文章目录
- 一、Hadoop集群部署模式
- 二、配置固定IP
- 2.1、虚拟机DHCP
- 2.2、步骤
- 三、配置ssh无密码登录
- 3.1、SSH
- 3.2、MS架构
- 3.3、配置主节点无密码登录
- 四、配置Hadoop集群
- 4.1、上传并解压Hadoop安装包
- 4.2、修改配置文件:hadoop-env.sh
- 4.3、修改配置文件:core-site.xml & hdfs-site.xml
- 4.4、修改配置文件:mapred-site.xml & yarn-site.xml & workers
- 4.5、拷贝Hadoop安装包
- 4.6、创建数据目录
- 4.7、格式化HDFS
- 五、Hadoop配置参数介绍
- 六、Hadoop集群启动与监控
- 6.1、Hadoop集群启动报错及解决
- 6.2、查看监控
- 6.3、优化配置
一、Hadoop集群部署模式
Hadoop的安装部署的模式一共有三种:
- 独立模式(本地模式) standalone
默认的模式,无需运行任何守护进程(daemon),所有程序都在单个JVM上执行。由于在本机模式下测试和调试MapReduce程序较为方便,因此,这种模式适宜用在开发阶段。使用本地文件系统,而不是分布式文件系统。 - 伪分布模式 pseudo distributed
在一台主机模拟多主机。即Hadoop的守护程序在本地计算机上运行,模拟集群环境,并且是相互独立的Java进程。在单机模式之上增加了代码调试功能,允许检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。类似于完全分布式模式,因此,这种模式常用来开发测试Hadoop程序的执行是否正确。 - 完全分布模式 fulldistributed, Hadoop
完全分布模式的守护进程运行在由多台主机搭建的集群上,是真正的生产环境。
二、配置固定IP
2.1、虚拟机DHCP
DHCP(动态主机配置协议)是一个局域网的网络协议。指的是由服务器控制一段IP地址范围,客户机登录服务器时就可以自动获得服务器分配的IP地址和子网掩码。
简单理解为给其他主机随机分配IP地址。
2.2、步骤
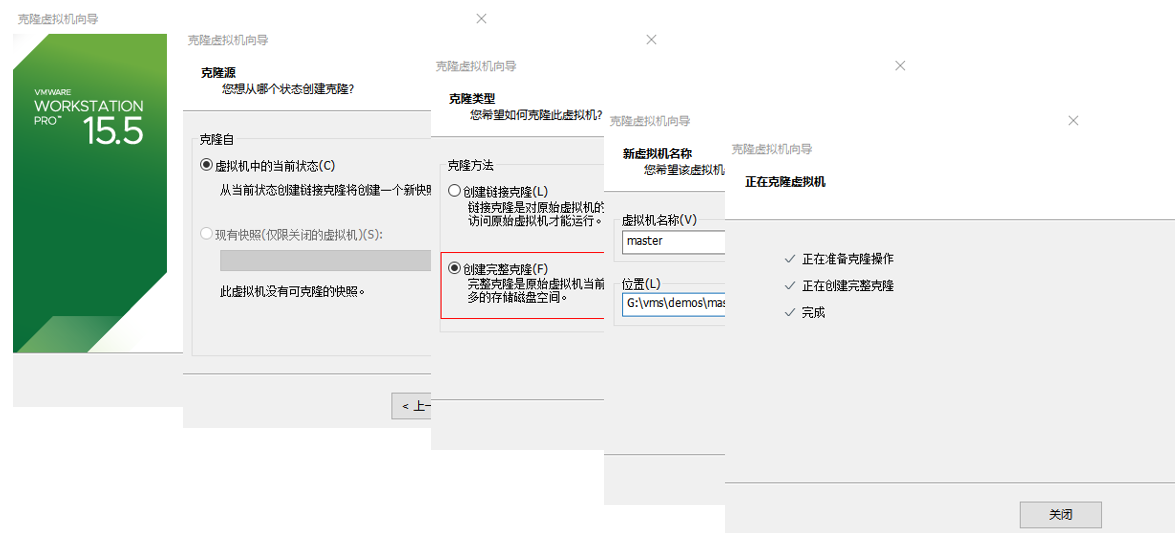
虚拟机克隆
虚拟机克隆分为“完整克隆”(Full Clone)和“链接克隆”(Linked Clone)两种方式:
- 完全克隆的虚拟机不依赖源虚拟机,是完全独立的虚拟机,它的性能与被克隆虚拟机相同。
- 链接克隆(Linked Clone)依赖于源虚拟机(称为父虚拟机)。由于链接克隆是通过父虚拟机的快照创建而成,因此节省了磁盘空间,而且克隆速度非常快,但是克隆后的虚拟机性能会有所下降。
虚拟机查看及修改机器名
注意:克隆机机器名仍是被克隆的机器名
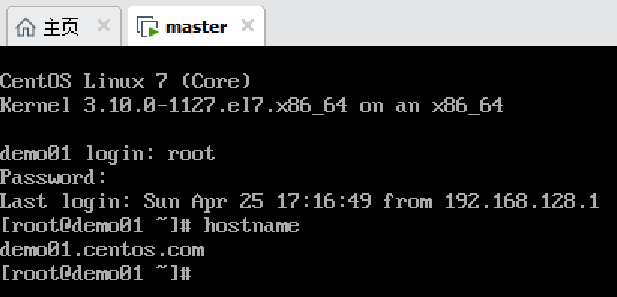
修改机器名指令:
hostnamectl set-hostname master #机器名改为master
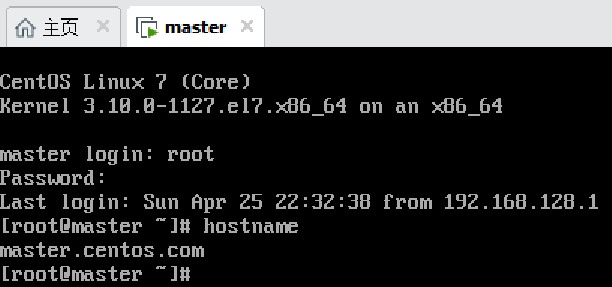
虚拟机查看及修改IP
由于IP使用的是DHCP,所以IP可能会是在范围内的任意值。
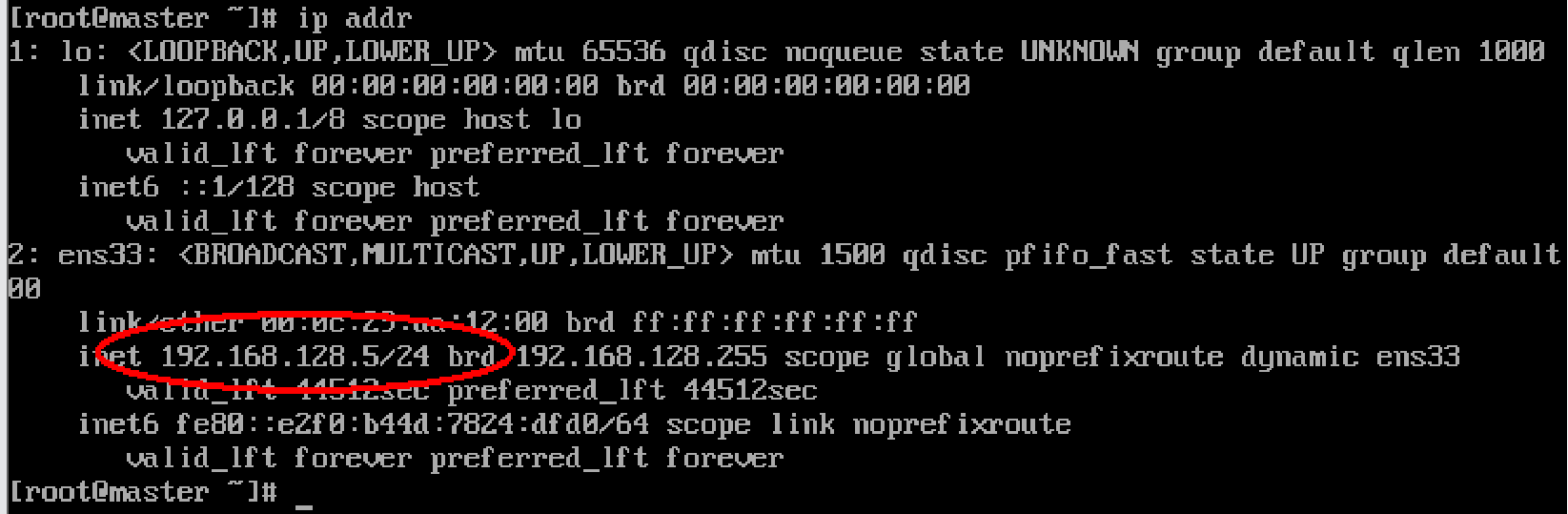
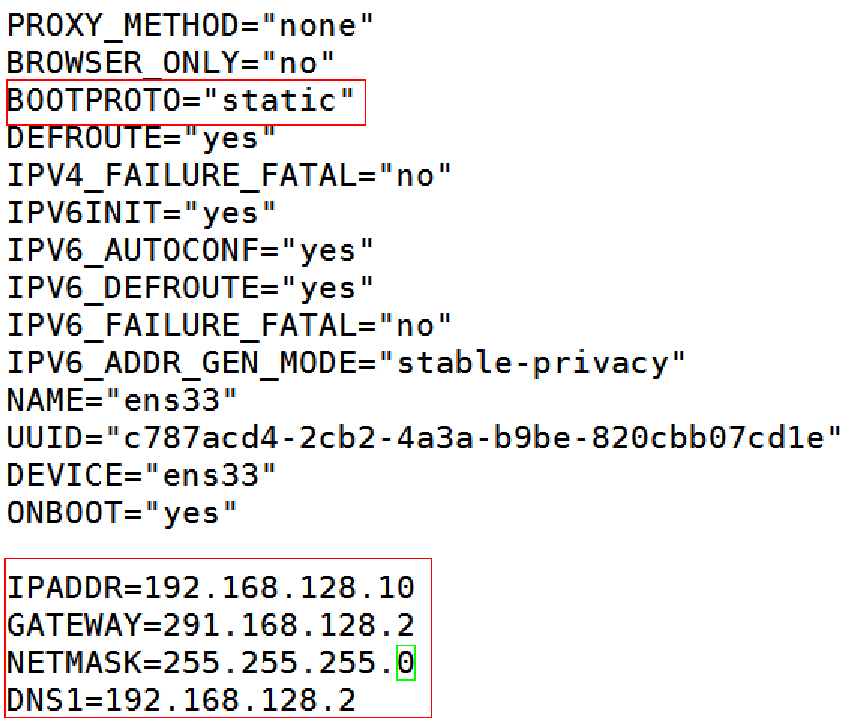
进入ifcfg-ens33 修改IP:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
然后我们再修改个东西:
vi /etc/hosts
添加:192.168.128.10 master master.centos.com
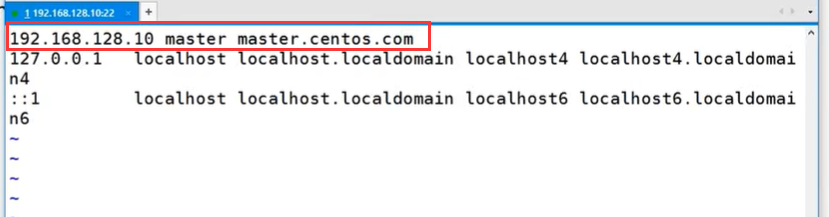
修改完后重启服务器:
service network restart
最后通过:
ping master
出现下面则配置完成:

虚拟机集群
虚拟机克隆node1, node2, node3, 并修改机器名及IP
这里node1为例:
修改机器名:
hostnamectl set-hostname node1 #node2、node3机器名就改为node2、node3
修改IP
vi /etc/sysconfig/network-scripts/ifcfg-ens33
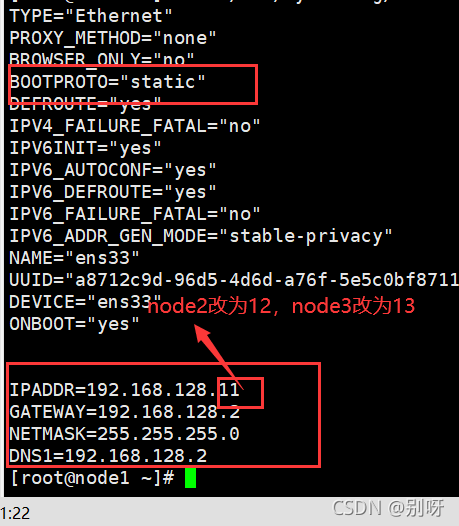
node1、node2、node3都配置完后,在master 、node1、node2、node3分别在在/etc/hosts添加如下:
192.168.128.10 master master.centos.com
192.168.128.11 node1 node1.centos.com
192.168.128.12 node2 node2.centos.com
192.168.128.13 node3 node3.centos.com
如:
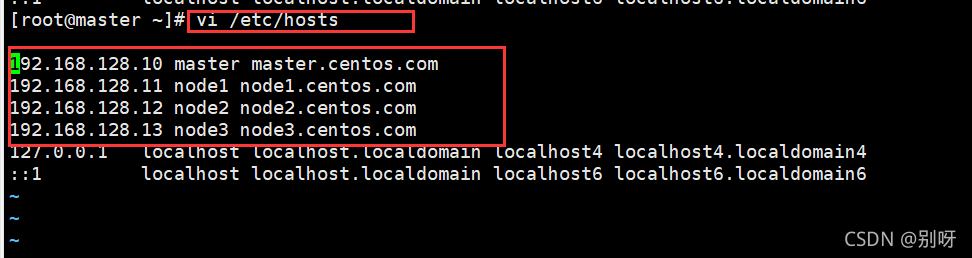
完成之后,使用ping指令查看情况
ping node1 #ping node2 ping node3
三、配置ssh无密码登录
3.1、SSH
SSH 为 Secure Shell 的缩写,由 IETF 的网络小组(Network Working Group)所制定;SSH 为建立在应用层基础上的安全协议。
SSH 是较可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。
SSH最初是UNIX系统上的一个程序,后来又迅速扩展到其他操作平台。几乎所有UNIX平台—包括HP-UX、Linux、AIX、Solaris、Digital UNIX、Irix,以及其他平台,都可运行SSH。
从客户端来看,SSH提供两种级别的安全验证:
第一种级别(基于口令的安全验证)
需要帐号和口令,就可以登录到远程主机。所有传输的数据都会被加密,但是不能保证正在连接的服务器就是你想连接的服务器。可能会有别的服务器在冒充真正的服务器,也就是受到“中间人”这种方式的攻击。
第二种级别(基于密匙的安全验证)
需要依靠密匙,也就是必须创建一对密匙,并把公用密匙放在需要访问的服务器上。如果要连接到SSH服务器上,客户端软件就会向服务器发出请求,请求用密匙进行安全验证。服务器收到请求之后,先在该服务器上的主目录下寻找公用密匙,然后把它和发送过来的公用密匙进行比较。如果两个密匙一致,服务器就用公用密匙加密“质询”(challenge)并把它发送给客户端软件。客户端软件收到“质询”之后就可以用私人密匙解密再把它发送给服务器。
3.2、MS架构
Hadoop是M-S架构,即Master-Slave架构。
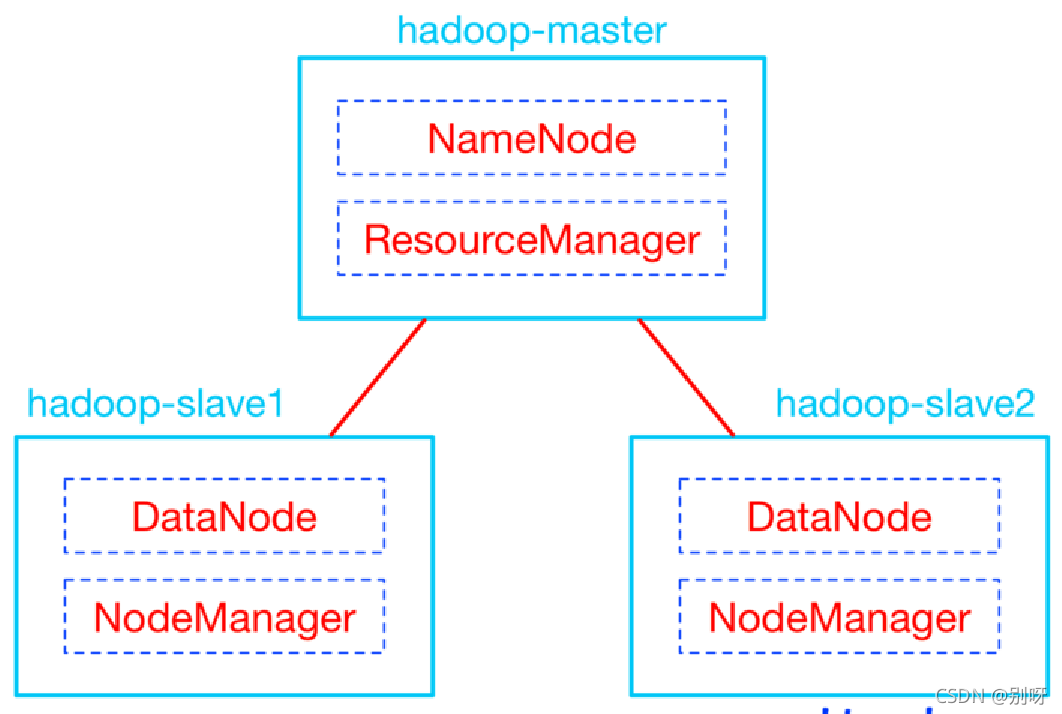
3.3、配置主节点无密码登录
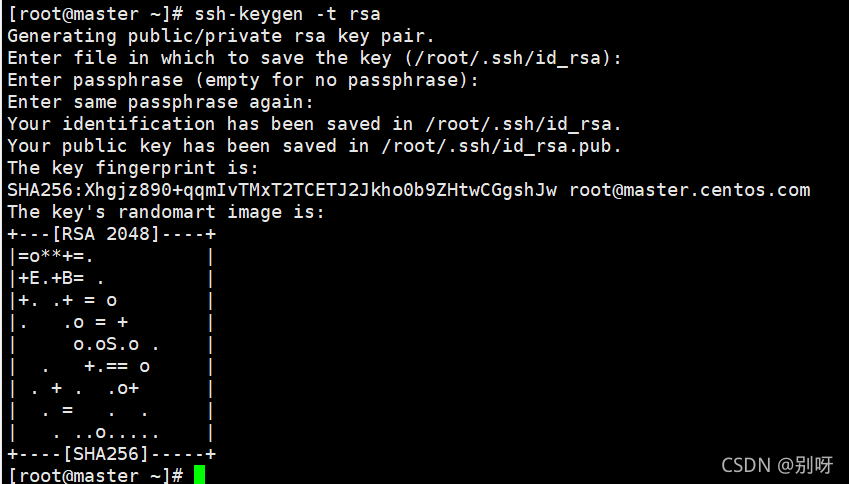
首先,生成密匙
ssh-keygen -t rsa
完成后,拷贝公匙(依次执行)
ssh-copy-id -i ~/.ssh/id_rsa.pub master
ssh-copy-id -i ~/.ssh/id_rsa.pub node1
ssh-copy-id -i ~/.ssh/id_rsa.pub node2
ssh-copy-id -i ~/.ssh/id_rsa.pub node3
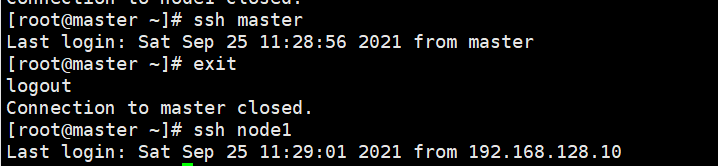
验证(依次执行):
ssh master
ssh node1
ssh node2
ssh node3
四、配置Hadoop集群
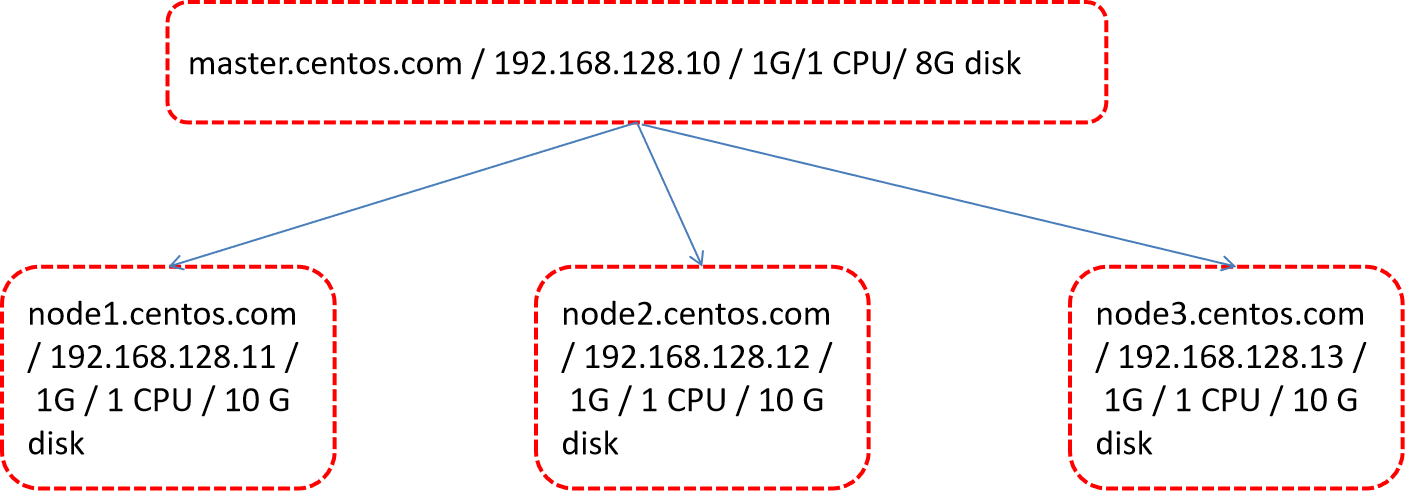
Hadoop集群总体规划
Hadoop集群安装采用下面步骤:
- 在Master节点:上传并解压Hadoop安装包 。
- 在Master节点:配置Hadoop所需configuration配置文件。
- 在Master节点:拷贝配置好的Hadoop安装包到其他节点。
- 在所有节点:创建数据存储目录 。
- 在Master节点:执行HDFS格式化操作。
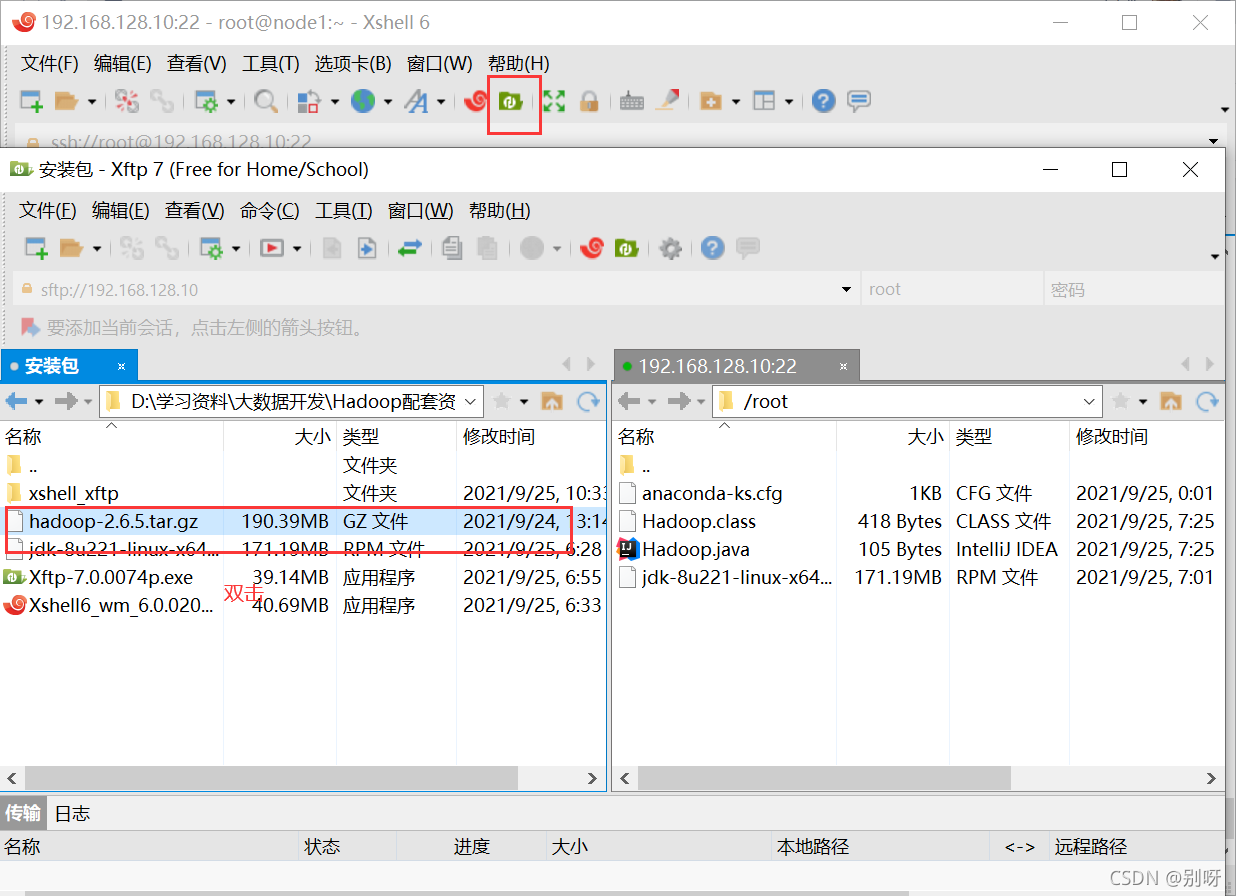
4.1、上传并解压Hadoop安装包
(这里我已经用Xshell连接到Master结点了)
Hadoop安装包链接:https://pan.baidu.com/s/1teHwnBH2Qm6F7iWZ3q-hSQ
提取码:cgnb
上传
完成后用 ls 指令查看
在这里插入图片描述
解压
tar -zxf hadoop-2.6.5.tar.gz -C /opt/

4.2、修改配置文件:hadoop-env.sh
首先进入/opt/hadoop-2.6.5/etc/hadoop/目录
cd /opt/hadoop-3.1.4/etc/hadoop/
配置hadoop-env.sh
vi hadoop-env.sh

4.3、修改配置文件:core-site.xml & hdfs-site.xml
首先进入/opt/hadoop-2.6.5/etc/hadoop/目录
cd /opt/hadoop-3.1.4/etc/hadoop/
配置core-site.xml
vi core-site.xml
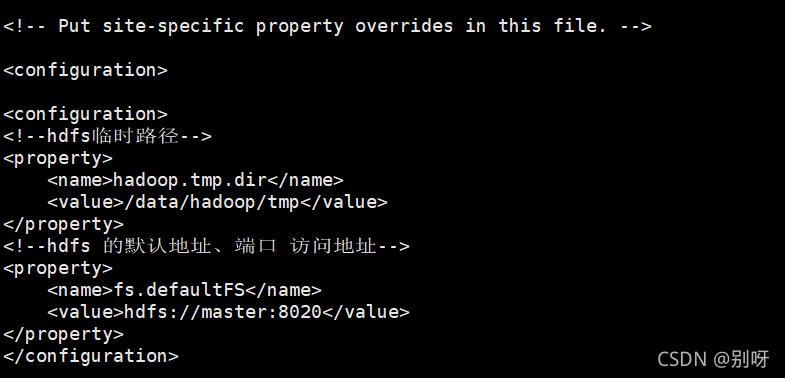
在<configuration> </configuration>间添加如下
<!--hdfs临时路径-->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
<!--hdfs 的默认地址、端口 访问地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
配置hdfs-site.xml
vi hdfs-site.xml
在<configuration> </configuration>间添加如下
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<!-- 副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 是否启用hdfs权限检查 false 关闭 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 块大小,默认字节, 可使用 k m g t p e-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/namenode</value>
</property>
<property>
<name>dfs.datanode.name.dir</name>
<value>/data/hadoop/datanode</value>
</property>
4.4、修改配置文件:mapred-site.xml & yarn-site.xml & workers
首先进入/opt/hadoop-2.6.5/etc/hadoop/目录
cd /opt/hadoop-3.1.4/etc/hadoop/
配置mapred-site.xml
vi mapred-site.xml
在<configuration> </configuration>间添加如下
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.1.4</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/hadoop-3.1.4/share/hadoop/mapreduce/*:/opt/hadoop-3.1.4/share/hadoop/mapreduce/lib/*</value>
</property>
配置yarn-site.xml
vi yarn-site.xml
在<configuration> </configuration>间添加如下
<!--集群master-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- NodeManager上运行的附属服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 关闭内存检测-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
配置workers
vi workers
把里面内容改为
node1
node2
node3
4.5、拷贝Hadoop安装包
进入/opt目录,通过指令(依次执行)拷贝到node1、node2、node3目录
(可以多建立几个会话,速度会快些)
scp -r hadoop-3.1.4/ node1:/opt/
scp -r hadoop-3.1.4/ node2:/opt/
scp -r hadoop-3.1.4/ node3:/opt/
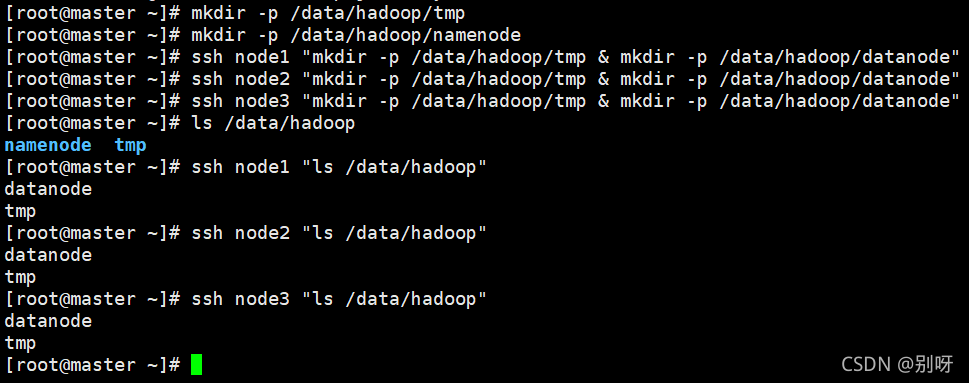
4.6、创建数据目录
(依次执行下面语句)
mkdir -p /data/hadoop/tmp
mkdir -p /data/hadoop/namenode
ssh node1 "mkdir -p /data/hadoop/tmp & mkdir -p /data/hadoop/datanode"
ssh node2 "mkdir -p /data/hadoop/tmp & mkdir -p /data/hadoop/datanode"
ssh node3 "mkdir -p /data/hadoop/tmp & mkdir -p /data/hadoop/datanode"
4.7、格式化HDFS
进入hadoop安装下的bin目录
cd /opt/hadoop-3.1.4/bin/
执行
./hdfs namenode -format demo
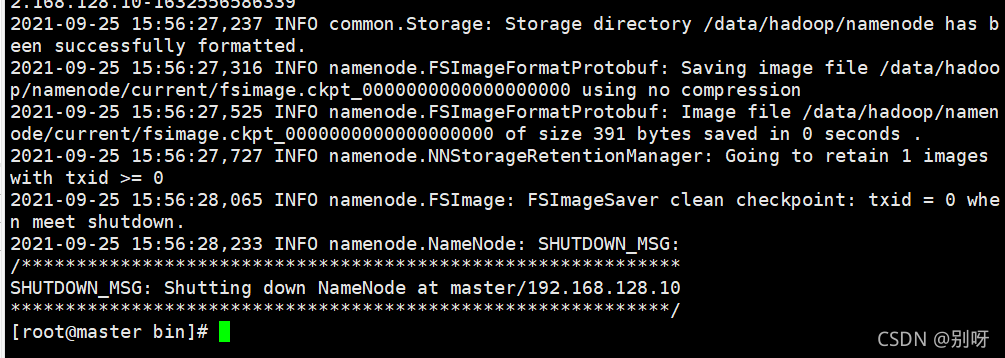
格式化完成,集群配置完成
五、Hadoop配置参数介绍
Hadoop集群配置文件主要有:
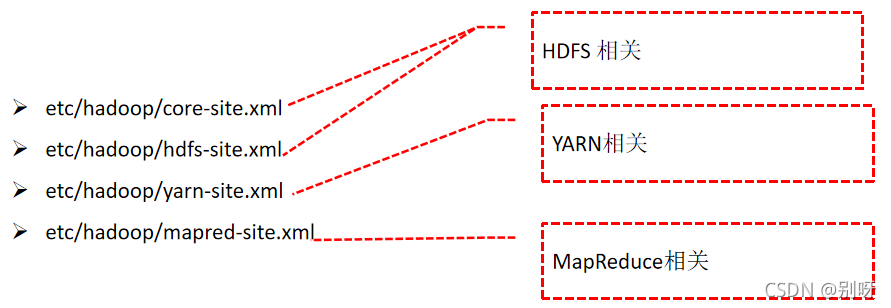
它们的默认参数配置可以看:
core-default.xml :https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/core-default.xml
hdfs-default.xml:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
mapred-default.xml:https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
yarn-default.xml:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
六、Hadoop集群启动与监控
Hadoop集群启动/关闭采用下面步骤:
启动:
- 在Master节点:$HADOOP_HOME/sbin/start-dfs.sh ,启动HDFS 。
- 在Master节点:$HADOOP_HOME/sbin/start-yarn.sh, 启动YARN。
- 在Master节点:$HADOOP_HOME/bin/mapred --daemon start historyserver,启动日志服务。
关闭:
- 在Master节点:$HADOOP_HOME/sbin/stop-dfs.sh ,关闭HDFS 。
- 在Master节点:$HADOOP_HOME/sbin/stop-yarn.sh, 关闭YARN。
- 在Master节点:$HADOOP_HOME/bin/mapred --daemon stop historyserver,关闭日志服务。
6.1、Hadoop集群启动报错及解决
报错:
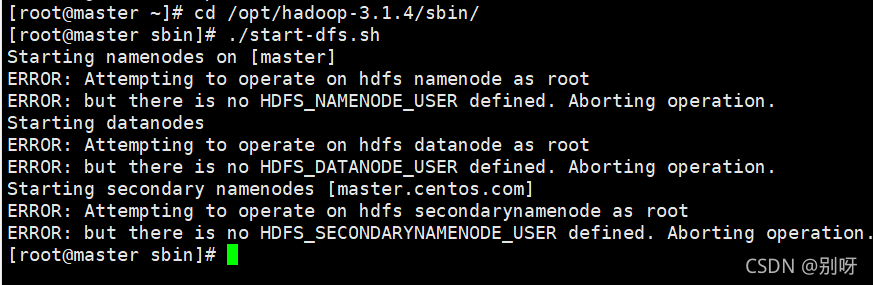
解决方法:
在/opt/hadoop-3.1.4/etc/hadoop/hadoop-env.sh添加如下语句
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
然后再拷贝到子节点
scp hadoop-env.sh node1:/opt/hadoop-3.1.4/etc/hadoop/
scp hadoop-env.sh node2:/opt/hadoop-3.1.4/etc/hadoop/
scp hadoop-env.sh node3:/opt/hadoop-3.1.4/etc/hadoop/
修改完后,启动HDFS可以看到:
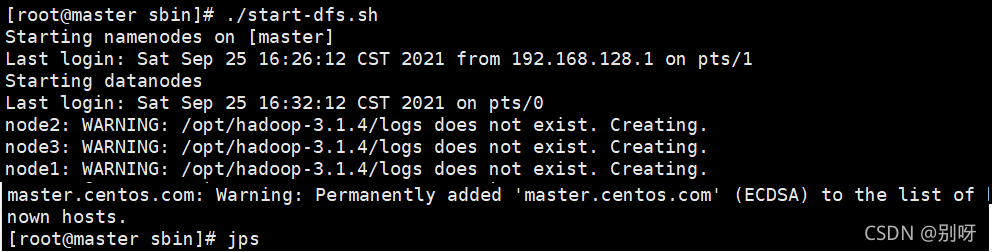
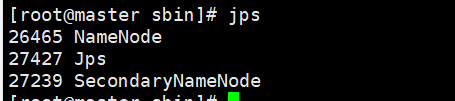
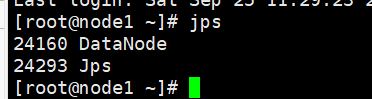
启动YARN
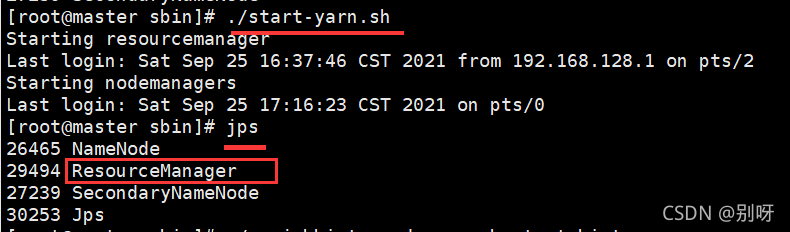
启动mapred
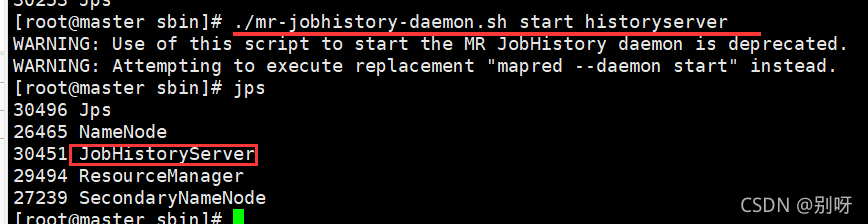
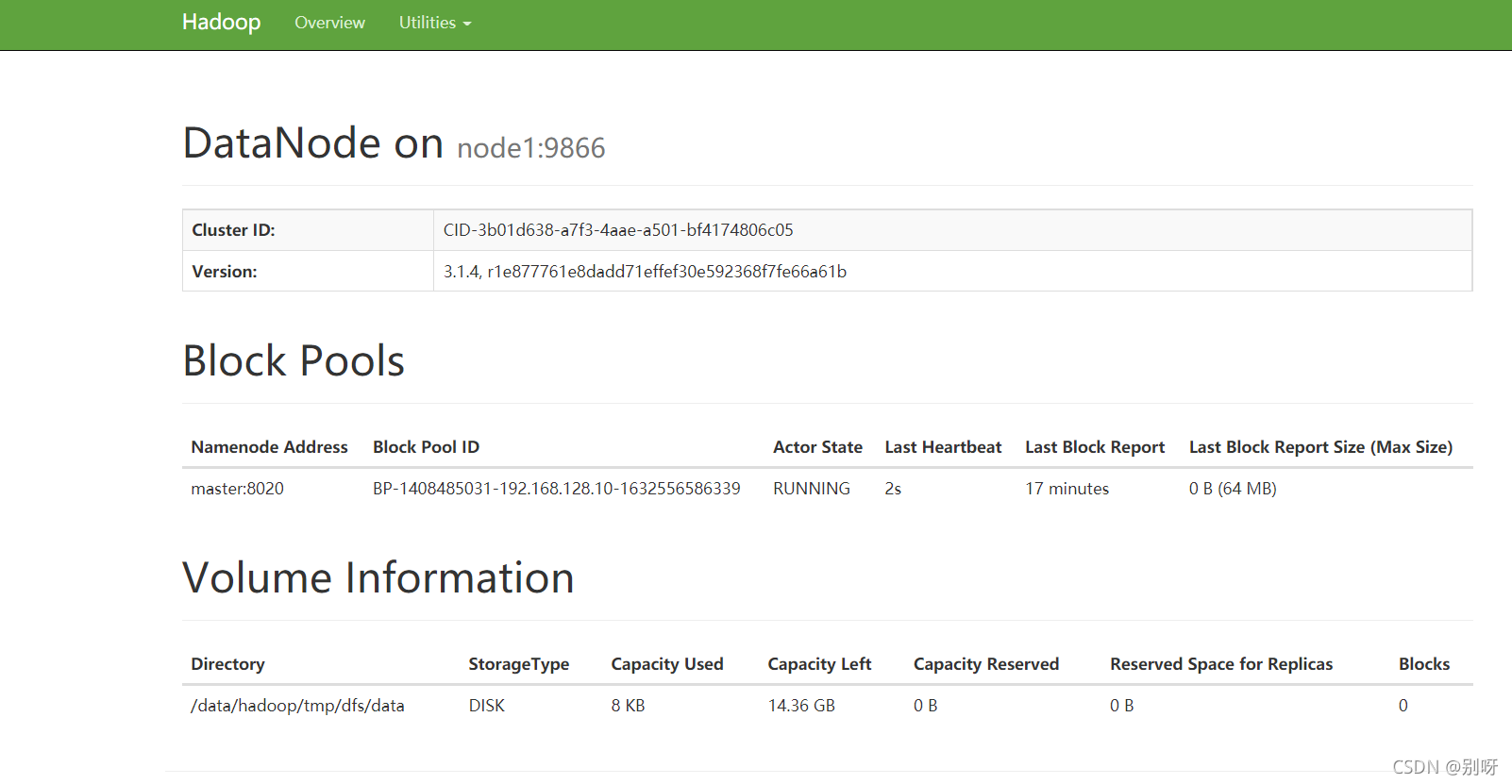
6.2、查看监控
在浏览器输入网址:192.168.128.10:50070
注意:看服务有没有开启;要记得关闭防火墙,否则会出现无法访问网站
服务已开启:
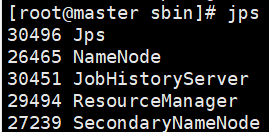
查看防火墙状态:
systemctl status firewalld.service
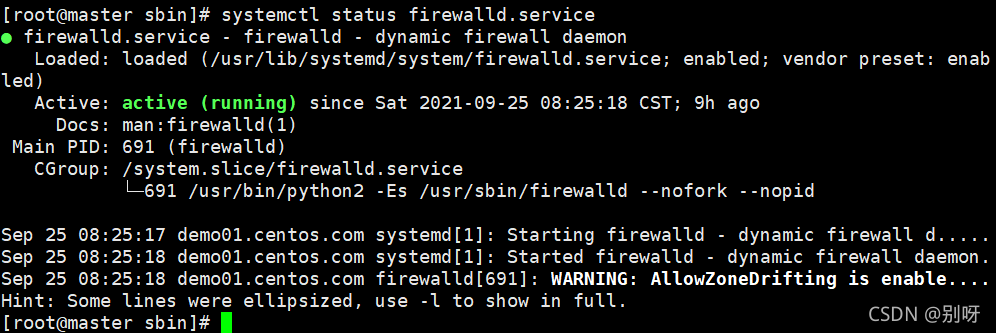
关闭防火墙:
systemctl stop firewalld.service
永久关闭防火墙:
systemctl disable firewalld.service
同时,我们也要把子节点的防火墙关掉:
ssh node1 "systemctl stop firewalld.service & systemctl disable firewalld.service"
ssh node2 "systemctl stop firewalld.service & systemctl disable firewalld.service"
ssh node3 "systemctl stop firewalld.service & systemctl disable firewalld.service"
最后,我们重新输入网址就可以看到界面了
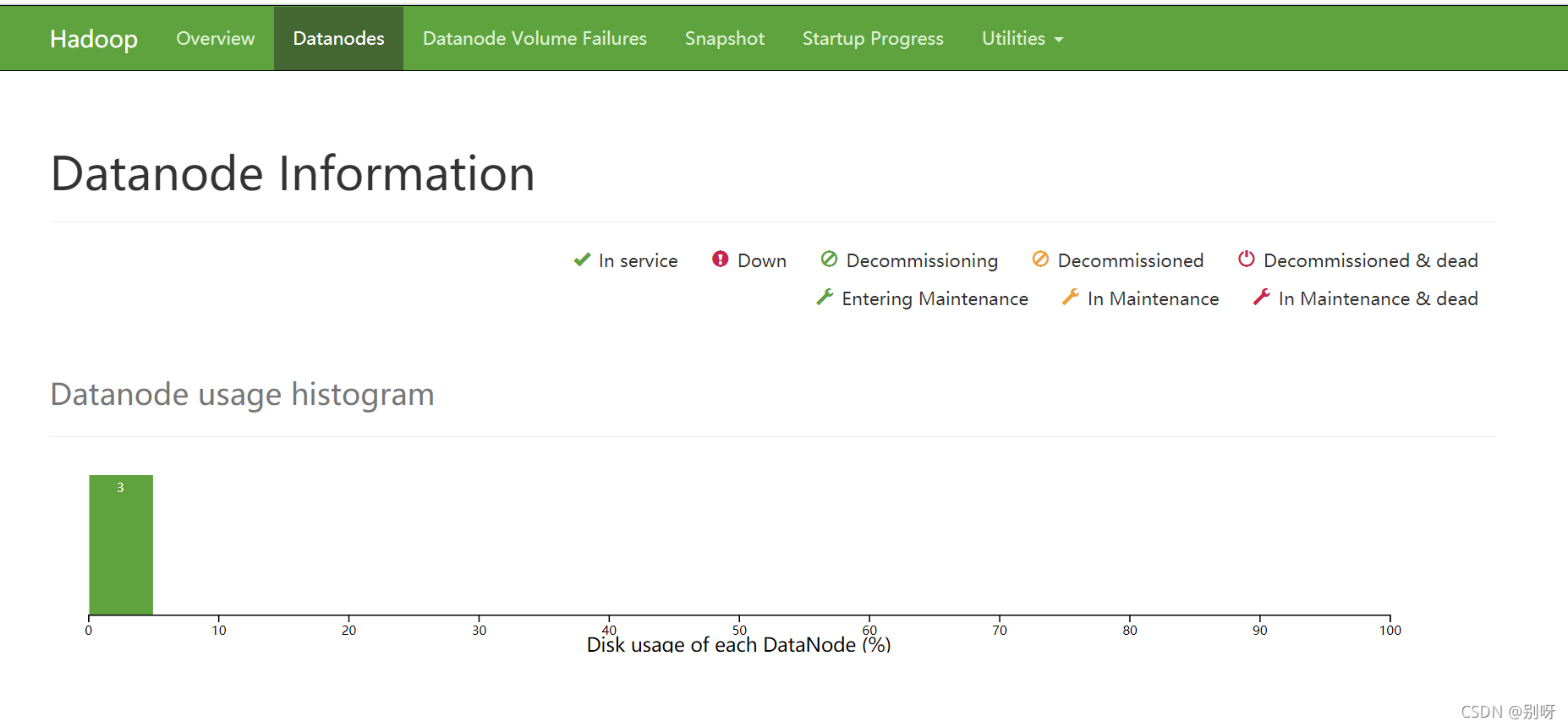
6.3、优化配置
在网址输入:node1:9864 发现无法访问,因此我们要设置机器名与IP映射
机器名与IP映射设置
打开C:\Windows\System32\drivers\etc\hosts添加如下:
192.168.128.10 master master.centos.com
192.168.128.11 node1 node1.centos.com
192.168.128.12 node2 node2.centos.com
192.168.128.13 node3 node3.centos.com
(如果遇到hosts没有权限无法更改,参考这篇博客:https://blog.csdn.net/ahmcwt/article/details/109578320)
完成!