大家好,我是老三,刷题刷烦了……
写篇文章缓一下,分享一下老八股:缓存击穿、缓存穿透、缓存雪崩。
在了解这三大问题之前,我们要理解,常用的分布式缓存Redis单机并发量能达到万级,常用的关系型数据库MySQL一般并发量是千级,他们支持的并发量可能差十倍,所以要尽可能把流量拦截在缓存层。
为什么呢?就像是大湖里多排点水,就可能把小河道冲垮,不知道你听过没——长江之水天上来,白洋淀里把不住。
缓存击穿
什么是缓存击穿
先从缓存击穿开始。
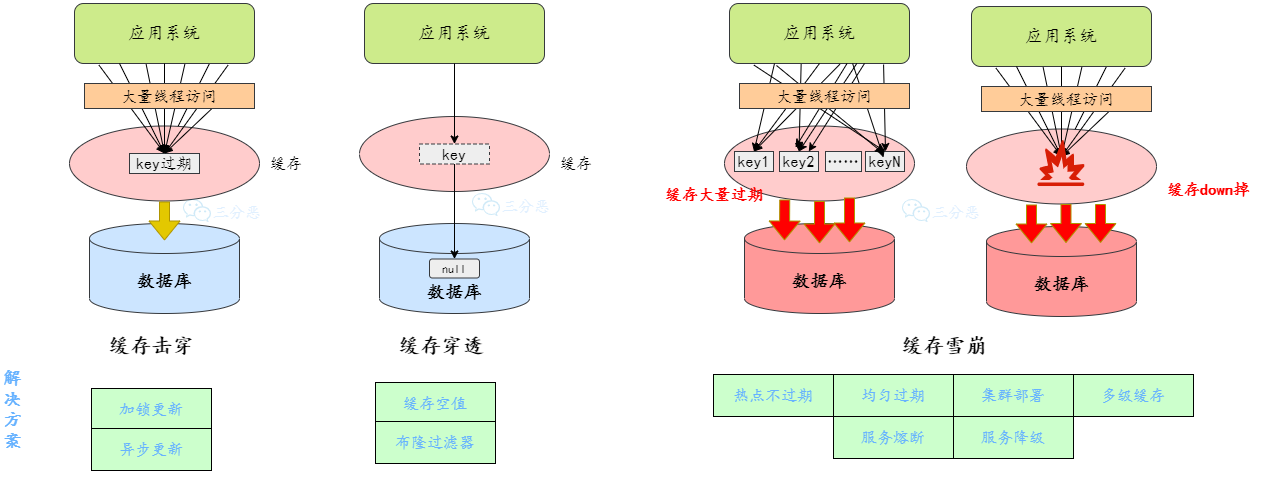
缓存击穿: 一个并发访问量比较大的key在某个时间过期,导致所有的请求直接打在DB上。
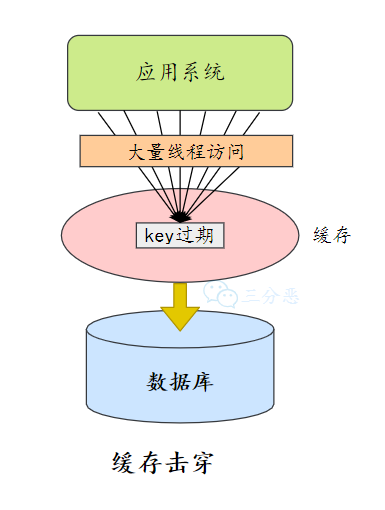
缓存击穿会增大数据库的负载,我们看看怎么缓解。
缓存击穿如何解决
加锁更新
查询缓存,发现缓存中不存在,加锁,让其它线程等待,只让一个线程去更新缓存。
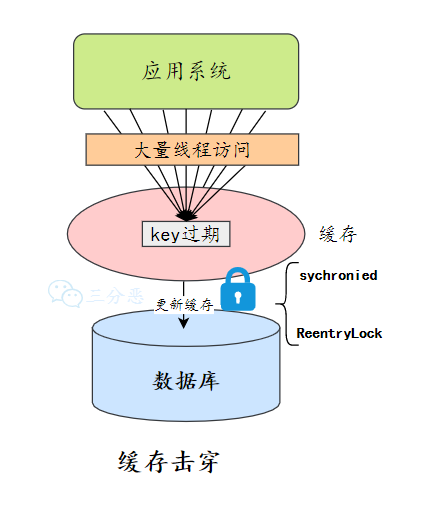
异步更新
还有一个可行的方案是把缓存设置永不过期。那缓存怎么更新呢?通过异步的方式去更新缓存。
比如后台设置一个守护线程定时更新缓存,但这种定时比较难以把握。
异步更新机制实际上更适合用于缓存预热。
缓存穿透
什么是缓存穿透
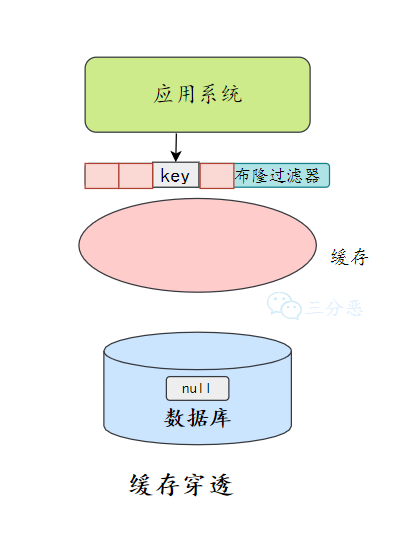
缓存穿透:缓存穿透指的查询缓存和数据库中都不存在的数据,这样每次请求直接打到数据库,就好像缓存不存在一样。
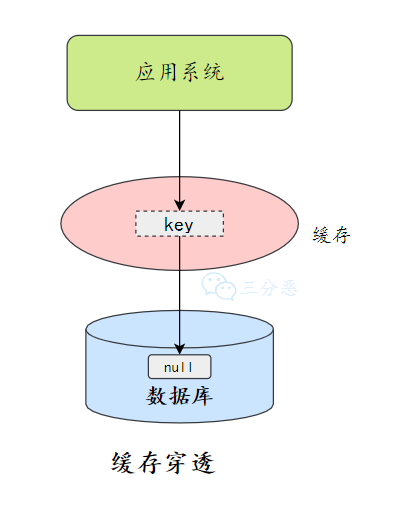
缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。
缓存穿透可能会使后端存储负载加大,如果发现大量存储层空命中,可能就是出现了缓存穿透问题。
缓存穿透可能有两种原因:
- 自身业务代码问题
- 恶意攻击,爬虫造成空命中
我们来看看如何解决。
缓存穿透如何解决
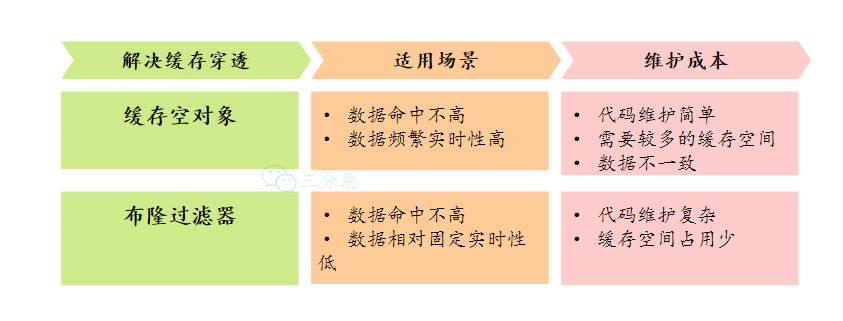
缓存空值/默认值
一种方式是在数据库不命中之后,把一个空对象或者默认值保存到缓存,之后再访问这个数据,就会从缓存中获取,这样就保护了数据库。
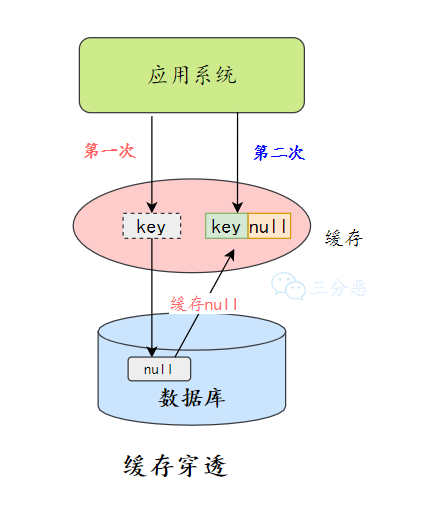
缓存空值有两大问题:
-
空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间(如果是攻击,问题更严重),比较有效的
方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
-
缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。
例如过期时间设置为5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致。
这时候可以利用消息队列或者其它异步方式清理缓存中的空对象。
布隆过滤器
除了缓存空对象,我们还可以在存储和缓存之前,加一个布隆过滤器,做一层过滤。
布隆过滤器里会保存数据是否存在,如果判断数据不不能再,就不会访问存储。
那布隆过滤器是什么玩意儿?查找它会不会很慢?
布隆过滤器是什么?
不知道你对哈希表了解多少,布隆过滤器是一个类似的东西。
它是一个连续的数据结构,每个存储位存储都是一个bit,即0或者1, 来标识数据是否存在。
存储数据的时时候,使用K个不同的哈希函数将这个变量映射为bit列表的的K个点,把它们置为1。
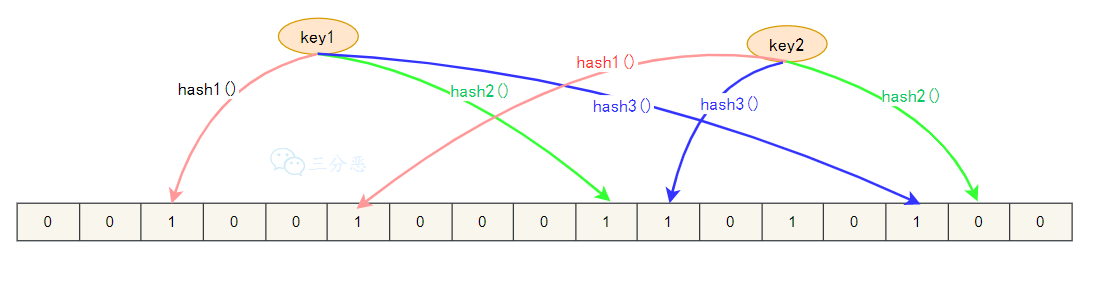
我们判断缓存key是否存在,同样,K个哈希函数,映射到bit列表上的K个点,判断是不是1:
- 如果全不是1,那么key不存在;
- 如果都是1,也只是表示key可能存在。
至于为什么?因为哈希函数是存在碰撞的可能的。
关于缓存穿透的两种主要解决方案,我们简单对比一下:
缓存雪崩
接下来我们看最严重的一种情况,缓存雪崩。
什么是缓存雪崩
缓存雪崩: 当某⼀时刻发⽣⼤规模的缓存失效的情况,例如缓存服务宕机、大量key在同一时间过期,这样的后果就是⼤量的请求进来直接打到DB上,可能导致整个系统的崩溃,称为雪崩。
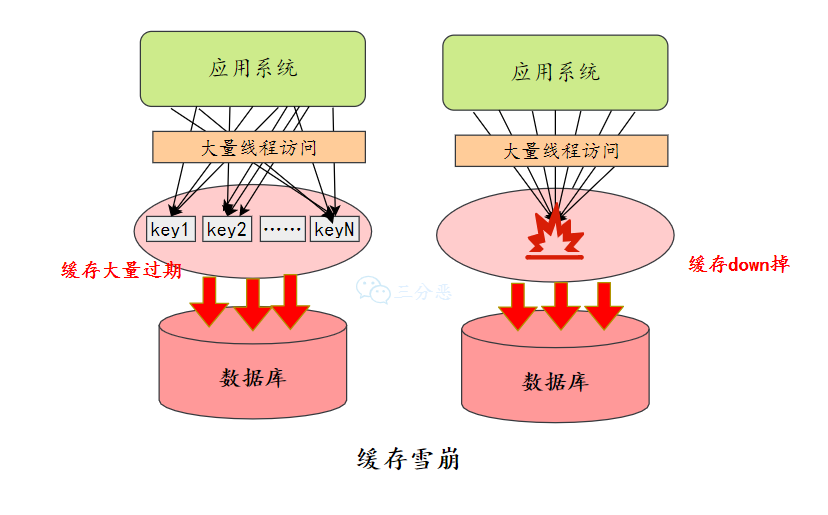
缓存雪崩如何解决
缓存雪崩是三大缓存问题里最严重的一种,我们来看看怎么预防和处理。
提高缓存可用性
- 集群部署:通过集群来提升缓存的可用性,可以利用Redis本身的Redis Cluster或者第三方集群方案如Codis等。
- 多级缓存:设置多级缓存,第一级缓存失效的基础上,访问二级缓存,每一级缓存的失效时间都不同。
过期时间
- 均匀过期:为了避免大量的缓存在同一时间过期,可以把不同的 key 过期时间随机生成,避免过期时间太过集中。
- 热点数据永不过期。
熔断降级
- 服务熔断:当缓存服务器宕机或超时响应时,为了防止整个系统出现雪崩,暂时停止业务服务访问缓存系统。
- 服务降级:当出现大量缓存失效,而且处在高并发高负荷的情况下,在业务系统内部暂时舍弃对一些非核心的接口和数据的请求,而直接返回一个提前准备好的 fallback(退路)错误处理信息。
总结
一张图总结:
参考:
[1]. 《Redis开发与运维》
[2]. 《极客时间 高并发系统设计四十问》
[4]. 缓存穿透、缓存击穿、缓存雪崩,看这篇就够了
[5]. 布隆过滤器,没那么难