SparkStreaming接收Flume数据方式一:Push模式
- 一、前置工作
- 二、Flume之Push模式
- 三、Flume配置
- 四、编写程序
- 五、运行验证
一、前置工作
- 需安装Flume,安装可参考:Flume安装配置与基本操作
二、Flume之Push模式
-
Push模式说明
Flume 被 用 于 在 Flume agents 之 间 推 送 数 据 . 在 这 种 方 式 下 ,Spark Streaming 可以很方便的建立一个 receiver,起到一个 Avro agent 的作用.Flume 可以将数据推送到改 receiver.
三、Flume配置
- Flume之Agent的结构,如下
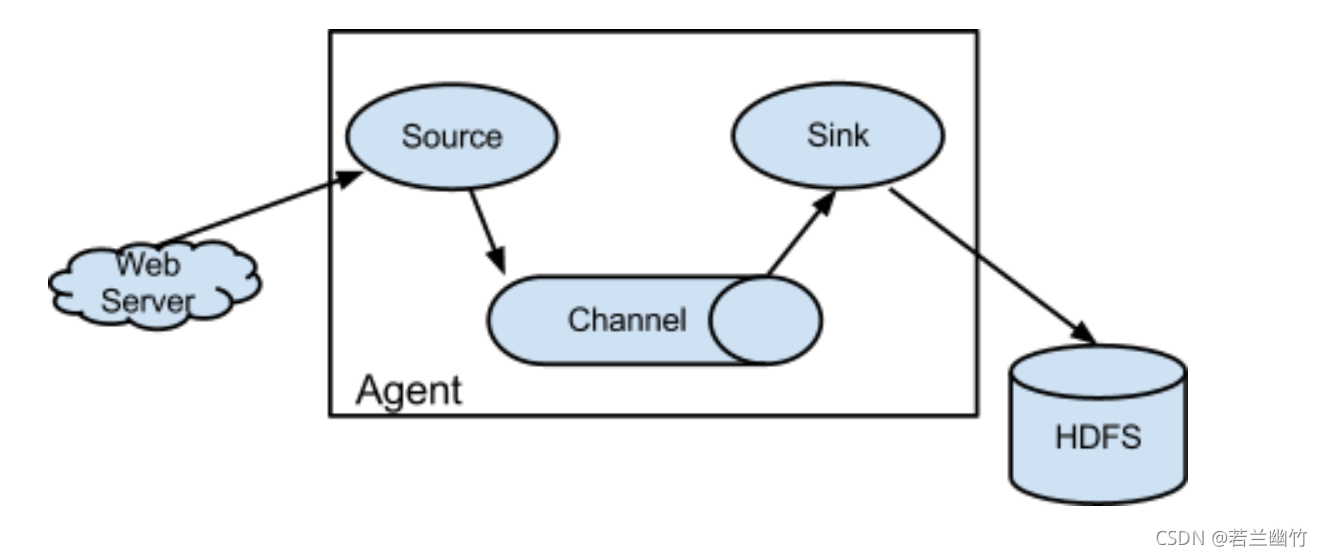
- 确定source、channel、sink,如下:
- source为:
spooldir - channel:
memory - sink:
avro
- source为:
- 在Flume的安装目录下的conf目录下创建a3.conf,添加如下内容:
# 定义agent的三大组件 a1.sources = r1 a1.channels = c1 a1.sinks = k1 #定义source a1.sources.r1.type=spooldir a1.sources.r1.spoolDir=/training/nginx/logs/flumeLogs a1.sources.r1.fileHeader=true # 定义sink a1.sinks.k1.type=avro a1.sinks.k1.channel=c1 a1.sinks.k1.hostname=192.168.88.1 a1.sinks.k1.port=1234 # 定义channel a1.channels.c1.type=memory a1.channels.c1.capacity=10000 a1.channels.c1.transactionCapacity= 100 # 定义三者关系 a1.sources.r1.channels=c1 a1.sinks.k1.channel=c1
四、编写程序
-
程序功能说明:
该程序接收Flume推送过来的数据:
一、查看下原始数据;
二、将数据简单处理,完成数据的统计,如求各个部门员工工资 -
编写程序,代码如下:
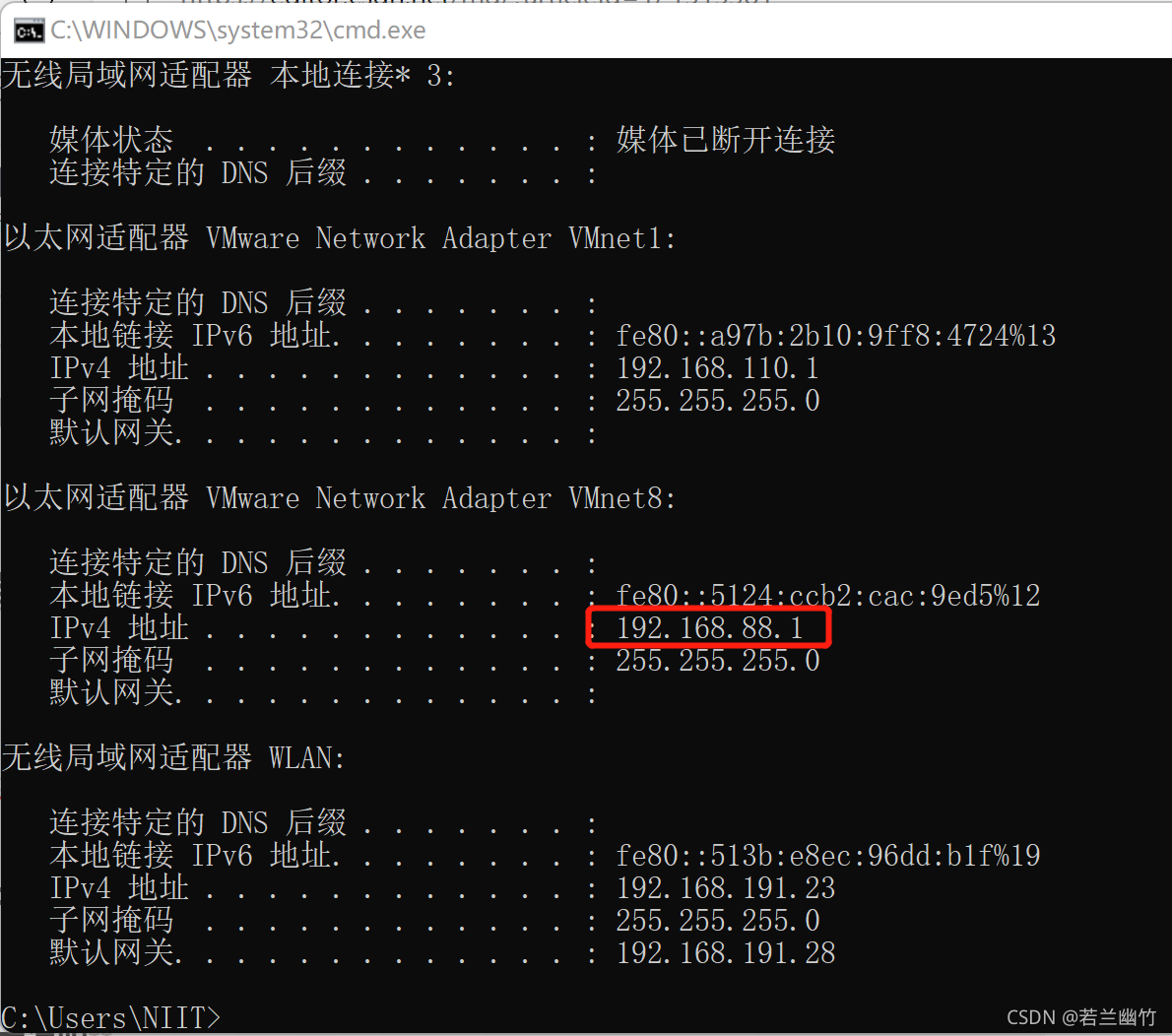
import org.apache.spark.SparkConf import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.flume.{FlumeUtils, SparkFlumeEvent} import org.apache.spark.streaming.{Seconds, StreamingContext} object FlumeDemo { def main(args: Array[String]): Unit = { val sparkConf = new SparkConf().setMaster("local[2]").setAppName("FlumeDemo") val streamingContext = new StreamingContext(sparkConf, Seconds(2)) // 192.168.88.1为Windows中虚拟机网卡vmnet8的IP地址 val flumeEvent: ReceiverInputDStream[SparkFlumeEvent] = FlumeUtils.createStream(streamingContext, "192.168.88.1", 2345,StorageLevel.MEMORY_AND_DISK_SER) // 查看接收到的原始数据 val flumeDStream: DStream[String] = flumeEvent.map(e => { println(new String(e.event.getBody.array())) new String(e.event.getBody.array()) }) // 分词,组合 val mapDStream: DStream[(Int,Int)] = flumeDStream.map(x => { val strings = x.trim.split(",") val salary = strings(5).toInt val deptNo = strings(7).toInt (deptNo,salary) }) // 实现统计 val resultDStream: DStream[(Int, Int)] = mapDStream.reduceByKey(_ + _) // 打印结果 resultDStream.print() // 启动实时计算 streamingContext.start() // 等待计算结束 streamingContext.awaitTermination() } }特别注意:程序中的IP地址为Windows上的虚拟机网卡即vmnet8的IP地址,如下图所示:
五、运行验证
-
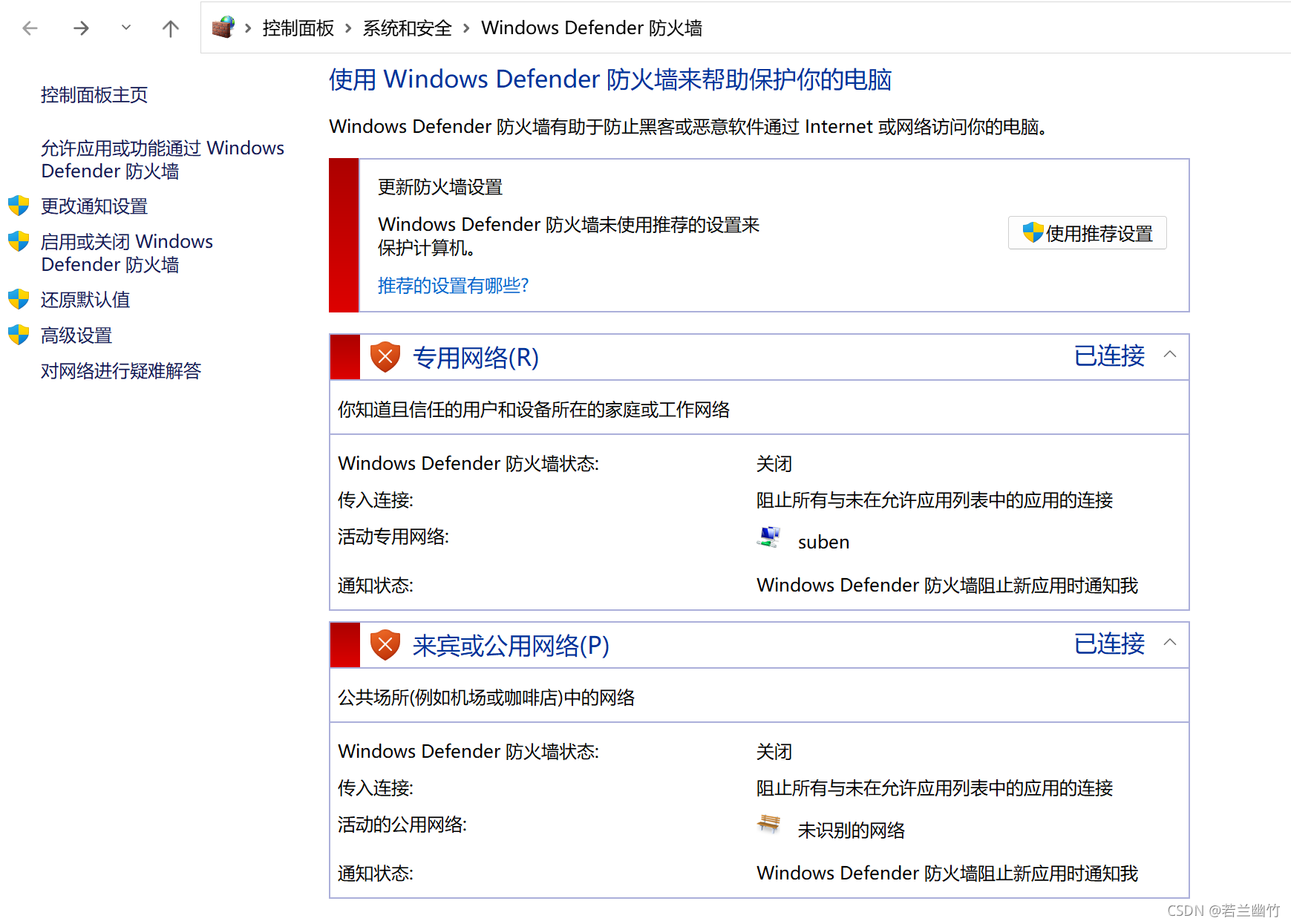
实验成功关键:需关闭Windows的防火墙,代码中的IP地址为Windows中虚拟机网卡vmnet8的IP地址,虚拟机中flume启动后需要访问到该地址,故需要关闭Windows防火墙。关闭后,如下图所示:
-
运行上述编写的程序,如下所示:
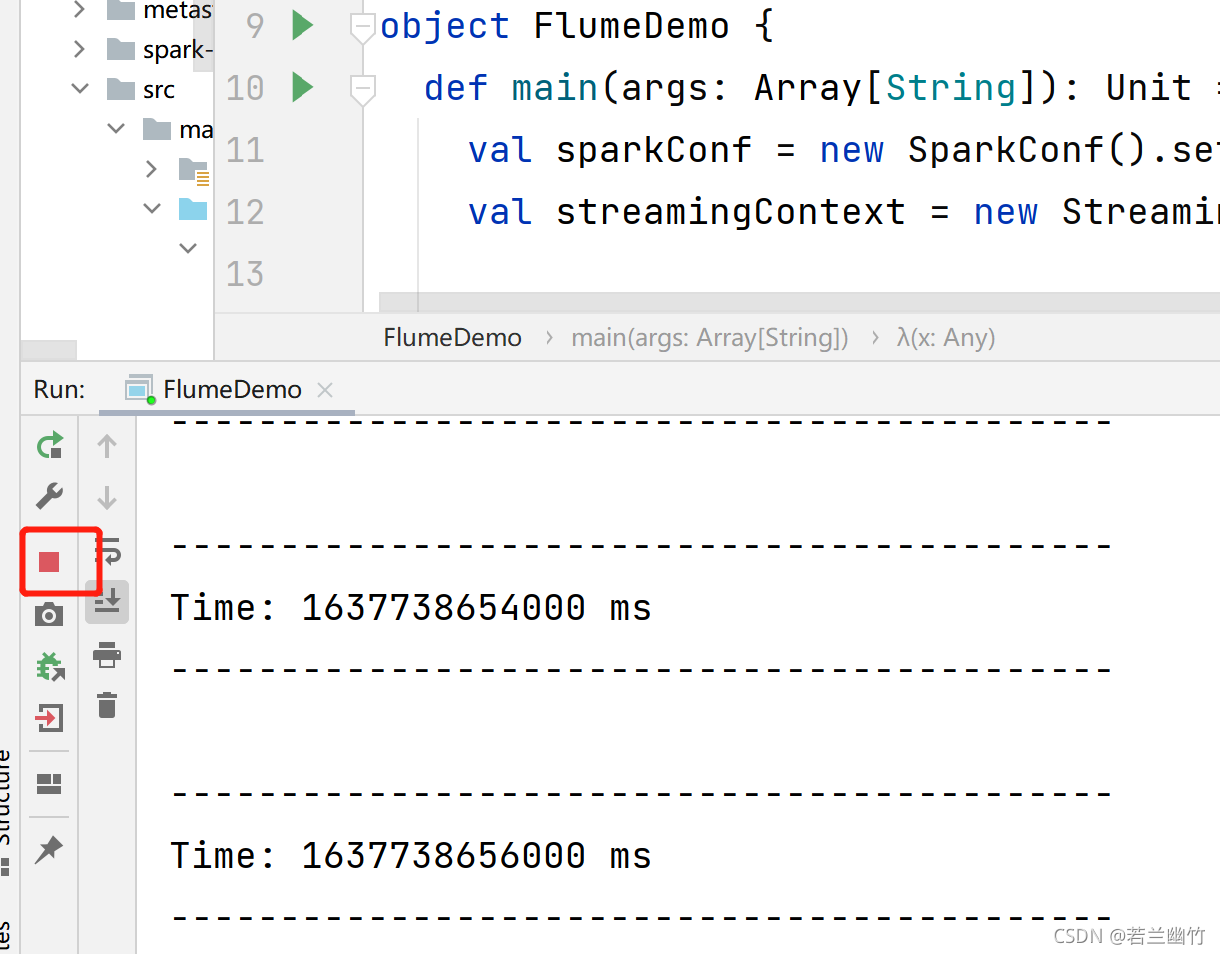
-
启动Flume,如下命令:
flume-ng agent -n a1 -f conf/a3.conf -Dflume.root.logger=INFO,console启动成功后,如下所示:
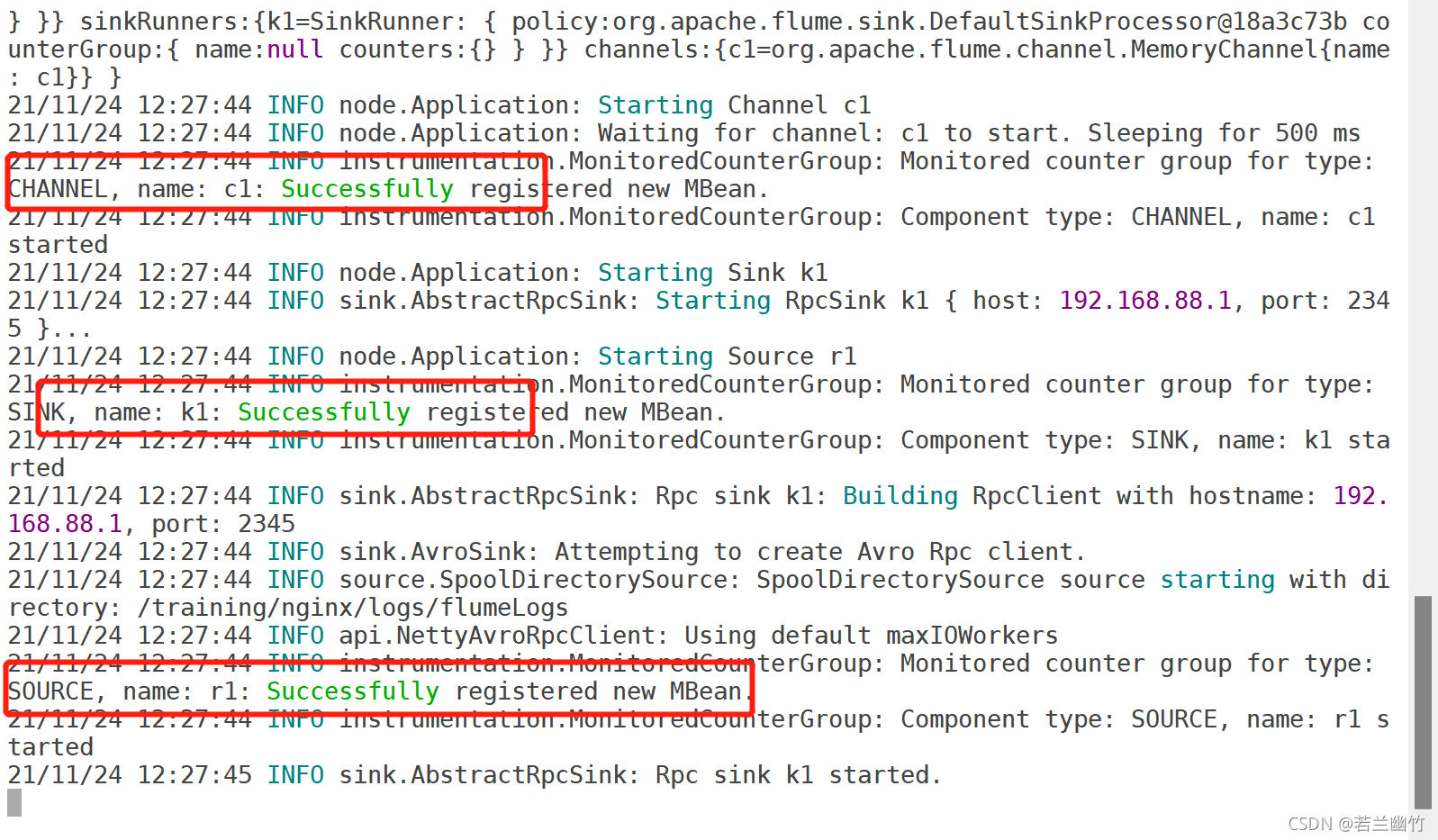
-
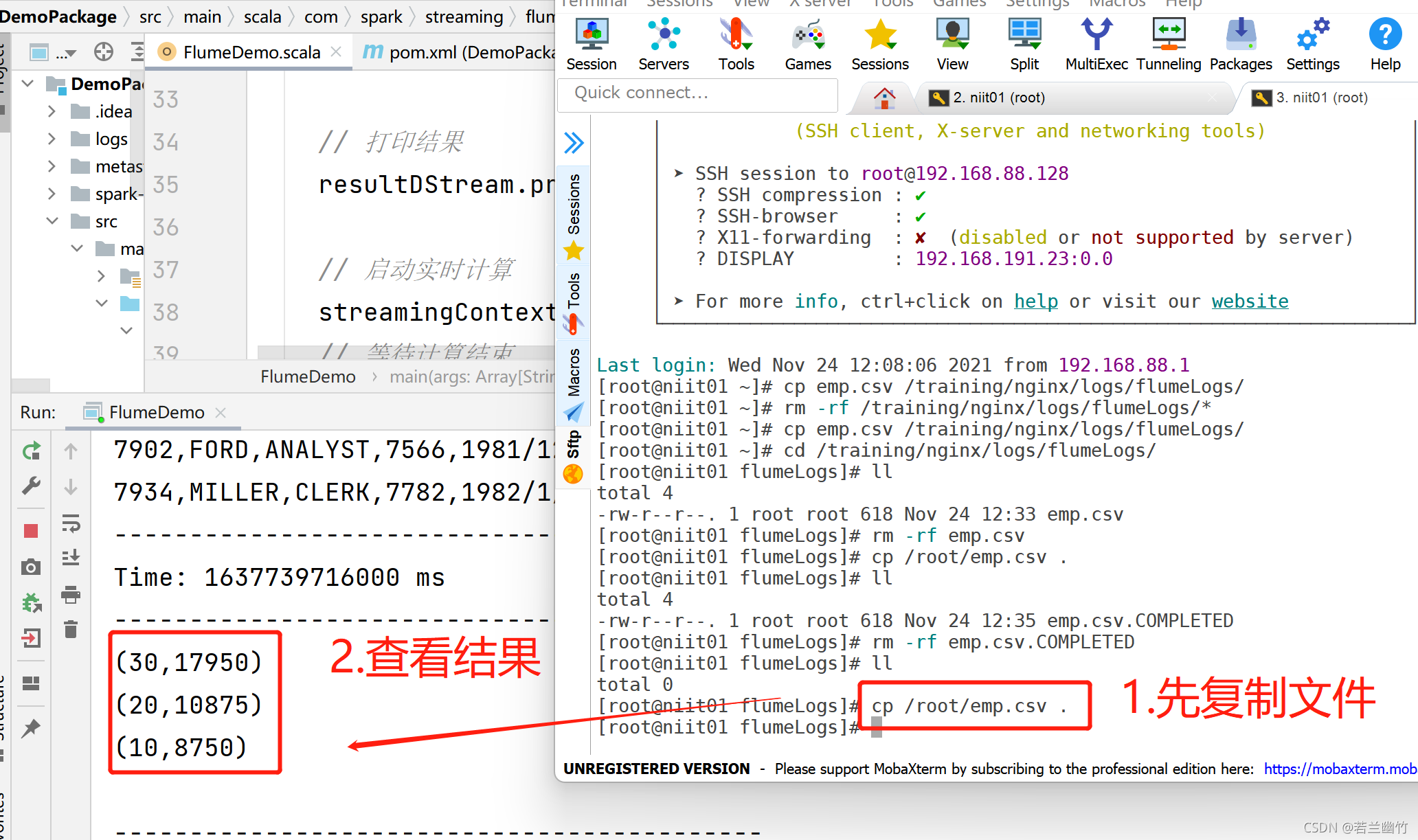
将文件emp.csv(如没有,则先上传到虚拟机中)复制到Fume的source所对应的目录下(/training/nginx/logs/flumeLogs),如下所示:
cp /root/emp.csv /training/nginx/logs/flumeLogs/ -
查看程序是否读取到数据并完成数据的处理,结果如下图所示: