文章目录
- 一、Selenium + PhantomJS | Chrome | Firefox
- 1、Selenium概述
- 2、PhantomJS概述
- 3、环境安装
- 4、selenium + Chrome
- 二、Selenium常用方法
- 1、浏览器对象
- 2、定位节点
- 3、节点对象方法
- 4、selenium+Chrome案例
- 三、Selenium 高级操作
- 1、设置无界面模式
- 2、selenium执行JS脚本
- 3、练习
- 4、selenium键盘操作
- 5、selenium鼠标操作
- 6、selenium切换句柄
- 7、selenium frame
- 9、控制浏览器操作的一些方法
讲解selenium之前,为了让读者更明白selenium,我会贴一些网站的图片和代码。
但是,【注意!!!】
【以下网站图片和代码仅供展示!!如果大家需要练习,请自己再找别的网站练习。】
【尤其是政府网站,千万不能碰哦!】
一、Selenium + PhantomJS | Chrome | Firefox
1、Selenium概述
- 定义
- 开源的Web自动化测试工具
- 特点
- 可根据指令操控浏览器
- 只是工具,必须与第三方浏览器结合使用
- 安装
- Linux:
sudo pip3 install selenium - Windows:
python -m pip install selenium
- Linux:
2、PhantomJS概述
- 定义
- 无界面浏览器(又称无头浏览器) 在内存中进行页面加载,高效
- 使用场景
- 页面自动化测试:自动登录网站并做操作然后检查结果是否正常
- 网页监控:定期打开页面,检查网站是否正常加载,加载结果是否符合预期,加载速度如何等。
- 网络爬虫:获取页面中数据
3、环境安装
-
以下三种方式安装一组即可
- selenium + PhantomJS
- selenium + chromedriver + Chrome
- selenium + geckodriver + Firefox
-
说明
- 以上3种组合任选其一,都可以实现基于selenium的强大网络爬虫
- chrome需要安装浏览器驱动器:chromedriver
- Firefox需要安装浏览器驱动器:geckodriver
-
下载地址
- chromedriver:http://npm.taobao.org/mirrors/chromedriver/
- geckodriver:https://github.com/mozilla/geckodrive/releases
- PhantomJS:https://phantomjs.org/downloqd.html
-
chromedriver版本要和浏览器大版本对应,否则会闪退


-
Windows安装
- 下载对应版本的PhantomJS、chromedriver、geckodriver
- 把解压后文件拷贝到python安装目录的Scripts目录下
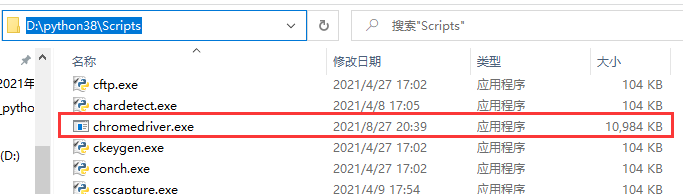
- 查看python安装目录(cmd命令行): where python

-
Ubuntu安装
- 下载后解压
- 拷贝解压后的文件到 /usr/bin/ 目录下
- 添加x权限
-
命令实现
- 解压:
tar -zxvf xxx.tar.gz - 拷贝:
sudo cp chromedriver /usr/bin - 权限:
sudo chmod +x /usr/bin/chromedriver
- 解压:
-
Windows 和 Ubuntu 验证 - 终端
- from selenium import webdriver
- browser = webdriver.Chrome()
- browser = webdriver.Firefox()
- 如果浏览器能够正常打开,则说明环境安装没有问题


4、selenium + Chrome
-
实例代码 - 打开Chrome浏览器,并打开百度首页
# 导入selenium的webdriver接口 from selenium import webdriver # 1.创建浏览器对象 - 此时浏览器打开 browser = webdriver.Chrome() # 2.输入百度地址并确认 browser.get('http://www.baidu.com/') # 3.关闭浏览器 browser.quit() -
示例代码 - 打开被堵,输入关键字搜索,查看结果页
from selenium import webdriver # 1、创建浏览器对象 - 打开浏览器 driver = webdriver.Chrome() # 2、打开百度首页 driver.get('http://www.baidu.com/') # 3、找到搜索框节点,并发送搜索关键字 driver.find_element_by_xpath('//*[@id="kw"]').send_keys('清华大学') # 4、找到 百度一下 按钮,并点击 driver.find_element_by_xpath('//*[@id="su"]').click()find_element_by_xpath可以直接在网页中复制xpath获取

二、Selenium常用方法
详细用法:https://blog.csdn.net/weixin_36279318/article/details/79475388
1、浏览器对象
- 浏览器对象browser常用方法及属性
- browser.get():地址栏输入url地址并确认
- browser.quit():关闭浏览器
- browser.close():关闭当前页
- browser.gmaximize_window():浏览器窗口最大化
- browser.page_source:HTML结构源码。(即前端的源码)
- browser.page_source.find(‘字符串’):从源码中查找指定字符串,返回源码大概的位置。如果没有就返回-1,常用于判断最后一页
-
# 假设说网页非最后一页的“下一页”的源代码为class='pn-next' # 网页最后一页的“下一页”的源代码为class='pn-next disabled' browser.page_source.find('pn-next disabled') == -1 # 说明不是最后一页
-
2、定位节点
- 元素查找 - 返回值为节点对象或节点对象的列表
| 定位一个元素 | 定位多个元素 | 含义 |
|---|---|---|
| find_element_by_id() | find_elements_by_id() | 通过元素id定位 |
| find_element_by_name() | find_elements_by_name() | 通过元素name定位 |
| find_element_by_class_name() | find_elements_by_class_name() | 通过类名进行定位 |
| find_element_by_xpath() | find_elements_by_xpath() | 通过xpath表达式定位 |
| find_element_by_link_text() | find_elements_by_link_text() | 通过完整超链接定位 |
| find_element_by_partical_link_text() | find_elements_by_partical_link_text() | 通过部分链接定位 |
| find_element_by_tag_name() | find_elements_by_tag_name() | 通过标签定位 |
| find_element_by_css_selector() | find_elements_by_css_selector() | 通过css选择器进行定位 |
-
实例演示
<!--假设页面源代码如下:--> <html> <head> <body link="#0000cc"> <a id="result_logo" href="/" onmousedown="return c({'fm':'tab','tab':'logo'})"> <form id="form" class="fm" name="f" action="/s"> <span class="soutu-btn"></span> <input id="kw" class="s_ipt" name="wd" value="" maxlength="255" autocomplete="off">查找元素:
# 通过id定位 driver.find_element_by_id("kw") # 通过name定位 driver.find_element_by_name("wd") # 通过class name定位 driver.find_element_by_class_name("s_ipt") # 通过tag name定位 driver.find_element_by_tag_name("input") # 通过xpath定位,xpath定位有N种写法,这里列几个常用写法 driver.find_element_by_xpath("//*[@id='kw']") driver.find_element_by_xpath("//*[@name='wd']") driver.find_element_by_xpath("//input[@class='s_ipt']") driver.find_element_by_xpath("/html/body/form/span/input") driver.find_element_by_xpath("//span[@class='soutu-btn']/input") driver.find_element_by_xpath("//form[@id='form']/span/input") driver.find_element_by_xpath("//input[@id='kw' and @name='wd']") # 通过css定位,css定位有N种写法,这里列几个常用写法 driver.find_element_by_css_selector("#kw") driver.find_element_by_css_selector("[name=wd]") driver.find_element_by_css_selector(".s_ipt") driver.find_element_by_css_selector("html > body > form > span > input") driver.find_element_by_css_selector("span.soutu-btn> input#kw") driver.find_element_by_css_selector("form#form > span > input") -------------------------------------------------------------------------- # 假设页面上有一组文本链接: <a class="mnav" href="http://news.baidu.com" name="tj_trnews">新闻</a> <a class="mnav" href="http://www.hao123.com" name="tj_trhao123">hao123</a> -------------------------------------------------------------------------- # 通过link text定位 driver.find_element_by_link_text("新闻") driver.find_element_by_link_text("hao123") # 通过partial link text定位 driver.find_element_by_partial_link_text("新") driver.find_element_by_partial_link_text("hao") driver.find_element_by_partial_link_text("123")
3、节点对象方法
- 节点对象常用属性及方法
- node.send_keys():向文本框发送内容
- node.click():点击
- node.clear():清空文本
- node.get_attribute(‘属性名’):获取节点属性值
- node.text:获取节点文本内容(包含子节点和后代节点)
4、selenium+Chrome案例
-
思路
- 打开浏览器输入top100主页地址
- 使用selenium的xpath找到电影信息节点对象列表
- 依次遍历每个元素,并依次提取每个电影信息
- 可利用find_element_by_link_text()判断是否为最后1页
-
重要
- 当selenium在页面中找不到指定节点时会抛出异常
- 可用try except语句,当抛出异常时则为最后1页
-
爬取一页数据

-
爬取多页数据:

三、Selenium 高级操作
1、设置无界面模式
-
设置无界面模式(Chrome | Firefox)
不会打开网页,但是一样能获取到数据。


2、selenium执行JS脚本
- 浏览器对象执行JS脚本方法
- browser.execute_script()
- 最常用脚本
- 把滚动条拉到底部
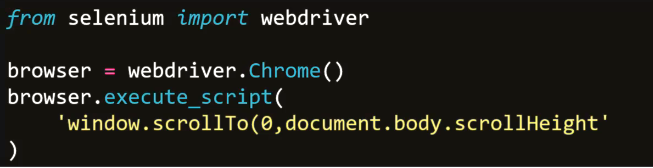
- 把滚动条拉到底部
3、练习
- 目标地址
- 由于各种原因不便写出地址,各位随便找个网页就可以
- 抓取目标
- 抓取爬虫书籍的所有商品信息
- 商品名称、商品价格、评价数量、商品商家
- 爬取思路
- 打开网站,到商品搜索页
- 匹配所有商品节点对象列表
- 把节点对象的文本内容取出来,查看规律,是否有更好的处理办法
- 提取完1页后,判断如果不是最后1页,则点击下一页
- 实现步骤
-
节点xpath
- 首页搜索框://*[@id=“key”]
- 首页搜索按钮://*[@id=“search”]/div/div[2]/button
- 商品信息节点对象列表://*[@id=“J_goodsList”]/ul/li
- 每个商品的具体信息xpath
- 名称:.//div[@class=“p-price”]/strong
- 价格:.//div[@class=“p-name p-name-type-2”]/a/em
- 评论:.//div[@class=“p-commit”]/strong
- 商家:.//div[@class=“p-shop”]/span


从爬取到的结果看,格式并不统一。
所以只能找他们的xpath进行获取数据

-
4、selenium键盘操作
Selenium中的Key模块为我们提供了模拟键盘按键的方法,那就是send_keys()方法。它不仅可以模拟键盘输入,也可以模拟键盘的操作。
常用的键盘操作如下:
| 模拟键盘按键 | 说明 |
|---|---|
| send_keys(Keys.BACK_SPACE) | 输入删除键(BackSpace) |
| send_keys(Keys.SPACE) | 输入空格键(Space) |
| send_keys(Keys.TAB) | 输入制表键(Tab) |
| send_keys(Keys.ESCAPE) | 输入回退键(Esc) |
| send_keys(Keys.ENTER) | 输入回车键(Enter) |
组合键的使用
| 模拟键盘按键 | 说明 |
|---|---|
| send_keys(Keys.CONTROL, ‘a’) | 全选(Ctrl+A) |
| send_keys(Keys.CONTROL, ‘c’) | 复制(Ctrl+C) |
| send_keys(Keys.CONTROL, ‘x’) | 剪切(Ctrl+X) |
| send_keys(Keys.CONTROL, ‘v’) | 粘贴(Ctrl+V) |
| send_keys(Keys.F1…Fn) | 键盘 F1…Fn |
5、selenium鼠标操作
在 WebDriver 中, 将这些关于鼠标操作的方法封装在 ActionChains 类提供。
| 方法 | 说明 |
|---|---|
| ActionChains(driver) | 构造ActionChains对象 |
| context_click() | 执行鼠标悬停操作 |
| move_to_element(above) | 右击 |
| double_click() | 双击 |
| drag_and_drop() | 拖动 |
| move_to_element(above) | 执行鼠标悬停操作 |
| context_click() | 用于模拟鼠标右键操作, 在调用时需要指定元素定位 |
| perform() | 执行所有 ActionChains 中存储的行为,可以理解成是对整个操作的提交动作 |
- 使用流程
- 导入鼠标事件类:
from selenium.webdriver import ActionChains - 实例化鼠标对象:
ActionChains(browser) - 指定鼠标行为:
move_to_element(node) - 执行鼠标行为:
perform()
- 导入鼠标事件类:
- 使用示例
ActionChains(browser).move_to_element(node).perform()
- 实例演示
from selenium import webdriver
#0.引入 ActionChains 类
from selenium.webdriver.common.action_chains import ActionChains
#1.创建Chrome浏览器对象,这会在电脑上在打开一个浏览器窗口
driver = webdriver.Firefox(executable_path ="F:\GeckoDriver\geckodriver")
driver.get("https://www.baidu.com")
#2.定位到要悬停的元素
element= driver.find_element_by_link_text("设置")
#3.对定位到的元素执行鼠标悬停操作
ActionChains(driver).move_to_element(element).perform()
#找到链接
elem1=driver.find_element_by_link_text("搜索设置")
elem1.click()
#通过元素选择器找到id=sh_2,并点击设置
elem2=driver.find_element_by_id("sh_1")
elem2.click()
#保存设置
elem3=driver.find_element_by_class_name("prefpanelgo")
elem3.click()
- 以百度为例,找到“高级搜索”并点击
- 查看https://www.baidu.com/的源代码,发现并没有“高级搜索”
- 当我们将鼠标移动到”设置“,此时在搜索源代码,发现有“高级搜索”


6、selenium切换句柄
-
使用网站类型
- 页面中点开链接出现新的窗口,但是浏览器对象browse还是之前页面的对象,需要切换到不同的窗口进行操作
-
应对方案(browser.switch_to.window())
- 先获取当前所有句柄(列表)
- 再切换到指定句柄(利用列表下标索引取值)
all_handles = browser.window_handlesbrowser.switch_to.window(all_handles[1])

【注意!!】以上图片仅供展示,请勿爬取。

【注意!!】以上图片仅供展示,请勿爬取。
【注意!!】以下代码仅供展示,请大家换个网站练习。

-- mysql 存储数据
create database mzbdb charset utf8;
use mzbdb;
create table mzbtab(
name varchar(30),
code varchar(20)
)charset=utf8;
【注意!!】以下代码仅供展示,请大家换个网站练习。

7、selenium frame
- 特点
- 网页中嵌套了网页,先切换到frame,然后再执行其他操作
- 处理步骤
- 切换到要处理的frame
- 在frame中定位页面元素并进行操作
- 返回当前处理的Frame的上一级页面或主页面
- 常用方法
- 切换到frame:browser.switch_to.frame(frame节点对象)
- 返回上一级:browser.switch_to.parent_frame()
- 返回主页面:browser.switch_to.default_content()
- 使用说明
- 默认支持id和name属性值查找:switch_to.frame(id|name)
- 先找到frame节点:frame_node = browser.find_element_by_
- 再切换到frame:browser.switch_to.frame(iframe_node)
–
-
以QQ邮箱为例:
从网页源码中可以看到,html中包含了html,此时用driver.find_element_by_xxx()查找元素,找的实际上是外层html中的元素。所以我们需切换到iframe中,才能找到里层的html元素。

-
豆瓣网登录
- 豆瓣也是一样的,下面用代码实现豆瓣的登录功能
-
selenium登录豆瓣网思路
- 打开豆瓣登录页
- 默认为手机号登录,找到密码登录节点并点击
- 找到用户名节点并输入真是用户名
- 找到密码节点并输入真实密码
- 找到登录豆瓣按钮并进行点击

-
selenium登录QQ邮箱
-
思路
- 打开登录页
- 切换frame
- 找到用户名、密码节点并发送QQ号和密码到文本框
- 找到登录按钮并点击

9、控制浏览器操作的一些方法
| 方法 | 说明 |
|---|---|
| webdriver.set_window_size() | 设置浏览器的大小 |
| webdriver.back() | 控制浏览器后退 |
| webdriver.forward() | 控制浏览器前进 |
| webdriver.refresh() | 刷新当前页面 |
| webdriver.clear() | 清除文本 |
| webdriver.send_keys(value) | 模拟按键输入 |
| webdriver.click() | 单击元素 |
| webdriver.submit() | 用于提交表单 |
| webdriver.get_attribute(name) | 获取元素属性值 |
| webdriver.is_displayed() | 设置该元素是否用户可见 |
| webdriver.size | 返回元素的尺寸 |
| webdriver.text | 获取元素的文本 |
- 实例演示
from selenium import webdriver
from time import sleep
#1.创建Chrome浏览器对象,这会在电脑上在打开一个浏览器窗口
browser = webdriver.Firefox(executable_path ="F:\GeckoDriver\geckodriver")
#2.通过浏览器向服务器发送URL请求
browser.get("https://www.baidu.com/")
sleep(3)
#3.刷新浏览器
browser.refresh()
#4.设置浏览器的大小
browser.set_window_size(1400,800)
#5.设置链接内容
element=browser.find_element_by_link_text("新闻")
element.click()
element=browser.find_element_by_link_text("“下团组”时间")
element.click()
-
获取断言信息
不管是在做功能测试还是自动化测试,最后一步需要拿实际结果与预期进行比较。这个比较的称之为断言。通过我们获取title 、URL和text等信息进行断言。
| 属性 | 说明 |
|---|---|
| title | 用于获得当前页面的标题 |
| current_url | 用户获得当前页面的URL |
| text | 获取搜索条目的文本信息 |
-
实例演示
from selenium import webdriver from time import sleep driver = webdriver.Firefox(executable_path ="F:\GeckoDriver\geckodriver") driver.get("https://www.baidu.com") print('Before search================') # 打印当前页面title title = driver.title print(title) # 百度一下,你就知道 # 打印当前页面URL now_url = driver.current_url print(now_url) # https://www.baidu.com/ driver.find_element_by_id("kw").send_keys("selenium") driver.find_element_by_id("su").click() sleep(1) print('After search================') # 再次打印当前页面title title = driver.title print(title) # selenium_百度搜索 # 打印当前页面URL now_url = driver.current_url print(now_url) # https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=0&rsv_idx=1&tn=baidu&wd=selenium&rsv_pq=a1d51b980000e36e&rsv_t=a715IZaMpLd1w92I4LNUi7gKuOdlAz5McsHe%2FSLQeBZD44OUIPnjY%2B7pODM&rqlang=cn&rsv_enter=0&rsv_sug3=8&inputT=758&rsv_sug4=759 # 获取结果数目 user = driver.find_element_by_class_name('nums').text print(user) # 百度为您找到相关结果约7,170,000个 #关闭所有窗口 driver.quit()