GeoPandas库使用入门教程
文章目录
- GeoPandas库使用入门教程
- 前言
- 使用步骤
- 1.文件导入\导出与数据结构
- 数据导出
- 2.绘制地图
- 基本功能
- 分区统计图
- 制作图例
- 修改颜色
- 绘制边界
- 指定图层的层数
- 3.管理投影
- 4.几何操作
- 5.集合操作
- 5.聚合与连接
- 聚合
- 连接
- 总结
- 参考
前言
Geopandas库扩展了Pandas的内容,使Python可以对几何类型进行空间操作,其大部分用法同Pandas一致。在教程开始之前,先导入最基本的库
import geopandas as gpd
import pandas as pd
import matplotlib.pyplot as plt
使用步骤
1.文件导入\导出与数据结构
使用read_file()可以导入任何的空间矢量数据,主要有shp和GeoJson两种。具体用法为geopandas.read_file(filename, bbox=None, mask=None, rows=None, **kwargs)
- filename 文件路径
- bbox 按照给定的条件筛选几何要素,仅加载与边框相交的数据
- mask 过滤与给定条件相交要素
- rows 要加载的行数
- ignore_geometry = Ture 返回dataframe
- ignore_fields [],选择不加载这几列
下面为导入Shp文件,注意如果文件中有中文字符,则需要指定编码方式为‘gbk’,否则会乱码
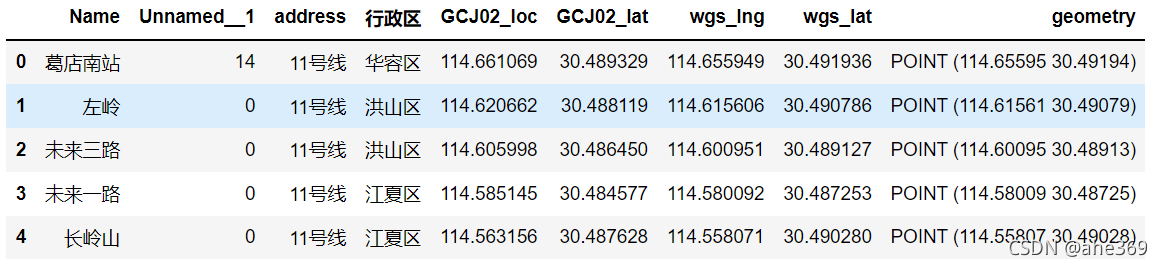
stop = gpd.read_file(r'D:\ArcGis\2021_3\时间可达性2021\whsta.shp',encoding = 'gbk')
stop.head(5)
对同样的数据使用Pandas导入
df = pd.read_excel(r'武汉市地铁站点_2021_3(集合).xlsx')
df.head()
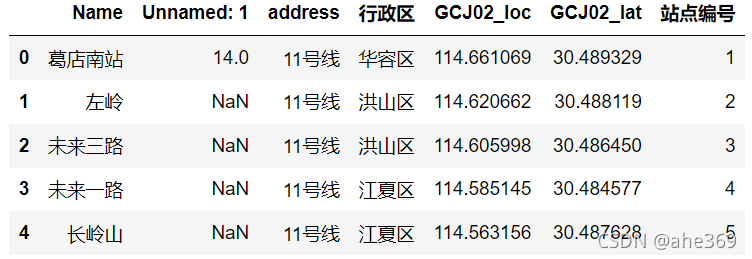
对比两个数据,可以看到GeoDataFrame数据多了一个几何列(geometry),记录数据的属性和坐标信息,几何列可以有多列,而活动几何(active geometry)列只能有一列,如果有关于对空间的方法,则自动作用到 active geometry列。如果想要改变活动几何列,则使用GeoDataFrame.set_geometry()方法
使用下面的方法可以将dataframe数据转换为Geodataframe数据
point = gpd.GeoDataFrame(df, geometry=gpd.points_from_xy(df.GCJ02_loc, df.GCJ02_lat))
options函数可以设置几何列显示的小数点位数,默认5位
gpd.options.display_precision = 5
数据导出
使用GeoDataFrame.to_file()方法可以导出为不多不同的格式,还可以使用GeoDataFrame.to_postgis方法将数据上传到PostGis数据库,元组或列表可以保存在Geopandas中,然而保存为Geopackage或者shp时可能报错。
world = world.set_geometry('borders')
#保存为shp形状文件
world['borders'].to_file(r'D:\Python\Geopython\Geopandas\世界地图\世界地图.shp')
#保存为geojson形状文件
world['borders'].to_file(r'世界地图.geojson', driver='GeoJSON')
2.绘制地图
基本功能
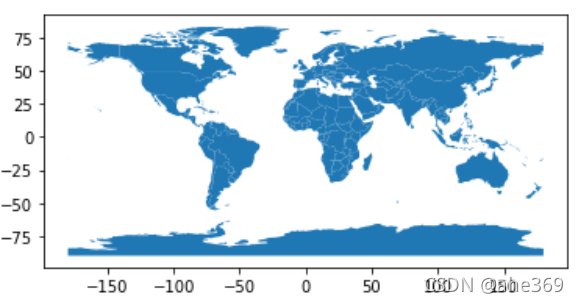
GeoPandas绘制地图使用matplotlib的接口,类似于DataFrame的plot()方法,其中的任何选项都可以在这里传递
#导入世界地图数据和城市数据
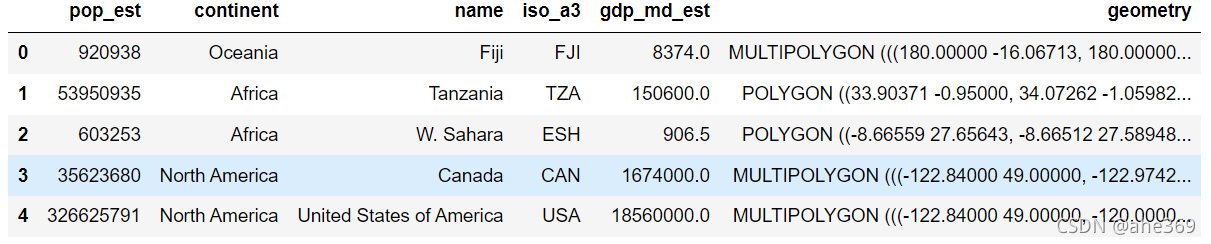
world = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres'))
cities = gpd.read_file(gpd.datasets.get_path('naturalearth_cities'))
#画图
world.plot()
分区统计图
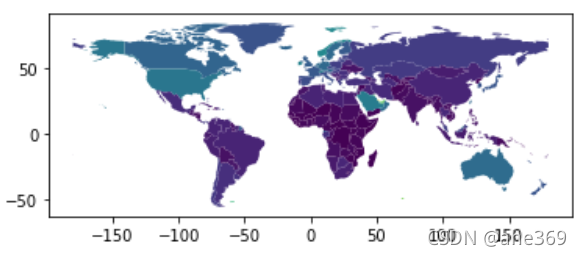
绘制分区统计图,根据关联的值确定形状的颜色,只需要将column设定为指定变量的列,
world = world[(world.pop_est>0) & (world.name!="Antarctica")]#筛选出人口大于0和非南极洲的地区
world['gdp_per_cap'] = world.gdp_md_est / world.pop_est#计算各个地区的人均gdp.dataframe.column返回对应列的series
world.plot(column='gdp_per_cap')#根据人均gdp绘制地图,区别颜色
制作图例
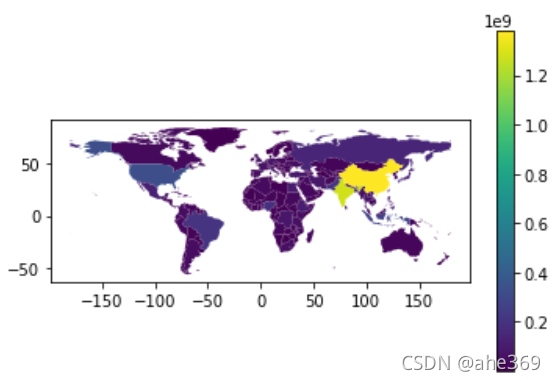
创建图例,使用面向对象的方法
fig, ax = plt.subplots(1, 1)
world.plot(column='pop_est', ax=ax, legend=True)#其中图例为颜色条
上面的图例并不好看,因此需要对图例进行美化,这段代码没看太懂,类似于fig与ax
from mpl_toolkits.axes_grid1 import make_axes_locatable
fig, ax = plt.subplots(1, 1)
divider = make_axes_locatable(ax)
cax = divider.append_axes("right", size="5%", pad=0.1)
world.plot(column='pop_est', ax=ax, legend=True, cax=cax)
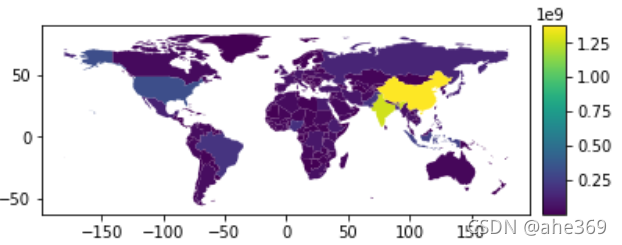
图片果然变得好看了呢,Sci风!
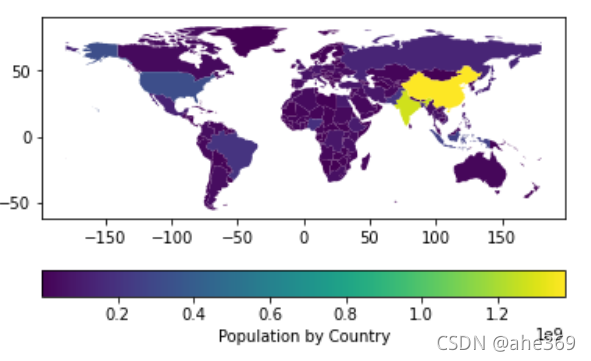
还可以将颜色条放在下面,并且设置颜色条的名称
fig, ax = plt.subplots(1, 1)
world.plot(column='pop_est',
ax=ax,
legend=True,#创建图例
legend_kwds={'label': "Population by Country",
'orientation': "horizontal"})#设置放置方式为水平
修改颜色
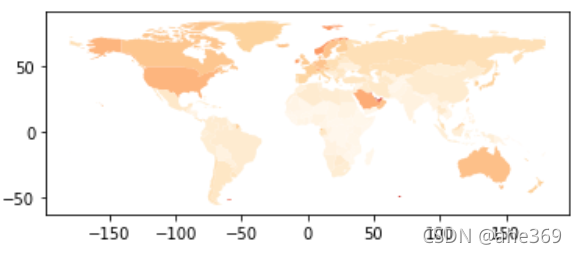
传入cmap参数还可以修改绘图的色系,具体的色系代码可以使用help()指令查阅,或者直接报错看提示也不失为一种方法!
world.plot(column='gdp_per_cap', cmap='OrRd')
绘制边界
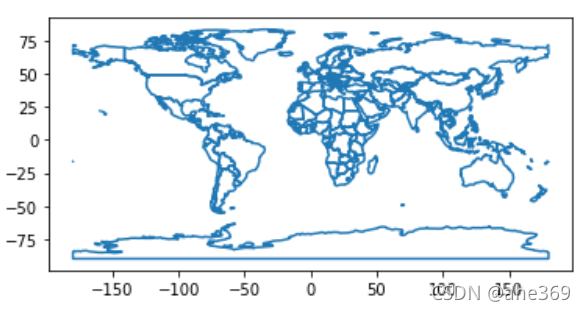
绘制边界有两种方法
#第一种类似将填充改为空白,然而none和None容易混淆
world.plot(facecolor="none", edgecolor="black")
#第二种方法更加清晰
world.boundary.plot()
对待缺失值,GeoPandas在绘制地图时会自动忽略,也可以对确实值的形式进行指定
指定图层的层数
即在同一个图上绘制多个图层,这是非常重要且实用h的功能,一共有两种方法,一种比较简介,一种更加灵活。在制作地图之间, 必须确保每个地图层拥有相同的CRS(方法后面会说到),即坐标系。依然使用前面导入的世界地图和城市数据,并对坐标系进行统一。
cities = cities.to_crs(world.crs)#统一坐标系
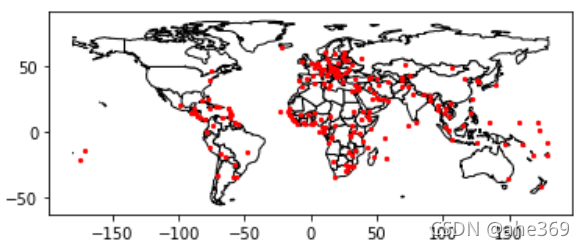
第一种方法是分开制作,按先后顺序确定图层
#方法一
base = world.plot(color='white', edgecolor='black')# 先制作世界地图
cities.plot(ax = base, marker='o', color='red', markersize=5)# 再直接画出来,使用ax关键字
第二种使用面向对象的方法
fig, ax = plt.subplots()
ax.set_aspect('equal')#将横纵比设置相等,当单独使用Geopandas时,自动完成
world.plot(ax = ax, color = 'white',edgecolor = 'black')
cities.plot(ax = ax, marker = 'o', color = 'red',markersize = 5)
plt.show()
通过使用zorder参数还可以控制图层的顺序,其中数字越小的越在下面
ax = cities.plot(color='k', zorder=2)
world.plot(ax=ax, zorder=1)
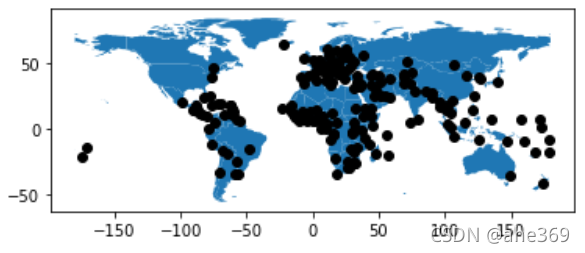
从绘制顺序来看,城市应该在下面,而通过指定zorder实现了改变。从这里也可看到使用面向对象的方式更加灵活,在绘制过程中直接指定即可。
同Pandas一样,Geopandas的plot()方法也可以绘制其他的图形,例如条形图、饼图等,只需要传入’kind’参数,具体可参考官方文档。不知道版本原因还是啥,我的一直报错。
总结一下plot()方法常用的用法有,具体参考官方文档
- column:根据该列的值确定地图的颜色
- legend: True/False, 是否增加图例
- ax:指定的画图对象
- legend_kwds:字典,设置图例的放置方式,label标明的文字,orientation放置的方向
- camp: 与legend搭配,设置色系.也可以单独使用,需要特殊的编码
- sheme:调整颜色的分配
- cax: 在彩色地图种指定图例的轴
- edgecolor:边的颜色
- marker: 点的形状
- markersize: 点的颜色
- zorder:画图的层数
- figsize = (,)设置画布的大小
除了上述静态图外,还可以使用explore()方法绘制动态交互地图
3.管理投影
管理投影一般有两个操作:定义投影和转换投影
通常情况下导入数据一般自带投影,如果必须可以使用GeoSeries.set_crs()方法,然而我在运行时会报错’‘GeoDataFrame’ object has no attribute ‘set_crs’’,可以试试geodataframe.crs = {‘init’: ‘epsg:3395’},其中{‘init’: ‘epsg:3395’}表示墨卡托投影,任何能够被pyproj.CRS.from_user_input()语句接受的字符串,都能被geopandas正确使用其他比较常用的还有’epsg: 4326’表示wgs84投影,具体的坐标系代码可以通过www.spatialreference.org查阅。
对坐标系转换的方法可以使用geodataframe.to_crs(),我的版本会报错’‘b’no arguments in initialization list’,运行pyproj.Proj("+init=epsg:4326")发现不是pyproj库的问题,于是按照之前坐标系转换的方法做了一点修改{‘init’: ‘epsg:3395’},应当传入proj4字典,最新版本的可以直接使用,将wgs84转换为墨卡托坐标
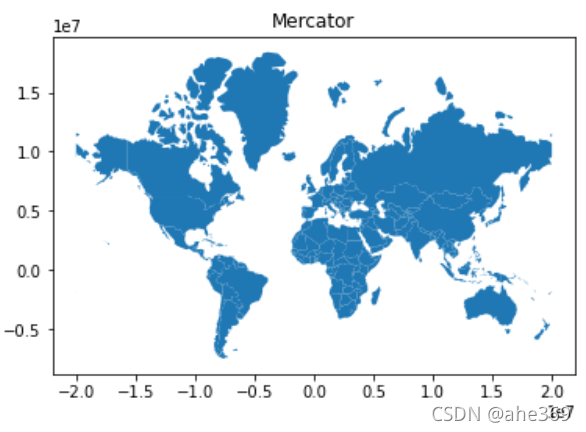
world = world[(world.name != "Antarctica") & (world.name != "Fr. S. Antarctic Lands")]
world = world.to_crs({'init': 'epsg:3395'}) # world.to_crs(epsg=3395) would also work
ax = world.plot()
ax.set_title("Mercator")
另外使用read_file()导入数据时,可以指定使用的坐标系,分为新的版本和旧的版本
## OLD
GeoDataFrame(..., crs={'init': 'epsg:4326'})
# or
gdf.crs = {'init': 'epsg:4326'}
# or
gdf.to_crs({'init': 'epsg:4326'})
## NEW
GeoDataFrame(..., crs="EPSG:4326")
# or
gdf.crs = "EPSG:4326"
# or
gdf.to_crs("EPSG:4326")
4.几何操作
对Geopandas中的几何文件进行操作主要有如下几个方法
- GeoSeries.buffer(distance, resolution=16) #根据距离对图形扩展
- GeoSeries.boundary #以圆形向周围扩展
- GeoSeries.centroid #质心
- GeoSeries.convex_hull #变成凸多边形
- GeoSeries.envelope #返回点或者与坐标轴平行矩形
- GeoSeries.simplify(tolerance, preserve_topology=True) #对图形进行简化
- GeoSeries.unary_union #进行合并
下面对一些方法进行举例
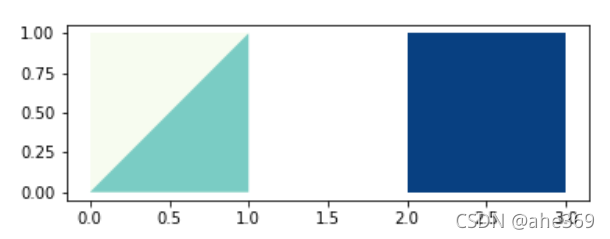
#生成数据,一个三角两个正方形
import geopandas as gpd
from geopandas import GeoSeries
from shapely.geometry import Polygon
p1 = Polygon([(0, 0), (1, 0), (1, 1)])
p2 = Polygon([(0, 0), (1, 0), (1, 1), (0, 1)])
p3 = Polygon([(2, 0), (3, 0), (3, 1), (2, 1)])
g = GeoSeries([p2,p1, p3])
g.plot(cmap = 'GnBu')
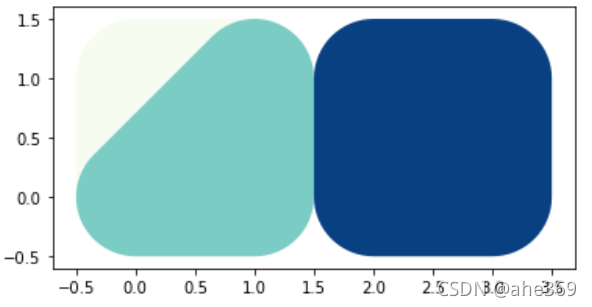
buffer操作,注意画完图后坐标轴的范围
#扩展距离为0.5
g.buffer(0.5)
g.buffer(0.5).plot(cmap = 'GnBu')
envelope操作,从结果可以看到,数据变成三个正方形了
g.envelope.plot(cmap = 'GnBu')
g
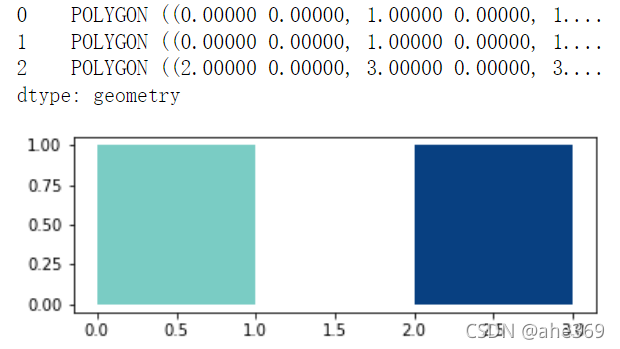
使用gdf.area()函数可以获取每个几何形状的面积
print(g.area)#返回pandas,每个元素的面积值

#获取城市的区域数据
nybb_path = gpd.datasets.get_path('nybb')
boros = gpd.read_file(nybb_path)
boros.set_index('BoroCode', inplace=True)#设置Geopandas的索引列
boros.sort_index(inplace=True)
boros.plot(cmap = 'GnBu')
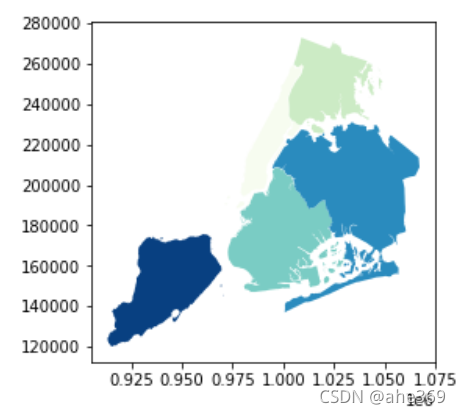
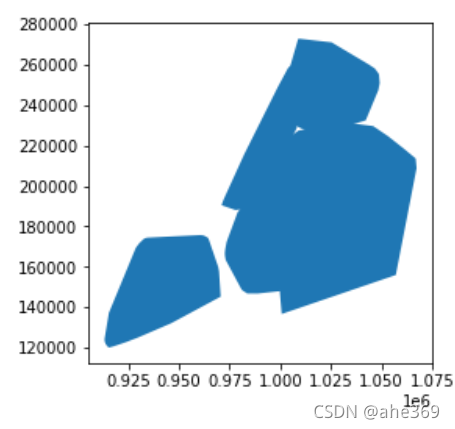
#凸多边形操作
boros['geometry'].convex_hull.plot()
其他操作为,类似美图秀秀,对图片缩放、偏斜等等
#其他操作
GeoSeries.affine_transform(self, matrix)
GeoSeries.rotate(self, angle, origin='center', use_radians=False)#对图形进行旋转
GeoSeries.scale(self, xfact=1.0, yfact=1.0, zfact=1.0, origin='center')#进行缩放
GeoSeries.skew(self, angle, origin='center', use_radians=False)#进行偏斜
GeoSeries.translate(self, xoff=0.0, yoff=0.0, zoff=0.0)#进行平移操作
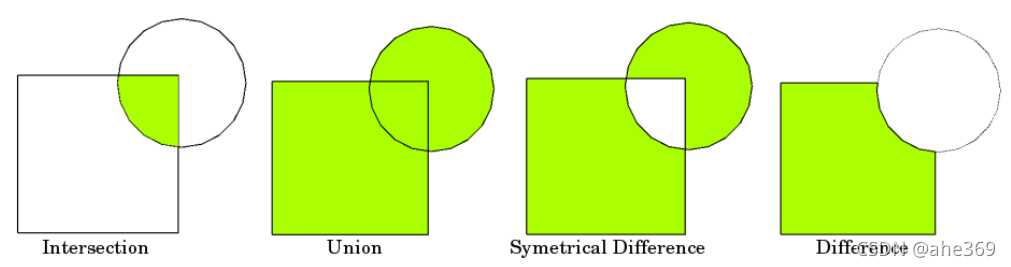
5.集合操作
根据重叠区域建立新的图形,主要使用函数为geodataframe.overlay()操作,具体的示意如下图
#创建基础的数据
from shapely.geometry import Polygon
polys1 = geopandas.GeoSeries([Polygon([(0,0), (2,0), (2,2), (0,2)]),
Polygon([(2,2), (4,2), (4,4), (2,4)])])
polys2 = geopandas.GeoSeries([Polygon([(1,1), (3,1), (3,3), (1,3)]),
Polygon([(3,3), (5,3), (5,5), (3,5)])])
df1 = geopandas.GeoDataFrame({'geometry': polys1, 'df1':[1,2]})
df2 = geopandas.GeoDataFrame({'geometry': polys2, 'df2':[1,2]})
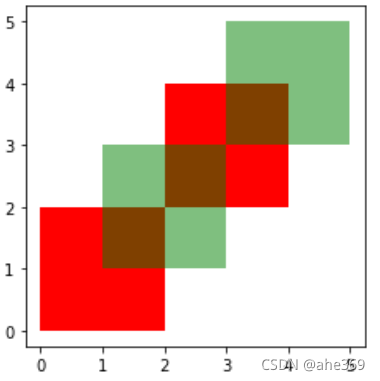
将例子画出来,原始的为两个形状红和绿,取并集后有多个图形,这里可以回顾一下多图层的画法
ax = df1.plot(color='red');
df2.plot(ax=ax, color='green', alpha=0.5)#第一种画图方法
#取并集操作
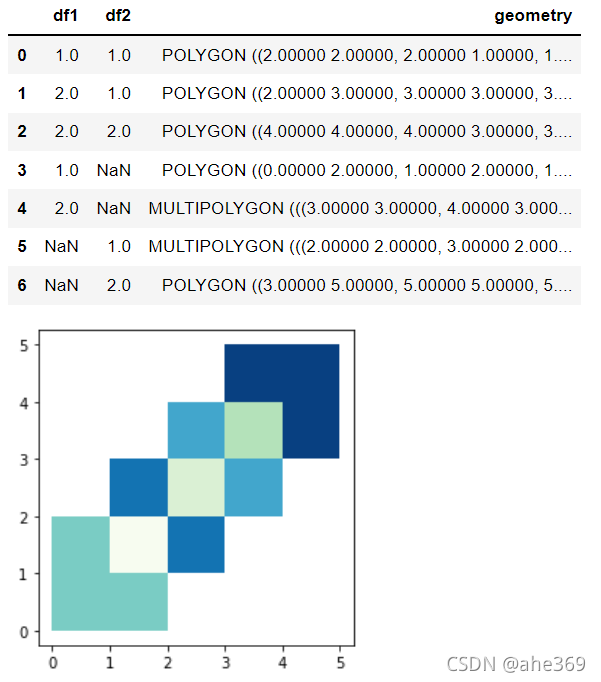
res_union = gpd.overlay(df1,df2, how='union')#或者df1.overlay(df2,how = '')我的版本会报错
res_union.plot(cmap = 'GnBu')
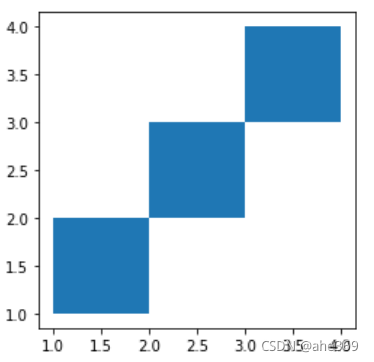
#取交集
res_intersection = gpd.overlay(df1, df2, how='intersection')
res_intersection.plot()
#df1['geometry'].intersection(df2['geometry'])同样的效果
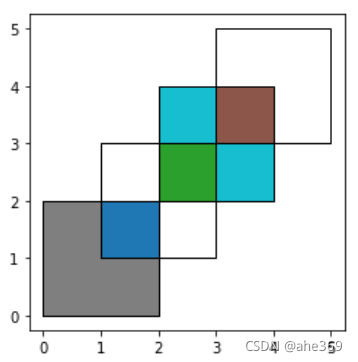
#identity表示取本身,加上交集
res_identity = gpd.overlay(df1, df2, how='identity')
res_identity
ax = res_identity.plot(cmap='tab10')
df1.plot(ax=ax, facecolor='none', edgecolor='k')
df2.plot(ax=ax, facecolor='none', edgecolor='k')
5.聚合与连接
聚合
在非空间数据中,我们可以使用groupby()函数对数据进行汇总。在空间数据中,我们可以使用dissolve()函数聚合几何特征
#加入我们只有国家的数据,而我们要研究大陆的特征
world = geopandas.read_file(geopandas.datasets.get_path('naturalearth_lowres'))
world = world[['continent', 'geometry']]
#通过大陆属性进行聚合
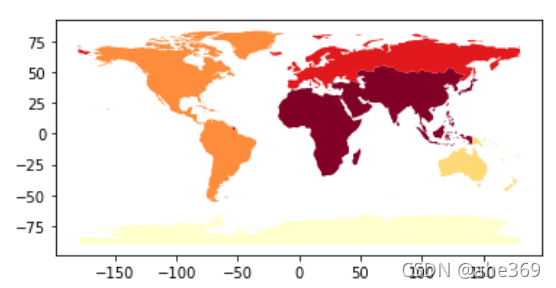
continents = world.dissolve(by='continent')#同一个大陆的聚合在一起
continents.plot()
continents.head()#只有大洲的数据了
#如果对聚合后的其他性质感兴趣,可以对dissolve函数传递不同的参数
world = geopandas.read_file(geopandas.datasets.get_path('naturalearth_lowres'))
world = world[['continent', 'geometry', 'pop_est']]
continent = world.dissolve(by = 'continent', aggfunc = 'sum')
continent.plot(column = 'pop_est', scheme='quantiles', cmap='YlOrRd')#scheme类似做一个归一化处理
#其他参数有:‘first’’last’‘min’‘max’‘sum’‘mean’‘median’
连接
连接主要分为属性连接(attribute joins)和空间连接(spatial joins)
#先导入基本的数据要素
world = geopandas.read_file(geopandas.datasets.get_path('naturalearth_lowres'))
cities = geopandas.read_file(geopandas.datasets.get_path('naturalearth_cities'))
# for attribute joins
country_shapes = world[['geometry', 'iso_a3']]
country_names = world[['name', 'iso_a3']]
#for spatial joins
countries = world[['geometry', 'name']]
countries = countries.rename(columns={'name':'country'})#更换列名,将name更换为country
属性连接主要使用geodataframe.merge()方法,和pandas的merge()用法相似,如果使用pandas.merge()对GeoDateFrame方法进行连接,则返回结果不再是GeoDataFrame数据
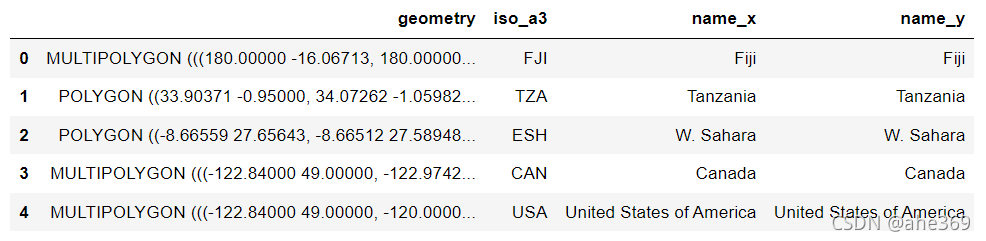
#根据iso_a3列对两个数据进行连接
country_shapes = country_shapes.merge(country_names, on = 'iso_a3')
country_shapes.head()
空间链接,使用gdf.sjoin()函数,spacial joins两个Geometry数据的连接,基于他们的空间关系
#一个国家数据,一个点的数据,通过空间关系进行连接
countries.head()
cities.head()
#cities_with_country = cities.sjoin(countries, how="inner", predicate='intersects')官网给的该方法报错,没有sjoin属性
cities_with_country = gpd.sjoin(cities, countries, how="inner")#没有关键字predicate
#结果差不多
Geopandas提供了两个空间连接函数
- gpd.sjoin(),基于binary predicates (intersects, contains, etc.)二进制谓词
- 和gpd.sjoin_nearest(), 基于邻进度,可以设置最大搜索半径
- gpd.sjoin()有两个核心how 和 predicate
- predicate: intersects\contains\within\touches\crosses\overlaps
- how:left\right\inner,其中inner使用共同的索引值,并且只保留左边的Geodf
另外使用gdf.append()可以对gdf数据进行拼接,类似pandas中的append()方法。同理pd.concat([])方法也可以使用
joined = world.geometry.append(cities.geometry)
pd.concat([world, cities])
总结
以上就是对GeoPandas库简单学习过程,该库可以和OSMnx结合,从OSMnx库获取地图资源,再通过GeoPandas进行可视化,以后有机会可以分享一下OSMnx的学习过程。下面为通过GeoPandas库制作的效果图
参考
Geopandas官网(https://geopandas.org/en/stable/index.html)