导航
- 前言
- 代码结构
- 展示界面
- 帮助文档
前言
紧接上一款fofa爬虫,这一款Jumper_Waf2.0做了重大更新,主要是界面优化,和添加了目录扫描功能,可以直接在子域名扫描模块搜索到的url_txt直接用于目录扫描模块的批量化处理功能,其次,在目录扫描模块,继承了前面的爬虫模块的自定义header头值、代理模块、增加了延时功能和超时功能,可以绕过市面上大多数的waf防护。
fofa稳定爬虫1.0链接
代码结构
整体代码结构(易于二次开发,模块清晰)
展示界面
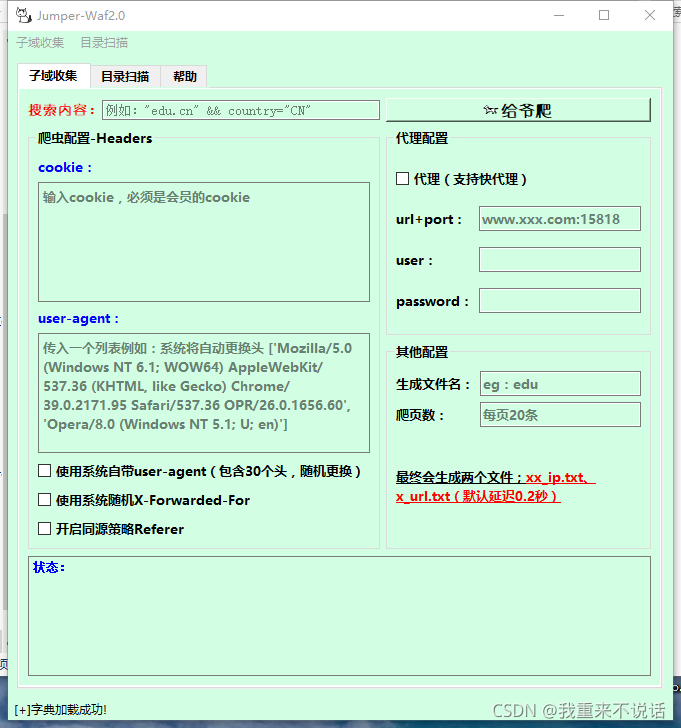
本次更新最大特点是可以 子域名收集与目录扫描联动进行批量url过墙扫描
帮助文档
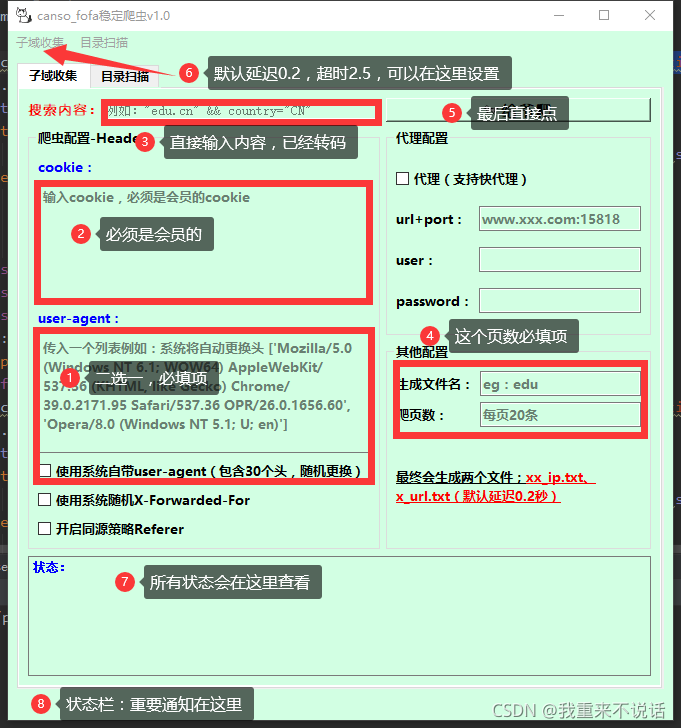
子域名收集:
1.标红的地方,都是必填项,否则无法运行;
2.对fofa网站进行子域名爬取,使用到requests库,所以延时和超时已经默认,默认为延时0.2s,超时2.5s,可在子域收集那修改;
3.代理功能,暂时只能使用快代理->https://www.kuaidaili.com/(并非推广,是指觉得这个好用,如果你发现其他很好用的请联系我);
4.生成的文件在当前目录下,别忘了;
5.保存的配置文件(先点击运行后在保存,不然无法成功,也可以自行写入配置文件,eg内容:{‘User-agent’:‘xxx’,‘Cookie’:‘xxx’,‘X-Forwarded-For’:‘xxx’,‘Referer’:‘xxx’),会存放在当前目录下,名为fofa_search.ini;
6.运行后会保存俩个文件,在当前目录下,xxx_url.txt\xxx_ip.txt;
↓↓↓↓↓↓↓↓↓↓↓↓
↓↓↓↓↓↓↓↓↓↓↓↓
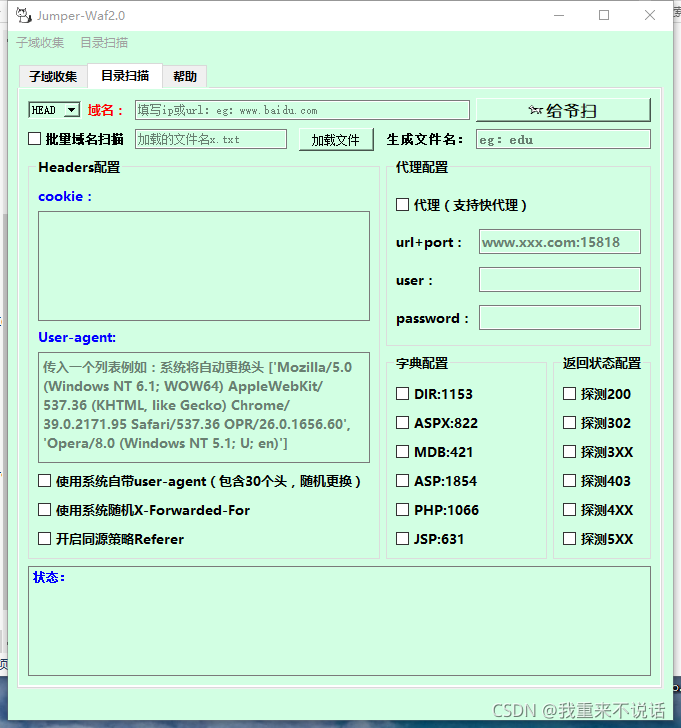
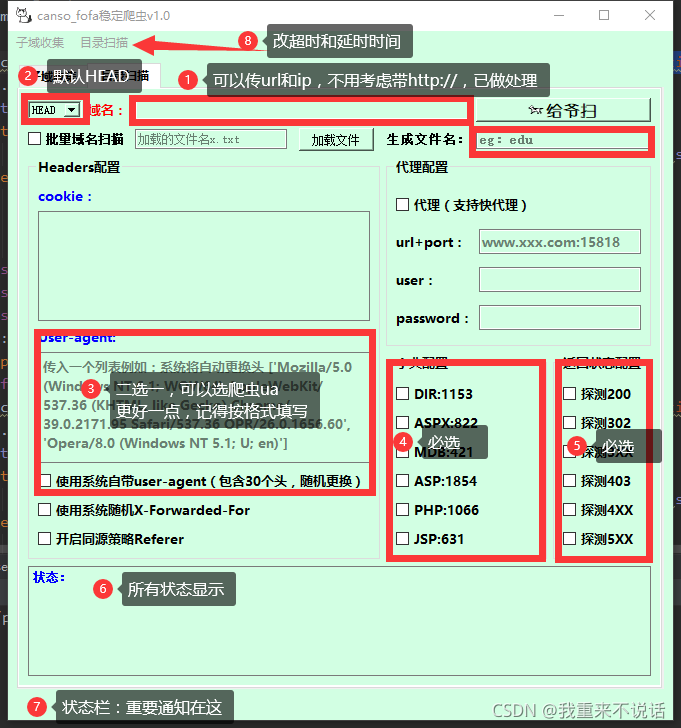
目录扫描:
1.标红的地方,都是必填项,否则无法运行;
2.使用批量域名扫描时,要把txt文件放在当前目录下,并把文件名填入,点击加载,下方提示加载成功才可以;
3.代理功能,暂时只能使用快代理->https://www.kuaidaili.com/(并非推广,是指觉得这个好用,如果你发现其他很好用的请联系我);
4.生成的文件在当前目录下,别忘了;
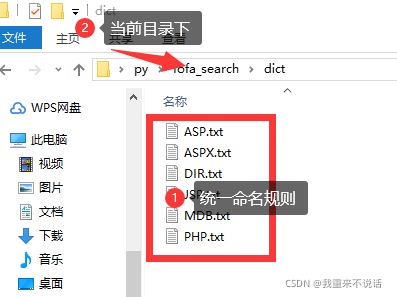
5.字典配置:将字典放在当前目录下的dict文件夹内,字典文件命名为ASP.txt、PHP.txt、ASPX.txt、JSP.txt、MDB.txt、DIR.txt(系统只能读取这种文件名,暂时不能自定义,后续会更新);
6.保存的配置文件(先点击运行后在保存,不然无法成功,也可以自行写入配置文件,eg内容:{‘User-agent’:‘xxx’,‘Cookie’:‘xxx’,‘X-Forwarded-For’:‘xxx’,‘Referer’:‘xxx’),会存放在当前目录下,名为fofa_search.ini;
7.运行后会保存一个文件,在当前目录下,xxx_当前时间_status_txt;
8.对于WAF防护:
(1)UA头方面的,可以使用随机头,或者使用爬虫UA;
(2)CC防护,简单的ip验证可以使用X-Forwarded-For随机,高级的ip验证必须使用代理了;
(3)请求时间方面的,可以利用更改延时时间;
(4)其他情况,具体而定,软件基本涵盖了大部分绕过waf的方法,可以多加尝试;
↓↓↓↓↓↓↓↓↓↓↓↓
↓↓↓↓↓↓↓↓↓↓↓↓
↓↓↓↓↓↓↓↓↓↓↓↓
↓↓↓↓↓↓↓↓↓↓↓↓