我们将从零开始实现整个方法,包括流水线、模型、损失函数和小批量随机梯度下降优化器。
import os
import matplotlib.pyplot as plt
#其中matplotlib包可用于作图,且设置成嵌入式
import torch
from IPython import display
from matplotlib import pyplot as plt
import numpy as np
import random
我们构造⼀个简单的⼈⼯训练数据集,给定随机⽣成的批量样本特征
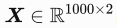 ,我们使⽤线性回归模型真实权重
,我们使⽤线性回归模型真实权重
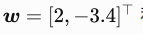 和偏差b=4.2,以及⼀个随机噪声 项€ 来⽣成标签:
和偏差b=4.2,以及⼀个随机噪声 项€ 来⽣成标签:
![]()
1、生成数据集
"""
根据带有噪声的线性模型构造一个人造数据集
"""
num_inputs=2 #输入个数(特征数)为2
num_examples=1000 #训练数据集样本数为1000
true_w=[2,-3.4] #线性回归模型的真实权重
true_b=4.2 #线性回归模型的真实偏差
features=torch.from_numpy(np.random.normal(0,1,(num_examples,num_inputs)))
# 均值为0,方差为1的随机数 ,有num_examples个样本,列数为num_inputs
labels=true_w[0]*features[:,0]+true_w[1]*features[:,1]+true_b
# lables就等于w的每列乘以features的每列然后相加,最后加上偏差true_b;
labels+=torch.from_numpy(np.random.normal(0,0.01,size=labels.size()))
# 加入了一个噪音,均值为0,方差为0.01,形状和lables的长度是一样的
"""
features 的每⼀⾏是⼀个⻓度为2的向量,⽽ labels 的每⼀⾏是⼀个⻓度为1的向量(标
量)
"""
print(features[0],labels[0])
#最后输出列向量(特征和标注) 
通过⽣成第⼆个特征 features[:, 1] 和标签 labels 的散点图,来观察两者间的线性关 系
def use_svg_display():
# 用矢量图表示
display.set_matplotlib_formats('svg')
def set_figsize(figsize=(3.5,2.5)):
use_svg_display()
#设置图的尺寸
plt.rcParams['figure.figsize']=figsize
set_figsize()
plt.scatter(features[:,1].numpy(),labels.numpy(),1);
plt.show()
也可以把上述的作图函数保存在d21zh_pytorch包中,步骤如下:
第一步:新建一个d21zh_pytorch包;
第二步:在包中新建一个methods.py 文件;
第三步:把plt 作 图 函 数 以 及 use_svg_display 函 数 和 set_figsize 函 数 定 义 在d2lzh_pytorch 中的methods.py文件中,如图:

然后可以直接调用保存好的函数,来显示散点图:
"""
如果在d21zh_pytorch里面添加上面两个函数后,就可以使用下面的方法调用即可
"""
import sys
sys.path.append("..")
from d21zh_pytorch import *
set_figsize()
plt.scatter(features[:,1].numpy(),labels.numpy(),1);
plt.show()
2、 读取数据
在训练数据时,我们需要遍历数据集并不断读取小批量数据样本。在这里我们定义一个函数:他每次返回batch_size(批量大小)个随机样本的特征和标签。
#定义一个data_iter函数,该函数接受批量大小、特征矩阵和标签向量作为输入,生成大小为batch_size的小批量
def data_iter(batch_size,features,labels):
num_examples=len(features)
indices=list (range(num_examples))
random.shuffle(indices) #样本的读取顺序是随机的
for i in range(0,num_examples,batch_size):
#从0开始到num_examples结束,每次跳batch_size个大小。
j=torch.LongTensor(indices[i:min(i+batch_size,num_examples)])
#最后一次可能不足一个batch,所以最后一个批量取一个最小值min
yield features.index_select(0,j),labels.index_select(0,j)
#读取第一个小批量数据样本并打印
batch_size=10
for X,y in data_iter(batch_size,features,labels):
print(X,'\n',y) #生成X是10乘2的向量,y是10乘1的向量
#加个‘\n’ 可以让y换行表示
break

3、 定义初始化模型参数
"""
我们将权重初始化成均值为0,标准差为0.01的正态随机数,偏差初始化成0
"""
tensor = tensor.to(torch.float32)
w=torch.tensor(np.random.normal(0,0.01,(num_inputs,1)),dtype=torch.double)
b=torch.zeros(1,dtype=torch.double)
#之后的模型训练中,需要对这些参数求梯度来迭代参数的值,因此我们要让它们的requires_grad=True
w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)注:w=torch.tensor(np.random.normal(0,0.01,(num_inputs,1)),dtype=torch.double) b=torch.zeros(1,dtype=torch.double)
这里数据类型要用double,而不能用float32,否则会报错。
4、定义模型
#下面是线性回归的矢量计算表达式的实现,我们使用mm函数做矩阵乘法
def linreg(X,w,b):#线性回归模型
return torch.mm(X,w)+b
#返回预测(输入X乘以w,矩阵乘以向量,加上偏差)5、定义损失函数
"""
描述的平方损失来定义线性回归的损失函数,在现实中,我们需要把真实值y变成预测值y_hat的形状。以下函数返回的结果也将和y_hat的形状相同
"""
def squared_loss(y_hat,y):
#squared_loss均方损失
return (y_hat - y.view(y_hat.size()))**2/2#按元素做减法,按元素做平方,最后除以2
# 注意这⾥返回的是向量, 另外, pytorch⾥的MSELoss并没有除以26、定义优化算法
# 以下的 sgd 函数实现了上⼀节中介绍的⼩批量随机梯度下降算法。它通过不断迭代模型参数来优化损失函数。这⾥⾃动求梯度模块计算得来的梯度是⼀个批量样本的梯度和。我们将它除以批量⼤⼩来得到平均值。
def sgd(params, lr, batch_size): #给定所有的参数param(包含了w和b),学习率,批量大小
#小批量随机梯度下降
for param in params: #对参数params中的每一个参数param(w或者b)
param.data -= lr * param.grad / batch_size # 梯度存在.grad中
## 注意这⾥更改param时⽤的param.data7、训练模型
lr = 0.03 #学习率设置为0.03
num_epochs = 3 #迭代周期个数为3,整个数据扫三遍
net = linreg #线性回归模型
loss = squared_loss #均方损失
#训练的实现就是两层for epoch
for epoch in range(num_epochs): # 训练模型⼀共需要num_epochs个迭代周期
# 在每⼀个迭代周期中,会使⽤训练数据集中所有样本⼀次(假设样本数能够被批量⼤⼩整除)
# X和y分别是⼩批量样本的特征和标签
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y).sum()
# l是有关⼩批量X和y的损失
l.backward() # ⼩批量的损失对模型参数求梯度
sgd([w, b], lr, batch_size) # 使⽤⼩批量随机梯度下降迭代模型参数
# 不要忘了梯度清零
w.grad.data.zero_()
b.grad.data.zero_()
train_l = loss(net(features, w, b), labels)
print('epoch %d, loss %f' % (epoch + 1, train_l.mean().item()))

输出很多条数据从epoch1到epoch3。
#比较真实参数和通过训练学到的参数来评估训练的成功程度
print(true_w, '\n', w)
print(true_b, '\n', b) 