文本文件的读取
Pandas读取官方文档查阅地址 Input/Output — pandas 0.24.2 documentation (pydata.org)
read_csv\read_table(filepath_or_buffer,sep=’\t’,header=’infer’,names=None,index_col=None,usecols=None,dtype=None,converters=None,skiprows=None,skipfooter=None,nrows=None,na_values=None,skip_blank_lines=True,parse_dates=False,thousands=None,comment=None,encoding=None)
读取txt,注意到以下问题:如何忽略其他不相关内容,手动添加#;如何添加变量名称;如何避免编号中’00’的消失。
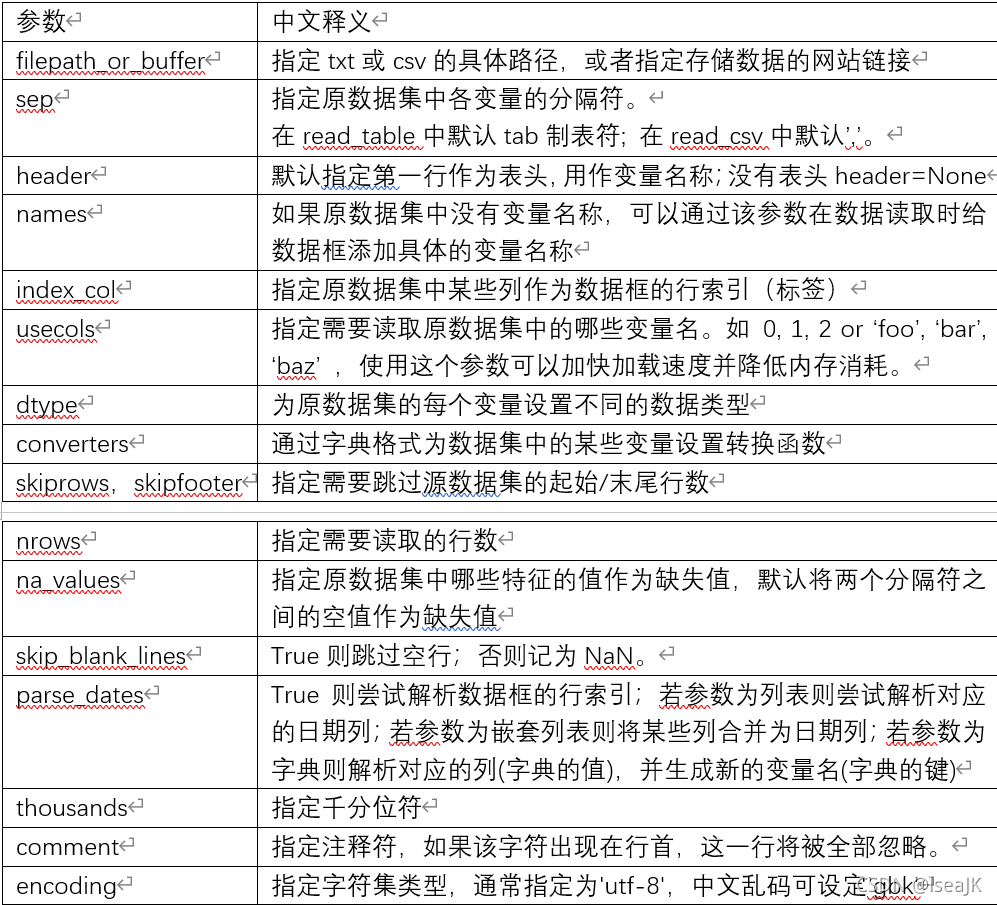
import pandas as pd
data1=pd.read_table(filepath_or_buffer=r'D:\Projects\Python\Doing\pythonProject\data\data1.txt',
sep=',',# 指定分隔符
header=None, # 不需要将原始数据中的第一行读作表头
names=['id','name','gender','occupation'], # 为各列起变量名称
skiprows=2, #跳过起始的两行数据
skipfooter=2, #跳过末尾的两行数据
comment='#', # 不读取'#'开头的数据行
converters={'id':str}, #对工号变量进行类型转换,避免开头的00消失
encoding='gbk'
)
print(data1)
'''
id name gender occupation
0 00446 张敏 女 前端工程师
1 00483 李琴 女 Java开发工程师
2 00552 赵东来 男 数据分析师
3 00589 丁顺昌 男 数据分析师
'''
电子表格的读取
read_excel(io,sheetname=0,header=0,skiprows=Nne,skip_footer=0,index_col=None,names=None,parse_cols=None,parse_dates=False,na_values=None,thousands=None,convert_float=True)
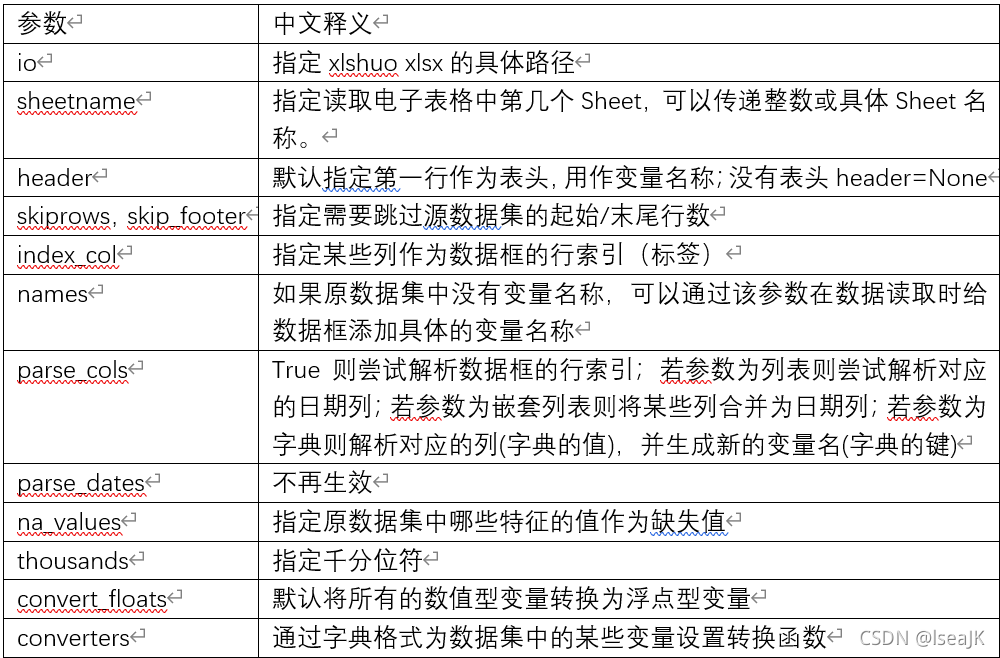
import pandas as pd
data2=pd.read_excel(io=r'D:\Projects\Python\Doing\pythonProject\data\data2.xlsx',
header=None, # 不需要将原始数据中的第一行读作表头
names=['id','date','prod_name','color','price'], # 为各列起变量名称
converters={'0':str}, #字典中的键必须为0,因为原始表中没有列名称
na_values='未知' # 原数据表中“未知”转换为缺失值
)
print(data2)
'''
id date prod_name color price
0 23146 2016-03-18 连衣裙 237 白色
1 1344527 2017-06-12 牛仔裤 368 蓝色
2 223685 2018-02-10 皮鞋 589 NaN
3 37249 2017-07-17 寸衫 299 白色
4 368241 2016-03-23 板鞋 299 蓝色
5 1127882 2018-09-17 西装 1599 黑色
'''
数据库数据的读取
读入SQL Server需要使用pymssql模块,在jupyter中输入“!pip install pymssql”;
读入MySQL需要使用Pymysql模块,在jupyter中输入“!pip install pymysql”。
然后基于两个模块各自的connect函数构建数据库与python之间的桥梁,最后在搭建好连接的基础上使用pandas模块中的read_sqll函数实现数据库数据的读取。
1.connect函数
(1)pymssql.connect(server=None,user=None,password=None,database=Nonesharset=None)

(2)pymysql.connect(host=None,user=None,password=’’,database=None,port=0,charset=’’)

2.read函数
pd.read_sql(sql,con,index_col=None,coerce_float=True,parse_dates=None,columns=None)

SQL SERVER连接
import pymssql
import pandas as pd
# 连接SQL Server数据库
connect=pymssql.connect(server='localhost',# 指定服务器名称
user='', # 指定访问数据库的用户名
password='', # 指定访问数据库的密码
database='train', # 指定数据所在数据库的名称
charset='utf8' # 指定UTF-8字符集,避免中文乱码
)
# 读取数据
data=pd.read_sql("select * from sec_buildings where direction='朝南'",con=connect)
# 关闭连接
connect.close()
# 数据输出
data.head()
MySQL连接
import pymysql
import pandas as pd
# 连接MySQL数据库
connect=pymysql.connect(host='localhost',# 指定服务器名称
user='root', # 指定访问数据库的用户名
password='123456', # 指定访问数据库的密码
database='wx', # 指定数据所在数据库的名称
port=3306, # 指定数据库连接的端口号
charset='utf8' # 指定UTF-8字符集,避免中文乱码
)
# 读取数据
data=pd.read_sql("select * from wx_gift",connect)
# 关闭连接
connect.close()
# 数据输出
print(data)
'''
gift_id name point_needed num_released img
0 1 党员学习笔记 100 3 /static/photo/礼品1.jpg
1 2 古典书签 50 23 /static/photo/礼品2.jpg
2 3 古风扇书签 300 4 /static/photo/礼品5.jpg
3 4 党建纪念品 1000 10 /static/photo/礼品4.jpg
'''
import pandas as pd
# 读取数据
data3=pd.read_excel(io=r'D:\Projects\Python\Doing\pythonProject\data\data3.xlsx')
# 查看数据规模
print(data3.shape
# (3000, 6)
# 查看表中各变量的数据类型
print(data3.dtypes)
'''
id int64
gender object
age float64
edu object
custom_amt object
order_date object
dtype: object
'''
数据的概览与清洗
从外部环境将数据读入到Python中后,首先要了解数据,数据规模、各变量的数据类型、是否存在重复值、缺失值等。
1.数据类型的判断和转换,读取数据,了解数据规模、各变量的数据类型
- astype用于数据类型的强制转换,常用转换类型包括str、float、int。
- 由于消费金额custom_amt变量中带有‘¥’,所以数据类型转换之前必须将包其删除(通过字符串切片方法删除,[1:]表示从字符的第二个元素开始截断)。
- 对于字符转日期问题,推荐使用更加灵活的pandas的to_datetime方法,在format参数的调解下,可以识别任意格式的字符型日期值。
import pymysql
import pandas as pd
# 读取数据
data3=pd.read_excel(io=r'D:\Projects\Python\Doing\pythonProject\data\data3.xlsx')
# 查看数据规模
# print(data3.shape
# (3000, 6)3000行6列
# 查看表中各变量的数据类型
# print(data3.dtypes)
'''
id int64
gender object
age float64
edu object
custom_amt object
order_date object
dtype: object
'''
# 数值型转字符型
data3['id']=data3['id'].astype(str)
# 字符型转数值型
data3['custom_amt']=data3['custom_amt'].str[1:].astype(float)
# 字符型转日期型
data3['order_date']=pd.to_datetime(data3['order_date'],format='%Y年%m月%d日')
# 重新查看数据集的各变量类型
# print(data3.dtypes)
'''
id object
gender object
age float64
edu object
custom_amt float64
order_date datetime64[ns]
dtype: object
'''
# 预览数据的前五行
print(data3.head())
'''
id gender age edu custom_amt order_date
0 890 female 43.0 NaN 2177.94 2018-12-25
1 2391 male 52.0 NaN 2442.18 2017-05-24
2 2785 male 39.0 NaN 849.79 2018-05-15
3 1361 female 26.0 NaN 2482.22 2018-05-16
4 888 female 61.0 本科 2027.90 2018-01-21
'''
2.冗余数据的判断和处理,监控数据表中是否存在“脏”数据,如冗余的重复观测值和缺失值等
可以通过duplicated方法进行“脏”数据的识别和处理,没有重复值返回False。若发现了重复值,可使用drop_duplicates方法将冗余信息删除。
在duplicated方法对数据行作重复性判断时,会返回一个与原数据行数相同的序列,如果数据行没有重复则对应False,否则对应True,为了得到最终的判断结果,需要再用any方法,即序列中只要存在一个true则返回true。
# 判断是否存在重复观测值
print(data3.duplicated().any())
# False
3.缺失数据的判断预处理,通常从两个方面入手:
①变量的角度,即判断每个变量中是否包含缺失值;
②数据行的角度,即判断每行数据中是否包含缺失值。
关于缺失值NaN的判断可以使用isnull方法,它会返回与原数据行列数相同的矩阵,并且矩阵的元素为bool类型的值。
为了得到每一列的判断结果,仍然需要使用any方法且设置axis参数为0;
统计各变量的缺失值个数可以在isnull的基础上使用sum方法,同样需要设置axis参数为0;
计算缺失比例就是在缺失数量的基础上除以总的样本量(shape方法返回数据集的行数和列数,[0]表示取出对应的数据行数)。
说明:axis=0行数增多,axis=1列数增多
对于缺失值的处理,最常用的方法无外乎删除法、替换法和插补法。
- 删除法指将缺失值所在的观测行删除,前提缺失行比例非常低如在5%以内;或者删除缺失值所对应的变量,前提是改变量中包含的缺失值比例非常高如70%左右。
- 替换法是指直接利用缺失变量的均值、中位数或众数替换该变量中的缺失值,其好处是处理速度快,弊端是容易产生有偏估计,导致缺失值替换的准确性下降。
- 插补法是指利用有监督的机器学习方法(如回归模型、树模型、网络模型等)对缺失值做预测,其优势在于预测的准确性高,缺点是需要大量的计算,导致缺失值的处理速度大打折扣。
# 判断各变量中是否存在缺失值
print(data3.isnull().any(axis=0))
'''
id False
gender True
age True
edu True
custom_amt False
order_date False
dtype: bool
'''
# 各变量中缺失值的数量
print(data3.isnull().sum(axis=0))
'''
id 0
gender 136
age 100
edu 1927
custom_amt 0
order_date 0
dtype: int64
'''
# 各变量中缺失值的比例
print(data3.isnull().sum(axis=0)/data3.shape[0])
'''
id 0.000000
gender 0.045333
age 0.033333
edu 0.642333
custom_amt 0.000000
order_date 0.000000
dtype: float64
'''
# 判断各数据行中是否存在缺失值
print(data3.isnull().any(axis=1))
'''
0 True
1 True
2 True
3 True
4 False
...
2995 True
2996 False
2997 True
2998 False
2999 True
Length: 3000, dtype: bool
'''
# 缺失观测值的行数
print(data3.isnull().any(axis=1).sum())
# 2024
# 缺失观测值的比例
print(data3.isnull().any(axis=1).sum()/data3.shape[0])
# 0.6746666666666666
# 删除变量,如删除缺失率非常高的edu变量
data3.drop(labels='edu',axis=1,inplace=True)
print(data3.head())
'''
id gender age custom_amt order_date
0 890 female 43.0 2177.94 2018-12-25
1 2391 male 52.0 2442.18 2017-05-24
2 2785 male 39.0 849.79 2018-05-15
3 1361 female 26.0 2482.22 2018-05-16
4 888 female 61.0 2027.90 2018-01-21
'''
# 删除观测值,如删除age变量中所对应的缺失观测值
data3_new=data3.drop(labels=data3.index[data3['age'].isnull()],axis=0)
print(data3_new.shape)
# (2900, 5)
# 替换法处理缺失观测值
data3.fillna(value={'gender':data3['gender'].mode()[0],# 使用性别的众数替换缺失性别
'age':data3['age'].mean() # 使用年龄的平均值替换缺失年龄
},
inplace=True # 原地修改数据
)
print(data3.isnull().sum(axis=0))
'''
id 0
gender 0
age 0
custom_amt 0
order_date 0
dtype: int64
'''
数据的引用
在pandas模块中,可以使用iloc、loc或ix方法既可以筛选也可以对变量进行挑选,他们的语法相同,可以表示成[rows_select,cols_select]。
- iloc只能通过行号和列号进行数据的筛选,可以将iloc中的’i’理解为integer,即只能向[rows_select,cols_select]指定整数列表。对于这种方式的索引,第一行货第一列必须用0表示,既可以向rows_select或cols_select指定连续的整数编号(即切片用法start🔚step,end的值取不到),也可以指定简短的整数编号。
- loc可以将’l’理解为label,即可以向[rows_select,cols_select]指定具体的行标签(行名称)和列标签(变量名)。注意,这里是标签而不再是整数索引。除此之外loc方法还可以将索引中的rows_select指定为数据的筛选条件,但在iloc中是不允许这样使用的。
- ix是iloc和loc的混胡,可以将ix理解为mix。
import pandas as pd
# 构造数据框
df1=pd.DataFrame({'name':['甲','乙','丙','丁','戊'],
'gender':['男','女','女','女','男'],
'age':[23,26,22,25,27],
'edu':['本科','本科','硕士''本科','硕士']
},
columns=['name','gender','edu','age']
)
# 查看数据预览
# print(df1)
# 取出数据集的中间三行(即所有女性),并且返回姓名、年龄和受教育水平三列
# iloc方法,切片上限无法取到
df1.iloc[1:4,[0,3,2]]
# loc方法,,通过名字索引
df1.loc[1:3,['name','age','edu']]
# ix方法,既可以指定位置索引,也可以指定名称索引
df1.ix[1:3,[0,3,2]]
1.假如数据集没有数值行号,而是具体的行名称应如何筛选
对于iloc来说,不管什么形式的数据集都可以使用,他始终需要指定目标数据所在的位置索引;
loc就不能使用数值表示标签栏,因为此时数据集的行标签是姓名,所以需要写入中间三行所对应的用户姓名;
对于ix方法,即可以使用行索引如1:4,也可以使用行名称表示。
另外,’:’表示取出数据集的所有变量。
# 将员工的姓名用作行标签
df2=df1.set_index('name')
# 查看数据预览
print(df2)
# iloc方法取出数据的中间三行
df2.iloc[1:4,:]
# loc方法取出数据的中间三行
df2.loc[['乙','丙','丁'],:]
# ix方法取出数据的中间三行
df2.ix[1:4,:]
2.显然在实际操作中很少通过指定具体的行索引或行名称尽心,而是基于列的条件表达式获得目标子集。
条件筛选只能使用在loc和ix两种方法中。
对变量的筛选loc方法必须指定具体的变量名称,而ix方法既可以指定变量名称,也可以指定变量所在的位置索引。
# 删除观测,如删除age变量中所对应的缺失观测
data3_new2=data3.loc[~data3['age'].isnul(),]
# 查看数据规模
print(data3_new2.shape)
#(2900,5)
注意:’~’表示逻辑非,如果不进行非操作,得到的将是缺失值所对应的行。
多表合并与连接314
SQL中多表合并采用UNION | UNION ALL;多表连接采用INNER JOIN | LEFT JOIN。
对Python来说,pandas模块提供了concat函数和merge函数实现多表之间的合并和连接。
1.合并函数concat
pd.concat(objs,axis=0,join=’outer’,join_axes=None,ignore_index=False,keys=None)
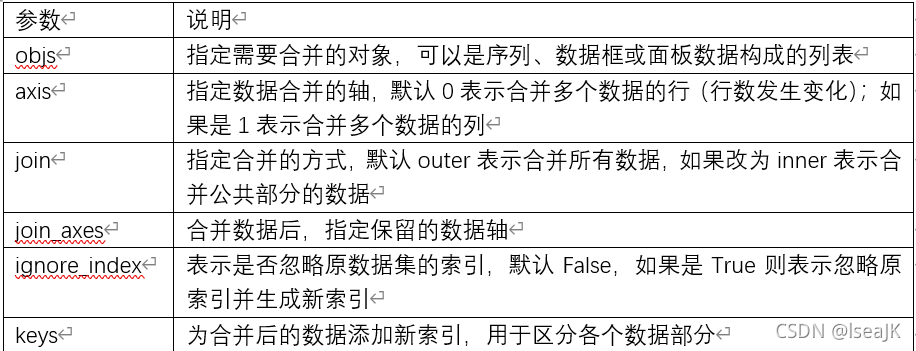
如果纵向合并多个数据集,name和Name是不同的;
对于join_axes参数的使用,例如纵向合并两个数据集df1和df2,可以写成pd.concat([df1,df2])。
如果该参数等于[df1.index],则表示保留与df1行标签值一样的数据,但需要配合axis=1一起使用(即实现变量横向合并操作);
如果等于[df1.columns],则保留与df1中所有变量值一样的数据,但不需要添加axis=1的约束。
import pandas as pd
# 构造数据框
df1=pd.DataFrame({'name':['张三','李四','王二'],
'age':[21,25,22],
'gender':['男','女','男']
})
df2=pd.DataFrame({'name':['丁一','赵五'],
'age':[23,22],
'gender':['女','女']
})
# 数据集的纵向合并
df3=pd.concat([df1,df2], # 需将被合并的数据集组合到列表中,否则报错
keys=['df1','df2'] # 借助于该参数区分不同的数据源
)
print(df3)
'''
name age gender
df1 0 张三 21 男
1 李四 25 女
2 王二 22 男
df2 0 丁一 23 女
1 赵五 22 女
'''
# 将第一列索引列转换为变量
df3.reset_index(level=0, #level用于指定第几个索引列需要转换,0表示第一个索引列
inplace=True
)
# 变量重命名
df3.rename(columns={'level_0':'tab_name'},inplace=True)
# 重新调整行索引值
df3.index=range(df3.shape[0])
print(df3)
'''
tab_name name age gender
0 df1 张三 21 男
1 df1 李四 25 女
2 df1 王二 22 男
3 df2 丁一 23 女
4 df2 赵五 22 女
'''
2.连接函数merge
merge(left,right,how=’inner’,on=None,left_on=None,right_on=None,
left_index=False,right_index=False,sort=False,suffixes=(‘_x’,’_y’))

该函数最大的缺点是每次只能操作两张数据表,如果有n张表需要连接,必须经过n-1次的merge函数使用。NaN为缺失值,表示无法匹配的值。
import pandas as pd
# 构造数据框
df3=pd.DataFrame({'id':[1,2,3,4,5],
'name':['张三','李四','王二','丁一','赵五'],
'age':[21,25,22,23,22],
'gender':['男','女','男','女','女']
})
df4=pd.DataFrame({'Id':[1,2,2,4,4,4,5],
'score':[83,81,87,75,86,74,88],
'kemu':['科目1','科目1','科目2','科目1','科目2','科目3','科目1']
})
df5=pd.DataFrame({'id':[1,3,5],'name':['张三','王二','赵五'],'income':[13500,18000,15000]})
# 首先将df3和df4连接,再将结果1 merge1和df5连接
merge1=pd.merge(left=df3,right=df4,how='left',left_on='id',right_on='Id')
print(merge1)
'''
id name age gender Id score kemu
0 1 张三 21 男 1.0 83.0 科目1
1 2 李四 25 女 2.0 81.0 科目1
2 2 李四 25 女 2.0 87.0 科目2
3 3 王二 22 男 NaN NaN NaN
4 4 丁一 23 女 4.0 75.0 科目1
5 4 丁一 23 女 4.0 86.0 科目2
6 4 丁一 23 女 4.0 74.0 科目3
7 5 赵五 22 女 5.0 88.0 科目1
'''
merge2=pd.merge(left=merge1,right=df5,how='right')
print(merge2)
'''
id name age gender Id score kemu income
0 1 张三 21 男 1.0 83.0 科目1 13500
1 3 王二 22 男 NaN NaN NaN 18000
2 5 赵五 22 女 5.0 88.0 科目1 15000
'''
数据的汇总319
pandas模块既提供了Excel中的透视表功能,也提供了数据库中的分组聚合功能。
1.透视表功能pivot_table函数
pd.pivot_table(data,values=None,index=None,columns=None,aggfunc=’mean’,
fill_value=None,margins=False,dropna=True,margins_name=’All’)

import pandas as pd
diamonds=pd.read_table(r'D:\Projects\Python\Doing\pythonProject\data\diamonds.csv',sep=',')
# 单个分组变量的均值统计
print(pd.pivot_table(data=diamonds,index='color',values='price',margins=True,margins_name='总计'))
'''
price
color
D 3169.954096
E 3076.752475
F 3724.886397
G 3999.135671
H 4486.669196
I 5091.874954
J 5323.818020
总计 3932.799722
'''
import pandas as pd
import numpy as np
diamonds=pd.read_table(r'D:\Projects\Python\Doing\pythonProject\data\diamonds.csv',sep=',')
# 两个分组变量的列联表
print(pd.pivot_table(data=diamonds,index='clarity',columns='cut',values='carat',aggfunc=np.size,margins=True,margins_name='总计'))
'''
cut Fair Good Ideal Premium Very Good 总计
clarity
I1 210.0 96.0 146.0 205.0 84.0 741.0
IF 9.0 71.0 1212.0 230.0 268.0 1790.0
SI1 408.0 1560.0 4282.0 3575.0 3240.0 13065.0
SI2 466.0 1081.0 2598.0 2949.0 2100.0 9194.0
VS1 170.0 648.0 3589.0 1989.0 1775.0 8171.0
VS2 261.0 978.0 5071.0 3357.0 2591.0 12258.0
VVS1 17.0 186.0 2047.0 616.0 789.0 3655.0
VVS2 69.0 286.0 2606.0 870.0 1235.0 5066.0
总计 1610.0 4906.0 21551.0 13791.0 12082.0 53940.0
'''
2.分组聚合操作,使用pandas模块中的groupby方法和aggregate方法。
import pandas as pd
import numpy as np
diamonds=pd.read_table(r'D:\Projects\Python\Doing\pythonProject\data\diamonds.csv',sep=',')
# 通过groupby方法,指定分组变量
grouped=diamonds.groupby(by=['color','cut'])
# 对分组变量进行统计汇总
result=grouped.aggregate({'color':np.size,'carat':np.min,'price':np.mean,'face_width':np.max})
# print(result)
'''
color carat price face_width
color cut
D Fair 163 0.25 4291.061350 73.0
Good 662 0.23 3405.382175 66.0
Ideal 2834 0.20 2629.094566 62.0
Premium 1603 0.20 3631.292576 62.0
Very Good 1513 0.23 3470.467284 64.0
E Fair 224 0.22 3682.312500 73.0
Good 933 0.23 3423.644159 65.0
Ideal 3903 0.20 2597.550090 62.0
Premium 2337 0.20 3538.914420 62.0
Very Good 2400 0.20 3214.652083 65.0
F Fair 312 0.25 3827.003205 95.0
Good 909 0.23 3495.750275 66.0
Ideal 3826 0.23 3374.939362 63.0
Premium 2331 0.20 4324.890176 62.0
Very Good 2164 0.23 3778.820240 65.0
G Fair 314 0.23 4239.254777 76.0
Good 871 0.23 4123.482204 66.0
Ideal 4884 0.23 3720.706388 62.0
Premium 2924 0.23 4500.742134 62.0
Very Good 2299 0.23 3872.753806 66.0
H Fair 303 0.33 5135.683168 73.0
Good 702 0.25 4276.254986 65.0
Ideal 3115 0.23 3889.334831 62.0
Premium 2360 0.23 5216.706780 62.0
Very Good 1824 0.23 4535.390351 65.0
I Fair 175 0.41 4685.445714 70.0
Good 522 0.30 5078.532567 66.0
Ideal 2093 0.23 4451.970377 62.0
Premium 1428 0.23 5946.180672 62.0
Very Good 1204 0.24 5255.879568 65.0
J Fair 119 0.30 4975.655462 68.0
Good 307 0.28 4574.172638 65.0
Ideal 896 0.23 4918.186384 62.0
Premium 808 0.30 6294.591584 62.0
Very Good 678 0.24 5103.513274 63.0
'''
# 数据集重命名
result.rename(columns={'color':'counts','carat':'min_weight','price':'avg_price','face_width':'max_face_width'},
inplace=True)
print(result)
'''
counts min_weight avg_price max_face_width
color cut
D Fair 163 0.25 4291.061350 73.0
Good 662 0.23 3405.382175 66.0
Ideal 2834 0.20 2629.094566 62.0
Premium 1603 0.20 3631.292576 62.0
Very Good 1513 0.23 3470.467284 64.0
E Fair 224 0.22 3682.312500 73.0
Good 933 0.23 3423.644159 65.0
Ideal 3903 0.20 2597.550090 62.0
Premium 2337 0.20 3538.914420 62.0
Very Good 2400 0.20 3214.652083 65.0
F Fair 312 0.25 3827.003205 95.0
Good 909 0.23 3495.750275 66.0
Ideal 3826 0.23 3374.939362 63.0
Premium 2331 0.20 4324.890176 62.0
Very Good 2164 0.23 3778.820240 65.0
G Fair 314 0.23 4239.254777 76.0
Good 871 0.23 4123.482204 66.0
Ideal 4884 0.23 3720.706388 62.0
Premium 2924 0.23 4500.742134 62.0
Very Good 2299 0.23 3872.753806 66.0
H Fair 303 0.33 5135.683168 73.0
Good 702 0.25 4276.254986 65.0
Ideal 3115 0.23 3889.334831 62.0
Premium 2360 0.23 5216.706780 62.0
Very Good 1824 0.23 4535.390351 65.0
I Fair 175 0.41 4685.445714 70.0
Good 522 0.30 5078.532567 66.0
Ideal 2093 0.23 4451.970377 62.0
Premium 1428 0.23 5946.180672 62.0
Very Good 1204 0.24 5255.879568 65.0
J Fair 119 0.30 4975.655462 68.0
Good 307 0.28 4574.172638 65.0
Ideal 896 0.23 4918.186384 62.0
Premium 808 0.30 6294.591584 62.0
Very Good 678 0.24 5103.513274 63.0
'''
# 将行索引变换为数据框的变量
result.reset_index(inplace=True)
print(result)
'''
color cut counts min_weight avg_price max_face_width
0 D Fair 163 0.25 4291.061350 73.0
1 D Good 662 0.23 3405.382175 66.0
2 D Ideal 2834 0.20 2629.094566 62.0
3 D Premium 1603 0.20 3631.292576 62.0
4 D Very Good 1513 0.23 3470.467284 64.0
5 E Fair 224 0.22 3682.312500 73.0
6 E Good 933 0.23 3423.644159 65.0
7 E Ideal 3903 0.20 2597.550090 62.0
8 E Premium 2337 0.20 3538.914420 62.0
9 E Very Good 2400 0.20 3214.652083 65.0
10 F Fair 312 0.25 3827.003205 95.0
11 F Good 909 0.23 3495.750275 66.0
12 F Ideal 3826 0.23 3374.939362 63.0
13 F Premium 2331 0.20 4324.890176 62.0
14 F Very Good 2164 0.23 3778.820240 65.0
15 G Fair 314 0.23 4239.254777 76.0
16 G Good 871 0.23 4123.482204 66.0
17 G Ideal 4884 0.23 3720.706388 62.0
18 G Premium 2924 0.23 4500.742134 62.0
19 G Very Good 2299 0.23 3872.753806 66.0
20 H Fair 303 0.33 5135.683168 73.0
21 H Good 702 0.25 4276.254986 65.0
22 H Ideal 3115 0.23 3889.334831 62.0
23 H Premium 2360 0.23 5216.706780 62.0
24 H Very Good 1824 0.23 4535.390351 65.0
25 I Fair 175 0.41 4685.445714 70.0
26 I Good 522 0.30 5078.532567 66.0
27 I Ideal 2093 0.23 4451.970377 62.0
28 I Premium 1428 0.23 5946.180672 62.0
29 I Very Good 1204 0.24 5255.879568 65.0
30 J Fair 119 0.30 4975.655462 68.0
31 J Good 307 0.28 4574.172638 65.0
32 J Ideal 896 0.23 4918.186384 62.0
33 J Premium 808 0.30 6294.591584 62.0
34 J Very Good 678 0.24 5103.513274 63.0
'''
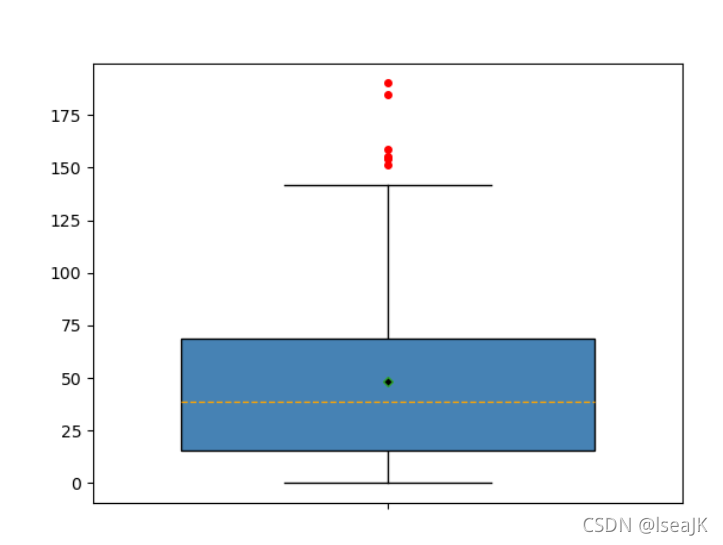
import matplotlib.pyplot as plt
import pandas as pd
sunspots=pd.read_csv(r'D:\Projects\Python\Doing\pythonProject\data\sunspots.csv')
# 绘制箱线图(1.5倍的四分位差,如需绘制3倍的四分位差,只需调整whis参数)
plt.boxplot(x=sunspots.counts, # 指定绘制箱线图的数据
whis=1.5, # 指定1.5倍的四分位差
widths=0.7, # 指定箱线图的宽度为0.8
patch_artist=True, # 指定需要填充箱体颜色
showmeans=True, # 指定需要显示均值
boxprops={'facecolor':'steelblue'}, # 指定箱体的填充色为铁蓝色
# 指定异常点的填充色、边框色和大小
flierprops={'markerfacecolor':'red','markeredgecolor':'red','markersize':4},
# 指定均值点的标记符号(菱形)、填充色和大小
meanprops={'marker':'D','markerfacecolor':'black','markersize':4},
medianprops={'linestyle':'--','color':'orange'}, # 指定中位数的标记符号(虚线)和颜色
labels=[''] # 去除箱线图的x轴刻度值
)
plt.show()
2.基于正态分布特性识别异常值——以某公司的支付转化率分析为例
(1)正态分布的基本概念
根据正态分布的定义可知,数据点落在偏离均值正负1倍标准差(即δ值)内的概率为68.2%;数据点落在偏离均值正负2倍标准差内的概率为95.4%;数据点落在偏离均值正负3倍标准差内的概率为99.6%。
也就是说,如果数据点落在偏离均值正负2倍标准差之外的概率就不足5%,它属于小概率事件,即认为这样的数据点为异常点。同理,如果数据点落在偏离均值正负3倍标准差
之外的概率将会更小,可以认为这些数据点为极端异常点。
(2)plot函数
plot(x,y,linestyle,linewidth,color,marker,markersize,markeredgecolor,markerfactcolor,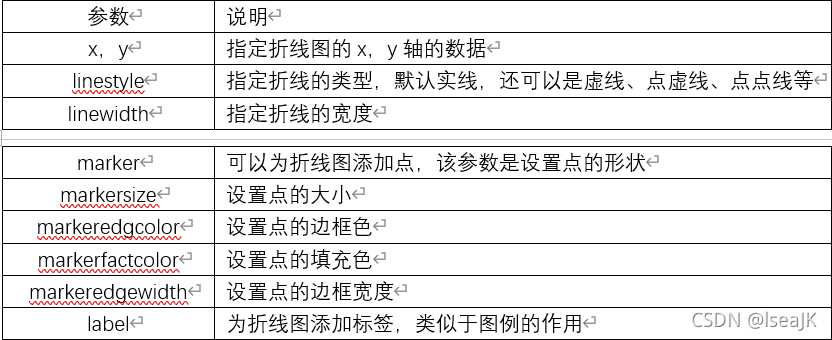
markeredgewidth,label,alpha)
(3)正态分布实例——某公司的支付转化率分析
如果待判断的变量近似服从正态分布,建议选择正态分布的参考线法识别异常点,否则使用分位数法识别异常点。
import matplotlib.pyplot as plt
import pandas as pd
pay_ratio=pd.read_excel(r'D:\Projects\Python\Doing\pythonProject\data\pay_ratio.xlsx')
# print(pay_ratio.head())
'''
date login pay ratio
0 2019-07-01 2234185 965957 0.432353
1 2019-07-02 1308983 598254 0.457038
2 2019-07-03 1395809 455764 0.326523
3 2019-07-04 1655896 522631 0.315618
4 2019-07-05 1141110 586891 0.514315
'''
# 绘制单条折线图,并在折线图的基础上添加点图
plt.plot(pay_ratio.date,pay_ratio.ratio, # x,y 轴数据
linestyle='-',linewidth=2,color='steelblue', # 设置折线类型、宽度和颜色
marker='o',markersize=4, # 往折线图中添加圆点,设置点的大小
markeredgecolor='black',markerfacecolor='black' # 设置点的边框色和填充色
)
# plt.show()
# 添加上下界的水平参考线(便于判断异常点,如下面判断极端异常点,只需将2改为3)
plt.axhline(y=pay_ratio.ratio.mean()-2*pay_ratio.ratio.std(),linestyle='--',color='gray')
plt.axhline(y=pay_ratio.ratio.mean()+2*pay_ratio.ratio.std(),linestyle='--',color='gray')
# 导入模块用于日期刻度的修改(因为默认格式下的日期刻度标签并不是很友好)
import matplotlib as mpl
# 获取图的坐标信息
ax=plt.gca()
# 设置日期的显示格式
date_format=mpl.dates.DateFormatter("%m-%d")
ax.xaxis.set_major_formatter(date_format)
# 设置x轴每个刻度的间隔天数
xlocator=mpl.ticker.MultipleLocator(7)
ax.xaxis.set_major_locator(xlocator)
# 为了避免x轴刻度标签的紧凑,将刻度标签旋转45°
plt.xticks(rotation=45)
# plt.show()
# 计算判断异常点和极端异常点的临界值
outlier_ll=pay_ratio.ratio.mean()-2*pay_ratio.ratio.std()
outlier_ul=pay_ratio.ratio.mean()+2*pay_ratio.ratio.std()
extreme_outlier_ll=pay_ratio.ratio.mean()-3*pay_ratio.ratio.std()
extreme_outlier_ul=pay_ratio.ratio.mean()+3*pay_ratio.ratio.std()
# 寻找异常点和极端异常点
print(pay_ratio.loc[(pay_ratio.ratio>outlier_ul)|(pay_ratio.ratio<outlier_ll),['date','ratio']])
'''
date ratio
10 2019-07-11 0.147000
32 2019-08-02 0.849452
34 2019-08-04 0.948245
45 2019-08-15 0.103448
63 2019-09-02 0.146569
67 2019-09-06 0.905321
79 2019-09-18 0.145246
89 2019-09-28 0.136075
'''
print(pay_ratio.loc[(pay_ratio.ratio>extreme_outlier_ul)|(pay_ratio.ratio<extreme_outlier_ll),['date','ratio']])
'''
date ratio
34 2019-08-04 0.948245
67 2019-09-06 0.905321
'''
3.异常值的处理方法
如果数据集中存在异常点,为避免异常点对后续分析或挖掘的影响,通常需要对异常点
做相应的处理,比较常见的处理办法有如下几种:
直接从数据集中删除异常点。
使用简单数值(均值或中位数)或者距离异常值最近的最大值(最小值)替换异常值,也可以使用判断异常值的临界值替换异常值。
将异常值当作缺失值处理,伸用插补法估计异常值,或者根据异常值衍生出表示是否异常的哑变量。