目录
1.树的定义和基本性质
二叉树概念及结构(重点)
二叉树的性质:
二叉树的存储结构
二叉树的遍历
遍历常考考点:
二叉树节点的个数:
二叉树叶子节点的个数:
求二叉树第k层有多少个节点(k>1):
二叉树中查找值为x的节点:
二叉树的销毁
判断一颗二叉树是否为完全二叉树:
非递归实现二叉树的(前中后序遍历重点)
1.树的定义和基本性质
树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。有一个特殊的结点,称为根结点,根节点没有前驱结点除根节点外,其余结点被分成M(M>0)个互不相交的集合T1、T2、……、Tm,其中每一个集合Ti(1<= i <= m)又是一棵结构与树类似的子树。每棵子树的根结点有且只有一个前驱,可以有0个或多个后继因此,树是递归定义的。
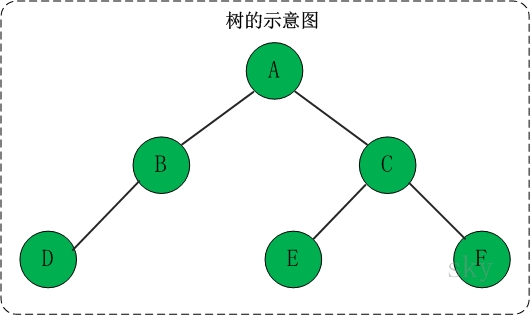
它之所以叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
(1) 每个节点有零个或多个子节点;
(2) 没有父节点的节点称为根节点;
(3) 每一个非根节点有且只有一个父节点;
(4) 除了根节点外,每个子节点可以分为多个不相交的子树。(5)一颗N个节点的树有N-1条边
2.树的相关概念:

在这里解释一下什么是节点的度:
2.1节点的度:
结点拥有的子树数目称为结点的度
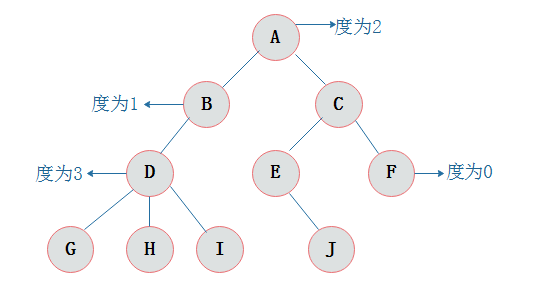
2.2节点的关系:
结点子树的根结点为该结点的孩子结点。相应该结点称为孩子结点的双亲结点。
图2.2中,A为B的双亲结点,B为A的孩子结点。
同一个双亲结点的孩子结点之间互称兄弟结点。
图2.2中,结点B与结点C互为兄弟结点。
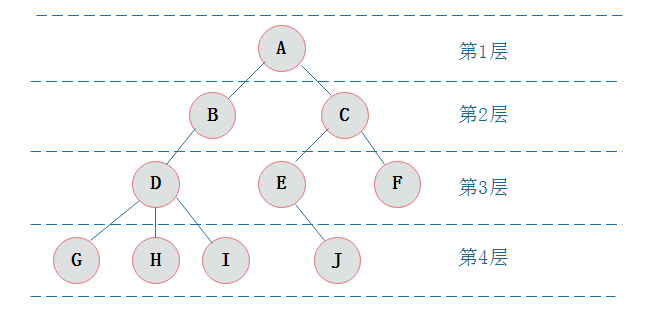
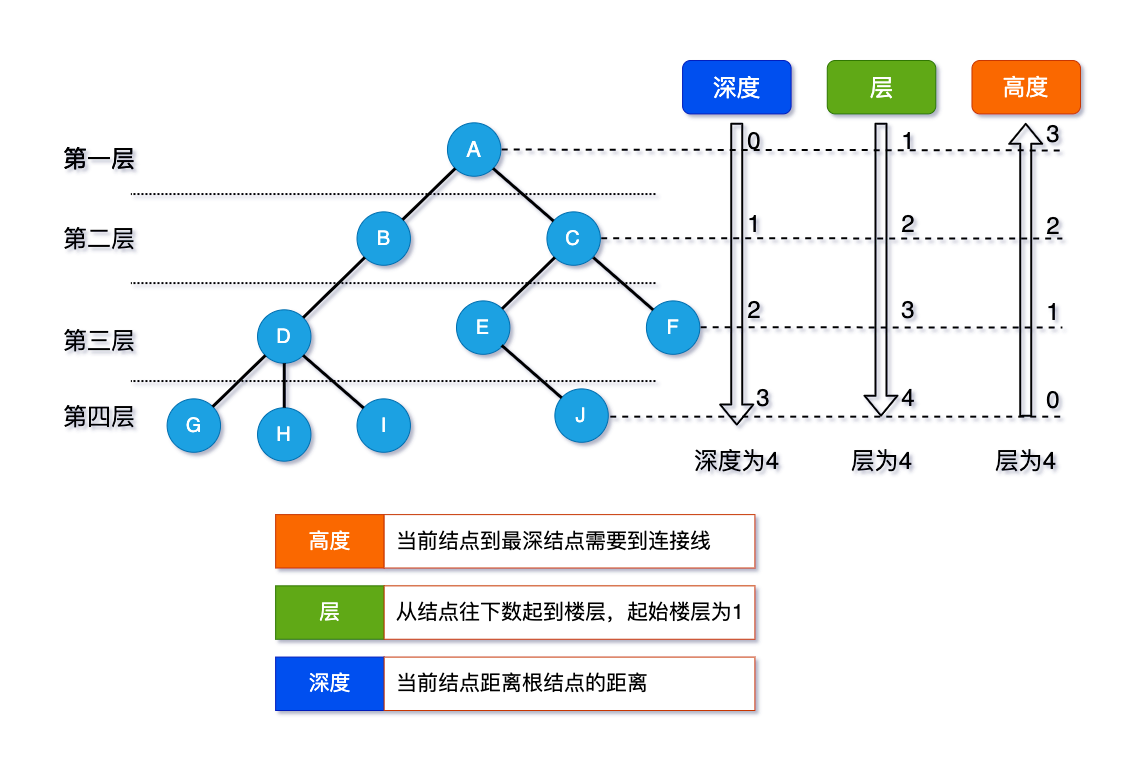
2.3:节点层次:
从根开始定义起,根为第一层,根的孩子为第二层,以此类推
3.树的表示:
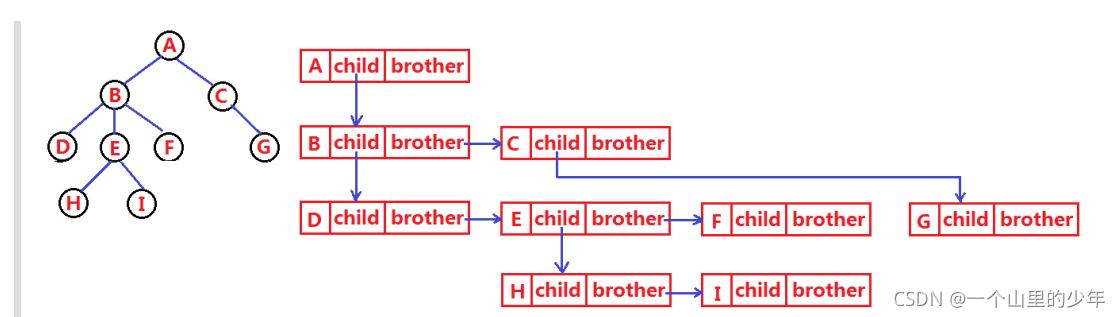
树结构相对线性表就比较复杂了,要存储表示起来就比较麻烦了,既然保存值域,也要保存结点和结点之间的关系,实际中树有很多种表示方式如:双亲表示法,孩子表示法、孩子双亲表示法以及孩子兄弟表示法等。我们这里就简单的了解其中最常用的孩子兄弟表示法。
typedef int DataType;
struct Node{
struct Node* _firstChild1;
// 第一个孩子结点
struct Node* _pNextBrother; // 指向其下一个兄弟结点
DataType _data;
// 结点中的数据域
};
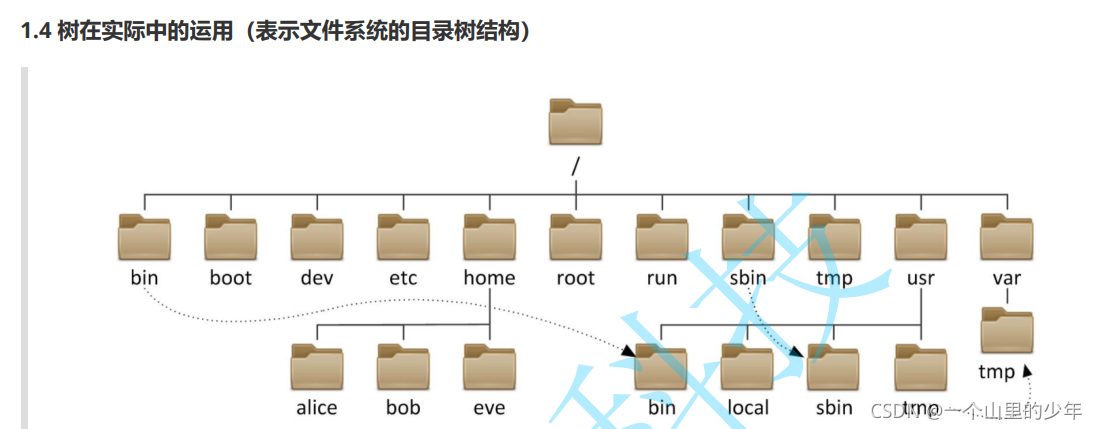
树在实际中的应用:
二叉树概念及结构(重点)
二叉树是n(n>=0)个节点的有限集合,该集合或者为空集(称为空二叉树),或者由一个根节点和两棵互不相交的、分别称为根节点的左子树和右子树组
从图上不难看出:
由二叉树定义以及图示分析得出二叉树有以下特点:
1)每个结点最多有两颗子树,所以二叉树中不存在度大于2的结点。
2)左子树和右子树是有顺序的,次序不能任意颠倒。
3)即使树中某结点只有一棵子树,也要区分它是左子树还是右子树
二叉树的性质:
1)在二叉树的第i层上最多有2i-1 个节点 。(i>=1)
2)二叉树中如果深度为k,那么最多有2k-1个节点。(k>=1)
3)n0=n2+1 n0表示度数为0的节点数,n2表示度数为2的节点数。
4)在完全二叉树中,具有n个节点的完全二叉树的深度为[log2n]+1,其中[log2n]是向下取整。
5)若对含 n 个结点的完全二叉树从上到下且从左至右进行 1 至 n 的编号,则对完全二叉树中任意一个编号为 i 的结点有如下特性:(1) 若 i=1,则该结点是二叉树的根,无双亲, 否则,编号为 [i/2] 的结点为其双亲结点;
(2) 若 2i>n,则该结点无左孩子, 否则,编号为 2i 的结点为其左孩子结点;
(3) 若 2i+1>n,则该结点无右孩子结点, 否则,编号为2i+1 的结点为其右孩子结点。
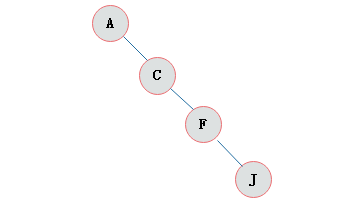
3.斜树
所有的结点都只有左子树的二叉树叫左斜树。所有结点都是只有右子树的二叉树叫右斜树。这两者统称为斜树。
左斜树
右斜树
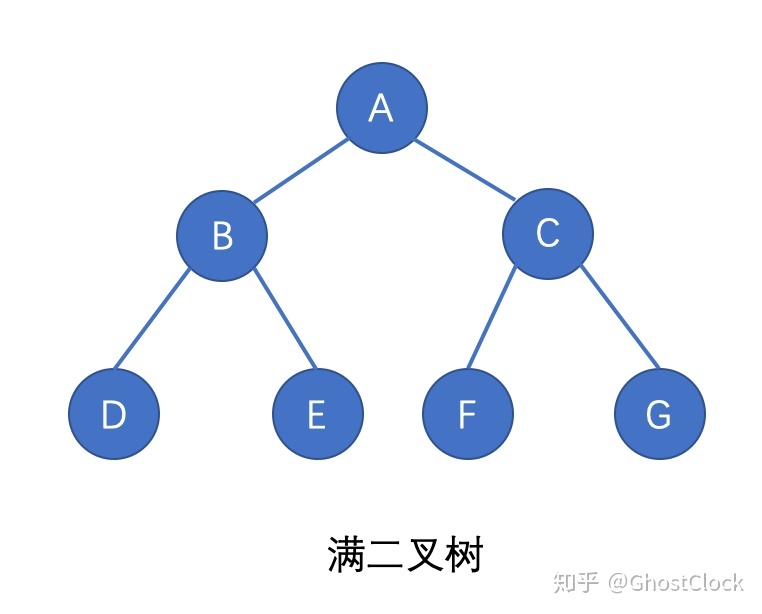
4满二叉树:
在一棵二叉树中。如果所有分支结点都存在左子树和右子树,并且所有叶子都在同一层上,这样的二叉树称为满二叉树。
满二叉树的特点有:
1)叶子只能出现在最下一层。出现在其它层就不可能达成平衡。
2)非叶子结点的度一定是2。
3)在同样深度的二叉树中,满二叉树的结点个数最多,叶子数最多
5.完全二叉树
1.对一颗具有n个结点的二叉树按层编号,如果编号为i(1<=i<=n)的结点与同样深度的满二叉树中编号为i的结点在二叉树中位置完全相同,则这棵二叉树称为完全二叉树。
2. 完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。 要注意的是满二叉树是一种特殊的完全二叉树。
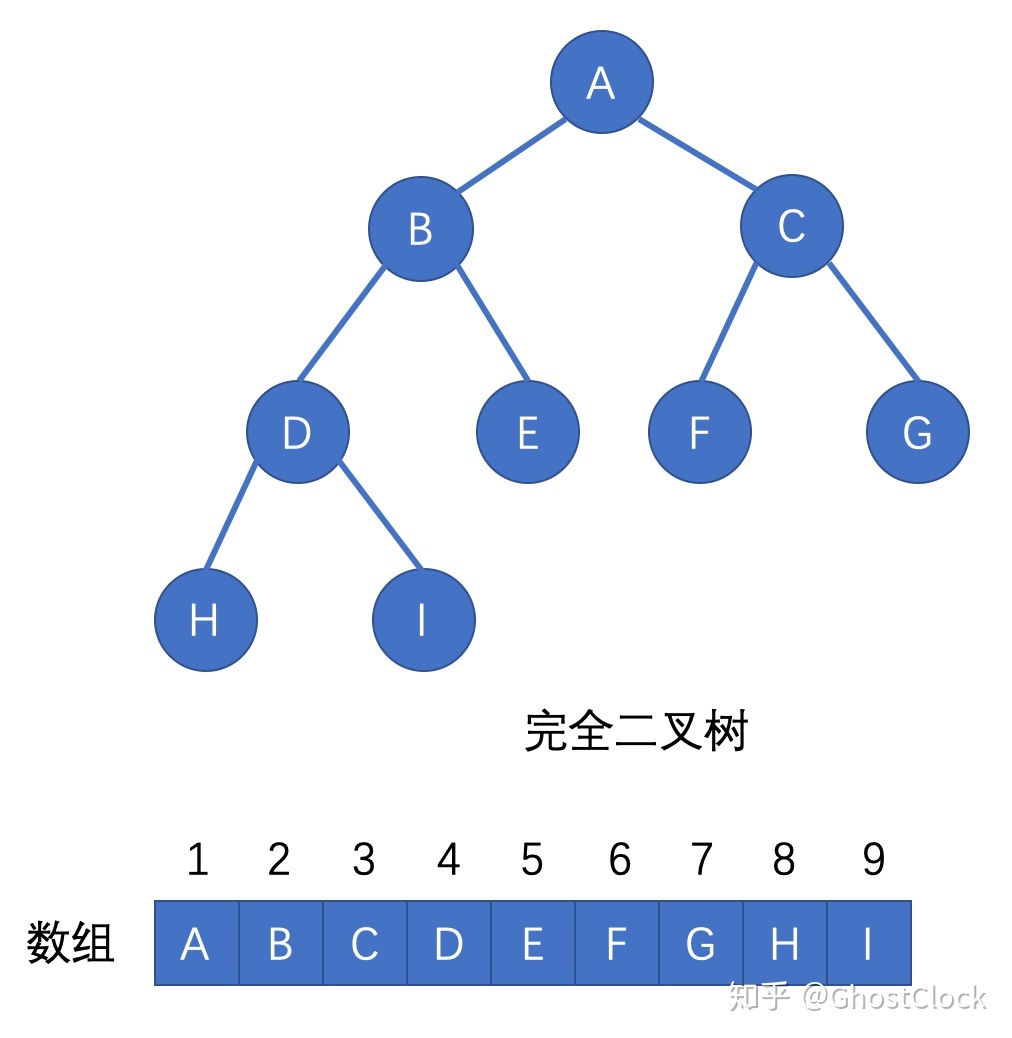
完全二叉树的特点:
1)叶子结点只能出现在最下层和次下层。
2)最下层的叶子结点集中在树的左部。
3)倒数第二层若存在叶子结点,一定在右部连续位置。
4)如果结点度为1,则该结点只有左孩子,即没有右子树。
5)同样结点数目的二叉树,完全二叉树深度最小
6.二叉搜索树:
6.1
二叉搜索树又称二叉查找树,亦称为二叉排序树。设x为二叉查找树中的一个节点,x节点包含关键字key,节点x的key值记为key[x]。如果y是x的左子树中的一个节点,则key[y] <= key[x];如果y是x的右子树的一个节点,则key[y] >= key[x]。
6.2性质:
(1)若左子树不空,则左子树上所有节点的值均小于它的根节点的值;
(2)若右子树不空,则右子树上所有节点的值均大于它的根节点的值;
(3)左、右子树也分别为二叉搜索树;

(具体内容后面会写专门的博客介绍)
平衡二叉树:
简称平衡二叉树。由前苏联的数学家 Adelse-Velskil 和 Landis 在 1962 年提出的高度平衡的二叉树,根据科学家的英文名也称为 AVL 树。它具有如下几个性质:
- 可以是空树。
- 假如不是空树,任何一个结点的左子树与右子树都是平衡二叉树,并且高度之差的绝对值不超过 1。
平衡之意,如天平,即两边的分量大约相同。
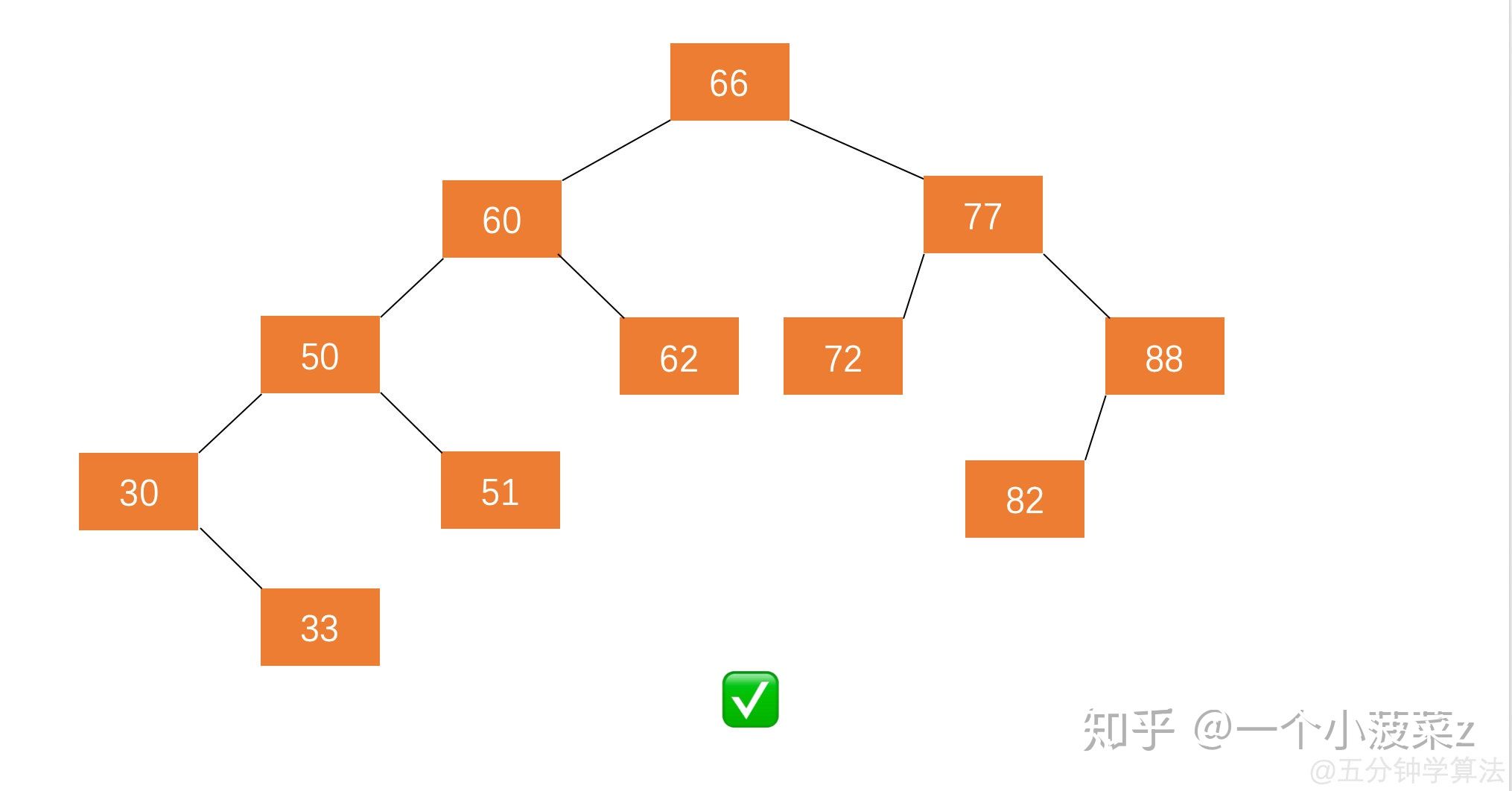
二叉树的存储结构
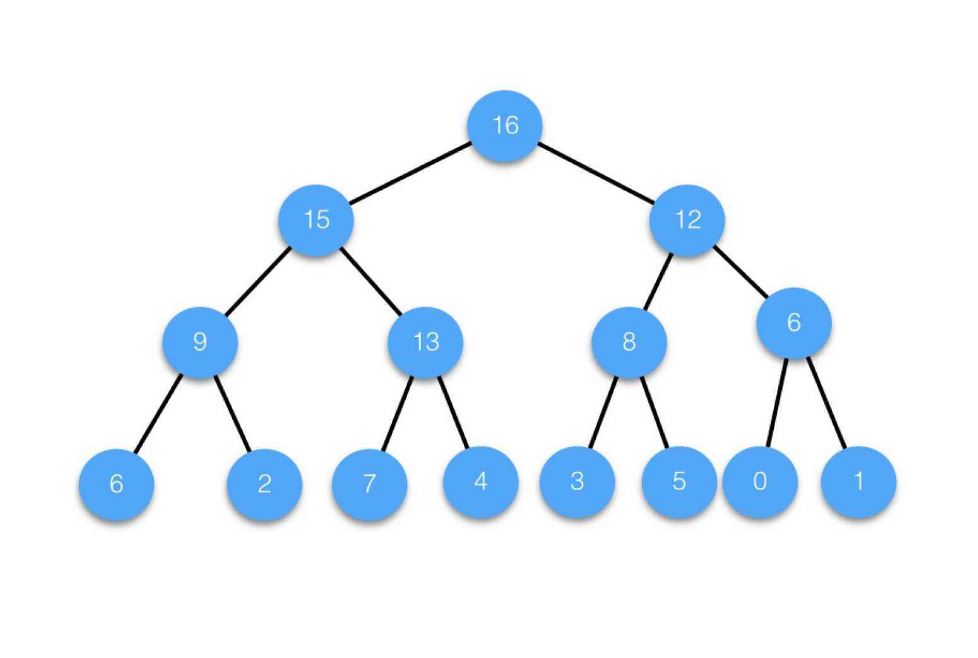
二叉树一般可以使用两种结构存储,一种顺序结构,一种链式结构。1. 顺序存储顺序结构存储就是使用数组来存储,一般使用数组只适合表示完全二叉树,因为不是完全二叉树会有空间的浪费。而现实中使用中只有堆才会使用数组来存储,关于堆我们后面的章节会专门讲解。二叉树顺序存储在物理上是一个数组,在逻辑上是一颗二叉树。
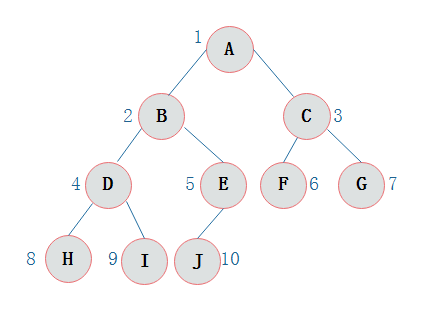
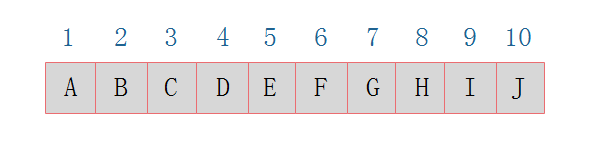
从图中我们可以看出
当二叉树为完全二叉树时,结点数刚好填满数组。
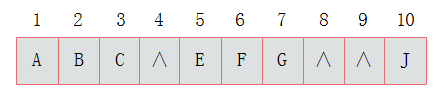
那么当二叉树不为完全二叉树时,采用顺序存储形式如何呢?

那么对应顺序存储形式将会是这样的:
二叉树的链式存储:
叉树的链式存储结构是指,用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。 通常的方法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址

定义节点的代码:
typedef int BTDataType
struct BinaryTreeNode{
struct BinTreeNode* _pLeft; // 指向当前节点左孩子
struct BinTreeNode* _pRight; // 指向当前节点右孩子
BTDataType _data; // 当前节点值域
};
那么上面的那个图就可以表示成这样
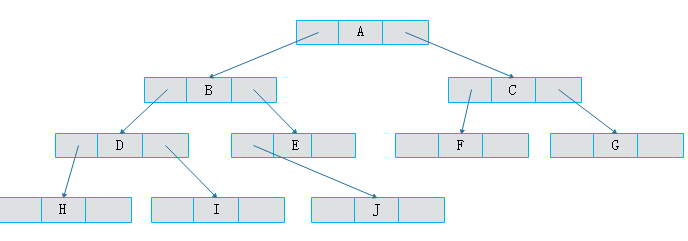
二叉树的遍历
二叉树遍历是指从二叉树的根结点出发,按照某种次序依次访问二叉树中的所有结点,使得每个结点被访问一次,且仅被访问一次。
二叉树的访问次序可以分为四种:
前序遍历
中序遍历
后序遍历
层序遍历
1.前序遍历
前序遍历通俗的说就是从二叉树的根结点出发,当第一次到达结点时就输出结点数据,按照先访问左子树在访问右子树的顺序
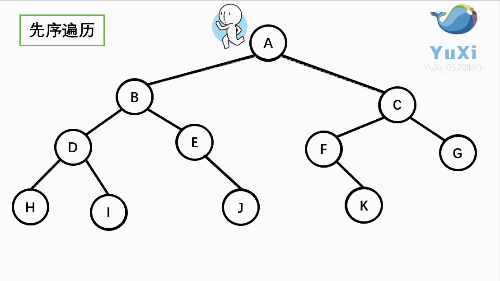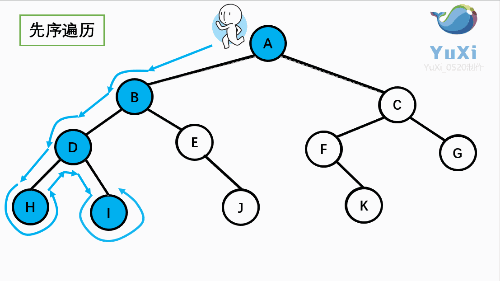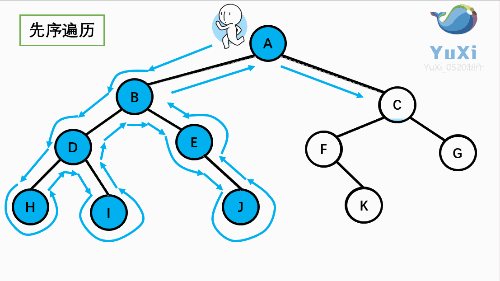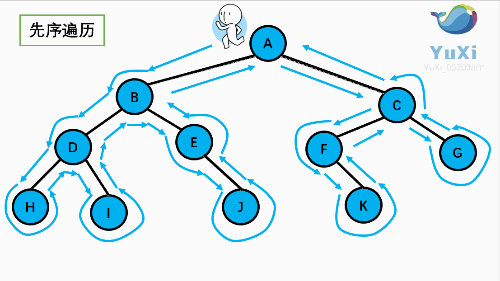
上图所示二叉树前序遍历如下:
从根结点出发,则第一次到达结点A,故输出A;
继续向左访问,第一次访问结点B,故输出B;
按照同样规则,输出D,输出H;
当到达叶子结点H,返回到D,此时已经是第二次到达D,故不在输出D,进而向D右子树访问,D右子树不为空,则访问至I,第一次到达I,则输出I;
I为叶子结点,则返回到D,D左右子树已经访问完毕,则返回到B,进而到B右子树,第一次到达E,故输出E;
向E左子树,E的左树为空返回到E进而访问E的右树J输出G
按照同样的访问规则,继续输出C、F K、G;故上图所示树的前序遍历为: 所示二叉树的前序遍历输出为:
ABDHIEJCFKG
2.中序遍历
就是从二叉树的根结点出发,当第二次到达结点时就输出结点数据,按照先访问左子树在访问右子树的顺序访问
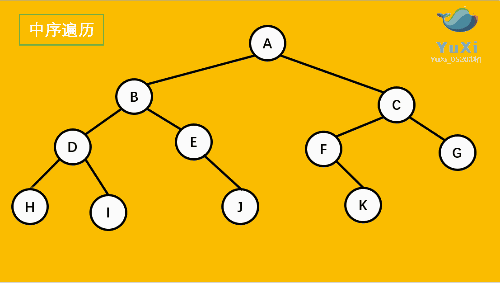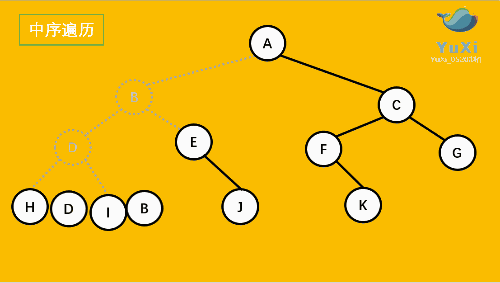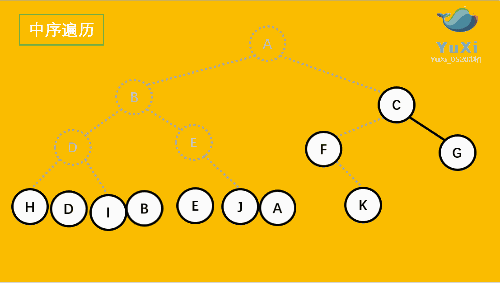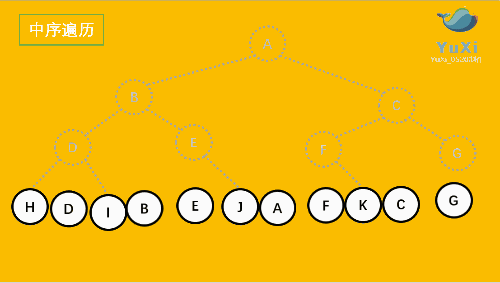
上图所示的二叉树的访问顺序如下:
从根结点出发,则第一次到达结点A,不输出A,继续向左访问,第一次访问结点B,不输出B;继续到达D,H;
到达H,H左子树为空,则返回到H,此时第二次访问H,故输出H;
H右子树为空,则返回至D,此时第二次到达D,故输出D,在访问D的右树I,I的右树为空,返回到 I,此时第二次到达I 故输出I;
由D返回至B,第二次到达B,故输出B;
按照同样规则继续访问,输出E J、A、F,K、C、G
3.后序遍历:
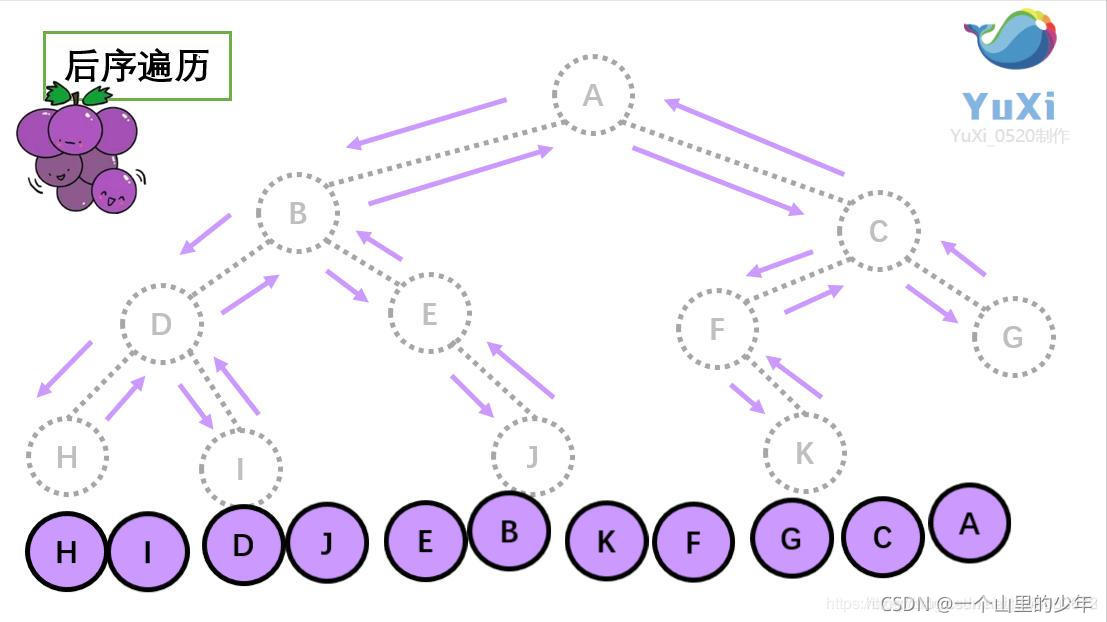
上图所示树的后序遍历如下:
从根结点出发,则第一次到达结点A,不输出A,继续向左访问,第一次访问结点B,不输出B;继续到达D,H;
到达H,H左子树为空,则返回到H,此时第二次访问H,不输出H;
H右子树为空,则返回至H,此时第三次到达H,故输出H;
由H返回至D,第二次到达D,不输出D;
继续访问至I,I左右子树均为空,故第三次访问I时,输出I;
返回至D,此时第三次到达D,故输出D;
按照同样规则继续访问,输出J、E、B、K ,F、G、C,A;故上述遍历的结果为:HIDJEBKFGCA
4.上述图对应代码:
4.1前序遍历:
void PrevOrder(TreeNode* root) { if (!root)return;//root走到空了就返回 cout << root->val << "";//访问当前节点 PrevOrder(root->_left);//访问左子树 PrevOrder(root->_right);访问右子树 }
4.2中序遍历:
void InOrder(TreeNode* root) { if (!root)return;//root走到空了就返回 InOrder(root->_left);//访问左子树 cout << root->val << " ";//访问根 InOrder(root->_right);//访问右子树 }
4.3后序遍历:
void PostOrder(TreeNode* root) { if (!root)return; PostOrder(root->_left);//访问左子树 PostOrder(root->_right);//访问右子树 cout << root->val << " ";//访问根 }
对应总代码:
#include<iostream>
using namespace std;
struct TreeNode {
TreeNode(int val=0)
:_left(nullptr)
,_right(nullptr)
,val(val)
{}
TreeNode* _left;
TreeNode* _right;
char val;
};
//前序遍历
void PrevOrder(TreeNode* root) {
if (!root)return;//root走到空了就返回
cout << root->val << " ";
PrevOrder(root->_left);
PrevOrder(root->_right);
}
//中序遍历
void InOrder(TreeNode* root) {
if (!root)return;//root走到空了就返回
InOrder(root->_left);//访问左子树
cout << root->val << " ";//访问根
InOrder(root->_right);//访问右子树
}
//后序遍历
void PostOrder(TreeNode* root) {
if (!root)return;
PostOrder(root->_left);//访问左子树
PostOrder(root->_right);//访问右子树
cout << root->val << " ";//访问根
}
int main() {
TreeNode* A = new TreeNode('A');
TreeNode* B= new TreeNode('B');
TreeNode* C = new TreeNode('C');
TreeNode* D = new TreeNode('D');
TreeNode* E = new TreeNode('E');
TreeNode* F = new TreeNode('F');
TreeNode* G = new TreeNode('G');
TreeNode* H = new TreeNode('H');
TreeNode* J = new TreeNode('j');
TreeNode* I = new TreeNode('I');
TreeNode* K = new TreeNode('k');
A->_left = B;
A->_right = C;
B->_left = D;
B->_right = E;
D->_left = H;
D->_right = I;
E->_right = J;
C->_left = F;
C->_right = G;
F->_right = K;
PrevOrder(A);
cout << endl;
InOrder(A);
cout << endl;
PostOrder(A);
return 0;
}
5.二叉树的层序遍历:
层次遍历就是按照树的层次自上而下的遍历二叉树。针对上图所示二叉树的层次遍历结果为:ABCDEFGHIJK
二叉树分好多层,因为要按层遍历,所以如果直接采用函数递归的话,一下子就深入层底了,达不到按层的目的。
所以在这里我们按照队列顺序输出!
实现思路:
在这里我们换一颗比较简单 的树来讲思路:

步骤如下
1、把根节点A放入队列中,此时队列为:A,队列头指针指向A,也就是队列第一个元素
2.访问当前队列队头指针所指的数据,并将其从队列中弹出,如果当前队列指针所指向的左孩子不为空,将其访入队列中,否则不放入队列中。如果当前队列指针所指向右孩子不为空,将其放入队列中,否则不放入队列中
3. 不断重复2步骤将B的右孩子和C的左孩子放入队列中
4.结束条件当队列为空说明已经访问完了,此时我们可以结束循环了
废话不多少我们来看代码:
void TreeLevelOrder(TreeNode* root) { queue<TreeNode*>q;//定义队列 if (root) q.push(root);//如果这颗树一个节点也没有就没有必要入 while (!q.empty()) {//队列不为空则继续入 TreeNode* top = q.front(); //取队头的数据 q.pop();//将其从队列中弹出 cout << top->val << " ";//访问当前节点的数据 if (top->_left) {//如果单前节点的左孩子不为空就将左孩子放到队列中 q.push(top->_left); } if (top->_right) {//如果当前队列的右孩子不为空,就将其放入队列中 q.push(top->_right); } } }
对应总代码:
#include<iostream> #include<queue> using namespace std; struct TreeNode {//创建节点 TreeNode(int val=0) :_left(nullptr) ,_right(nullptr) ,val(val) {} TreeNode* _left; TreeNode* _right; char val; }; void PrevOrder(TreeNode* root) { if (!root)return;//root走到空了就返回 cout << root->val << " "; PrevOrder(root->_left); PrevOrder(root->_right); } void InOrder(TreeNode* root) { if (!root)return;//root走到空了就返回 InOrder(root->_left);//访问左子树 cout << root->val << " ";//访问根 InOrder(root->_right);//访问右子树 } void PostOrder(TreeNode* root) { if (!root)return; PostOrder(root->_left);//访问左子树 PostOrder(root->_right);//访问右子树 cout << root->val << " ";//访问根 } void TreeLevelOrder(TreeNode* root) { queue<TreeNode*>q;//定义队列 if (root) q.push(root);//如果这颗树一个节点也没有就没有必要入 while (!q.empty()) {//队列不为空则继续入 TreeNode* top = q.front(); //取队头的数据 q.pop();//将其从队列中弹出 cout << top->val << " ";//访问当前节点的数据 if (top->_left) {//如果单前节点的左孩子不为空就将左孩子放到队列中 q.push(top->_left); } if (top->_right) {//如果当前队列的右孩子不为空,就将其放入队列中 q.push(top->_right); } } } int main() { TreeNode* A = new TreeNode('A'); TreeNode* B = new TreeNode('B'); TreeNode* C = new TreeNode('C'); TreeNode* D = new TreeNode('D'); TreeNode* E= new TreeNode('E'); A->_left = B; A->_right = C; B->_right = D; C->_left = E; TreeLevelOrder(A); return 0; }
运行结果:
遍历常考考点:
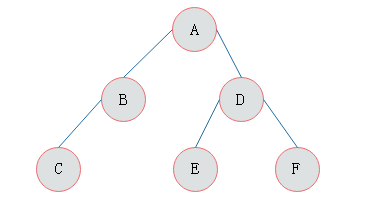
)已知前序遍历序列和中序遍历序列,确定一棵二叉树。
例题:若一棵二叉树的前序遍历为ABCDEF,中序遍历为CBAEDF,请画出这棵二叉树。
分析:前序遍历第一个输出结点为根结点,故A为根结点。早中序遍历中根结点处于左右子树结点中间,故结点A的左子树中结点有CB,右子树中结点有EDF。
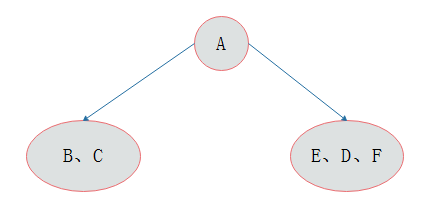
照同样的分析方法,对A的左右子树进行划分,最后得出二叉树的形态
已知后序遍历序列和中序遍历序列,确定一棵二叉树。
后序遍历中最后访问的为根结点,因此可以按照上述同样的方法,找到根结点后分成两棵子树,进而继续找到子树的根结点,一步步确定二叉树的形态。
注意:已知前序遍历序列和后序遍历序列,不可以唯一确定一棵二叉树,应为它无法区分左右子树。
二叉树节点的个数:
实现思路:
根据递归函数实现,如果树不为空,根节点为1
1 统计根节点左子树节点的个数
2 统计根节点右子树节点的个数
3 将左子树节点个数+右子树节点个数+根节点个数(1)即为整颗树的节点个数
4 统计左右子树的节点个数也是按照1~3的步骤进行
5 当树为空时,根节点的个数为0,即为递归函数的出口。
也就是整颗树节点的个数=左子树节点的个数+右子树节点的个数+根节点(也就是1)
代码实现:
size_t TreeSize(TreeNode* root) { if (!root)return 0;//走到空树,空树的节点个数为0; return TreeSize(root->_left) + TreeSize(root->_right) + 1;// //总节点的个数等于左子树节点的个数+右子树节点的个树+根节点的个数+1(也就是根节点) }
这个代码到底对不对了我们可以去OJ上去测试一下:
https://leetcode-cn.com/problems/count-complete-tree-nodes/
图片可能看不清大家可以复制链接去letecode里面看
对应代码:
class Solution { public: int countNodes(TreeNode* root) { if(root==nullptr) { return 0; } return countNodes(root->left)+countNodes(root->right)+1; } };
二叉树叶子节点的个数:
实现思路:
1. 如果给定节点T为NULL,则是空树,叶子节点为0,返回0;
2. 如果给定节点T左、右子树均为NULL,则是叶子节点,且叶子节点数为1,返回1;
3. 如果给定节点p左、右子树不都为NULL,则不是叶子节点,以p为根节点的子树叶子节点数 = p左子树叶子节点数 + p右子树叶子节点数;树中的叶子节点的个数 = 左子树中叶子节点的个数 + 右子树中叶子节点的个数。
利用递归代码实现,简单,易懂。
代码实现:
size_t TreeLeafSize(TreeNode* root) { if (!root)return 0;//空树则它的叶子节点的个数为0; if (!root->_left && !root->_right)return 1; //如果它的左为空并且右为空那么它一定就是叶子节点 return TreeLeafSize(root->_left) + TreeLeafSize(root->_right); //整颗树叶子节点的个数等于对应左子树叶子节点的个数+对应右子树节点的个数 }
求二叉树第k层有多少个节点(k>1):
实现思路:
假设根节点是第一层:
1.第k层节点的个数等价于求以根节点的左孩子为根的k-1层节点的个数+以根节点的右孩子为根的k-1层的节点的个数
2.把k作为计数器通过参数递归传递,递归的过程中不断减1
3.递归终止条件:如果走到空了说明该条路径深度小于k则返回0,如果K==1了则返回1
对应代码实现:
size_t TreeKLeveSize(TreeNode* root,int k) { if (!root||k<1)return 0;//空树返回0;防止k不合法 if (k == 1)return 1; return TreeKLeveSize(root->_left, k - 1) + TreeKLeveSize(root->_right, k - 1); }
拓展求第k层叶子节点的个数
思路上面叉不多之间看代码吧:
int GetTreeKthLevelLeafSize(TreeNode* root,int k) { if (!root || k < 0)return 0;//空树则返回0; if (k == 1) { if (!root->_left && !root->_right)//判断是否为叶子节点 return 1; else return 0; } return GetTreeKthLevelLeafSize(root->_left,k-1) + GetTreeKthLevelLeafSize(root->_right,k-1); }
二叉树中查找值为x的节点:
实现思路:
1:单边递归查找。
2:先对左子树递归查找。如果未找到x,则返回NULL,如果找到x,便返回x所在节点。3:根据返回值判断是否需要进行右递归查找操作
代码实现:
TreeNode* TreeFind(TreeNode* root, int x) { if (!root)return nullptr; if (root->val == x)return root;//判断当前树是不是,如果是则返回 TreeNode* leftRet = TreeFind(root->_left,x);//去root的左子树找 if(leftRet) return leftRet;//找到了则返回 TreeNode* rightRet = TreeFind(root->_right); if (rightRet) return rightRet; return nullptr;//对应左子树和右子树都没有找到 }
二叉树的销毁
由于比较简单在这里就不赘述了:
void TreeDestroy(TreeNode* root) { if (!root)return; TreeDestroy(root->_left); TreeDestroy(root->_right); delete root; }
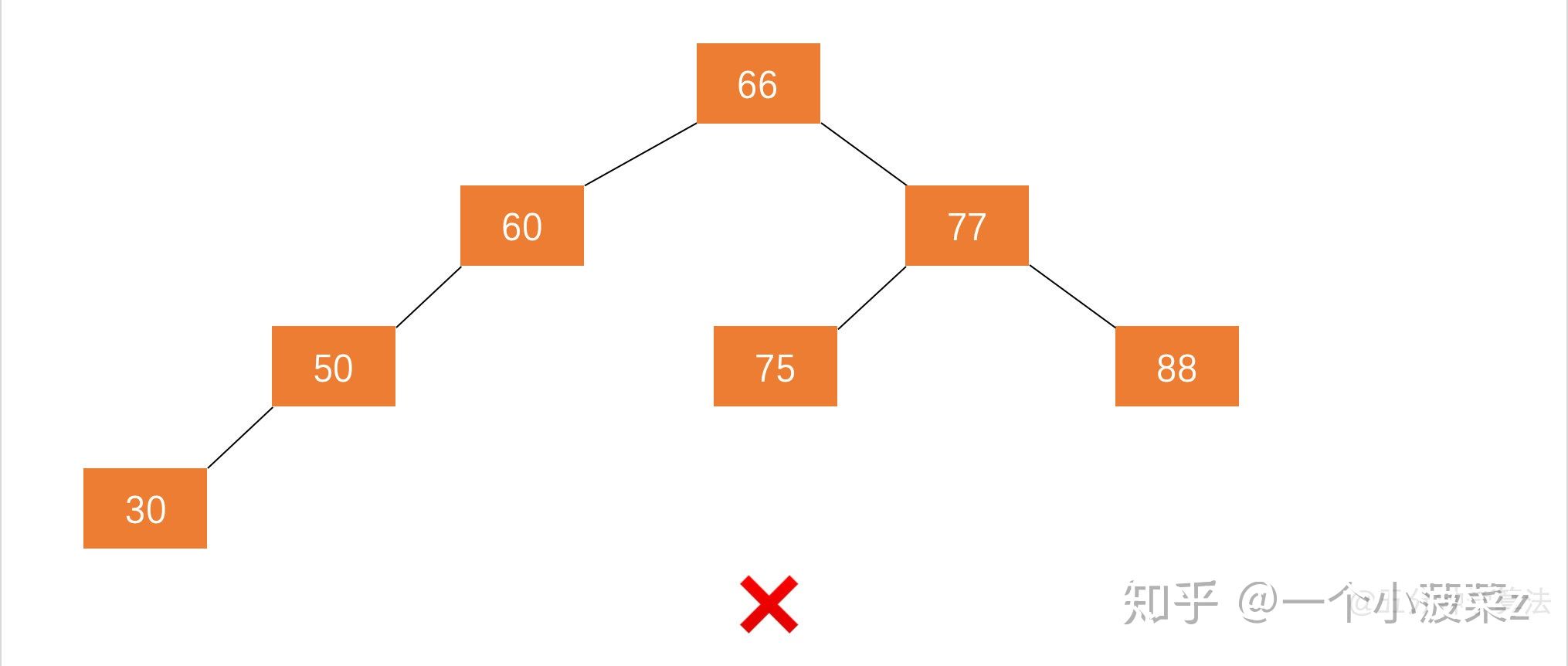
判断一颗二叉树是否为完全二叉树:
什么是完全二叉树了在上面已经说过了:
完全二叉树也就是没有满的满二叉树,它的节点在每一层一定是连续分布的。如果出现哪一层中两个非空节点间隔一个空节点,那一定不是完全二叉树。如下图所示:

完全二叉树的一些规律:

有了这我们就可以写代码了:
思路:
1.判断是否为完全二叉 树的关键是找到不饱和节点
2.完全二叉树每一层非空节点都是一个接一个连续分布的不可能出现两个非空节点之间出现空节点。
3.通过层序遍历来遍历树中的每一个结点
4.采取特殊结点值为 NULL替代 NULL结点,5入队列的标记方法每一个结点分为两种情况:
5.1.如果当前结点不为空,直接将当前结点入队列
5.2.如果当前结点为空,将结点值为 null 的标记结点入队列
6当出队列的结点的值为标记结点 null 时,终止循环
7.接着循环队列,条件为队列不为空,进行出队列操作,
8.当出现队列出的结点的值不为 null 时,返回 false如果循环结束,返回 true,说明是一个完全二叉树
对应代码实现:
bool isTreeComplete(TreeNode* root) { queue<TreeNode*>q; if (root)q.push(root); while (!q.empty()) { TreeNode* top = q.front(); q.pop(); if (top == nullptr)break;//出到空跳出循环 q.push(top->_left); q.push(top->_right); } while (!q.empty()) { auto top = q.front(); q.pop(); if (top)return false;//有不为空的则不是完全二叉树 } return true; }
非递归实现二叉树的(前中后序遍历重点)
首先,有一点是明确的:非递归写法一定会用到栈,这个应该不用太多的解释。我们先看前序遍历:
1. 前序遍历的递归定义:先根节点,后左子树,再右子树。如何写非递归代码呢?一句话:让代码跟着思维走:
2.假设你面前有一棵二叉树,现要求你写出它的前序遍历序列,如果你对前序遍历很熟悉的话你一定是先访问根节点在访问左子树其实是右子树,遍历完根之后我就要遍历左子树一直遍历到左子树的最下边的节点所以这段代码是理所当然的
stack<TreeNode*>stk;
TreeNode* cur = root;
while (cur) {
q.push(root);
cout << root->val << " ";
cur = cur->_left;
}一路保存根节点的原因是:遍历完左子树后,需要借助根节点进入右子树。
大致思路如下:
首先我们应该创建一个stack用来存放节点,首先我们想要打印根节点的数据,此时Stack里面的内容为空,所以我们优先将头结点加入stack,然后打印。
之后我们应该先打印左子树,然后右子树。所以先加入stack的就是右子树,然后左子树。
步鄹:
前序遍历:①首先访问根节点是否为空,则入栈→输出栈顶元素→当前节点的左子树入栈
②当左子树为空,则栈顶元素出栈,转向该节点的右子树
③全部元素出栈以后,结束循环
图解:

代码实现:
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
vector<int>res;
stack<TreeNode*>st;
TreeNode*cur=root;
while(!st.empty()||cur){
while(cur){
res.push_back(cur->val);
st.push(cur);
cur=cur->left;
}
TreeNode*top=st.top();
st.pop();
cur=top->right;
}
return res;
}
};对应letecode链接:
力扣
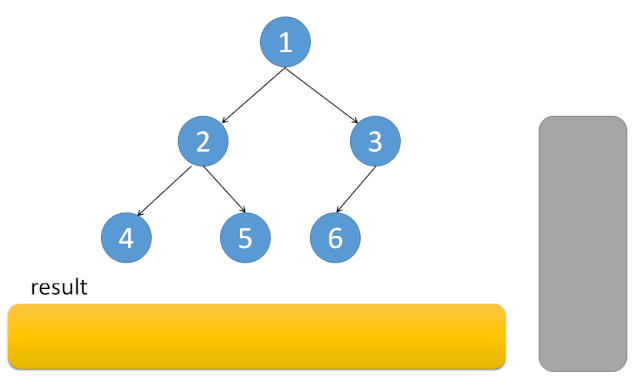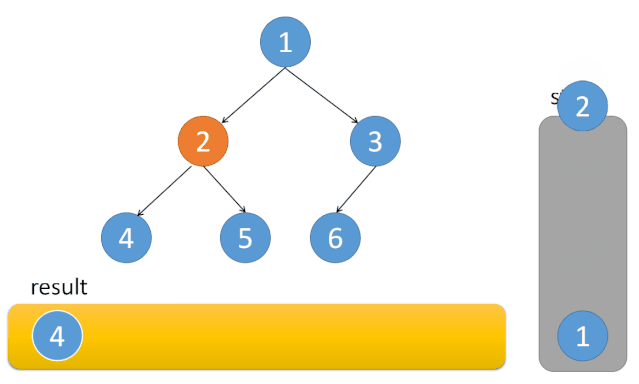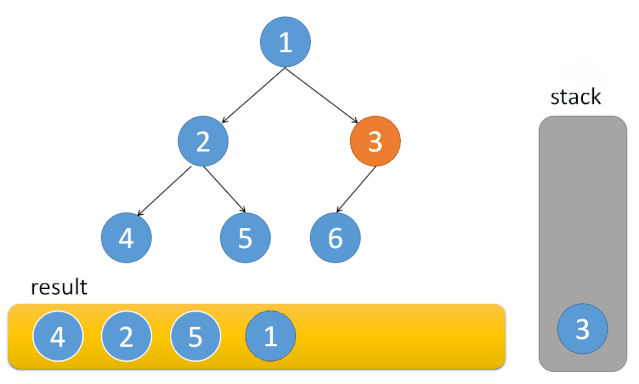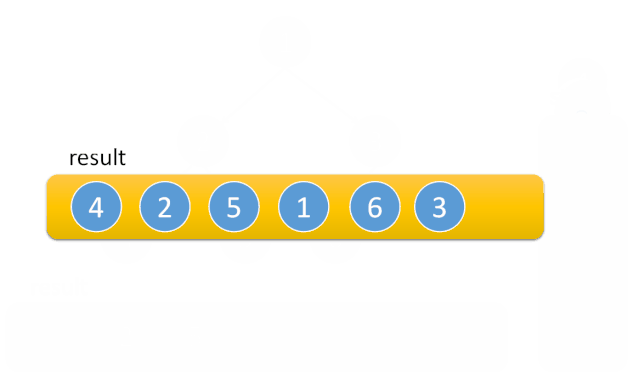
中序遍历:
二叉树的前序,中序非递归遍历的唯一不同是出栈的时间
中序遍历:①入栈→当前节点的左子树入栈
②当左子树为空,则栈顶元素出栈,输出栈顶元素→转向该节点的右子树
③栈为空时,结束循环
对应动图:
代码实现:
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int>res;
stack<TreeNode*>st;
TreeNode*cur=root;
while(cur||!st.empty()){
while(cur){
st.push(cur);
cur=cur->left;
}
TreeNode*top=st.top();
st.pop();
res.push_back(top->val);
cur=top->right;
}
return res;
}
};对应letecode链接:
力扣
后序遍历:
表的后序非递归遍历:cur指向当前的节点,lastnode指向前一个节点
①根节点入栈,如果栈不为空,则判断栈顶元素节点的左右节点是否为空,同时判断
前一个节点是否是当前节点的左孩子或者右孩子
②如果①为真,则输出当前节点且栈顶元素出栈,同时令cur等于当前节点
③如果①为假,则当前节点的孩子节点入栈
④当栈为空时,退出循环
对应图:


对应代码:
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
vector<int>res;
stack<TreeNode*>st;
TreeNode*cur=root;
TreeNode*lastNode=nullptr;//最近访问的节点
while(!st.empty()||cur){
while(cur){
st.push(cur);
cur=cur->left;
}
TreeNode*top=st.top();
if(top->right==nullptr||lastNode==top->right){
res.push_back(top->val);
lastNode=top;
st.pop();
}
else{
cur=top->right;
}
}
return res;
}
};对应letecode链接:
力扣
上述代码汇总:
#include<iostream> #include<stack> #include<queue> using namespace std; struct TreeNode { TreeNode(int val=0) :_left(nullptr) ,_right(nullptr) ,val(val) {} TreeNode* _left; TreeNode* _right; char val; }; void PrevOrder(TreeNode* root) { if (!root)return;//root走到空了就返回 cout << root->val << " "; PrevOrder(root->_left); PrevOrder(root->_right); } void InOrder(TreeNode* root) { if (!root)return;//root走到空了就返回 InOrder(root->_left);//访问左子树 cout << root->val << " ";//访问根 InOrder(root->_right);//访问右子树 } void PostOrder(TreeNode* root) { if (!root)return; PostOrder(root->_left);//访问左子树 PostOrder(root->_right);//访问右子树 cout << root->val << " ";//访问根 } void TreeLevelOrder(TreeNode* root) { queue<TreeNode*>q;//定义队列 if (root) q.push(root);//如果这颗树一个节点也没有就没有必要入 while (!q.empty()) {//队列不为空则继续入 TreeNode* top = q.front(); //取队头的数据 q.pop();//将其从队列中弹出 cout << top->val << " ";//访问当前节点的数据 if (top->_left) {//如果单前节点的左孩子不为空就将左孩子放到队列中 q.push(top->_left); } if (top->_right) {//如果当前队列的右孩子不为空,就将其放入队列中 q.push(top->_right); } } } size_t TreeSize(TreeNode* root) { if (!root)return 0;//走到空树,空树的节点个数为0; return TreeSize(root->_left) + TreeSize(root->_right) + 1;// //总节点的个数等于左子树节点的个数+右子树节点的个树+根节点的个数+1(也就是根节点) } size_t TreeLeafSize(TreeNode* root) { if (!root)return 0;//空树则它的叶子节点的个数为0; if (!root->_left && !root->_right)return 1;//如果它的左为空并且右为空那么它一定就是叶子节点 return TreeLeafSize(root->_left) + TreeLeafSize(root->_right); //整颗树叶子节点的个数等于对应左子树叶子节点的个数+对应右子树节点的个数 } size_t TreeKLeveSize(TreeNode* root,int k) { if (!root||k<1)return 0;//空树返回0;防止k不合法 if (k == 1)return 1; return TreeKLeveSize(root->_left, k - 1) + TreeKLeveSize(root->_right, k - 1); } TreeNode* TreeFind(TreeNode* root, int x) { if (!root)return nullptr; if (root->val == x)return root;//判断当前树是不是,如果是则返回 TreeNode* leftRet = TreeFind(root->_left,x);//去root的左子树找 if(leftRet) return leftRet;//找到了则返回 TreeNode* rightRet = TreeFind(root->_right); if (rightRet) return rightRet; return nullptr;//对应左子树和右子树都没有找到 } void TreeDestroy(TreeNode* root) { if (!root)return; TreeDestroy(root->_left); TreeDestroy(root->_right); delete root; } bool isTreeComplete(TreeNode* root) { queue<TreeNode*>q; if (root)q.push(root); while (!q.empty()) { TreeNode* top = q.front(); q.pop(); if (top == nullptr)break;//出到空跳出循环 q.push(top->_left); q.push(top->_right); } while (!q.empty()) { auto top = q.front(); q.pop(); if (top)return false;//有不为空的则不是完全二叉树 } return true; } int GetTreeKthLevelLeafSize(TreeNode* root,int k) { if (!root || k < 0)return 0;//空树则返回0; if (k == 1) { if (!root->_left && !root->_right)//判断是否为叶子节点 return 1; else return 0; } return GetTreeKthLevelLeafSize(root->_left,k-1) + GetTreeKthLevelLeafSize(root->_right,k-1); } int main() { TreeNode* A = new TreeNode('A'); TreeNode* B = new TreeNode('B'); TreeNode* C = new TreeNode('C'); TreeNode* D = new TreeNode('D'); TreeNode* E= new TreeNode('E'); A->_left = B; A->_right = C; B->_right = D; C->_left = E; TreeLevelOrder(A); return 0; }
总结:
在非递归版本中的几个要点:
①、我们需要理解三种遍历方法的思想(以跟节点为基准);
②、所有的节点都可看做是父节点(叶子节点可看做是两个孩子为空的父节点);
③ 、利用堆栈来保存中间值,来实现非递归版本。

如果觉得写的不错的话可以点个赞!如果有错误请在评论区留言谢谢!