进来了就点个赞呗
本次实战项目一共分三篇教学(二三篇后续更新)
第一篇:对主播文本数据的清洗,从大量数据中获取我们所需要的数据(如播放量,时长等)
第二篇:对清洗后的数据进行统计求和处理操作,对id进行升序排序打印结果
第三篇:对统计好的数据进行TopN展示的操作,排序规则可自定义(如播放量,分数数量),N的大小也可以自定义
目录
一、流程介绍
二、创建Maven工程项目
(1)创建Maven
(2)添加依赖
三、编写MapReduce程序
(1)Map类
(2)主类(入口类)
四、编译打包成Jar包上传
五、原始数据上传到HDFS文件系统
五、执行Jar包程序
Gitee仓库Hadoop项目下载地址
前言大数据时代越来越多的数据,我们怎么才能从大量数据中提取有价值的数据呢,同时这么多的数据我们该如何编写有效快速的程序进行获取
一、流程介绍原始数据集如下
第一章的教学只涉及到数据的清洗和获取,所以只有Map,没有Reduce(统计的时候才需要),大致过程如图
二、创建Maven工程项目
(1)创建Maven打开IDAD,新建一个项目,选择Maven,点击下一步
添加项目名称,点击完成
创建之后,右下角会弹出提示,选择Auto自动导入依赖
(2)添加依赖
编辑pom.xml配置文件,添加如下内容,等待自动导入完成
<dependencies> <!-- Hadoop相关依赖包--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.3.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>3.3.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.3.1</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> </dependencies> <build> <plugins> <!-- 打包编译的插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>6</source> <target>6</target> </configuration> </plugin> </plugins> </build>
一个基本的Hadoop的Maven工程项目就创建完毕了
三、编写MapReduce程序(1)Map类
map类的作用是对原始数据的清洗操作,解析JSON格式的数据,获取我们所需要的数据
在java目录下新建一个DataCleanMap类,继承Mapper类,复写map方法
public class DataCleanMap extends Mapper<LongWritable, Text, Text, Text> { @Override protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException { } }在map方法里,解析JSON数据,读取数据
String line = v1.toString();//获取每一行内容 JSONObject jsonObj = new JSONObject(line); //将字符串转换为JSON格式 String id = jsonObj.getString("uid"); //获取主播的id数据 /** * 获取主播的其他数据 * gold-------->>金币 * watchnumpv-->>播放量 * follower---->>粉丝 * length------>>开播时长 */ int gold = jsonObj.getInt("gold"); int watchnumpv = jsonObj.getInt("watchnumpv"); int follower = jsonObj.getInt("follower"); int length = jsonObj.getInt("length");过滤掉异常的数据(如<0的数据等),最后封装到上下文中
if (gold >= 0 && watchnumpv >= 0 && follower >= 0 && length >= 0) { // 封装数据到Text中,最后写入context上下文中 Text k2 = new Text(); k2.set(id); Text v2 = new Text(); v2.set(gold + "\t" + watchnumpv + "\t" + follower + "\t" + length); context.write(k2, v2); }(2)主类(入口类)
相当于一个程序的主函数,最先开始执行的地方
在java目录下新建一个DataCleanJob类,在主函数设置Job作业的参数信息
// 运行程序指令输入错误,直接退出程序 if (args.length != 2) { System.exit(100); } Configuration conf = new Configuration(); //job需要的配置参数 Job job = Job.getInstance(conf); //创建一个job job.setJarByClass(DataCleanJob.class); //指定输入路径(可以是文件,也可以是目录) FileInputFormat.setInputPaths(job, new Path(args[0])); //指定输出路径(只能是指定一个不存在的目录) FileOutputFormat.setOutputPath(job, new Path(args[1])); //指定map相关代码 job.setMapperClass(DataCleanMap.class); //指定K2的类型 job.setMapOutputKeyClass(Text.class); //指定v2的类型 job.setMapOutputValueClass(Text.class); //设置reduce的数量,0表示禁用reduce job.setNumReduceTasks(0); //提交作业job job.waitForCompletion(true);四、编译打包成Jar包上传
展开右侧的Mavan,双击clean清理一下,再双击package生成jar包
这时在项目目录会多了一个target的文件夹,下面就有一个jar包程序,右键复制,粘贴到桌面
打开winscp工具,连接自己的虚拟机,将jar包拷贝到虚拟机里(前提要打开虚拟机)
五、原始数据上传到HDFS文件系统
准备数据集,数据集我已经放在底部gitee仓库里了
同样的,将数据集拷贝到虚拟机里
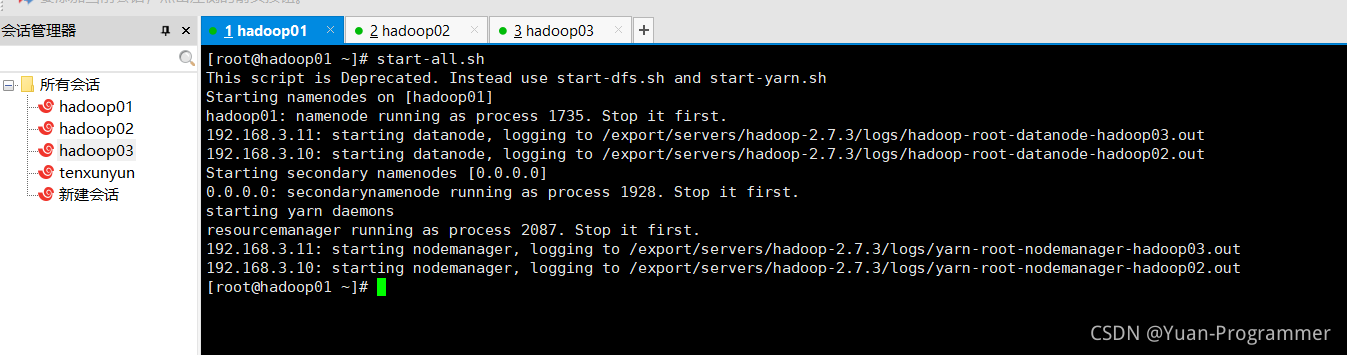
打开主节点虚拟机,start-all一键启动hadoop集群服务
跳转到刚刚拷贝的目录下,查看文件
先在HDFS文件系统创建一个文件夹,用来存放数据,在虚拟机输入指令
[root@hadoop01 data]# hadoop fs -mkdir -p /zhubo/data/接着输入指令将数据拷贝到HDFS的zhubo文件下的data文件夹下(路径可以自己选,前提要和上一步一样创建文件夹)
[root@hadoop01 data]# hadoop fs -put video_rating.log /zhubo/data/刷新浏览器,成功拷贝上来了
五、执行Jar包程序
在虚拟机中输入运行指令
zhuboClean.jar jar包名称 DataCleanJob 主类(入口类)类名 /zhubo/data/ 输入路径(数据所在目录) /zhubo/resultClean/ 输出路径(必须不存在的文件夹) 运行结束后,刷新浏览器,在输出路径可以看到一个结果文件,点击下载hadoop jar zhuboClean.jar DataCleanJob /zhubo/data/ /zhubo/resultClean/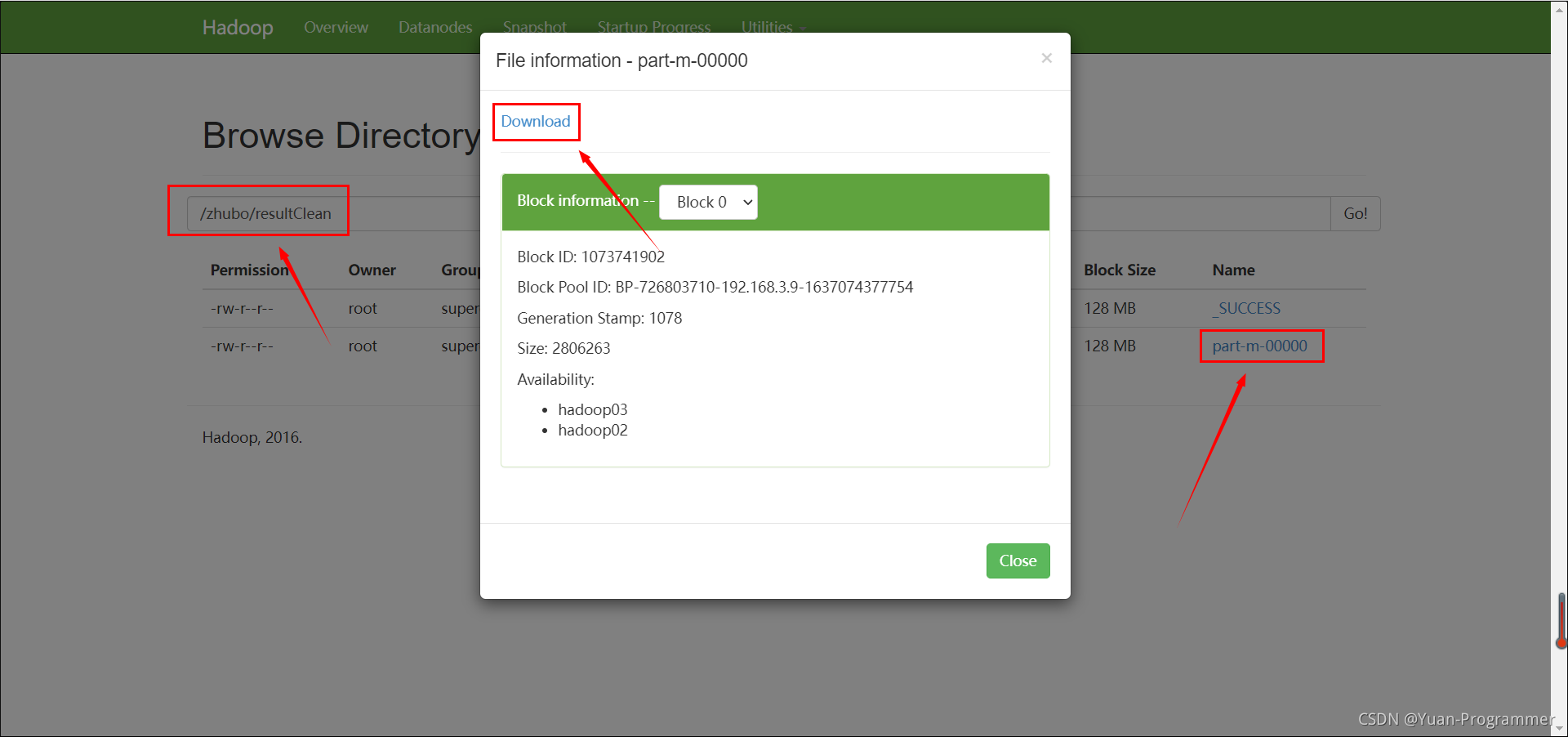
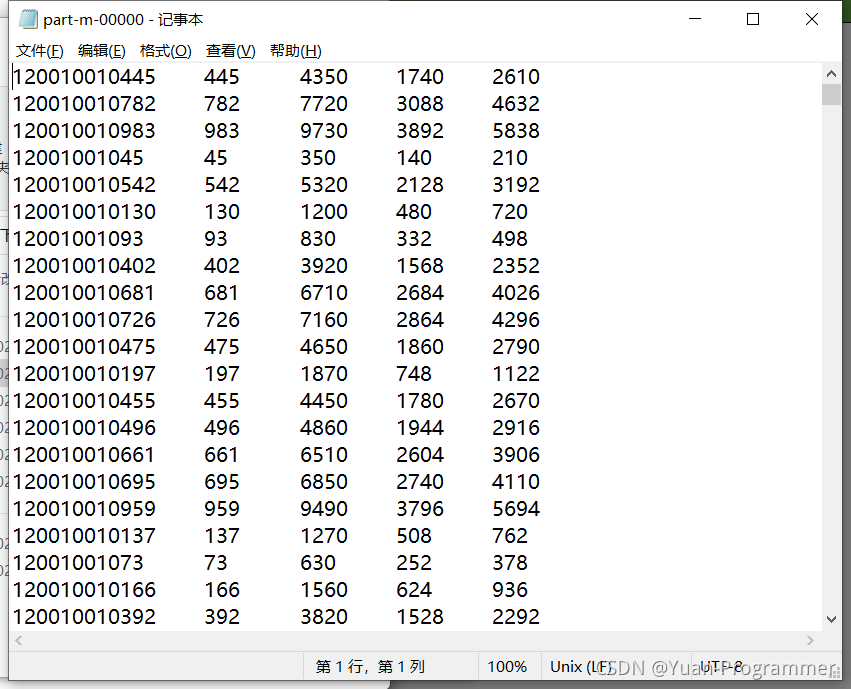
以记事本打开,统计成功













Gitee仓库Hadoop项目下载地址
Gitee仓库地址:Hadoop实战项目源码集合: https://blog.csdn.net/weixin_47971206CSDN文章教学中的源码汇总集合
其他系列技术教学、实战开发
各大技术基础教学、实战开发教学(最新更新时间2021-11-23)