本文主要写神经网络Tensorflow的相关函数
目录
Tensorflow的相关函数
强制tensor转换为该数据类型:tf.cast (张量名,dtype=数据类型)
计算张量维度上元素的最小值:tf.reduce_min (张量名)
计算张量维度上元素的最大值:tf.reduce_max (张量名)
axis
reduce_mean()
reduce_sum()
Variable()
TensorFlow中的数学运算
对应元素的四则运算:tf.add,tf.subtract,tf.multiply,tf.divide
举例:
平方、次方与开方: tf.square,tf.pow,tf.sqrt
data.Dataset.from_tensor_slices
GradientTape
enumerate
one_hot
nn.softmax
assign_sub
argmax
下篇文章会讲利用神经网络实现鸢尾花分类的具体代码
Tensorflow的相关函数
强制tensor转换为该数据类型:tf.cast (张量名,dtype=数据类型)
计算张量维度上元素的最小值:tf.reduce_min (张量名)
计算张量维度上元素的最大值:tf.reduce_max (张量名)
举例:
x1 = tf.constant ([1., 2., 3.], dtype=tf.float64)
print(x1)
x2 = tf.cast (x1, tf.int32)
print(x2)
print (tf.reduce_min(x2), tf.reduce_max(x2))
运行结果:
tf.Tensor([1. 2. 3.], shape=(3,), dtype=float64)
tf.Tensor([1 2 3], shape=(3,), dtype=int32)
tf.Tensor(1, shape=(), dtype=int32)
tf.Tensor(3, shape=(), dtype=intt32)
tf. Cast 用于实现强制类型转换 把这个张量转换为指定类型
可以用reduce_min()找到这个张量中的最小值
可以用reduce_max()找到这个张量中的最大值
我们构造一个张量 他把转换为32位整型
他的最小值时1 最大值是3
axis
在一个二维张量或数组中,可以通过调整 axis 等于0或1 控制执行维度。
axis=0代表跨行(经度,down),而axis=1代表跨列(纬度,across)
如果不指定axis,则所有元素参与计算。

axis可以指定操作的方向
对于一个二维张量
如果axis=0 表示对第一个维度进行操作 纵向操作 沿经度方向
如果axis=1 表示对第一个维度进行操作 横向操作 沿维度方向
如果axis不知道 表示对所有维度进行操作
reduce_mean()
计算张量沿着指定维度的平均值
tf.reduce_mean (张量名,axis=操作轴)
x=tf.constant([[1,2,3],[2,2,3]])
print(x)
print(tf.reduce_mean( x ))
运行结果:
tf.Tensor([[1 2 3][2 2 3]], shape=(2, 3), dtype=int32)
tf.Tensor(2, shape=(), dtype=int32) 比如我们可以通过调整axis=0或者1来控制求平均值的方向
不指定 则对所有元素进行操作
两行三列种所有元素求均值 均值位2
reduce_sum()
计算张量沿着指定维度的和
tf.reduce_sum (张量名,axis=操作轴)
举例:
x=tf.constant([[1,2,3],[2,2,3]])
print(x)
print(tf.reduce_sum( x, axis=1 ))
运行结果:
tf.Tensor([[1 2 3][2 2 3]], shape=(2, 3), dtype=int32)
tf.Tensor([6 7], shape=(2,), dtype=int32)横向求和 第一行和为6 第二行和为7
Variable()
tf.Variable () 将变量标记为“可训练”,被标记的变量会在反向传播 中记录梯度信息。神经网络训练中,常用该函数标记待训练参数。
tf.Variable(初始值)
w = tf.Variable(tf.random.normal([2, 2], mean=0, stddev=1))Variable函数可以将变量标记为“可训练”的
被它标记了的变量会在反向传播中记录自己的梯度信息
神经网络训练中常用这个函数标记待训练的参数
这个例子就是神经网络初始化参数w的代码
随机生成正态分布随机数
再给生成的随机数标记为可训练
这样在反向传播中就可以通过梯度下降更新参数w了
TensorFlow中的数学运算
对应元素的四则运算:tf.add,tf.subtract,tf.multiply,tf.divide
实现两个张量的对应元素相加
tf.add (张量1,张量2)
实现两个张量的对应元素相减
tf.subtract (张量1,张量2)
实现两个张量的对应元素相乘
tf.multiply (张量1,张量2)
实现两个张量的对应元素相除
tf.divide (张量1,张量2)
只有维度相同的张量才可以做四则运算实现两个张量对应元素相加用tf. add (张量1,张量2)
实现两个张量对应元素相减用tf. subtract(张量1,张量2)
实现两个张量对应元素相乘用tf. multiply(张量1,张量2)
实现两个张量对应元素相除用t divide张量1.张量2)
只有维度相同的张量才可以做四则运算
举例:
a = tf.ones([1, 3])
b = tf.fill([1, 3], 3.)
print(a)
print(b)
print(tf.add(a,b))
print(tf.subtract(a,b))
print(tf.multiply(a,b))
运行结果:
tf.Tensor([[1. 1. 1.]], shape=(1, 3), dtype=float32)
tf.Tensor([[3. 3. 3.]], shape=(1, 3), dtype=float32
tf.Tensor([[4. 4. 4.]], shape=(1, 3), dtype=float32)
tf.Tensor([[-2. -2. -2.]], shape=(1, 3), dtype=float32)
tf.Tensor([[3. 3. 3.]], shape=(1, 3), dtype=float32)
举个例子看一下效果
先创建一个张量 一行三列 全为1
再创建一个张量 一行三列 全为3
进行四则运算 得到结果
平方、次方与开方: tf.square,tf.pow,tf.sqrt
计算某个张量的平方
tf.square (张量名)
计算某个张量的n次方
tf.pow (张量名,n次方数)
计算某个张量的开方
tf.sqrt (张量名)
a = tf.fill([1, 2], 3.)
print(a)
print(tf.pow(a, 3))
print(tf.square(a))
print(tf.sqrt(a))
运行结果:
tf.Tensor([[3. 3.]], shape=(1, 2), dtype=float32)
tf.Tensor([[27. 27.]], shape=(1, 2), dtype=float32)
tf.Tensor([[9. 9.]], shape=(1, 2), dtype=float32)
tf.Tensor([[1.7320508 1.7320508]],
shape=(1, 2), dtype=float32)
举个例子看一下效果
创建一个张量 一行两列 全为3
进行平方 开放 次方运算
data.Dataset.from_tensor_slices
切分传入张量的第一维度,生成输入特征/标签对,构建数据集
data = tf.data.Dataset.from_tensor_slices((输入特征, 标签))
(Numpy和Tensor格式都可用该语句读入数据)神经网络在训练时 是把输入特征和标签配对后喂入网络的
Tensorflow给出了把特征和标签配对的函数from_tensor_slices
这个函数对numpy格式和tensor格式都适用
举例:
features = tf.constant([12,23,10,17])
labels = tf.constant([0, 1, 1, 0])
dataset = tf.data.Dataset.from_tensor_slices((features, labels))
print(dataset)
for element in dataset:
print(element)
运行结果:
<TensorSliceDataset shapes: ((),()), types: (tf.int32, tf.int32))> (特征,标签)配对
(<tf.Tensor: id=9, shape=(), dtype=int32, numpy=12>, <tf.Tensor: id=10, shape=(), dtype=int32, numpy=0>)
(<tf.Tensor: id=11, shape=(), dtype=int32, numpy=23>, <tf.Tensor: id=12, shape=(), dtype=int32, numpy=1>)
(<tf.Tensor: id=13, shape=(), dtype=int32, numpy=10>, <tf.Tensor: id=14, shape=(), dtype=int32, numpy=1>)
(<tf.Tensor: id=15, shape=(), dtype=int32, numpy=17>, <tf.Tensor: id=16, shape=(), dtype=int32, numpy=0>)
举个例子看一下:
收集特征是12 23 10 17每个特征对应的标签是0 1 1 0
用这个函数把特征和标签配上对
看程序运行结果:
特征12和标签0相对应
特征23和标签1相对应
特征10和标签1相对应
特征17和标签0相对应
GradientTape
with tf.GradientTape( ) as tape:
若干个计算过程
grad=tape.gradient(函数,对谁求导)我们可以在with结构中使用Gradient Tape函数实现某个函数对指定参数的求导运算
配合前面讲过的 gradient函数可以实现损失函数loos对参数w的求导计算
with tf.GradientTape( ) as tape:
w = tf.Variable(tf.constant(3.0))
loss = tf.pow(w,2)
grad = tape.gradient(loss,w)
print(grad)
运行结果:
tf.Tensor(6.0, shape=(), dtype=float32)

在这个例子中:
W初始值为3 损失函数是w的平方 损失函数对w求导数 是2w
把初始值w=3.0带入得到结果为6.0
计算机运行的结果也是6.0
enumerate
enumerate是python的内建函数,它可遍历每个元素(如列表、元组 或字符串)
组合为:索引 元素,常在for循环中使用。
enumerate(列表名)
enumerate是枚举的意思
它可以枚举出每一个元素 并在元素前配上对应的索引号
组合为:索引元素 常在for循环中使用
seq = ['one', 'two', 'three']
for i, element in enumerate(seq):
print(i, element)
运行结果:
0 one
1 two
2 three
举例:
i 接收 索引号 element接收 元素 运行结果如上
one_hot
独热编码(one-hot encoding):在分类问题中,常用独热码做标签, 标记类别:1表示是,0表示非。

在实现分类问题时 我们常用独热码表示标签
比如我们之前提到的鸢尾花分类 如果标签是1 表示分类结果是1杂色鸢尾
把他用独热码的型式表示:
标签: 1
独热码: ( 0 . 1 . 0 .)
这样可以表示出每个分类的概率 也就是百分之0的可能是0狗尾草鸢尾
tf.one_hot()函数将待转换数据,转换为one-hot形式的数据输出。
tf.one_hot (待转换数据, depth=几分类)Tensorflow中提供了one_hot函数 可以将待转换数据,直接转换为独热码形式形式
两个参数:(带转换数据 几分类)
举例:
classes = 3
labels = tf.constant([1,0,2]) # 输入的元素值最小为0,最大为2
output = tf.one_hot( labels, depth=classes )
print(output)
运行结果:
[[0. 1. 0.]
[1. 0. 0.]
[0. 0. 1.]], shape=(3, 3), dtype=float32)
比如:
对于三分类 一组标签是1 0 2
转换为独热码型式
把 标签1 标签0 标签2 转为为独热码 结果是 010 100 001
nn.softmax
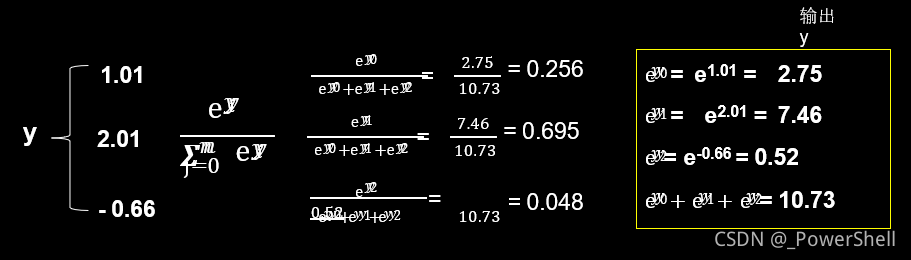

0-1概率函数
对于分类问题 神经网络完成前向传播 计算出了每种类型的可能性大小1.01 2.01 -0.66
这些数字只有符合概率分布后 才可以与独热码的标签作比较
于是我们使用这个公式 使输出符合概率分布 结果是0.256 0. 695 0. 048和为1
0. 256表示0类鸢尾的概率是25. 6%
Tensorflow 中可以使用softmax函数 实现这个公式的计算
当n分类的n个输出 (y0 ,y1, …… yn-1)通过softmax( ) 函数, 便符合概率分布了。

举例:
y = tf.constant ( [1.01, 2.01, -0.66] )
y_pro = tf.nn.softmax(y)
print("After softmax, y_pro is:", y_pro)
输出结果:
After softmax, y_pro is: tf.Tensor([0.25598174 0.69583046 0.0481878], shape=(3,), dtype=float32)
举例:
创建如图张量:送入 softmax函数 输出就符合概率分布的值
assign_sub
赋值操作,更新参数的值并返回。
调用assign_sub前,先用 tf.Variable 定义变量 w 为可训练(可自更新)。
w.assign_sub (w要自减的内容) w -= 1 即 w = w - 1
Assign_sub函数:常用于参数的自更新 等待自更新的参数w 要先被指定为可更新可训练
w = tf.Variable(4)
w.assign_sub(1)
print(w)
运行结果:
<tf.Variable 'Variable:0' shape=() dtype=int32, numpy=3>
比如:
这个例子里w要先被定义为variable类型 初始值是4 I
对w做自减操作,可以用W. assign_sub(1)函数 1表示自减1
这个例子的运行结果:
W的初始值4做自减1操作 w被更新为3
argmax
返回张量沿指定维度最大值的索引
tf.argmax (张量名,axis=操作轴)
tf.argmax可以返回指定操作轴方向最大值的索引号
axis=0表示经度 axis=0表示纬度
import numpy as np
test = np.array([[1, 2, 3], [2, 3, 4], [5, 4, 3], [8, 7, 2]])
print(test)
print( tf.argmax (test, axis=0)) # 返回每一列(经度)最大值的索引
print( tf.argmax (test, axis=1)) # 返回每一行(纬度)最大值的索引
[[1 2 3]
[2 3 4]
[5 4 3]
[8 7 2]]
tf.Tensor([3 3 1], shape=(3,), dtype=int64)
tf.Tensor([2 2 0 0], shape=(4,), dtype=int64)
比如:
1 2 5 8 最大8 8索引号 3,2 3 4 7最大7 索引号 3,3 4 3 2最大4 索引号 1
1 2 3 最大3 3索引号 2,2 3 4 最大4 索引号 2,5 4 3最大5 索引号 0,8 7 2最大8 索引号 0