学习总结
- 传统深度学习模型如 LSTM 和 CNN在欧式空间中表现不俗,却无法直接应用在非欧式数据上。因此大佬们通过引入图论中抽象意义上的“图”来表示非欧式空间中的结构化数据,并通过图卷积网络来提取(graph)的拓扑结构,以挖掘蕴藏在图结构数据中的深层次信息。
- GCN的本质:图中的每个结点无时无刻不因为邻居和更远的点的影响而在改变着自己的状态直到最终的平衡,关系越亲近的邻居影响越大。
- K i p f Kipf Kipf 大佬并非拍脑子就想出所有的算法和公式,先是图信号分析和图谱论搭建谱图卷积网络,然后Deferrard等人为了解决前者求图拉普拉斯矩阵的特征向量、每次向前传递的矩阵运算等的时间复杂度较高,提出切比雪夫网络(用了 C h e b S h e v ChebShev ChebShev 多项式展开近似);而本次的主角一作Kipf为了进一步简化 C h e b N e t ChebNet ChebNet,即将其中的多项式卷积核限定为1阶(只使用一阶 C h e b S h e v ChebShev ChebShev 多项式),将图卷积近似成一个关于 D ~ \tilde{D} D~ 的线性函数,于是有了下面的故事。
- 论文的附录WL理论可以回顾【GNN】task6-基于图神经网络的图表征学习方法,论文中的附录部分的实验还没细看。
文章目录
- 学习总结
- 零、Abstract
- 一、Introduction
- 1.1 经典的分类方法
- (1)Standard Approach
- (2)Embedding-based Approach
- 1.2 本文的工作
- 1.3 数学符号说明:
- 二、Fast approximate convolutions on graphs
- 2.1 Spectral graph convolutions
- (1)谱图卷积网络
- (2)切比雪夫近似谱卷积
- (3)写回L的函数
- 2.2 Layer-wise linear model 逐层线性模型
- (1)简化:K=1(2个参数的模型)
- (2)简化:1个参数的模型
- (3)推广:特征映射公式
- 三、Semi-supervised node classification
- 3.1 Example
- (1)预处理操作
- (2)交叉熵误差
- (3)训练
- 3.2 Implementation
- 四、Related work
- 4.1 Graph-based semi-supervised learning
- 4.2 Neural networks on graphs
- 五、Experiments
- 5.1 Datasets
- (1)Citation networks
- (2)NELL
- (3)Random graphs
- 5.2 Experimental set-up 参数设置
- 5.3 Baselines
- 六、Results
- 6.1 Semi-supervised node classification
- 6.2 Evaluation of propagation model
- 6.3 Training time per epoch
- 七、Discussion
- 7.1 Semi-supervisied model
- 7.2 Limitations and future work
- (1)内存要求较大
- (2)不支持边的特征
- (3)硬性假定
- 八、Conclusion
- 附录A:Relation to Weisfeiler-Lehman algorithm
- A.1 Node embeddings with random weights
- A.2 Semi-supervised node embedding
- 附录B:Experiments on model depth
- Reference

论文:GCN - Semi-Supervised Classification with Graph Convolutional Networks
题目中文:用图卷积进行半监督节点分类
论文作者:Thomas N. Kipf, Peter Bloem, Rianne van den Berg, Ivan Titov, Max Welling
论文来源:ICLR 2017
论文链接:https://arxiv.org/abs/1609.02907
一作代码pytorch版:https://github.com/tkipf/pygcn
一作代码tensorflow版:https://github.com/tkipf/gcn
零、Abstract
本文提出一种具有可扩展性的用于图数据结构的半监督学习的方法。我们通过谱图卷积(spectral graph convolution)的局部一阶近似(localized first-order approximation),方便确定选择我们的卷积结构。GCN模型的规模会随着图中边的数量的增长而线性增长。GCN能够学习编码局部图结构和节点特征的隐藏层表示。在引文数据集和知识图数据集上的多次实验表明,本文的方法明显优于该领域的相关方法。
一、Introduction
基于图的半监督学习:给定的图结构的数据中,只有少部分节点是有标记(label)的,任务就是预测出未标记节点的label。
1.1 经典的分类方法
(1)Standard Approach
基于平滑正则(假设相邻的节点具有相似的label)
论文:[Zhu et al., 2003]
L
=
L
0
+
λ
L
reg
,
\mathcal{L}=\mathcal{L}_{0}+\lambda \mathcal{L}_{\text {reg }},
L=L0+λLreg ,
with
L
reg
=
∑
i
,
j
A
i
j
∥
f
(
X
i
)
−
f
(
X
j
)
∥
2
=
f
(
X
)
⊤
Δ
f
(
X
)
.
\text { with } \quad \mathcal{L}_{\text {reg }}=\sum_{i, j} A_{i j}\left\|f\left(X_{i}\right)-f\left(X_{j}\right)\right\|^{2}=f(X)^{\top} \Delta f(X) \text {. }
with Lreg =i,j∑Aij∥f(Xi)−f(Xj)∥2=f(X)⊤Δf(X). 第一项是fitting error,即在有label的数据上的误差;
第二项是平滑正则项,两个节点的
A
i
j
A_{ij}
Aij越大,表明越相关,即标记应该越接近。
平滑性假设限制了模型的表达能力(因为节点相连不一定都是相似,会包含附加条件)。
(2)Embedding-based Approach
1)学习每个节点的embedding
2)学的embedding上训练一个分类器
- DeepWalk –[Perozzi et al., 2014]
- node2vec –[Grover & Leskovec, 2016]
1.2 本文的工作
- 作者对Defferrard的工作进一步简化,每个卷积层仅处理一阶邻居特征,通过分层传播规则(聚合函数)叠加一个个卷积层达到多阶邻居特征传播。
- 演示了GCN如何应用与图中节点的快速和扩展的半监督分类任务。将GCN在多个数据集上实验表明,模型在分类进度和效率(以wall-clock衡量)方面都优于当前优秀的半监督学习方法。
1.3 数学符号说明:
-
G = ( V , E ) \mathcal{G}=(\mathcal{V},\mathcal{E}) G=(V,E)表示一个图, V \mathcal{V} V、 E \mathcal{E} E分别表示点集与边集, u , v ∈ V u, v \in \mathcal{V} u,v∈V表示图中的节点, ( u , v ) ∈ E (u, v) \in \mathcal{E} (u,v)∈E表示图中的边。
-
A A A为图中的邻接矩阵(adjacency matrix)
-
D D D为图中的度矩阵(degree matrix), D i D_{i} Di表示节点 i i i 的度,显然度矩阵是一个对角矩阵。
-
L L L为图中的拉普拉斯矩阵(Laplacian matrix), L \mathcal{L} L为图中的归一化的拉普拉斯矩阵: L s y s = D − 1 / 2 L D − 1 / 2 = I − D − 1 / 2 A D − 1 / 2 L^{s y s}=D^{-1 / 2} L D^{-1 / 2}=I-D^{-1 / 2} A D^{-1 / 2} Lsys=D−1/2LD−1/2=I−D−1/2AD−1/2
二、Fast approximate convolutions on graphs
经过作者的一系列推导(下文会讲过程),得到了图卷积神经网络的(单层)最终形式:
H
(
l
+
1
)
=
f
(
H
l
,
A
)
=
σ
(
D
~
−
1
/
2
A
~
D
~
−
1
/
2
H
(
l
)
W
(
l
)
)
(
6
)
H^{(l+1)}=f\left(H^{l}, A\right)=\sigma\left(\tilde{D}^{-1 / 2} \tilde{A} \tilde{D}^{-1 / 2} H^{(l)} W^{(l)}\right) \qquad (6)
H(l+1)=f(Hl,A)=σ(D~−1/2A~D~−1/2H(l)W(l))(6) 其中:
- 第 l l l 层网络的输入为 H ( l ) ∈ R N × D H^{(l)} \in \mathbb{R}^{N \times D} H(l)∈RN×D (初始输入为 H ( 0 ) = X H^{(0)}=X H(0)=X), N N N 为图中的节点数量,每个节点使用 D D D 维的特征向量进行表示。
- A ~ = A + I N \tilde{A}=A+I_{N} A~=A+IN为添加了自连接的邻接矩阵, D ~ \tilde{D} D~ 为度矩阵, D ~ i i = Σ j A ~ i j \tilde{D}_{i i}=\Sigma_{j} \tilde{A}_{i j} D~ii=ΣjA~ij。
- W ( l ) ∈ R D × D W^{(l)} \in \mathbb{R}^{D \times D} W(l)∈RD×D为待训练的参数
- σ \sigma σ 为相应的激活函数,例如 R e L U ( ⋅ ) = m a x ( 0 , ⋅ ) ReLU(·)=max(0, ·) ReLU(⋅)=max(0,⋅)
2.1 Spectral graph convolutions
(1)谱图卷积网络
一开始我们考虑信号
x
∈
R
N
x∈\mathbb{R}^N
x∈RN(通常是节点的特征向量)与以参数为
θ
∈
R
N
θ∈\mathbb{R}^N
θ∈RN的滤波器
g
θ
=
d
i
a
g
(
θ
)
g_θ=diag(θ)
gθ=diag(θ)在傅里叶域的谱卷积。
g
θ
∗
x
=
U
g
θ
U
T
x
(
3
)
g_{\theta} * x=U g_{\theta} U^{T} x \qquad (3)
gθ∗x=UgθUTx(3)
其中U是对称归一化的拉普拉斯算子
L
=
I
N
−
D
−
1
/
2
A
D
−
1
/
2
=
U
Λ
U
T
L=I_{N}-D^{-1 / 2} A D^{-1 / 2}=U \Lambda U^{T}
L=IN−D−1/2AD−1/2=UΛUT的特征向量矩阵,
Λ
\Lambda
Λ是由
L
L
L的特征向量构成的对角矩阵。
L
=
D
−
1
2
(
D
−
A
)
D
−
1
2
=
D
−
1
2
D
D
−
1
2
−
D
−
1
2
A
D
−
1
2
=
I
N
−
D
−
1
2
A
D
−
1
2
\begin{aligned} L &=D^{-\frac{1}{2}}(D-A) D^{-\frac{1}{2}} \\ &=D^{-\frac{1}{2}} D D^{-\frac{1}{2}}-D^{-\frac{1}{2}} A D^{-\frac{1}{2}} \\ &=I_{N}-D^{-\frac{1}{2}} A D^{-\frac{1}{2}} \end{aligned}
L=D−21(D−A)D−21=D−21DD−21−D−21AD−21=IN−D−21AD−21由于
L
L
L是实对称矩阵,因此其特征向量矩阵
U
U
U是正交矩阵,即
U
U
T
=
I
N
UU^{T}=I_{N}
UUT=IN
- U T x U^Tx UTx是 x x x的傅里叶变换
- g θ g_\theta gθ是由参数 θ \theta θ构成的对角矩阵 d i a g ( θ ) diag(\theta) diag(θ)。由于参数 θ \theta θ的确定与L的特征值有关,作者认为 g θ g_\theta gθ是特征值 Λ \Lambda Λ的一个函数,即令 g θ = g θ ( Λ ) g_\theta=g_\theta(\Lambda) gθ=gθ(Λ)
(2)切比雪夫近似谱卷积
其中(3)的计算量很大,因为特征向量矩阵U的复杂度是
O
(
N
2
)
O(N^{2})
O(N2)。另外对于大型图来说,L的特征值分解的计算量很大。为了解决这个问题,Hammond et al.(2011) :Wavelets on graphs via spectral graph theory论文指出
g
θ
(
Λ
)
g_{\theta}(\Lambda)
gθ(Λ)可以很好的通过Chebyshev多项式
T
k
(
x
)
T_k(x)
Tk(x)的Kth阶截断展开来拟合,并对
Λ
\Lambda
Λ进行scale使其元素位于[-1, 1]:
g
θ
(
Λ
)
≈
∑
k
=
0
K
θ
k
T
K
(
Λ
~
)
(
4
)
g_{\theta}(\Lambda) \approx \sum_{k=0}^{K} \theta_{k} T_{K}(\tilde{\Lambda}) \qquad (4)
gθ(Λ)≈k=0∑KθkTK(Λ~)(4)其中:
- Λ ~ = 2 Λ / λ max − I N \tilde{\Lambda}=2 \Lambda / \lambda_{\max }-I_{N} Λ~=2Λ/λmax−IN 是缩放后的特征向量矩阵,缩放后的范围是[-1, 1],单位矩阵的特征值是n重1。缩放的目的是为了满足Chebyshev多项式 T k ( x ) T_k(x) Tk(x) 的 K t h K^{th} Kth阶截断展开的条件:自变量范围需要在[-1, 1]之间。
- λ m a x \lambda_{max} λmax是 L L L 的最大特征值(又叫谱半径)。
- θ ∈ R N \theta \in \mathbb{R}^N θ∈RN是切比雪夫系数的向量
- Chebyshev多项式(即切比雪夫多项式)递归定义如下,之所以用切比雪夫多项式是因为可以循环递归求解。 T k ( x ) = 2 x T k − 1 ( x ) − T k − 2 ( x ) T_{k}(x)=2 x T_{k-1}(x)-T_{k-2}(x) Tk(x)=2xTk−1(x)−Tk−2(x)其中: T 0 ( x ) = 1 , T 1 ( x ) = x T_{0}(x)=1, \quad T_{1}(x)=x T0(x)=1,T1(x)=x
(3)写回L的函数
为了避免特征值分解,回到对信号x与滤波器
g
θ
g_{\theta}
gθ的卷积的定义,我们将,现在有:
g
θ
∗
x
=
∑
k
=
0
K
θ
k
T
K
(
L
~
)
x
(
5
)
g_{\theta} * x=\sum_{k=0}^{K} \theta_{k} T_{K}(\tilde{L}) x \qquad (5)
gθ∗x=k=0∑KθkTK(L~)x(5)
其中:
- L ~ = 2 L / λ max − I N = U Λ ~ U T \tilde{L}=2 L / \lambda_{\max }-I_{N}=U \tilde{\Lambda} U^{T} L~=2L/λmax−IN=UΛ~UT
- ( U Λ U T ) k = U Λ k U T \left(U \Lambda U^{T}\right)^{k}=U \Lambda^{k} U^{T} (UΛUT)k=UΛkUT
注意:此表达式现在是K-localized,因为它是拉普拉斯算子中的Kth-阶多项式(因此它仍然保持了K-局部化),即它仅取决于离中央节点(Kth阶邻域)最大K步的节点(节点仅被周围的K阶邻居节点所影响)。上式的复杂度是O(|E|),即与边数呈线性关系。Defferrard et al. 2016:Toward an Architecture for Never-Ending Language Learning使用这个K-localized卷积来定义图上的卷积神经网络。
PS:公式(4)到(5)的证明是用到数学归纳法和切比雪夫多项式的定义。
2.2 Layer-wise linear model 逐层线性模型
(1)简化:K=1(2个参数的模型)
因此可以通过堆叠多个形式为式(5)的卷积层来建立基于图卷积的神经网络模型。现在,文中将分层卷积操作限制为K=1(式(5)),即关于L是线性的,因此在图拉普拉斯谱上具有线性函数。
(以上展示了改进后的卷积的形式,都是前人的工作,本文的工作如下)
在GCN的这个线性公式中,作者进一步近似
λ
max
≈
2
\lambda_{\max } \approx 2
λmax≈2 , 可以预测到GCN的参数能够在训练中适应这一变化。根据这些近似,式(5)简化为:
g
θ
∗
x
=
∑
k
=
0
K
θ
k
T
K
(
L
~
)
x
=
∑
k
=
0
K
θ
k
′
T
k
(
2
λ
max
L
−
I
N
)
x
=
∑
k
=
0
K
θ
k
′
T
k
(
L
−
I
N
)
x
(
λ
max
≈
2
)
=
[
θ
0
′
T
0
(
L
−
I
N
)
+
θ
1
′
T
1
(
L
−
I
N
)
]
x
=
θ
0
′
x
+
θ
1
′
(
L
−
I
N
)
x
=
θ
0
′
x
+
θ
1
′
(
I
N
−
D
−
1
2
A
D
−
1
2
−
I
N
)
x
(
L
=
I
N
−
D
−
1
2
A
D
−
1
2
)
=
θ
0
′
x
−
θ
1
′
D
−
1
2
A
D
−
1
2
x
\begin{aligned} g_{\theta} * x &=\sum_{k=0}^{K} \theta_{k} T_{K}(\tilde{L}) x \\ &=\sum_{k=0}^{K} \theta_{k}^{\prime} T_{k}\left(\frac{2}{\lambda_{\max }} L-I_{N}\right) x \\ &=\sum_{k=0}^{K} \theta_{k}^{\prime} T_{k}\left(L-I_{N}\right) x \quad\left(\lambda_{\max } \approx 2\right) \\ &=\left[\theta_{0}^{\prime} T_{0}\left(L-I_{N}\right)+\theta_{1}^{\prime} T_{1}\left(L-I_{N}\right)\right] x \\ &=\theta_{0}^{\prime} x+\theta_{1}^{\prime}\left(L-I_{N}\right) x \\ &=\theta_{0}^{\prime} x+\theta_{1}^{\prime}\left(I_{N}-D^{-\frac{1}{2}} A D^{-\frac{1}{2}}-I_{N}\right) x \quad\left(L=I_{N}-D^{-\frac{1}{2}} A D^{-\frac{1}{2}}\right) \\ &=\theta_{0}^{\prime} x-\theta_{1}^{\prime} D^{-\frac{1}{2}} A D^{-\frac{1}{2}} x \end{aligned}
gθ∗x=k=0∑KθkTK(L~)x=k=0∑Kθk′Tk(λmax2L−IN)x=k=0∑Kθk′Tk(L−IN)x(λmax≈2)=[θ0′T0(L−IN)+θ1′T1(L−IN)]x=θ0′x+θ1′(L−IN)x=θ0′x+θ1′(IN−D−21AD−21−IN)x(L=IN−D−21AD−21)=θ0′x−θ1′D−21AD−21x
即:
g
θ
′
∗
x
≈
θ
0
′
x
+
θ
1
′
(
L
−
I
N
)
x
=
θ
0
′
x
−
θ
1
′
D
−
1
/
2
A
D
−
1
/
2
x
g_{\theta^{\prime}} * x \approx \theta_{0}^{\prime} x+\theta_{1}^{\prime}\left(L-I_{N}\right) x=\theta_{0}^{\prime} x-\theta_{1}^{\prime} D^{-1 / 2} A D^{-1 / 2} x
gθ′∗x≈θ0′x+θ1′(L−IN)x=θ0′x−θ1′D−1/2AD−1/2x上式子中有两个自由参数
θ
0
′
\theta_{0}^{\prime}
θ0′ 和
θ
1
′
\theta_{1}^{\prime}
θ1′。滤波器参数可以被整个图上共享。连续应用这种形式的滤波器,然后有效地卷积节点的kth-阶领域,其中k是神经网络模型中连续滤波操作或卷积层的数目。
(2)简化:1个参数的模型
实际上,进一步限制参数的数量以解决过拟合并最小化每层的操作数量(例如矩阵乘法)会是有益的。具体来说,文中令(为了进一步减少参数数量,防止过拟合)
θ
=
θ
0
′
=
−
θ
1
′
\theta=\theta_{0}^{\prime}=-\theta_{1}^{\prime}
θ=θ0′=−θ1′则有:
g
θ
∗
x
≈
θ
(
I
N
+
D
−
1
/
2
A
D
−
1
/
2
)
x
g_{\theta} * x \approx \theta\left(I_{N}+D^{-1 / 2} A D^{-1 / 2}\right) x
gθ∗x≈θ(IN+D−1/2AD−1/2)x其中矩阵:
I
N
+
D
−
1
/
2
A
D
−
1
/
2
I_{N}+D^{-1 / 2} A D^{-1 / 2}
IN+D−1/2AD−1/2是有范围 [0, 2] 的特征值。因此如果在深度神经网络模型中使用该算子,则反复应用该算子会导致数值不稳定(发散)和梯度爆炸/消失。
为了解决该问题,引入了一个renormalization trick(归一化技巧),让它的特征值落在[0, 1]范围内:
I
N
+
D
−
1
/
2
A
D
−
1
/
2
⟶
A
~
=
A
+
I
N
D
~
−
1
/
2
A
~
D
~
−
1
/
2
I_{N}+D^{-1 / 2} A D^{-1 / 2} \stackrel{\tilde{A}=A+I_{N}}{\longrightarrow} \tilde{D}^{-1 / 2} \tilde{A} \tilde{D}^{-1 / 2}
IN+D−1/2AD−1/2⟶A~=A+IND~−1/2A~D~−1/2其中
A
~
=
A
+
I
N
,
D
~
i
i
=
∑
j
A
~
i
j
\tilde{A}=A+I_{N}, \tilde{D}_{i i}=\sum_{j} \tilde{A}_{i j}
A~=A+IN,D~ii=j∑A~ij即图中加上自环。现在我们再加上一个激活函数,最后就可以得到公式(6)的快速卷积公式了,即每层图卷积正式定义为:
H
(
l
+
1
)
=
f
(
H
l
,
A
)
=
σ
(
D
~
−
1
/
2
A
~
D
~
−
1
/
2
H
(
l
)
W
(
l
)
)
(
6
)
H^{(l+1)}=f\left(H^{l}, A\right)=\sigma\left(\tilde{D}^{-1 / 2} \tilde{A} \tilde{D}^{-1 / 2} H^{(l)} W^{(l)}\right) \qquad (6)
H(l+1)=f(Hl,A)=σ(D~−1/2A~D~−1/2H(l)W(l))(6)
W
W
W是参数
θ
\theta
θ参数矩阵。
(3)推广:特征映射公式
可以将这个定义推广到具有C个输入通道(即每个节点的C维特征向量)的信号 X ∈ R N × C X∈\mathbb{R}^{N×C} X∈RN×C和 F 个滤波器或特征映射如下: Z = D ~ − 1 / 2 A ~ D ~ − 1 / 2 X Θ Z=\tilde{D}^{-1 / 2} \tilde{A} \tilde{D}^{-1 / 2} X \Theta Z=D~−1/2A~D~−1/2XΘ其中:
- Θ ∈ R C × F \Theta \in \mathbb{R}^{C \times F} Θ∈RC×F 是一个滤波器参数矩阵
- Z ∈ R N × F Z \in \mathbb{R}^{N \times F} Z∈RN×F是卷积信号参数矩阵
这个滤波操作复杂度是 O ( ∣ E ∣ F C ) O(|E| F C) O(∣E∣FC),因为 X X ~ X \tilde X XX~可以有效地实现为密集矩阵和稀疏矩阵的乘积。(在源代码中使用了稀疏矩阵和稠密矩阵乘法)
三、Semi-supervised node classification
3.1 Example
考虑一个两层的半监督节点分类GCN抹香鲸,在对称邻接矩阵A上操作。
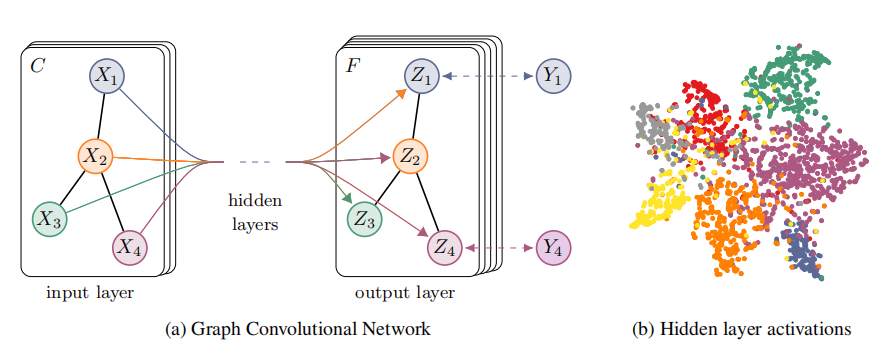
(1)预处理操作
首先计算 A ^ = D ~ − 1 / 2 A D ~ − 1 / 2 \hat{A}=\tilde{D}^{-1 / 2} A \tilde{D}^{-1 / 2} A^=D~−1/2AD~−1/2因此,前向计算变成一个简单的形式: Z = f ( X , A ) = softmax ( A ^ ReLU ( A ^ X W ( 0 ) ) W ( 1 ) ) Z=f(X, A)=\operatorname{softmax}\left(\hat{A} \operatorname{ReLU}\left(\hat{A} X W^{(0)}\right) W^{(1)}\right) Z=f(X,A)=softmax(A^ReLU(A^XW(0))W(1))注意:
- W ( 0 ) ∈ R C × H W^{(0)} \in \mathbb{R}^{C \times H} W(0)∈RC×H是输入层到隐藏层的权重矩阵,隐藏层有H个特征。
- W ( 1 ) ∈ R H × F W^{(1)} \in \mathbb{R}^{H \times F} W(1)∈RH×F是隐藏层到输出层的权重矩阵。
- softmax定义为 softmax ( x i ) = 1 Z exp ( x i ) , Z = ∑ i exp ( x i ) \operatorname{softmax}\left(x_{i}\right)=\frac{1}{Z} \exp \left(x_{i}\right), Z=\sum_{i} \exp \left(x_{i}\right) softmax(xi)=Z1exp(xi),Z=i∑exp(xi)softmax作用在每一行上。
(2)交叉熵误差
评估所有标记标签的交叉熵误差:
L
=
−
∑
l
∈
Y
L
∑
f
=
1
F
Y
l
f
ln
Z
l
f
\mathcal{L}=-\sum_{l \in \mathcal{Y}_{L}} \sum_{f=1}^{F} Y_{l f} \ln Z_{l f}
L=−l∈YL∑f=1∑FYlflnZlf
其中
y
L
y_{L}
yL为带标签的节点集。
(3)训练
神经网络的权重
W
(
0
)
,
W
(
1
)
W^{(0)}, W^{(1)}
W(0),W(1)通过梯度下降来进行训练。
使用完整的数据集对每个训练迭代执行批量梯度下降( batch gradient descent)。只要数据集适合内存,这就是一个可行的选择。
邻接矩阵A使用稀疏表示法,内存需求是O(E),E为边数,即和边数呈线性关系。
通过Dropout引入训练过程中的随机性(srivastava等人,2014)。
将内存效率扩展与小批随机梯度下降(mini-batch stochastic gradient descent) 留作以后的工作。
3.2 Implementation
在实践中,利用TensorFlow,使用稀疏-密集矩阵乘法在GPU上高效实现了下式:
Z
=
f
(
X
,
A
)
=
softmax
(
A
^
ReLU
(
A
^
X
W
(
0
)
)
W
(
1
)
)
Z=f(X, A)=\operatorname{softmax}\left(\hat{A} \operatorname{ReLU}\left(\hat{A} X W^{(0)}\right) W^{(1)}\right)
Z=f(X,A)=softmax(A^ReLU(A^XW(0))W(1)) 上式的时间复杂度为
O
(
∣
E
∣
C
H
F
)
O(|E| C H F)
O(∣E∣CHF),即和图的边数呈线性关系。
四、Related work
4.1 Graph-based semi-supervised learning
4.2 Neural networks on graphs
五、Experiments
5.1 Datasets
数据集的信息表如图:

(1)Citation networks
本文考虑三个引文网络数据集:Citeseer、Cora和PubMed(Sen等人,2008)。数据集包含每个文档的稀疏bag-of-words特征向量和文档之间的引用链接列表。本文将引用链接视为(无向)边,并构造一个二元对称邻接矩阵A。每个文档都有一个类标签。在训练时,每个类只使用20个标签。
(2)NELL
NELL是从中引入的知识图中提取的数据集(Carlson,2010年)。知识图是一组与有向标记边(关系)相连的实体。实验中遵循Yang等人所述的预处理方案(2016年)。文中为每个实体对(E1,R,E2)分配单独的关系节点R1和R2作为(E1,R1)和(E2,R2)。其中,实体节点由稀疏特征向量描述。通过为每个关系节点分配一个唯一的 o n e − h o t one-hot one−hot 表示来扩展NELL中的特征数量,从而有效地为每个节点生成 61278 维稀疏特征向量。这里的半监督任务只考虑训练集中每个类一个标记示例的极端情况。如果节点i和j之间存在一条或多条边,作者通过设置 A i j = 1 A_{ij}=1 Aij=1,从图中构造一个二元对称邻接矩阵(binary, symmetric adjacency matrix)。
(3)Random graphs
文中模拟各种大小的随机图数据集进行实验,测量每个 e p o c h epoch epoch 的训练时间。对于一个具有n个节点的数据集,创建一个随机图,随机均匀地分配 2 n 2n 2n 条边。将单位矩阵 I N I_N IN 作为输入特征矩阵x,从而隐式地采用一种无特征的方法,其中模型只知道每个节点的标识,由唯一的 o n e − h o t one-hot one−hot 向量指定。文中为每个节点添加 d u m m y dummy dummy 标签 y i = 1 y_i = 1 yi=1。
5.2 Experimental set-up 参数设置
训练两层GCN,并评估1000个标记示例的测试集的预测精度。补充实验(附录)中提供了使用最多10层的更深层次模型的额外实验。
相关参数
- 最大200 epoch
- Adam算法
- 学习率为0.01
- 停止条件:验证集loss连续十个迭代期没有下降
- 权重初始化方法:Xavier
- (按行)对输入特征向量归一化
- 隐藏层32个单元
- 省略dropout和L2正则化
5.3 Baselines
- label propagation(LP)
- semi-supervised embedding(SemiEmb)
- manifold regularization(ManiReg)
- DeepWalk
- iterative classification algorithm(ICA)
- Planetoid
六、Results
6.1 Semi-supervised node classification
半监督节点分类
结果如下表所示,表中分类准确度的数字的单位是百分比。对于ICA,计算了100次随机节点排序运行的平均精度。

6.2 Evaluation of propagation model
表中数字表示100次随机权重矩阵初始化重复运行的平均分类精度。在每层有多个变量的情况下,文中对第一层的所有权重矩阵施加L2正则化。

6.3 Training time per epoch
文中使用了100个epochs在模拟的随机图上每一个epoch的平均训练时间(前向传播、交叉熵计算、后向传播)的结果,以wall-clock时间测量。并且用GPU和只用CPU的两组实验结果进行如下对比。

Wall-clock time:就是响应时间,指计算机完成某一个任务所花的全部时间,也叫墙上时间(wall clock)或流逝时间(elapsed time)。
七、Discussion
7.1 Semi-supervisied model
7.2 Limitations and future work
(1)内存要求较大
在当前setup中,采用批量梯度下降(full-batch gradient descent),内存需求在数据集的大小上呈线性增长。文中已经证明,对于不适合GPU内存的大型图形,采用CPU训练仍然是一个可行的选择。小批量随机梯度下降(Mini-batch stochastic gradient descent)可以缓解这一问题。然而,生成Mini-batch的过程应该考虑到GCN模型中的层数,因为具有k层的GCN的k阶邻居必须存储在内存中,以便进行精确的过程。对于非常大且紧密相连的图数据集,可能需要进一步的近似。
(2)不支持边的特征
文中的框架目前不支持边的特征(edge features)(即有向还是无向),只限于无向图(加权或不加权)。然而,NELL上的结果表明,通过将原始有向图表示为无向二部图,以及表示原始图中边缘的附加节点,可以处理有向边和边缘特征。
(3)硬性假定
文中直接认为 A ~ = A + I N \tilde A=A+I_N A~=A+IN。但是,对于某些数据集,在A的定义中引入一个权衡参数 λ \lambda λ 可能更有益的: A ~ = A + λ I N \tilde{A}=A+\lambda I_{N} A~=A+λIN 在典型的半监督的参数设置中,该参数现在扮演着与监督学习的损失函数和非监督学习的损失函数之间的权衡参数相似的角色,并且该参数能够通过梯度下降进行学习。
八、Conclusion
本文提出了一种新的图结构数据半监督分类方法,所提出的GCN模型使用了一种基于图上谱卷积的一阶近似的高效层传播规则。对多个网络数据集的实验表明,所提出的GCN模型能够以一种对半监督分类有用的方式对图结构和节点特征进行编码。在这种情况下,文中的模型在很大程度上优于最近提出的几种方法,同时具有不错的计算效率。
作者在附录给最终得到的propagation rule找到了理论解释。第一种理论解释是建立了该方法与经典的Weisfeiler-Lehman algorithm之间的联系,将该propagation rule解释为一种特殊的hash function。第二种是从Spectral Graph Theory推导而来。对这部分理论解释感兴趣的童鞋可以去看paper~
附录A:Relation to Weisfeiler-Lehman algorithm

A.1 Node embeddings with random weights
随机权重的GCN模型
A.2 Semi-supervised node embedding
附录B:Experiments on model depth
H ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) W ( l ) ) + H ( l ) H^{(l+1)}=\sigma\left(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} H^{(l)} W^{(l)}\right)+H^{(l)} H(l+1)=σ(D~−21A~D~−21H(l)W(l))+H(l)实验设置
- 在公式(13)基础上添加一个softmax层
- 每个类只使用一个带标记的示例进行训练(即总共有4个带标记的节点)
- 使用Adam对300个训练迭代进行训练
- 交叉熵损失的学习率为0.01
图4显示了节点嵌入在许多训练迭代中的演化。该模型成功地实现了基于最小监督和图结构的社区线性分离。整个训练过程的视频可以在作者的网站上找到:http://tkipf.github.io/graph-convolutional-networks/
Reference
(1)https://tkipf.github.io/graph-convolutional-networks/
(2)https://towardsdatascience.com/how-to-do-deep-learning-on-graphs-with-graph-convolutional-networks-62acf5b143d0
(3)机器学习论文笔记-Semi-Supervised Classification with Graph Convolutional Networks
(4)土豆哥:https://blog.csdn.net/yyl424525/article/details/98724104?spm=1001.2014.3001.5502
(5)https://github.com/wangyouze
(6)图卷积网络(GCN)原理解析https://www.jianshu.com/p/35212baf6671(很棒,公式推理清晰明了,发展脉络)
(7)GCN图卷积网络本质理解(真的是从本质讲解,从热传播模型开始)
(8)基于图卷积网络的半监督学习:https://luweikxy.gitbook.io/machine-learning-notes/graph-neural-networks/graph-convolutional-networks/semi-supervised-classification-with-graph-convolutional-networks