文章目录
- 前言
- Raft中的角色
- 算法过程
- 1.选举阶段
- 2.log replication阶段
- 如果leader挂了怎么办?
- 如何处理平票情况?
- 如果网络阻塞, 那么会出现两个leader,如果网络正常了会发生什么?
前言
Raft 是一种 分布式共识算法,目前被consul和etcd使用。
Raft中的角色
- Follower:追随者
- Candidate:竞选者
- Leader:领导者
算法过程
我们以一个简单的集群为例说明,这个集群有三个结点,现在我们需要这三个结点共识一份数据。
1.选举阶段
- 初始状态下,集群中的结点都是
follwer state,即都是follower - 当follower在一定的时间范围内(介于150ms~300ms之间,可配置),没有听到leader发送的消息时,会认为leader已经不在了,那么该节点会变成一个
candidate竞选者。
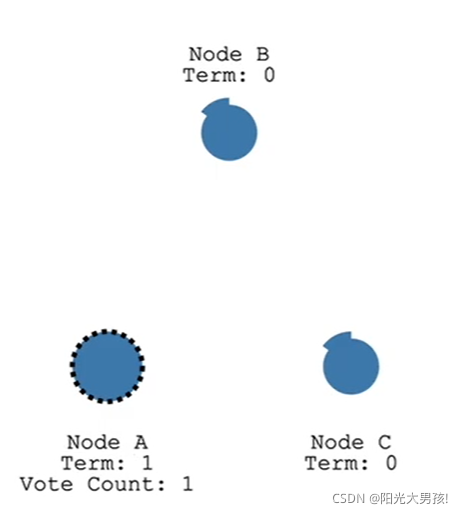
term是任期的概念,follwer变身candidate后任期会++,而其他的follower接收到索要投票要求时,term++,且在该任期内它的票只能投给一个candidate - 变身candidate之后,该竞选者可以向其他结点索要投票以期待变成leader,并且自己会投自己一票,当该candidate拿到超过半数结点的票时,就会正式成为
leader,其他follower也会记录自己的leader是谁 - 成为leader之后,会广播给其他follower一个请求
AppendEntries,这个请求是有可能带数据的,如果不带数据代表是心跳,如果携带数据,代表是做一些事情,做什么呢? 看下文~
2.log replication阶段
如果说客户端要给集群set一个数据5,那么会有以下共识过程:
- 客户端修改数据都是需要交由leader来处理,如果交给了follwer,那么follwer也会把set 5交由
leader处理 - leader处理set 5时,会暂存到本地,并不立马修改,而是设置为uncommit状态,并通知其他follower进行同步备份,这是一个广播的过程,follower接收到leader的消息之后会返回投票,如果leader收到半数以上投票,那么会把数据进行修改,也就不再是commit状态。
- 此时follower们对该数据还是uncommit状态,那么
leader再次广播,让follower都提交数据set 5,且在广播的同时向客户端返回请求,代表这条修改是被审核认可的。
log replication阶段同步多份日志,就是为了应对leader挂掉的情况,那么其他的结点还能产生新的共识数据。
如果leader挂了怎么办?
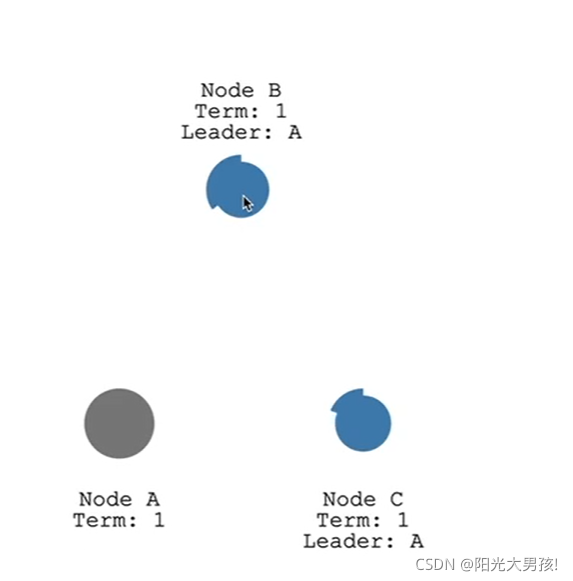
leader如果挂了,那么就会按照前面的算法过程去处理,即检测不到心跳请求,follower成为candidate,之后进行选举,成为新的leader
如何处理平票情况?
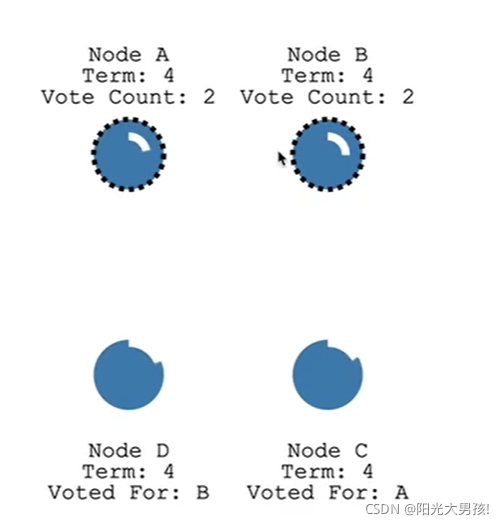
平票状态下,两个candidate都拿不到半票,都成不了leader,那么另外一个follower会变成一个新的candidate,进行新的投票,直到产生唯一leader,而产生唯一leader的关键在于timeout是随机的,每个node的timeout是random的。
如果网络阻塞, 那么会出现两个leader,如果网络正常了会发生什么?
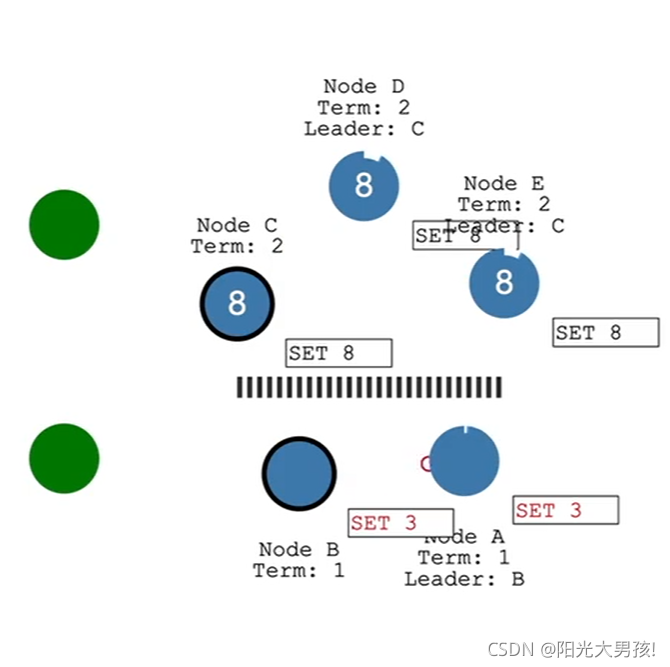
会根据term的值(越大代表任期越新),以此决定哪个leader是应该留下来的,而另一个leader则会被“卸任”,变成一个follower,例如上图中,B是卸任的,而且B会与C进行同步,进行一个rollback的操作。