文章目录
- 前言
- 安装
- 基本使用
- User类
- @task装饰器
- 任务间隔
- @tag装饰器
- 前置与后置
- HttpUser类
- 常用参数
- 命令行配置
- 配置文件配置
- 常用压测场景实战
- 高用户高并发场景压测
- 每个用户循环取数据
- 保证并发测试数据唯一性,不循环取数据
- 保证并发测试数据唯一性,循环取数据
- 梯度增压
- 非http协议压测
- 参考
前言
locust是一款由python编写的压测工具,可以很好的和python进行结合使用,功能强大。
locust文档是英文版的,不利于阅读,本文从文档出发,模拟真实的压测需求与场景,带你领略locust的强大。
安装
locust安装方便,直接使用pip3进行安装
pip3 install locust
检查是否安装成功
locust -V
基本使用
需求1: 项目紧急,我接到了个压测需求,url地址为"https://www.baidu.com/hello" ,get请求,需要模拟100个用户同时访问,每个用户访问url频率在1-5秒之间随机选择,压测10分钟。
对于这样的需求,如何编写locust压测脚本呢?下面是最简单的入门脚本。
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
wait_time = between(1, 5)
host = "https://www.baidu.com"
@task
def hello_world(self):
self.client.get("/hello")
假设该脚本文件名称为locust_test.py,可以使用以及下命令启动脚本
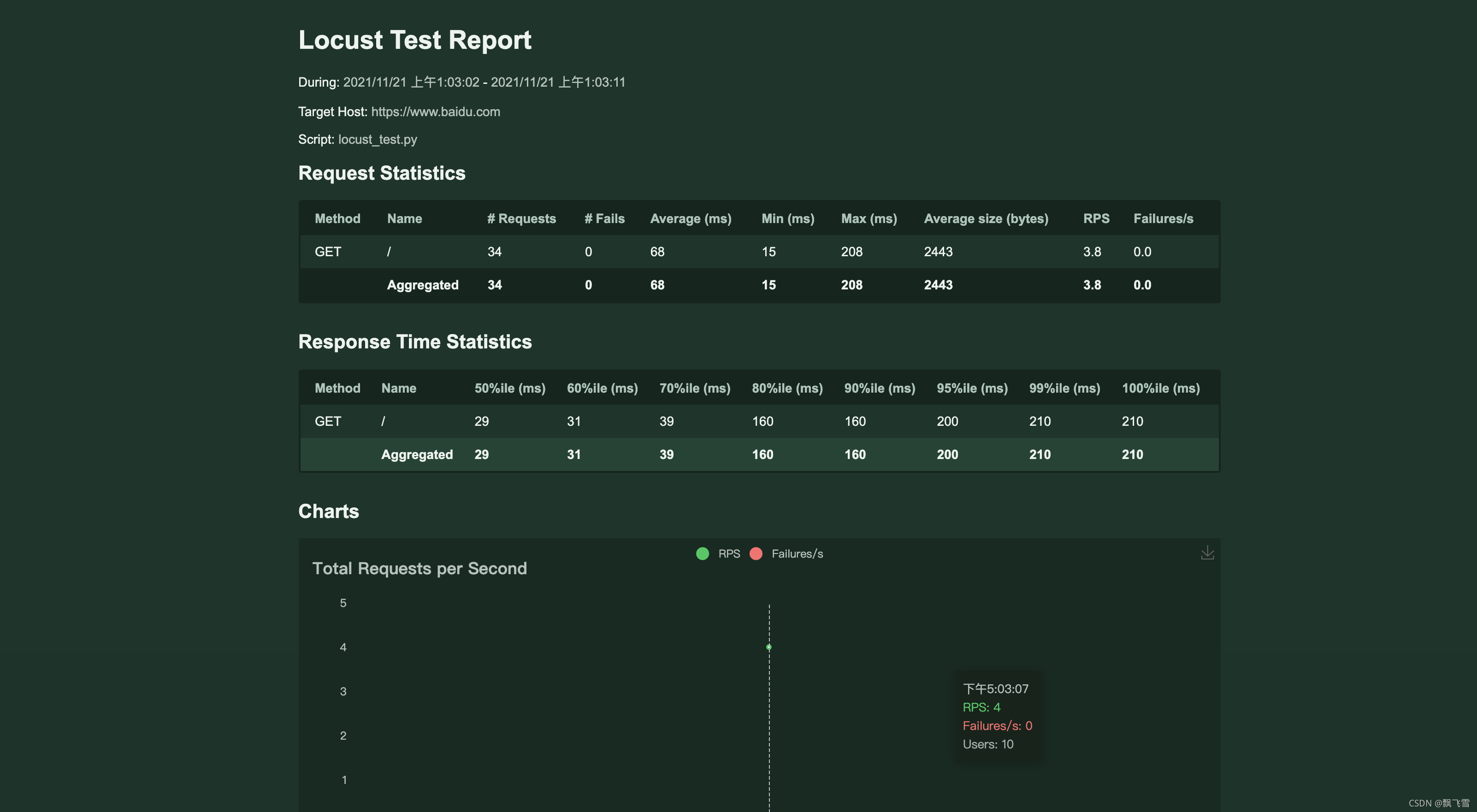
locust -f locust_test.py --headless -u 100 -r 100 -t 10m --html report.html
更多参数会在后文详细列举。
-f locust_test.py //代表执行哪一个压测脚本
--headless //代表无界面执行
-u 100 //模拟100个用户操作
-r 100 //每秒用户增长数
-t 10m //压测10分钟
--html report.html //html结果输出的文件路径名称
最后html测试结果结果如下
User类
每个locust脚本都需要继承User类,在User类定义了每个用户的压测行为。在上面例子中,QuickstartUser类继承HttpUser类,而HttpUser类继承User类,那么User类中究竟有哪些东西呢。
@task装饰器
既然locust定义了一个用户类,那么必然每个用户需要执行对应的任务,@task装饰器就定义了一个任务,函数就是任务执行的过程,其中装饰器后面的参数可以定义一个int代表任务的权重。
需求2: 接到了个压测需求,url地址为"https://www.baidu.com" ,get请求,需要模拟100个用户同时访问,每个用户访问循环访问"/hello"和"/world"这两个接口,任务之间没有间隔,并且用户选择这两个接口的比例为1:3,压测10分钟。
import os
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
# wait_time = between(1, 5)
host = "https://www.baidu.com"
@task
def hello_world(self):
self.client.get("/hello")
@task(3)
def hello_world(self):
self.client.get("/world")
if __name__ == '__main__':
os.system("locust -f locust_test.py --headless -u 100 -r 100 -t 10m --html report.html")
这边我把wait_time = between(1, 5)注释掉了。任务执行没有间隔,类似每个用户执行wile True操作不停给服务器发送请求。@task(3)定义了任务权重,脚本期望的情况是每执行4次请求,3次是“/world” 1次是"/hello"
任务间隔
返回需求1,如果把需求换成每个用户访问url频率固定2秒,这个怎么办呢?这边引出了任务间隔的概念,分为以下3类:
- 任务随机间隔wait_time = between(a, b)
- 任务固定间隔wait_time =constant(a)
- 任务无间隔
怎么理解间隔呢?其实可以这么理解,压测其实就是模拟用户给服务器发请求,任务无间隔代表每个用户不停的while 1给服务器发请求,任务固定间隔可以理解成while 1 sleep固定时间给服务器发请求。
需求3: 我接到了个压测需求,url地址为"https://www.baidu.com/hello" ,get请求,需要模拟100个用户同时访问,每个用户访问url频率固定2秒发一次,压测10分钟。
from locust import HttpUser, task, constant
class QuickstartUser(HttpUser):
wait_time = constant(2)
host = "https://www.baidu.com"
@task
def hello_world(self):
self.client.get("/hello")
@tag装饰器
当我们需要选取其中一个任务或者几个任务进行压测时,@tag装饰器就发挥作用了。
class QuickstartUser(HttpUser):
# wait_time = between(1, 5)
host = "https://www.baidu.com"
@task
@tag("task1")
def hello_world(self):
self.client.get("/hello")
@task(3)
@tag("task2")
def hello_world2(self):
self.client.get("/world")
@task(3)
@tag("task3")
def hello_world3(self):
self.client.get("/world")
当前有3个任务,我们需要只选取task2和task3运行怎么办 --tags task2 task2 参数就可以解决这个问题。
locust -f locust_test.py --headless -u 100 -r 100 -t 10m --html report.html --tags task2 task2
前置与后置
用户可以声明on_start方法和/或on_stop方法。用户将调用on_start方法开始运行时on_stop方法。对于任务集on_start方法在模拟用户开始执行该任务集时调用,并且on_stop当模拟用户停止执行该任务集时调用(当interrupt()或者用户被杀死)
HttpUser类
HttpUser类继承自User类,所以User类中的属性HttpUser类都有,唯一存在不同的是HttpUser类自己实现了http的请求方法。
使用方法与requests库相同,获取requests对象可以使用self.client的方式获取。这边重点介绍一下self.client的断言方式。
需求4: 我接到了个压测需求,url地址为"https://www.baidu.com/hello" ,post请求,返回结果为json格式{“code”:0,“msg”:“ok”},其中code0代表成功,-1代表失败,需要模拟100个用户同时访问,每个用户访问url频率固定2秒发一次,压测10分钟。
import json
import os
from locust import HttpUser, task, tag, constant
class QuickstartUser(HttpUser):
wait_time = constant(2)
host = "https://www.baidu.com"
@task
@tag("task1")
def hello_world(self):
with self.client.post("/hello", catch_response=True) as response:
try:
status_code = response.status_code
text = json.loads(response.text)
if status_code != 200:
response.failure("status_code断言失败")
elif text["code"] != 0:
response.failure("code断言失败")
elif response.elapsed.total_seconds() > 0.5:
response.failure("Request took too long")
except Exception as e:
response.failure(str(e))
常用参数
具体见官方文档:http://docs.locust.io/en/stable/configuration.html
命令行配置
这边列出几个常用的参数
- -f locust_test.py //代表执行哪一个压测脚本
- –headless //代表无界面执行
- -u 100 //模拟100个用户操作
- -r 100 //每秒用户增长数
- -t 10m //压测10分钟
- –html report.html //html结果输出的文件路径名称
- -H https://www.baidu.com //定义访问的host
- –csv=CSV_PREFIX //将当前请求统计信息存储到CSV格式的文件中。设置此选项将生成三个文件:[CSV_PREFIX]_stats.CSV,[CSV_PREFIX]_stats_history.CSV和[CSV_PREFIX]_failures.CSV
- –only-summary //只打印摘要统计
- –print-stats //在控制台中打印统计信息
配置文件配置
# master.conf in current directory
locustfile = locust_files/my_locust_file.py
headless = true
master = true
expect-workers = 5
host = http://target-system
users = 100
spawn-rate = 10
run-time = 10m
locust --config=master.conf
常用压测场景实战
高用户高并发场景压测
需求5: 我接到了个压测需求,url地址为"https://www.baidu.com/hello" ,get请求,需要模拟4000个用户同时访问,每个用户访问url不间断,压测10分钟。
HttpUser无法支持高并发压测,这时候需要将HttpUser换成FastHttpUser即可
from locust import FastHttpUser, task
class QuickstartUser(FastHttpUser):
host = "https://www.baidu.com"
@task
def hello_world(self):
self.client.get("/hello")
每个用户循环取数据
需求6: 我接到了个压测需求,url地址为"https://www.baidu.com/hello" ,get请求,有个参数叫id,捞取线上数据进行真实场景压测,每个用户循环读取数据。
from locust import FastHttpUser, task
def prepare_data():
# 准备ids数据,模拟从文件中读取
return [i for i in range(100)]
class QuickstartUser(FastHttpUser):
host = "https://www.baidu.com"
data = prepare_data()
def on_start(self):
self.index = 0
@task
def hello_world(self):
id = self.data[self.index]
print(id)
self.client.get("hello", params={"id": id})
self.index += 1
self.index = self.index % (len(self.data))
保证并发测试数据唯一性,不循环取数据
需求7: 我接到了个压测需求,url地址为"https://www.baidu.com/hello" ,get请求,有个参数叫id,捞取线上数据进行真实场景压测,保证每个id只请求一次,不循环取数据。
这边使用到了python内置类Queue,他是线程安全的。
from queue import Queue
from locust import FastHttpUser, task
def prepare_data():
q = Queue()
# 准备ids数据,模拟从文件中读取
for i in range(100):
q.put(i)
return q
class QuickstartUser(FastHttpUser):
host = "https://www.baidu.com"
data_queue = prepare_data()
@task
def hello_world(self):
id = self.data_queue.get(timeout=3)
print(id)
self.client.get("hello", params={"id": id})
if self.data_queue.empty():
print("结束压测")
exit()
保证并发测试数据唯一性,循环取数据
需求8: 我接到了个压测需求,url地址为"https://www.baidu.com/hello" ,get请求,有个参数叫id,捞取线上数据进行真实场景压测,保证每个id只请求一次,循环取数据。
from queue import Queue
from locust import FastHttpUser, task
def prepare_data():
q = Queue()
# 准备ids数据,模拟从文件中读取
for i in range(100):
q.put(i)
return q
class QuickstartUser(FastHttpUser):
host = "https://www.baidu.com"
data_queue = prepare_data()
@task
def hello_world(self):
id = self.data_queue.get()
print(id)
self.client.get("hello", params={"id": id})
self.data_queue.put_nowait(id)
这边使用data_queue.put_nowait(id),id用完之后再塞回队列中
梯度增压
需求9: 我接到了个压测需求,url地址为"https://www.baidu.com/hello" ,get请求,现在需要对其进行梯度增压,每10分钟增加20个用户,压测3小时,以窥探其性能瓶颈。
import math
import os
from locust import HttpUser, LoadTestShape, task
class QuickstartUser(HttpUser):
host = "https://www.baidu.com"
@task
def hello_world(self):
self.client.get("hello")
class StepLoadShaper(LoadTestShape):
'''
逐步加载实例
参数解析:
step_time -- 逐步加载时间
step_load -- 用户每一步增加的量
spawn_rate -- 用户在每一步的停止/启动
time_limit -- 时间限制
'''
setp_time = 600
setp_load = 20
spawn_rate = 20
time_limit = 60 * 60 * 3
def tick(self):
run_time = self.get_run_time()
if run_time > self.time_limit:
return None
current_step = math.floor(run_time / self.setp_time) + 1
return (current_step * self.setp_load, self.spawn_rate)
if __name__ == '__main__':
os.system("locust -f test4.py --headless -u 10 -r 10 --html report.html")
这边就需要使用到LoadTestShape这个内置类,类似于开了个线程,每秒都会调用tick方法,返回一个元组(当前用户数,增长率)
非http协议压测
有些情况下,我们压测并不是基于http协议的,比如websocket协议压测,jce协议的压测,这时候就需要重写User类的client,满足自己的压测需求。下面是重写client重要两点:
- self.client: locust协议入口实例,我们只要重写一个实例给client即可。
- 以下两个事件,用来收集报告信息,否则写好后执行你会发现收集不到性能数据
events.request_failure.fire()
events.request_success.fire()
需求10: 我接到了个压测需求,基于websocket协议接口进行压测。
import os
import time
import websocket
from locust import task, events, User
class WebSocketClient(object):
def __init__(self, host):
self.host = host
self.ws = websocket.WebSocket()
def connect(self, burl):
start_time = time.time()
try:
self.conn = self.ws.connect(url=burl)
except websocket.WebSocketTimeoutException as e:
total_time = int((time.time() - start_time) * 1000)
events.request_failure.fire(request_type="websockt", name='urlweb', response_time=total_time, exception=e)
else:
total_time = int((time.time() - start_time) * 1000)
events.request_success.fire(request_type="websockt", name='urlweb', response_time=total_time,
response_length=0)
return self.conn
def recv(self):
return self.ws.recv()
def send(self, msg):
self.ws.send(msg)
class WebSocketUser(User):
"""
A minimal Locust user class that provides an XmlRpcClient to its subclasses
"""
abstract = True # dont instantiate this as an actual user when running Locust
def __init__(self, environment):
super().__init__(environment)
self.client = WebSocketClient(self.host)
class QuickstartUser(WebSocketUser):
url = 'ws://localhost:8000/v1/ws/marketpair'
def on_start(self):
self.client.connect(self.url)
@task
def hello_world(self):
self.client.send("ok")
if __name__ == '__main__':
os.system("locust -f locust_test.py --headless -u 10 -r 10 -t 10s --html report.html")
最主要是events.request_failure.fire和events.request_success.fire这两个用来收集性能数据,如果不写报告收集不到性能数据。
参考
- 《locust官方文档》http://docs.locust.io/en/stable/writing-a-locustfile.html
- 《locust-基于python的性能测试工具(进化篇)》 https://km.woa.com/group/571/articles/show/411249
- 《locust压测rpc协议》https://www.cnblogs.com/yhleng/p/10031209.html