
正文字数:8411 阅读时长:15分钟
本文整理自中国电信研究院新技术所机器视觉标准与应用研究部主任张园在LiveVideoStack做的线上分享。她详细介绍了VCM、DCM等标准组织机器视觉编码标准化工作最新进展、技术创新思路。
文 / 张园
整理 / LiveVideoStack
各位LVS的小伙伴大家好,非常感谢大家用宝贵的晚上时间,来听我跟大家分享机器视觉编码标准和技术的最新进展。类似的主题,我在今年LVS的4月上海站上讲过一次,根据当场收集到的意见,今天会把一些主要内容再做一次介绍。还因为4月份开了VCM会议,也会把最新的进展跟大家分享。欢迎大家后续多多交流和参与我们的工作。

我简单介绍一下背景。首先,现在其实物物通信已经逐渐在超越和取代人和人之间的通信,机器视觉编码的目标是,就是让机器拥有人类感知视觉信号的能力,代替人类大脑,作为机器大脑来服务于整个机器系统。根据统计数据,视觉是占据了人类所有感官数据摄入的87%。神经网络各方面的研究,包括脑机的研究,都是从视觉作为切入的,在机器的层面,视觉也是一个最重要的信息来源,所以我们把它作为一个首先要攻克的目标。
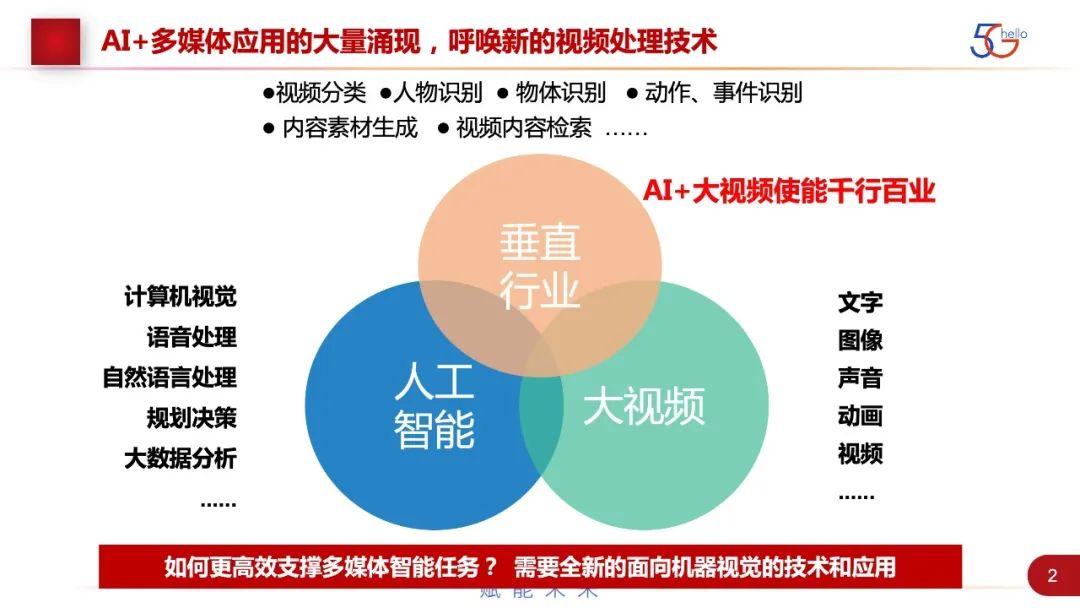
随着5G的发展,人工智能学习网络、深度学习和机器学习的发展,各种数据来源,包括文字、图像、声音、动画、视频等数据类型,现在都已经有了神经网络的处理方式,我们可以做CV、NLP的处理,语音的处理,以及基于数据挖掘、大数据分析、规划决策等的处理。这一系列智能任务,即识别、检测、分类、跟踪等都可以通过神经网络的方式来实现。传统的是采集视频,对视频进行压缩处理,现在加上神经网络,就非常自然地把视频这个独立的技术与垂直行业的应用,包括工业、车路、自动驾驶这些领域就天然结合起来。在新的发展情况下,要支持多媒体智能分析的任务,就需要面向机器视觉新的技术和应用。
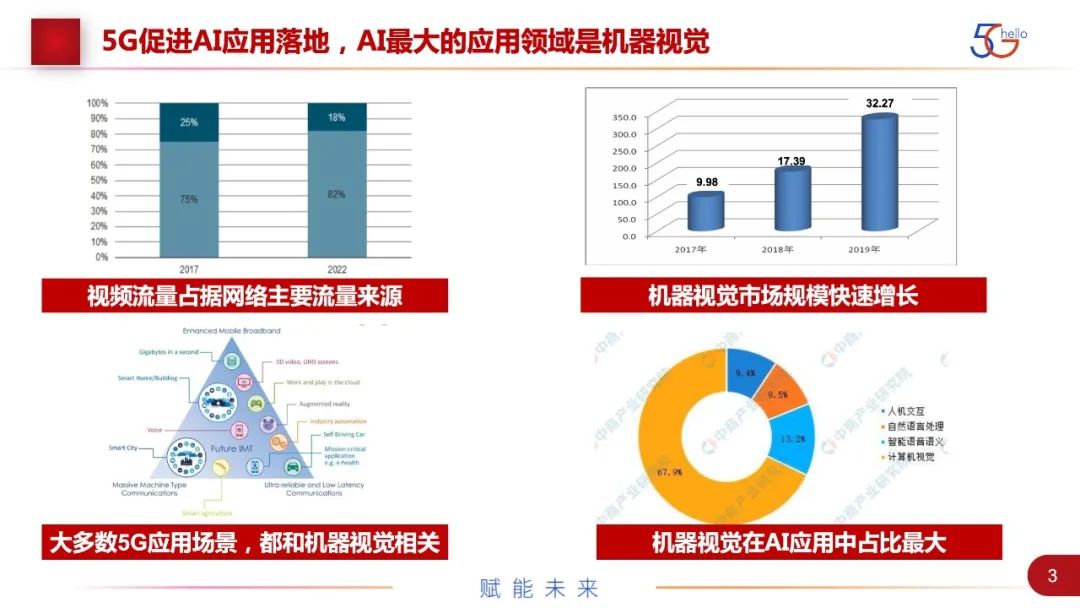
这里是一些简单的统计数据,首先在整个网络流量里,视频大概占了80%,这里面有一半或一半以上是服务于机器或各种算法分析。虽然人们观看视频网站也是一大来源,但现在视频走向两条分支:一条是人类娱乐,一条是机器的智能分析算法。整个机器视觉的市场规模也在快速增长,现在也是一个风口、投资的重点领域。著名的5G三角形和5.5G六边形里面的主要应用都是跟机器视觉密切相关的,这里有智慧城市、智能家居、智慧楼宇、自动驾驶、工业自动化等。机器视觉现在非常广泛地应用在各个领域,是未来5.5G、6G流量的重要来源。整个CV算法在AI中,不管是成熟度、投融资比数、实际应用的占比,现在都是最大的一部分。
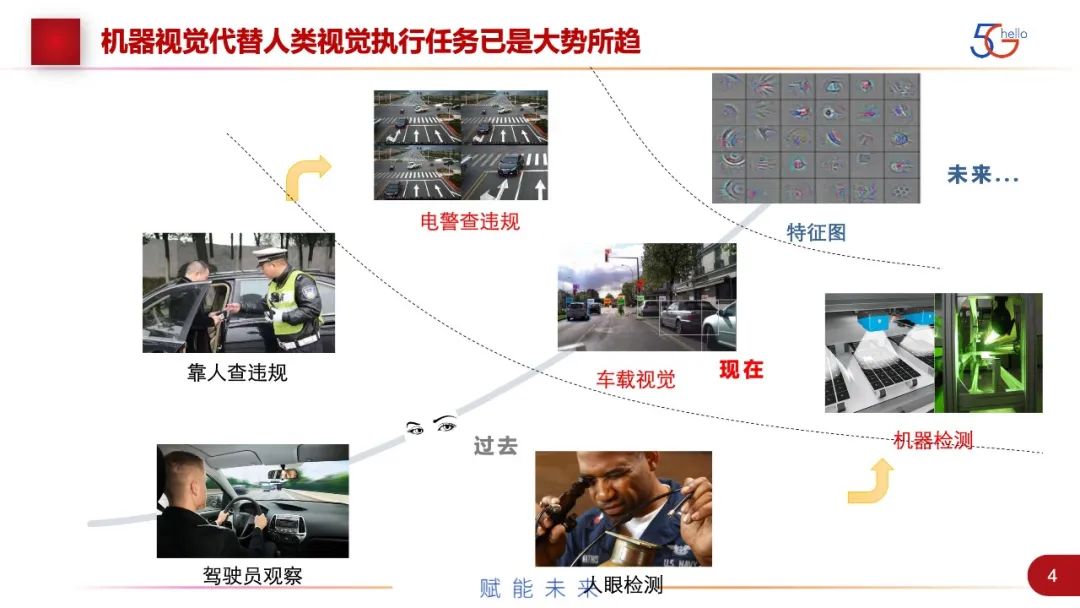
从这个背景,我们可以分析出,我们用机器视觉算法来代替人工处理任务已经是大势所趋。在过去监控的场景,如道路查违规、驾驶的场景,以及检测的场景,是以人为主。现在是机器逐渐在占据主导。电子眼已经广泛地使用,车载视觉都是L2、L3级别的自动驾驶,以及机器质量检测、故障检测,这些算法都非常普遍。
这里还是基于人眼,把图像用CMOS、CCD采集,再重建成像素,然后用机器算法以给人看的像素来分析。其实人类要看单个像素,但机器需要的只是里面的特征值,比如有没有故障这样一个特征状态,只要相关特征有了就可以,就可以推测出我们给人的这种方法来给机器做任务分析,它其实在存储和传输方面是有冗余的。我们从逻辑层面做了一个假设,可以用一种特征图只给机器看,用特征图的方式就避免了人所需要的色彩、饱和度这些信息,就可以满足物物通信视觉的需求,就降低带宽、时延等这些要求。
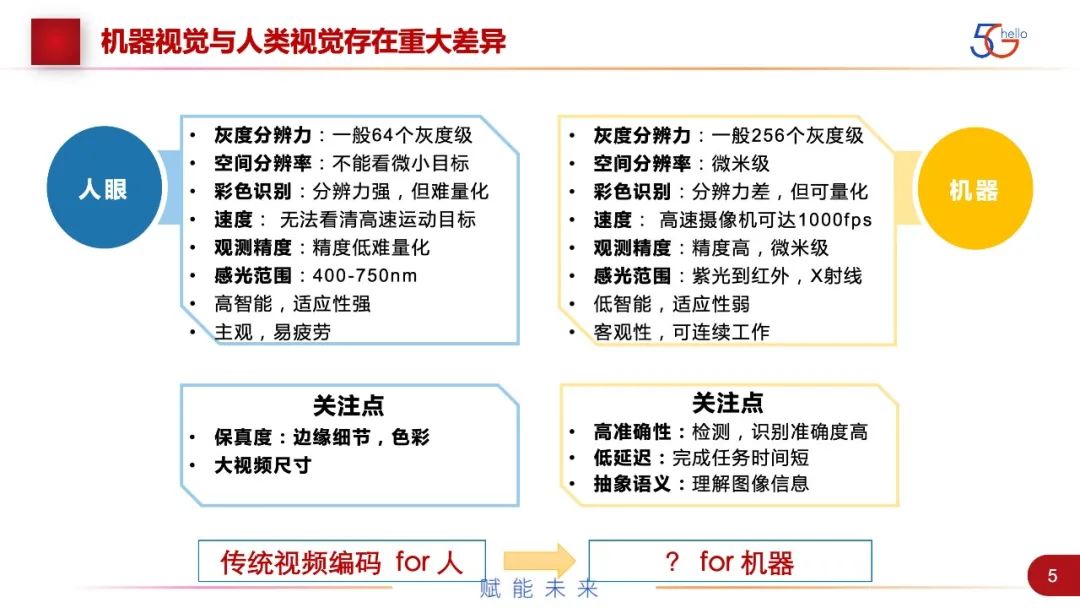
让我们的想法成为可能,最主要还是机器视觉和人类视觉有本质上的差异。这里进行了一些列举。在主要的纬度,机器视觉比人类视觉更好,这个比较好理解,譬如,灰度分辨力、空间分辨力、色彩的分辨、速度、精度等,都是比人类强。这里最主要的是速度,人只能看到25~30帧每秒,而机器可以抓到1000~2000帧每秒。但是人脑在智能方面非常好,人脑在V1、V2、V3等大脑结构中不同的处理,把接收到的光电信号,自动进行了压缩、分析和合成。但是机器在这方面,比如变换一个角度,或者天气环境的变化,它可能有误识别,机器在这方面还有很长的路要走。
总结一下,人眼和机器算法看的是不同的东西。人看的是边缘、细节,对大尺度的视频要求视频保真。机器就是关注任务的完成,要的是语义级信息来做检测、识别等,之外还有时延的要求,机器需要语义信息,不需要人眼看到的。基于这些差别,我们可以得出一个结论,传统的视频编码与无失真或无限接近去还原视频的编码方法,其实是不适用于机器的。

对于视频编码,这里简单介绍一下。我们做视频编码最主要还是因为带宽不够。压缩方法基本是时间、空间的去冗余,或者针对人眼特性的去冗余。但是到机器领域,冗余的维度增加了,我们针对机器的任务,比如检测、分割、识别、跟踪等,能够性能不下降地完成,这就是无损,与传统的视频压缩无损的定义是不同的。在增加的维度上,我们就有了更多的压缩手段。
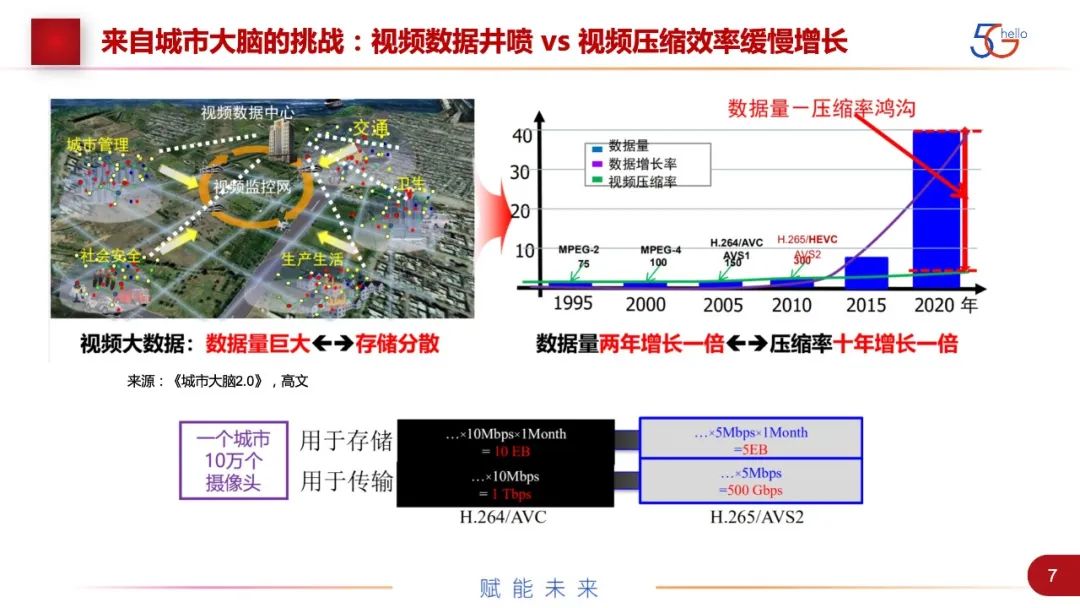
图中是现在网络上的数据量曲线,包括了一个对比,一代代视频编解码压缩率提升的对比,是呈线性增长,而数据量是指数增长的,数据量和压缩率之间存在巨大鸿沟。随着现在智能化或数字化的发展,鸿沟会越来越大。我们对于视频压缩算法和性能的需求还是很高的,不会随着光纤或5G的建设而降低。
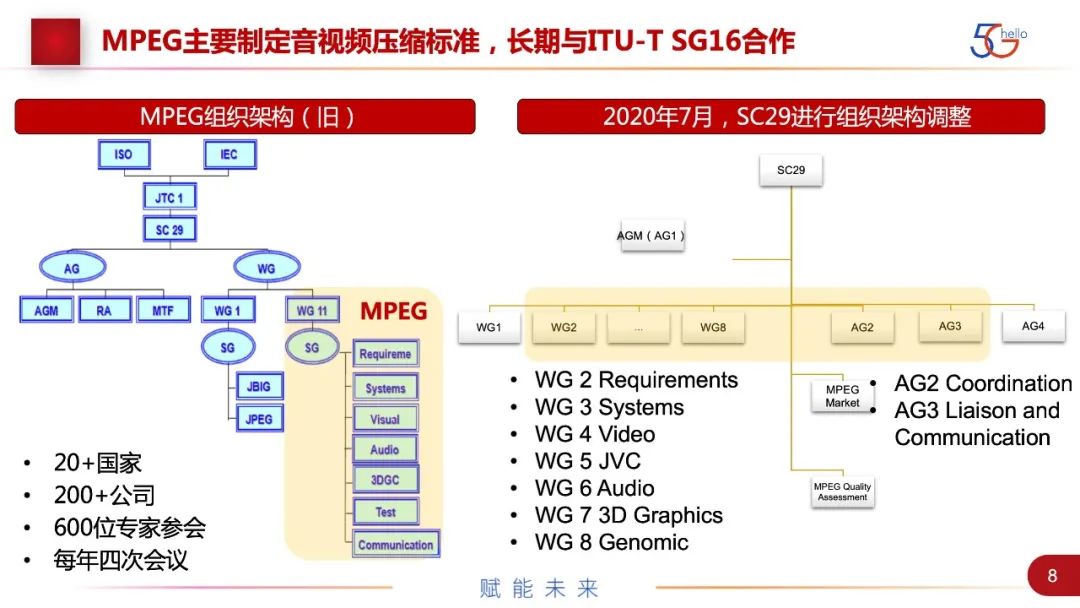
现在制定音视频压缩标准的主要的还是MPEG,32年前建立,现在经历了一系列的改革。以前在ISO、IEC的JTC1、SC29下面两个工作组是JPEG和MPEG,是早稻田大学的一对同学创立的,去年进行了改组。第一组还是JPEG,MPEG所有的组拆成了7个组,包括需求、系统、视频、JVC、音频、3D和基因。工作还是在继续,整个标准组有巨大的产业影响力、产业化能力,所以,整个标准组一直吸引很多方的参与,也产出了一系列AVC、HEVC等高价值的标准。现在也有了一些竞争标准组织,比如AOM、MPAI。这也从侧面说明这一市场价值非常大。

说到机器视觉编码(VCM),是从2014年开始就在策划和推动,中间也经历了一系列变化,于2019年成功。当时的逻辑是,因为我们有很多监控、工业场景,要大量基于视频来做分析,这与广电场景的信息处理、编码和信息使用上存在巨大差异,其实我们用H.264、H.265的编码的效率不够。基于产业需要,当时也做了学术界的调研,得出结论在专门针对机器的编解码方面有很大空间。支撑证据有意向编码结合对象的属性进行编码和生成。和直接在压缩域做任务,也可以重建,基于学术调研和产业需求,认为这件事是存在可行性的。我们也经过了一系列推广,从最开始提出面向智能安防场景。因为安防场景的背景基本上都是固定的,只有不多的前景变化,针对安防场景特定的压缩编码,效率可能提高到90%以上。当时MPEG组织接受了,但这件事没有推下去。后来我们分析,因为当年整个AI技术发展受限,5G网络环境也没有,虽然成功了,但没能把这件事做完。2017年我们又提了一次,是基于视频内容和语义特征进行编码,因为提到了应用层,没办法穷举,最后没被接受。一直到2019年,与美国GTI(芯片独角兽公司)联合,提出了面向机器视觉和人机混合视觉的压缩编码概念和框架,得到广泛认可,成立了机器视觉编码专家组。

在2019年7月的MPEG会议上,我们提出了要研究下一代视频编解码标准。当时的逻辑是,H.266快做完了,接下来朝什么方向走。我们当时的判断是,一条路向着4K、8K、沉浸式走,不断追求压缩率和更高的清晰度,是面向人类视觉的。另外一条路面向机器,不一定要还原视频,但要做到任务的无损或者任务性能的可接受范围内的下降。这里还包括了人机混合视觉,是指针对人需要做验证或取证的场景,还是要做重建,但质量要求不同,以及优先级不同,或者有额外码流。结合AI深度学习特征的提取和编码,预期会成为未来5G、6G的主要流量来源。受到业界的广泛支持,时任MPEG的主席Leonardo也非常支持,包括需求组和视频组主席也参与了这个组的工作。

机器视觉编码的定义是研究以智能应用为目标的压缩编码技术。保障压缩率,要节省带宽,和智能任务,要做到任务的无损。目标是定义一种从视频中提取的压缩的视频或特征码流。这里说的比较抽象,其实就是bitstream,可服务于多种机器任务,同时保障高压缩效率和机器智能任务性能。虽然名称是机器视觉编码,但其实是服务于机器视觉和人机混合视觉两种场景应用。
具体到场景,全球产业界识别的六大场景,其中视频监控和智慧城市是有从属关系的,还有智慧交通、智慧工业、智能制播和消费电子。智能制播比较特殊,还是人在看视频,但因为国内有审核的需要,国外有视频分级的需要,所以可能要在不完全解码的情况下,要做任务。我们具体的做法是针对六大场景。除了六大场景,还有十几个待细化场景,暂时不是主流。
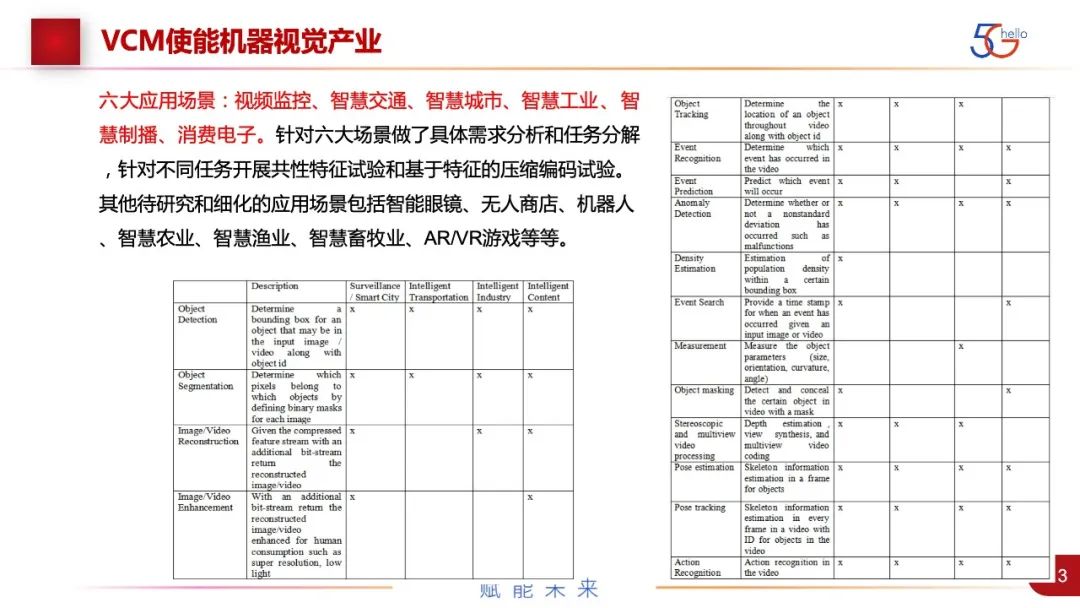
针对六大场景对所有的任务进行了分析和分解。图中列出了所有的任务。最主要的就是检测、分割,这两个任务是人机混合的,包括了视频重建和增强。比如,针对驾驶场景比较多的、根据事件的识别、异常的检测、人流密度的分析,针对工业场景的测量,针对隐私的做mask,还有多视角的视频。我们的做法是把所有任务都列出来,根据任务给定数据集,在数据集上做新数据的压缩和编码。然后跟现有最好的情况VVC同样的算法进行对比,来看机器视觉编码是不是比现有的用视频来做的方法更优。
除了六大场景以外,还有一些场景有待细化,包括智能眼镜、无人商店、机器人、智慧农业、智慧渔业、智慧畜牧业、AR/VR、游戏等。

VCM组成立之后召开了7次正式会议,产业界和学术界的参与度比较高。各个领域,包括芯片、算法和应用的企业都有参与。开始的研究还是聚集在应用的场景的需求和架构的定义,后面就逐渐在定anchor、用哪些matrix。在技术方面,最先提出的是CDVA的扩展。CDVA算是第一个针对特征的压缩标准,是一个有限智能,只能针对做这样的任务,并不能针对所有的机器任务。后来逐渐有专家提出提取特征、对象编码、端到端神经网络视频压缩等方法。现在逐渐形成了多种的技术路线。
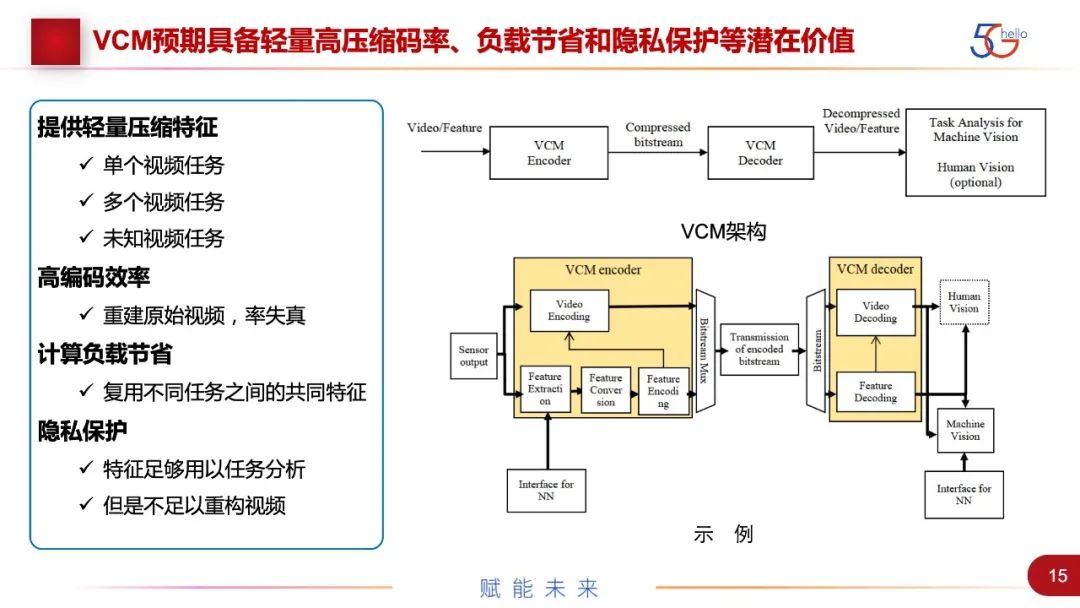
图中给出了整个VCM的架构。上面是非常通用的架构,视频或者特征进来,进入VCM的编码器,进行压缩编码,然后传输,或者存储到解码端,解码出来的视频或者特征,一方面服务于机器智能任务,一方面是可选的,重建视频给人观看。下面是一个示例,它包括了现有的技术方案。同样也是从视频或特征进来,一条路走特征编码,一条路走视频编码,比如对象编码就包含在视频编码里。如果走特征编码路线,先是特征提取,之后有两个选项。一个是根据特征来统计的压缩方法。另一个是将特征转换成图像,然后再进行图像压缩编码。可以做两者结合,取得性能最佳。
解码端就是一个逆过程,服务于机器视觉和人机混合的视觉。整个VCM预取可达到的性能的提升,主要分了几方面。第一点是,提供轻量压缩特征,降低带宽,针对单个任务、多个任务和未知任务有不同方案。第二点,不是主要的,但要比现有的VVC、H.266编码的效率更高。第三点是,计算负载节省,因为我们是把整个端到端的AI算法一部分前移在采集端,在编码端就完成了一部分AI算法,所以可以根据实际应用情况,调整前端、云端或终端的计算资源,并据此进行分配。比如一个采集端,对应上万个客户端,这种情况就比较适合前移,来进行计算负载的节省。第四点,是在过程中逐渐发现的一点,就是隐私保护。现在涉及人脸或者涉及个人身份的图像或视频数据,都是非常敏感的,无论是国内还是国际上。如果用特征的方法来处理,如果无法重建人脸或视频,或者不公开特征提取的方法,也不能恢复,但任务还是能够执行。另外,如果最后得出的是统计数据,结果不定位到个人的话,就可以规避隐私保护的问题。
具体的做法是,我们用了一些数据集,有些是公共数据集,也有自己采集、贡献的数据集。基于这些数据集,先做出anchor,现有最佳性能,再基于其他数据集,进行对比。数据集选取的原则是,最好是没有经过压缩的、可以下载、有明确的授权许可的。
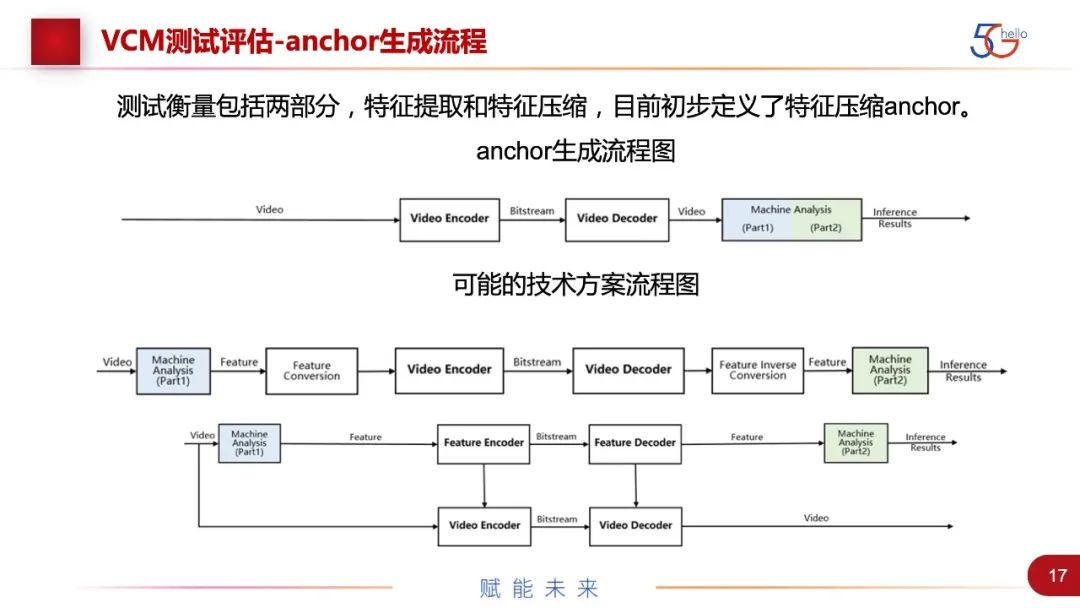
我们前期也做了大量贡献性质的工作,就是anchor的生成。基于我们现有的最佳方法,H.266的方法经过压缩编码,然后做机器任务,出来的结果。根据任务的不同,用压缩率和任务性能两个指标来看性能。
下面的示例包括VCM可能的技术方案架构。上面一条是纯走特征压缩的方法。还有一个是视频加特征的方法。这里需要注意的是,我们把上面的机器分析拆成了两块,一部分功能前置了。
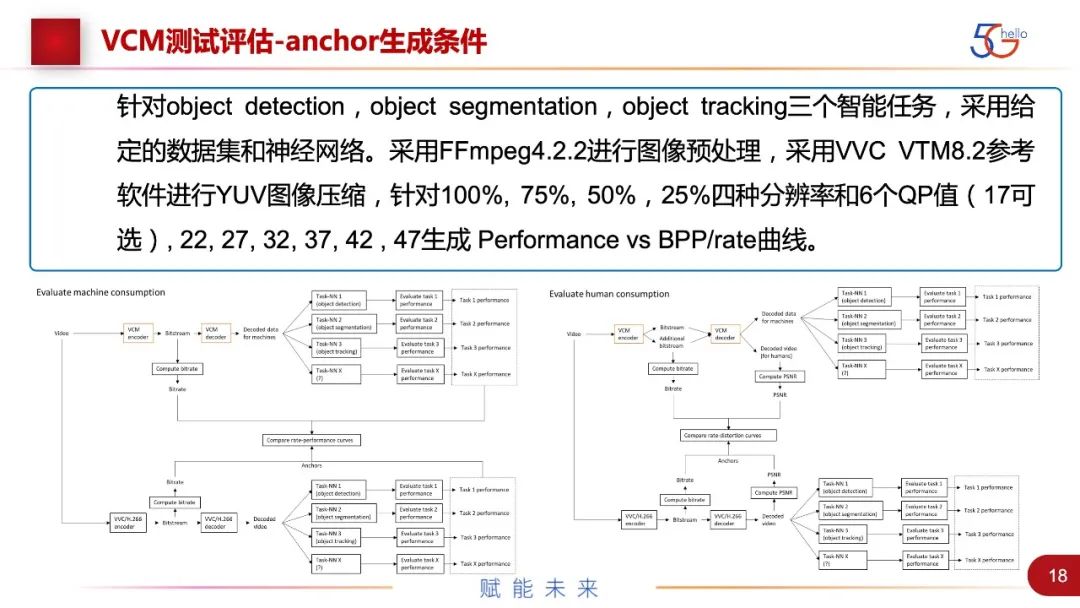
具体的anchor生成,针对了三个最通用的智能任务:detection、segmentation、tracking,我们用给定的数据集和神经网络,用现有的FFmpeg来进行图像的预处理,用VVC里面最新的VTM8.2(也在不断根据最新的VTM发展进行更新),来进行图像的压缩。我们定了4种分辨率和6个QP值,生成压缩率和性能的曲线。下面是两个性能评估的框架对比图。一个是纯机器视觉的,下面的路线是现有的方法,把传输这一侧的bitstream拿出来,再把任务这一侧的performance拿出来,画一个RD-curve。上面的路线是VCM的codec,就是各个提案方提出的算法,将bitstream和performance进行对比。另外一个是针对人机混合的,要增加PSNR进行对比。
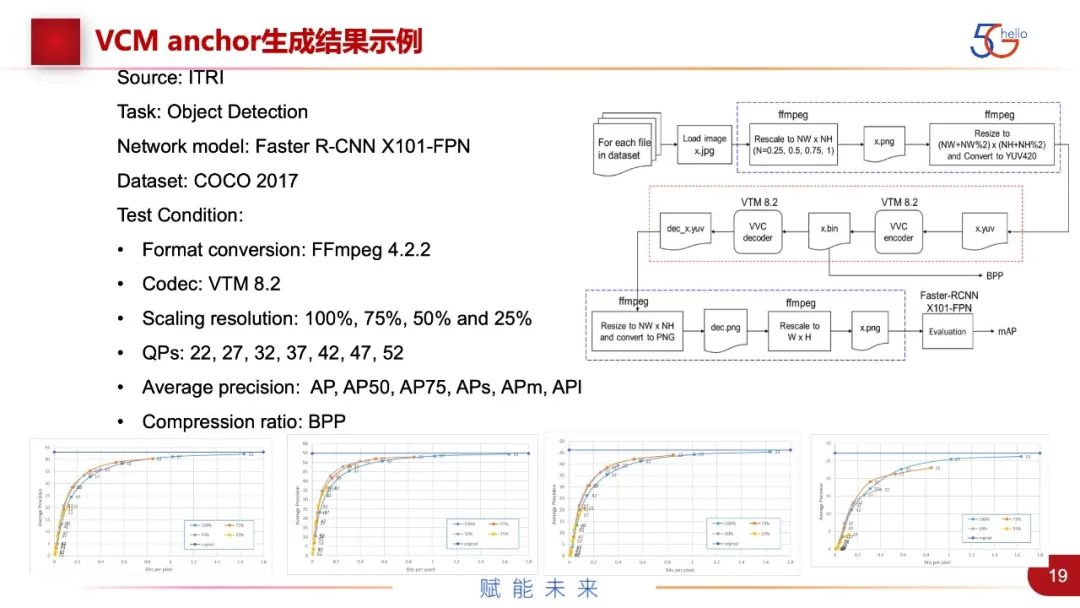
图中是一个anchor生成的例子,针对Object Detection、Faster R-CNN,用COCO数据集做出来的anchor。下的直线是没有经过压缩的数据,其他曲线是在不同的resolution和不同的QP下做的anchor,把VCM与这个进行对比,看性能是否可以支撑一个新的标准,以及产生相应的商业价值。右图是生成anchor的pipeline,也是出于标准化工作的考虑,整个组都会follow一样的程序来进行评估。

整个VCM标准组现在还是处于探索性实验阶段,还没有开始正式的标准化工作。过去完成的工作包括确定需求、几大任务、公开的数据集,也做了8种anchor,发布了正式的证据征集,于今年1月正式发布。在4月刚开了一次MPEG会议,对所有征集到的证据进行了评估。这次征集证据还比较成功,也形成了几条不同的技术路线,下面具体介绍一下。
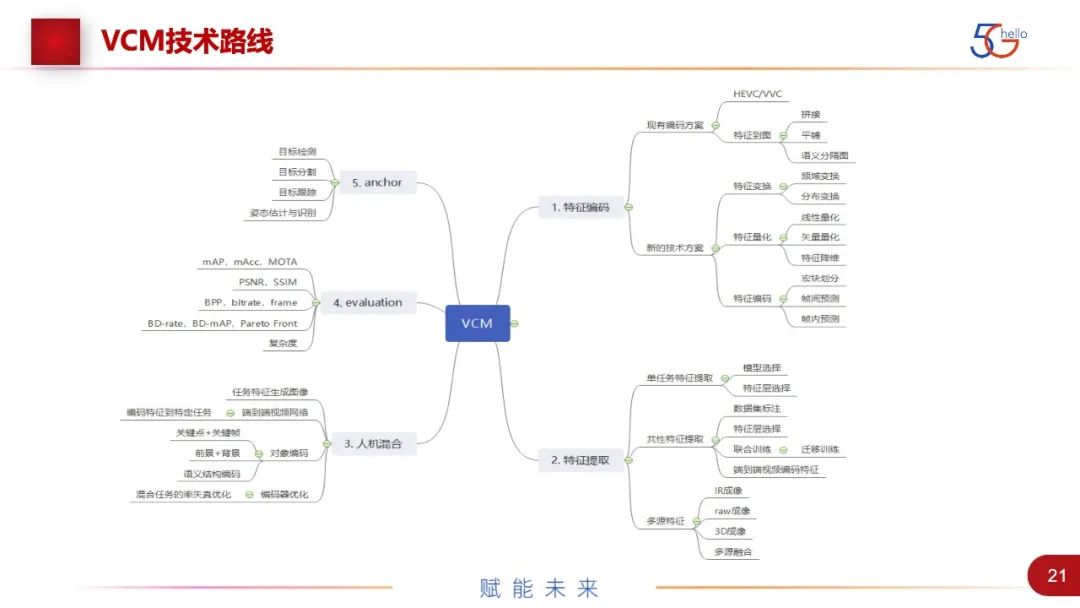
图中是整个VCM组的技术路线,我个人总结可以分成5块:特征编码、特征提取、人机混合、跟标准组相关的评估,以及anchor的工作。特征编码还可以分得比较细。其实,视频编码经过30多年的发展,已经发展到了非常细节的程度,每一个小的变化都会有不同的方法和尝试,特征集是刚开始的工作,里面做的事情会非常多。一方面是现有的编解码方案,可以把它变成HEVC、VVC等,也可以对图进行不同操作,如何做crop等,也会对结果有影响。另一方面是新的技术方案,包括有特征变换,就是对统计特性进行视频域的分布的变换。最主要的是特征量化,这是特有的一种性能,相比视频,它对量化更不敏感。标准组尝试了很多的量化方法,如线性量化、矢量量化和特征降维。第三个是特征编码,包括宏块划分,特征也可以类比图像,有不同通道的预测以及特征的帧间预测。
特征提取方面,我们可以对单任务的特征提取,就是选择哪一种模型,对它的哪一层进行提取,然后可以达到数据量的最小,对任务的影响可以接受。这一块还包括数据集的选择,共性特征要支持多任务才认为是共性的,所以数据集也要进行标注,对损失函数要进行联合优化、联合训练或迁移训练等。还有多源特征,这里可能包括不同的数据源,有IR、弱数据、3D和多源融合等。这里值得一提的是弱成像,因为ISP主要还是在做一些针对人眼的任务,现在有论文表示可以基于这种弱数据,来做机器智能任务,不用ISP处理就可完成,在给定的数据集上达到比较好的性能。这也可以是未来研究方向,以及真正的产业应用。
人机混合方面,主要有两条路。一条是端到端的神经网络编码。MPEG还有一个组DNNVC,它在用神经网络在做针对人眼的压缩编码,也是以端到端神经网络为主要解决方案,性能的提升比较多,但可能调整的空间不是很大。另外一条路是特征的逆向工程。还有对象编码的方法比较特殊,可以是根据语义结构进行编码,就是穷举所有的对象,也可以是前背景的分离,可以使关键点加上视频、关键帧等。
还有如何进行测试和评估的方法,进行了一系列matrix的定义,有人在做联合乘法优化等。现在我们基本上还是根据任务,进行RD-curve,BD-mAP的曲线,算出最后结果值,以这个值来标定,到底是否比现在的场景更优。最后就是anchor的工作。
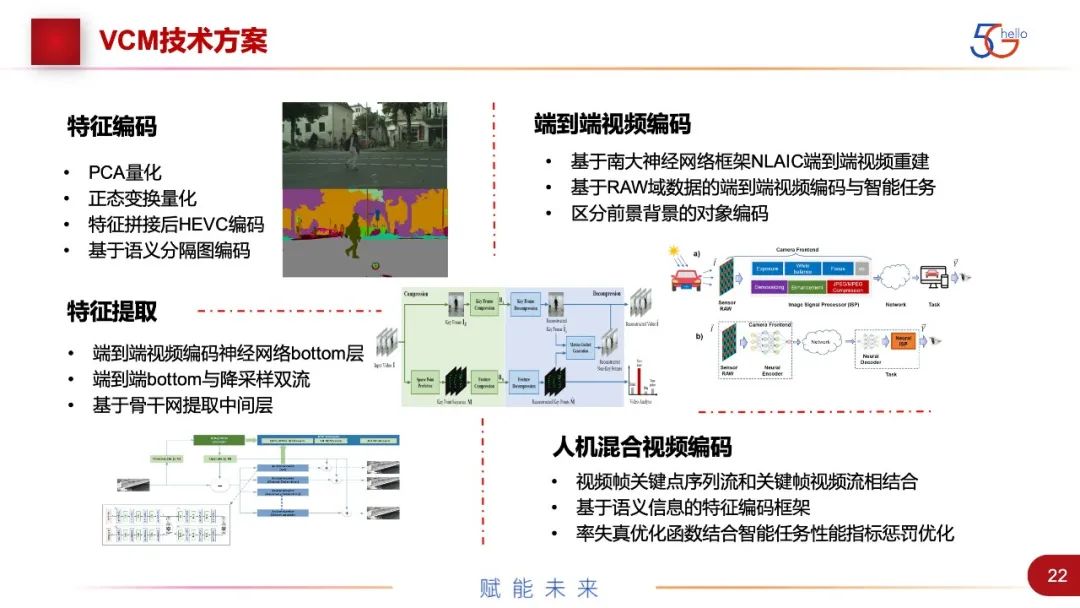
图中是4个主要技术方案的总结。特征编码包括PCA量化、正态变换量化、特征拼接后HEVC编码,以及基于语义分割图编码。语义分割图是一种非常特殊的特征,与图像是强相关的,在一个领域内的色度值都是一样的,有一些比较特殊的压缩编码方法。
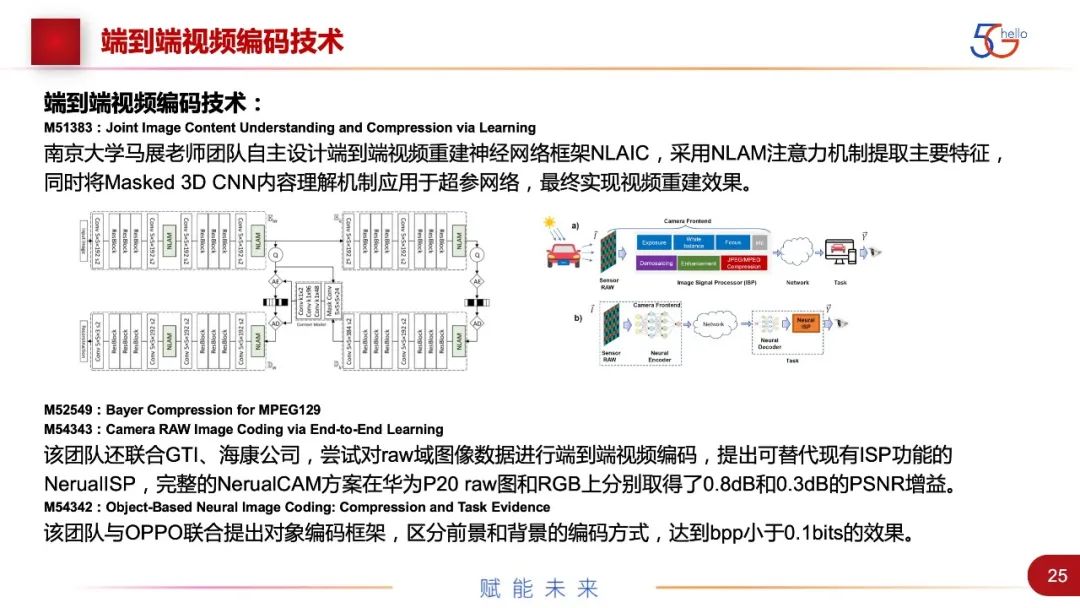
第二个是端到端视频编码,它的性能比较好,基于compressAI的模型有相应的结果,做了一些优化调整。比如南大提了网络框架,也提升了一些性能。还有基于RAW域数据的端到端压缩编码,主要是性能不下降,也可以节省出ISP的时延。还有基于前景和背景的对象编码。
第三个是特征提取,就是找共性特征,将神经网络从中间打开,把map取出来,对矢量进行编码。最关键的是用什么样的骨干网,选取哪一层。现在选stem层较多,也有把stage1~stage5全部加起来,但是这样的数据量就比较大。这是因为特征比图像的数据量要大很多,但是特征是新的领域,可以做压缩的手段也非常多,虽然现在的性能不是最好,但未来可能会有非常多的优化方法。
第四个是人机混合视频编码,包括了视频帧关键点序列流和关键帧视频流相结合、基于语义信息的特征编码框架,以及率失真优化函数结合智能任务性能优化等。

图中列出了一些特征编码技术的细节。基于ResNet网络模型,提取C4层输出特征,在COCO数据集下,BD>=4的特征量化对于目标检测和目标分割性能无影响,BD=3时,性能有一定下降。南洋理工大学对VGGNet和ResNet进行特征的拼接和平铺,可以在C5层得到比JPEG高5~10倍的压缩率。还有PCA的量化,和对特征做正态分布变换,对通道做归一化操作。得到的结果,有的可以做得性能的无损,有的可能有性能的下降。

针对语义分割图有一些特殊的压缩编码,语义分割图在驾驶场景中有非常多的应用。北大用四叉树的方法,爱立信用内容编码的方法,GTI用划分不同宏块的方法,他们进行了一系列尝试。还有端到端神经网络的编码方法,性能很好,比现有方法有超过20%~30%的性能提升。
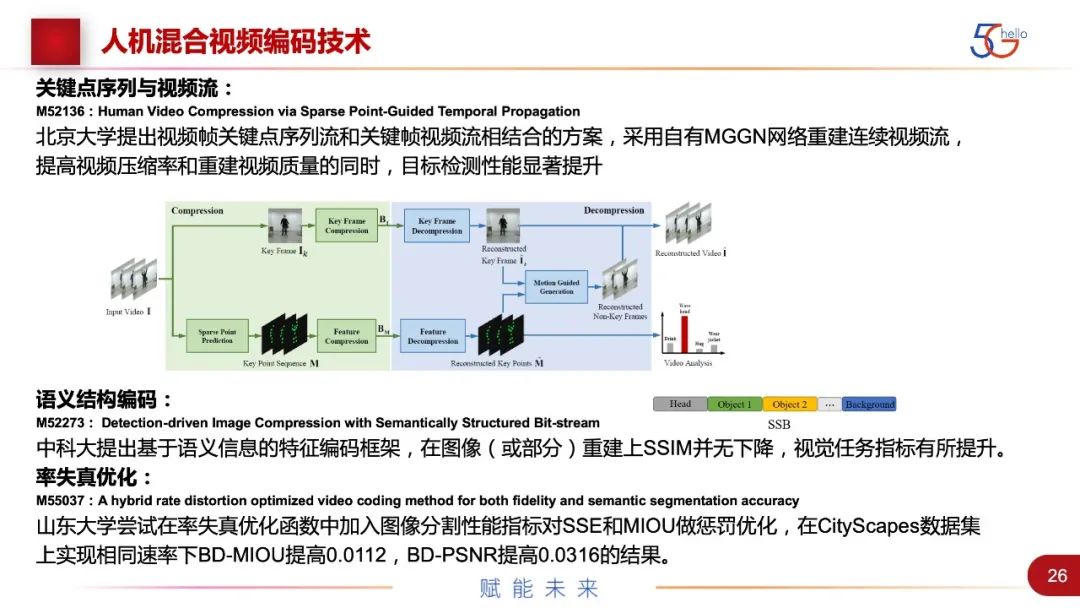
北大提出的视频帧关键点序列流和关键帧视频流相结合,采用自有网络重建连续视频流,在提高压缩率和视频质量的同时,目标检测性能也有显著提升。中科大提出基于语义信息的特征编码框架,之前提了对象编码的概念,就是把所有的对象都进行表征,前背景进行分离,在4月份的会议上进行了一定的优化,能实现任务性能20%的提升。山东大学尝试在率失真优化函数中加入图像分割性能指标,同时对SSE和MIOU做优化,最后实现在相同速率下的性能提升。
关于特征提取技术,一个是对端到端神经网络的bottom层提出来,另外一个是针对骨干网,把stem层提出来,能够达到最佳压缩率。
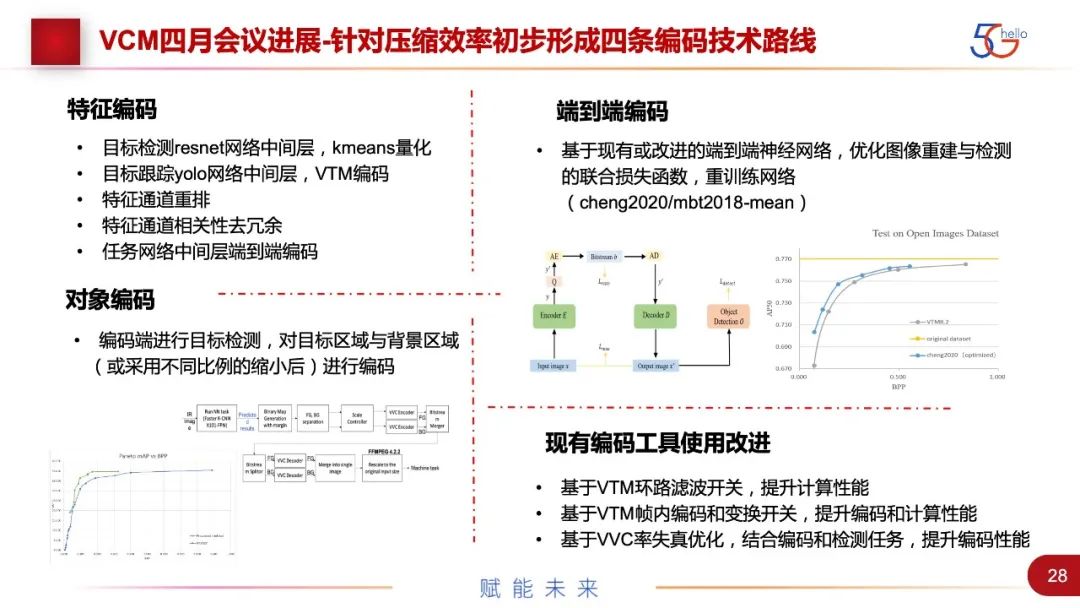
这里再讲一下,4月份刚结束的会议的最新进展。今年1月我们发表了CFE,分了几个步骤,针对整个编码有几种预期的性能优势,比如压缩效率的提升、隐私的保护、计算复杂的节省。针对压缩效率的提升总结出四条技术路线。
一个是特征编码,是我们组最开始提出的设想,会用特征代替视频,未来的空间很大,但目前它的性能还不是特别好。组内得到了一些方法,如目标检测ResNet网络中间层和kmeans量化、目标跟踪yolo网络中间层、特征通道重排、特征通道相关性去冗余,以及任务网络中间层的编码。

端到端编码是目前性能是最好的,这次被接受的两个证据是,基于cheng2020/mbt2018这两个网络进行了重训练,做了端到端的优化和改进,也优化了图像重建和检测的损失函数,性能提升有20%~30%。浙江大学基于cheng2020端到端神经网络,比VTM节省了BD-Rate 22.8%的提升。阿里和香港城市大学基于mbt2018端到端神经网络,比VVC提升了20%~30%。
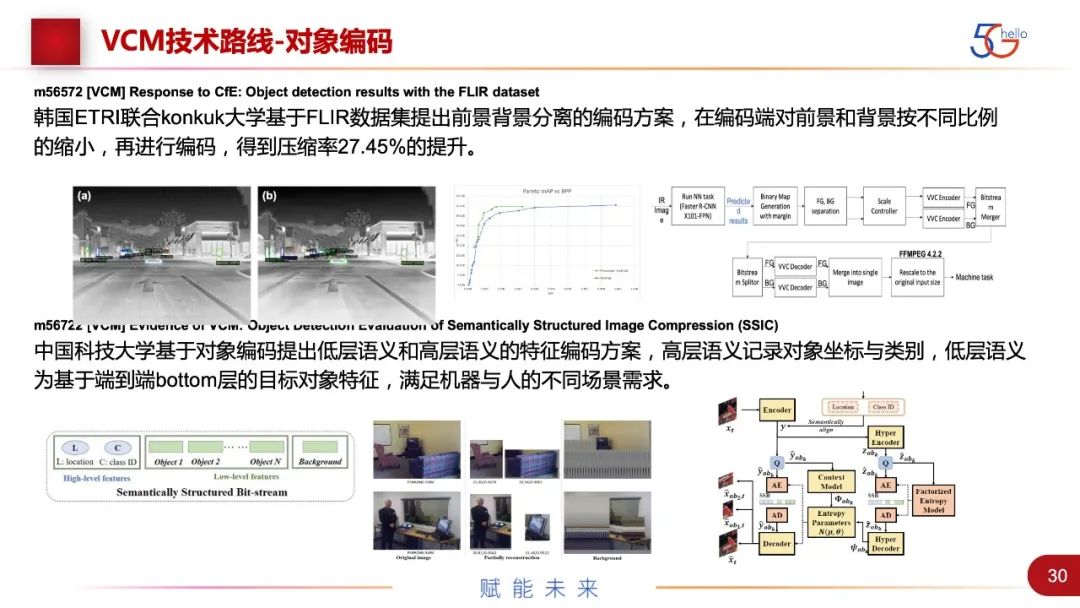
韩国和国内都有人提出对象编码,就是编码端进行目标检测,对目标区域和背景区域做分离后再编码。韩国ETRI基于FLIR数据集提出前背景分离,对前景和背景按照不同比例缩小再编码,压缩率有27%的提升。中国科技大学提出低层语义和高层语义的特征编码,大概有20%的性能提升。
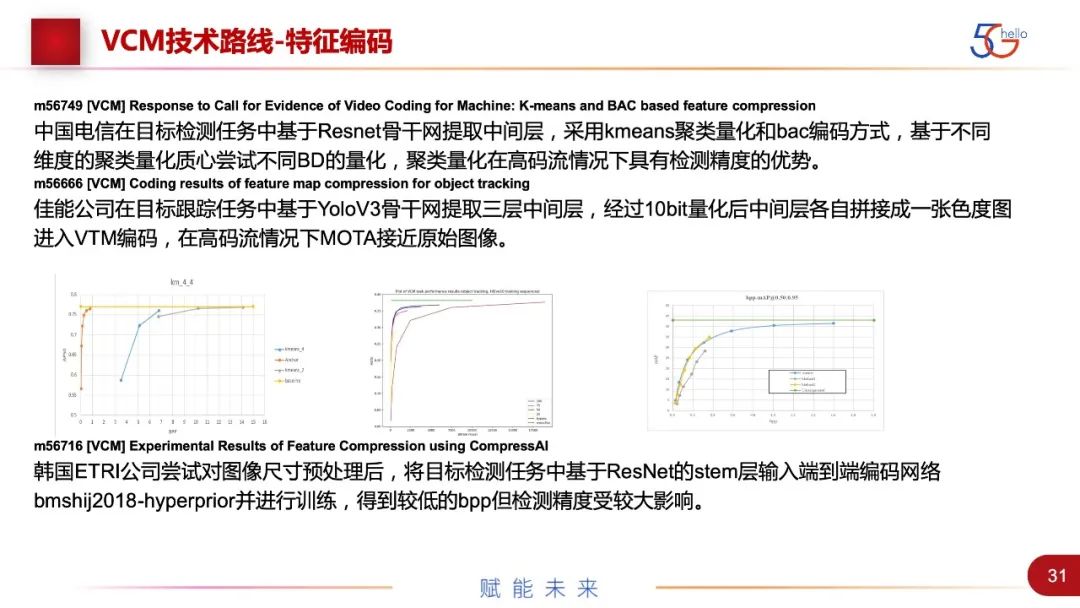
中国电信提出了在目标检测里,基于ResNet骨干网提取中间层,采用kmeans聚类和bac编码,基于不同维度的聚类量化质心尝试不同BD的量化,在高码流情况下具有检测精度的优势。还有佳能公司和ETRI公司都做了尝试,目前压缩性能还不是特别好。
最后是对现有编码工具的改进。VVC现在已经非常成熟,里面是分模块设计的。很多专家对其中很多模块进行了尝试,给出了一个详细的报告,譬如哪些模块关掉的情况下,计算性能是最好的。这也存在一种可能,就是VVC会给VCM出一个profile。
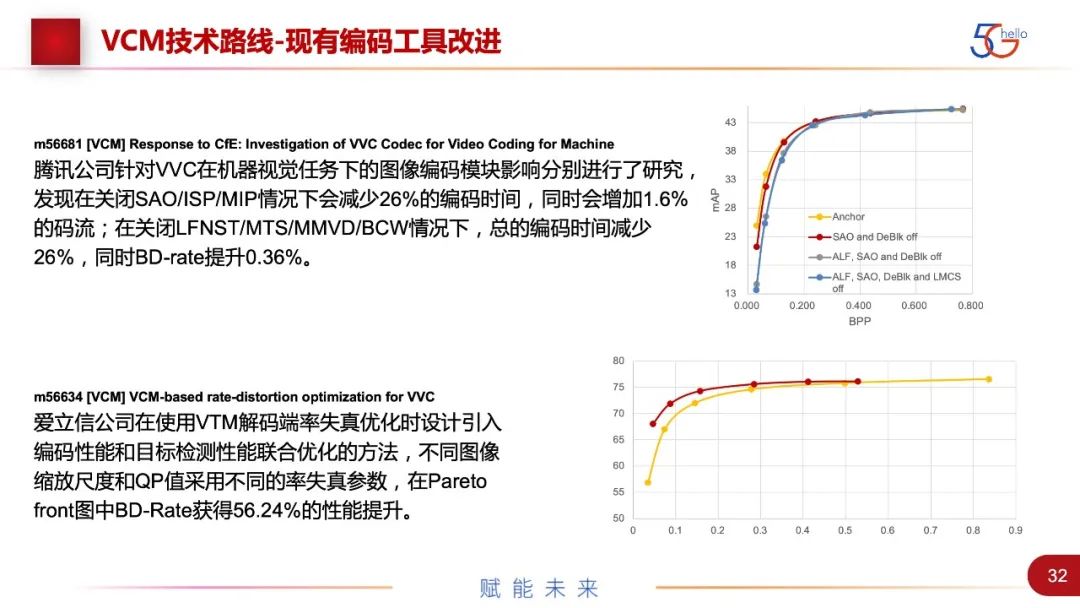
腾讯公司发现在关闭SAO/ISP/MIP模块的情况下,降低复杂度,减少26%的编码时间。爱立信也做了类似的工作,在使用VTM解码端率失真优化时,引入编码性能和目标检测性能联合优化的方法,对不同图像缩放尺度和QP值采用不同的率失真参数,可以获得56%的性能提升。这可能还无法实际使用,但对于研究工作很有帮助。
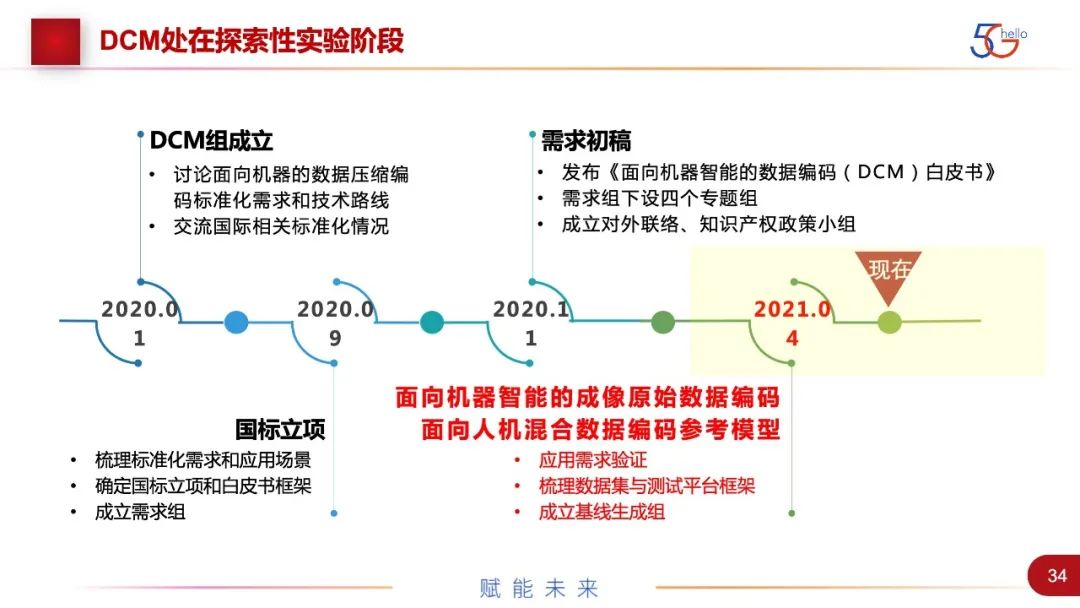
中国在这方面的工作也在快速进展。去年1月成立了面向机器智能的数据压缩编码标准组DCM。与国际VCM的区别是,除了视频,还增加了音频、点云等其他数据类型。但目前进展最快的可能还是视频图像方面,DCM与国际VCM的功能基本是重合的,并可以支撑国际标准组的工作。参与方会不同,以及聚焦到的应用场景会根据我国产业会有变化。国内进展更快,因为国际上政策法规的限制比较严格。到目前为止,DCM组举行了四次会议,期间还有一些小的讨论,梳理了技术文档、技术路线,做了相应的国标立项,包含面向机器视觉相关和人机混合视觉相关两种国际标准,发布了相应的白皮书。成立了7个专题组,非技术的有对外联络、知识产权小组。技术相关的有需求组、数据集组、测试组等。目前在开展相应的anchor工作、测试工作,也在征集技术相关的提案。
因为编解码的目标还是要服务于产业界,要能够产业化,所以这里列出了除了编解码以外,国际上应用相关的标准组织和产业组织,需要与他们联络和合作。目标是在整个过程中,我们可以得到市场的真实需求,以及来源于实际应用的数据集,等标准做好后,可以被应用组织直接采用。
谢谢大家!
讲师招募 LiveVideoStackCon 2021 北京站
LiveVideoStackCon 2021 北京站(9月3-4日)正在面向社会公开招募讲师,欢迎通过 speaker@livevideostack.com 提交个人及议题资料,无论你的公司大小,title高低,老鸟还是菜鸟,只要你的内容对技术人有帮助,其他都是次要的,我们将会在24小时内给予反馈。