本处理更为方便,也可以使用 byte 型进行默认字符串处理,性能和扩展性都有照顾
rune 类型
rune类型,代表一个 UTF-8字符
需要处理中文、日文或者其他复合字符时,则需要用到rune类型。rune类型实际是一个int32
字符串底层是一个byte数组,所以可以和[]byte类型相互转换。字符串是不能修改的 字符串是由byte字节组成,所以字符串的长度是byte字节的长度。 rune类型用来表示utf8字符,一个rune字符由一个或多个byte组成
结论:rune比byte大
类型转换
Go语言中只有强制类型转换,没有隐式类型转换。该语法只能在两个类型之间支持相互转换的时候使用
格式:T(表达式)
T表示要转换的类型。表达式包括变量、函数返回值等
实战
编写代码统计出字符串"hello沙河小王子"中汉字的数量。
答案:
package main
import "fmt"
func main() {
a := 0
s1 := "hello沙河小王子"
for _, i := range s1 {
if i > 'z' {
a ++
}
}
fmt.Println(a)
}
运行结果:
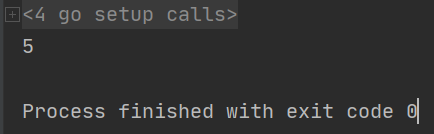
语法之运算符
算数运算符
+相加
-相减
*相乘
/相除
%求余
++(自增)和--(自减)在Go语言中是单独的语句,并不是运算符,Go语言中只可以后--不可以前--,++也一样
关系运算符
==检查两个值是否相等,如果相等返回 True 否则返回 False。
!=检查两个值是否不相等,如果不相等返回 True 否则返回 False。
>检查左边值是否大于右边值,如果是返回 True 否则返回 False。
>=检查左边值是否大于等于右边值,如果是返回 True 否则返回 False。
<检查左边值是否小于右边值,如果是返回 True 否则返回 False。
<=检查左边值是否小于等于右边值,如果是返回 True 否则返回 False。
逻辑运算符
&&逻辑 AND 运算符,如果两边的操作数都是 True,则为 True,否则为False。
||逻辑 OR 运算符, 如果两边的操作数有一个 True,则为 True,否则为 False。
!逻辑 NOT 运算符, 如果条件为 True,则为 False,否则为 True。
位运算符
&参与运算的两数各对应的二进位相与。(两位均为1才为1)
|参与运算的两数各对应的二进位相或。(两位有一个为1就为1)
^参与运算的两数各对应的二进位相异或,当两对应的二进位相异时,结果为1。(两位不一样则为1)
<<左移n位就是乘以2的n次方。“a<<b”是把a的各二进位全部左移b位,高位丢弃,低位补0。
>>右移n位就是除以2的n次方。“a>>b”是把a的各二进位全部右移b位。
赋值运算符
=简单的赋值运算符,将一个表达式的值赋给一个左值
+=相加后再赋值
-=相减后再赋值
*=相乘后再赋值
/=相除后再赋值
%=求余后再赋值
<<=左移后赋值
>>=右移后赋值
&=按位与后赋值
|=按位或后赋值
^=按位异或后赋值
实战
有一堆数字,如果除了一个数字以外,其他数字都出现了两次,那么如何找到出现一次的数字?
答案:
package main
import "fmt"
func main() {
var nums = []int {5,7,8,8,9,7,9}
i := 0
for j := 0; j < len(nums); j ++ {
i = i ^ nums[j]
}
fmt.Println(i)
}
执行结果

语法之流程控制
if else(分支结构)
基础写法:
if 表达式1 {
分支1
} else if 表达式2 {
分支2
} else{
分支3
}
规定与if/else匹配的左括号{必须与if/else和表达式放在同一行,{放在其他位置会触发编译错误
特殊写法
if条件判断还有一种特殊的写法,可以在 if 表达式之前添加一个执行语句,再根据变量值进行判断
for(循环结构)
Go 语言中的所有循环类型均可以使用for关键字来完成
基础写法
for 初始语句;条件表达式;结束语句{
循环体语句
}
初始语句,条件表达式,结束语句三者都可以省略,也可以理解为单独的三个部分
无限循环
for循环可以通过break、goto、return、panic语句强制退出循环,也可以配合goto,return,panic完成其他事情,不一定非要死循环中使用
for range(热键循环)
for range遍历数组、切片、字符串、map 及通道(channel)。
数组、切片、字符串返回索引和值。
map返回键和值。
通道(channel)只返回通道内的值。
switch case(分支结构)
使用switch语句可方便地对大量的值进行条件判断
Go语言规定每个switch只能有一个default分支
一个分支可以有多个值,多个case值中间使用英文逗号分隔
switch n := 7; n {
case 1, 3, 5, 7, 9:
fmt.Println("奇数")
分支还可以使用表达式,这时候switch语句后面不需要再跟判断变量
age := 30
switch {
case age < 25:
fmt.Println("你的年龄是",age,"岁")
fallthrough语法可以执行满足条件的case的下一个case,是为了兼容C语言中的case设计的
举例:
package main
import "fmt"
func main() {
s := "a"
switch {
case s == "a":
fmt.Println("a")
fallthrough
case s == "b":
fmt.Println("b")
}
}
运行结果
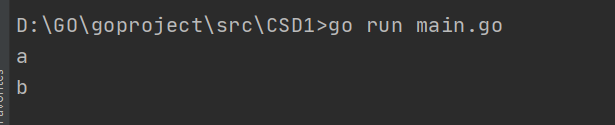
goto(跳转到指定标签)
goto语句通过标签进行代码间的无条件跳转。goto语句可以在快速跳出循环、避免重复退出上有一定的帮助。Go语言中使用goto语句能简化一些代码的实现过程
举例:
package main
import "fmt"
func main() {
Demo()
}
func Demo() {
for i := 0; i < 10; i++ {
for j := 0; j < 10; j++ {
if j == 2 {
// 设置退出标签
goto breakTag
}
fmt.Printf("%v-%v\n", i, j)
}
}
return
// 标签
breakTag:
fmt.Println("结束for循环")
}
运行结果
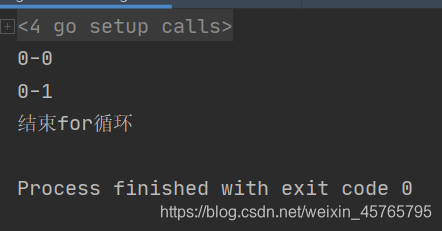
break(结束循环)
break语句可以结束for、switch和select的代码块
break语句还可以在语句后面添加标签,表示退出某个标签对应的代码块,标签要求必须定义在对应的for、switch和 select的代码块上
例如:
package main
import "fmt"
func main() {
Demo()
}
func Demo() {
DEMO:
for i := 0; i < 10; i++ {
for j := 0; j < 10; j++ {
if j == 2 {
break DEMO
}
fmt.Printf("%v-%v\n", i, j)
}
}
fmt.Println("...")
}
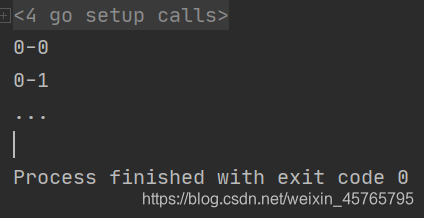
continue(继续下一个循环)
continue语句可以结束当前循环,开始下一次的循环迭代过程,仅限在for循环内使用。
在 continue语句后添加标签时,表示开始标签对应的循环
举例
package main
import "fmt"
func main() {
Demo()
}
func Demo() {
loop:
for i := 0; i < 5; i++ {
for j := 0; j < 5; j++ {
if i == 2 && j == 2 {
continue loop
}
fmt.Printf("%v-%v\n", i, j)
}
}
}
运行结果
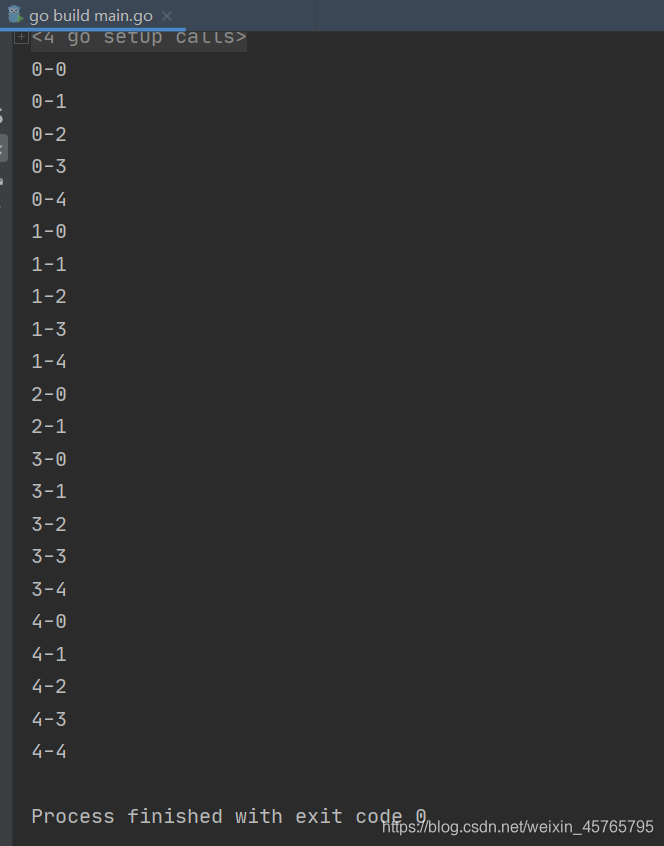
实战
编写代码打印9*9乘法表
答案:
package main
import "fmt"
func main() {
for i := 1; i <= 9; i++ {
for j := 1; j <= i; j++ {
fmt.Printf("%d * %d = %-2d ", i, j, i*j)
}
fmt.Println()
}
}
执行结果
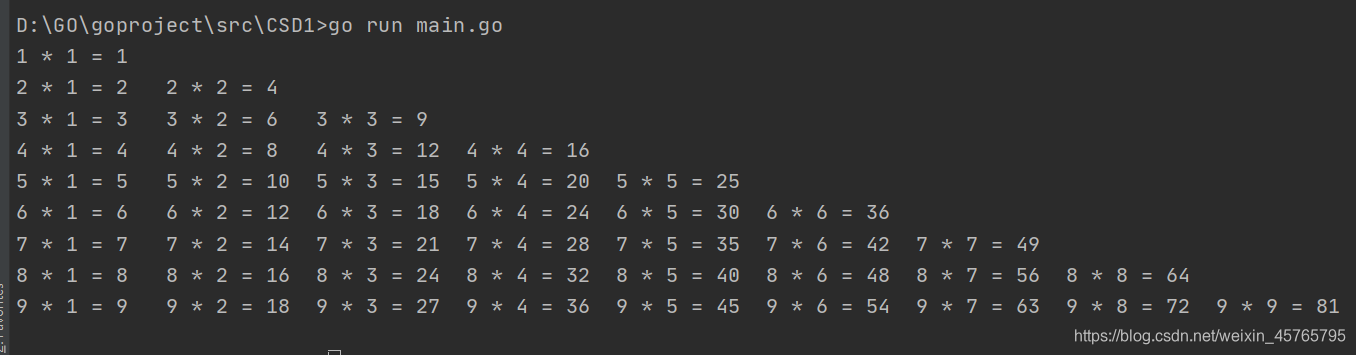
语法之数组
基础语法
// 定义一个长度为6元素类型为int的数组a
var a [6]int
数据定义
var 数组变量名 [元素数量]T
数组的长度必须是常量,并且长度是数组类型的一部分。 [5]int和[10]int是不同的类型。
两种相等类型的数组可以直接交换值
var num = []int {2,3,5}
var nums = []int {3,8,7}
num, nums = nums, num
fmt.Println(num, nums)
数组可以通过下标进行访问,下标是从0开始,最后一个元素下标是:len-1,访问越界(下标在合法范围之外),则触发访问越界,会panic
数组的初始化
方法一:
初始化数组时可以使用初始化列表来设置数组元素的值
//数组会初始化为int类型的零值
var testArray [3]int
//使用指定的初始值完成初始化
var numArray = [3]int{1, 2}
//使用指定的初始值完成初始化
var cityArray = [3]string{"北京", "上海", "深圳"}
方法二:
也可以不写长度,编译器根据初始值的个数自行推断数组的长度
var testArray [3]int
var numArray = [...]int{1, 2}
var cityArray = [...]string{"北京", "上海", "深圳"}
方法三:
可以使用指定索引值的方式来初始化数组
a := [...]int{1: 1, 3: 5}
fmt.Println(a) // [0 1 0 5]
数组初始化后默认是0
数组的遍历
方法一:
// 方法1:for循环遍历
for i := 0; i < len(a); i++ {
fmt.Println(a[i])
}
方法二:
// 方法2:for range遍历
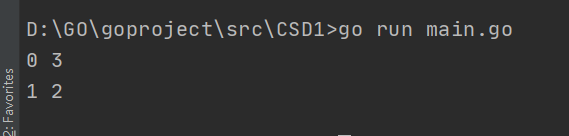
for index, value := range a {
fmt.Println(index, value)
}
多维数组
二维数组的定义
a := [3][2]string{
{"北京", "上海"},
{"广州", "深圳"},
{"成都", "重庆"},
}
fmt.Println(a) //[[北京 上海] [广州 深圳] [成都 重庆]]
fmt.Println(a[2][1]) //支持索引取值:重庆
二维数组的遍历
for _, v1 := range a {
for _, v2 := range v1 {
fmt.Printf("%s\t", v2)
}
fmt.Println()
}
注意: 多维数组只有第一层可以使用…来让编译器推导数组长度
数组是值类型
数组是值类型,赋值和传参会复制整个数组。因此改变副本的值,不会改变本身的值。
注意:
数组支持 “==“、”!=” 操作符,因为内存总是被初始化过的。
[n]T表示指针数组,[n]T表示数组指针 。
实战
找出数组中和为指定值的两个元素的下标,比如从数组[1, 3, 5, 7, 8]中找出和为8的两个元素的下标分别为(0,3)和(1,2)。
答案:
package main
import "fmt"
func main() {
var num = []int {1, 3, 5, 7, 8}
sum := 8
for i := 0; i < len(num); i ++ {
for j := i; j < len(num); j ++ {
if num[i] + num[j] == sum {
fmt.Println(i, j)
}
}
}
}
执行结果
语法之切片
切片是什么?
切片(Slice)是一个拥有相同类型元素的可变长度的序列。它是基于数组类型做的一层封装。它非常灵活,支持自动扩容。
切片是一个引用类型,它的内部结构包含地址、长度和容量。切片一般用于快速地操作一块数据集合
为什么要有切片?
因为数组的长度是固定的并且数组长度属于类型的一部分,所以数组有很多的局限性,比如不可以追加新元素
切片的定义
基本语法
var name []T
name:表示变量名
T:表示切片中的元素类型
var a []string //声明一个字符串切片
var b = []int{} //声明一个整型切片并初始化
var c = []bool{false, true} //声明一个布尔切片并初始化
切片的长度和容量
切片拥有自己的长度和容量,我们可以通过使用内置的len()函数求长度,使用内置的cap()函数求切片的容量
切片表达式
a[low : high : max]
low默认值是0,low代表开始切数组的左边
high代表开始切片数组的右边,但是不包含右下标的数字
总结:就是所谓的左开右闭
max 代表当前切片的最多切多大的长度,如果比切出来的长度小则会报语法错误
完整切片表达式需要满足的条件是0 <= low <= high <= max <= cap(a),其他条件和简单切片表达式相同。
使用make()函数构造切片
需要动态的创建一个切片,我们就需要使用内置的make()函数,格式如下:
make([]T, size, cap)
T:切片的元素类型
size:切片中元素的数量
cap:切片的容量
切片的本质
切片的本质就是对底层数组的封装,它包含了三个信息:底层数组的指针、切片的长度(len)和切片的容量(cap)
判断切片是否为空
要检查切片是否为空,请始终使用len(s) == 0来判断,而不应该使用s == nil来判断
切片不能直接比较
切片之间是不能比较的,我们不能使用==操作符来判断两个切片是否含有全部相等元素。 切片唯一合法的比较操作是和nil比较。 一个nil值的切片并没有底层数组,一个nil值的切片的长度和容量都是0。但是我们不能说一个长度和容量都是0的切片一定是nil
var s1 []int //len(s1)=0;cap(s1)=0;s1==nil
s2 := []int{} //len(s2)=0;cap(s2)=0;s2!=nil
s3 := make([]int, 0) //len(s3)=0;cap(s3)=0;s3!=nil
所以要判断一个切片是否是空的,要是用len(s) == 0来判断,不应该使用s == nil来判断。
切片的赋值拷贝
拷贝前后两个变量共享底层数组,对一个切片的修改会影响另一个切片的内容,这点需要特别注意
s1 := make([]int, 3) //[0 0 0]
s2 := s1 //将s1直接赋值给s2,s1和s2共用一个底层数组
s2[0] = 100
fmt.Println(s1) //[100 0 0]
fmt.Println(s2) //[100 0 0]
切片指向的是底层数组的那一段连续空间,因为切片里包含了,指针,切片的长度,切片的容量
切片遍历
切片的遍历方式和数组是一致的,支持索引遍历和for range遍历
append()方法为切片添加元素
Go语言的内建函数append()可以为切片动态添加元素。 可以一次添加一个元素,可以添加多个元素,也可以添加另一个切片中的元素(后面加…)。
var s []int
s = append(s, 1) // [1]
s = append(s, 2, 3, 4) // [1 2 3 4]
s2 := []int{5, 6, 7}
s = append(s, s2...) // [1 2 3 4 5 6 7]
注意:通过var声明的零值切片可以在append()函数直接使用,无需初始化
var s []int
s = append(s, 1, 2, 3)
没有必要像下面的代码一样初始化一个切片再传入append()函数使用
每个切片会指向一个底层数组,这个数组的容量够用就添加新增元素。当底层数组不能容纳新增的元素时,切片就会自动按照一定的策略进行“扩容”,此时该切片指向的底层数组就会更换。“扩容”操作往往发生在append()函数调用时,所以我们通常都需要用原变量接收append函数的返回值。
切片的扩容策略
首先判断,如果新申请容量(cap)大于2倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)。
否则判断,如果旧切片的长度小于1024,则最终容量(newcap)就是旧容量(old.cap)的两倍,即(newcap=doublecap),
否则判断,如果旧切片长度大于等于1024,则最终容量(newcap)从旧容量(old.cap)开始循环增加原来的1/4,即(newcap=old.cap,for {newcap += newcap/4})直到最终容量(newcap)大于等于新申请的容量(cap),即(newcap >= cap)
如果最终容量(cap)计算值溢出,则最终容量(cap)就是新申请容量(cap)。
需要注意的是,切片扩容还会根据切片中元素的类型不同而做不同的处理,比如int和string类型的处理方式就不一样
使用copy()函数赋值切片
由于切片是引用类型,所以a和b其实都指向了同一块内存地址。修改b的同时a的值也会发生变化
Go语言内建的copy()函数可以迅速地将一个切片的数据复制到另外一个切片空间中,copy()函数的使用格式如下
copy(destSlice, srcSlice []T)
srcSlice: 数据来源切片
destSlice: 目标切片
从切片中删除元素
目前唯一方法:
要从切片a中删除索引为index的元素,操作方法是:
a = append(a[:index], a[index+1:]...)
实战
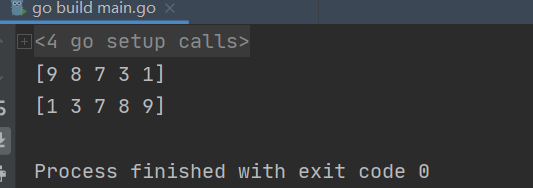
请使用内置的sort包对数组var a = […]int{3, 7, 8, 9, 1}进行排序
答案
package main
import (
"fmt"
"sort"
)
func main() {
var a = [...]int{3, 7, 8, 9, 1}
sort.Sort(sort.Reverse(sort.IntSlice(a[:]))) // 降序排列
fmt.Println(a)
sort.Ints(a[:]) // 升序排列
fmt.Println(a)
}
执行结果
语法之map
map是一种无序的基于key-value的数据结构,Go语言中的map是引用类型,必须初始化才能使用。
map定义
定义语法格式:
map[KeyType]ValueType
KeyType:表示键的类型。
ValueType:表示键对应的值的类型
map类型的变量默认初始值为nil,需要使用make()函数来分配内存
make(map[KeyType]ValueType, [cap])
其中cap表示map的容量,该参数虽然不是必须的,但是我们应该在初始化map的时候就为其指定一个合适的容量
map基本使用
map中的数据都是成对出现的
map也支持在声明的时候填充元素
m判断某个值是否存在
Go语言中有个判断map中键是否存在的特殊写法
value, ok := map[key]
map的遍历
使用for range遍历map。
for k, v := range scoreMap {
fmt.Println(k, v)
}
单独遍历键key
for k := range scoreMap {
fmt.Println(k)
}
注意: 遍历map时的元素顺序与添加键值对的顺序无关。
使用delete()函数删除值
使用delete()内建函数从map中删除一组键值对
delete(map, key)
map:表示要删除键值对的map
key:表示要删除的键值对的键
按照指定顺序遍历map
代码
package main
import (
"fmt"
"math/rand"
"sort"
"time"
)
func main() {
rand.Seed(time.Now().UnixNano()) // 初始化随机数种子
var scoreMap = make(map[string]int, 20)
for i := 0; i < 10; i++ {
key := fmt.Sprintf("stu%02d",i) // 生成stu开头的字符串
value := rand.Intn(10)
scoreMap[key] = value
}
// 取出map中的所有key存入切片keys
var keys = make([]string, 0, 20)
for key := range scoreMap{
keys = append(keys, key)
}
// 对切片进行排序
sort.Strings(keys)
// 按照排序后的key遍历map
for _, key := range keys{
fmt.Println(key, scoreMap[key])
}
}
执行结果

元素为map类型的切片
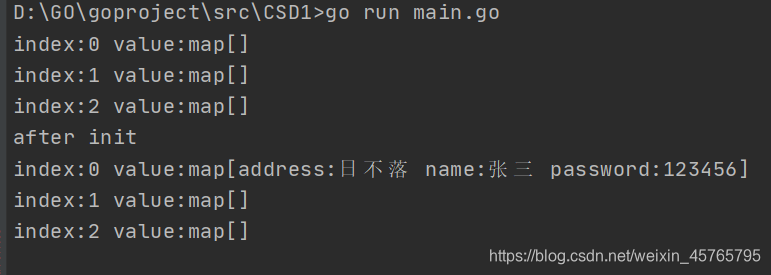
代码
package main
import (
"fmt"
)
func main() {
var mapSlice = make([]map[string]string, 3)
for index, value := range mapSlice {
fmt.Printf("index:%d value:%v\n", index, value)
}
fmt.Println("after init")
// 对切片中的map元素进行初始化
mapSlice[0] = make(map[string]string, 10)
mapSlice[0]["name"] = "张三"
mapSlice[0]["password"] = "123456"
mapSlice[0]["address"] = "日不落"
for index, value := range mapSlice {
fmt.Printf("index:%d value:%v\n", index, value)
}
}
执行结果
值为切片类型的map
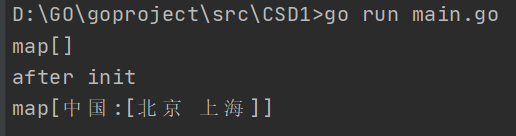
代码
package main
import (
"fmt"
)
func main() {
var sliceMap = make(map[string][]string, 3)
fmt.Println(sliceMap)
fmt.Println("after init")
key := "中国"
value, ok := sliceMap[key]
if !ok {
value = make([]string, 0, 2)
}
value = append(value, "北京", "上海")
sliceMap[key] = value
fmt.Println(sliceMap)
}
执行结果
实战
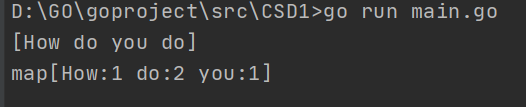
写一个程序,统计一个字符串中每个单词出现的次数。比如:”how do you do”中how=1 do=2 you=1。
答案
package main
import (
"fmt"
"strings"
)
func main() {
str := "How do you do"
strSlice := strings.Split(str, " ")
fmt.Println(strSlice)
keyMap := make(map[string]int, 20)
for _, key := range strSlice {
_, isReal := keyMap[key]
if !isReal {
keyMap[key] = 1
} else {
keyMap[key] += 1
}
}
fmt.Println(keyMap)
}
执行结果
语法之Go语言指针
区别于C/C++中的指针,Go语言中的指针不能进行偏移和运算,是安全指针。
要搞明白Go语言中的指针需要先知道3个概念:指针地址、指针类型和指针取值。
Go语言中的指针不能进行偏移和运算,因此Go语言中的指针操作非常简单,我们只需要记住两个符号:&(取地址)和*(根据地址取值)。
指针地址和指针类型
去变量指针的语法
ptr := &v // v的类型为T
v:代表被取地址的变量,类型为T
ptr:用于接收地址的变量,ptr的类型就为*T,称做T的指针类型。*代表指针。
指针取值
对普通变量使用&操作符取地址后会获得这个变量的指针,然后可以对指针使用*操作,也就是指针取值
总结:
取地址操作符&和取值操作符*是一对互补操作符,&取出地址,*根据地址取出地址指向的值。
变量、指针地址、指针变量、取地址、取值的相互关系和特性如下:
对变量进行取地址(&)操作,可以获得这个变量的指针变量。
指针变量的值是指针地址。
对指针变量进行取值(*)操作,可以获得指针变量指向的原变量的值。
new和make
new和make是内建的两个函数,主要用来分配内存。
new
func new(Type) *Type
new: new是一个内置的函数,它的函数签名如下
Type表示类型,new函数只接受一个参数,这个参数是一个类型
*Type表示类型指针,new函数返回一个指向该类型内存地址的指针
make
make也是用于内存分配的,区别于new,它只用于slice、map以及chan的内存创建,而且它返回的类型就是这三个类型本身,而不是他们的指针类型,因为这三种类型就是引用类型,所以就没有必要返回他们的指针了
func make(t Type, size ...IntegerType) Type
make函数是无可替代的,我们在使用slice、map以及channel的时候,都需要使用make进行初始化,然后才可以对它们进行操作
new与make的区别
二者都是用来做内存分配的。
make只用于slice、map以及channel的初始化,返回的还是这三个引用类型本身;
而new用于类型的内存分配,并且内存对应的值为类型零值,返回的是指向类型的指针。
语法之go语言函数
函数是组织好的、可重复使用的、用于执行指定任务的代码块 Go语言中支持函数、匿名函数和闭包
函数定义
定义函数使用func关键字基本格式:
func 函数名(参数)(返回值){
函数体
}
函数名:由字母、数字、下划线组成。但函数名的第一个字母不能是数字。在同一个包内,函数名也称不能重名(包的概念详见后文)。
参数:参数由参数变量和参数变量的类型组成,多个参数之间使用,分隔。
返回值:返回值由返回值变量和其变量类型组成,也可以只写返回值的类型,多个返回值必须用()包裹,并用,分隔。
函数体:实现指定功能的代码块。
函数的调用
定义了函数之后,我们可以通过函数名()的方式调用函数。 例如我们调用上面定义的两个函数
package main
func main() {
Hello()
}
func Hello() {
}
注意:调用有返回值的函数时,可以不接收其返回值
参数
类型简写
函数的参数中如果相邻变量的类型相同,则可以省略类型
func intSum(x, y int) int {
return x + y
}
类型均为int,因此可以省略x的类型,因为y后面有类型说明,x参数也是该类型
可变参数
可变参数是指函数的参数数量不固定。Go语言中的可变参数通过在参数名后加…来标识。
注意:可变参数通常要作为函数的最后一个参数。
返回值
Go语言中通过return关键字向外输出返回值。
多返回值
Go语言中函数支持多返回值,函数如果有多个返回值时必须用()将所有返回值包裹起来
返回值命名
函数定义时可以给返回值命名,并在函数体中直接使用这些变量,最后通过return关键字返回
返回值补充
当我们的一个函数返回值类型为slice时,nil可以看做是一个有效的slice,没必要显示返回一个长度为0的切片
变量作用域
全局变量
全局变量是定义在函数外部的变量,它在程序整个运行周期内都有效。 在函数中可以访问到全局变量
局部变量
第一种
函数内定义的变量无法在该函数外使用
第二种
如果局部变量和全局变量重名,优先访问局部变量
语句块定义的变量,通常我们会在if条件判断、for循环、switch语句上使用这种定义变量的方式
for循环语句中定义的变量,也是只在for语句块中生效
for i := 0; i < 10; i++ {
fmt.Println(i) //变量i只在当前for语句块中生效
}
//fmt.Println(i) //此处无法使用变量i
函数类型与变量
定义函数类型
使用type关键字来定义一个函数类型
type calculation func(int, int) int定义了一个
calculation类型,它是一种函数类型,这种函数接收两个int类型的参数并且返回一个int类型的返回值。
函数类型变量
type cal func(int, int)int
func add(x,y int)int {
return x + y
}
func main() {
var c cal
c = add
fmt.Println(c(2,4)) // 6
}
高级函数
高阶函数分为函数作为参数和函数作为返回值两部分
函数作为参数
func add(x, y int) int {
return x + y
}
func calc(x, y int, op func(int, int) int) int {
return op(x, y)
}
func main() {
ret2 := calc(10, 20, add)
fmt.Println(ret2) //30
}
函数作为返回值
func do(s string) (func(int, int) int, error) {
switch s {
case "+":
return add, nil
case "-":
return sub, nil
default:
err := errors.New("无法识别的操作符")
return nil, err
}
}
匿名函数和闭包
匿名函数
定义
函数可以作为返回值,但在函数内部不能再像之前那样定义函数了,只能定义匿名函数。匿名函数就是没有函数名的函数格式:
func(参数)(返回值){
函数体
}
闭包
定义
闭包指的是一个函数和与其相关的引用环境组合而成的实体。闭包=函数+引用环境
func adder() func(int) int {
var x int
return func(y int) int {
x += y
return x
}
}
变量f是一个函数并且它引用了其外部作用域中的x变量,此时f就是一个闭包。 在f的生命周期内,变量x也一直有效
func adder2(x int) func(int) int {
return func(y int) int {
x += y
return x
}
}
func makeSuffixFunc(suffix string) func(string) string {
return func(name string) string {
if !strings.HasSuffix(name, suffix) {
return name + suffix
}
return name
}
}
func calc(base int) (func(int) int, func(int) int) {
add := func(i int) int {
base += i
return base
}
sub := func(i int) int {
base -= i
return base
}
return add, sub
}
牢记闭包=函数+引用环境
defer语句
定义
defer语句会将其后面跟随的语句进行延迟处理。在defer归属的函数即将返回时,将延迟处理的语句按defer定义的逆序进行执行,也就是说,先被defer的语句最后被执行,最后被defer的语句,最先被执行
使用
defer语句延迟调用的特性,所以defer语句能非常方便的处理资源释放问题。比如:资源清理、文件关闭、解锁及记录时间等。
我的理解
defer的底层像一个栈一样,先入后出
执行时机
return语句在底层并不是原子操作,它分为给返回值赋值和RET指令两步。而defer语句执行的时机就在返回值赋值操作后,RET指令执行前
面试题
func calc(index string, a, b int) int {
ret := a + b
fmt.Println(index, a, b, ret)
return ret
}
内置函数介绍
close 主要用来关闭channel
len 用来求长度,比如string、array、slice、map、channel
new 用来分配内存,主要用来分配值类型,比如int、struct。返回的是指针
make 用来分配内存,主要用来分配引用类型,比如chan、map、slice
append 用来追加元素到数组、slice中
panic和recover 用来做错误处理
panic/recover
目前(Go1.12)是没有异常机制,但是使用panic/recover模式来处理错误。 panic可以在任何地方引发,但recover只有在defer调用的函数中有效
func funcA() {
fmt.Println("func A")
}
func funcB() {
panic("panic in B")
}
func funcC() {
fmt.Println("func C")
}
func main() {
funcA()
funcB()
funcC()
}
程序运行期间funcB中引发了panic导致程序崩溃,异常退出了。这个时候我们就可以通过recover将程序恢复回来
注意:
recover()必须搭配defer使用。
defer一定要在可能引发panic的语句之前定义。
实战
后序详细介绍:http://oie.fliggy.top/(目前只适用于电脑端)
技术栈:
后端:Python+Go(Mysql+redis+MVC+三层架构+swagge+Zip日志库+gin框架+Grom)
这次就先讲到这里,如果想要了解更多的golang语言内容一键三连后序持续更新!
