一、什么是循环依赖?什么是三级缓存?
【什么是循环依赖】什么是循环依赖很好理解,当我们代码中出现,形如BeanA类中依赖注入BeanB类,BeanB类依赖注入A类时,在IOC过程中creaBean实例化A之后,发现并不能直接initbeanA对象,需要注入B对象,发现对象池里还没有B对象。通过构建函数创建B对象的实例化。又因B对象需要注入A对象,发现对象池里还没有A对象,就会套娃。
【三级缓存】三级缓存实际上就是三个Map对象,从存放对象的顺序开始
三级缓存singletonFactories存放ObjectFactory,传入的是匿名内部类,ObjectFactory.getObject() 方法最终会调用getEarlyBeanReference()进行处理,返回创建bean实例化的lambda表达式。
二级缓存earlySingletonObjects存放bean,保存半成品bean实例,当对象需要被AOP切面代时,保存代理bean的实例beanProxy
一级缓存(单例池)singletonObjects存放完整的bean实例
/** Cache of singleton objects: bean name to bean instance. */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of early singleton objects: bean name to bean instance. */
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
/** Cache of singleton factories: bean name to ObjectFactory. */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);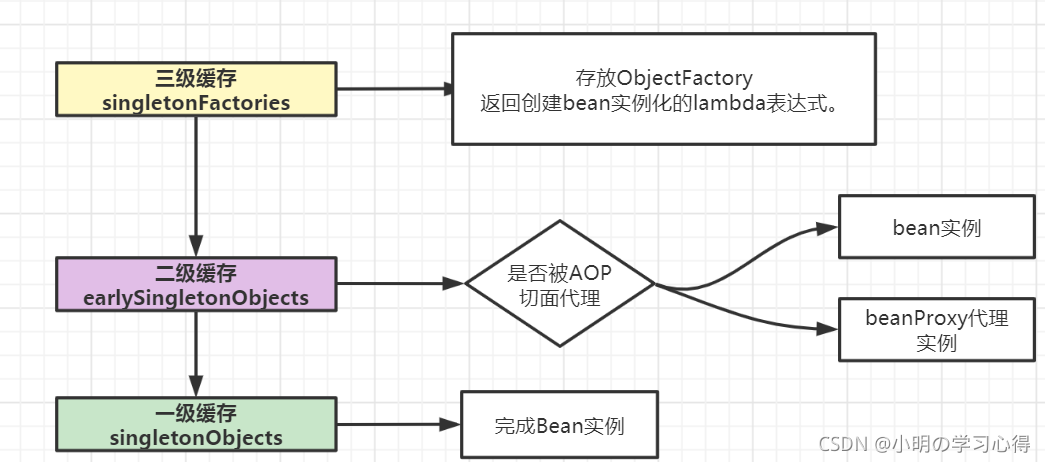
二、三级缓存如何解决循环依赖?
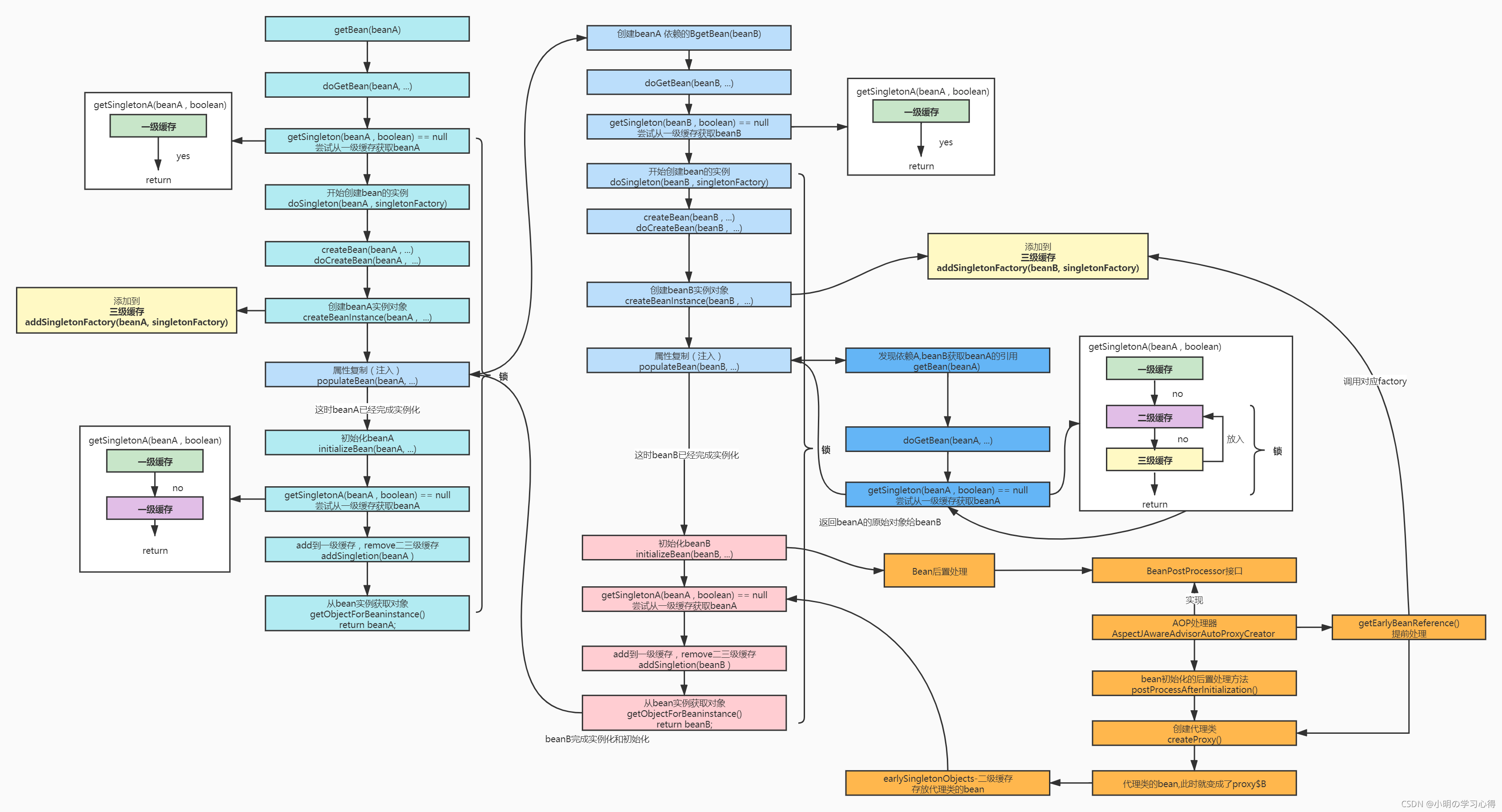
【如何解决循环依赖】Spring解决循环依赖的核心思想在于提前曝光,首先创建实例化A,并在三级缓存singletonFactories中保存实例化A的lambda表达式以便获取A实例,当我没有循环依赖和AOP时,这个三级缓存singletonFactories是没用在后续用到的。
但是当我A对象需要注入B对象,发现缓存里还没有B对象,创建B对象并又上述所说添加进三级缓存singletonFactories,B对象需要注入A对象,这时从半成品缓存里取到半成品对象A,通过缓存的lambda表达式创建A实例对象,并放到二级缓存earlySingletonObjects中。
此时B对象可以注入A对象实例和初始化自己,之后将完成品B对象放入完成品缓存singletonObjects。但是当有aop时,B对象还没有把完成品B对象放入完成品缓存singletonObjects中,B对象初始化后需要进行代理对象的创建,此时需要从singletonFactories获取bean实例对象,进行createProxy创建代理类操作,这是会把proxy&B放入二级缓存earlySingletonObjects中。这时候才会把完整的B对象放入完成品一级缓存也叫单例池singletonObjects中,返回给A对象。
A对象继续注入其他属性和初始化,之后将完成品A对象放入完成品缓存。
三、使用二级缓存能不能解决循环依赖?
一定是不行,我们只保留二级缓存有两个可能性保留一二singletonObjects和earlySingletonObjects,或者一三singletonObjects和singletonFactories
【只保留一二singletonObjects和earlySingletonObjects】
流程可以这样走:实例化A ->将半成品的A放入earlySingletonObjects中 ->填充A的属性时发现取不到B->实例化B->将半成品的B放入earlySingletonObjects中->从earlySingletonObjects中取出A填充B的属性->将成品B放入singletonObjects,并从earlySingletonObjects中删除B->将B填充到A的属性中->将成品A放入singletonObjects并删除earlySingletonObjects。
这样的流程是线程安全的,不过如果A上加个切面(AOP),这种做法就没法满足需求了,因为earlySingletonObjects中存放的都是原始对象,而我们需要注入的其实是A的代理对象。
【只保留一三singletonObjects和singletonFactories】
流程是这样的:实例化A ->创建A的对象工厂并放入singletonFactories中 ->填充A的属性时发现取不到B->实例化B->创建B的对象工厂并放入singletonFactories中->从singletonFactories中获取A的对象工厂并获取A填充到B中->将成品B放入singletonObjects,并从singletonFactories中删除B的对象工厂->将B填充到A的属性中->将成品A放入singletonObjects并删除A的对象工厂。
同样,这样的流程也适用于普通的IOC已经有并发的场景,但如果A上加个切面(AOP)的话,这种情况也无法满足需求。
因为拿到ObjectFactory对象后,调用ObjectFactory.getObject()方法最终会调用getEarlyBeanReference()方法,getEarlyBeanReference这个方法每次从三级缓存中拿到singleFactory对象,执行getObject()方法又会产生新的代理对象
所有这里我们要借助二级缓存来解决这个问题,将执行了singleFactory.getObject()产生的对象放到二级缓存中去,后面去二级缓存中拿,没必要再执行一遍singletonFactory.getObject()方法再产生一个新的代理对象,保证始终只有一个代理对象。
getSingleton()、getEarlyBeanReference() 源码如下
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName); // 先从一级缓存拿
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName); // 拿二级缓存
if (singletonObject == null && allowEarlyReference) {
// 拿三级缓存
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 最终会调用传入的匿名内部类getEarlyBeanReference()方法,这里面没调用一次会生成一个新的代理对象
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}