前言:
一个月前,博主在学过python(一年前)、会一点网络(能按F12)的情况下,凭着热血和兴趣,开始了python爬虫的学习。一路过来走了相当多弯路,但是前不久终于成功了!!!(泪目)
经过一个月的学习,博主我感觉CSDN上图片爬取教程确实详细且方法繁多,但大都偏公式化或者不够贴近小白。且本小白也亲身经历了整个从小白到爬虫初入门的过程,因此就斗胆在CSDN上开一个栏目,以我的python图片爬虫全实现过程为例,以期用更简单、清晰、详尽的方式来帮助更多小白应对更大多数的爬虫实际问题。
第一次写blog真的十分激动!!!希望大家多多鼓励点赞,过路大神多多指教,写得不对的地方请直接指出!!!
本栏目大致会分为4章(有空马上更)分别是:
- 环境配置+基础知识
- 获取图片地址+根据地址下载图片
- 翻页+反爬+完整代码
- 爬虫实战案例:爬取网站商品信息
正文:
博主本人用的是window10系统、python3.8(需要add to path)和pycharm
所谓之所以要基于selenium库爬虫,是因为现在网页大部分由JavaScript语言所写,特点是动态加载网络元素,网络元素经过浏览器渲染才向用户显示(表现为在网页右键查看源码和按F12调出开发者工具看到的网络元素不尽相同),用requests库不能实现爬虫,而selenium库能模拟用户使用浏览器,能很好地处理绝大多数的网络爬虫。本文开始几个篇章以图片爬虫为例,后面附一个爬取京东iPhone价格、商品名称、评论、店铺信息的实例。
开始前,我想说看视频是最最快的学习方法,个人是在B站学到了requests库实战和selenium库实战(两个视频都是我看过那么多最详细最好的,链接【1】【2】我放在下面)。期间在网络基础和浏览器知识这一块也参考了紫书《python网络爬虫权威指南》,还有关于网络想要深入了解的同学可以看链接【3】。
新手警告:刚开始爬虫建议用IDLE!!!
新手警告:刚开始爬虫建议用IDLE!!!
新手警告:刚开始爬虫建议用IDLE!!!
(selenium库查找不到元素就会报错容易把心态搞崩,建议一步步在IDLE上执行,最后适当加上time.sleep()复制到pycharm)
- 【1】Python爬虫实战教程:批量爬取某网站图片_哔哩哔哩_bilibili
- 【2】Python爬虫+反爬虫实战【数据爬取+数据解析+scrapy+selenium+反爬虫】_哔哩哔哩_bilibili
- 【3】HTML 教程 | 菜鸟教程
一、环境
01浏览器环境
from selenium import webdriver
driver = webdriver.Chrome()#用谷歌浏览器
#driver = webdriver.Edge()#用Microsoft Edge
#driver = webdriver.PhantomJS()#用无头浏览器- 用selenium库爬虫需要用到driver,也就是可供selenium库使用的浏览器.exe,调用的时候如上
- 下载对应浏览器可在CSDN查找就可,附带教程很详细(搜索:‘“selenium库webdriver+浏览器名称”)
- 所谓无头浏览器就是不显示界面的浏览器,但可以通过截图了解状态
注意:
- 下载webdriver时需选择和自己当前浏览器的版本一致
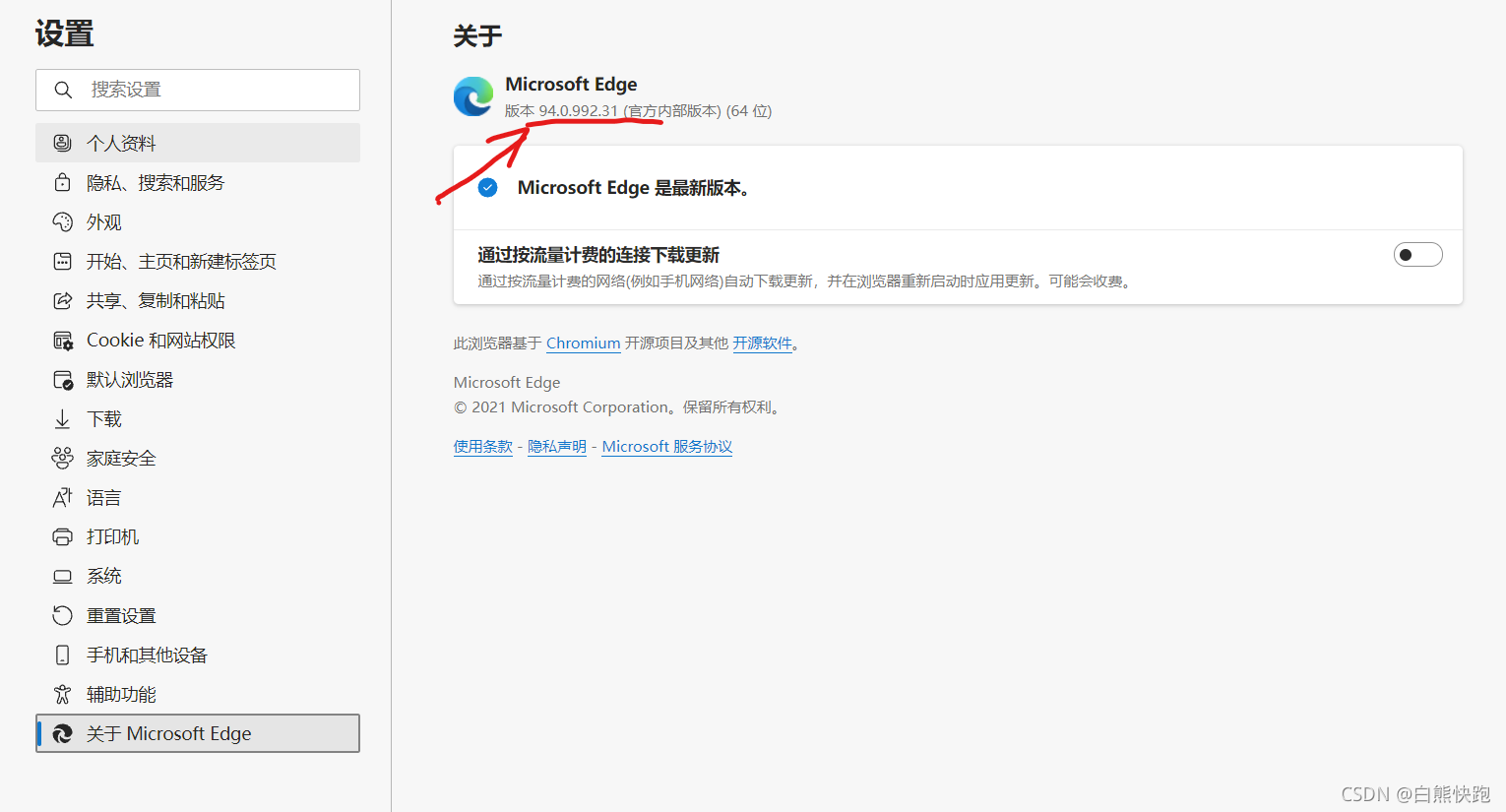
2. 下载后的浏览器.exe直接拖动到python所在地址。python所在地址可直接window键+R,再输入cmd调出命令行窗口输入“where python”就找到python路径了。
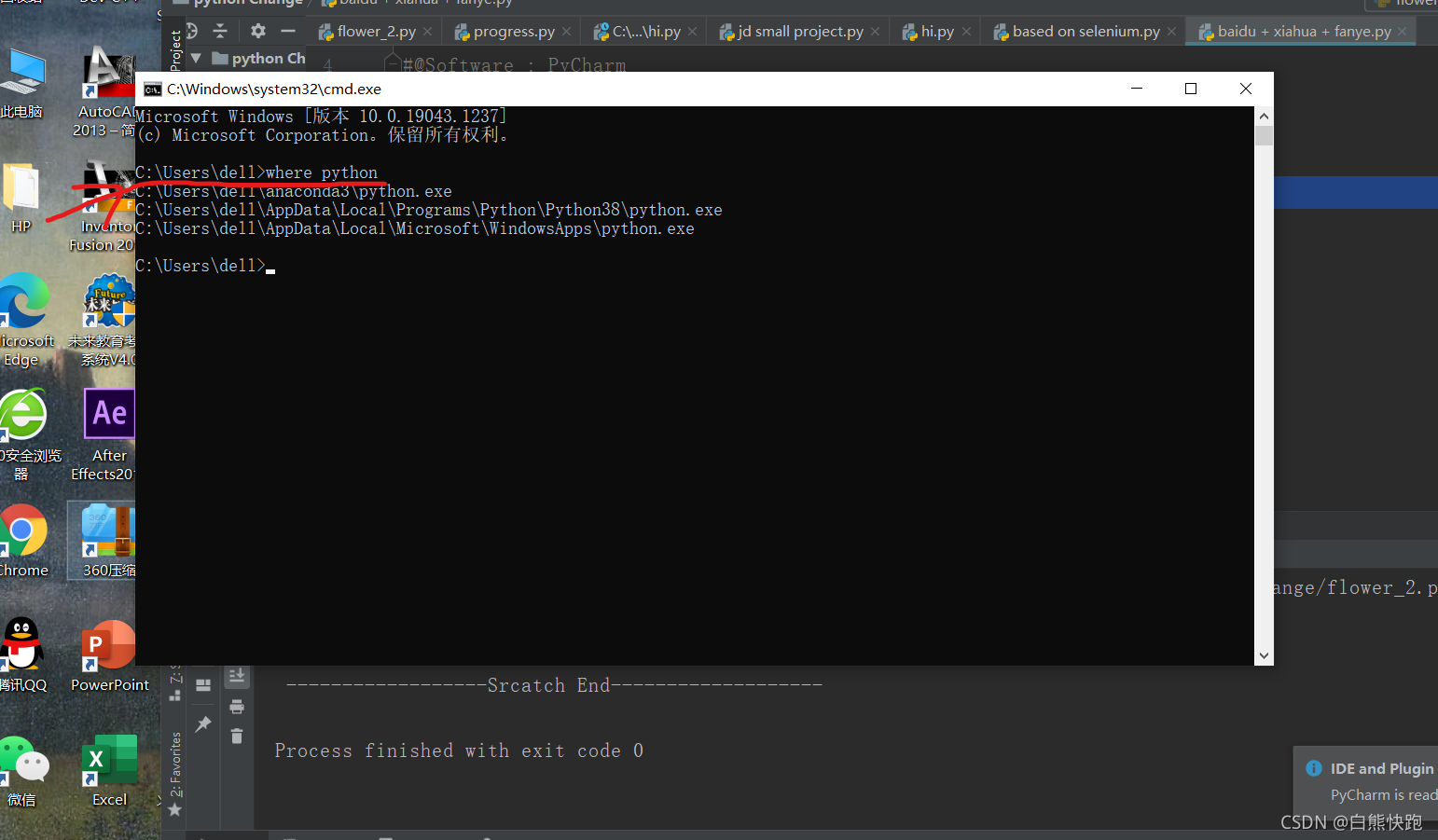
然后就可正常使用webdriver了。
02下载外部库
也是在命令行窗口,先输入python看下python是否正常加到path
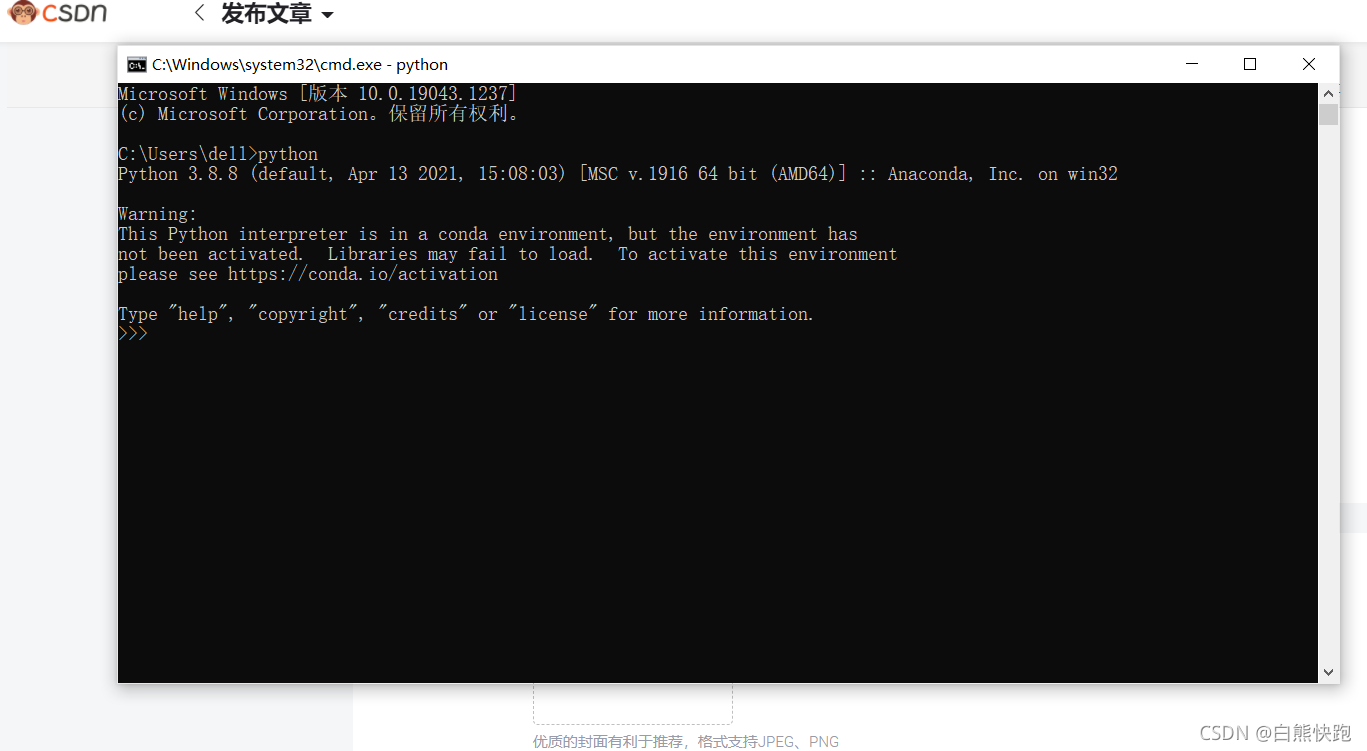
然后先输入“quit()”退出python,再依次输入“pip install selenium”,“pip install requests”,如出现“...install successfully”不报错就是安装成功(warning不用管)、
注意:如果报错可以改成“pip3 install selenium”,“pip3 install requests”
二、基础知识
这里比较重要的是字符串操作和网页知识(主要是一些快捷键)
01字符串操作
主要用到的功能是截取、相加(也就是拼接),以及format函数(可用于字符串拼接)和split函数(用于选取字符串内容),需要用的时候去CSDN查看即可。在爬取图片时一般用于修正图片地址和创建图片名称
02数组知识
主要用到选取元素和遍历
03通过requests库从图片地址下载图片
其实是一组模块,和创建文件模块一起使用(后面的bloc会说的)
04网页基础知识
重点说说网页基础知识,爬虫中很需要实时根据网页内容改变爬取方法。
- 首先需要的是开发者工具,有的同学可以直接按F12调出,有的需要手动按一按。我们需要点击右边的“元素”,然后在页面中选择一个元素右键点击“检查”,就可以找到对应的代码。
2.然后具体说说网页元素
- 节点的名称有的叫div,有的叫a,有的叫img。
- 我们所需的要素也有一个名称,有的叫class,有的叫id,有的叫src。
- 这些节点里面的要素有一个值(比如class=“”里面的东西),网页上所有的元素,都存放在这一个个值中。通过这些要素的值,我们可以寻找到特定的节点;也可以根据值的名称,在节点里获取这个值
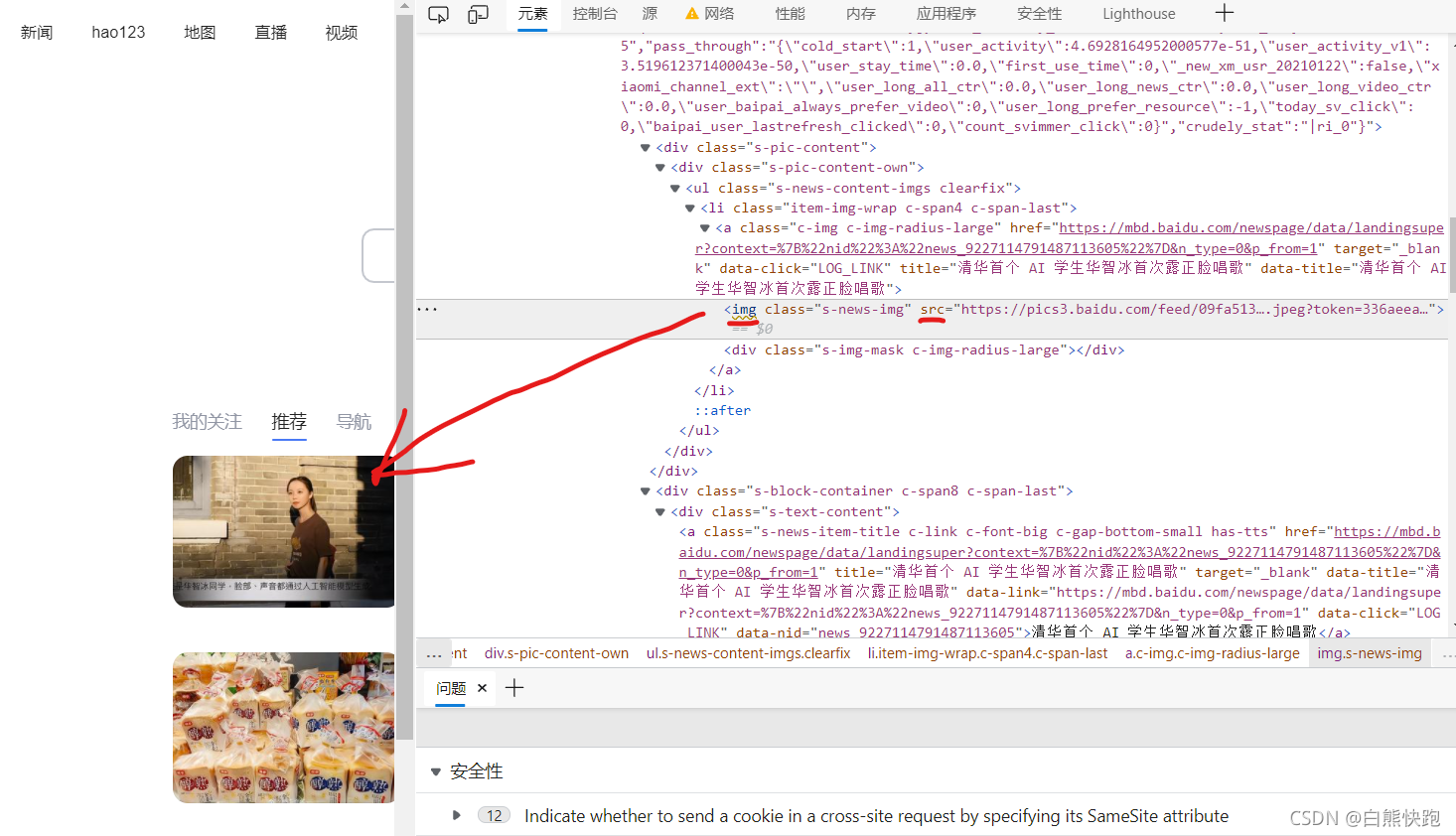
- 我们所需的图片地址,一般就是img节点的src要素的值(如下图)
注意:
- 在开发者工具中可按Ctrl+F查找需要的网页元素
- “元素”的左边按钮可把页面从电脑模式切换成手机模式,再左边按钮按动后划过网页元素会自动跳到对应代码
下一篇获取图片地址+根据地址下载图片是重头戏,喜欢的朋友请追更。
码字不易求点赞!