【R语言文本挖掘】:情感分析与词云图绘制
?个人主页:JoJo的数据分析历险记?个人介绍:小编大四统计在读,目前保研到统计学top3高校继续攻读统计研究生?如果文章对你有帮助,欢迎✌
关注、?点赞、✌收藏、?订阅专栏✨本文收录于【R语言文本挖掘】本系列主要介绍R语言在文本挖掘领域的应用包括:情感分析、TF-IDF、主题模型等。本系列会坚持完成下去,请大家多多关注点赞支持,一起学习~,尽量坚持每周持续更新,欢迎大家订阅交流学习! 
引言
在上一章中,我们深入探讨了tidy data的含义,并展示了如何使用这种格式来处理有关词频的问题。这使我们能够分析文档中最常用的单词并比较文档,但现在让我们研究一个不同的问题。让我们讨论情绪分析的主题。当我们阅读一段文本时,我们会利用我们对词语情感意图的理解来推断一段文本是正面的还是负面的,或者可能以其他更细微的情绪为特征,如惊讶或厌恶。 我们可以使用文本挖掘工具以编程方式处理文本的情感内容,如下图所示

上图演示了如何使用 tidytext 进行情感分析的典型文本分析流程图。本章展示了如何使用 tidy data 原则来实现情感分析。
分析文本情感的一种方法是将文本视为单个单词的组合,将整个文本的情感内容视为各个单词的情感内容的总和。这不是进行情绪分析的唯一方法,但它是一种常用的方法,也是一种自然利用整洁工具生态系统的方法。
1.情感数据集
如上所述,存在多种用于评估文本中的观点或情感的方法和字典。 tidytext 包提供了对几个情感词典的访问。三个通用词典是:
所有这三个词典都基于一元词组(unigram),即单个单词。这些词典包含许多英语单词,并且这些单词被分配了正面/负面情绪的分数,也可能是喜悦、愤怒、悲伤等情绪。 nrc 词典以二进制方式(“是”/“否”)将单词分类为积极、消极、愤怒、预期、厌恶、恐惧、快乐、悲伤、惊讶和信任的类别。bing词典以二进制方式将单词分为正面和负面类别。 AFINN 词典为单词分配一个介于 -5 和 5 之间的分数,负分表示负面情绪,正分表示正面情绪。
在下载数据之前,我们可能会被要求同意许可。如果在jupyter-notebook里面运行的话会失败,建议大家在rstudio里面先运行下载。
函数 get_sentiments() 允许我们获取特定的情感词典,并为每个词典提供适当的度量。我们现在来看一下各个情绪词典的信息
library(`tidytext`)library(dplyr)get_sentiments("nrc") %>% head()| word | sentiment |
|---|---|
| <chr> | <chr> |
| abacus | trust |
| abandon | fear |
| abandon | negative |
| abandon | sadness |
| abandoned | anger |
| abandoned | fear |
get_sentiments("bing") %>% head()| word | sentiment |
|---|---|
| <chr> | <chr> |
| 2-faces | negative |
| abnormal | negative |
| abolish | negative |
| abominable | negative |
| abominably | negative |
| abominate | negative |
get_sentiments("afinn") %>% head()| word | value |
|---|---|
| <chr> | <dbl> |
| abandon | -2 |
| abandoned | -2 |
| abandons | -2 |
| abducted | -2 |
| abduction | -2 |
| abductions | -2 |
这些词典都是通过整合云资源、餐厅或电影评论等数据的某种组合进行验证。鉴于这些信息,我们可能会犹豫将这些情感词典应用于与它们所验证的文本风格截然不同的文本风格,例如 200 年前的叙事小说,虽然可能这些情感词典来分析之前作家的小说可能不完全准确,但为了方便分析,这里我们还是使用这些词典来进行情感分析.还有一些特定领域的情感词典可用,用于分析来自特定内容领域的文本。后续我们会探讨使用用于金融的情绪词典的分析。
我们通过基于字典的方法通过将文本中每个单词的单独情绪分数相加来找到一段文本的总情绪。
但是并非每个英语单词都在词典中,因为许多英语单词都是相当中性的。重要的是要记住,这些方法不考虑单词前的限定词,例如“no good”或“not true”;像这样的基于词典的方法仅基于 unigrams。如果要根据上下文分析的话,我们需要使用语言模型来解决,这在后续将进行相关介绍。需要注意的是:我们使用累加 unigram 情绪分数的方法可能会受到文本块的大小的影响。 当大段落的文本通常可以具有平均为零的正面和负面情绪,而向几句话句子大小或段落大小的文本通常效果更好。
2.使用内连接进行情感分析
使用tidydata格式的数据,可以将情感分析作为内连接来完成。这是将文本挖掘视为一项整洁的数据分析任务的又一巨大成功;就像删除停用词是一种反连接操作一样,执行情感分析是一种内连接操作。
让我们看一下 NRC 词典中带有joy的单词。Emma中最常见的快乐词是什么?首先,我们需要获取小说的文本,并使用 unnest_tokens() 将文本转换为整洁的格式,就像我们在上一篇文章中所做的那样。让我们还设置一些其他列来跟踪每个单词来自书的哪一行和哪一章;我们使用 group_by 和 mutate 来构造这些列。具体代码如下:
library(janeaustenr)library(dplyr)library(stringr)tidy_books <- austen_books() %>% group_by(book) %>% mutate( linenumber = row_number(), chapter = cumsum(str_detect(text, regex("^chapter [\\divxlc]", ignore_case = TrUE)))) %>%#使用正则表达式来定义章节 ungroup() %>% unnest_tokens(word, text)#分词tidy_books %>% head()| book | linenumber | chapter | word |
|---|---|---|---|
| <fct> | <int> | <int> | <chr> |
| Sense & Sensibility | 1 | 0 | sense |
| Sense & Sensibility | 1 | 0 | and |
| Sense & Sensibility | 1 | 0 | sensibility |
| Sense & Sensibility | 3 | 0 | by |
| Sense & Sensibility | 3 | 0 | jane |
| Sense & Sensibility | 3 | 0 | austen |
注意,我们从 unnest_tokens() 中为输出列选择了名称 word。这是一个方便的选择,因为情感词典和停用词数据集都有名为 word 的列;执行内部连接和反连接因此更容易。
现在文本的格式很整洁,每行一个单词,我们准备好进行情绪分析了。首先,让我们使用 NRC 词典和 filter() 来表示快乐的词。接下来,让我们使用filter来筛选来自 Emma 的单词,然后使用 inner_join() 执行情绪分析。艾玛中最常见的joy是什么?让我们使用 dplyr 中的 count()。
nrc_joy <- get_sentiments("nrc") %>% filter(sentiment == "joy")tidy_books %>% filter(book=='Emma') %>% inner_join(nrc_joy) %>% count(word,sort=TrUE)%>% head()| word | n |
|---|---|
| <chr> | <int> |
| good | 359 |
| friend | 166 |
| hope | 143 |
| happy | 125 |
| love | 117 |
| deal | 92 |
我们在这里看到的大多是关于friend和love的积极、快乐的话语。
我们还可以检查每部小说的情绪如何变化。我们只需几行主要是 dplyr 函数就可以做到这一点。首先,我们使用 Bing 词典和 inner_join() 找到每个单词的情感分数。
接下来,我们计算每本书的某些位置有多少积极和消极的词。这样我们可以分析情绪的变化情况。我们在这里定义一个索引来跟踪我们在叙述中的位置;该索引(使用整数除法)对 80 行文本的部分进行计数。
一小段文本可能没有足够的单词来很好地估计情绪,但对于太大的文本可能会导致正负情绪抵消。对于这些书,使用80行效果很好,但这可能会因单个文本、行的开头长度等而有所不同。然后我们使用 pivot_wider() 以便我们在不同的列中拥有消极和积极的情绪,最后计算净情绪(正面 - 负面)。
library(tidyr)jane_austen_sentiment <- tidy_books %>% inner_join(get_sentiments("bing")) %>%#使用bing情绪词典进行内连接 count(book, index = linenumber %/% 80, sentiment) %>%#按八十行为一个小段进行记数 pivot_wider(names_from = sentiment, values_from = n, values_fill = 0) %>%#将数据转换成宽数据 mutate(sentiment = positive - negative)#计算净情绪,如果大于0说明是积极情绪,小于0说明是消极的jane_austen_sentiment %>% head()| book | index | negative | positive | sentiment |
|---|---|---|---|---|
| <fct> | <dbl> | <int> | <int> | <int> |
| Sense & Sensibility | 0 | 16 | 32 | 16 |
| Sense & Sensibility | 1 | 19 | 53 | 34 |
| Sense & Sensibility | 2 | 12 | 31 | 19 |
| Sense & Sensibility | 3 | 15 | 31 | 16 |
| Sense & Sensibility | 4 | 16 | 34 | 18 |
| Sense & Sensibility | 5 | 16 | 51 | 35 |
现在我们可以在每部小说的情节轨迹上绘制这些情绪分数。请注意,我们绘制在x轴上的索引,是对应的小段文本,即每隔八十行为一段,这也反应了每本书的时间情绪变化
library(ggplot2)ggplot(jane_austen_sentiment, aes(index, sentiment, fill = book)) + geom_col()+#绘制柱形图 facet_wrap(~book, ncol = 2, scales = "free_x")#根据不同书进行分面绘图,两行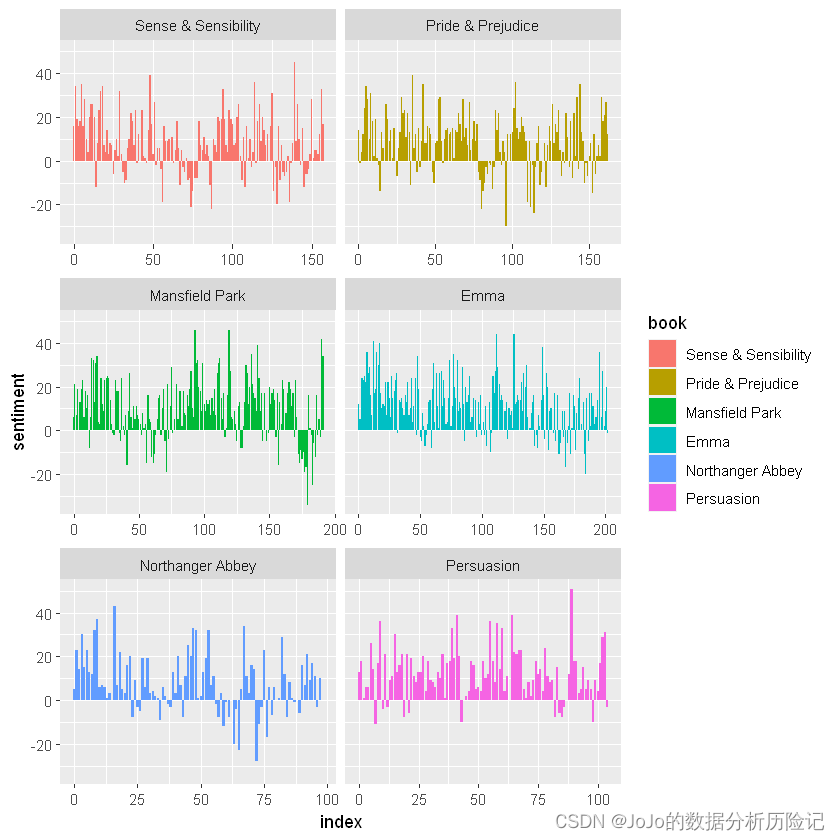
我们可以在上图中看到,每部小说故事情节的情绪变化
3.对比三种情感字典
如何选用不同的情绪词典,我们可能需要更多信息,了解哪一个适合我们研究的目的。现在我们使用三个不同的情感词典,并分析情感在《傲慢与偏见》中是如何变化的。 首先,让我们使用 filter() 从我们感兴趣的一本小说中选择单词。代码如下:
pride_prejudice <- tidy_books %>% filter(book == 'Pride & Prejudice')pride_prejudice %>% head()| book | linenumber | chapter | word |
|---|---|---|---|
| <fct> | <int> | <int> | <chr> |
| Pride & Prejudice | 1 | 0 | pride |
| Pride & Prejudice | 1 | 0 | and |
| Pride & Prejudice | 1 | 0 | prejudice |
| Pride & Prejudice | 3 | 0 | by |
| Pride & Prejudice | 3 | 0 | jane |
| Pride & Prejudice | 3 | 0 | austen |
我们现在可以使用inner_join()计算不同形式的情感
注意:AFINN词典是通过-5—+5来衡量情感的。而其他两个词典以二进制方式对情感单词进行分类。
# 使用AFINN词典afinn <- pride_prejudice %>% inner_join(get_sentiments("afinn")) %>% #内连接,得到带有情感的文本 group_by(index = linenumber %/% 80) %>% #每隔80行作为一小段 summarise(sentiment = sum(value)) %>% #这里我们进行一个求和处理,因为这里是以数字表示情感的 mutate(method = "AFINN")# bing词典bing <- pride_prejudice %>% inner_join(get_sentiments("bing")) %>%#使用bing词典进行内连接 mutate(method = "Bing")%>% count(index = linenumber %/% 80, sentiment) %>% pivot_wider(names_from = sentiment, values_from = n, values_fill = 0) %>% mutate(sentiment = positive - negative)# 使用nrc词典nrc <- pride_prejudice %>% inner_join(get_sentiments("nrc") %>% filter(sentiment %in% c('positive','negative'))) %>% mutate(method = "NRC")%>% count(index = linenumber %/% 80, sentiment) %>% pivot_wider(names_from = sentiment, values_from = n, values_fill = 0) %>% mutate(sentiment = positive - negative)现在我们比较使用三个不同词典的结果进行可视化分析
bind_rows(afinn, bing_and_nrc) %>% ggplot(aes(index, sentiment, fill = method)) + geom_col(show.legend = FALSE) + facet_wrap(~method, ncol = 1, scales = "free_y")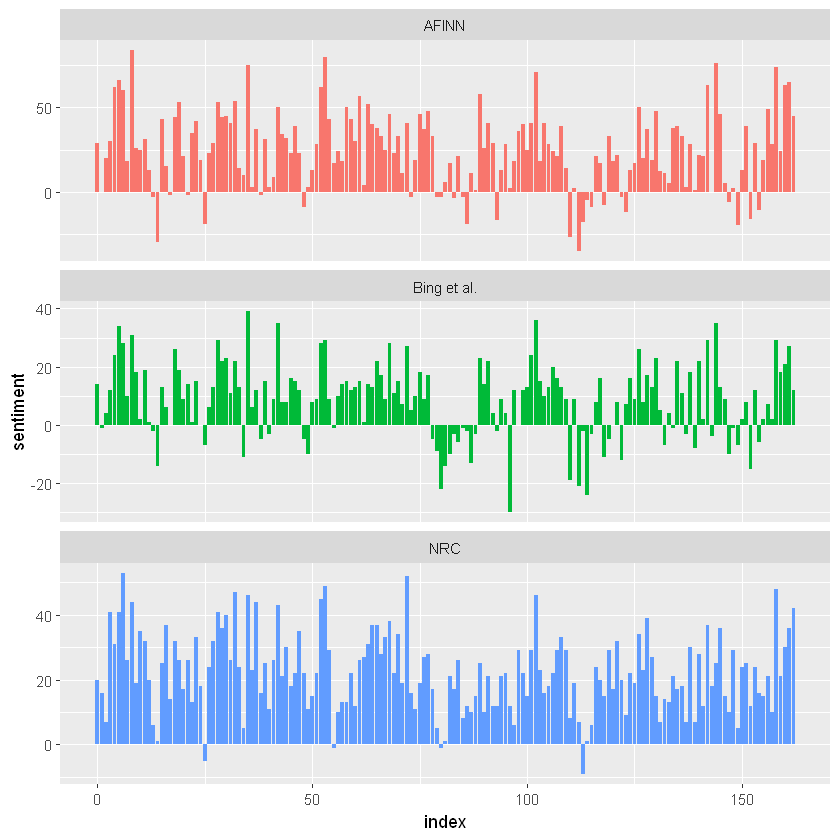
用于情感分析的三个不同词典给出的结果在绝对意义上是不同的,但在小说情节中具有相似的相对轨迹。我们在小说中几乎相同的地方看到了类似的情绪低谷和高峰,但绝对值明显不同。
AFINN词典给出了最大的绝对值,具有较高的正值。Bing 等的词典。具有较低的绝对值,并且似乎标记了较大的连续正面或负面文本块。NRC结果相对于其他两个词典,更积极地标记文本。在查看其他小说时,我们发现这些方法之间存在类似的差异; NRC更偏向给予积极的情绪,AFINN 情绪有更多变化,Bing的情绪似乎会找到更长的相似文本,但三个词典都大致情绪的整体趋势。
例如,与 Bing等词典相比,为什么 NRC 词典的结果在情感上的偏差如此之大。让我们简要地看一下这些词典中有多少积极和消极的词。
get_sentiments('nrc') %>% filter(sentiment %in% c('positive','negative')) %>% count(sentiment)| sentiment | n |
|---|---|
| <chr> | <int> |
| negative | 3316 |
| positive | 2308 |
get_sentiments('bing') %>% count(sentiment)| sentiment | n |
|---|---|
| <chr> | <int> |
| negative | 4781 |
| positive | 2005 |
两个词典的否定词都多于肯定词,但 Bing 词典中否定词与肯定词的比率高于 NRC 词典。这将有助于分析我们在上图中看到的效果,以及单词匹配中的任何系统差异,例如如果 NRC 词典中的否定词与简·奥斯汀使用得很好的词不匹配。无论这些差异的来源是什么,在选择情感词典进行分析时,这些都是要注意.
4.最常见的积极和消极的单词
拥有情绪和词的数据框的一个优点是我们可以分析对每种情绪有贡献的词数。通过在此处使用word和sentiment参数实现 count(),我们找出了每个词都构成每种情绪的比例。
bing_word_count <- tidy_books %>% inner_join(get_sentiments('bing')) %>% count(word, sentiment, sort = TrUE) %>% ungroup()[1m[22mJoining, by = "word"bing_word_count %>% head()| word | sentiment | n |
|---|---|---|
| <chr> | <chr> | <int> |
| miss | negative | 1855 |
| well | positive | 1523 |
| good | positive | 1380 |
| great | positive | 981 |
| like | positive | 725 |
| better | positive | 639 |
这可以直观地显示出来各个积极和消极的词数量, 我们可以使用ggplot2,因为我们一直在使用为处理整洁的数据帧而构建的工具。
bing_word_count %>% group_by(sentiment) %>% slice_max(n, n = 10) %>% #删选出前10的 ungroup() %>% mutate(word = reorder(word, n)) %>%#重新排序 ggplot(aes(n, word, fill = sentiment)) + geom_col(show.legend = FALSE) + facet_wrap(~sentiment, scales = "free_y") + labs(x = "Contribution to sentiment", y = NULL)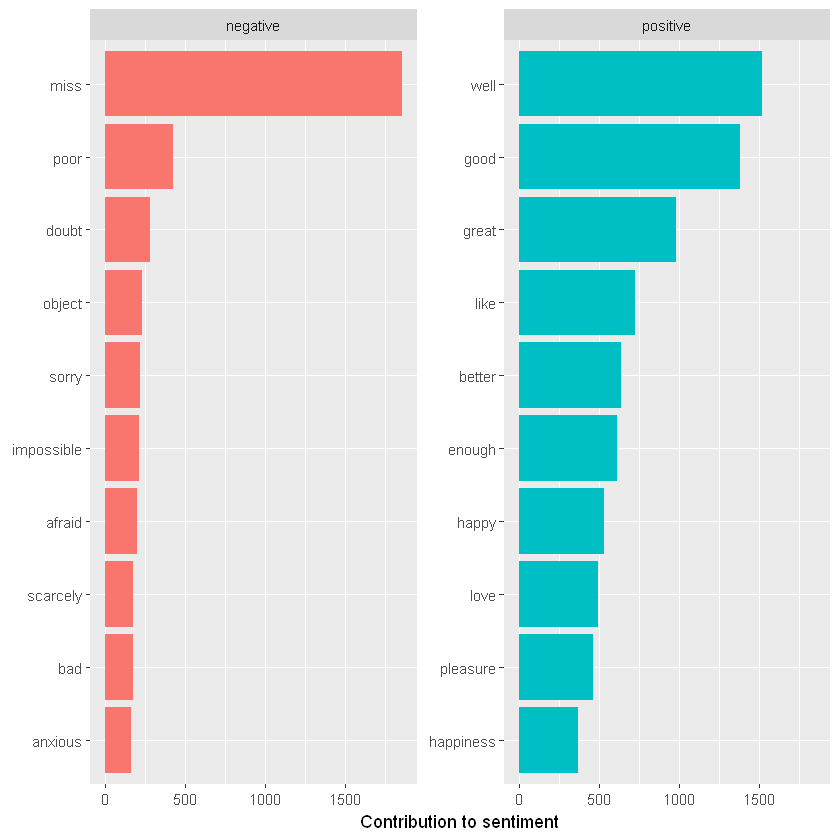
上图我们发现了情绪分析中的异常情况; “miss”这个词被判断否定词, 但在简·奥斯汀的作品中,它被用作年轻未婚女性的称号。为了去除这样的错误,我们可以使用 bind_rows() 轻松地将“miss”添加到自定义停用词列表中。我们可以通过这样的策略来实现它。
custom_stop_words <- bind_rows(tibble(word = c("miss"), lexicon = c("custom")), stop_words)custom_stop_words %>% head()| word | lexicon |
|---|---|
| <chr> | <chr> |
| miss | custom |
| a | SMArT |
| a's | SMArT |
| able | SMArT |
| about | SMArT |
| above | SMArT |
5.词云绘制
我们已经看到,这种整洁的文本挖掘方法与 ggplot2 配合得很好,但是让我们的数据以整洁的格式显示对其他绘图也很有用。
例如,考虑使用基本 r 图形的 wordcloud 包。这样我们就可以绘制词云图。
library(wordcloud)tidy_books %>% anti_join(stop_words) %>% count(word) %>% with(wordcloud(word, n, max.words = 100))#出现次数最多的前100个
现在我们进一步进行情感分析的词云图绘制, 使用内连接标记正面和负面词,然后找到最常见的正面和负面词。在这里我们需要使用reshape2包的comparison.cloud()函数,其余操作和我们之前一样
library(reshape2)tidy_books %>% inner_join(get_sentiments("bing")) %>% count(word, sentiment, sort = TrUE) %>% acast(word ~ sentiment, value.var = "n", fill = 0) %>% comparison.cloud(colors = c("blue", "red"), max.words = 100)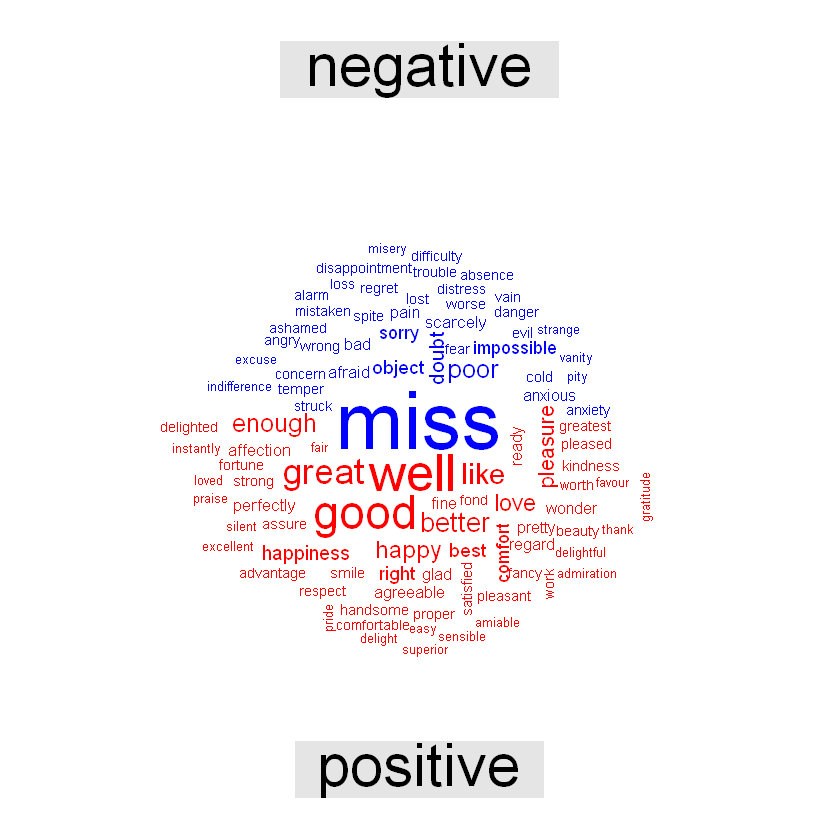
上图中,单词文本的大小与其在情绪中的频率成正比。我们可以使用这种可视化来查看最重要的正面和负面词,但词的大小在不同情绪之间没有可比性
6.总结
情感分析提供了一种理解文本中表达的态度和观点的方法。在本章中,我们探讨了如何使用整洁的数据原则进行情感分析;当文本数据在一个整洁的数据结构中时,情感分析可以通过内连接实现。我们可以使用情感分析来了解小说情节在其整个过程中如何变化,或者哪些具有情感和观点内容的词对特定文本很重要。
✨✨✨如果文章对你有帮助,请多多点赞、收藏、评论、关注支持!!
参考资料:Text Mining with R