作者:Anatoly Yakovenko(anatoly@solana.io)
翻译:tangenter.eth
摘要
本文提出了一种新的区块链架构,其基础是一种能够验证链上事件发生的先后顺序及时间间隔的新共识算法,称作工作历史证明(Proof of History,PoH)。PoH算法能够将不可信任的时间间隔数据打包为区块链账本——一种只允许添加数据的数据结构。与工作量证明(Proof of Work,PoW)和权益证明(Proof of Stake,PoS)这些原有的共识算法相比较,PoH可减少具备拜占庭容错机制(Byzantine Fault Tolerant)的复制状态机(Replicated State Machine)在传递信息时的开销,从而使传输时长降到秒级以下。与此同时,根据PoH账本能够保存时间间隔数据的特点,本文还提出了两种算法,首先是一种可从任意大小的分区恢复数据的PoS算法,其次是一种高效的复制证明算法(Proof of Replication,PoRep)。PoRep和PoH的组合能够抵御伪造区块链账本上时间(事件的排列顺序)和存储内容的欺诈行为。本文将展示,在速度为1Gbps的网络环境和当今的硬件条件下,该协议的每秒数据吞吐量(TPS)可以达到71万次。
1,引言
区块链技术的本质是具备容错性的复制状态机。目前可用的一系列公链并不依赖于时间,换句话说,它们的运行机制不假定参与者们能够各自维持完全相同的本地时间。区块链网络上的每个节点通常仅参考它们自己的时钟,对网络中其余参与者的时钟毫无了解。缺乏可信的时间来源导致无法使用时间戳来确定是否保留某条消息,因为不能保证网络中的每个参与者都做出相同的选择。这里介绍的PoH算法旨在创建具有可验证时间间隔数据(即消息和事件之间的间隔时长)的区块链账本。在预期中,网络上的每个节点都可以依靠账本上的时间间隔数据而不必完全信任其余节点。
2,内容概述
以下是本文剩余部分的内容:
第3节介绍本系统的总体设计;
第4节描述工作历史证明算法;
第5节描述摘要中提及的PoS算法;
第6节描述摘要中提及的高效PoRep算法;
第7节分析系统架构和性能限制;
第7.5节将描述一种适用于高性能GPU的智能合约引擎。
3,网络设计
如图一所示,在任何给定时间都有一个被指定为Leader的系统节点负责生成PoH序列,从而为整个网络提供具备一致性的可验证时间间隔数据。Leader节点还负责把用户发出的信息组织成有序序列,使系统中的其他节点可以高效处理这些信息,以最大限度地提高数据吞吐量。它对存储在RAM中的当前状态执行操作,然后将操作数据和终止状态的签名发布到被称作验证者的复制器节点。验证者在它们手中的状态副本上执行相同的操作,并公开计算出的终止状态签名作为确认。每次公开确认都将被共识算法用作确定状态的投票。
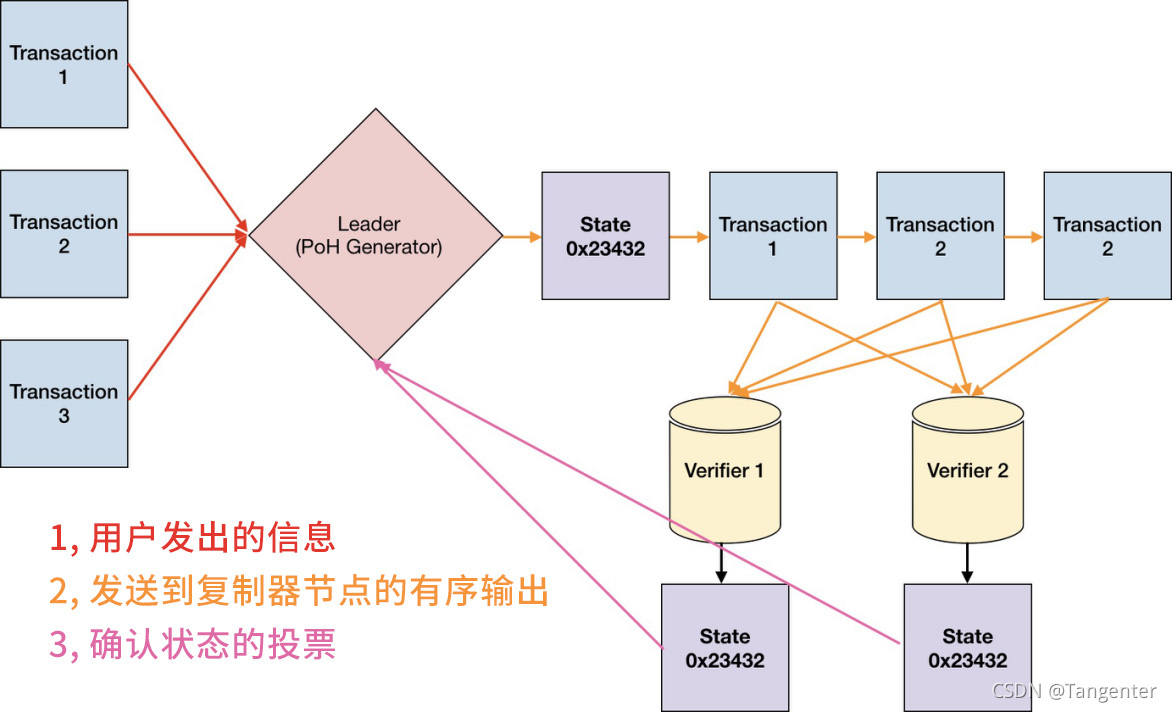
在未分片状态下的任何给定时间点,网络中都有且仅有一个Leader。每个验证者节点都具有与Leader节点相同的硬件能力,并且能够通过基于PoS算法的选举来成为Leader。选举的具体过程将在5.6小节中介绍。
由于CAP定理(CAP theorem)的存在,一致性在分片中的优先级几乎总是高于可用性。在分片较大的情况下,本文提出了一种从任意大小的分片恢复对网络的整体控制的机制。5.12小节对该机制进行了详细阐释。
4,工作历史证明
工作历史证明是一系列计算流程,它提供了确认两个事件之间的时间间隔的加密方法。由于它使用加密安全函数,所以无法从输入推测输出,必须完整执行算法才能得到输出。该函数在单个处理器上按顺序运行,将上一次的输出作为这一次的输入,并定期记录当前输出值以及被调用的总次数。接下来,通过在独立处理器上检查序列中的每个分段,输出值可以被外部计算机并行地重新计算和验证。数据(或者数据的哈希值)可附加在函数的状态上,从而将它添加到序列当中。当状态、索引或数据被添加到序列中时,一个时间戳将生成,它可以保证这些数据是在序列中的下一个哈希值生成之前创建的。该设计同时支持横向扩展,因为多个生成器可以通过将它们各自的状态混合到彼此的序列中来互相同步。横向扩展的具体方法将在4.4小节进行讨论。
4.1 具体描述
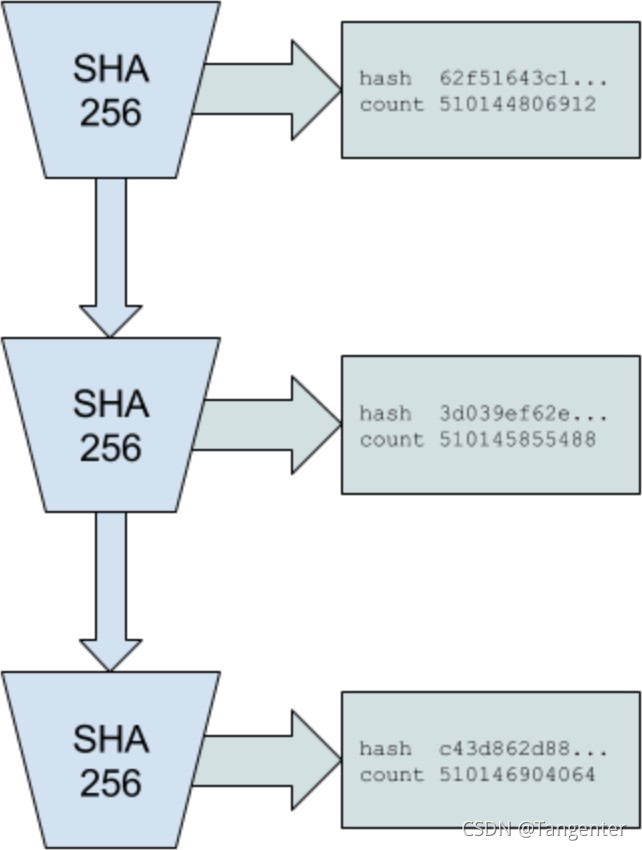
该系统按如下方式工作:对于一个不运行便无法预测其输出的加密哈希函数(例如SHA256,RIPEMD等哈希函数),我们从某个随机初始值开始运行此函数,并将每次运行的输出作为输入再次传递给同一函数,同时记录该函数被调用的次数和每次调用后的输出。选择的随机初始值可以是任何字符串,比如当天的《纽约时报》头版标题。如下所示:
| PoH序列 | ||
|---|---|---|
| 索引 | 操作 | 输出哈希值 |
| 1 | sha256(”随机初始值”) | hash1 |
| 2 | sha256(hash1) | hash2 |
| 3 | sha256(hash2) | hash3 |
此处的hashN代表省略后的哈希值。
在实际操作中,只需要以一定间隔发布哈希值和索引的子集即可。如下所示:
| PoH序列 | ||
|---|---|---|
| 索引 | 操作 | 输出哈希值 |
| 1 | sha256(”随机初始值”) | hash1 |
| 200 | sha256(hash199) | hash200 |
| 300 | sha256(hash299) | hash300 |
再重复一遍:如果不从初始值起实际运行算法300次,就无法预测索引值为300时的哈希值将是什么。所以,只要选择的哈希函数具备足够好的防冲突性,这组哈希值就只能由单个计算机线程按顺序计算得到。由此我们可以推断,在索引0和索引300之间必定经过了一段真实存在的时间。
在图2的示例中,哈希值62f51643c1在索引510144806912处产生,哈希值c43d862d88在索引510146904064处产生。根据上文讨论过的PoH算法的属性,我们确信在索引510144806912和索引510146904064之间经过了一段真实存在的时间。
4.2 事件时间戳
这一哈希值序列也可用于记录“某段数据在特定哈希值索引生成之前被创建”这一信息。使用“合并”函数将这段数据与当前索引处的哈希值合并。该数据可以是任意事件数据的哈希值。“合并”函数可以简单地将数据追加至末尾,也可以是能够防止哈希冲突的任何操作。下一个生成的哈希值即表示该数据的时间戳,因为它只能在插入特定数据段之后生成。举例如下:
| PoH序列 | ||
|---|---|---|
| 索引 | 操作 | 输出哈希值 |
| 1 | sha256(”随机初始值”) | hash1 |
| 200 | sha256(hash199) | hash200 |
| 300 | sha256(hash299) | hash300 |
此后发生了一些外部事件,例如一张照片被上传,或者任意文件被创建:
| 带数据的PoH序列 | ||
|---|---|---|
| 索引 | 操作 | 输出哈希值 |
| 1 | sha256(”随机初始值”) | hash1 |
| 200 | sha256(hash199) | hash200 |
| 300 | sha256(hash299) | hash300 |
| 336 | sha256(append(hash335,photograph_sha256)) | hash336 |
hash335在和照片的哈希值合并之后经计算得出了hash336。索引值和照片的哈希值都被记录为序列输出的一部分,因此该序列的任何验证者都可以重新模拟改变该序列的过程。验证步骤同样可以并行处理,这将在4.3小节中讨论。
由于初始过程仍然是有序的,所以我们可以断定,输入到序列中的事件必定发生于算出未来的哈希值之前的某个时间。
| PoH序列 | ||
|---|---|---|
| 索引 | 操作 | 输出哈希值 |
| 1 | sha256(”随机初始值”) | hash1 |
| 200 | sha256(hash199) | hash200 |
| 300 | sha256(hash299) | hash300 |
| 336 | sha256(append(hash335,photograph1_sha256)) | hash336 |
| 400 | sha256(hash399) | hash400 |
| 500 | sha256(hash499) | hash500 |
| 600 | sha256(append(hash599,photograph2_sha256)) | hash600 |
| 700 | sha256(hash699) | hash700 |
在表一所代表的序列中,照片2在hash600之前被创建,而照片1在hash336之前被创建。将数据插入哈希值序列会导致后续所有哈希值都被更改。只要使用的哈希函数是防冲突的,且数据被附加上去,就不可能基于哪些数据将被添加到序列中的先验知识来预计算出任何未来的哈希序列。
添加到序列中的数据可以是原始数据本身,也可以是附带元数据的哈希值。
在图三的示例中,输入值cfd40df8…被插入PoH序列。它插入的位置索引是510145855488,状态是3d039eef3。所有将来生成的哈希值都因为本次修改而产生变动,这一变化由图中的颜色更改表示。
每个观察该序列的节点都可以确定事件的插入顺序,并估计每次插入之间的实际时间。

4.3 验证过程
与完整生成序列的过程相比,多核计算机可以在更短的时间内验证序列的正确性。如下所示:
| 处理器1 | ||
|---|---|---|
| 索引 | 操作 | 输出哈希值 |
| 200 | sha256(hash199) | hash200 |
| 300 | sha256(hash299) | hash300 |
| 处理器2 | ||
|---|---|---|
| 索引 | 操作 | 输出哈希值 |
| 300 | sha256(hash299) | hash300 |
| 400 | sha256(hash399) | hash400 |
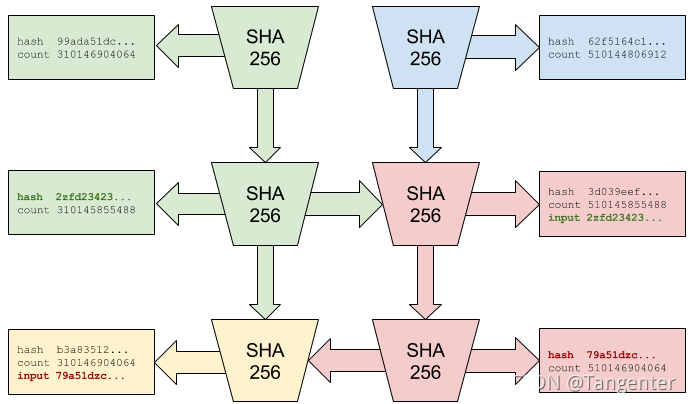
在具有多个处理器的情况下(如具有4000个核心的现代GPU),验证者可以将哈希值序列及其索引拆分成4000个切片,通过并行计算确保每个序列切片中从头到尾的哈希值都是正确的。
如果生成整个序列的预期时间=哈希运算总次数/单核每秒哈希运算次数;
则验证序列正确性的预期时间=哈希运算总次数/(单核每秒哈希运算次数*可用总核数)。
在图四的示例中,每个处理器都能够并行验证序列中的各个片段。由于所有输入字符串都被记录在输出中,且附加了它们的索引和状态,所以验证者们可以并行地重复验证这些片段。标红的哈希值表示该序列在这一步被插入了外部数据。

4.4 横向扩展
我们可以将一个生成器所产生的序列状态混合到另一个生成器当中来同步多个PoH序列生成器,从而实现生成器的横向扩展。这一扩展过程不需要对网络进行分片。被混合的两个生成器的输出对于重建系统中事件的完整顺序是必需的。示例如下:
| PoH序列生成器A | ||
|---|---|---|
| 索引 | 输出哈希值 | 插入数据 |
| 1 | hash1a | |
| 2 | hash2a | hash1b |
| 3 | hash3a | |
| 4 | hash4a |
| PoH序列生成器B | ||
|---|---|---|
| 索引 | 输出哈希值 | 插入数据 |
| 1 | hash1b | |
| 2 | hash2b | hash1a |
| 3 | hash3b | |
| 4 | hash4b |
给定序列生成器A和B,A从B处接收数据包hash1b,其中包含生成器B的上一状态,以及从生成器A处观察到的生成器B的上一状态。由于生成器A输出的下一个哈希值取决于生成器B的状态,因此我们可以推导出hash1b比hash3a要产生得更早。这一属性同样是可传递的,也就是说,假如三个生成器通过A ↔ B ↔ C的过程进行同步,即使A和C之间并没有直接的数据传递,我们仍然可以追踪它们的依赖关系。
通过定期对生成器进行同步,每个生成器都可以只处理外部信息的一部分,从而使整个系统能够处理的事件量显著增加,虽然生成器之间的通信延迟会导致系统时间的准确度下降。不过,网络中事件的全局顺序仍然可以通过选择某个具有确定性的函数来对同步窗口中的事件进行排序(例如哈希值本身的大小)而实现。
在图五中,两个生成器互相插入彼此的输出状态并记录操作。颜色变化表明来自另一生成器的数据已经修改了本序列。被混合到数据流中的哈希值以粗体突出显示。
重复一遍,同步过程是可传递的。在A ↔ B ↔ C的同步过程中,A和C之间存在一个可以验证的事件顺序。
这种扩展方式是以系统的可用性为代价的。10×1Gbps的连接在原可用性为0.999的情况下的新可用性将下降到0.999^10=0.99。
4.5 一致性
网络中的用户需要将自己观察到的合法序列的最后一个输出值添加到他们的输入当中,从而维持已生成序列的一致性和抵抗攻击的能力。
| PoH序列A | ||
|---|---|---|
| 索引 | 插入数据 | 输出哈希值 |
| 10 | hash10a | |
| 20 | 事件1 | hash20a |
| 30 | 事件2 | hash30a |
| 40 | 事件3 | hash40a |
| 隐藏PoH序列B | ||
|---|---|---|
| 索引 | 插入数据 | 输出哈希值 |
| 10 | hash10b | |
| 20 | 事件3 | hash20b |
| 30 | 事件2 | hash30b |
| 40 | 事件1 | hash40b |
如上所示,如果恶意PoH生成器可以一次性访问所有事件,或者生成序列的速度更快,则恶意PoH生成器就可以生成一个具有相反事件顺序的隐藏序列。为防止此攻击,每个客户端生成的事件数据当中都应包含客户端观察到的有效序列当中最新的哈希值。所以,当客户端创建“事件1”数据时,它们应该附加上自己观察到的最后一个哈希值。
| PoH序列A | ||
|---|---|---|
| 索引 | 插入数据 | 输出哈希值 |
| 10 | hash10a | |
| 20 | 事件1=append(事件1原始数据,hash10a) | hash20a |
| 30 | 事件2=append(事件2原始数据,hash20a) | hash30a |
| 40 | 事件3=append(事件3原始数据,hash30a) | hash40a |
当序列发布时,事件3将引用hash30a,如果它不在此事件添加之前的序列输出当中,则该序列的使用者将知道它是无效的。于是,重排序攻击的范围将被限制在从客户端观察到事件起到事件被添加到序列里这段时间当中产生的所有哈希值以内。客户端应当能够编写软件,该软件不假定最后观察到的哈希值到插入序列的哈希值之间存在的少数哈希值顺序是正确的。
为了防止恶意PoH生成器重写客户端事件哈希值,客户端可以同时提交事件数据的签名和最后观察到的哈希值,而不仅仅是数据本身。
| PoH序列A | ||
|---|---|---|
| 索引 | 插入数据 | 输出哈希值 |
| 10 | hash10a | |
| 20 | 事件1=sign(append(事件1原始数据,hash10a),客户端私钥) | hash20a |
| 30 | 事件2=sign(append(事件2原始数据,hash20a),客户端私钥) | hash30a |
| 40 | 事件3=sign(append(事件3原始数据,hash30a),客户端私钥) | hash40a |
验证此数据需要签名,并在之前的哈希值序列中查找哈希值。具体过程如下:
(签名,公钥,hash30a,事件3原始数据)=事件3
验证(签名,公钥,事件3)
查找(hash30a,PoH序列)
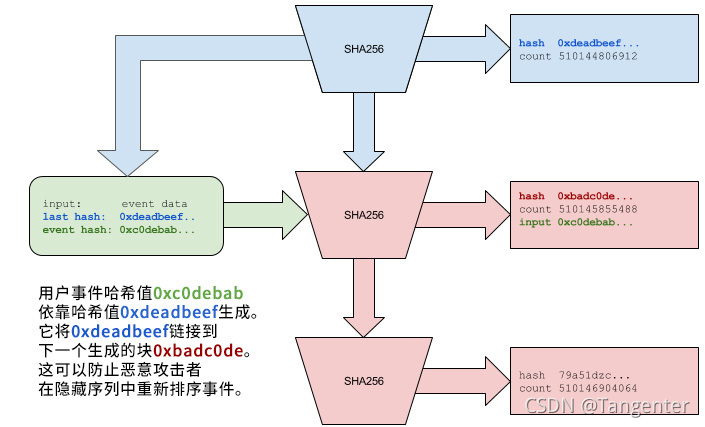
在图六中,用户提供的输入依赖于哈希值0xdeadbeef…,它需要在用户插入数据之前的某个时间就存在于已生成的序列中。左上角的蓝色箭头表示客户端正在引用以前生成的哈希值。客户端消息仅在包含哈希值0xdeadbeef…的序列中有效。变红的部分表示该序列已被客户端数据修改。
4.6 运行消耗
每秒4000次哈希运算将生成160kb的数据,具有4000个内核的GPU大约需要0.25-0.75毫秒的时间对其进行验证。
4.7 攻击
4.7.1 重排序攻击
生成一个反向序列要求攻击者在第二个事件产生之后才能启动恶意序列的生成过程,这段延迟应当足以让任何非恶意节点间就序列的原始顺序进行交流。
4.7.2 速度
使用多个序列生成器可能会使部署后的网络更能抵御攻击。举例而言,可以让一个高带宽的序列生成器接收大量事件并将其混合到自己生成的序列当中,让另一个速度快但低带宽的序列生成器周期性地把输出结果和前者混合。高速生成的序列将创建一个攻击者必须反转的次要数据序列。
4.7.3 远距离攻击
远距离攻击的一种方式是获取废弃的旧客户端私钥,并生成伪造的区块链账本。PoH算法提供了一些针对远距离攻击的保护。获得旧私钥访问权限的恶意用户将不得不重新创建一条历史记录,其花费的时间与生成他们试图伪造的原始记录一样长。这将需要比网络当前使用的处理器更快的处理器,否则攻击者永远无法赶上序列的总长度。
此外,单一的时间来源允许构建更简单的复制证明算法(在第6节中有更多介绍),因为网络被设计成其中所有参与者都依赖于同一份事件历史记录的模式。
PoREP和PoH算法共同提供了对伪造区块链账本的空间和时间防御。