CUDA 编程入门
更好的阅读体验
CUDA 概述
CUDA 是 NVIDIA 推出的用于其发布的 GPU 的并行计算架构,使用 CUDA 可以利用 GPU 的并行计算引擎更加高效的完成复杂的计算难题。
在目前主流的使用冯·诺依曼体系结构的计算机中,GPU 属于一个外置的设备,因此即便在利用 GPU 进行并行计算的时候也无法脱离 CPU,需要与 CPU 协同工作。因此当我们在说 GPU 并行计算时,其实指的是基于 CPU+GPU 的异构计算架构。在异构计算架构中,CPU 和 GPU 通过 PCI-E 总线连接在一起进行协同工作,所以 CPU 所在位置称为 Host,GPU 所在位置称为 Device,如下图所示。
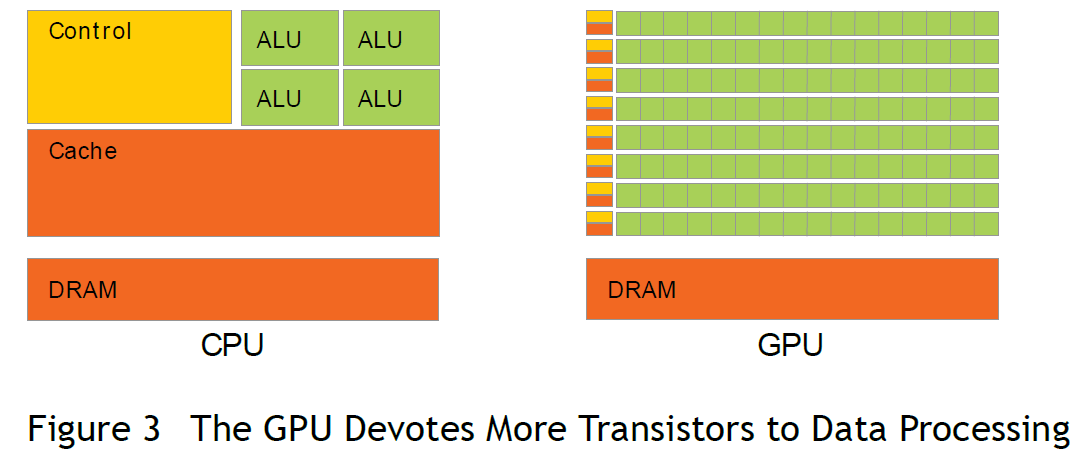
从上图可以看到,GPU 中有着更多的运算核心,非常适合数据并行的计算密集型任务,比如大型的矩阵计算。
CUDA 编程模型基础
在了解了 CUDA 的基本概念之后,还需要了解 CUDA 编程模型的基本概念以便于之后利用 CUDA 编写并行计算程序。
CUDA 模型时一个异构模型,需要 CPU 和 GPU 协同工作,在 CUDA 中一般用 Host 指代 CPU 及其内存,Device 指代 GPU 及其内存。CUDA 程序中既包含在 Host 上运行的程序,也包含在 Device 上运行的程序,并且 Host 和 Device 之间可以进行通信,如进行数据拷贝等操作。一般的将需要串行执行的程序放在 Host 上执行,需要并行执行的程序放在 Device 上进行。
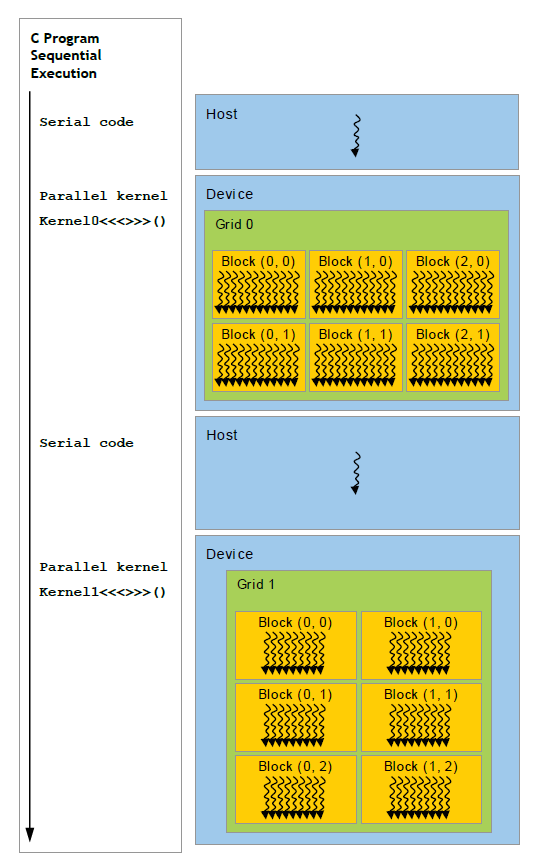
CUDA 程序一般的执行流程:
- 分配 Host 内存,并进行数据初始化
- 分配 Device 内存,并将 Host 上的数据拷贝到 Device 上
- 调用 CUDA Kernel 在 Device 上进行并行运算
- 将运算结果从 Device 上拷贝到 Host 上,并释放 Device 上对应的内存
- 并行运算结束,Host 得到运算结果,释放 Host 上分配的内存,程序结束
在第 3 步中,CUDA Kernel 指的是在 Device 线程上并行执行的函数,在程序中利用 __global__ 符号声明,在调用时需要用 <<<grid, block>>> 来指定 Kernel 执行的线程数量,在 CUDA 中每一个线程都要执行 Kernel 函数,并且每个线程会被分配到一个唯一的 Thread ID,这个 ID 值可以通过 Kernel 的内置变量 threadIdx 来获得。
__gloabl__ vectorAddition(float* device_a, float* device_b, float* device_c); // 定义 Kernel
int main()
{
/*
some codes
*/
vectorAddition<<<10, 32>>>(parameters); // 调用 Kernel 并指定 grid 为 10, block 为 32
/*
some codes
*/
}
Kernel 的层次结构
Kernel 在 Device 执行的时候实际上是启动很多线程,这些线程都执行 Kernel 这个函数。其中,由这个 Kernel 启动的所有线程称为一个 grid,同一个 grid 中的线程共享相同的 Global memory,grid 是线程结构的第一个层次。一个 grid 又可以划分为多个 block,每一个 block 包含多个线程,其中的所有线程又共享 Per-block shared memory,block 是线程结构的第二个层次。最后,每一个线程(thread)有着自己的 Per-thread local memory。
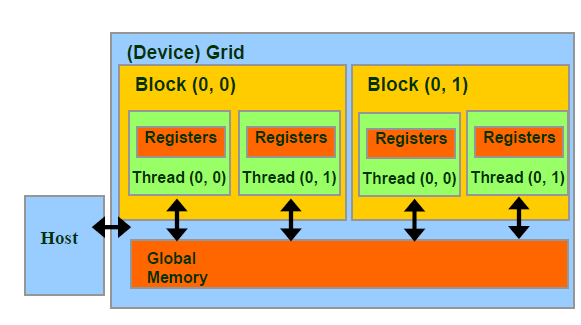
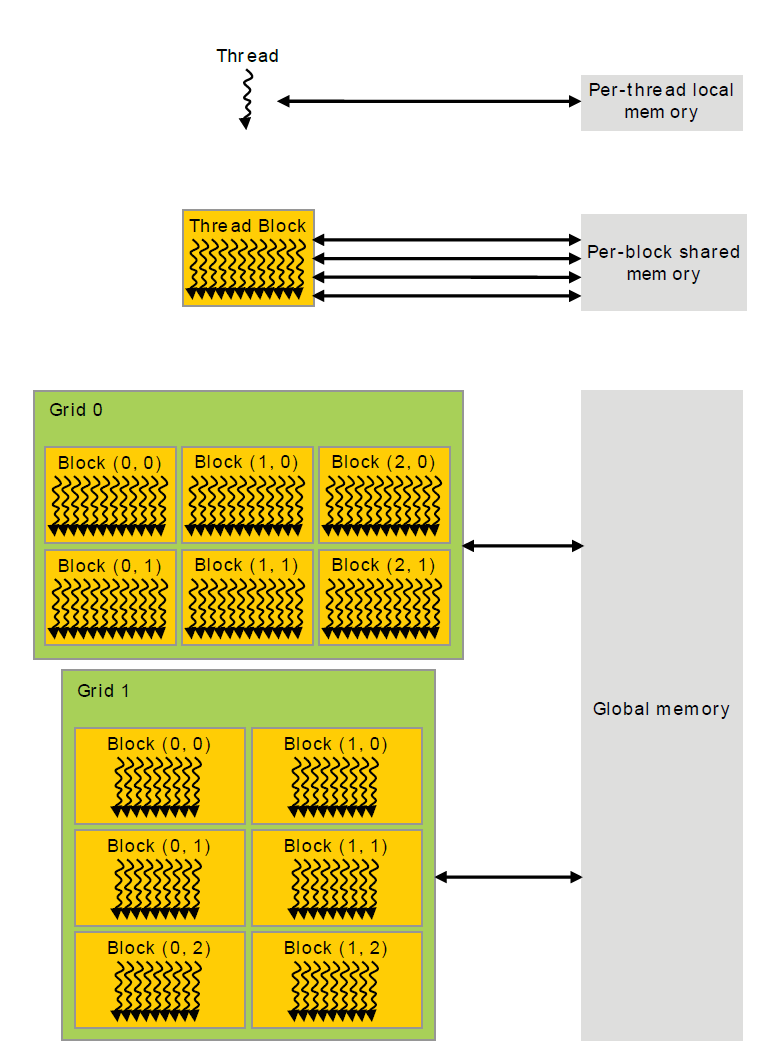
下图是一个线程两层组织结构的示意图,其中 grid 和 block 均为 2-dim 的线程组织。grid 和 block 都是定义为 dim3 类型的变量,dim3 可以看成是包含三个无符号整数(x, y, z)成员的结构体变量,在定义时,缺省值初始化为1。
dim3 grid(3, 2);
dim3 block(5, 3);
kernel<<<grid, block>>>(parameters);

从线程的组织结构可以得知,一个线程是由(blockIdx, threadIdx)来唯一标识的,blockIdx 和 threadIdx 都是 dim3 类型的变量,其中 blockIdx 指定线程所在 block 在 grid 中的位置,threadIdx 指定线程在 block 中的位置,如图中的 Thread(2,1) 满足:
threadIdx.x = 2;
threadIdx.y = 1;
blockIdx.x = 1;
blockIdx.y = 1;
一个 block 是放在同一个流式多处理器(SM)上运行的,但是单个 SM 上的运算核心(cuda core)有限,这导致线程块中的线程数是有限制的,因此在设置 grid 和 block 的 shape 时需要根据所使用的 Device 来设计。
如果要知道一个线程在 block 中的全局 ID,就必须要根据 block 的组织结构来计算,对于一个 2-dim 的 block( D x D_x Dx, D y D_y Dy),线程( x x x, y y y)的 ID 值为 x + y ∗ D x x+y*D_x x+y∗Dx,如果是 3-dim 的 block( D x D_x Dx, D y D_y Dy, D z D_z Dz),线程( x x x, y y y, z z z)的 ID 值为 x + y ∗ D x + z ∗ D x ∗ D y x+y*D_x+z*D_x*D_y x+y∗Dx+z∗Dx∗Dy。
CUDA 实现向量加法
查看 Device 基本信息
在进行 CUDA 编程之前,需要先看一下自己的 Device 的配置,便于之后自己设定 grid 和 block 更好的利用 GPU。
#include <stdio.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
int main()
{
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, 0);
printf("Device 0 information:\n");
printf("设备名称与型号: %s\n", deviceProp.name);
printf("显存大小: %d MB\n", (int)(deviceProp.totalGlobalMem / 1024 / 1024));
printf("含有的SM数量: %d\n", deviceProp.multiProcessorCount);
printf("CUDA CORE数量: %d\n", deviceProp.multiProcessorCount * 192);
printf("计算能力: %d.%d\n", deviceProp.major, deviceProp.minor);
}
Device 0 information:
设备名称与型号: Tesla K20c
显存大小: 4743 MB
含有的SM数量: 13
CUDA CORE数量: 2496
计算能力: 3.5
Device 1 information:
设备名称与型号: Tesla K20c
显存大小: 4743 MB
含有的SM数量: 13
CUDA CORE数量: 2496
计算能力: 3.5
其中第 12 行乘 192 的原因是我所使用的设备为 Tesla K20,而 Tesla K 系列均采用 Kepler 架构,该架构下每个 SM 中的 cuda core 的数量为 192。
实现 Vector Addition
#include <stdio.h>
#include <time.h>
#include <math.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
const int LENGTH = 5e4;
clock_t start, end;
void vectorAdditionOnDevice(float*, float*, float*, const int);
__global__ void additionKernelVersion(float*, float*, float*, const int);
int main()
{
start = clock();
float A[LENGTH], B[LENGTH], C[LENGTH] = {0};
for (int i = 0; i < LENGTH; i ++) A[i] = 6, B[i] = 5;
vectorAdditionOnDevice(A, B, C, LENGTH); //calculation on GPU
end = clock();
printf("Calculation on GPU version1 use %.8f seconds.\n", (float)(end - start) / CLOCKS_PER_SEC);
}
void vectorAdditionOnDevice(float* A, float* B, float* C, const int size)
{
float* device_A = NULL;
float* device_B = NULL;
float* device_C = NULL;
cudaMalloc((void**)&device_A, sizeof(float) * size); // 分配内存
cudaMalloc((void**)&device_B, sizeof(float) * size); // 分配内存
cudaMalloc((void**)&device_C, sizeof(float) * size); // 分配内存
const float perBlockThreads = 192.0;
cudaMemcpy(device_A, A, sizeof(float) * size, cudaMemcpyHostToDevice); // 将数据从 Host 拷贝到 Device
cudaMemcpy(device_B, B, sizeof(float) * size, cudaMemcpyHostToDevice); // 将数据从 Host 拷贝到 Device
additionKernelVersion<<<ceil(size / perBlockThreads), perBlockThreads>>>(device_A, device_B, device_C, size); // 调用 Kernel 进行并行计算
cudaDeviceSynchronize();
cudaMemcpy(device_C, C, sizeof(float) * size, cudaMemcpyDeviceToHost); // 将数据从 Device 拷贝到 Host
cudaFree(device_A); // 释放内存
cudaFree(device_B); // 释放内存
cudaFree(device_C); // 释放内存
}
__global__ void additionKernelVersion(float* A, float* B, float* C, const int size)
{
// 此处定义用于向量加法的 Kernel
int i = blockIdx.x * blockDim.x + threadIdx.x;
C[i] = A[i] + B[i];
}
Calculation on GPU version1 use 0.14711700 seconds.
参考资料
CUDA编程入门极简教程
CUDA C Programming Guide