[推荐系统]基于个性化推荐系统研究与实现(1)_强heaven的博客
目 录
一、搜索引擎与推荐系统
二、推荐系统原理与算法
2.1 Jaccard系数
2.2 余弦相似度
三、数据定向爬取及电影数据集
3.1 爬取近七日天气预报数据存入DB数据库,分为五步完成。
3.2 爬取豆瓣电影数据集存入CSV文件,分四步。
3.3 电影(MovieLens)数据集数据分析
一、搜索引擎与推荐系统
从信息获取的角度来看,搜索和推荐是用户获取信息的两种主要手段。无论在互联网上,还是在线下的场景里,搜索和推荐这两种方式都大量并存。搜索是主动行为,并且用户的需求十分明确,在搜索引擎提供的结果里,用户也能通过浏览和点击来明确的判断是否满足了用户需求。然而,推荐系统接受信息是被动的,需求也都是模糊而不明确的。如图1所示,搜索引擎和推荐系统是获取信息的两种不同方式。

图1 搜索引擎和推荐系统是获取信息的两种不同方式
搜索和推荐虽然有很多差异,但两者都是大数据技术的应用分支,存在着大量的交叠。推荐系统也大量运用了搜索引擎的技术,搜索引擎解决运算性能的一个重要的数据结构是倒排索引技术,而在推荐系统中,一类重要算法是基于内容的推荐,这其中大量运用了倒排索引、查询、结果归并等方法。它们都是数据挖掘技术、信息检索技术、计算统计学等悠久学科的智慧结晶。图2就是一个百度搜索引擎和推荐系统结合的实例,圆圈部分就是推荐系统的内容。

图2 百度搜索引擎和推荐系统结合的实例,圆圈部分是推荐系统内容
二、推荐系统原理与算法
推荐系统有三个重要模型:用户模型、推荐对象模块、推荐算法模型。推荐系统把用户模型中,兴趣需求信息和推荐对象模型中的特征信息匹配,同时使用相应的推荐算法进行计算筛选,找到用户可能感兴趣的推荐对象,然后推荐给用户。常用的推荐算法有:Jaccard系数,余弦相似度,皮尔逊系数等。
2.1 Jaccard系数
Jaccard系数等于样本集交集个数和样本集并集个数的比值,用J(A,B)表示。定义集合(A,B)都为空时,J(A,B)=1。
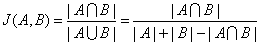
Jaccard系数主要的应用的场景有:
- 过滤相似度很高的新闻,或者网页去重;
- 考试防作弊系统;
- 论文查重系统。
# -*- coding: utf-8 -*-
"""
Created on Thu Jul 2 22:52:58 2020
@author: zcq
"""
import jieba
def Jaccrad(model, reference):#terms_reference为源句子,terms_model为候选句子
terms_reference= jieba.cut(reference)#默认精准模式
terms_model= jieba.cut(model)
grams_reference = set(terms_reference)#去重;如果不需要就改为list
grams_model = set(terms_model)
temp=0
for i in grams_reference:
if i in grams_model:
temp=temp+1
fenmu=len(grams_model)+len(grams_reference)-temp #并集
jaccard_coefficient=float(temp/fenmu)#交集
return jaccard_coefficient
a="香农在信息论中提出的信息熵定义为自信息的期望"
b="信息熵作为自信息的期望"
jaccard_coefficient=Jaccrad(a,b)
print(jaccard_coefficient)图2是Python实现a,b两个集合的Jaccard系数,相似度为0.3846。
Python运行结果:
0.38461538461538464
2.2 余弦相似度
使用余弦相似度计算用户与每部电影的距离。用户与每部电影的余弦相似度越高,则说明用户对电影的偏好程度越高。

Ua:用户对电影类型a的偏好程度;
Ia:电影是否属于类型a,即“构建电影的特征信息矩阵”中对应类型a的特征信息矩阵。
三、数据定向爬取及电影数据集
3.1 爬取近七日天气预报数据存入DB数据库,分为五步完成。
步骤1:获取西安天气预报网址http://www.weather.com.cn/weather/101110101.shtml;
步骤2:引入sqlite3、BeautifulSoup、urllib.request组件,实现WeatherDB、WeatherForecast类;
步骤3:实现WeatherDB类的数据库创建openDB、插入insert、查询show、关闭closeDB方法;
步骤4:实现WeatherForecast类的初始化init、城市预测forecastCity、批量预测process;
步骤5:Python编程实现(程序代码见下图)
# -*- coding: utf-8 -*-
"""
Created on Sat Jun 27 09:18:48 2020
@author: zcq
"""
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class WeatherDB:
def openDB(self):
self.con=sqlite3.connect("weathers.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key(wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self,city,date,weather,temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values (?,?,?,?)" ,(city,date,weather,temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows=self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("city","date","weather","temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0],row[1],row[2],row[3]))
class WeatherForecast:
def __init__(self):
self.headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
self.cityCode={"北京":"101010100","上海":"101020100","广州":"101280101","深圳":"101280601","西安":"101110101"}
def forecastCity(self,city):
if city not in self.cityCode.keys():
print(city+" code cannot be found")
return
url="http://www.weather.com.cn/weather/"+self.cityCode[city]+".shtml"
try:
req=urllib.request.Request(url,headers=self.headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml")
lis=soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date=li.select('h1')[0].text
weather=li.select('p[class="wea"]')[0].text
temp=li.select('p[class="tem"] span')[0].text+"/"+li.select('p[class="tem"] i')[0].text
print(city,date,weather,temp)
self.db.insert(city,date,weather,temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
def process(self,cities):
self.db=WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
#self.db.show()
self.db.closeDB()
ws=WeatherForecast()
ws.process(["北京","上海","广州","深圳","西安"])
print("completed")运行结果:
北京 3日(明天) 雷阵雨转多云 25℃/20℃
北京 4日(后天) 雷阵雨 28℃/20℃
北京 5日(周日) 雷阵雨 29℃/21℃
北京 6日(周一) 多云 31℃/23℃
北京 7日(周二) 雷阵雨 32℃/22℃
北京 8日(周三) 多云 30℃/22℃
上海 3日(明天) 中雨转阴 26℃/23℃
上海 4日(后天) 小雨转大雨 28℃/24℃
上海 5日(周日) 中雨 29℃/24℃
上海 6日(周一) 小雨 29℃/25℃
上海 7日(周二) 小雨 30℃/26℃
上海 8日(周三) 阴转小雨 29℃/26℃
广州 3日(明天) 雷阵雨 33℃/27℃
广州 4日(后天) 雷阵雨 33℃/28℃
广州 5日(周日) 晴 34℃/28℃
广州 6日(周一) 晴 35℃/28℃
广州 7日(周二) 晴 35℃/28℃
广州 8日(周三) 晴 35℃/28℃
深圳 3日(明天) 雷阵雨 32℃/27℃
深圳 4日(后天) 雷阵雨 32℃/27℃
深圳 5日(周日) 雷阵雨转阵雨 32℃/27℃
深圳 6日(周一) 阵雨 33℃/28℃
深圳 7日(周二) 阵雨 33℃/28℃
深圳 8日(周三) 阵雨 33℃/28℃
西安 3日(明天) 多云转阴 35℃/23℃
西安 4日(后天) 多云 33℃/22℃
西安 5日(周日) 晴 36℃/23℃
西安 6日(周一) 晴转多云 37℃/22℃
西安 7日(周二) 晴 37℃/22℃
西安 8日(周三) 多云转阴 33℃/21℃
Completed3.2 爬取豆瓣电影数据集存入CSV文件,分四步。
步骤1:获取豆瓣电影 Top 250:豆瓣电影 Top 250
步骤2:引入requests_html 、csv
步骤3:爬取结果存入文件:豆瓣top251.csv
步骤4:Python编程实现

图3 豆瓣电影 Top 250

图4 豆瓣top251.csv
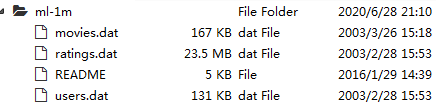
由于爬虫爬取的数据集特征有限,本文采用公开电影数据集(MovieLens ml-lm),该数据集包含四个文件:README、ratings.dat(用户评分数据集)、movies.dat(电影类型数据集)、users.dat(用户数据集)。
3.3 电影(MovieLens)数据集数据分析
MovieLens数据集是一个关于电影评分的数据集。下载地址:https://grouplens.org/datesets/movielens.
本例使用ml-lm电影数据集,该数据集包含四个文件:README、ratings.dat、movies.dat、users.dat。
(1)ratings.dat(用户评分数据集)包含四个字段,分别用户ID,电影ID,评分(1-5分)和时间戳,共100多万记录(如下图,电影得分及评分人数分布情况图);
包含1000209条数据。
names=["userID", "movieID", "rate", "timestamp"],
userID的范围为: <1,6040>
movieID的范围为: <1,3952>
评分值的范围为: <1,5>
数据总条数为:
userID 1000209
movieID 1000209
rate 1000209
timestamp 1000209
dtype: int64
数据前5条记录为:
userID movieID rate timestamp
0 1 1193 5 978300760
1 1 661 3 978302109
2 1 914 3 978301968
3 1 3408 4 978300275
4 1 2355 5 978824291
用户评分记录最少条数为:20

(2)movies.dat(电影类型数据集)包含三个字段,分别为电影ID,电影名称,电影类型(共18种类型,3883条记录,如下图中电影分类及数量);
names=["movieID", "title", "genres"]
movieID的范围为: <1,3952>
数据总条数为:
movieID 3883
title 3883
genres 3883
dtype: int64
电影类型总数为:18
电影类型分别为:dict_keys(['Animation', "Children's", 'Comedy', 'Adventure', 'Fantasy', 'Romance', 'Drama', 'Action', 'Crime', 'Thriller', 'Horror', 'Sci-Fi', 'Documentary', 'War', 'Musical', 'Mystery', 'Film-Noir', 'Western'])
{'Animation': 105, "Children's": 251, 'Comedy': 1200, 'Adventure': 283, 'Fantasy': 68, 'Romance': 471, 'Drama': 1603, 'Action': 503, 'Crime': 211, 'Thriller': 492, 'Horror': 343, 'Sci-Fi': 276, 'Documentary': 127, 'War': 143, 'Musical': 114, 'Mystery': 106, 'Film-Noir': 44, 'Western': 68}

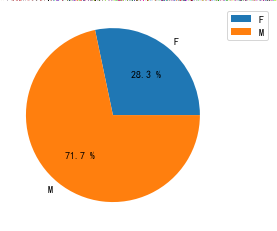
(3)users.dat(用户数据集)包含5字段,分别用户ID,性别取向,年龄,职业,邮编(6040条记录,如下图用户年龄分布图)
names=["userID", "gender", "age", "Occupation", "zip-code"],
userID的范围为: <1,6040>
数据总条数为:
userID 6040
gender 6040
age 6040
Occupation 6040
zip-code 6040
dtype: int64
gender
F 1709
M 4331
Name: gender, dtype: int64
age
1 222
18 1103
25 2096
35 1193
45 550
50 496
56 380
Name: age, dtype: int64
用户年龄分布统计

[推荐系统]基于个性化推荐系统研究与实现(2)
登录后可发表评论
点击登录