目录
一、项目背景
二、数据爬取
1、相关库的导入与说明
2、获取二级页面链接
1)分析一级页面url特征
2)构建一级url库
3)爬取所有二级url链接
3、获取岗位信息并保存
三、数据清洗
1、数据读取、去重、空值处理
1)相关库导入及数据读取
2)数据去重与控制处理
2、“岗位名称”字段预处理
1)”岗位名称“字段预览
2)构建关键词,筛选名称
3)岗位名称标准化处理
3、“岗位薪资”字段预处理
4、“公司规模”字段预处理
5、“职位信息”字段预处理
6、其它字段预处理
7、数据存储
四、Tableau数据可视化展示
1、岗位数量城市分布气泡图
2、热门城市用人需求Top15
3、用人需求Top15行业及其薪资情况
4、各类型企业岗位需求树状分布图
5、经验学历与薪资需求突出显示表
6、不同行业知识、技能要求词云图
1)传统制造业
2) 计算机相关行业
3)服务行业
6、岗位数量与薪资水平地理分布
7、可视化看板最终展示结果
五、源代码
1、爬虫源代码
2、数据预处理源码
一、项目背景
随着科技的不断进步与发展,数据呈现爆发式的增长,各行各业对于数据的依赖越来越强,与数据打交道在所难免,而社会对于“数据”方面的人才需求也在不断增大。因此了解当下企业究竟需要招聘什么样的人才?需要什么样的技能?不管是对于在校生,还是对于求职者来说,都显得十分必要。
对于一名小白来说,想要入门数据分析,首先要了解目前社会对于数据相关岗位的需求情况,基于这一问题,本文针对前程无忧招聘网站,利用python爬取了其全国范围内大数据、数据分析、数据挖掘、机器学习、人工智能等与数据相关的岗位招聘信息。并通过Tableau可视化工具分析比较了不同行业的岗位薪资、用人需求等情况;以及不同行业、岗位的知识、技能要求等。
可视化分析效果图示例:

二、数据爬取
- 爬取字段:岗位名称、公司名称、薪资水平、工作经验、学历需求、工作地点、招聘人数、发布时间、公司类型、公司规模、行业领域、福利待遇、职位信息;
- 说明:在前程无忧招聘网站中,我们在搜索框中输入“数据”两个字进行搜索发现,共有2000个一级页面,其中每个页面包含50条岗位信息,因此总共有约100000条招聘信息。当点击一级页面中每个岗位信息时,页面会跳转至相应岗位的二级页面,二级页面中即包含我们所需要的全部字段信息;
一级页面如下:
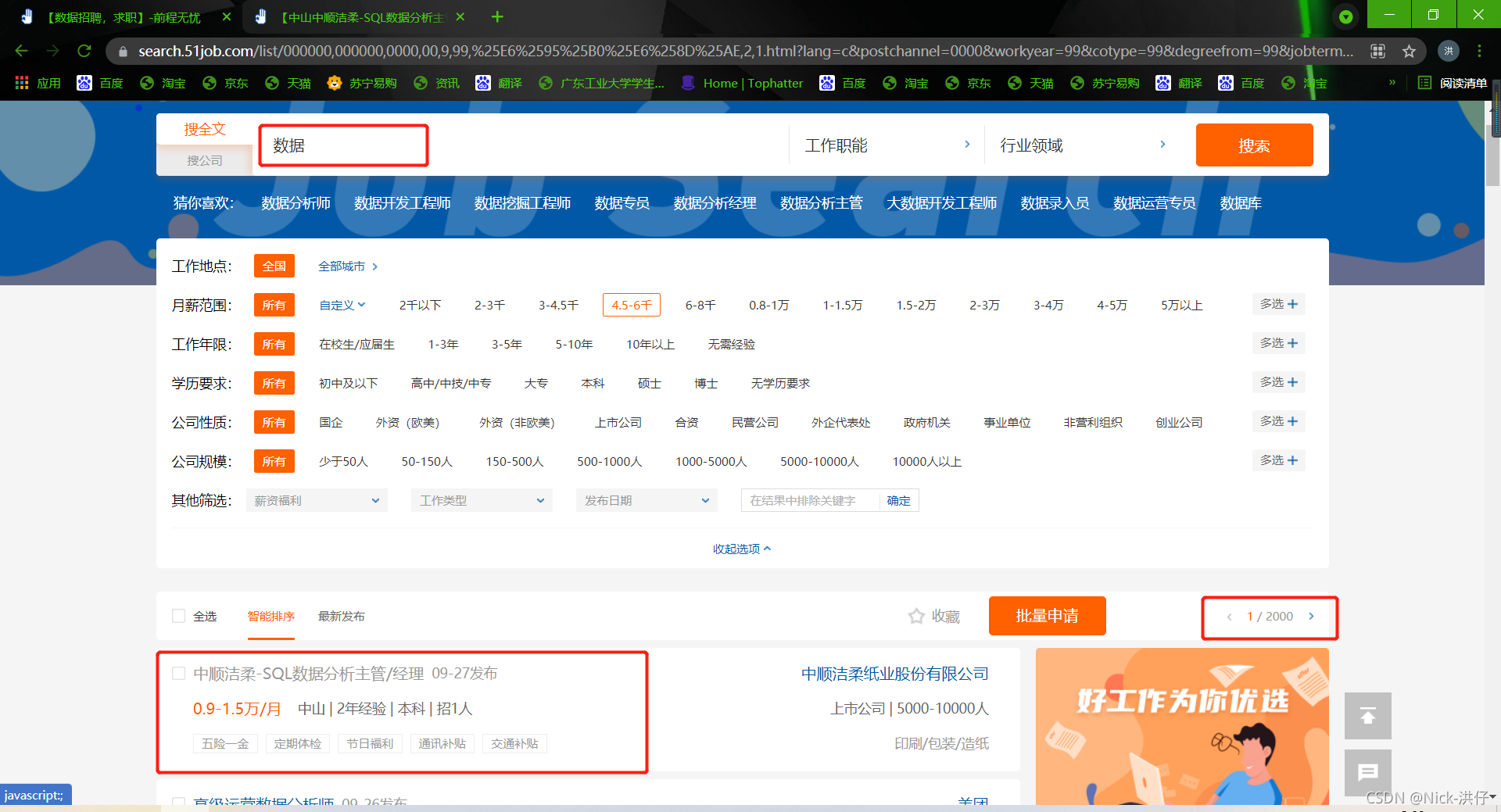
二级页面如下:
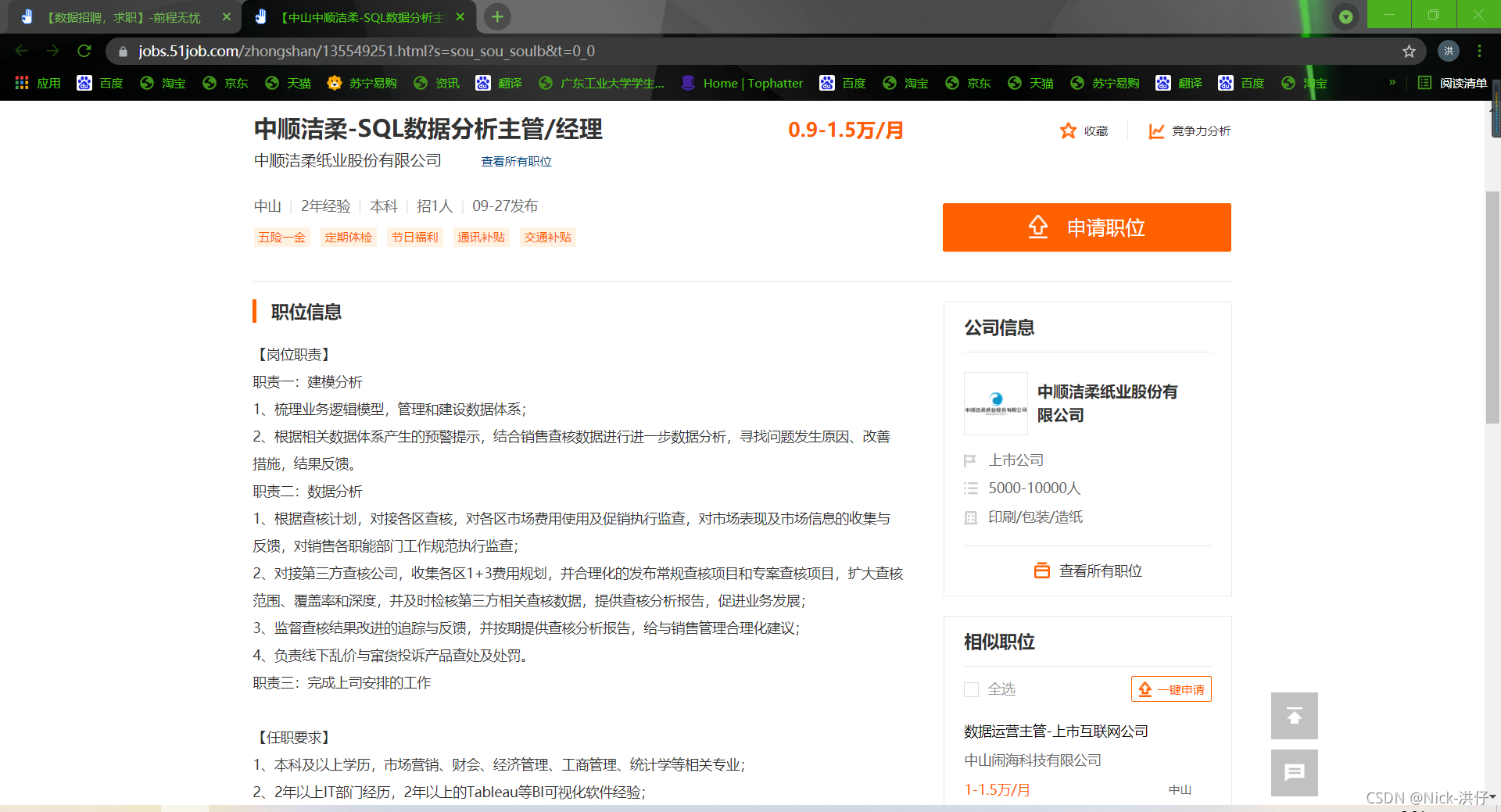
- 爬取思路:先针对一级页面爬取所有岗位对应的二级页面链接,再根据二级页面链接遍历爬取相应岗位信息;
- 开发环境:python3、Spyder
1、相关库的导入与说明
import json
import requests
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from lxml import etree
from selenium.webdriver import ChromeOptions由于前程无忧招聘网站的反爬机制较强,采用动态渲染+限制ip访问频率等多层反爬,因此在获取二级页面链接时需借助json进行解析,本文对于二级页面岗位信息的获取采用selenium模拟浏览器爬取,同时通过代理IP的方式,每隔一段时间换一次请求IP以免触发网站反爬机制。
2、获取二级页面链接
1)分析一级页面url特征
# 第一页URL的特征
"https://search.51job.com/list/000000,000000,0000,00,9,99,数据,2,1.html?"
# 第二页URL的特征
"https://search.51job.com/list/000000,000000,0000,00,9,99,数据,2,2.html?"
# 第三页URL的特征
"https://search.51job.com/list/000000,000000,0000,00,9,99,数据,2,3.html?"通过观察不同页面的URL可以发现,不同页面的URL链接只有“.html”前面的数字不同,该数字正好代表该页的页码 ,因此只需要构造字符串拼接,然后通过for循环语句即可构造自动翻页。
2)构建一级url库
url1 = []
for i in range(2000):
url_pre = "https://search.51job.com/list/000000,000000,0000,00,9,99,数据,2,%s" % (1+i) #设置自动翻页
url_end = ".html?"
url_all = url_pre + url_end
url1.append(url_all)
print("一级URL库创建完毕")3)爬取所有二级url链接
url2 = []
j = 0
for url in url1:
j += 1
re1 = requests.get(url , headers = headers,proxies= {'http':'tps131.kdlapi.com:15818'},timeout=(5,10)) #通过proxies设置代理ip
html1 = etree.HTML(re1.text)
divs = html1.xpath('//script[@type = "text/javascript"]/text()')[0].replace('window.__SEARCH_RESULT__ = ',"")
js = json.loads(divs)
for i in range(len(js['engine_jds'])):
if js['engine_jds'][i]['job_href'][0:22] == "https://jobs.51job.com":
url2.append(js['engine_jds'][i]['job_href'])
else:
print("url异常,弃用") #剔除异常url
print("已爬取"+str(j)+"页")
print("成功爬取"+str(len(url2))+"条二级URL")注意:爬取二级URL链接时发现并非爬取的所有链接都是规范的,会存在少部分异常URL,这会对后续岗位信息的爬取造成干扰,因此需要利用if条件语句对其进行剔除。
3、获取岗位信息并保存
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument('--proxy-server=http://tps131.kdlapi.com:15818') #设置代理ip
driver = webdriver.Chrome(options=option)
for url in url2:
co = 1
while co == 1:
try:
driver.get(url)
wait = WebDriverWait(driver,10,0.5)
wait.until(EC.presence_of_element_located((By.ID,'topIndex')))
except:
driver.close()
driver = webdriver.Chrome(options=option)
co = 1
else:
co = 0
try:
福利待遇 = driver.find_elements_by_xpath('//div[@class = "t1"]')[0].text
岗位名称 = driver.find_element_by_xpath('//div[@class = "cn"]/h1').text
薪资水平 = driver.find_element_by_xpath('//div[@class = "cn"]/strong').text
职位信息 = driver.find_elements_by_xpath('//div[@class = "bmsg job_msg inbox"]')[0].text
公司类型 = driver.find_elements_by_xpath('//div[@class = "com_tag"]/p')[0].text
公司规模 = driver.find_elements_by_xpath('//div[@class = "com_tag"]/p')[1].text
公司领域 = driver.find_elements_by_xpath('//div[@class = "com_tag"]/p')[2].text
公司名称 = driver.find_element_by_xpath('//div[@class = "com_msg"]/a/p').text
工作地点 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[0]
工作经验 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[1]
学历要求 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[2]
招聘人数 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[3]
发布时间 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[4]
except:
福利待遇 = "nan"
岗位名称 = "nan"
薪资水平 = "nan"
职位信息 = "nan"
公司类型 = "nan"
公司规模 = "nan"
公司领域 = "nan"
公司名称 = "nan"
工作地点 = "nan"
工作经验 = "nan"
学历要求 = "nan"
招聘人数 = "nan"
发布时间 = "nan"
print("信息提取异常,弃用")
finally:
info = {
"岗位名称" : 岗位名称,
"公司名称" : 公司名称,
"薪资水平" : 薪资水平,
"工作经验" : 工作经验,
"学历要求" : 学历要求,
"工作地点" : 工作地点,
"招聘人数" : 招聘人数,
"发布时间" : 发布时间,
"公司类型" : 公司类型,
"公司规模" : 公司规模,
"公司领域" : 公司领域,
"福利待遇" : 福利待遇,
"职位信息" : 职位信息
}
jobs_info.append(info)
df = pd.DataFrame(jobs_info)
df.to_excel(r"E:\python爬虫\前程无忧招聘信息.xlsx") 在爬取并剔除异常数据之后,最终得到了90000多条完整的数据做分析,但经过观察发现,所爬取的数据并非全都与“数据”岗位相关联。实际上,前程无忧招聘网站上与“数据”有关的只有几百页,而我们爬取了2000页的所有数据,因此在后面进行数据处理时需要把无关的数据剔除掉。在爬取前根据对代码的测试发现,有些岗位字段在进行爬取时会出现错位,从而导致数据存储失败,为了不影响后面代码的执行,这里设置了“try-except”进行异常处理,同时使用while循环语句在服务器出现请求失败时关闭模拟浏览器并进行重新请求。
三、数据清洗
1、数据读取、去重、空值处理
在获取了所需数据之后,可以看出数据较乱,并不利于我们进行分析,因此在分析前需要对数据进行预处理,得到规范格式的数据才可以用来最终做可视化数据展示。
获取的数据截图如下:

1)相关库导入及数据读取
#导入相关库
import pandas as pd
import numpy as np
import jieba
#读取数据
df = pd.read_excel(r'E:\python爬虫\前程无忧招聘信息.xlsx',index_col=0)2)数据去重与控制处理
- 对于重复值的定义,我们认为一个记录的公司名称和岗位名称一致时,即可看作是重复值。因此利用drop_duplicates()函数剔除所有公司名称和岗位名称相同的记录并保留第一个记录。
- 对于空值处理,只删除所有字段信息都为nan的记录。
#去除重复数据
df.drop_duplicates(subset=['公司名称','岗位名称'],inplace=True)
#空值删除
df[df['公司名称'].isnull()]
df.dropna(how='all',inplace=True)2、“岗位名称”字段预处理
1)”岗位名称“字段预览
首先我们对“岗位名称”的格式进行调整,将其中所有大写英文字母统一转换为小写,例如将"Java"转换为"java",然后对所有岗位做一个频次统计,统计结果发现“岗位名称”字段很杂乱,且存在很多与“数据”无关的岗位,因此要对数据做一个筛选。
df['岗位名称'] = df['岗位名称'].apply(lambda x:x.lower())
counts = df['岗位名称'].value_counts() 2)构建关键词,筛选名称
首先我们列出与“数据”岗位“有关的一系列关键词,然后通过count()与for语句对所有记录进行统计判断,如果包含任一关键词则保留该记录,如果不包含则删除该字段。
#构建目标关键词
target_job = ['算法','开发','分析','工程师','数据','运营','运维','it','仓库','统计']
#筛选目标数据
index = [df['岗位名称'].str.count(i) for i in target_job]
index = np.array(index).sum(axis=0) > 0
job_info = df[index]3)岗位名称标准化处理
基于前面对“岗位名称”字段的统计情况,我们定义了目标岗位列表job_list,用来替换统一相近的岗位名称,之后,我们将“数据专员”、“数据统计”统一归为“数据分析”。
job_list = ['数据分析',"数据统计","数据专员",'数据挖掘','算法','大数据','开发工程师','运营',
'软件工程','前端开发','深度学习','ai','数据库','仓库管理','数据产品','客服',
'java','.net','andrio','人工智能','c++','数据管理',"测试","运维","数据工程师"]
job_list = np.array(job_list)
def Rename(x,job_list=job_list):
index = [i in x for i in job_list]
if sum(index) > 0:
return job_list[index][0]
else:
return x
job_info['岗位名称'] = job_info['岗位名称'].apply(Rename)
job_info["岗位名称"] = job_info["岗位名称"].apply(lambda x:x.replace("数据专员","数据分析"))
job_info["岗位名称"] = job_info["岗位名称"].apply(lambda x:x.replace("数据统计","数据分析"))统一之后的“岗位名称”如下图所示:
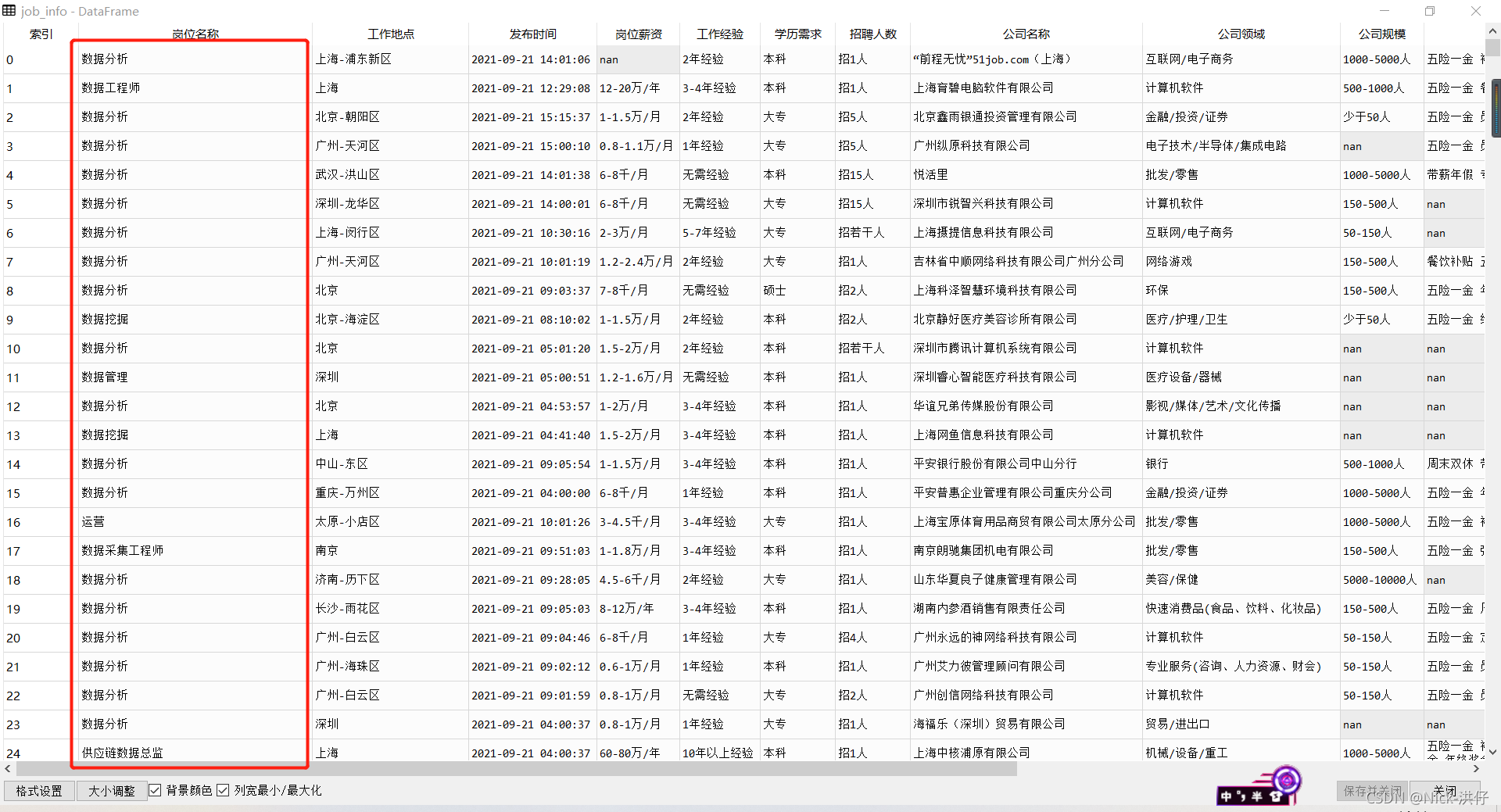
3、“岗位薪资”字段预处理
对于“岗位薪资”字段的处理,重点在于对其单位格式转换,在简单观察该字段后发现,其存在“万/年”、“万/月”、“千/月”等不同单位,因此需要对其做一个统一换算,将数据格式统一转换为“元/月”,并根据最高工资与最低工资求出平均值。
job_info['岗位薪资'].value_counts()
#剔除异常数据
index1 = job_info["岗位薪资"].str[-1].isin(["年","月"])
index2 = job_info["岗位薪资"].str[-3].isin(["万","千"])
job_info = job_info[index1 & index2]
#计算平均工资
job_info['平均薪资'] = job_info['岗位薪资'].astype(str).apply(lambda x:np.array(x[:-3].split('-'),dtype=float))
job_info['平均薪资'] = job_info['平均薪资'].apply(lambda x:np.mean(x))
#统一工资单位
job_info['单位'] = job_info['岗位薪资'].apply(lambda x:x[-3:])
def con_unit(x):
if x['单位'] == "万/月":
z = x['平均薪资']*10000
elif x['单位'] == "千/月":
z = x['平均薪资']*1000
elif x['单位'] == "万/年":
z = x['平均薪资']/12*10000
return int(z)
job_info['平均薪资'] = job_info.apply(con_unit,axis=1)
job_info['单位'] = '元/月'说明:首先我们对该字段进行统计预览,之后做一个数据筛选剔除异常单位与空值记录,再计算出每个字段的平均工资,接着定义一个函数,将格式换算为“元/月”,得到最终的“平均薪资”字段。
4、“公司规模”字段预处理
对于“公司规模”字段的处理较简单,只需要定义一个if条件语句将其格式做一个转换即可。
job_info['公司规模'].value_counts()
def func(x):
if x == '少于50人':
return "<50"
elif x == '50-150人':
return "50-150"
elif x == '150-500人':
return '150-500'
elif x == '500-1000人':
return '500-1000'
elif x == '1000-5000人':
return '1000-5000'
elif x == '5000-10000人':
return '5000-10000'
elif x == '10000人以上':
return ">10000"
else:
return np.nan
job_info['公司规模'] = job_info['公司规模'].apply(func)5、“职位信息”字段预处理
job_info['职位信息'] = job_info['职位信息'].apply(lambda x:x.split('职能类别')[0])
with open(r"E:\python爬虫\数据处理\停用词表.txt",'r',encoding = 'utf8') as f:
stopword = f.read()
stopword = stopword.split()
#对“职业信息”字段进行简单处理,去除无意义的文字,构造jieba分词
job_info['职位信息'] = job_info['职位信息'].apply(lambda x:x.lower()).apply(lambda x:"".join(x)).apply(lambda x:x.strip()).apply(jieba.lcut).apply(lambda x:[i for i in x if i not in stopword])
#按照行业进行分类,求出每一个行业下各关键词的词频统计,以便于后期做词云图
cons = job_info['公司领域'].value_counts()
industries = pd.DataFrame(cons.index,columns=['行业领域'])
industry = pd.DataFrame(columns=['分词明细','行业领域'])
for i in industries['行业领域']:
words = []
word = job_info['职位信息'][job_info['公司领域'] == i]
word.dropna(inplace=True)
[words.extend(str(z).strip('\'[]').split("\', \'")) for z in word]
df1 = pd.DataFrame({'分词明细':words,
'行业领域':i})
industry = industry.append(df1,ignore_index=True)
industry = industry[industry['分词明细'] != "\\n"]
industry = industry[industry['分词明细'] != ""]
#剔除词频小于300的关键词
count = pd.DataFrame(industry['分词明细'].value_counts())
lst = list(count[count['分词明细'] >=300].index)
industry = industry[industry['分词明细'].isin(lst)]
#数据存储
industry.to_excel(r'E:\python爬虫\数据处理\词云.xlsx') 6、其它字段预处理
- “工作地点”字段:该字段有”市-区“和”市“两种格式,如”广州-天河“与”广州“,因此需要统一转换为”市“的格式;
- “公司领域”字段:每个公司的行业字段可能会有多个行业标签,我们默认以第一个作为改公司的行业标签;
- “招聘人数”字段:由于某些公司岗位没有具体招聘人数,因此我们默认以最低需求为标准,将“招若干人”改为“招1人”,以便于后面统计分析;
- 其它字段:对于其他几个字段格式只存在一些字符串空格问题,因此只需要对其进行去除空格即可。
#工作地点字段处理
job_info['工作地点'] = job_info['工作地点'].apply(lambda x:x.split('-')[0])
#公司领域字段处理
job_info['公司领域'] = job_info['公司领域'].apply(lambda x:x.split('/')[0])
a = job_info['公司领域'].value_counts()
#招聘人数字段处理
job_info['招聘人数'] = job_info['招聘人数'].apply(lambda x:x.replace("若干","1").strip()[1:-1])
#工作经验与学历要求字段处理
job_info['工作经验'] = job_info['工作经验'].apply(lambda x:x.replace("无需","1年以下").strip()[:-2])
job_info['学历需求'] = job_info['学历需求'].apply(lambda x:x.split()[0])
#公司福利字段处理
job_info['公司福利'] = job_info['公司福利'].apply(lambda x:str(x).split())
7、数据存储
我们针对清洗干净后的数据另存为一个文档,对源数据不做修改。
job_info.to_excel(r'E:\python爬虫\前程无忧(已清洗).xlsx')四、Tableau数据可视化展示
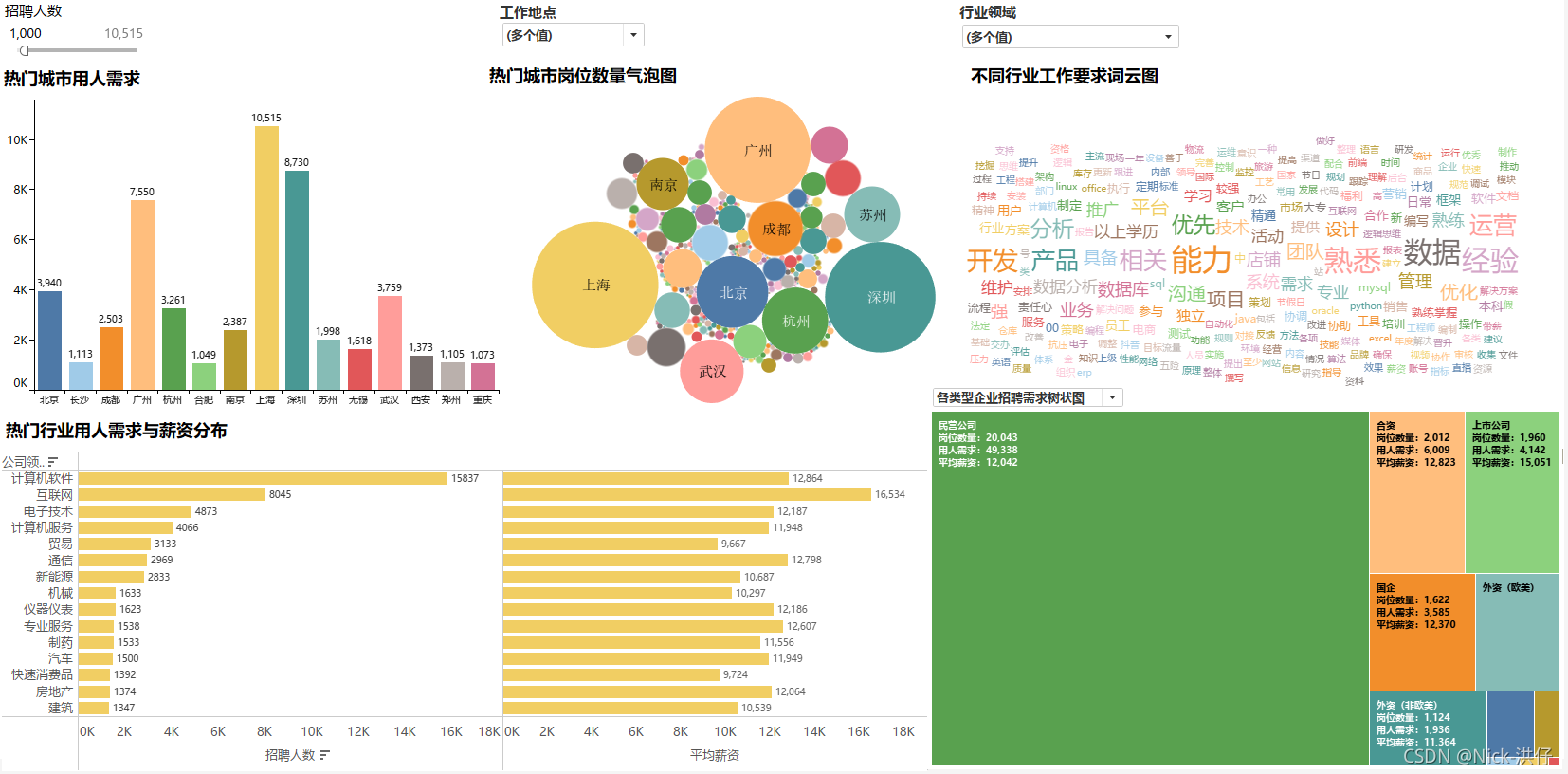
1、岗位数量城市分布气泡图
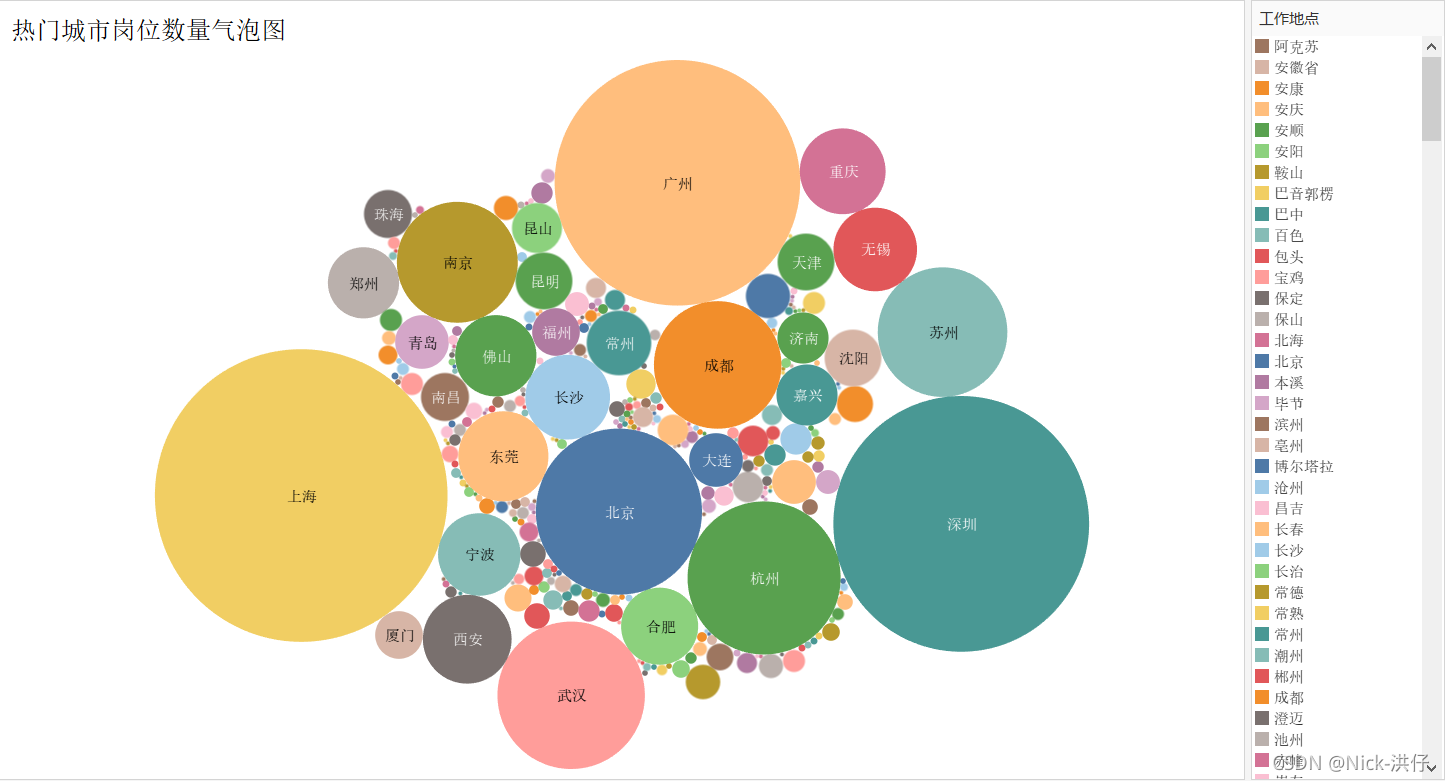
结论分析:从气泡图中可以看出,“数据”相关岗位数量较高的城市有:上海、深圳、广州、北京、杭州、武汉等。
2、热门城市用人需求Top15
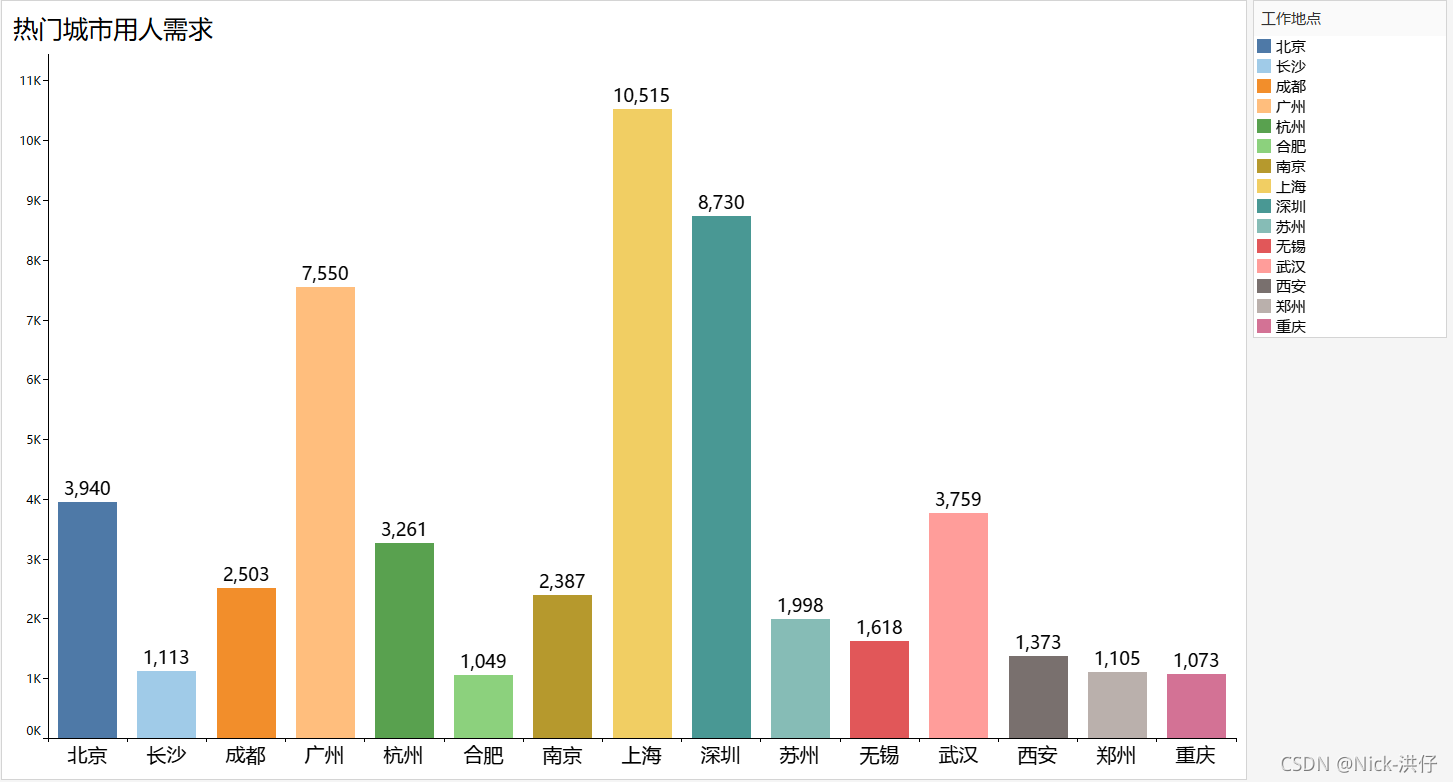
结论分析:通过条形图可以看出,“数据”相关岗位用人需求达1000人以上的城市有15个,需求由高到低依次为:上海、深圳、广州、北京、武汉、杭州、成都、南京、苏州、无锡、西安、长沙、郑州、重庆。其中上海用人需求高达10000人。
3、用人需求Top15行业及其薪资情况
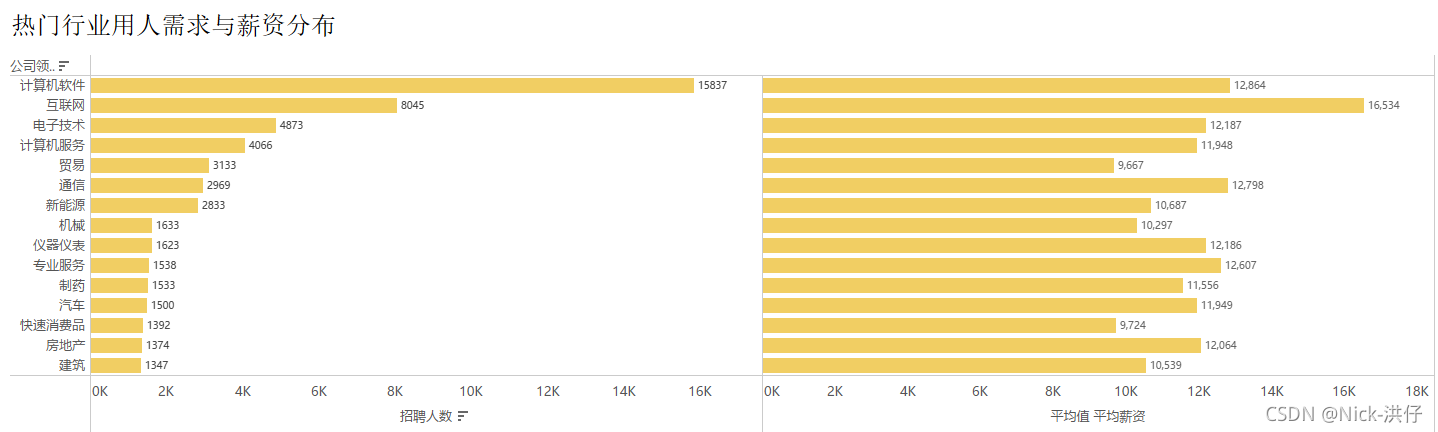
结论分析:从不同行业的用人需求与薪资对比可知,用人需求排名前4的行业分别:计算机软件、互联网、电子技术、计算机服务;平均薪资排名前4的行业分别为:互联网、计算机软件、通信、专业服务。可以发现,“数据”相关岗位在计算机领域需求大,薪资高,前景好。
4、各类型企业岗位需求树状分布图
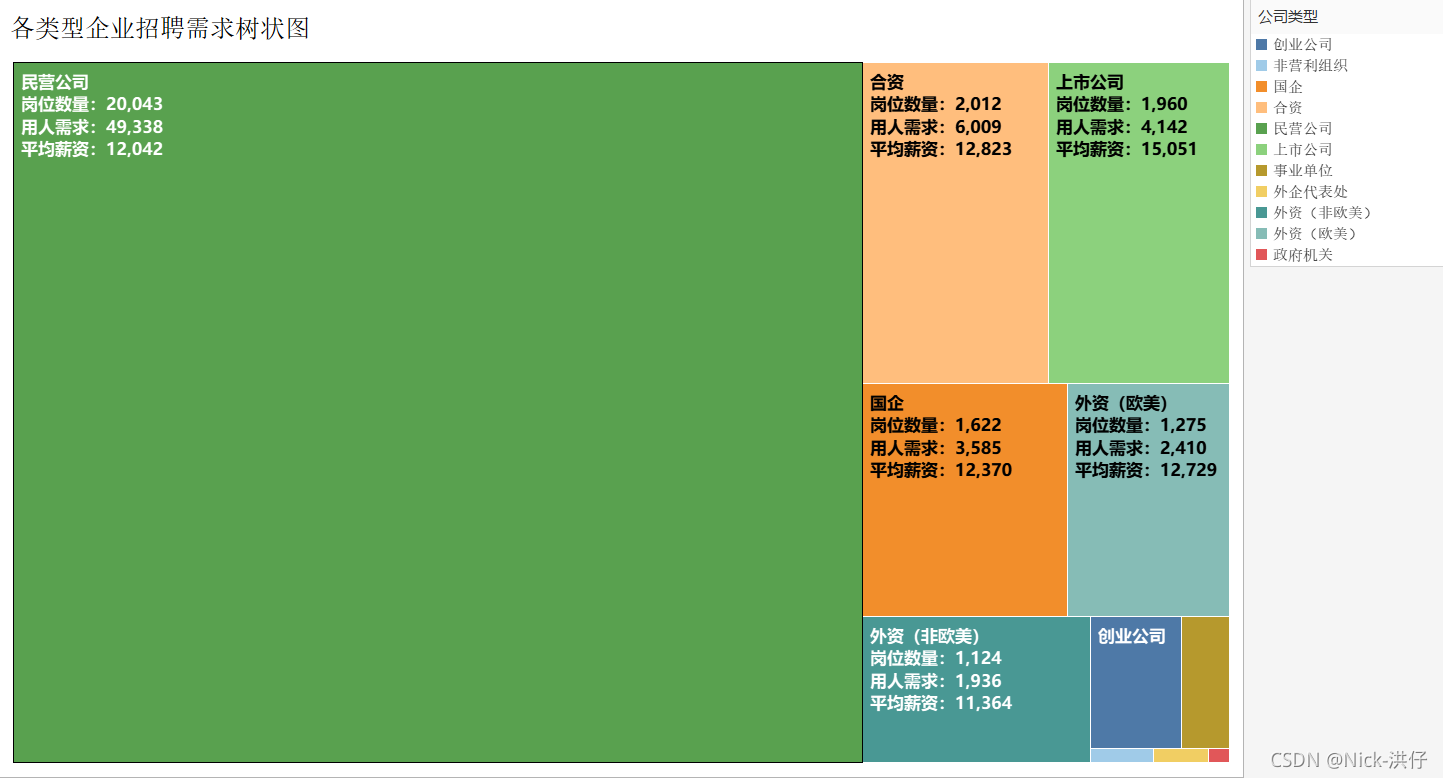
结论分析:在发布的众多岗位需求信息中,以民营公司为主,其岗位数量、用人需求极高,但薪资待遇一般,而上市公司的岗位数量一般,但薪资待遇好。
5、经验学历与薪资需求突出显示表
注:颜色深浅表示薪资高低,数字表示招聘人数
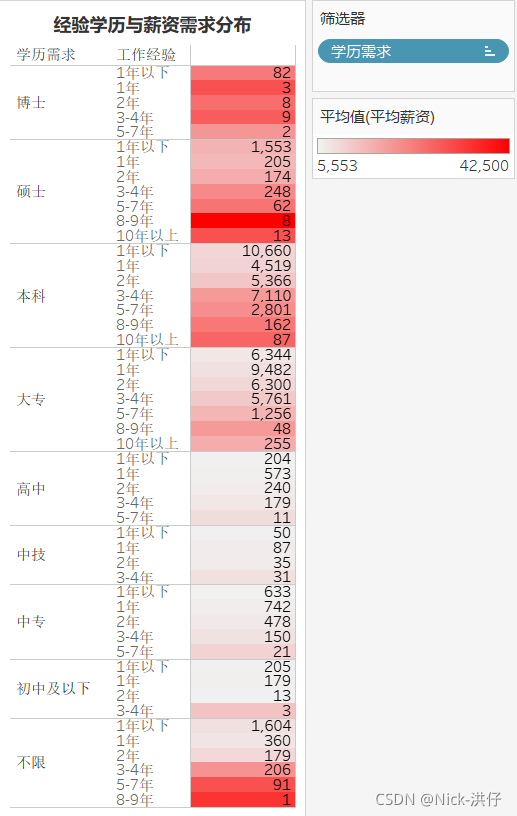
结论分析:根据突出显示表可以发现,在学历要求方面,大专与本科生需求量较大;经验要求方面,3年以下相关经验的岗位占大多数,而薪资方面,学历越高,经验越丰富则薪资越高。因此可以判断数据分析行业还是一个较新兴的行业,目前行业的基础岗位较多,且具有丰富经验的专家较少。
6、不同行业知识、技能要求词云图
1)传统制造业

2) 计算机相关行业

3)服务行业
结论分析:上图通过列举了传统制造业、计算机相关行业以及服务业三个行业进行对比分析,三个行业对于“数据”相关岗位工作要求的共同点都是注重相关的行业经验及数据处理等能力,而计算机相关行业对于技术如开发、数据库、系统维护等编程能力要求较高,传统制造业和服务行业则更侧重于业务分析、管理、团队合作综合型能力等。
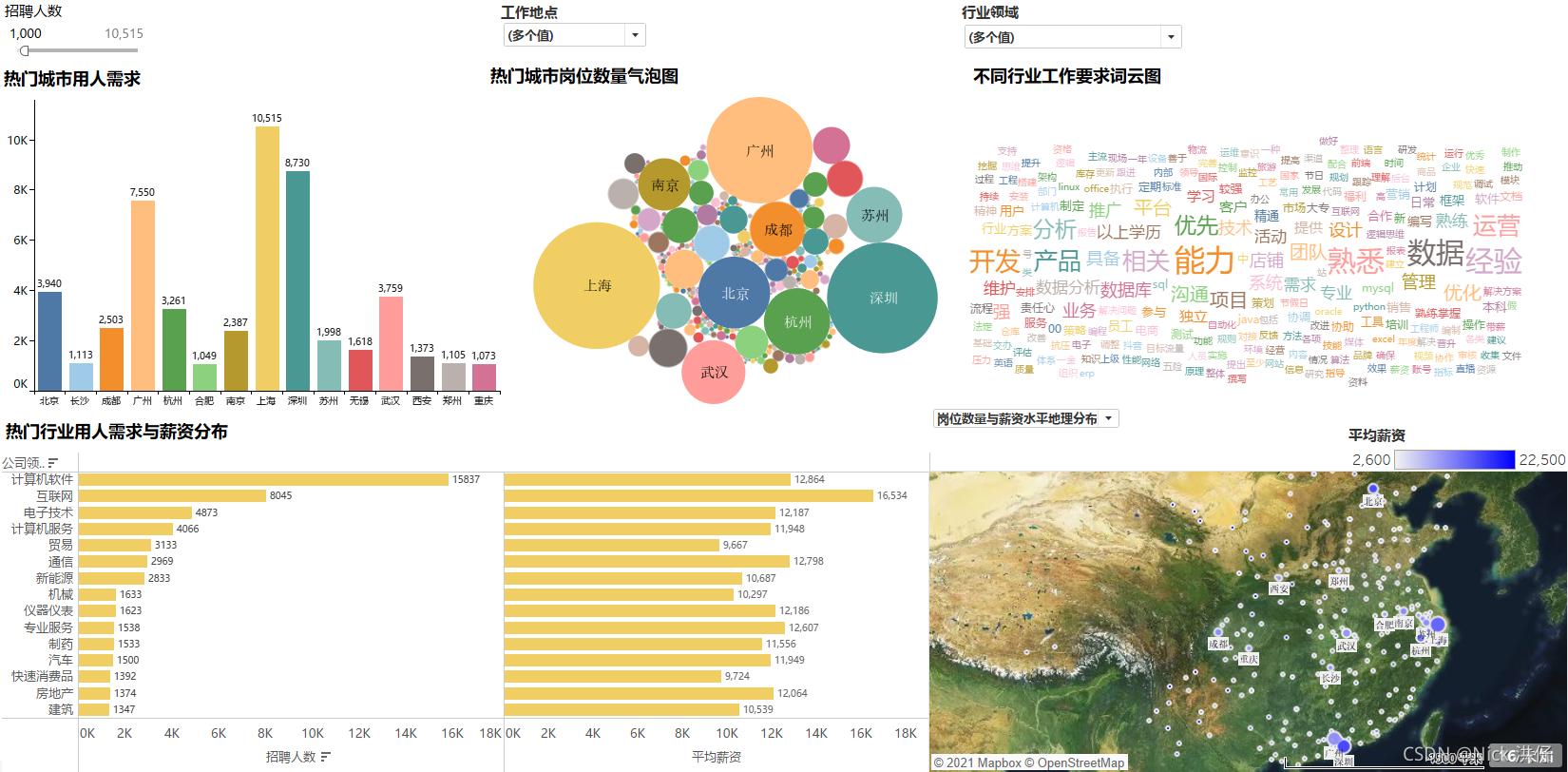
6、岗位数量与薪资水平地理分布

7、可视化看板最终展示结果
五、源代码
1、爬虫源代码
import json
import requests
import pandas as pd
from lxml import etree
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ChromeOptions
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
url1 = []
url2 = []
jobs_info = []
for i in range(2000):
url_pre = "https://search.51job.com/list/000000,000000,0000,00,9,99,数据,2,%s" % (1+i) #页面跳转
url_end = ".html?"
url_all = url_pre + url_end
url1.append(url_all)
print("一级URL库创建完毕")
#从json中提取数据并加载
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36',
'Connection': 'close',
'Host': 'search.51job.com'}
j = 0
for url in url1:
j += 1
re1 = requests.get(url , headers = headers,proxies= {'http':'tps131.kdlapi.com:15818'},timeout=(5,10))
html1 = etree.HTML(re1.text)
divs = html1.xpath('//script[@type = "text/javascript"]/text()')[0].replace('window.__SEARCH_RESULT__ = ',"")
js = json.loads(divs)
for i in range(len(js['engine_jds'])):
if js['engine_jds'][i]['job_href'][0:22] == "https://jobs.51job.com":
url2.append(js['engine_jds'][i]['job_href'])
else:
print("url异常,弃用")
print("已解析"+str(j)+"页")
print("成功提取"+str(len(url2))+"条二级URL")
#爬取岗位数据
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument('--proxy-server=http://tps131.kdlapi.com:15818')
driver = webdriver.Chrome(options=option)
for url in url2:
co = 1
while co == 1:
try:
#设置IP代理
driver.get(url)
wait = WebDriverWait(driver,10,0.5)
wait.until(EC.presence_of_element_located((By.ID,'topIndex')))
except:
driver.close()
driver = webdriver.Chrome(options=option)
co = 1
else:
co = 0
try:
福利待遇 = driver.find_elements_by_xpath('//div[@class = "t1"]')[0].text
岗位名称 = driver.find_element_by_xpath('//div[@class = "cn"]/h1').text
薪资水平 = driver.find_element_by_xpath('//div[@class = "cn"]/strong').text
职位信息 = driver.find_elements_by_xpath('//div[@class = "bmsg job_msg inbox"]')[0].text
公司类型 = driver.find_elements_by_xpath('//div[@class = "com_tag"]/p')[0].text
公司规模 = driver.find_elements_by_xpath('//div[@class = "com_tag"]/p')[1].text
公司领域 = driver.find_elements_by_xpath('//div[@class = "com_tag"]/p')[2].text
公司名称 = driver.find_element_by_xpath('//div[@class = "com_msg"]/a/p').text
工作地点 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[0]
工作经验 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[1]
学历要求 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[2]
招聘人数 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[3]
发布时间 = driver.find_elements_by_xpath('//div[@class = "cn"]//p[@class = "msg ltype"]')[0].text.split("|")[4]
except:
福利待遇 = "nan"
岗位名称 = "nan"
薪资水平 = "nan"
职位信息 = "nan"
公司类型 = "nan"
公司规模 = "nan"
公司领域 = "nan"
公司名称 = "nan"
工作地点 = "nan"
工作经验 = "nan"
学历要求 = "nan"
招聘人数 = "nan"
发布时间 = "nan"
print("信息提取异常,弃用")
finally:
info = {
"岗位名称" : 岗位名称,
"公司名称" : 公司名称,
"薪资水平" : 薪资水平,
"工作经验" : 工作经验,
"学历要求" : 学历要求,
"工作地点" : 工作地点,
"招聘人数" : 招聘人数,
"发布时间" : 发布时间,
"公司类型" : 公司类型,
"公司规模" : 公司规模,
"公司领域" : 公司领域,
"福利待遇" : 福利待遇,
"职位信息" : 职位信息
}
jobs_info.append(info)
df = pd.DataFrame(jobs_info)
df.to_excel(r"E:\python爬虫\前程无忧招聘信息.xlsx") 2、数据预处理源码
import pandas as pd
import numpy as np
import jieba
#数据读取
df = pd.read_excel(r'E:\python爬虫\前程无忧招聘信息.xlsx',index_col=0)
#数据去重与空值处理
df.drop_duplicates(subset=['公司名称','岗位名称'],inplace=True)
df[df['招聘人数'].isnull()]
df.dropna(how='all',inplace=True)
#岗位名称字段处理
df['岗位名称'] = df['岗位名称'].apply(lambda x:x.lower())
counts = df['岗位名称'].value_counts()
target_job = ['算法','开发','分析','工程师','数据','运营','运维','it','仓库','统计']
index = [df['岗位名称'].str.count(i) for i in target_job]
index = np.array(index).sum(axis=0) > 0
job_info = df[index]
job_list = ['数据分析',"数据统计","数据专员",'数据挖掘','算法','大数据','开发工程师',
'运营','软件工程','前端开发','深度学习','ai','数据库','仓库管理','数据产品',
'客服','java','.net','andrio','人工智能','c++','数据管理',"测试","运维","数据工程师"]
job_list = np.array(job_list)
def Rename(x,job_list=job_list):
index = [i in x for i in job_list]
if sum(index) > 0:
return job_list[index][0]
else:
return x
job_info['岗位名称'] = job_info['岗位名称'].apply(Rename)
job_info["岗位名称"] = job_info["岗位名称"].apply(lambda x:x.replace("数据专员","数据分析"))
job_info["岗位名称"] = job_info["岗位名称"].apply(lambda x:x.replace("数据统计","数据分析"))
#岗位薪资字段处理
index1 = job_info["岗位薪资"].str[-1].isin(["年","月"])
index2 = job_info["岗位薪资"].str[-3].isin(["万","千"])
job_info = job_info[index1 & index2]
job_info['平均薪资'] = job_info['岗位薪资'].astype(str).apply(lambda x:np.array(x[:-3].split('-'),dtype=float))
job_info['平均薪资'] = job_info['平均薪资'].apply(lambda x:np.mean(x))
#统一工资单位
job_info['单位'] = job_info['岗位薪资'].apply(lambda x:x[-3:])
job_info['公司领域'].value_counts()
def con_unit(x):
if x['单位'] == "万/月":
z = x['平均薪资']*10000
elif x['单位'] == "千/月":
z = x['平均薪资']*1000
elif x['单位'] == "万/年":
z = x['平均薪资']/12*10000
return int(z)
job_info['平均薪资'] = job_info.apply(con_unit,axis=1)
job_info['单位'] = '元/月'
#工作地点字段处理
job_info['工作地点'] = job_info['工作地点'].apply(lambda x:x.split('-')[0])
#公司领域字段处理
job_info['公司领域'] = job_info['公司领域'].apply(lambda x:x.split('/')[0])
#招聘人数字段处理
job_info['招聘人数'] = job_info['招聘人数'].apply(lambda x:x.replace("若干","1").strip()[1:-1])
#工作经验与学历要求字段处理
job_info['工作经验'] = job_info['工作经验'].apply(lambda x:x.replace("无需","1年以下").strip()[:-2])
job_info['学历需求'] = job_info['学历需求'].apply(lambda x:x.split()[0])
#公司规模字段处理
job_info['公司规模'].value_counts()
def func(x):
if x == '少于50人':
return "<50"
elif x == '50-150人':
return "50-150"
elif x == '150-500人':
return '150-500'
elif x == '500-1000人':
return '500-1000'
elif x == '1000-5000人':
return '1000-5000'
elif x == '5000-10000人':
return '5000-10000'
elif x == '10000人以上':
return ">10000"
else:
return np.nan
job_info['公司规模'] = job_info['公司规模'].apply(func)
#公司福利字段处理
job_info['公司福利'] = job_info['公司福利'].apply(lambda x:str(x).split())
#职位信息字段处理
job_info['职位信息'] = job_info['职位信息'].apply(lambda x:x.split('职能类别')[0])
with open(r"E:\C++\停用词表.txt",'r',encoding = 'utf8') as f:
stopword = f.read()
stopword = stopword.split()
job_info['职位信息'] = job_info['职位信息'].apply(lambda x:x.lower()).apply(lambda x:"".join(x)).apply(lambda x:x.strip()).apply(jieba.lcut).apply(lambda x:[i for i in x if i not in stopword])
cons = job_info['公司领域'].value_counts()
industries = pd.DataFrame(cons.index,columns=['行业领域'])
industry = pd.DataFrame(columns=['分词明细','行业领域'])
for i in industries['行业领域']:
words = []
word = job_info['职位信息'][job_info['公司领域'] == i]
word.dropna(inplace=True)
[words.extend(str(z).strip('\'[]').split("\', \'")) for z in word]
df1 = pd.DataFrame({'分词明细':words,
'行业领域':i})
industry = industry.append(df1,ignore_index=True)
industry = industry[industry['分词明细'] != "\\n"]
industry = industry[industry['分词明细'] != ""]
count = pd.DataFrame(industry['分词明细'].value_counts())
lst = list(count[count['分词明细'] >=300].index)
industry = industry[industry['分词明细'].isin(lst)]
#数据存储
industry.to_excel(r'E:\python爬虫\数据预处理\词云.xlsx')
job_info.to_excel(r'E:\python爬虫\数据预处理\前程无忧(已清洗).xlsx')